






一. DEC 深度嵌入聚类
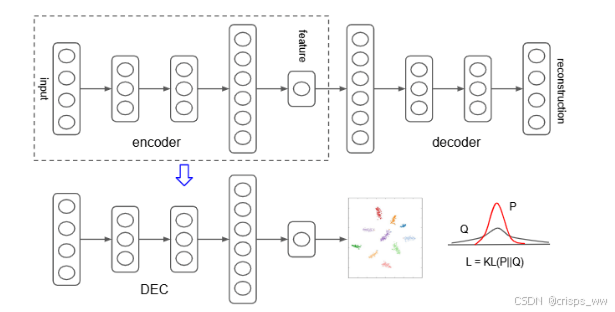
1.KL散度聚类
在DEC论文中,聚类过程通过KL散度(Kullback-Leibler Divergence)来优化,并涉及一个非线性映射 和一组初始聚类中心 。整个过程是一个迭代的无监督学习算法,交替执行步骤,直至满足收敛条件。
(1)soft assignment软分配计算
论文中详细解释了软分配(Soft Assignment)的计算方法,该方法基于Maaten和Hinton(2008)的研究。软分配是一种衡量嵌入点 与聚类中心
之间相似度的方法,允许一个样本属于多个聚类的概率分布。具体计算步骤如下:
·计算距离:首先,计算每个嵌入点 与每个聚类中心
之间的欧氏距离的平方。
·调整距离:将上述距离平方除以Student's t-分布的自由度参数 并加1,得到。这里α控制分布的尖锐程度,通常设为1以保证无监督学习的稳定性。
·计算相似度:对上一步的结果取倒数并乘以 ,得到
。这个表达式衡量了嵌入点
与聚类中心
之间的相似度。
·归一化:对每个聚类中心 j,计算上述相似度表达式的值,并进行归一化处理,即除以所有聚类中心相似度之和,得到软分配概率。
软分配概率 表示在给定参数α 的情况下,将样本i 分配到聚类 j 的概率。软分配允许一个样本属于多个聚类。这种方法在聚类分析中提供了更灵活的数据表示,有助于处理复杂的数据结构和关系。
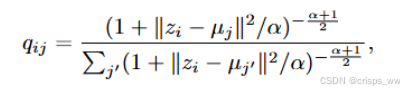
(2)KL散度最小化
核心思想是:通过辅助目标分布(auxiliary target distribution)对高置信度的聚类结果进行迭代优化。具体而言,该方法通过将模型的软分配结果与目标分布进行匹配,从而优化模型。
qi:代表模型输出的软分配结果,即每个样本被分配到不同聚类的概率分布。可以理解为当前模型对样本类别的判断。
pi:代表辅助的目标分布,是根据当前软分配调整得到的,引导模型进一步学习。它的设计通常强调那些模型较为确信的分类结果,以进一步减少错误。
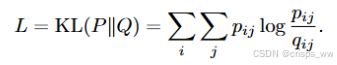
设pi服从delta分布,此法仅对高于置信度阈值的pi有效
:表示数据点i属于聚类中心j的软分配概率,通常由当前模型的输出(如神经层的输出层)计算得出
:目标分布,表示经过调整后的数据点i属于聚类中心j的概率
:软聚类概率,表示当前属于聚类中心j的所有数据点的总概率
目标分布的计算公式如下
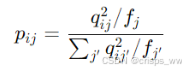
其中,表示当前所有数据点对聚类中心j的软分配概率之和,即聚类中心j的频率
(3)优化
我们旨在优化聚类中心μj和DNN参数θ,引入带动量的随机梯度下降法
