






 本文详细描述了一项使用NaiveBayes算法对Ljubljana幼儿园入学推荐进行预测的实验。通过分析训练集规模对模型性能的影响,展示了朴素贝叶斯分类器如何随着数据量增加而提升准确率,同时探讨了拉普拉斯平滑在处理零概率事件中的作用和过拟合问题。
本文详细描述了一项使用NaiveBayes算法对Ljubljana幼儿园入学推荐进行预测的实验。通过分析训练集规模对模型性能的影响,展示了朴素贝叶斯分类器如何随着数据量增加而提升准确率,同时探讨了拉普拉斯平滑在处理零概率事件中的作用和过拟合问题。
山东大学计算机学院机器学习实验四(A Python Version)
From lyz103
实验题目:
Naive Bayes
实验目的:
The purpose of the experiment is to use Naive Bayes to make admission recommendations based on a dataset of admission decisions to a nursery in Ljubljana, Slovenia. The goal is to build a Naive Bayes classifier that can accurately predict admission recommendations.
实验步骤与内容:
① 数据加载:
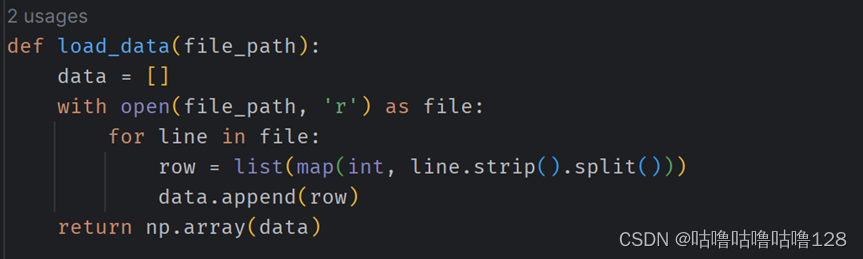
② 使用 load_data 函数加载包含文本特征和对应类别的训练数据和测试数据。
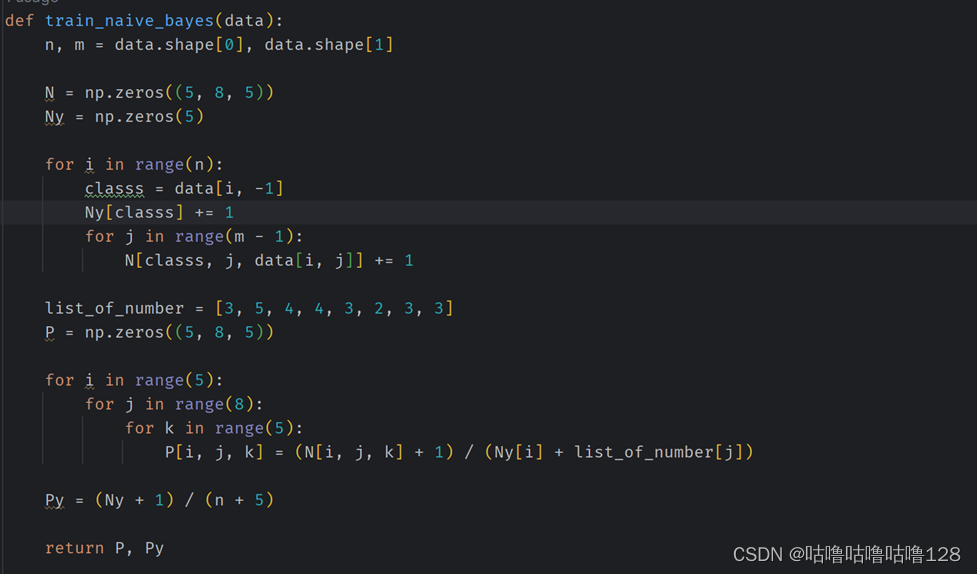
朴素贝叶斯训练:
使用 train_naive_bayes 函数进行训练。
统计每个类别的文档数和每个特征在给定类别下的出现次数。
计算每个类别的先验概率和每个特征在给定类别下的条件概率。
引入拉普拉斯平滑以处理概率为零的情况。
③ 朴素贝叶斯测试:
使用 test_naive_bayes 函数对测试数据进行分类。
对每个测试样本,计算其属于每个类别的概率。
选择概率最大的类别作为预测结果。
计算分类准确率。
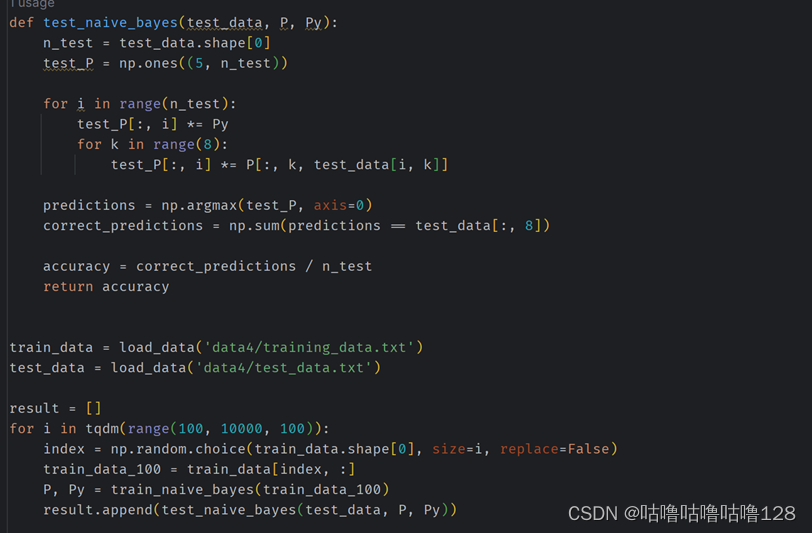
④ 性能评估:
在循环中,逐步增加训练集的规模(从 100 到 10000)。
对于每个规模,随机选择对应数量的样本构成新的训练集。
用新的训练集重新训练朴素贝叶斯模型,并在测试数据上进行测试。
记录每次测试的准确率。
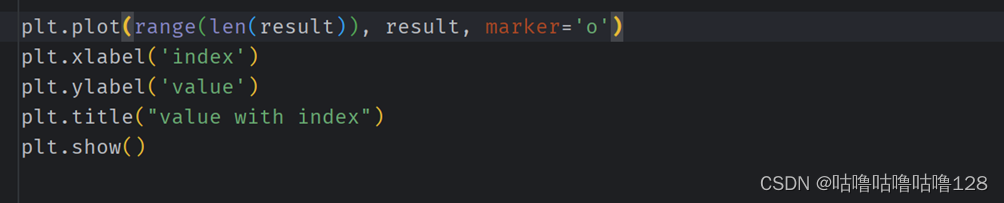
⑤ 结果可视化:
使用 plt.plot 函数绘制图表,横坐标为训练集规模的索引,纵坐标为每次测试的准确率。
展示随着训练集规模的增加,模型性能的变化趋势。
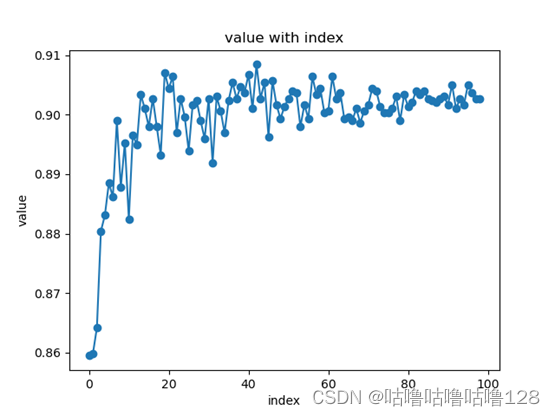
结论分析与体会:
① 模型性能随训练集规模的变化:
通过观察绘制的图表,可以看到朴素贝叶斯分类器的性能随着训练集规模的增加而变化。
在小规模数据集上,模型可能受到噪声和样本偶然性的影响,表现不够稳定。
随着训练集规模的增加,模型可能更好地学习数据的统计特征,从而提高在测试数据上的分类准确率。
② 训练集规模与过拟合:
随着训练集规模的增加,模型可能更容易捕捉数据的真实分布,减轻过拟合问题。
过拟合可能在小规模数据上更为明显,因为模型过度依赖有限的样本,而在大规模数据上,模型能更好地泛化到未见过的数据。
③ 拉普拉斯平滑的影响:
在朴素贝叶斯模型中使用拉普拉斯平滑可以避免概率为零的问题,使得模型更具有鲁棒性。
拉普拉斯平滑对于小规模数据集尤为重要,因为在这种情况下零概率事件更容易发生。
④ 实验的局限性与改进方向:
实验中随机选择训练集可能导致实验结果的随机性。可以多次进行实验并取平均值来降低随机性的影响。
实验中使用的特定数据集和朴素贝叶斯模型的性能表现不一定适用于其他问题。可以考虑使用不同数据集和模型进行更全面的实验。
⑤ 对朴素贝叶斯的理解:
通过这个实验,更深入理解了朴素贝叶斯分类器的工作原理,以及在文本分类任务中的应用。了解了模型参数(概率)的计算方式,以及训练和测试的基本流程。
