







在高光谱图像(HSI)分类任务中,充分利用 HSI 中的空间信息对提升分类性能至关重要。传统方法在处理 HSI 时,难以有效捕捉复杂的数据模式和交互,无法充分挖掘空间信息的价值。卷积神经网络(CNNs)在分析空间特征方面有一定优势,但在利用 HSI 的序列光谱信息时存在不足;基于 Transformer 的方法虽能识别空间和光谱数据之间的长程依赖关系,但在从卷积获得的浅层特征中提取多维特征时面临挑战。为了更高效地利用 HSI 的空间信息,增强像素级注意力,建立局部和非局部依赖关系,从而提升整体分类性能,设计了混合池化注意力(HPA)模块。
上面是原模型,下面是改进模型


1. 混合池化注意力模块HPA介绍
平均池化和最大池化操作的结合可以有效整合通用和详细信息,增强特征图的表示能力。平均池化近似窗口内的值,类似对日常经验的模糊记忆,能获取数据的大致趋势;最大池化捕获窗口内的峰值,类似对重要或特殊事件的清晰记忆,可突出数据的关键特征。通过在不同空间维度上分别进行平均池化和最大池化操作,HPA 可以从不同角度捕捉特征信息。同时,利用分组和重加权的思想,对输入特征图进行分组处理,通过跨空间学习的方式整合不同组的特征,自适应地重新校准通道间的关系,实现不同的跨通道交互,从而有效捕捉和学习复杂的低级特征表示。
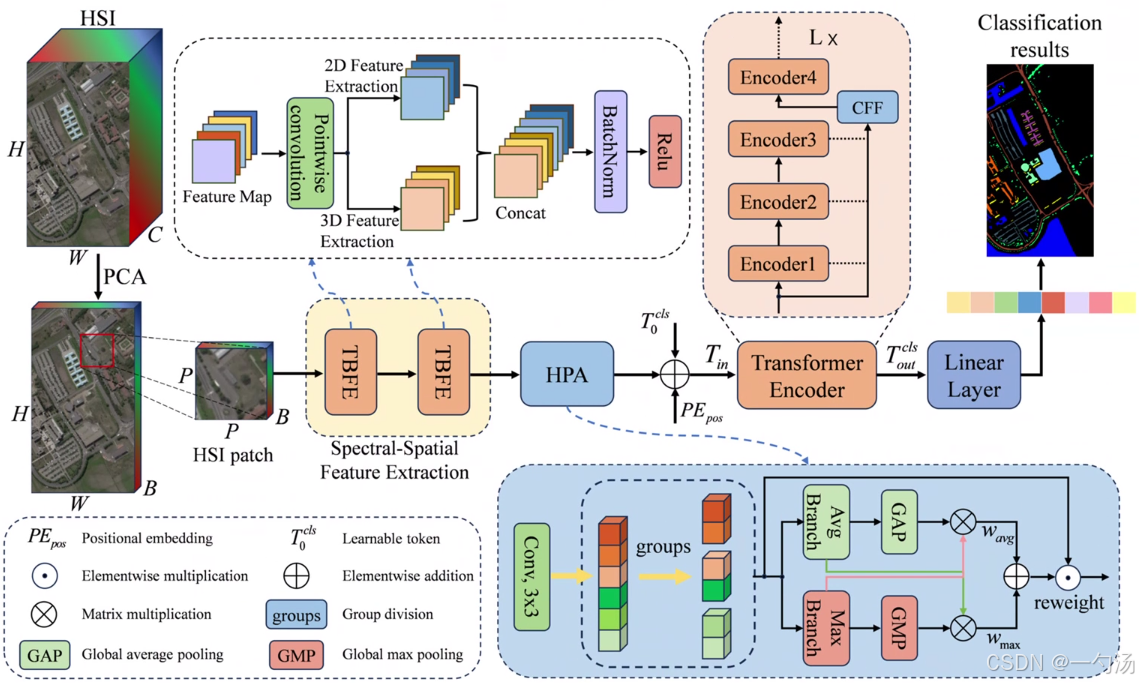
从提供的图片来看,HPA 模块主要包含以下几个部分:
分组操作:将输入特征图沿着通道维度划分为个子特征,以捕捉不同的语义信息,随后将分组数据重新组织,得到分组数据。
并行路径池化操作:利用两条并行路径从分组特征图中获取注意力权重表示。在平均池化分支,将分组数据分解为两个并行的 1D 特征编码子分支,分别沿高度和宽度维度进行 1D 全局平均池化操作,以收集垂直和水平方向的位置信息;在最大池化分支,同样分解为两个并行子分支,分别沿水平和宽度维度进行 1D 全局最大池化操作。
特征融合与校准:将两个编码特征沿图像高度方向连接,然后使用 1×1 卷积整合两个维度的特征,并应用 Sigmoid 函数拟合二项分布。通过元素相乘的方式聚合每组内的两个通道注意力图,自适应地重新校准通道间的关系。
