









YOLOv8 是 YOLO 系列目标检测模型的最新版本,由 Ultralytics 团队发布。YOLOv8 继续继承了 YOLO 系列的优势,并在性能、训练效率、模型设计、易用性等多个方面进行了改进,成为一个更加高效和强大的目标检测模型。
YOLOv8 的改进
从 网络结构 和 正样本选择 这两个角度来看,YOLOv8 相较于前几代 YOLO 模型在目标检测任务中进行了重要的改进和优化。我们将分别从这两个方面分析 YOLOv8 如何提升其目标检测性能。
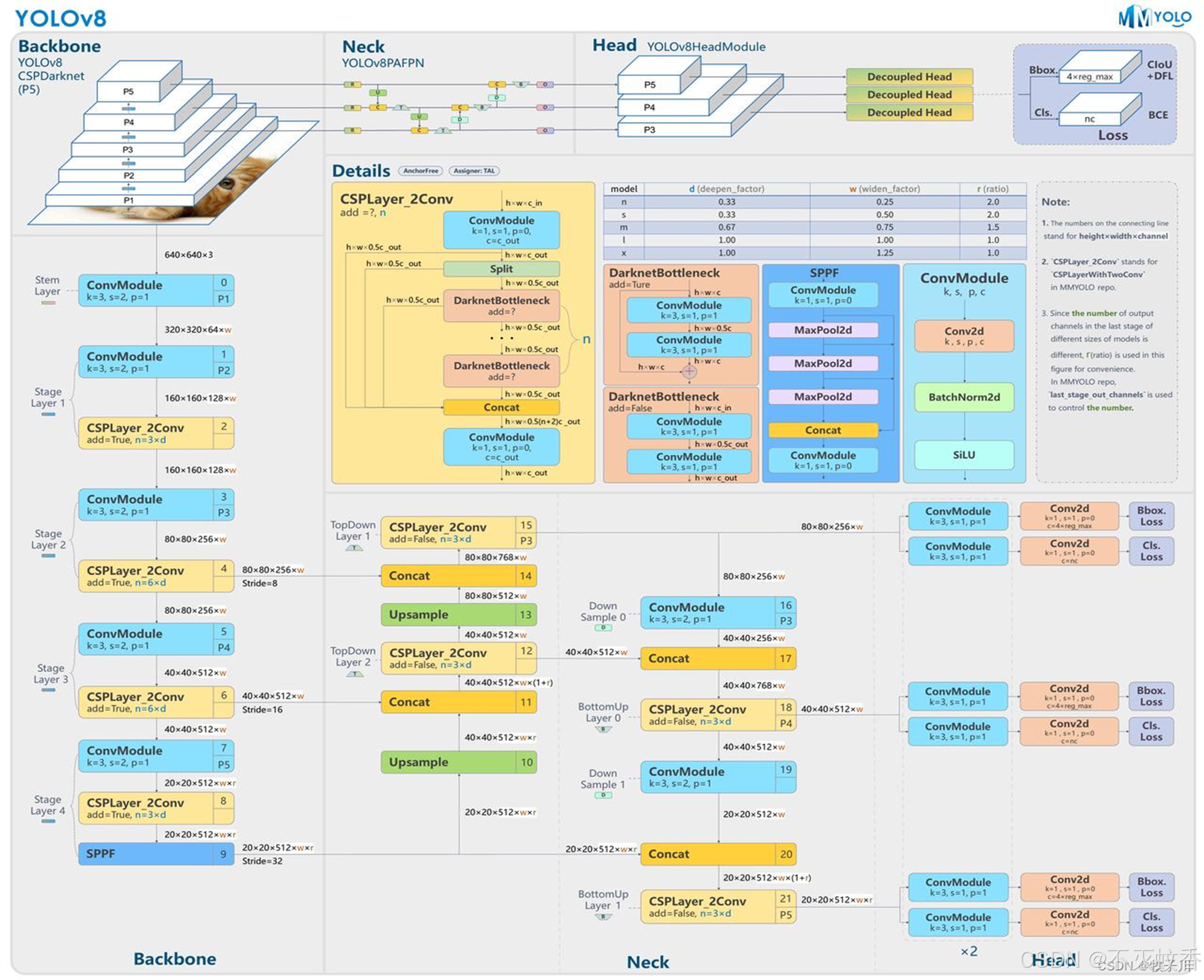
1. 网络结构的改进
YOLOv8 延续了 YOLO 系列的基础架构——单阶段检测(single-stage detection),但对网络结构进行了多方面的优化,以进一步提高检测精度和推理速度。以下是一些关键的网络结构改进:
a. Backbone 网络优化
- Backbone 网络负责从输入图像中提取特征,YOLOv8 在此部分做了优化,采用了更加高效的特征提取网络。具体来说,YOLOv8 在骨干网络(Backbone)中集成了多种优化方法,如:
- CSPNet(Cross-Stage Partial Network):通过跨阶段部分连接(partial connections),减少计算负担,同时提高了网络的表现能力和特征信息的传递效率。
- Swin Transformer:YOLOv8 引入了基于 Transformer 的网络结构(例如 Swin Transformer),使得网络能够更好地捕捉长距离的依赖关系,提升了对复杂场景(例如遮挡、复杂背景)的处理能力。
b. Neck 网络优化
- YOLOv8 的 Neck 部分通过 PANet(Path Aggregation Network) 和 FPN(Feature Pyramid Network) 进行多层次特征融合,增强了多尺度目标的检测能力。不同尺度的特征会通过加权连接以得到更好的目标定位和分类结果,尤其对小物体检测有显著提升。
c. Head 网络改进
- Head 网络是最终预测目标的位置和类别的部分,YOLOv8 在 Head 部分进行了一些轻量化设计,增强了对小物体、密集目标的检测能力。同时,YOLOv8 在预测时使用了 自适应锚框(Anchor-free)技术,使得预测结果更加精准,减少了传统锚框方法中可能出现的误差。
d. 新型激活函数与卷积
- YOLOv8 引入了更加高效的激活函数,例如 SiLU(Sigmoid Linear Unit)和 Mish,这些激活函数相较于传统的 ReLU 函数具有更好的梯度传递特性,尤其在深度网络中可以加速训练过程。
- 采用了更加高效的 深度可分离卷积(depthwise separable convolutions),减少了模型的参数量和计算复杂度,进一步提高了检测速度。
e. 轻量化与优化版本
- YOLOv8 提供了多个变种,例如 YOLOv8-tiny 和 YOLOv8-slim,这些轻量化版本适用于计算能力较弱的边缘设备、嵌入式系统等,同时仍然能够保持较高的精度。