总体来说,这个实验提供了一个直观的视角,展示了在文本分类任务中朴素贝叶斯模型如何随着训练集规模的变化而表现。在实际应用中,这些观察有助于指导如何有效地利用数据来提高分类模型的性能。
问题回答:
Question 1: Estimate a Naive Bayes model using Maximum Likelihood on the training data, and use it to predict the categories of the test data. Report the accuracy of your classifier
Answer1:the accuracy is 0.9030405405405405
Question 2: Try smaller data sets for training. Use data sets of different sizes to train your Naive Bayes model. Specifically, extract smaller subsets from the given training data in a randomized manner. Show how the size of the training data impact on the accuracy of the Naive Bayes model, and give corresponding analysis.
Answer2:According to the graph, it can be observed that increasing the size of the training data initially leads to a significant improvement in the accuracy of the Naive Bayes classifier. This effectively addresses the overfitting issue associated with small datasets. However, as the dataset grows to a certain extent, the accuracy plateaus because most of the features have already been learned. In the initial stages of increasing the training data, the model benefits from a richer and more diverse set of examples, allowing it to generalize better to unseen instances. This helps mitigate the overfitting that may occur when the model is trained on a limited number of samples. As the dataset continues to grow, the model becomes saturated with information, and additional data may not contribute significantly to further improvement. The diminishing returns suggest that the model has already captured the essential patterns and relationships within the data. In summary, the experiment highlights the importance of a sufficiently large and diverse dataset for training a Naive Bayes classifier. The observed pattern underscores the trade-off between the benefits of increased data volume and the point of diminishing returns in terms of model performance.
