






MobileMamba论文分享
论文简介
计算机视觉领域的轻量化深度学习模型

作者
研究问题
模型的轻量化研究。以往的轻量级模型研究主要集中在CNN和Transformer的设计上,而这两种模型也都有各自固有的局限性。
| 模型 | 优点 | 局限 | 轻量化方法 |
|---|---|---|---|
| 基于CNN | 计算复杂度低 | 局部有效感知野,难以捕获长距离依赖。在具有高分辨率的输入下只有通过增加计算负载来提高性能 | 深度可分离卷积(MobileNets) 在一半的通道上使用廉价的计算方式(GhostNets) |
| 基于Transformer | 全局感知 | 二次计算复杂性导致比CNN更高的开销 | 三阶段网络(EfficientViT) 单头注意力,选择通道(SHViT) |
| 基于状态空间(SSM)模型 | 线性计算复杂性度 | 当前基于mamba的结构推理速度慢且性能不佳(对比CNN和Transformer),且当前的工作只提到了FLOPs,但FLOPs并不能直接反应模型的推理速度 | 优化扫描方式 |
主要贡献:
- 三阶段网络框架
- 多感知野的特征交互模块
方法
3个维度去做模型的轻量化:
- 粗粒度:三阶段框架
- 细粒度:多感知野特征交互模块
- 训练策略和推理策略
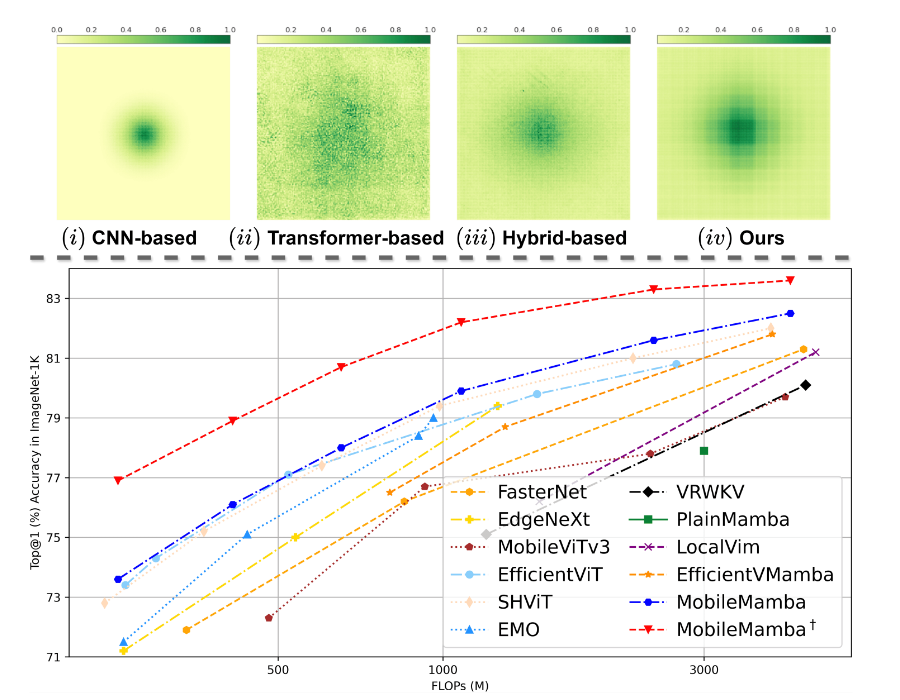
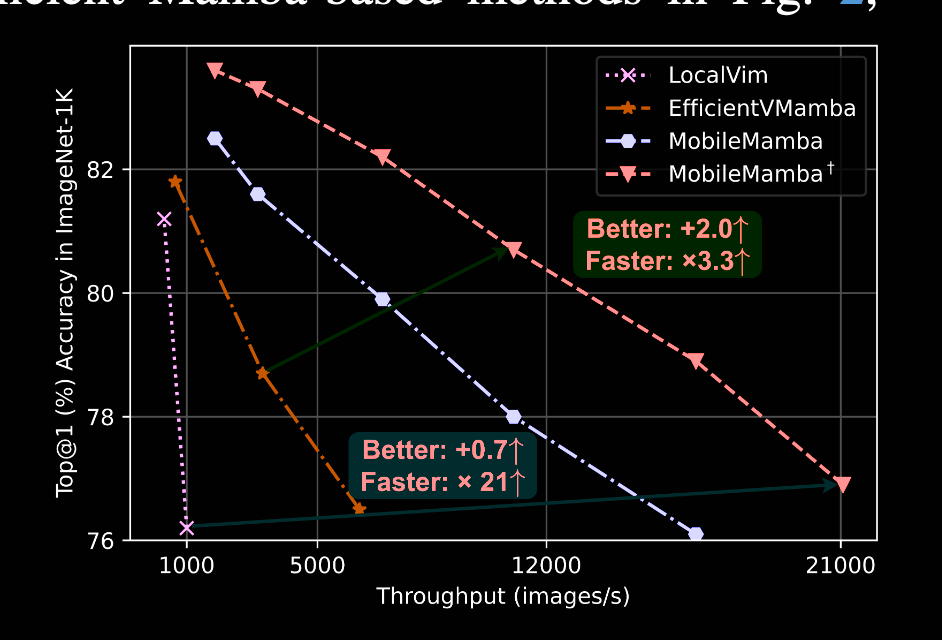
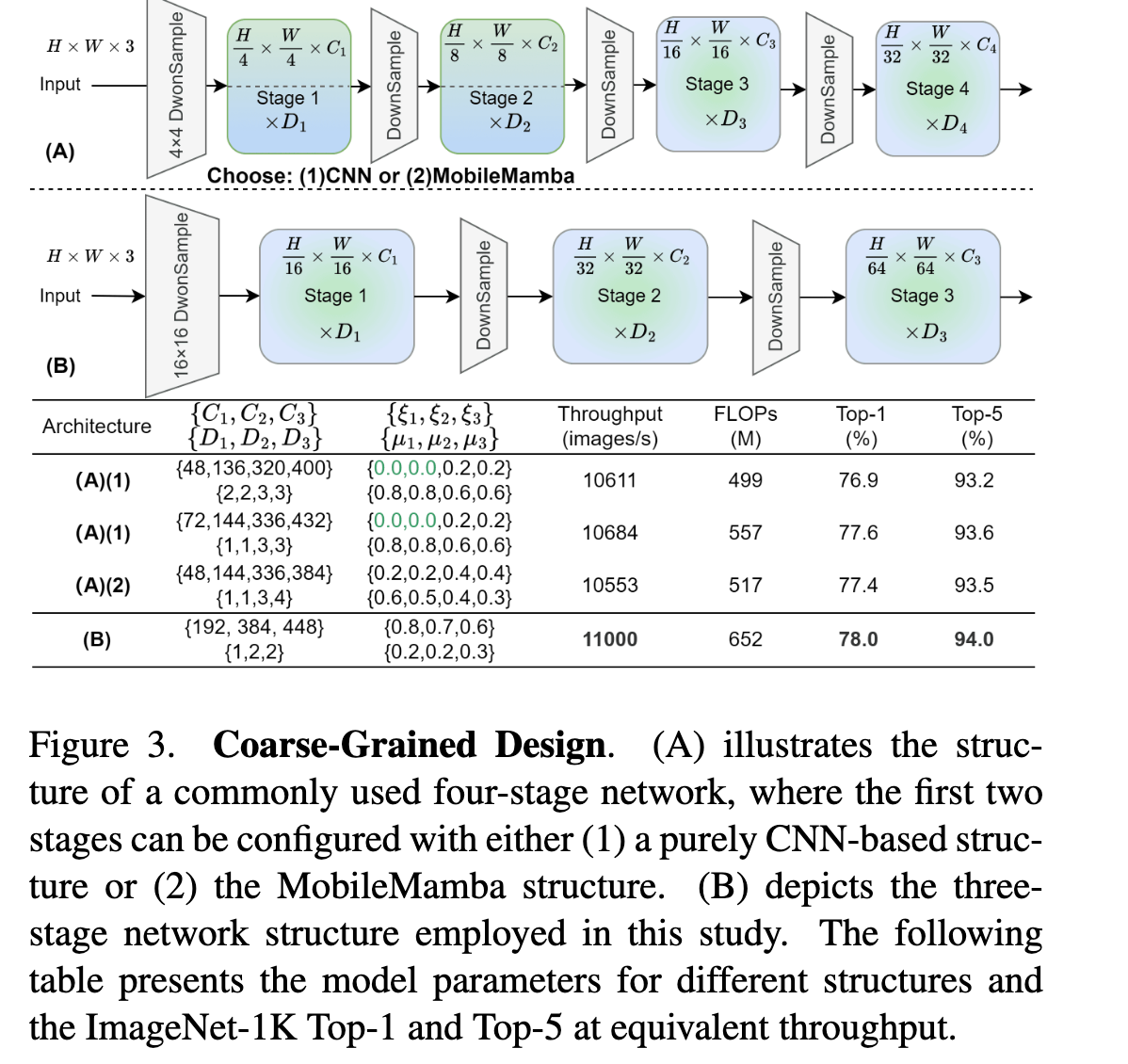
粗粒度:three-stage network
