







PaperInfive:五分钟了解一篇前沿论文

全文总结:本文提出iTransformer,无需修改任何模块,倒置建模多变量时间序列,将变量的整条序列独立地映射为词(Variate Token)。以变量为主体,通过注意力机制自然地挖掘以词为单位的多变量关联。此外,Transformer的前馈网络和层归一化互相配合,消弭变量测量单位之间的范围差异,学习适合于时序预测的序列特征。
题目:iTransformer:Inverted Transformers Are effective for Time Series Forecasting
作者:Yong Liu
期刊/会议:ICLR
时间:2024
链接:https://doi.org/10.48550/arXiv.2310.06625
源码:https://github.com/thuml/iTransformer
问题背景
在时序分析领域,受益于其强大的序列建模能力与可扩展性,Transformer广泛应用于时序预测,派生出了许多模型改进。然而,研究人员最近开始质疑基于transformer的预测器的有效性,这些预测器通常将同一时间戳的多个变量嵌入到不可区分的通道中,并将注意力集中在这些时间标记上,以捕获时间依赖性。近期涌现的线性预测模型,比起相对更复杂的Transformer及其变体,能够取得相当甚至更好的效果。由此,针对Transformer是否适合时序预测,引发了热烈讨论。
与此同时,最近的研究更加强调了确保变量的独立性和利用互信息,现有的研究大多以颠覆普通的Transformer架构来显式地建模多元相关性,否则则难以实现准确的预测。
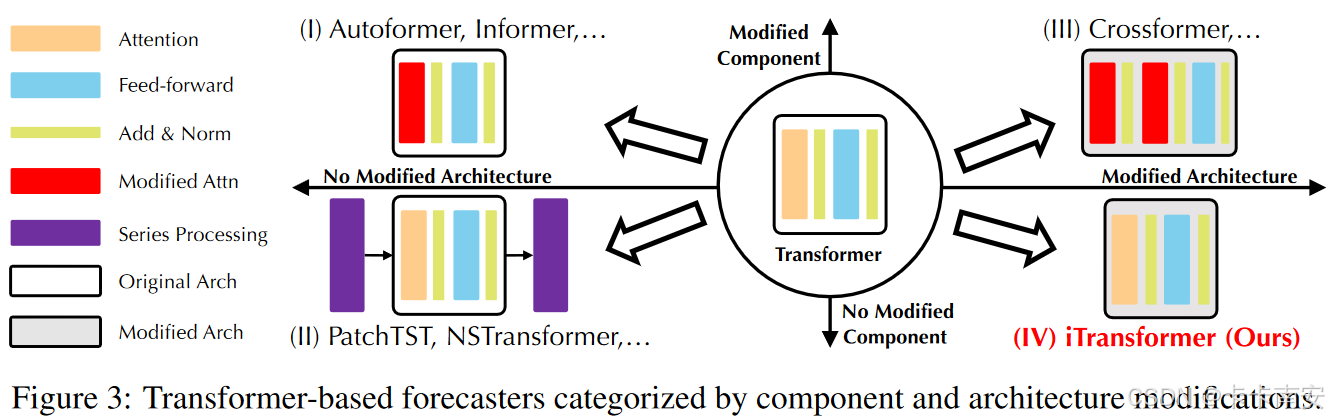
针对上述问题,作者认为在多变量时间序列上,Transformer的建模能力没有得到充分发挥,主要基于以下几个原因:
- 现有的基于Transformer的预测器结构可能不适合多变量时间序列预测。现有的Transformer模型将同一个时刻的多个变量作为一个Token(Temporal Token),然而相同时间步长的点基本上表示完全不同的物理含义,这些点嵌入到一个Token中,消除了多元相关性;
- 由于过度的局部感受野和由相同时间点表示的时间非对齐事件,单个时间步长的token可能很难揭示有益信息;
- 序列变化会受到序列顺序的很大影响,但在时间维度上采用置换不变注意力机制并不恰当。
因此,Transformer在捕捉基本序列表示和描绘多元相关性方面被削弱,限制了其在不同时间序列数据上的能力和泛化能力。
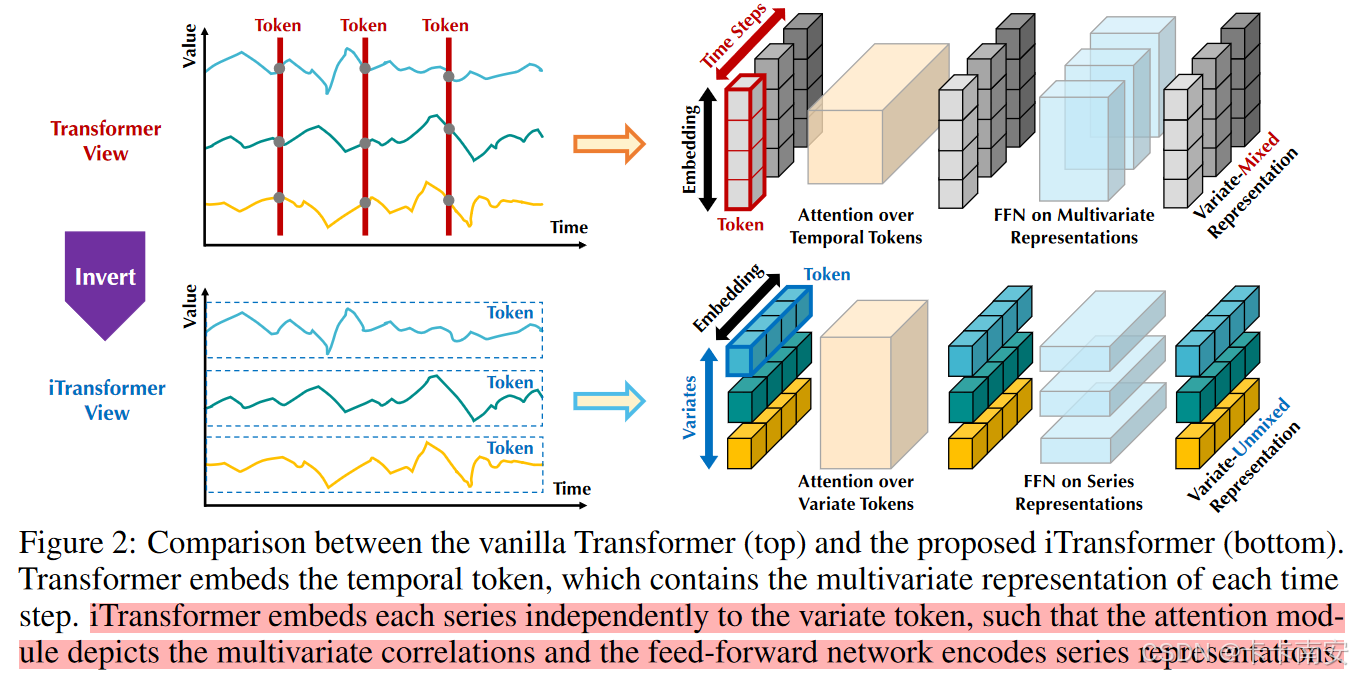
基于此,作者提出Inverted Transformer,无需修改任何模块,倒置建模多变量时间序列。将变量的整条序列独立地映射为词(Variate Token)。以变量为主体,通过注意力机制自然地挖掘以词为单位的多变量关联。此外,Transformer的前馈网络和层归一化互相配合,消弭变量测量单位之间的范围差异,学习适合于时序预测的序列特征。
