







《MAmmoTH2: Scaling Instructions from the Web》
MAmmoTH2:从网络规模化采集指令数据
摘要
指令调优提升了大语言模型(LLM)的推理能力,其中数据质量和规模化是关键因素。大多数指令调优数据来源于人工众包或GPT-4蒸馏。我们提出一种范式,有效采集1千万条自然存在于预训练网络语料中的指令数据,以提升LLM的推理能力。我们的方法包含三步:(1)召回相关文档,(2)提取指令-响应对,(3)利用开源LLM对提取对进行精炼。在此数据集上微调基础LLM,我们构建了MAmmoTH2模型,显著提升了各类推理基准的性能。值得注意的是,MAmmoTH2-7B(基于Mistral)在MATH数据集的准确率从 11 % 11\% 11%提升至 36.7 % 36.7\% 36.7%,在GSM8K数据集从 36 % 36\% 36%提升至 68.4 % 68.4\% 68.4%,且未使用任何领域内训练数据。进一步在公共指令调优数据集上继续训练,得到MAmmoTH2-Plus模型,在多个推理和聊天机器人基准上达到最先进性能。我们的工作展示了无需昂贵人工标注或GPT-4蒸馏即可收集大规模、高质量指令数据的新范式,为构建更优指令调优数据集提供了新思路。
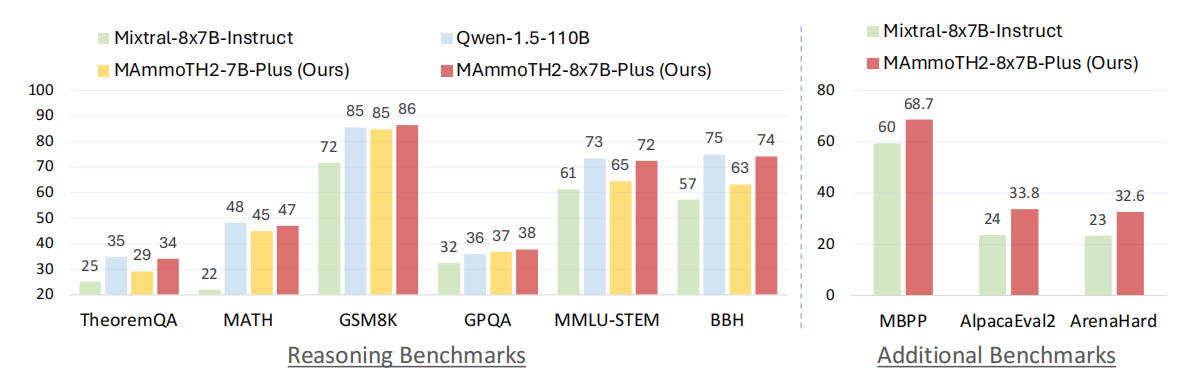
图1:MAmmoTH2-Plus的总体结果概览。MAmmoTH2-8x7B-Plus变体在推理基准上优于Mixtral-Instruct,并且仅用13B激活参数即可匹配Qwen-1.5-110B的性能。在通用代码和聊天机器人基准上也比Mixtral-Instruct高出约10分。
1 引言
推理是人类认知和问题解决的基础[Clark等, 2018; Hendrycks等, 2021a; Cobbe等, 2021; Rein等, 2023; Yue等, 2023a]。推理能力对于推进科学知识、开发新技术以及做出明智决策至关重要。近期,大型语言模型(LLMs)[Brown等, 2020; Ouyang等, 2022; Touvron等, 2023a,b; Achiam等, 2023; Team等, 2023]在各种NLP任务上展现显著进步,然而它们在数学、科学和工程领域处理复杂推理任务的能力仍有限[Lin等, 2024]。
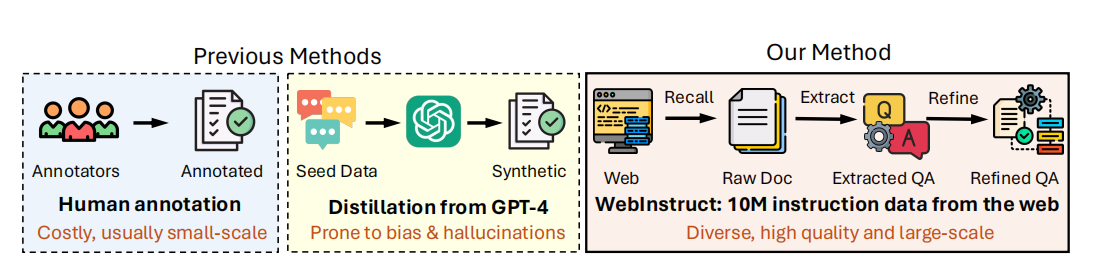