跨空间信息聚合:受通道和空间位置间相互依赖关系的启发,提出跨空间信息聚合方法。对重新加权的特征图先通过 GroupNorm 层增强训练稳定性,再分别利用 2D 全局平均池化和最大池化编码全局空间信息 。
2. YOLOv11与HPA 的结合
本文使用HPA 模块替换C3K2模块中的普通卷积,增强YOLOv11模型空间特征,解决小目标、遮挡问题。
3. TBFE代码部分
YOLOv8_improve/YOLOv11.md at master · tgf123/YOLOv8_improve · GitHub
视频讲解:YOLOv11模型改进讲解,教您如何修改YOLOv11_哔哩哔哩_bilibili
YOLOv11模型改进讲解,教您如何根据自己的数据集选择最优的模块提升精度_哔哩哔哩_bilibili
YOLOv11全部代码,现有几十种改进机制。
4. 将TBFE引入到YOLOv11中
第一: 将下面的核心代码复制到D:\model\yolov11\ultralytics\change_model路径下,如下图所示。
第二:在task.py中导入包
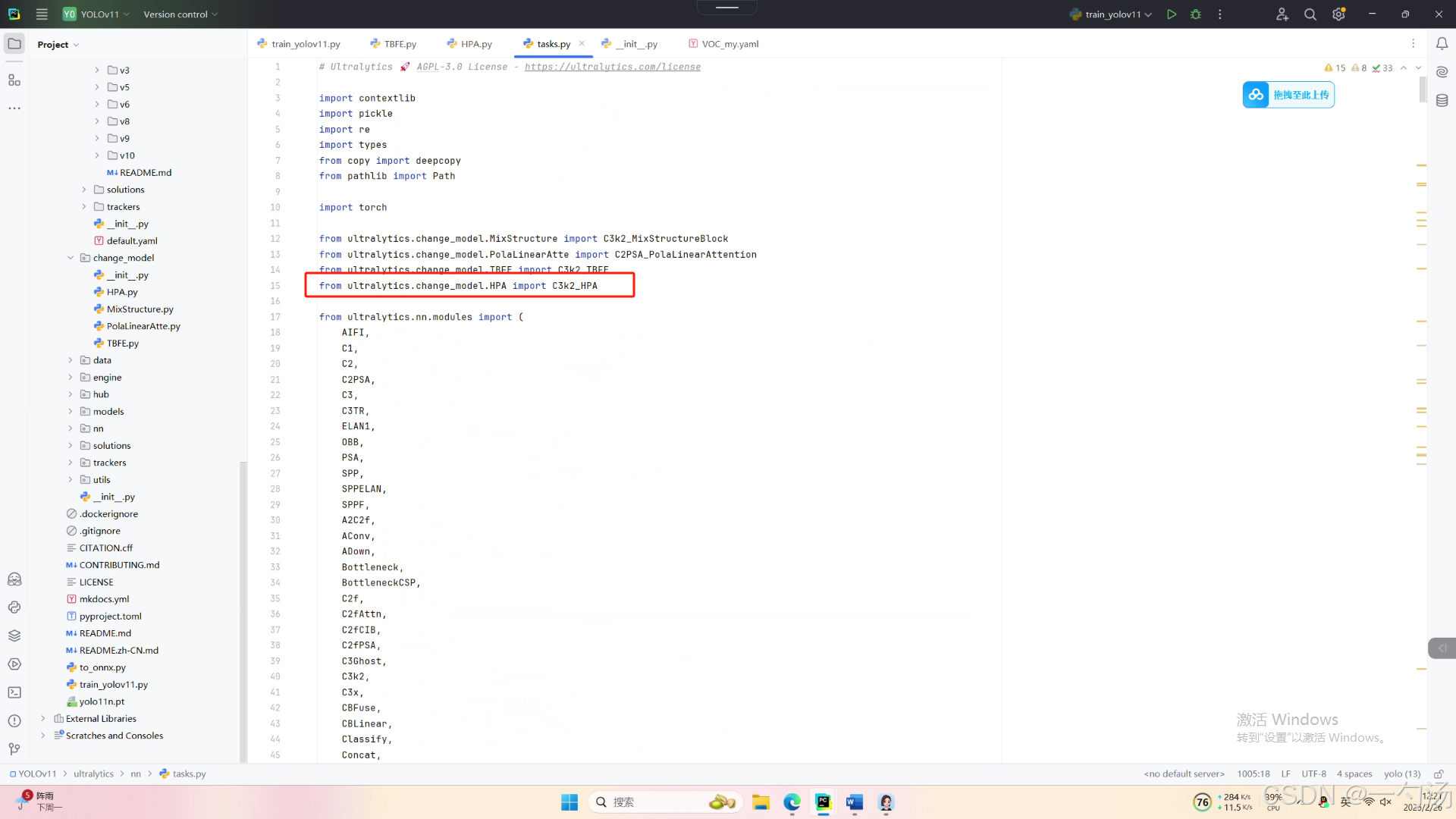