研究方法
1. iTransformer模型架构
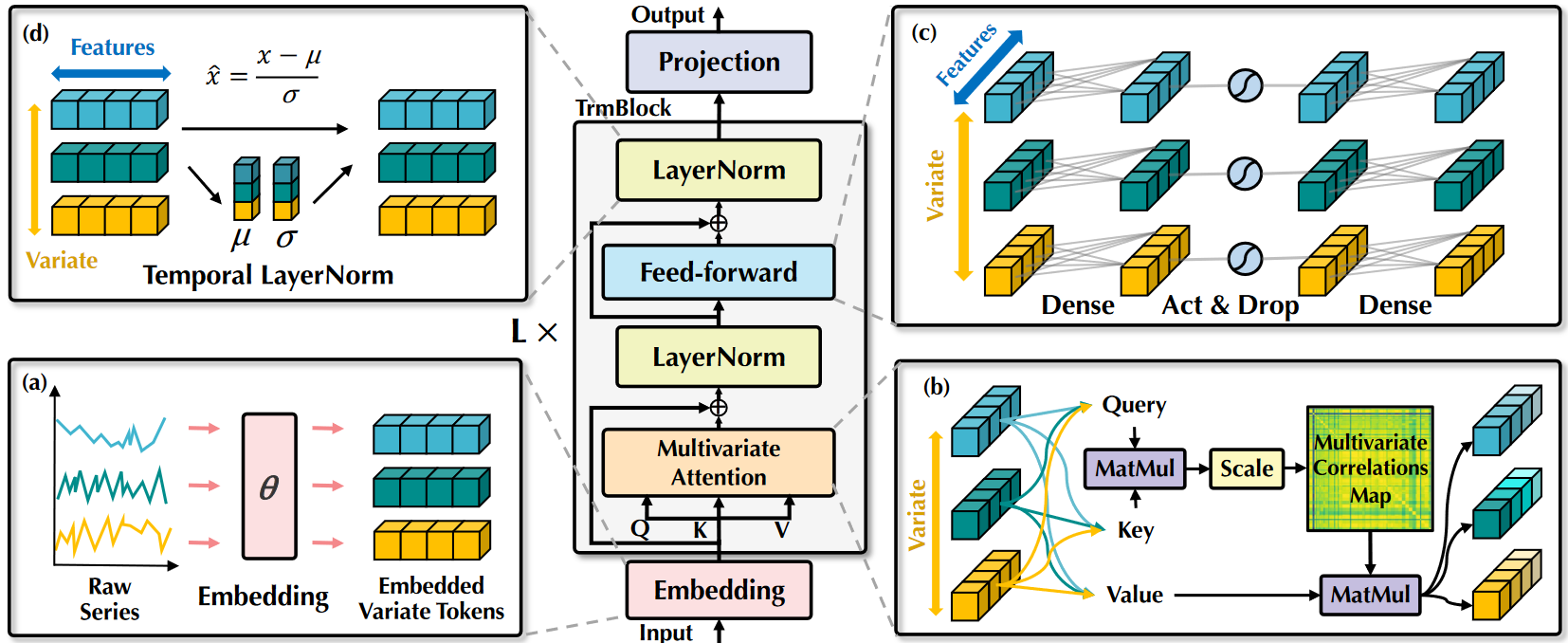
从上图可以看到,iTransformer模型主要有三个模块构成,分别是Embedding、TrmBlock和Temporal Projection:
- Embedding:Embedding对时间序列中的时间模式进行建模,由一个全连接层组成,不同变量的原始序列作为标记独立嵌入;
- TrmBlock:传统的Attention机制多应用于时间维度,即计算其他时刻与当前时刻的权重;TrmBlock则将Self-Attention应用于变量维度,即计算其他的变量与当前变量之间的权重,从而提取不同变量之间的相关性。
- Projection:时间投影是应用于时域的全连接层。它们不仅学习时间模式,还将时间序列映射到目标预测长度T。
假设给定时间长度为 T T T,变量数为 N N N的多维时间序列 X ∈ R T × N \mathbf{X}\in \mathbb{R}^{T\times N} X∈RT×N,则:
- Embedding: H = Embedding ( X T ) \mathbf{H}=\text{Embedding}\left( \mathbf{X}^{\text{T}} \right) H=Embedding(XT), H ∈ R N × D \mathbf{H}\in \mathbb{R}^{N\times D} H∈RN×D,即将 X \mathbf{X} X转置后将全连接层应用于时间维度 T T T上,得到特征维度 D D D;
- TrmBlock: H l + 1 = TrmBlock ( H l ) \mathbf{H}^{l+1}=\text{TrmBlock}\left( \mathbf{H}^{\text{l}} \right) Hl+1=TrmBlock(Hl),这一层用于提取变量之间的相关性,前后数据的维度不发生改变,都是 H ∈ R N × D \mathbf{H}\in \mathbb{R}^{N\times D} H∈RN×D;
- Projection: Y = Projection ( H ) \mathbf{Y}=\text{Projection}\left( \mathbf{H} \right) Y=Projection(H), Y ∈ R N × S \mathbf{Y}\in \mathbb{R}^{N\times S} Y∈RN×S,其中 S S S表示待预测的序列长度,得到的 Y \mathbf{Y} Y即为最终的预测结果,表示 N N N个变量未来 S S S长度的预测值。
需要注意的是,由于时间点之间的顺序已经隐含在神经元的排列顺序中,模型能够感知时间点的顺序关系,因此不需要额外引入位置编码(Position Embedding)。