大多数现有网络遵循四阶段框架,但其feature-map size比较大,运算速度缓慢。
论文探讨了三阶段框架和四阶段框架在准确率、速度和FLOPs的表现。经过实验验证,三级网络在相同吞吐量的情况下具备更高的准确率。同样,对于相同的性能,三级网络有更高的吞吐量。因此,作者采用三级网络作为Coarse-Grained framework.
细粒度
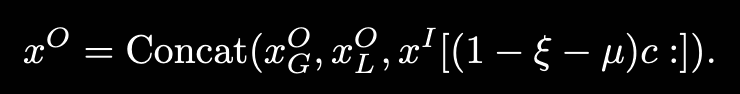
- 多感受野特征交互 Multi-Receptive Field Feature Interaction (MRFFI)
- 多核深度卷积 Multi-Kernel Depthwise Convolution (MKDeConv)
- 冗余恒等映射 Eliminate redundant Identity mapping
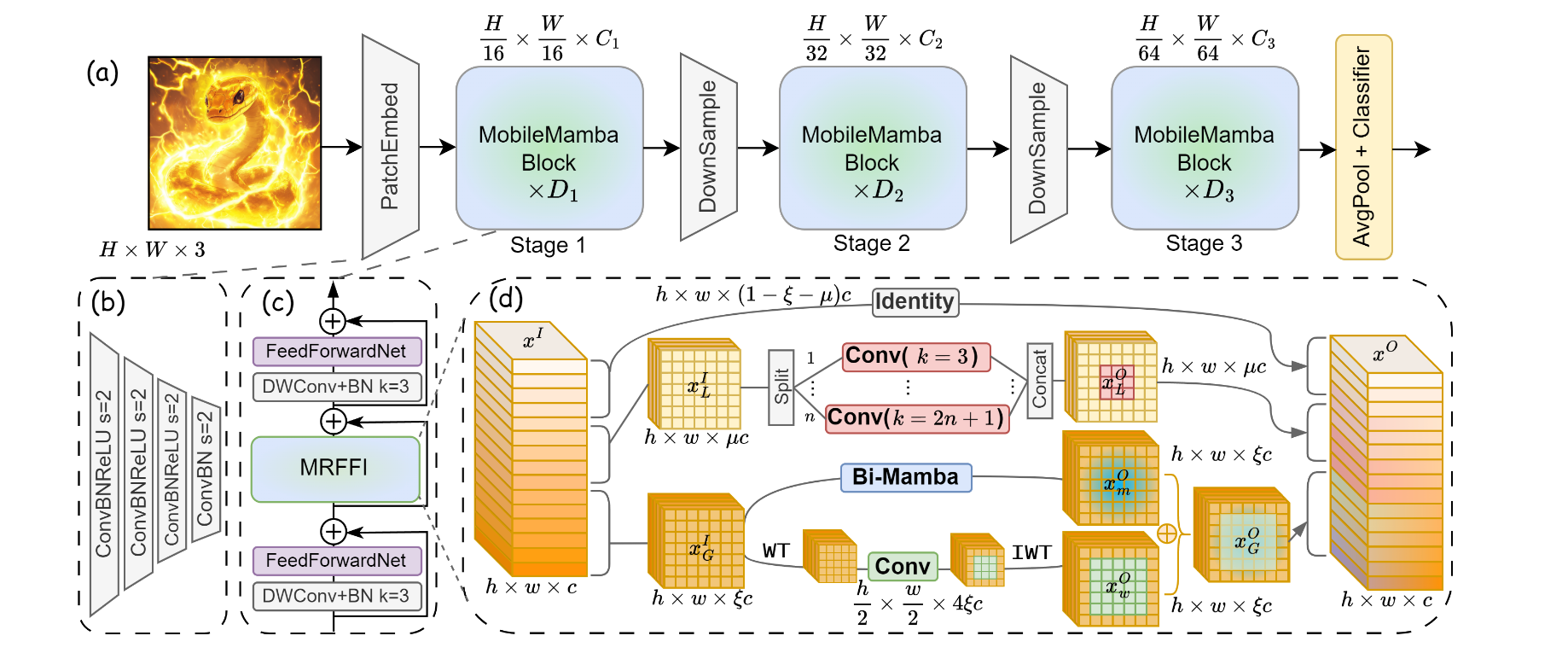
** 通道筛选**
Long-range WTE-Mamba:

- Bi-Mamba
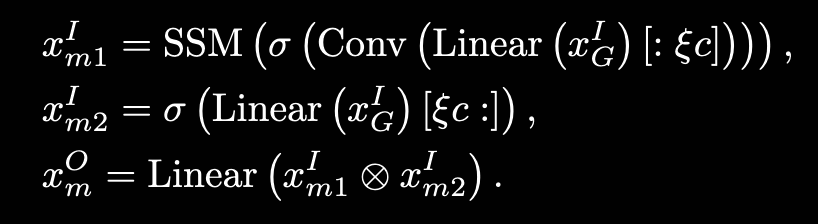
- 通过做Haar小波变换得到WT特征图,对WT特征图做特征提取
:::info
WT特征图:Also, the convolution operations [12] on the WT feature maps have a larger ERF compared to normal scales and exhibit lower computational complexity.
