







是什么
WandB 是一个帮助机器学习开发者跟踪和可视化他们实验的软件库。它提供了一个平台,可以帮助团队和个人记录机器学习实验的各种参数、模型训练过程中的指标以及最终结果。WandB 的设计目的是简化和加速机器学习项目的开发流程,让研究者和开发者能够更容易地分享结果、复现实验,并进行协作。
主要特点
- 实验跟踪:自动记录代码版本、实验结果、超参数等。
- 实时可视化:实时查看指标和日志,帮助分析模型表现。
- 报告生成:创建交互式报告和仪表板,以可视化方式分享实验结果。
- 协作:团队成员可以查看、评论和分享实验结果,促进协作和知识共享。
- 资源管理:跟踪和优化计算资源的使用情况,如GPU利用率。
WandB 通过其易用的API和集成,支持广泛的机器学习框架,如TensorFlow、PyTorch和Keras等。用户可以通过简单的代码行将WandB集成到现有的机器学习项目中,无需进行大量修改。此外,WandB 提供免费版和付费版,以适应不同规模和需求的项目。
如何用
- 步骤 1: 安装 WandB
首先,你需要在你的工作环境中安装WandB。你可以使用pip安装它:
pip install wandb
- 步骤 2: 注册和登录
-在开始使用WandB之前,你需要创建一个WandB账户(如果你还没有的话)。你可以在WandB官网注册。
注册成功后会出现你的账号的一个API密钥。可以点击复制这个密钥。
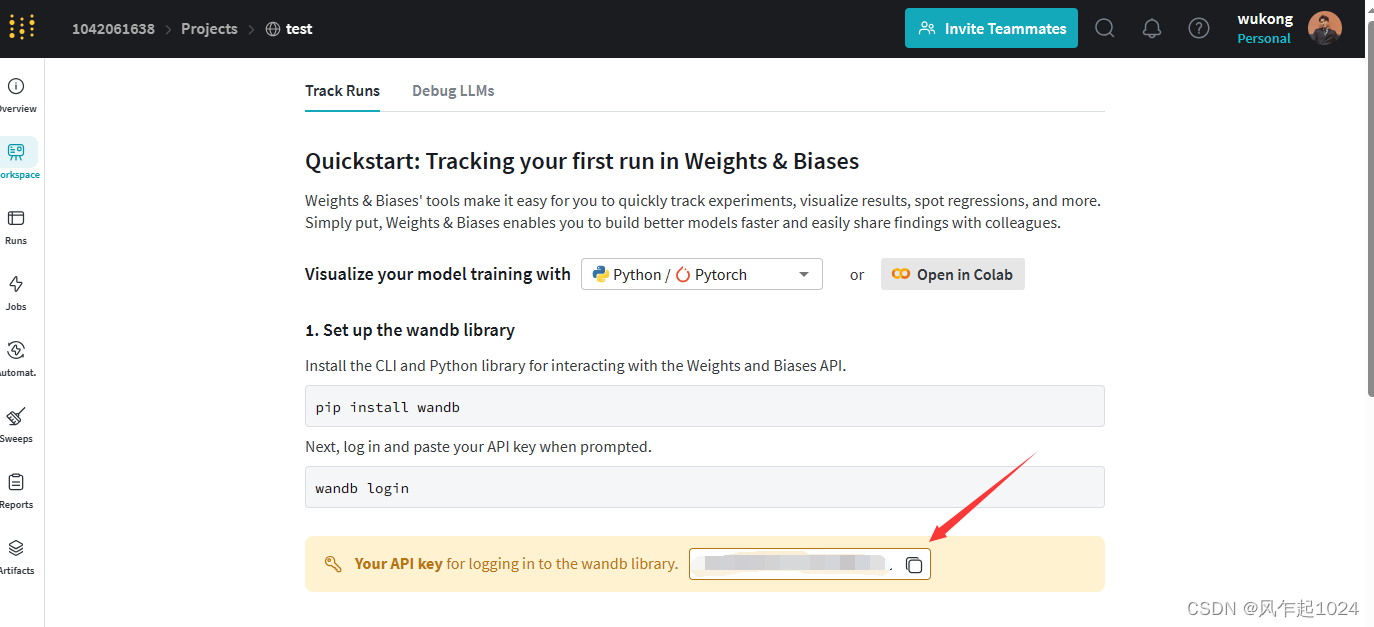
同时也提供了一段样例代码,可以测试。
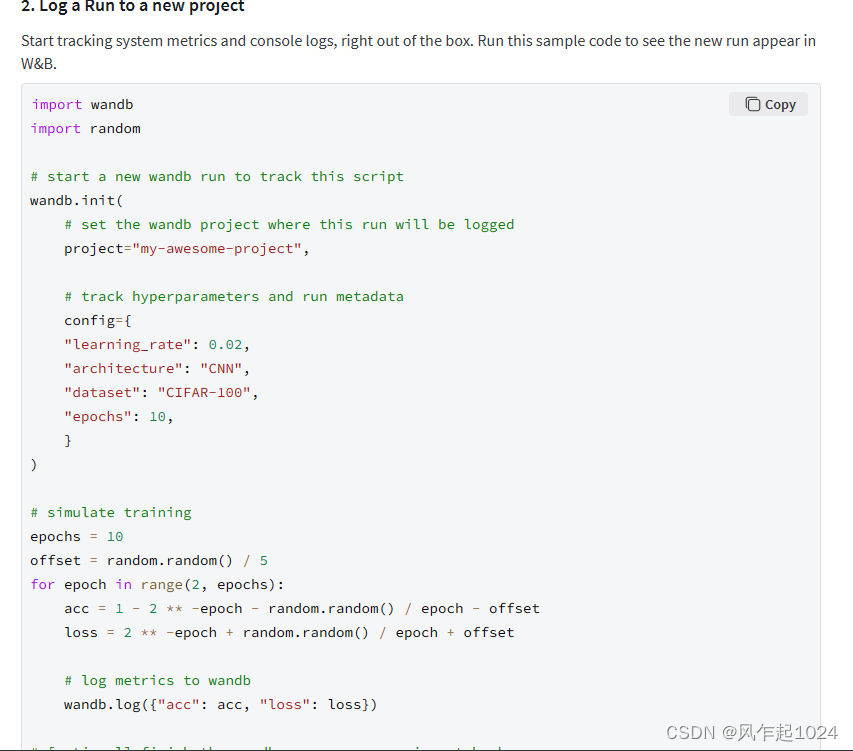
安装完WandB并注册账户后,通过以下命令登录:
wandb login
稍后会出现以下界面:

粘贴之前复制的私钥,点击enter即可。
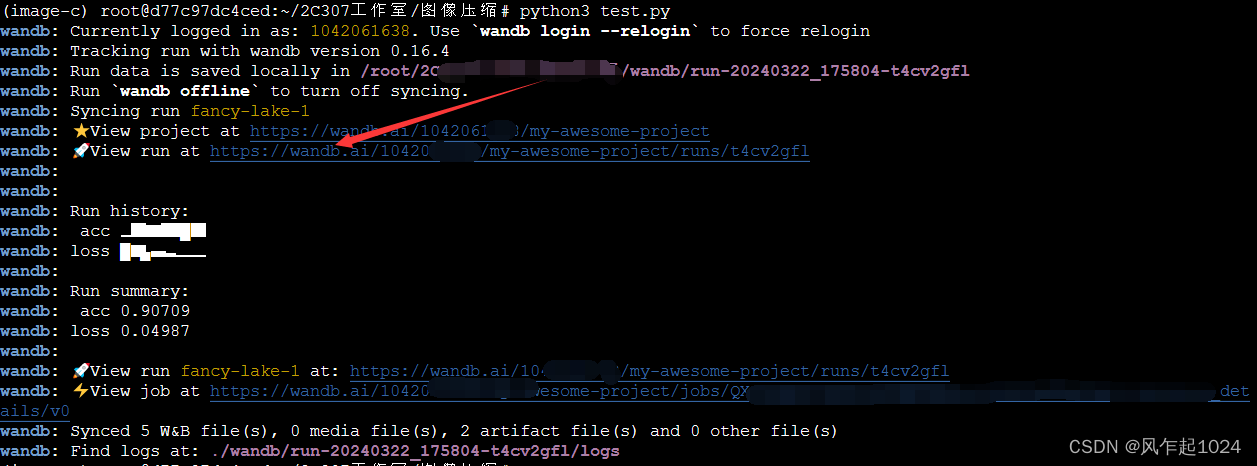
测试:
将上面的样例代码复制下来,写成一个python文件。
#test.py
import wandb
import random