2. 模块分析
接下来介绍一下TrmBlock中各个模块的作用:
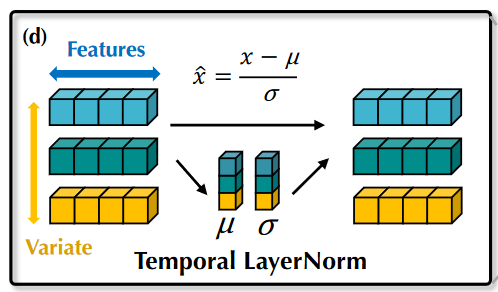
- 层归一化(LayerNorm):在此前Transformer中,层归一化将同一时刻的的多个变量进行归一化,使每个变量杂糅无法区分,提高了注意力建模词关联的难度。在倒置版本中,层归一化作用于Variate Token内部,让所有变量的特征都处于相对统一的分布下,减弱测量单位的差异。这种方式还可以有效处理时间序列的非平稳问题问题。(对每个变量单独做归一化)
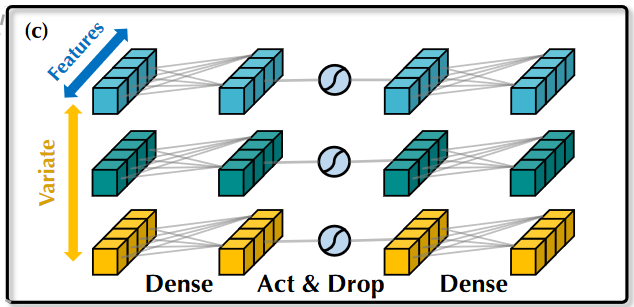
- 前馈网络(Feed-Forward):基于多层感知机的万能表示定理,前馈网络作用在整条序列上,能够提取序列的内在属性,例如幅值,周期性,频率谱(傅立叶变换可视作在序列上的全连接映射),从而提高在其他的序列上的泛化性。(在特征维度D上应用两层MLP)
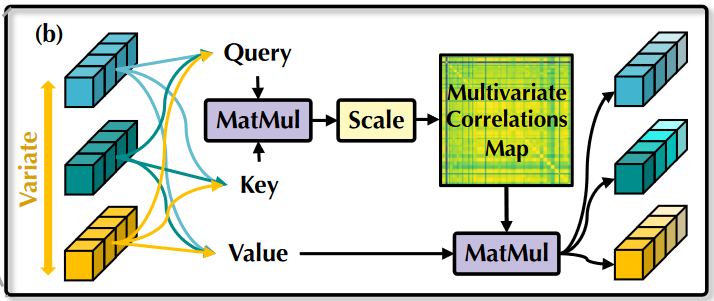
- 注意力机制(Multivariat Attention): 自注意力模块在该模型中用于建模不同变量的相关性,与传统的Attention计算公式相同: A i , j = ( Q K T / d k ) i , j ∝ q i T k j \mathbf{A}_{i,j}=\left( \mathbf{QK}^{\text{T}}/\sqrt{d_k} \right) _{i,j}\propto \text{q}_{i}^{\text{T}}\text{k}_j Ai,j=(QKT/dk)i,j∝qiTkj,其中传统的Attention应用于时间维度,即 A ∈ R T × T \mathbf{A}\in \mathbb{R}^{T\times T} A∈RT×T,在iTransformer中Attention应用于变量维度,即 A ∈ R N × N \mathbf{A}\in \mathbb{R}^{N\times N} A∈RN×N。在后续的Softmax加权操作中,高度相关的变量将在与其Value向量的交互中获得更大的权重,因此这种设计更自然地建模了多变量时序数据的关联,在有物理知识驱动的复杂预测场景中格外重要。
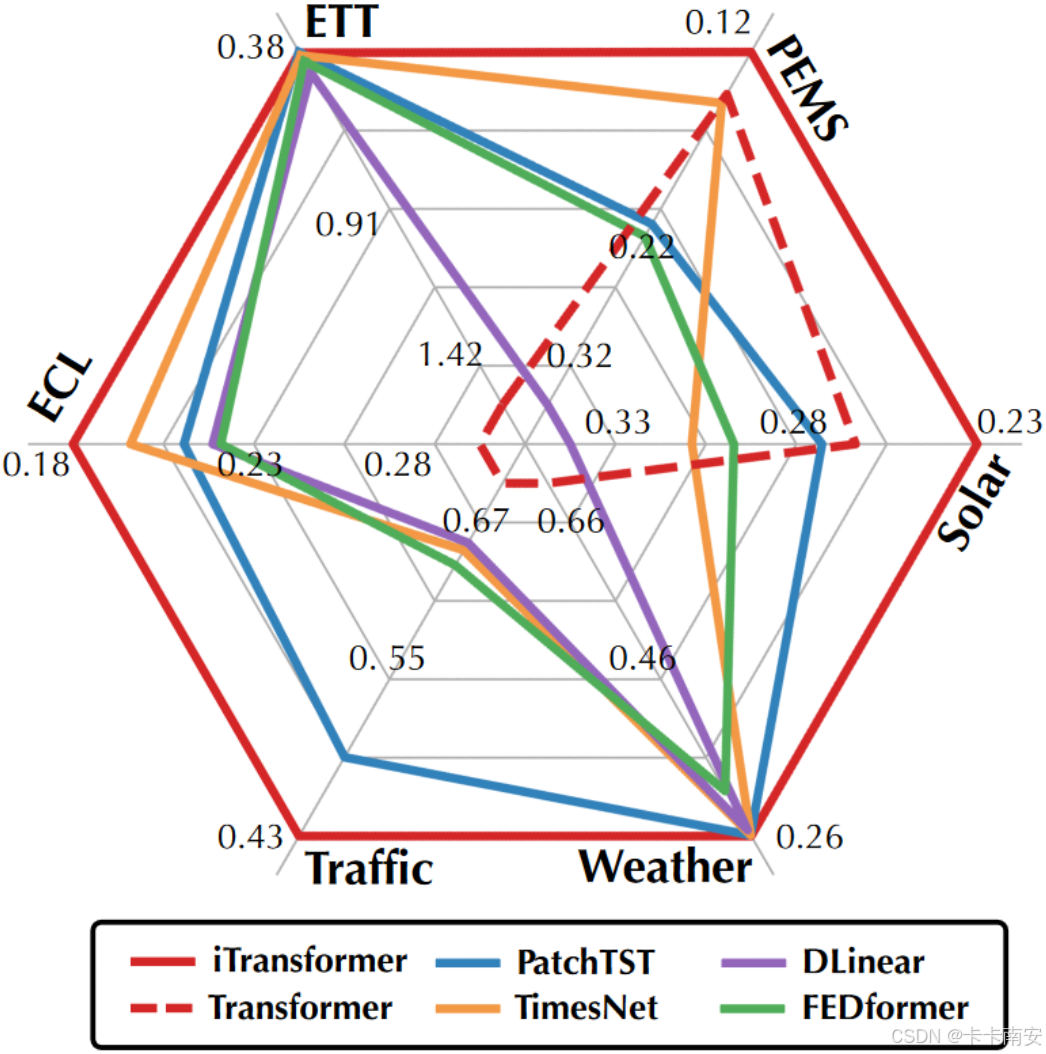
预测效果
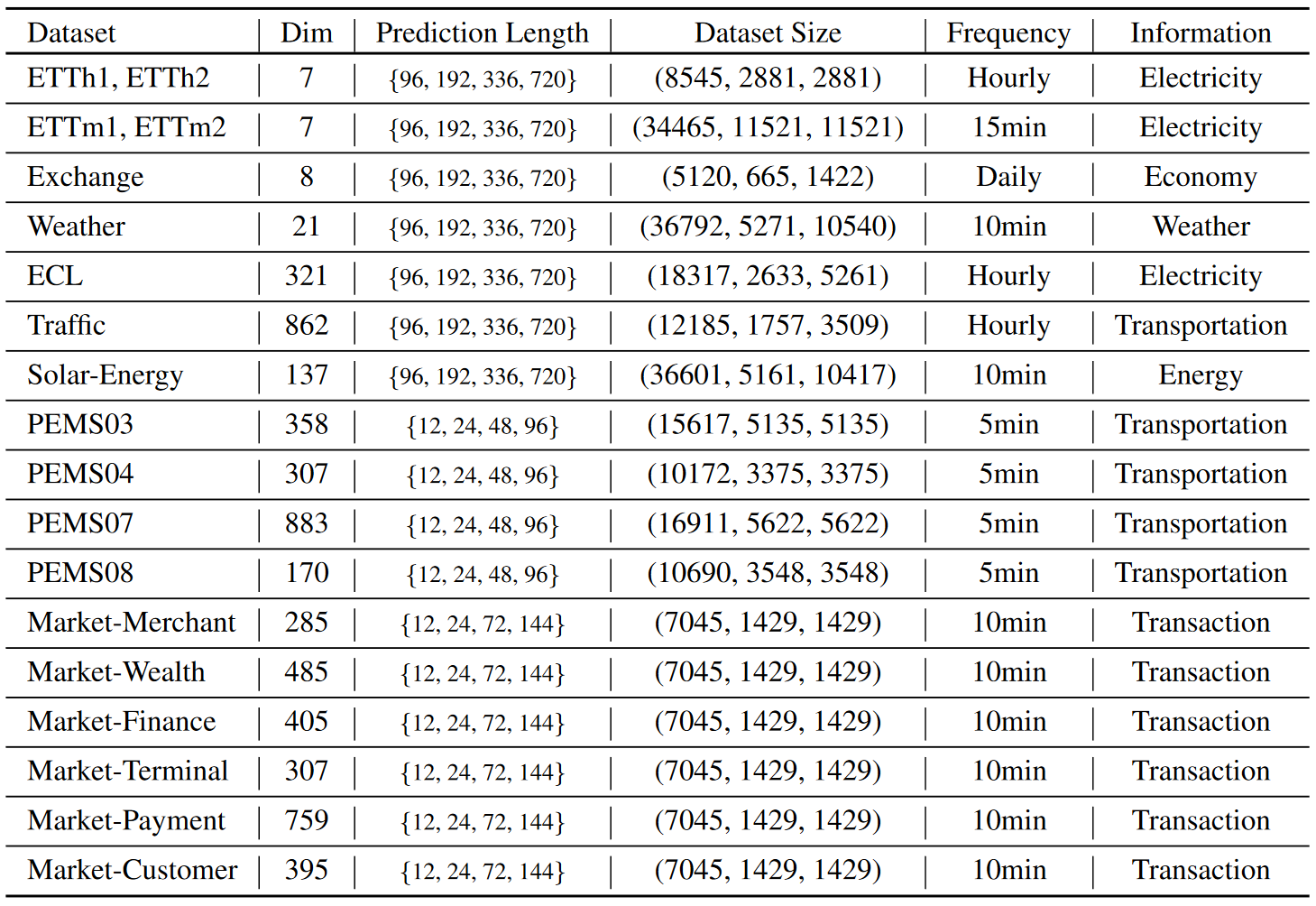
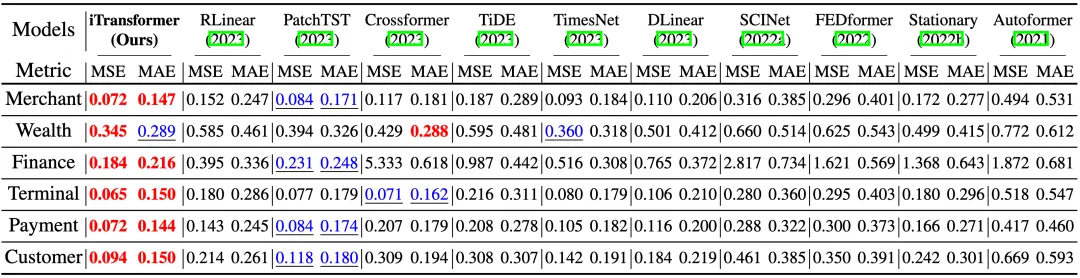
作者在七大多维时序预测基准上进行了广泛的实验,同时在支付宝交易平台的线上服务负载预测任务场景的数据(Market)中进行了预测,涵盖19个数据集,76种不同的预测设置。