import numpy as np
import matplotlib.pyplot as plt
from tqdm import tqdm
def load_data(file_path):
data = []
with open(file_path, 'r') as file:
for line in file:
row = list(map(int, line.strip().split()))
data.append(row)
return np.array(data)
def train_naive_bayes(data):
n, m = data.shape[0], data.shape[1]
N = np.zeros((5, 8, 5))
Ny = np.zeros(5)
for i in range(n):
classs = data[i, -1]
Ny[classs] += 1
for j in range(m - 1):
N[classs, j, data[i, j]] += 1
list_of_number = [3, 5, 4, 4, 3, 2, 3, 3]
P = np.zeros((5, 8, 5))
for i in range(5):
for j in range(8):
for k in range(5):
P[i, j, k] = (N[i, j, k] + 1) / (Ny[i] + list_of_number[j])
Py = (Ny + 1) / (n + 5)
return P, Py
def test_naive_bayes(test_data, P, Py):
n_test = test_data.shape[0]
test_P = np.ones((5, n_test))
for i in range(n_test):
test_P[:, i] *= Py
for k in range(8):
test_P[:, i] *= P[:, k, test_data[i, k]]
predictions = np.argmax(test_P, axis=0)
correct_predictions = np.sum(predictions == test_data[:, 8])
accuracy = correct_predictions / n_test
return accuracy
train_data = load_data('data4/training_data.txt')
test_data = load_data('data4/test_data.txt')
result = []
for i in tqdm(range(100, 10000, 100)):
index = np.random.choice(train_data.shape[0], size=i, replace=False)
train_data_100 = train_data[index, :]
P, Py = train_naive_bayes(train_data_100)
result.append(test_naive_bayes(test_data, P, Py))
plt.plot(range(len(result)), result, marker='o')
plt.xlabel('index')
plt.ylabel('value')
plt.title("value with index")
plt.show()
















 984
984











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