# start a new wandb run to track this script
wandb.init(
# set the wandb project where this run will be logged
project="my-awesome-project",
# track hyperparameters and run metadata
config={
"learning_rate": 0.02,
"architecture": "CNN",
"dataset": "CIFAR-100",
"epochs": 10,
}
)
# simulate training
epochs = 10
offset = random.random() / 5
for epoch in range(2, epochs):
acc = 1 - 2 ** -epoch - random.random() / epoch - offset
loss = 2 ** -epoch + random.random() / epoch + offset
# log metrics to wandb
wandb.log({"acc": acc, "loss": loss})
# [optional] finish the wandb run, necessary in notebooks
wandb.finish()
在终端输入命令行,python3 test.py,即会输出:只需要点击有火箭图标的那一行。
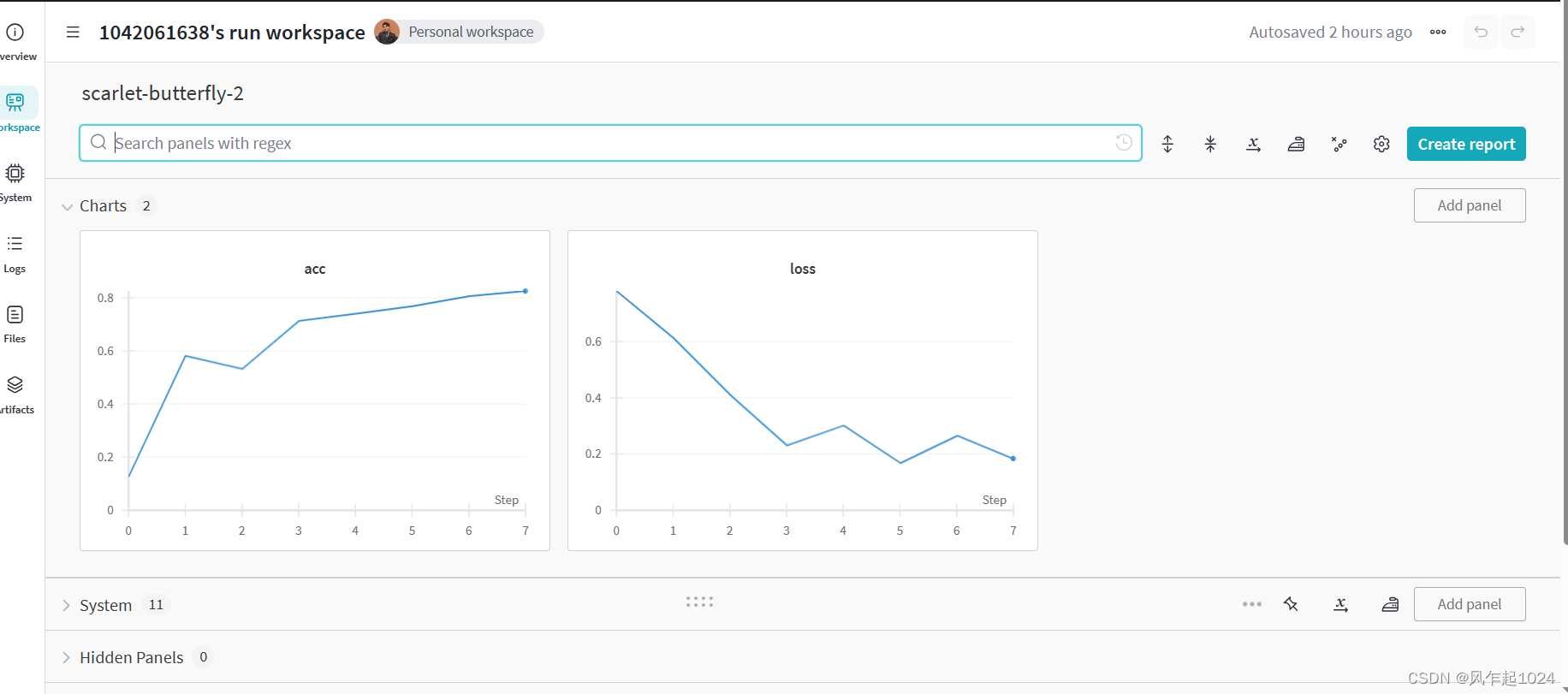
显示出相关指标的可视化
如何在自己的项目使用WandB呢?
- 步骤 1: 初始化 WandB 项目
使用wandb.init()初始化WandB。你可以指定项目名称和实验名称等信息。
import wandb
# 初始化项目
wandb.init(project='my_project', entity='my_username', name='experiment_name')
entity(不是随便的填的)是你在WandB中的用户名或者团队名,project是你希望创建或者已有的项目名。
- 步骤 2: 配置实验
使用wandb.config记录实验的超参数或配置。
wandb.config.learning_rate = 0.01
wandb.config.batch_size = 32
- 步骤3 : 记录指标
在你的训练循环中,使用wandb.log方法来记录你感兴趣的指标,如损失和准确率。
for epoch in range(epochs):
# 假设这里是你的训练逻辑
train_loss, train_accuracy = train()
val_loss, val_accuracy = validate()
# 记录训练和验证指标
wandb.log({'train_loss': train_loss, 'train_accuracy': train_accuracy,
'val_loss': val_loss, 'val_accuracy': val_accuracy})
- 步骤 4: 结束实验
当实验完成后,可以调用wandb.finish()来结束这次实验的记录。
wandb.finish()
具体的示例
这里给出我的项目的示例:
- 原代码:
import argparse
import random
import shutil
import sys
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
from torchvision import transforms
from compressai.datasets import ImageFolder
from compressai.losses import RateDistortionLoss
from compressai.optimizers import net_aux_optimizer
from compressai.zoo import image_models
class AverageMeter:
"""Compute running average."""