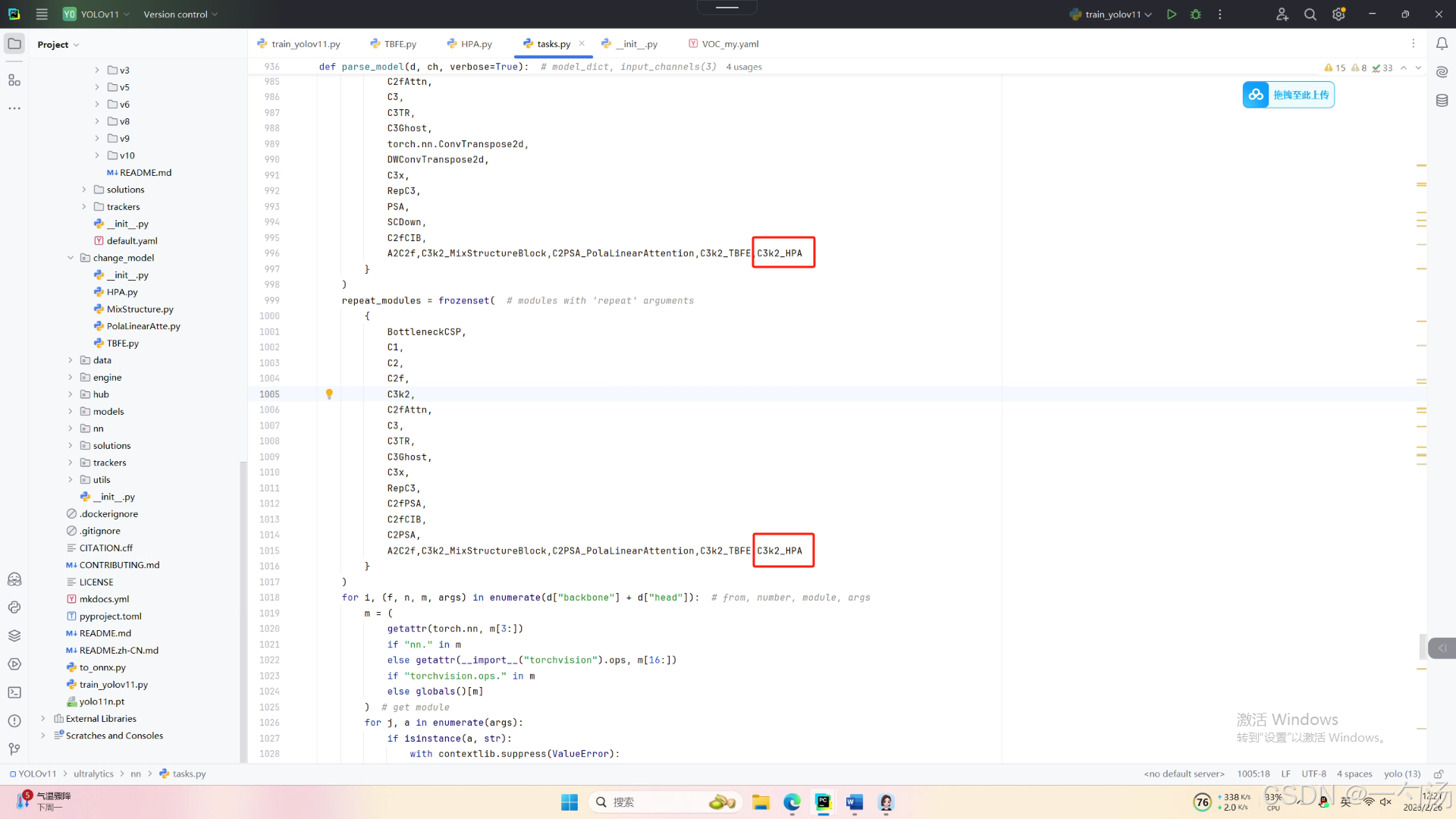
第三:在task.py中的模型配置部分下面代码
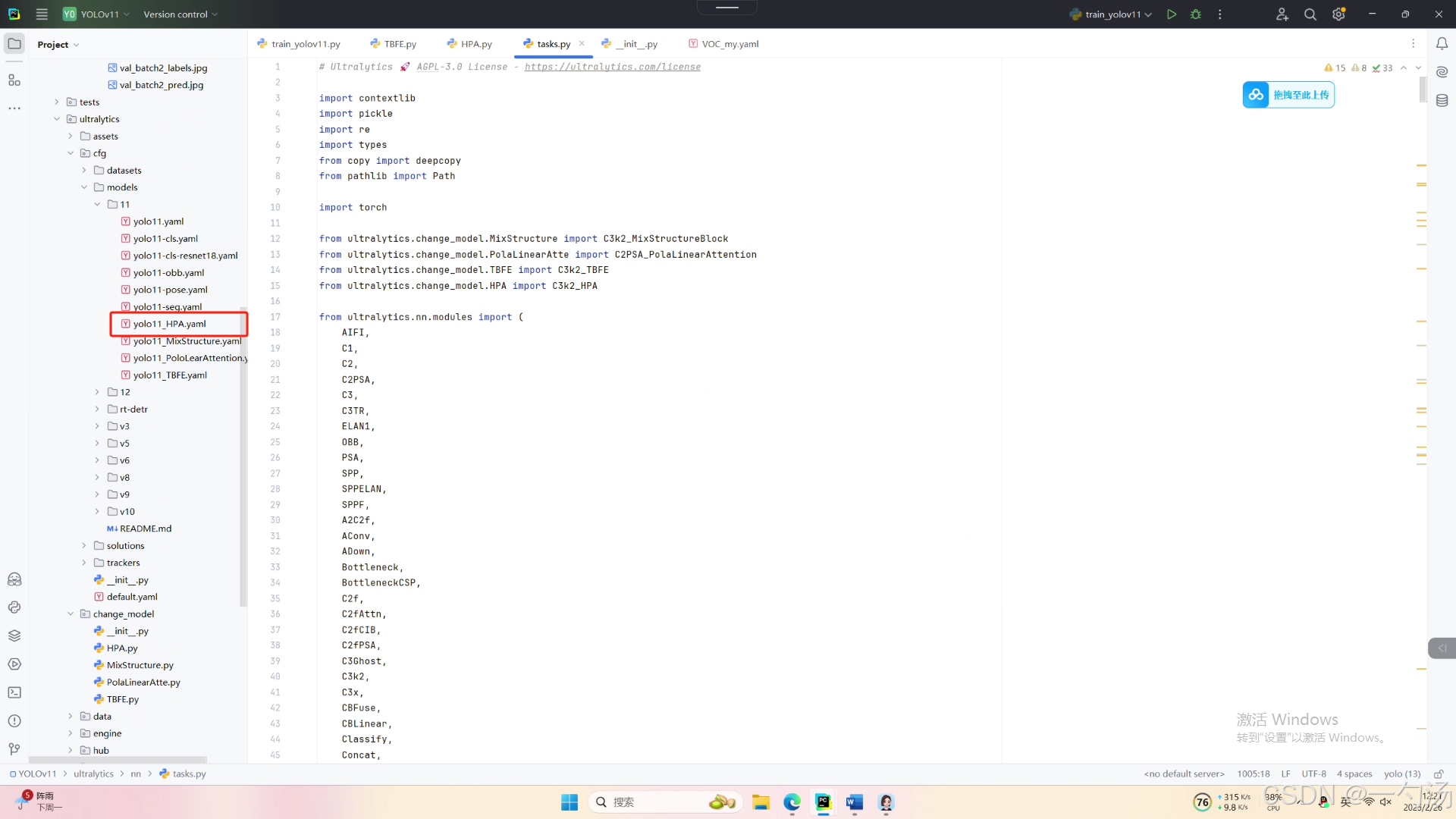
第四:将模型配置文件复制到YOLOV11.YAMY文件中
第五:运行成功
from sympy import false
from ultralytics.models import NAS, RTDETR, SAM, YOLO, FastSAM, YOLOWorld
if __name__=="__main__":
# 使用自己的YOLOv8.yamy文件搭建模型并加载预训练权重训练模型
model = YOLO(r"E:\Part_time_job_orders\YOLO\YOLOv11\ultralytics\cfg\models\11\yolo11_PHA.yamy")\
.load(r'E:\Part_time_job_orders\YOLO\YOLOv11\yolo11n.pt') # build from YAML and transfer weights