对比了10种深度预测模型,包含领域代表性Transformer模型:PatchTST(2023)、Crossformer(2023)、FEDformer(2022)、Stationary(2022)、Autoformer(2021);线性预测模型:TiDE(2023)、DLinear(2023)、RLinear(2023);TCN系模型:TimesNet(2023)、SCINet(2022)。
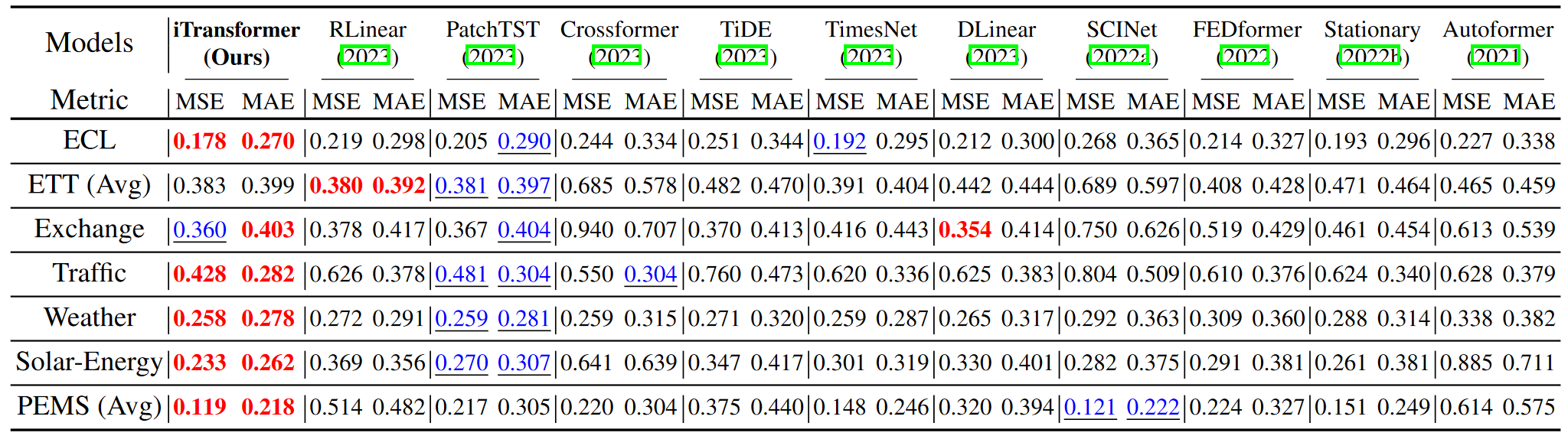
1. 时序预测
相较以往测试基准汇报模型在不同输入长度下调优后的效果,作者使用统一的输入长度,一方面避免过度调参,另一方面契合真实预测场景。如下表所示,iTransformer在基准比较中显著超过此前领域最优效果。此前受到质疑的Transformer,只需简单倒置,就能在多变量时序预测中超越目前主流预测模型。
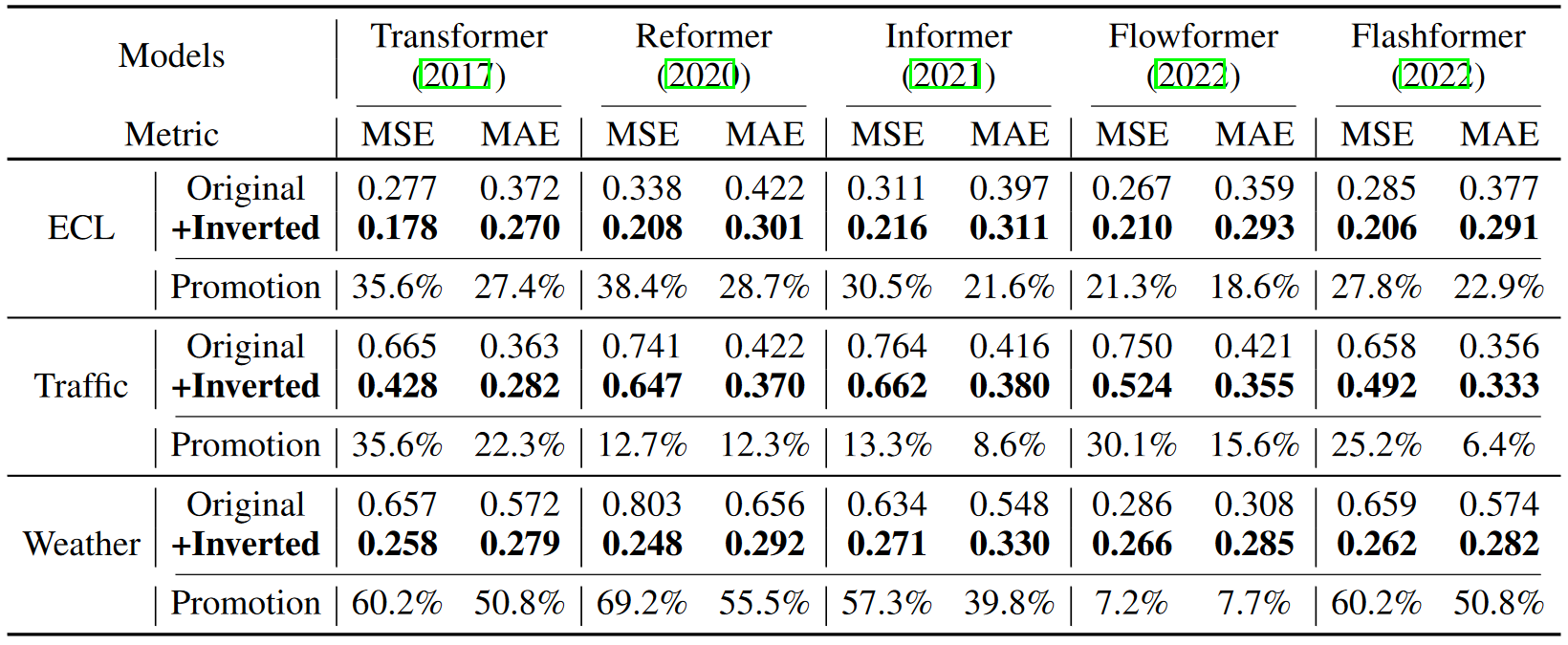
2. 通用性实验
作者将其他Transformer变体模型进行同样的倒置,证明倒置是符合建模多变量时序数据的通用框架。
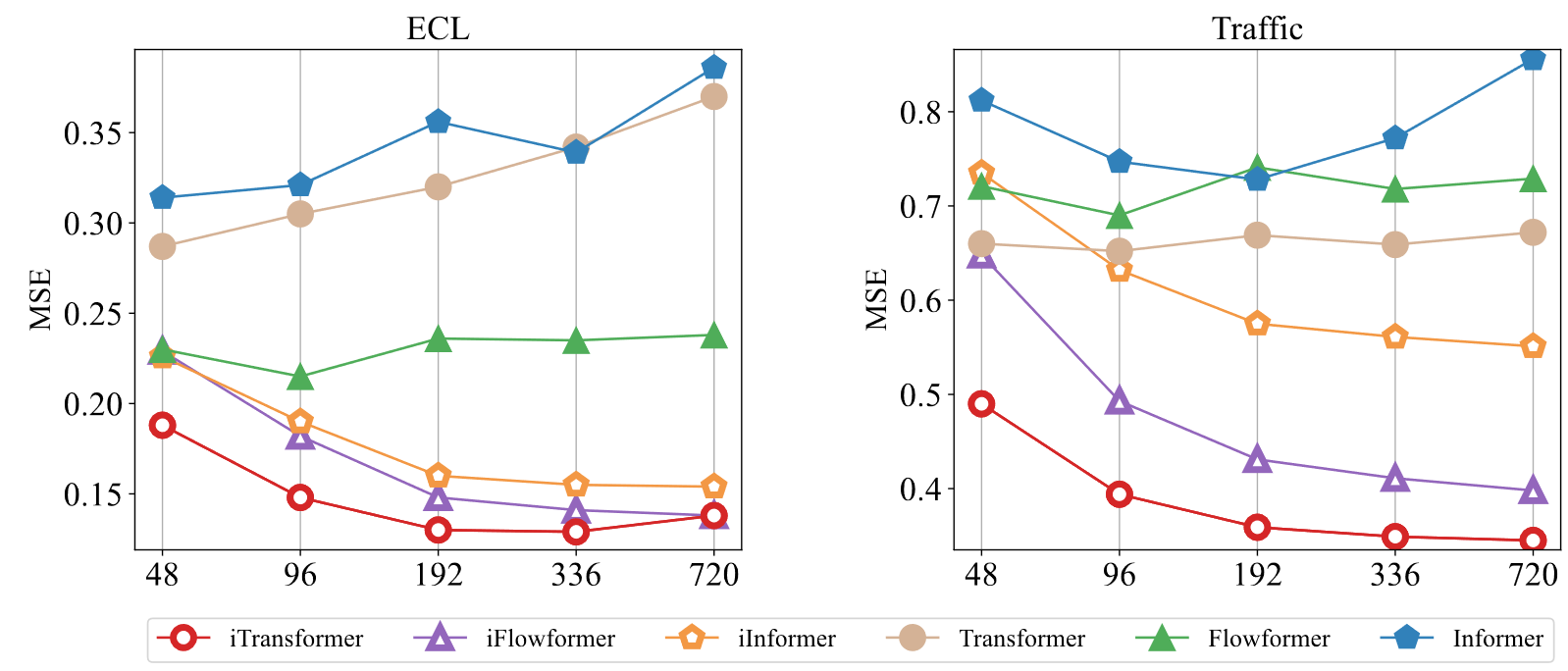
3. 长时预测
以往Transformer模型的效果不一定随着输入的历史观测的变长而提升,在使用倒置框架后,模型随着历史观测长度的增加,呈现明显的预测误差降低趋势。
4. 泛化到未知变量