def __init__(self):
self.val = 0
self.avg = 0
self.sum = 0
self.count = 0
def update(self, val, n=1):
self.val = val
self.sum += val * n
self.count += n
self.avg = self.sum / self.count
class CustomDataParallel(nn.DataParallel):
"""Custom DataParallel to access the module methods."""
def __getattr__(self, key):
try:
return super().__getattr__(key)
except AttributeError:
return getattr(self.module, key)
def configure_optimizers(net, args):
"""Separate parameters for the main optimizer and the auxiliary optimizer.
Return two optimizers"""
conf = {
"net": {"type": "Adam", "lr": args.learning_rate},
"aux": {"type": "Adam", "lr": args.aux_learning_rate},
}
optimizer = net_aux_optimizer(net, conf)
return optimizer["net"], optimizer["aux"]
def train_one_epoch(
model, criterion, train_dataloader, optimizer, aux_optimizer, epoch, clip_max_norm
):
model.train()
device = next(model.parameters()).device
for i, d in enumerate(train_dataloader):
d = d.to(device)
optimizer.zero_grad()
aux_optimizer.zero_grad()
out_net = model(d)
out_criterion = criterion(out_net, d)
out_criterion["loss"].backward()
if clip_max_norm > 0:
torch.nn.utils.clip_grad_norm_(model.parameters(), clip_max_norm)
optimizer.step()
aux_loss = model.aux_loss()
aux_loss.backward()
aux_optimizer.step()
if i % 10 == 0:
print(
f"Train epoch {epoch}: ["
f"{i*len(d)}/{len(train_dataloader.dataset)}"
f" ({100. * i / len(train_dataloader):.0f}%)]"
f'\tLoss: {out_criterion["loss"].item():.3f} |'
f'\tMSE loss: {out_criterion["mse_loss"].item():.3f} |'
f'\tBpp loss: {out_criterion["bpp_loss"].item():.2f} |'
f"\tAux loss: {aux_loss.item():.2f}"
)
def test_epoch(epoch, test_dataloader, model, criterion):
model.eval()
device = next(model.parameters()).device
loss = AverageMeter()
bpp_loss = AverageMeter()
mse_loss = AverageMeter()
aux_loss = AverageMeter()
with torch.no_grad():
for d in test_dataloader:
d = d.to(device)
out_net = model(d)
out_criterion = criterion(out_net, d)
aux_loss.update(model.aux_loss())
bpp_loss.update(out_criterion["bpp_loss"])
loss.update(out_criterion["loss"])
mse_loss.update(out_criterion["mse_loss"])
print(
f"Test epoch {epoch}: Average losses:"
f"\tLoss: {loss.avg:.3f} |"
f"\tMSE loss: {mse_loss.avg:.3f} |"
f"\tBpp loss: {bpp_loss.avg:.2f} |"
f"\tAux loss: {aux_loss.avg:.2f}\n"
)
return loss.avg
def save_checkpoint(state, is_best, filename="checkpoint.pth.tar"):
torch.save(state, filename)
if is_best:
shutil.copyfile(filename, "checkpoint_best_loss.pth.tar")
def parse_args(argv):
parser = argparse.ArgumentParser(description="Example training script.")