:::
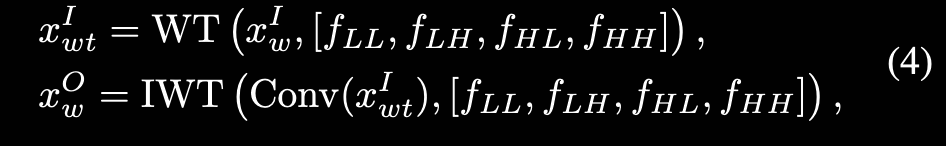
Efficient MK-DeConv:
目标是使用不同的感受野提取局部信息。
在做法上,首先从通道维度再次切分数据:
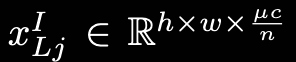
然后将切分后的数据分别用对应的卷积核做卷机:
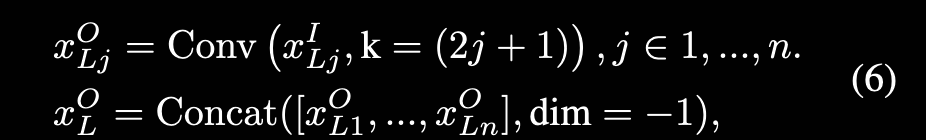
Eliminate redundant Identity:
目标是减少特征冗余,方法是直接做恒等映射。
class MobileMambaModule(torch.nn.Module):
def __init__(self, dim, global_ratio=0.25, local_ratio=0.25,
kernels=3, ssm_ratio=1, forward_type="v052d",):
super().__init__()
self.dim = dim
self.global_channels = nearest_multiple_of_16(int(global_ratio * dim))
if self.global_channels + int(local_ratio * dim) > dim:
self.local_channels = dim - self.global_channels
else:
self.local_channels = int(local_ratio * dim)