通过倒置,模型在推理时可以输入不同于训练时的变量数,结果表明该框架在仅使用部分变量训练时能够取得较低的误差,证明证明倒置结构在变量特征学习上的泛化性。同时与通道独立(Chanel Independence)的模型进行比较,结果表明通过转置的方法考虑多元像关系有利于提升预测精度。
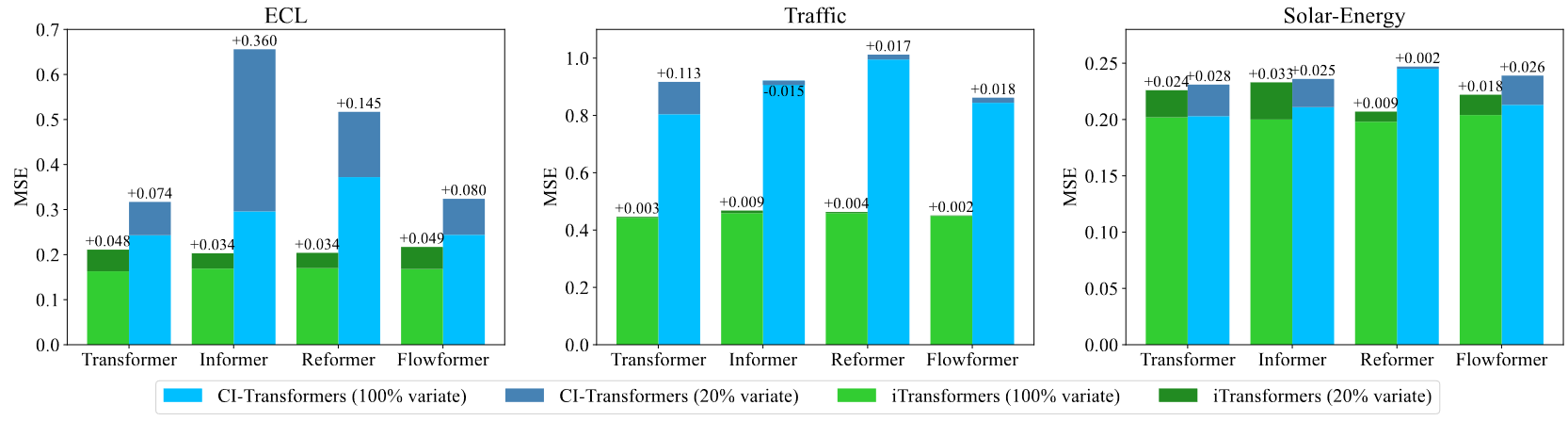
5. 消融实验
使用注意力建模变量间关系,使用线性层提取变量内表征,在大部分数据集取得了最优效果,验证了倒置结构设计的合理性。
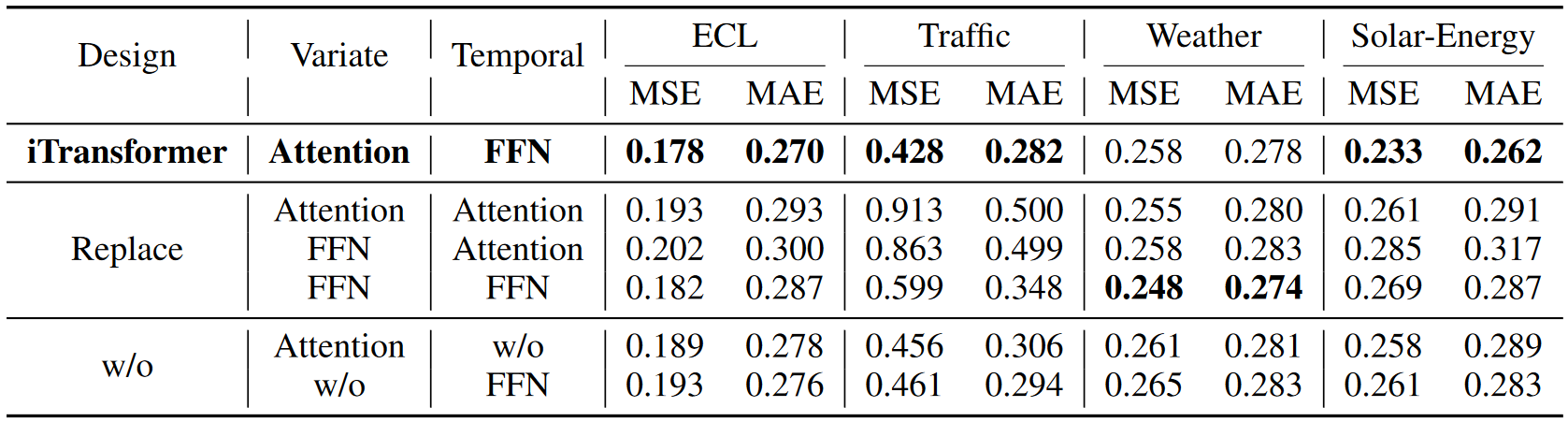
结论
考虑到多元时间序列的特点,本文提出iTransformer,在不修改任何原生模块的情况下反转Transformer的结构。iTransformer将独立序列作为变量标记,通过注意力捕捉多元相关性,并利用层归一化和前馈网络学习序列表示。实验表明,iTransformer取得了最先进的性能,并在有希望的分析支持下表现出显著的框架通用性。
思考
iTransformer实际上提出了一种新的视角来思考多元时间序列模态,特别是如何考虑变量和标记化。当前魔改Transformer之风盛行,这篇文章通过一个简单的转置操作即达到了SOTA的效果,正所谓“重剑无锋,大巧不工”,这种简单又好用的创新点和模块我觉得才是科研工作应该追求的。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