近期大量研究致力于提升基础LLM的推理能力,主要有两大途径:持续训练和指令调优。持续训练即在大规模过滤文档上继续训练[ Lewkowycz等, 2022; Taylor等, 2022; Azerbayev等, 2023; Shao等, 2024; Ying等, 2024 ];指令调优则采用小规模高质量指令-响应对进行监督微调[Ouyang等, 2022; Chung等, 2024]。人工标注的指令数据集[ Cobbe等, 2021; Hendrycks等, 2021b; Amini等, 2019]往往规模有限,而近期研究[Yu等, 2023; Yue等, 2023b; Toshniwal等, 2024; Li等, 2024; Tang等, 2024]尝试用GPT-4基于种子数据进行指令数据扩展,但合成数据通常存在偏差,缺乏多样性且易产生幻觉。
为突破上述限制,我们提出从网络中挖掘自然存在指令数据(图2)。我们认为预训练语料(如Common Crawl)自身蕴含大量高质量、多领域的指令-响应对(如教育资料)。这类数据涵盖数学、科学、工程乃至人文诸多领域,既丰富多样又质量优良。但其在语料中高度分散,难以采集。
本文设计了一条三步流水线用于挖掘这些指令-回答对:(1)召回:通过爬取多个测验网站建立种子数据,利用fastText模型从Common Crawl召回相关文档,再用GPT-4按域名精简,得到1800万文档;(2)提取:使用开源LLM Mixtral从这些文档中抽取问答对,获得约500万候选对;(3)精炼:进一步用Mixtral- 8 × 7 B 8 \times 7 \mathrm{~B} 8×7 B和Qwen-72B对候选对进行格式优化、内容筛查及补充推理步骤,最终产出1000万高质量指令-响应对的WebInstruct数据集。该数据集纯粹由网络数据挖掘获得,无任何人工注释或GPT-4合成。
我们用多个基础模型(Mistral-7B、Llama3-8B、Mixtral-8×7B和Yi-34B)在WebInstruct上进行微调,构建MAmmoTH2系列模型(图1),在七个推理基准上显著提升性能:TheoremQA[Chen等, 2023b]、GSM8K[Cobbe等, 2021]、MATH[Hendrycks等, 2021b]、ARC-C[Clark等, 2018]、MMLU-STEM[Hendrycks等, 2021b]、GPQA[Rein等, 2023]和BBH[Suzgun等, 2022]。