







 本文分析了一数据集中用户的各种特征与信用卡申请结果的关系,探讨了特征选择、模型建立及处理数据不平衡的方法。通过随机森林、支持向量机和XGBoost模型,研究了性别、收入、职业等因素对申请影响,并展示了模型性能和特征重要性。
本文分析了一数据集中用户的各种特征与信用卡申请结果的关系,探讨了特征选择、模型建立及处理数据不平衡的方法。通过随机森林、支持向量机和XGBoost模型,研究了性别、收入、职业等因素对申请影响,并展示了模型性能和特征重要性。
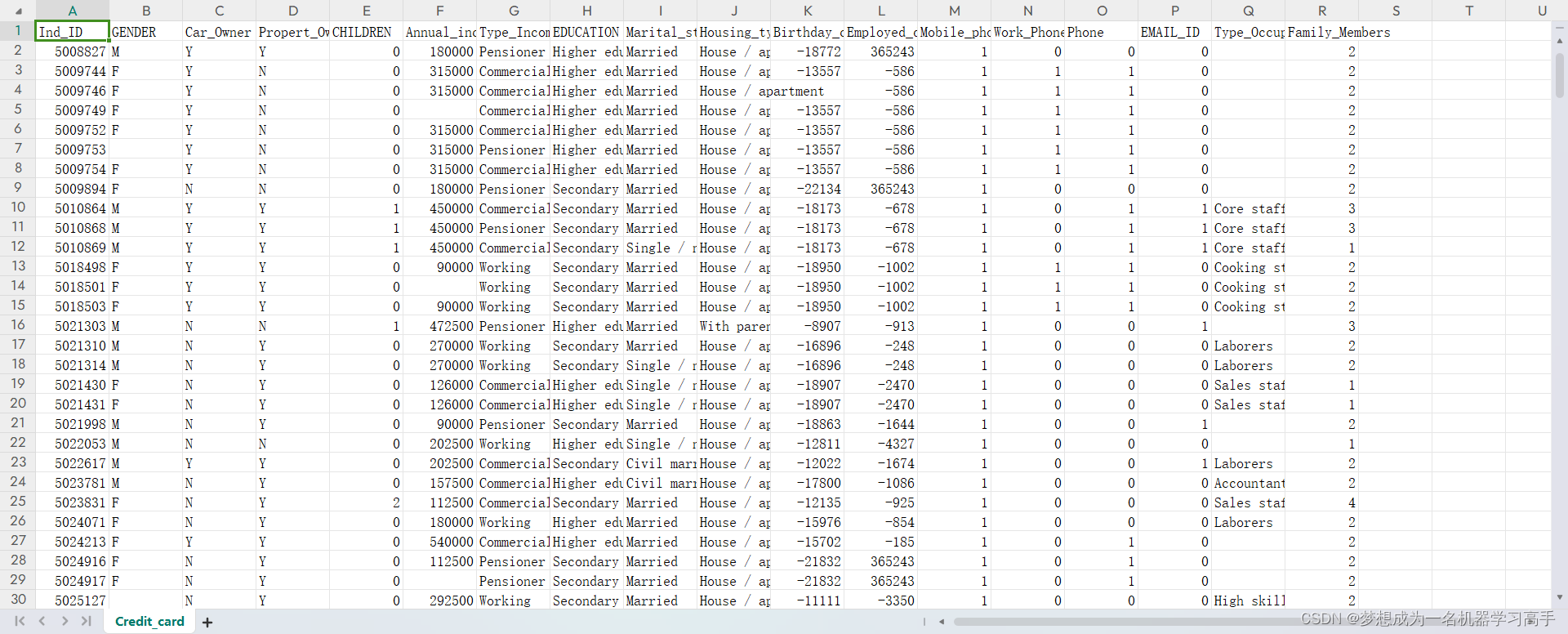
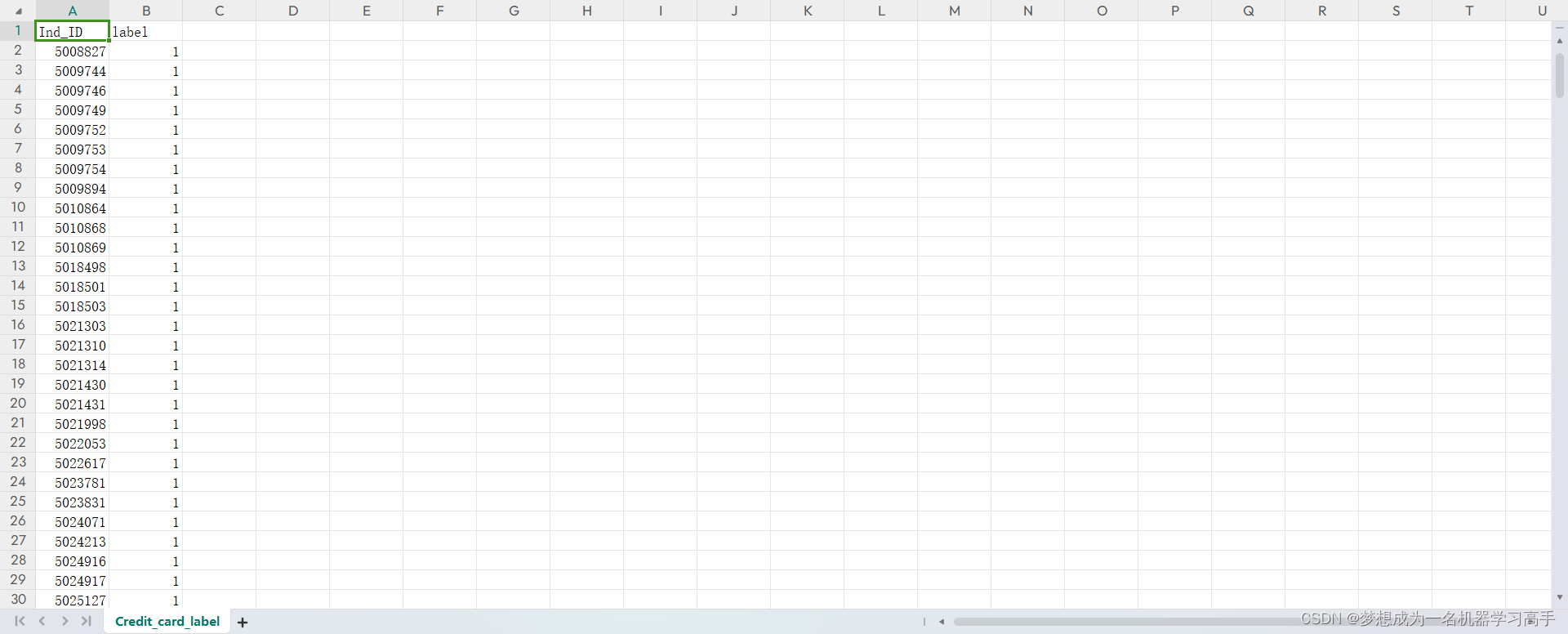
数据集的截图
# 字段 说明 # Ind_ID 客户ID # Gender 性别信息 # Car_owner 是否有车 # Propert_owner 是否有房产 # Children 子女数量 # Annual_income 年收入 # Type_Income 收入类型 # Education 教育程度 # Marital_status 婚姻状况 # Housing_type 居住方式 # Birthday_count 以当前日期为0,往前倒数天数,-1代表昨天 # Employed_days 雇佣开始日期。以当前日期为0,往前倒数天数。正值意味着个人目前未就业。 # Mobile_phone 手机号码 # Work_phone 工作电话 # Phone 电话号码 # EMAIL_ID 电子邮箱 # Type_Occupation 职业 # Family_Members 家庭人数 # Label 0表示申请通过,1表示申请拒绝 # 知道了数据集的情况,我们来看问题 # 问题描述 # 用户特征与信用卡申请结果之间存在哪些主要的相关性或规律?这些相关性反映出什么问题? # # 从申请用户的整体特征来看,银行信用卡业务可能存在哪些风险或改进空间?