self.identity_channels = self.dim - self.global_channels - self.local_channels
if self.local_channels != 0:
self.local_op = DWConv2d_BN_ReLU(self.local_channels, self.local_channels, kernels)
else:
self.local_op = nn.Identity()
if self.global_channels != 0:
self.global_op = MBWTConv2d(self.global_channels, self.global_channels, kernels, wt_levels=1, ssm_ratio=ssm_ratio, forward_type=forward_type,)
else:
self.global_op = nn.Identity()
self.proj = torch.nn.Sequential(torch.nn.ReLU(), Conv2d_BN(
dim, dim, bn_weight_init=0,))
def forward(self, x): # x (B,C,H,W)
x1, x2, x3 = torch.split(x, [self.global_channels, self.local_channels, self.identity_channels], dim=1)
x1 = self.global_op(x1)
x2 = self.local_op(x2)
x = self.proj(torch.cat([x1, x2, x3], dim=1))
return x
训练和推理策略
训练策略:
- 知识蒸馏:使用TResNet-L模型作为教师模型
- 把epochs设置成1000
推理策略:
归一化层融合:将批归一化的计算合并到前一层的卷积或全连接层中,以减少计算量

实验
图像分类:
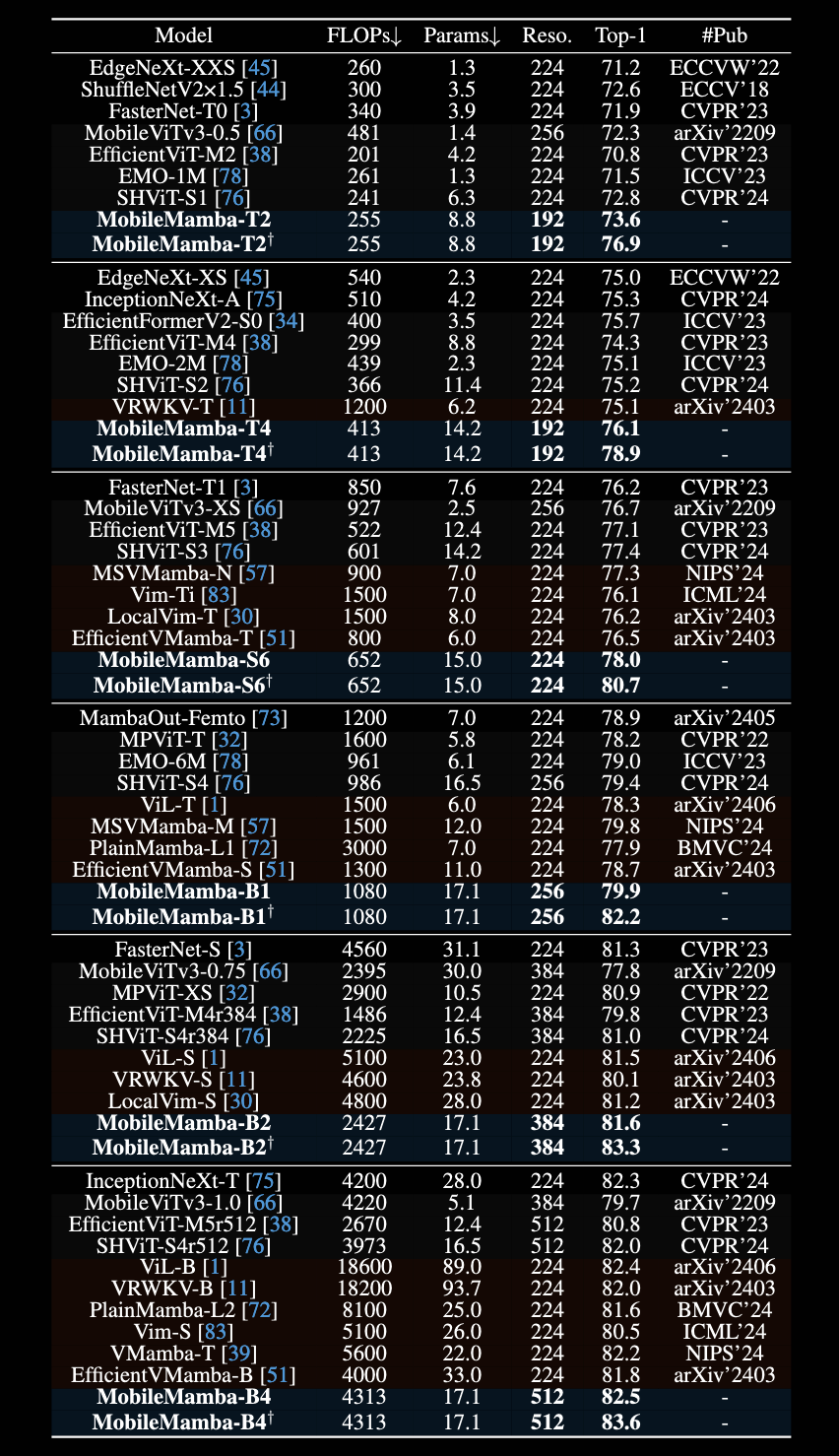
物体检测:
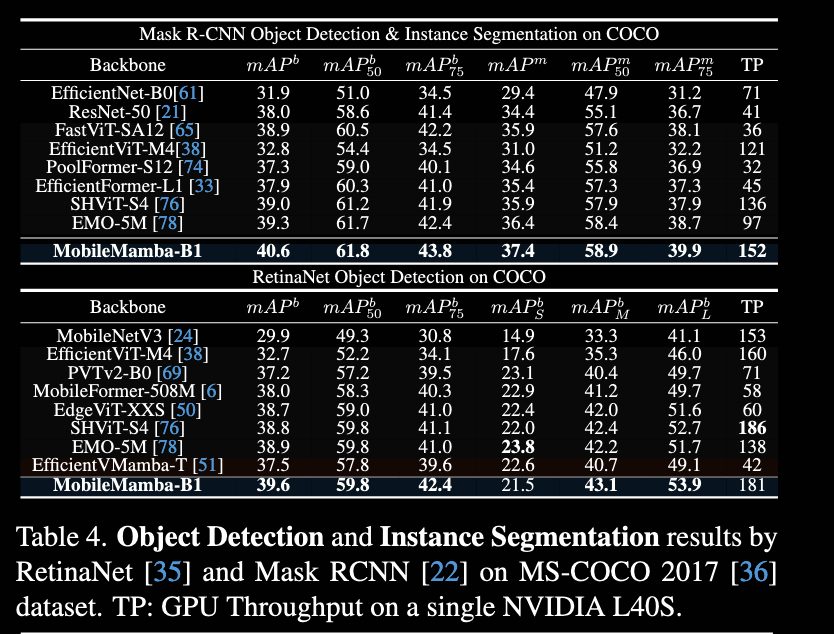
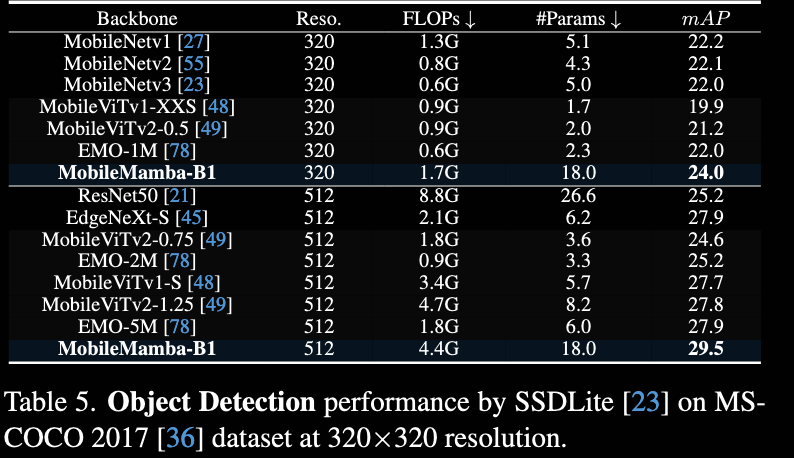
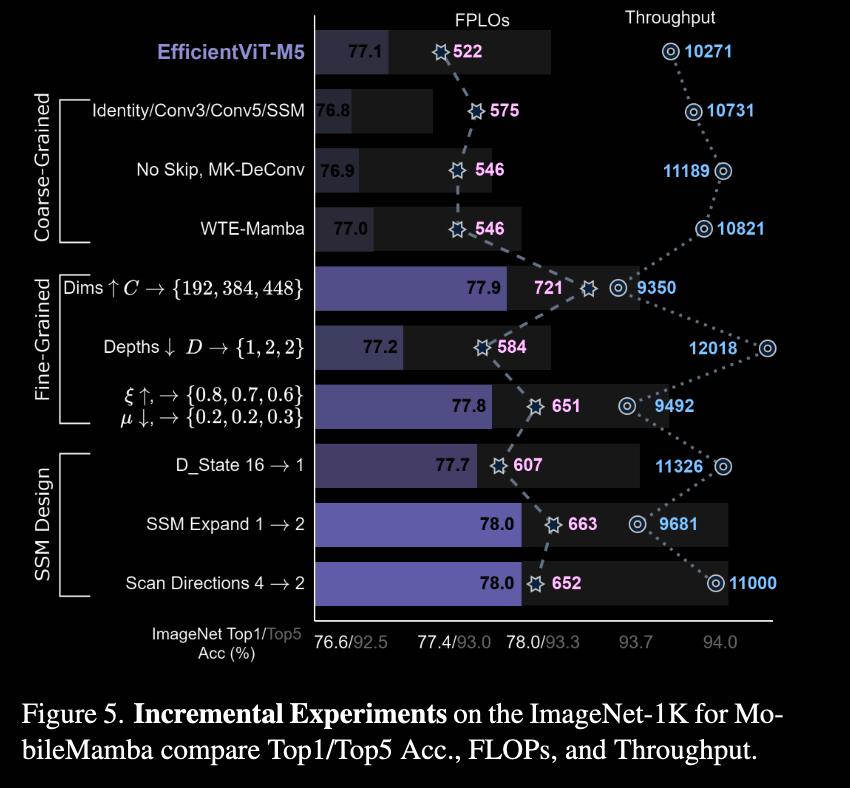
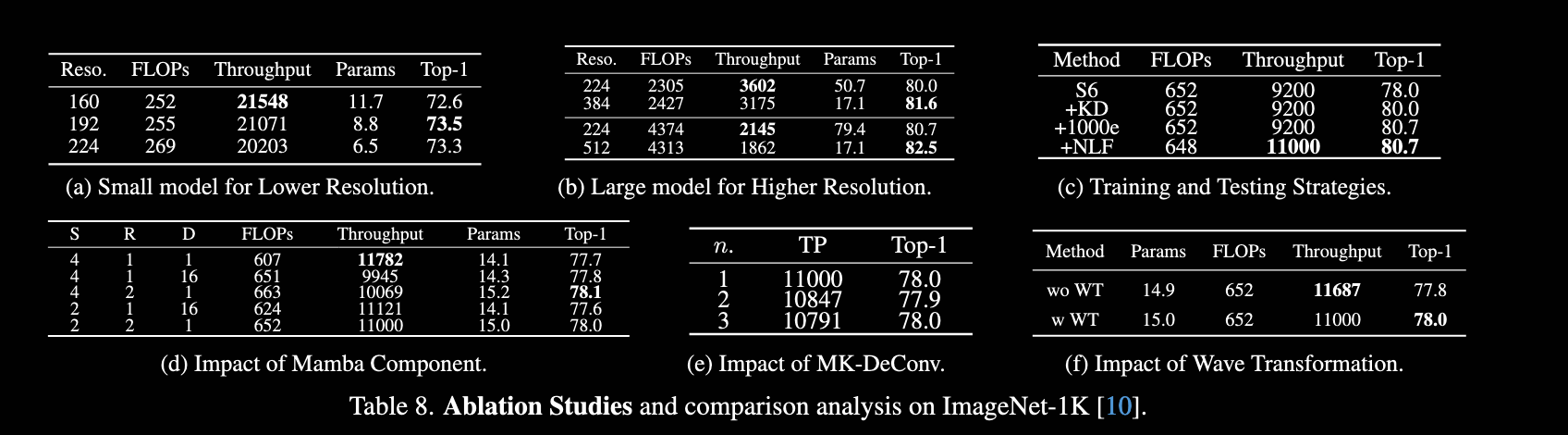
消融实验:
论文十问
- 论文试图解决一个什么问题: 计算机视觉领域的轻量化深度学习模型研究。
- 这是否是一个新的问题:不是,之前已经有许多基于CNN、transformer、SSG的轻量化的工作。
- 这篇文章需要验证一个什么样的科学假设:使用基于mamba的轻量化模型能够取得超过基于CNN和transformer轻量化模型的性能
- **有哪些相关研究,如何归类,谁是在这一课题值得关注的研究员:**MobileNets,GhostNets,EfficientViT,EfficientVMamba,LocalVim等。根据基于等模型可以分为基于CNN的、基于Transformer的和基于SSG的。在这一领域值得关注的研究员有:Andrew G.Howard, Han Cai, Terry Pei 等