parser.add_argument(
"-m",
"--model",
default="bmshj2018-factorized",
choices=image_models.keys(),
help="Model architecture (default: %(default)s)",
)
parser.add_argument(
"-d", "--dataset", type=str, required=True, help="Training dataset"
)
parser.add_argument(
"-e",
"--epochs",
default=100,
type=int,
help="Number of epochs (default: %(default)s)",
)
parser.add_argument(
"-lr",
"--learning-rate",
default=1e-4,
type=float,
help="Learning rate (default: %(default)s)",
)
parser.add_argument(
"-n",
"--num-workers",
type=int,
default=4,
help="Dataloaders threads (default: %(default)s)",
)
parser.add_argument(
"--lambda",
dest="lmbda",
type=float,
default=1e-2,
help="Bit-rate distortion parameter (default: %(default)s)",
)
parser.add_argument(
"--batch-size", type=int, default=16, help="Batch size (default: %(default)s)"
)
parser.add_argument(
"--test-batch-size",
type=int,
default=64,
help="Test batch size (default: %(default)s)",
)
parser.add_argument(
"--aux-learning-rate",
type=float,
default=1e-3,
help="Auxiliary loss learning rate (default: %(default)s)",
)
parser.add_argument(
"--patch-size",
type=int,
nargs=2,
default=(256, 256),
help="Size of the patches to be cropped (default: %(default)s)",
)
parser.add_argument("--cuda", action="store_true", help="Use cuda")
parser.add_argument(
"--save", action="store_true", default=True, help="Save model to disk"
)
parser.add_argument("--seed", type=int, help="Set random seed for reproducibility")
parser.add_argument(
"--clip_max_norm",
default=1.0,
type=float,
help="gradient clipping max norm (default: %(default)s",
)
parser.add_argument("--checkpoint", type=str, help="Path to a checkpoint")
args = parser.parse_args(argv)
return args
def main(argv):
args = parse_args(argv)
if args.seed is not None:
torch.manual_seed(args.seed)
random.seed(args.seed)
train_transforms = transforms.Compose(
[transforms.RandomCrop(args.patch_size), transforms.ToTensor()]
)
test_transforms = transforms.Compose(
[transforms.CenterCrop(args.patch_size), transforms.ToTensor()]
)
train_dataset = ImageFolder(args.dataset, split="train", transform=train_transforms)
test_dataset = ImageFolder(args.dataset, split="test", transform=test_transforms)
device = "cuda" if args.cuda and torch.cuda.is_available() else "cpu"
train_dataloader = DataLoader(
train_dataset,
batch_size=args.batch_size,
num_workers=args.num_workers,
shuffle=True,
pin_memory=(device == "cuda"),
)
test_dataloader = DataLoader(
test_dataset,
batch_size=args.test_batch_size,
num_workers=args.num_workers,
shuffle=False,
pin_memory=(device == "cuda"),
)
net = image_models[args.model](quality=3)
net = net.to(device)
if args.cuda and torch.cuda.device_count() > 1:
net = CustomDataParallel(net)
optimizer, aux_optimizer = configure_optimizers(net, args)
lr_scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer, "min")
criterion = RateDistortionLoss(lmbda=args.lmbda)
last_epoch = 0
if args.checkpoint: # load from previous checkpoint
print("Loading", args.checkpoint)
checkpoint = torch.load(args.checkpoint, map_location=device)
last_epoch = checkpoint["epoch"] + 1
net.load_state_dict(checkpoint["state_dict"])
optimizer.load_state_dict(checkpoint["optimizer"])
aux_optimizer.load_state_dict(checkpoint["aux_optimizer"])
lr_scheduler.load_state_dict(checkpoint["lr_scheduler"])
best_loss = float("inf")
for epoch in range(last_epoch, args.epochs):
print(f"Learning rate: {optimizer.param_groups[0]['lr']}")
train_one_epoch(
net,
criterion,
train_dataloader,
optimizer,
aux_optimizer,
epoch,
args.clip_max_norm,
)
loss = test_epoch(epoch, test_dataloader, net, criterion)
lr_scheduler.step(loss)
is_best = loss < best_loss
best_loss = min(loss, best_loss)
if args.save:
save_checkpoint(
{
"epoch": epoch,
"state_dict": net.state_dict(),
"loss": loss,
"optimizer": optimizer.state_dict(),
"aux_optimizer": aux_optimizer.state_dict(),
"lr_scheduler": lr_scheduler.state_dict(),
},
is_best,
)
if __name__ == "__main__":
main(sys.argv[1:])
- 集成后:
import argparse
import random
import shutil
import sys
import wandb
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
from torchvision import transforms
from compressai.datasets import ImageFolder
from compressai.losses import RateDistortionLoss
from compressai.optimizers import net_aux_optimizer
from compressai.zoo import image_models
class AverageMeter:
"""Compute running average."""
def __init__(self):
self.val = 0
self.avg = 0
self.sum = 0
self.count = 0
def update(self, val, n=1):
self.val = val
self.sum += val * n
self.count += n
self.avg = self.sum / self.count
class CustomDataParallel(nn.DataParallel):
"""Custom DataParallel to access the module methods."""
def __getattr__(self, key):
try:
return super().__getattr__(key)
except AttributeError:
return getattr(self.module, key)
def configure_optimizers(net, args):
"""Separate parameters for the main optimizer and the auxiliary optimizer.