数据反映出的问题对银行信用卡业务有哪些启示? # # 根据数据集反映的客户画像和信用卡申请情况,如果你是该银行的风控或市场部门负责人,你会提出哪些战略思考或建议? # # 参考分析角度 # 用户画像分析 # # 分析不同人口统计学特征(如性别、年龄、婚姻状况等)对信用卡申请的影响和规律 # 分析不同社会经济特征(如收入、职业、教育程度等)与申请结果的关系 # 特征选取和模型建立 # # 评估不同特征对预测信用卡申请结果的重要性,进行特征筛选 # 建立信用卡申请结果预测模型,评估模型性能 # 申请结果分析 # # 分析不同用户群的申请通过率情况,找到可能的问题原因 # 对申请被拒绝的用户进行细分,寻找拒绝的主要原因 # 知道问题后,我们先进行数据预处理
print(data.info()) # 有缺失值
print(data.isnull().sum() / len(data)) # 可以看出有的列缺失值有点多# GENDER 7 Annual_income 23 Birthday_count 22 Type_Occupation 488 # GENDER 0.004522 Annual_income 0.014858 Birthday_count 0.014212 Type_Occupation 0.315245 # Type_Occupation 0.315245 这一列缺失值数据占比有点高了,但是,这一列是职业,跟我们的业务相关性较高,我觉得应该将缺失值单独分为一个属性 # 其他的列的缺失值较少,woe们可以填充,也可以删除,我觉得对于信用卡这种模型精度要求较严的,我们就删除,填充的值不是很准确,可能对模型造成一定的影响 # 观察数据,我们可以发现,ID,电话号,邮箱这种特征对我们来说没有用 ,生日记数我也感觉没用
data['Type_Occupation'] = data['Type_Occupation'].fillna("无") 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 7686
7686

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