MAmmoTH2-7B将Mistral-7B性能平均提升超过14点,MAmmoTH2-34B提升超过5.8点。特别地,Mistral-7B在MATH的准确率从 11.2 % 11.2\% 11.2%升至 36.7 % 36.7\% 36.7%,且未使用测试领域数据,充分证明了模型的强泛化能力。
进一步基于开源指令调优数据(如OpenHermes 2.5[Teknium, 2023]、Code-Feedback[Zheng等, 2024c]和Math-plus)对MAmmoTH2进行训练,形成MAmmoTH2-Plus,显著提升代码生成、数学推理和指令遵循表现。MAmmoTH2-Plus在七个推理基准及多个通用任务上均表现出色。其中,MAmmoTH2-7B-Plus和MAmmoTH2-8B-Plus在TheoremQA、ARC-C、MMLU-STEM、GPQA和BBH上创下同规模最好成绩,在MATH(45%)和GSM8K(85%)得到具有竞争力的结果。MAmmoTH2-Plus还在HumanEval、MBPP和聊天评测如AlpacaEval 2.0和Arena Hard排行榜上表现优异。
值得一提的是,MAmmoTH2-8B-Plus与Llama-3-8B-Instruct均基于相同规模Llama3-base训练,前者无人工标注数据,后者使用了1000万条人工标注指令数据集。MAmmoTH2-8B-Plus在推理任务上超越Llama-3-Instruct约6个百分点,在通用任务上表现相当,体现了WebInstruct的高性价比。MAmmoTH2-Plus持续超越官方指令模型如Mixtral-Instruct在聊天测试中的表现,展示了规模化从网络构建指令数据的潜力,也为未来指令调优研究提供新视角。
2 WebInstruct
本节介绍WebInstruct的数据构建方法。数据采集分为三阶段:(1)从网络语料召回相关文档;(2)从召回文档中提取问答对;(3)对问答对进行精炼。整套流程示意见图3,图4展示了抽取与精炼的示例。
2.1 从Common Crawl召回相关文档