Return two optimizers"""
conf = {
"net": {"type": "Adam", "lr": args.learning_rate},
"aux": {"type": "Adam", "lr": args.aux_learning_rate},
}
optimizer = net_aux_optimizer(net, conf)
return optimizer["net"], optimizer["aux"]
def train_one_epoch(
model, criterion, train_dataloader, optimizer, aux_optimizer, epoch, clip_max_norm
):
model.train()
device = next(model.parameters()).device
for i, d in enumerate(train_dataloader):
d = d.to(device)
optimizer.zero_grad()
aux_optimizer.zero_grad()
out_net = model(d)
out_criterion = criterion(out_net, d)
out_criterion["loss"].backward()
if clip_max_norm > 0:
torch.nn.utils.clip_grad_norm_(model.parameters(), clip_max_norm)
optimizer.step()
aux_loss = model.aux_loss()
aux_loss.backward()
aux_optimizer.step()
if i % 10 == 0:
print(
f"Train epoch {epoch}: ["
f"{i*len(d)}/{len(train_dataloader.dataset)}"
f" ({100. * i / len(train_dataloader):.0f}%)]"
f'\tLoss: {out_criterion["loss"].item():.3f} |'
f'\tMSE loss: {out_criterion["mse_loss"].item():.3f} |'
f'\tBpp loss: {out_criterion["bpp_loss"].item():.2f} |'
f"\tAux loss: {aux_loss.item():.2f}"
)
# 记录指标到 WandB
wandb.log({
"epoch": epoch,
"train_loss": out_criterion["loss"].item(),
"train_mse_loss": out_criterion["mse_loss"].item(),
"train_bpp_loss": out_criterion["bpp_loss"].item(),
"train_aux_loss": aux_loss.item()
})
def test_epoch(epoch, test_dataloader, model, criterion):
model.eval()
device = next(model.parameters()).device
loss = AverageMeter()
bpp_loss = AverageMeter()
mse_loss = AverageMeter()
aux_loss = AverageMeter()
with torch.no_grad():
for d in test_dataloader:
d = d.to(device)
out_net = model(d)
out_criterion = criterion(out_net, d)
aux_loss.update(model.aux_loss())
bpp_loss.update(out_criterion["bpp_loss"])
loss.update(out_criterion["loss"])
mse_loss.update(out_criterion["mse_loss"])
print(
f"Test epoch {epoch}: Average losses:"
f"\tLoss: {loss.avg:.3f} |"
f"\tMSE loss: {mse_loss.avg:.3f} |"
f"\tBpp loss: {bpp_loss.avg:.2f} |"
f"\tAux loss: {aux_loss.avg:.2f}\n"
)
# 记录指标到 WandB
wandb.log({
"epoch": epoch,
"test_loss": loss.avg,
"test_mse_loss": mse_loss.avg,
"test_bpp_loss": bpp_loss.avg,
"test_aux_loss": aux_loss.avg
})
return loss.avg
def save_checkpoint(state, is_best, filename="checkpoint.pth.tar"):