论文中提到损失函数L对每个数据点的特征空间嵌入和每个聚类中心
的梯度计算方式如下
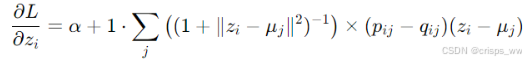
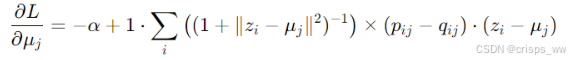
计算梯度按BP算法进行,当在两个连续迭代之间,改变聚类分配的点数少于总点数的某个比例(如tol%)时,停止优化过程
2.参数初始化
(1)去噪自动编码器DAE
去噪自动编码器是由两个层组成的神经网络,其目标是从被损坏的数据(即加入噪声的数据)中重构出原始数据,具体操作步骤如下。
·随机损坏输入数据:使用dropout将一部分输入维随机置为零
·编码:损坏后的输入通过编码器层,该层是一个全连接层,使用了某种激活函数
·随机损坏编码后的输出
·解码
整个去噪自动编码器的训练目标是最小化输入 x 和重构输出 y 之间的重构误差,通常使用的是平方误差损失,即 ![]() 。
。
(2)层级训练
网络逐层训练,编码和解码过程中,除了最后一层以及第一对编码-解码对之外,都使用ReLU激活函数。在完成逐层训练之后,将所有编码层拼接在一起,形成一个完整的编码器。接着,将解码层按逆序排列,拼接在一起,形成一个完整的解码器。这样,模型就构建成了一个深度自动编码器。
将整个深度自动编码器进行微调,以最小化整个模型的重构损失,完成微调后,舍弃解码层,仅保留编码层。编码层将作为数据空间到特征空间之间的映射,形成数据的低维嵌入表示。
(3)聚类中心初始化
最后一步是在特征空间中初始化聚类中心。具体过程为:获取嵌入数据点,即将数据通过训练好的编码器,得到数据的嵌入表示。再在嵌入空间上运行标准的K-means聚类算法,初始化K个聚类中心。这些聚类中心就是后续深度嵌入聚类(DEC)过程中使用的初始聚类中心。
二、SDEC半监督自适应深度嵌入聚类
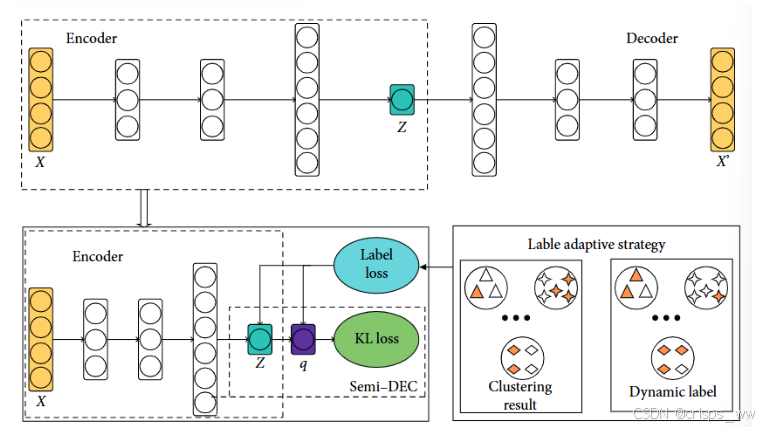
如图,SDEC依然存在KL loss,我们将其定义为L1
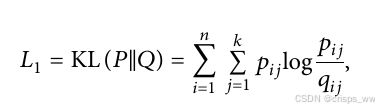
相比于DEC,SDEC的损失增加了一份Label loss用以实现半监督的算法,我们将其定义为L2
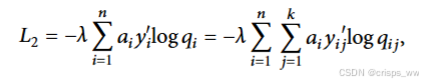
总体损失为
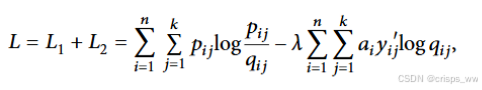
损失优化中,梯度的计算式如下
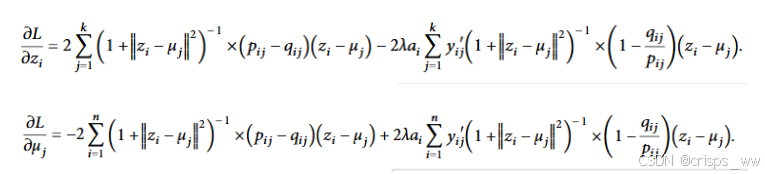
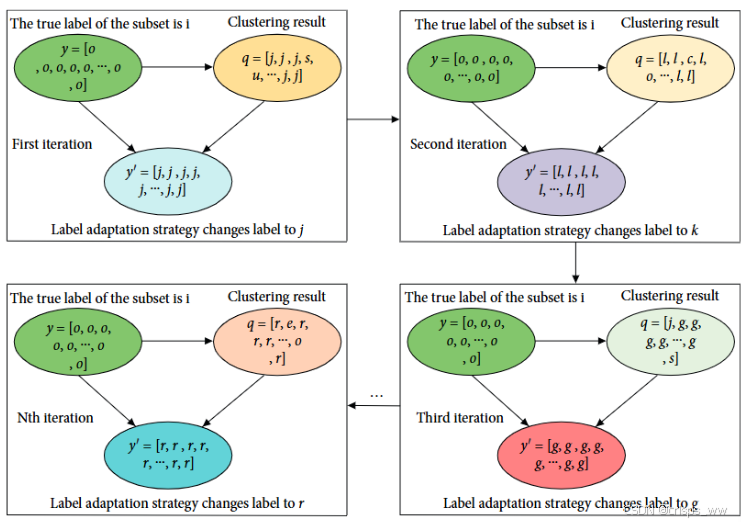
如下为SDEC中引入的投票机制

















 1073
1073

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