与以往聚焦数学的研究[Paster等, 2023; Wang等, 2023c; Shao等, 2024]不同,我们追求涵盖数学、科学、工程等广领域,因此种子数据需均衡多样。但现有公开训练集多偏向数学。为此,我们从多个教学网站爬取新数据。这些网站提供涵盖多学科的问题,保证多样性。我们收集了10万条种子正样本,并随机采样10万条负样本训练fastText模型[ Joulin等, 2016]。fastText使用256维向量训练3轮,学习率0.1,最大n-gram长度3,词频上限3。利用训练好的fastText模型从内部Common Crawl中召回了1000亿token的文档。将召回文档按域名聚类,仅保留文档数千以上的域,大约得到60万个域。接着用GPT-3.5扫描域名,自动选出可能含指令数据的域,约5万个确认标记为正。此阶段召回的所有文档不直接用于后续问答对提取和精炼。随后,从前述正域采样文档作为正样本,非选域及通用CC文档做负样本,重新训练改进fastText分类器,再次召回40亿token,使用GPT-4重新筛选域,最终得到1800万篇原始文档,主要来自目标网站。
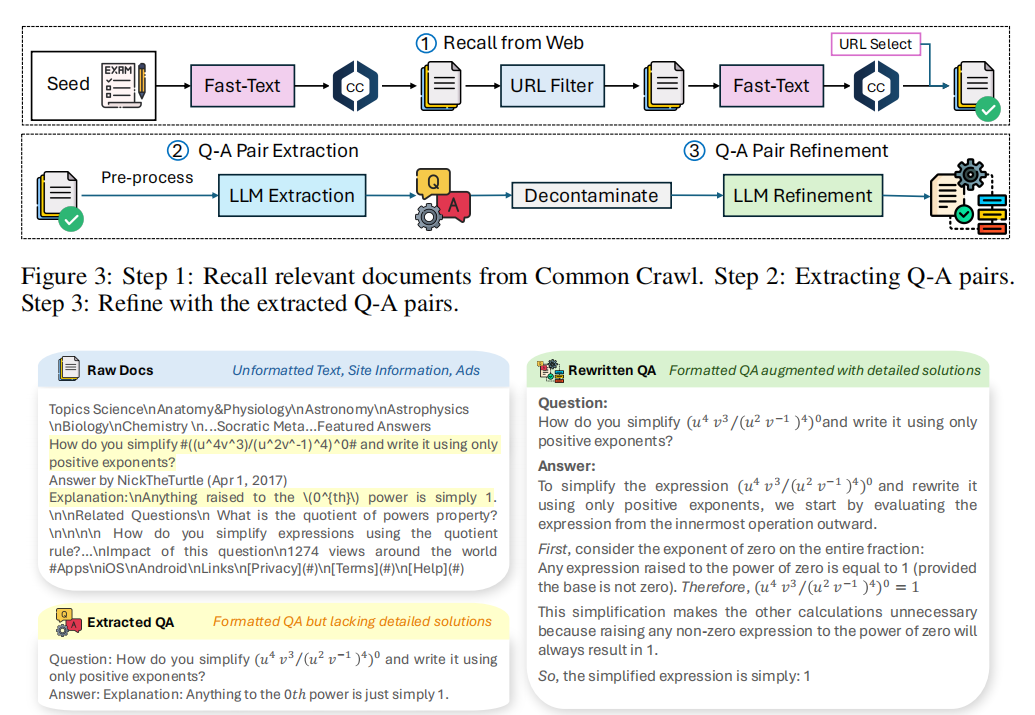
2.2 问答对提取
在1800万文档中,存在大量天然问答对,但噪音多如广告、标签、模板信息等。用原始文档训练仅带来有限提升。
首先对HTML进行规则化预处理,剔除站点信息、广告、标签模板等,有效缩短文档长度。随后用Qwen-72B[Bai等, 2023]结合示例提示从预处理文档中识别问答对;若无自然问答对返回空。约30%文档被判含天然问答对,得到约500万候选对,供后续精炼。候选对仍含大量无关内容、格式混乱且大多缺乏解题思路。为提高质量,需进一步精炼。
为避免测试集污染,我们依前人做法[Shao等, 2024],滤除与测试集题目及答案出现10-gram以上字符串匹配的网页。
2.3 问答对精炼
为提升候选问答对质量,我们用Mixtral-22B×8[Jiang等, 2024]和Qwen-72B[Bai等, 2023]对其格式化。如果答案不含解释,两个模型会自动补全中间推理步骤。这两个模型交替使用,保证数据多样性。最终收获1000万条问答对构成最终数据集WebInstruct。
2.4 数据集统计