torch.save(state, filename)
if is_best:
shutil.copyfile(filename, "checkpoint_best_loss.pth.tar")
def parse_args(argv):
parser = argparse.ArgumentParser(description="Example training script.")
parser.add_argument(
"-m",
"--model",
default="bmshj2018-factorized",
choices=image_models.keys(),
help="Model architecture (default: %(default)s)",
)
parser.add_argument(
"-d", "--dataset", type=str, required=True, help="Training dataset"
)
parser.add_argument(
"-e",
"--epochs",
default=100,
type=int,
help="Number of epochs (default: %(default)s)",
)
parser.add_argument(
"-lr",
"--learning-rate",
default=1e-4,
type=float,
help="Learning rate (default: %(default)s)",
)
parser.add_argument(
"-n",
"--num-workers",
type=int,
default=4,
help="Dataloaders threads (default: %(default)s)",
)
parser.add_argument(
"--lambda",
dest="lmbda",
type=float,
default=1e-2,
help="Bit-rate distortion parameter (default: %(default)s)",
)
parser.add_argument(
"--batch-size", type=int, default=16, help="Batch size (default: %(default)s)"
)
parser.add_argument(
"--test-batch-size",
type=int,
default=64,
help="Test batch size (default: %(default)s)",
)
parser.add_argument(
"--aux-learning-rate",
type=float,
default=1e-3,
help="Auxiliary loss learning rate (default: %(default)s)",
)
parser.add_argument(
"--patch-size",
type=int,
nargs=2,
default=(256, 256),
help="Size of the patches to be cropped (default: %(default)s)",
)
parser.add_argument("--cuda", action="store_true", help="Use cuda")
parser.add_argument(
"--save", action="store_true", default=True, help="Save model to disk"
)
parser.add_argument("--seed", type=int, help="Set random seed for reproducibility")
parser.add_argument(
"--clip_max_norm",
default=1.0,
type=float,
help="gradient clipping max norm (default: %(default)s",
)
parser.add_argument("--checkpoint", type=str, help="Path to a checkpoint")
args = parser.parse_args(argv)
return args
def main(argv):
args = parse_args(argv)
# WandB 初始化
wandb.init(project="compressAI", entity="1042061638")
# 配置 WandB
wandb.config.update(vars(args)) # 使用 vars() 函数将 args 转换为字典
args = parse_args(argv)
if args.seed is not None:
torch.manual_seed(args.seed)
random.seed(args.seed)
train_transforms = transforms.Compose(
[transforms.RandomCrop(args.patch_size), transforms.ToTensor()]