results = model.train(data=r'E:\Part_time_job_orders\YOLO\YOLOv11\ultralytics\cfg\datasets\VOC_my.yaml',
epochs=300,
imgsz=640,
batch=64,
# cache = False,
# single_cls = False, # 是否是单类别检测
# workers = 0,
# resume=r'D:/model/yolov8/runs/detect/train/weights/last.pt',
amp = True
)

















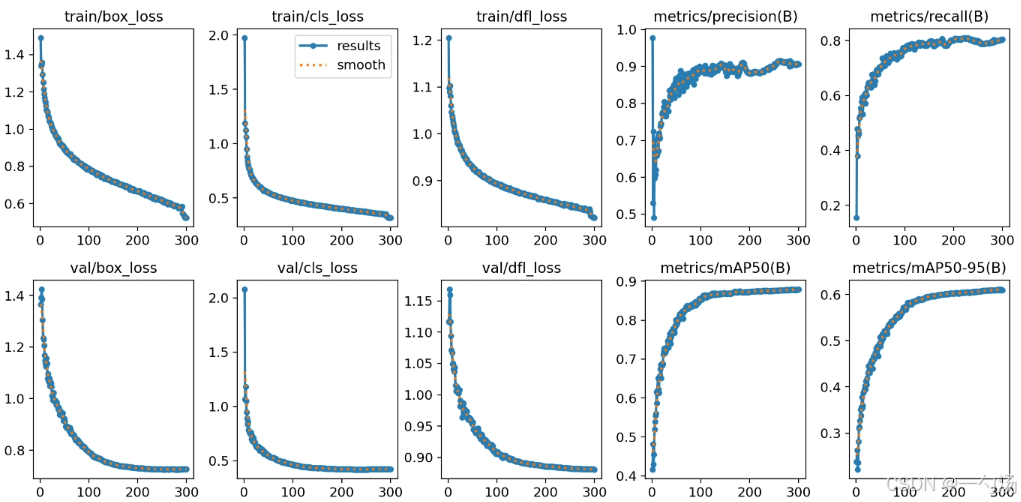
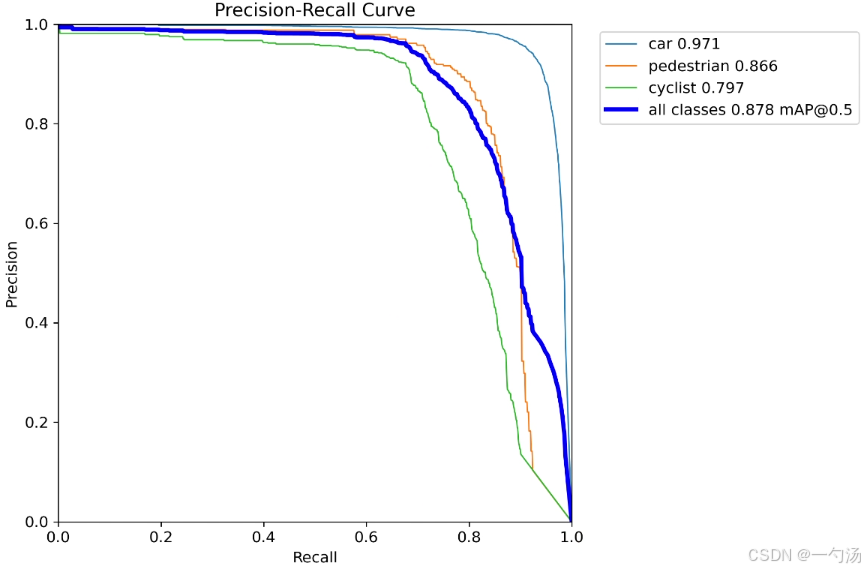
 2264
2264

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