为更好区分我们数据集与现有集合,表1汇总展示。可见多数监督微调(SFT)数据不足100万条,质量高;最大的是XwinMath[Li等, 2024a]通过GPT-4合成扩展至140万条;OpenMathInstruct[Toshniwal等, 2024]非GPT-4合成而用Mixtral-8x7B生成,但仅基于GSM和MATH,领域覆盖局限。相比之下,持续训练(CT)数据通常从网页过滤,规模巨大,超10B tokens甚至达120B,成本高且噪声多。WebInstruct规模约50亿tokens,兼顾规模与质量,处于SFT与CT之间,具独特优势。
2.5 额外公开指令调优数据集
为进一步丰富数据多样性与质量,我们将MAmmoTH2基于与WebInstruct匹配格式的三个公开指令数据集Fine-tune,覆盖不同推理主题并适度平衡聊天能力。包含OpenHermes 2.5[Teknium, 2023],Code-Feedback[Zheng等, 2024c],以及Math-Plus(融合MetaMathQA[Yu等, 2023]与Orca-Math[Mitra等, 2024]的扩充版本,具体见附录A)。
3 实验设置}
3.1 训练设置}
所有指令数据样本统一为多轮指令调优格式,确保微调模型输入一致。基础模型选择Mistral 7B[Jiang等, 2023]、Mixtral 8 × 7 8 \times 7 8×7B[Jiang等, 2024]、Llama-3 8B[Meta, 2024]和Yi-34B[Young等, 2024]。用LLaMA-Factory[Zheng等, 2024d]库进行微调。Mistral-7B学习率设为5e-6,其他模型为1e-5。全局批量大小512,最大序列长度4096,采用余弦学习率调度,3%warm-up,训练2轮。训练时使用DeepSpeed[Rasley等, 2020]的ZeRO-3优化阶段,使用32块A100 GPU。
3.2 评测数据集}
为全面评估模型在不同领域推理能力,采用多项标准基准:GSM8K[Cobbe等, 2021]、MATH[Hendrycks等, 2021b]、TheoremQA[Chen等, 2023b]、BIG-Bench Hard (BBH)[Suzgun等, 2022]、ARC-C[Clark等, 2018]、GPQA[Rein等, 2023]以及MMLU-STEM[Hendrycks等, 2021a],覆盖复杂程度和现实度各异。具体见附录B。
