






1. 问题背景
在传统的transformer预测模型中,将多个变量的同一时间戳作为一个temporal token,然后使用attention机制捕获时间相关性。但由于各时间戳间语义关系较小,transformer模型在性能和效率上都不如简单的线性层。
作者认为基于transformer的预测器不适合多元时间序列预测。理由如下:1. 将同一时间戳不同变量值融合为一个temporal token,会消除多元相关性。2. 由单个时间戳形成的token,会受局部感受野和时间未对齐事件影响,很难揭露有用信息。3. 在时间维度上不正确地采用了排列不变注意力机制
基于以上原因,作者将每个变量的整个时间序列作为一个variate token,这样的token聚合了变量的完整序列,可以更加以变量为中心;注意力模块可以更好地建模多变量之间的相关性;前馈网络可以更好地从任意历史序列捕获特征,并用学到的特征来预测未来序列。
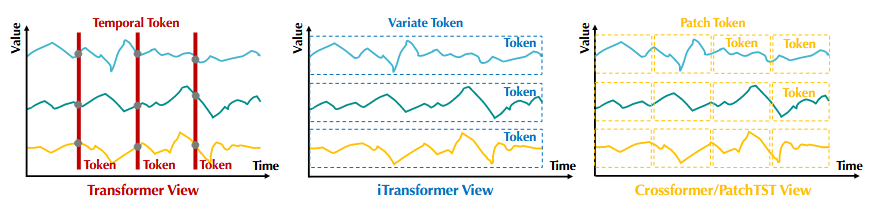
总的来说,作者将每个时间序列作为variate token,采用多变量相关性的注意力机制,并采用前馈网络进行序列表示。提出了iTransformer,在真实任务上取得了优秀的表现。
2. 相关工作
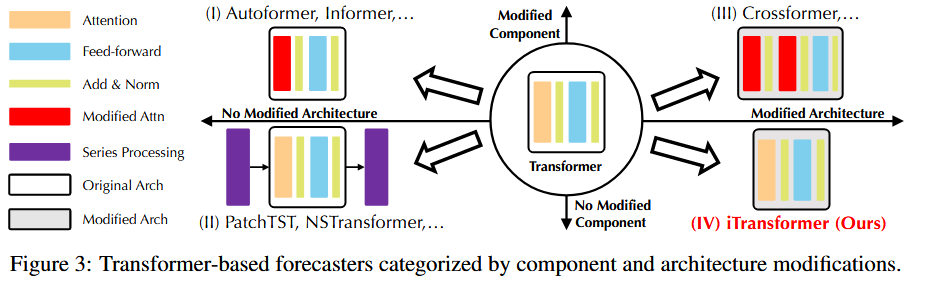
根据是否修改模型组件和架构,可以将transformer类预测器分为4类。
(1)主要涉及组件适应和优化,但不如线性预测器的性能和效率强。
(2)更注重时间序列的固有处理,例如平稳性、通道独立性和patching
(3)对transformer的组件和架构都进行了修改,从而更好应对多变量独立性和交互性。
(4)对transformer的组件未进行任何修改,只是进行了维度倒置。
3. iTransformer模型结构
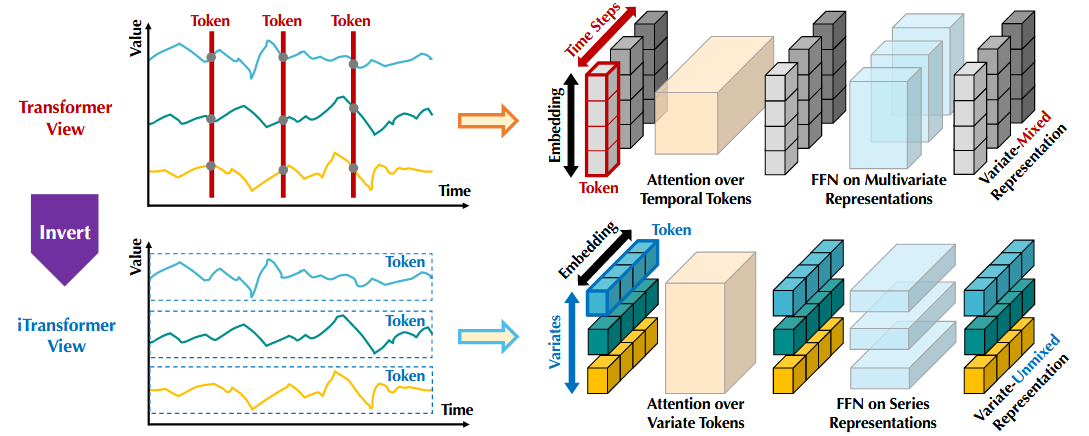
iTransformer只采用了transformer的encoder,包含嵌入层、映射层和Transformer块。
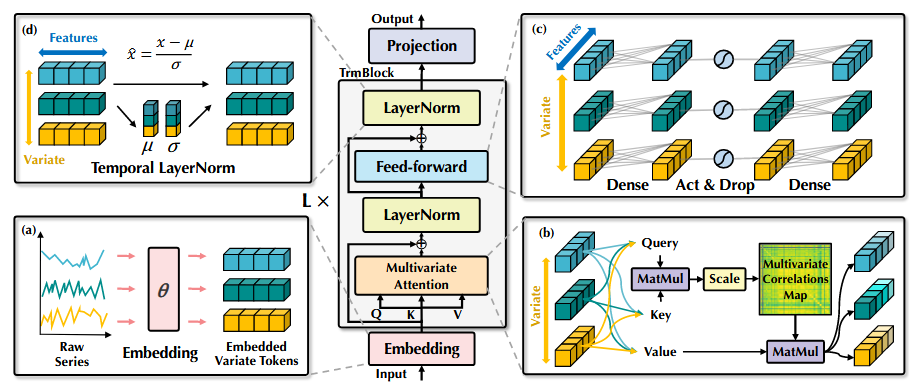
iTransformer专注于多元序列的表示学习和多元序列的关联。 表示第i个变量在过去时间内的全部时序变化,即variate token.;每个variate token通过注意力机制进行信息交互;在每个variate token内部进行层归一化统一不同变量的测量单位和特征分布,并通过前馈网络进行全连接式特征编码;最后通过映射层将每个variate token分别映射为预测结果。计算过程如下:
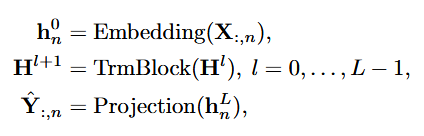
嵌入层和映射层均由多层感知机实现。由于时间点之间的顺序已经隐含在神经元的排列顺序中,模型能够感知时间点的顺序关系,因此不需要引入位置编码。
(1)层归一化