)
test_transforms = transforms.Compose(
[transforms.CenterCrop(args.patch_size), transforms.ToTensor()]
)
train_dataset = ImageFolder(args.dataset, split="train", transform=train_transforms)
test_dataset = ImageFolder(args.dataset, split="test", transform=test_transforms)
device = "cuda" if args.cuda and torch.cuda.is_available() else "cpu"
train_dataloader = DataLoader(
train_dataset,
batch_size=args.batch_size,
num_workers=args.num_workers,
shuffle=True,
pin_memory=(device == "cuda"),
)
test_dataloader = DataLoader(
test_dataset,
batch_size=args.test_batch_size,
num_workers=args.num_workers,
shuffle=False,
pin_memory=(device == "cuda"),
)
net = image_models[args.model](quality=3)
net = net.to(device)
if args.cuda and torch.cuda.device_count() > 1:
net = CustomDataParallel(net)
optimizer, aux_optimizer = configure_optimizers(net, args)
lr_scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer, "min")
criterion = RateDistortionLoss(lmbda=args.lmbda)
last_epoch = 0
if args.checkpoint: # load from previous checkpoint
print("Loading", args.checkpoint)
checkpoint = torch.load(args.checkpoint, map_location=device)
last_epoch = checkpoint["epoch"] + 1
net.load_state_dict(checkpoint["state_dict"])
optimizer.load_state_dict(checkpoint["optimizer"])
aux_optimizer.load_state_dict(checkpoint["aux_optimizer"])
lr_scheduler.load_state_dict(checkpoint["lr_scheduler"])
best_loss = float("inf")
for epoch in range(last_epoch, args.epochs):
print(f"Learning rate: {optimizer.param_groups[0]['lr']}")
train_one_epoch(
net,
criterion,
train_dataloader,
optimizer,
aux_optimizer,
epoch,
args.clip_max_norm,
)
loss = test_epoch(epoch, test_dataloader, net, criterion)
lr_scheduler.step(loss)
is_best = loss < best_loss
best_loss = min(loss, best_loss)
if args.save:
save_checkpoint(
{
"epoch": epoch,
"state_dict": net.state_dict(),
"loss": loss,
"optimizer": optimizer.state_dict(),
"aux_optimizer": aux_optimizer.state_dict(),
"lr_scheduler": lr_scheduler.state_dict(),
},
is_best,
)
wandb.finish()
if __name__ == "__main__":
main(sys.argv[1:])
使用效果
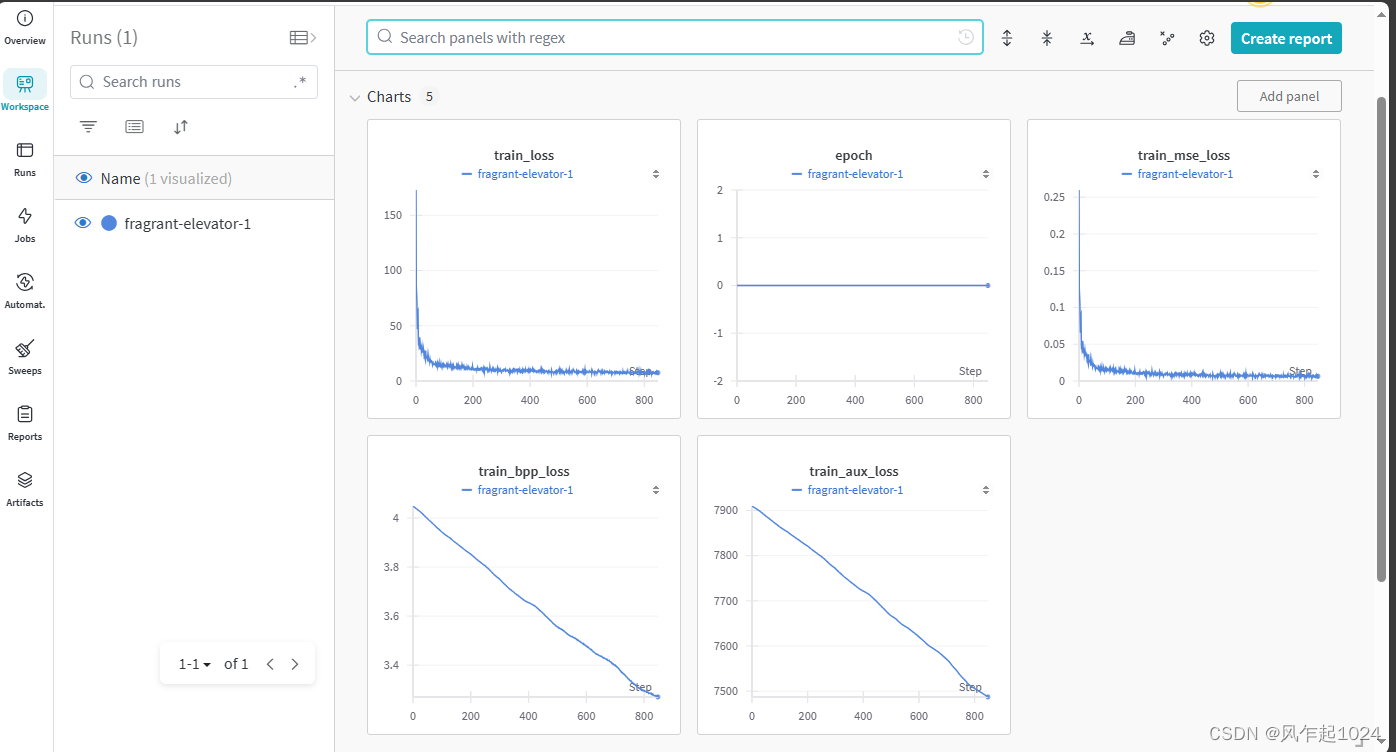
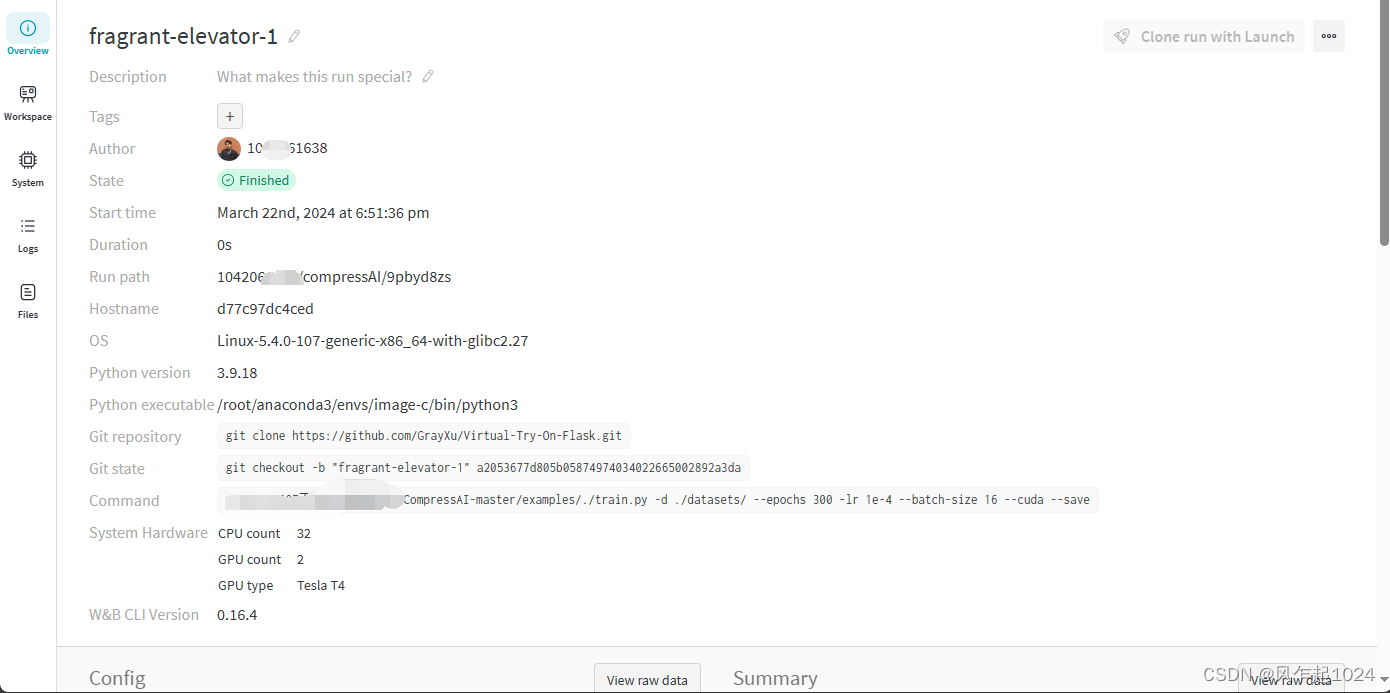
总结
WandB还有许多高级用法,详情请参考官方文档

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