此外,评测代码生成任务(HumanEval[Chen等, 2021]、MBPP[Austin等, 2021]和其扩充版本[Liu等, 2024])、通用LLM基准(MMLU和更具挑战性版本MMLU-Pro[TIGER-Lab, 2024])、聊天机器人任务(MT-Bench[Zheng等, 2024a]、AlpacaEval 2.0[Li等, 2023b]和Arena Hard[Li等, 2024b]),以考察WebInstruct及其plus版本的泛化能力。
4 主要结果
4.1 推理基准实验结果
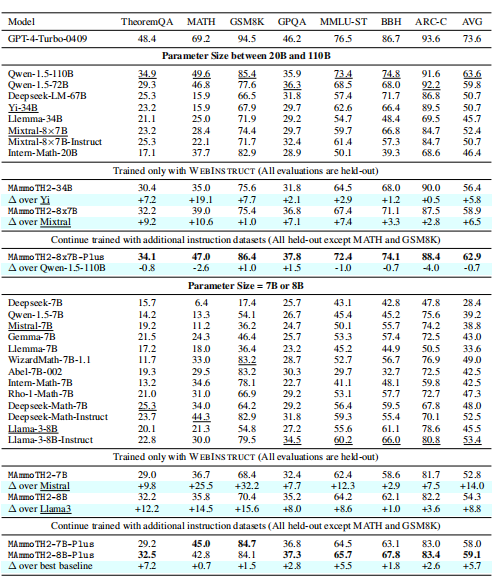
表2列出主要结果,基于参数规模分轨展示。7B规模模型中,仅用WebInstruct训练的MAmmoTH2相较基础模型大幅提升性能。MAmmoTH2-7B比Mistral-7B平均高出14点。WebInstruct不含测试领域数据,验证了模型泛化性能。MAmmoTH2-8B比Llama-3-8B-base提升8.8点。同样大模型如Yi-34B和Mixtral亦表现出稳定提升,Yi-34B MATH准确率提升达19%。
继续用额外公开数据训练,MAmmoTH2-Plus表现大幅提升。MAmmoTH2-Plus在TheoremQA、GPQA、ARC-C等多项指标刷新同规模最佳纪录。MAmmoTH2-7B-Plus在MATH和GSM8K也接近最佳结果。附录E中展示仅用公开数据训练模型结果。
对比MAmmoTH2-8B-Plus与Llama3-Instruct,两者均以Llama3-base为底,本质相似,前者无人工标注指令数据,后者使用1千万人工标注,MAmmoTH2-8B-Plus推理基准平均超越6点,表明WebInstruct性价比优越。大模型中,MAmmoTH2-8x7B-Plus用13B激活参数即可匹配Qwen-1.5-110B表现。以上充分证明规模化网络指令调优路径的效力。
4.2 额外实验结果}
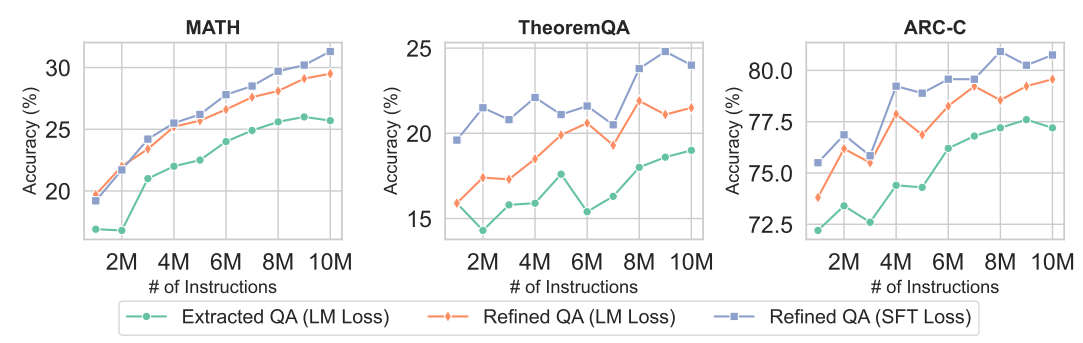
进一步评估模型在代码生成、通用语言理解及指令遵循任务上的表现,见表3。MAmmoTH2-7B-Plus代码生成保持领先HumanEval(+)和MBPP(+)平均最高分66.1及58.2,优于Mistral-7B-Instruct-v0.2,显示代码生成实力。
通用语言理解及指令遵循测试中,MAmmoTH2-Plus系列表现优异,特别是MAmmoTH2-8×7B-Plus在AlpacaEval 2.0和Arena Hard排行榜均领先,包括对抗GPT-3.5-Turbo及Tulu-2-DPO-70B[ Ivison等, 2023]。