层归一化最初是为了提高深度网络的收敛性和稳定性提出的。在原始transformer中,该模块对同一时间戳的多变量进行标准化,逐渐将变量相互融合,提高了注意力建模词关联的难度。若收集到的数据没有按时间对齐,该操作会在延迟过程中引入噪声。在iTransformer中,该操作被应用于单变量序列中,所有序列都会归一化为高斯分布,因此可以减少由测量引起的差异。而在传统transformer中,所有时间戳的temporal token会被归一化,会导致模型看到的是过平滑的时间序列。
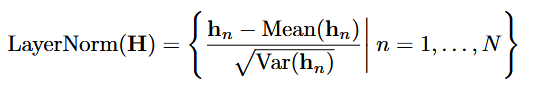
(2)前馈网络
在传统transformer中,temporal token可能是错位的,并且过于局部化而不能揭露足够的信息进行预测。
在iTransformer中,变量的整条序列作为variate token,基于多层感知机的万能表示定理,其具备足够大的模型容量来提取在历史观测和未来预测中共享的时间特征,并使用特征外推为预测结果。
另一个使用前馈网络建模时间维的依据来自最近的研究,研究发现线性层擅长学习任何时间序列都具备的时间特征。作者提出如下的解释:线性层的神经元可以学习到如何提取任意时间序列的内在属性,如幅值,周期性,甚至频率谱。
因此相较以往Transformer使用注意力机制建模时序依赖的做法,使用前馈网络更有可能完成在未见过的序列上的泛化。
(3)自注意力
自注意力模块在该模型中用于建模不同变量的相关性,这种相关性在有物理知识驱动的复杂预测场景中(例如气象预报)是极其重要的。
![]()
注意力机制建模了不同词之间的关联,其中对qi, ki应任意两个变量的Query和Key向量,作者认为整个注意力图可以在一定程度上揭示变量的相关性,并且在后续基于注意力图的加权操作中,高度相关的变量将在与其Value向量的交互中获得更大的权重,因此这种设计对多维时序数据建模更为自然和可解释。
4. 模型分析
可以提升预测效果:通过对比实验发现,iTransformer学到了更合适的序列表示,实现了更准确的预测。结果同时表明倒置维度可以作为新的预测通用框架。
通过分析注意力图发现,倒置维度实现了注意力的可解释性。
可以使用更长的历史观测:以往Transformer模型的效果不一定随着输入的历史观测的变长而提升,在使用倒置框架后,模型随着历史观测长度的增加,呈现明显的预测误差降低趋势。
能够泛化未知变量:通过倒置,模型在推理时可以输入不同于训练时的变量数,结果表明该框架在仅使用部分变量训练时能够取得较低的误差,证明证明倒置结构在变量特征学习上的泛化性。
参考
ICLR2024 | iTransformer: 倒置Transformer,刷新时序预测新纪录 - 天戈朱 - 博客园

















 1129
1129

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