- 论文提到的解决方法关键之处是什么:三级网络架构,从减少通道数的角度去减少计算量
- 论文的实验如何设计:论文在图像分类任务,目标检测和语义分割任务等多个任务对比了 MobileMamba 和其他模型等性能差距。除了关注准确率,还重点关注FLOPs和输入分辨率以及模型吞吐量等反应模型推理速度的指标。在消融实验中,该论文还对比了随着模块的提升,模型在GPU上的推理速度的变化。
- 用于定量评估的数据集是什么,有没有开源代码:代码:https://github.com/lewandofskee/MobileMamba,使用的数据集:ImageNet-1K (图像分类)和MS-COCO 2017(目标检测),COCO(实例分段),ADE20K(语意分割)
- 论文的实验及结果有没有很好的支持需要验证的科学假设:基本上能够支持其所有假设。但是在MK-DeConv部分**,**实验表明不去做多内核的卷积反而性能更好。以及WT的使用似乎效果不是很明显。
- 这篇论文到底有什么贡献:基于mamba的轻量化模型有推理速度慢或者准确率不高的缺陷,且这些模型在性能上都落后于基于CNN和基于Transformer的模型。这篇论文提出的基于三级网络架构和多感知野特征交互的轻量级mamba模型能够在性能和效率之间实现良好的平衡
- 下一步有什么工作可以深入:一是这篇论文在通道选择上感觉比较随意,二是并没有对mamba做改进,没有做结合硬件相关的提升等。

















 596
596

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