综上,MAmmoTH2不仅未对推理专项过拟合,还具备良好多任务泛化能力和鲁棒性,佐证WebInstruct高质量。
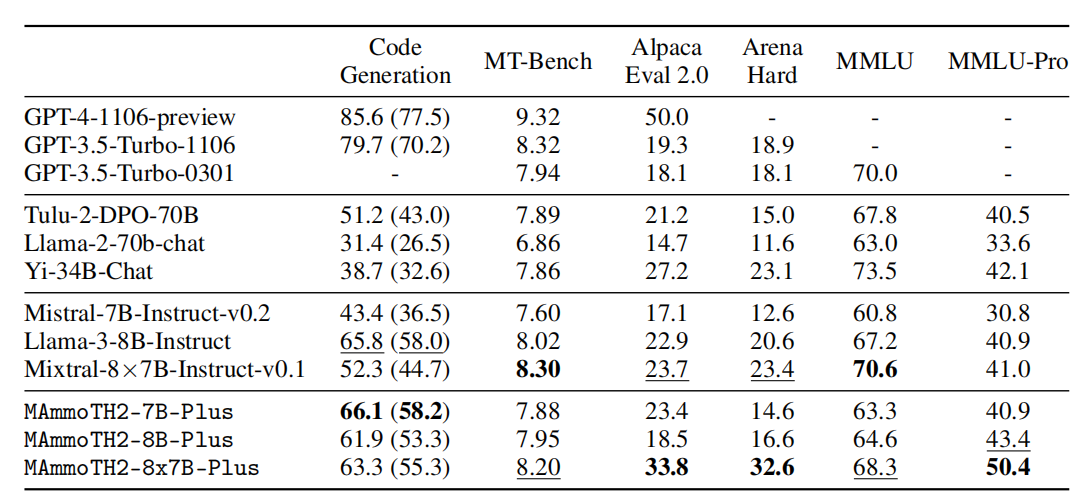
图5:Mistral-7B模型随指令规模化推理性能提升。同时,采用监督微调(SFT)损失优于语言建模(LM)损失。
5 消融实验
5.1 指令规模效应
考察模型规模和训练损失函数对MATH、TheoremQA和ARC-C三任务的影响。训练样本数量从100万到1000万,分别用抽取问答和精炼问答,再比较LM与SFT损失。图5显示,增大模型规模并选用SFT损失及合成数据持续推动准确率提升,说明模型扩展与监督微调对多领域推理性能提升关键。
5.2 两种精炼模型比较
评估用不同LLM精炼数据的效果,我们训练三版Mistral-7B模型:一版用Mixtral-22B×8精炼数据,另一版用Qwen-72B精炼数据,第三版用两者合并数据,均训练9000步,批量512。结果见表4:单一精炼数据训练模型性能相近,合并数据训练模型普遍优异,说明不同模型精炼互补,减轻单一模型偏差。我们的做法不同于传统蒸馏,而是用LLM辅助提取与精炼,减少知识继承偏差,保留网络源指令多样性。
5.3 不同领域与数据源对比
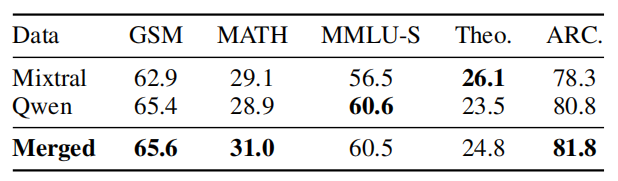
分析不同领域(数学、科学、其它)及数据源(论坛网站、教育网站)对训练贡献,用Mistral-7B训练子集,领域标签详见附录G。
表5显示,教育网站数据整体优于论坛,说明教育题质量更高。数学领域数据在MATH上表现优异,但对GSM8K提升有限,表明单一数学数据难泛化至不同数学基准。此外仅数学数据对科学和STEM基准帮助不显著,强化领域多样性需求。其它领域数据在GSM8K上表现最佳,凸显训练多样性重要性。
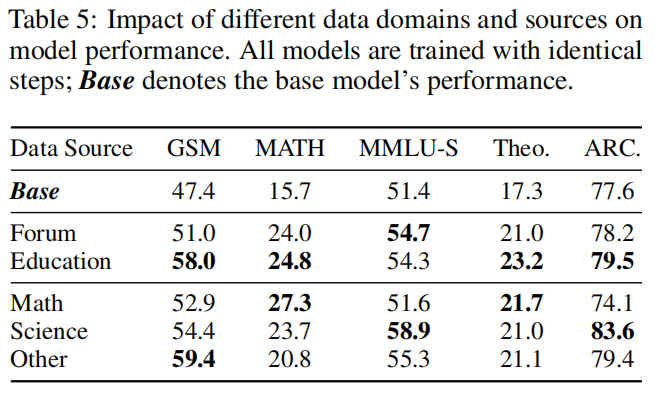
表5:不同领域与数据源对模型表现的影响,均训练相同步数,Base为基线。
5.4 提取与精炼步骤有效性
消融实验强调“提取”和“精炼”步骤对模型多任务推理性能提升的核心作用。
设置说明:
-
召回:仅用召回的1800万篇文档训练作为基线。
-
(a’) DeepSeek Math Recall[Shao等, 2024]:5000亿令牌的Deepseek数学预训练数据。
-
(b) 提取:从召回文档中筛选高质量问答对。
-
© 精炼:对提取对进行推理步骤补全与格式规范。
-
(d) 公开SFT:额外公开的监督微调数据。
-
(d’) DeepSeek Math SFT:DeepSeek Math的SFT集。
表6结果显示,单独训练召回文档加公开SFT(a+d)仅获适度提升,体现过滤与精炼重要性。增加提取步骤(a+b+d)显著提升性能,通过缩减数据至高质量问答对节约令牌开销并提升表现。融入精炼(a+b+c+d)进一步优化,尤其对推理任务表现卓越。与DeepSeek Math(a’+d’)对比,本工作虽数据规模较小,但在多个推理任务上表现持平甚至优越。
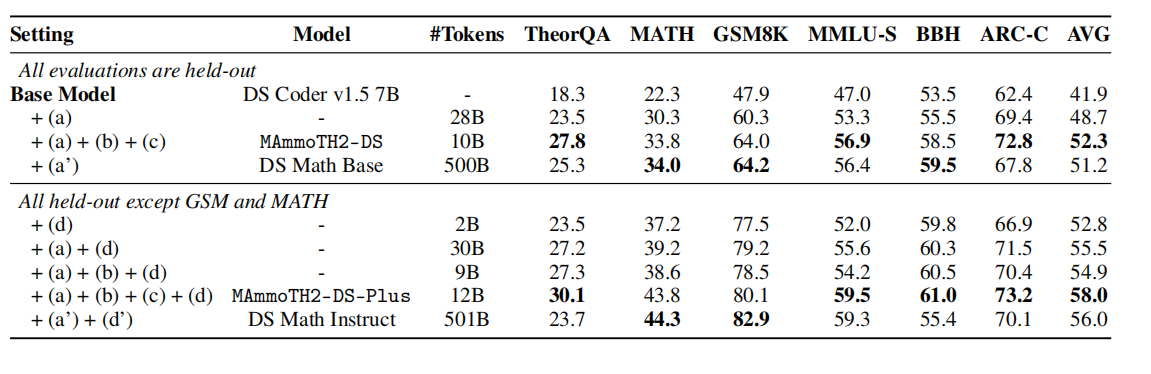
表6:基于不同训练数据的消融实验结果摘要。基线模型为DeepSeek Coder V1.5 7B[Guo等, 2024]。
综上,提取与精炼步骤对有效挖掘网络指令调优数据至关重要。此方法不仅经济可行,还提升模型推理泛化。
5.5 案例分析
我们对数据集中抽取及精炼的问答对质量进行案例分析(附录J)。发现来自格式规范的考试和教育网站的问答对质量较高。常见问题为答案过短无中间推理链,影响泛化。对此,我们提示Mixtral和Qwen-72B补全中间步骤,成功率较高。但也存在格式严重破坏情况,精炼难以修复。LLM有时会改变原意,产生幻觉。
为量化错误率,抽样50个精炼问答由人工判定是否较抽取版本格式更规范、具有中间推理且正确。结果见图6,78%样本因精炼获提升,仅10%出现幻觉,整体质量较高。
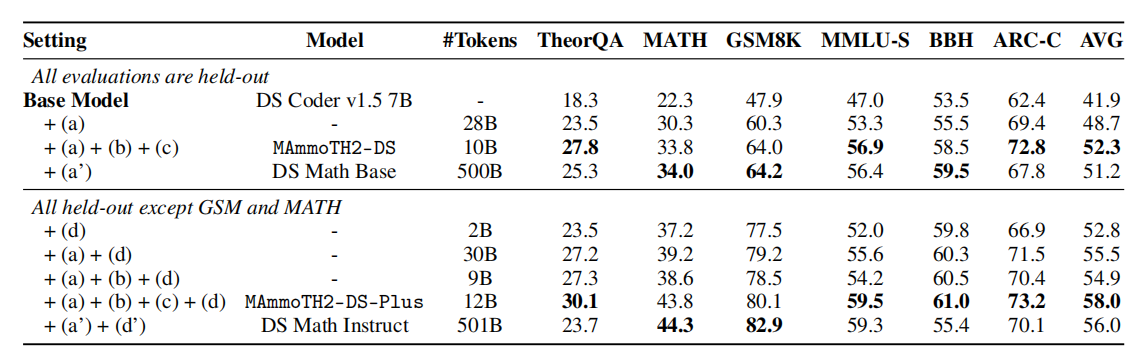
图6:50个采样的精炼问答质量分布。
6 结论
本文观点是网络语料中蕴藏丰富各领域高质量指令数据。我们设计召回、提取、精炼三步流水线挖掘出WebInstruct约1000万条多样高质指令-响应对。基于此数据训练的MAmmoTH2模型在科学推理能力上显著优于基础模型。工作展示利用网络现有指令数据挖掘,能有效推动大众化具备卓越推理能力的LLM发展。

















 855
855

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