2. 正样本选择的改进
正样本选择(即正负样本的标注和选择)在目标检测中扮演着至关重要的角色,它直接影响到训练的效果和模型的泛化能力。YOLOv8 在正样本选择上进行了一些创新和优化,解决了传统方法中存在的一些问题,提升了检测性能。
a. Anchor-free 方法
- 在过去的 YOLO 系列(如 YOLOv4 和 YOLOv5)中,目标检测模型依赖于 Anchor-based 方法来选择正样本。这些锚框(Anchor)是预定义的形状和尺寸,通过与真实目标框(Ground Truth)进行匹配来决定正负样本。
- 然而,Anchor-based 方法在处理多样化目标时容易产生锚框失配,特别是对于形状和大小变化大的目标。
- YOLOv8 采用了 Anchor-free 方法,直接预测目标的 中心点 和 尺寸,而不是依赖固定的锚框,这解决了锚框匹配问题,减少了模型的复杂性,并提高了对小物体的检测精度。
b. IoU (Intersection over Union) 匹配策略
- 在传统目标检测中,正样本通常是通过 IoU(交并比)与目标框进行匹配的。IoU 越大,匹配的可能性就越高。YOLOv8 优化了 IoU 匹配策略,改进了 正负样本的选择,尤其是在检测小物体和远距离目标时,能够更加准确地匹配。
- YOLOv8 采用了 IoU-aware(IoU感知)的方法,使得模型能够根据目标框的 IoU 自适应地调整学习策略,减少了样本的标记偏差,提升了正样本的选择精度。
c. Hard Negative Mining(困难负样本挖掘)
- 在训练过程中,负样本(即没有目标的区域)通常占据了大部分的数据,但只有一小部分负样本会对模型的学习产生很大影响。YOLOv8 引入了 Hard Negative Mining 技术,自动选择难以分类的负样本进行训练。这样可以帮助模型更好地区分目标与背景,提升目标检测精度。
- 这种方法通过自动选择难负样本(即模型容易错误分类的样本),使得训练过程更加高效,避免了背景样本占据过多训练时间。
d. Focal Loss 与 Label Smoothing
- YOLOv8 使用了 Focal Loss,这是一种针对 类别不平衡问题 的损失函数。Focal Loss 通过降低易分类样本的损失权重,重点加强对难分类样本(尤其是正样本)的训练,从而帮助模型更好地学习少数类别。
- 另外,YOLOv8 在训练中使用了 Label Smoothing 技术,这可以帮助缓解过拟合问题,使得模型在训练过程中更加鲁棒。
3. 总结
从 网络结构 和 正样本选择 角度来看,YOLOv8 在多个方面进行了改进,确保了它在目标检测任务中的高效性和准确性。
- 网络结构的优化 提供了更高的性能,特别是在特征提取、特征融合和预测方面。
- 正样本选择 的优化,尤其是 Anchor-free 方法 和 IoU-aware 策略,让模型能够更好地适应多变的目标形态和尺寸。
- 困难负样本挖掘 和 Focal Loss 等技术,帮助模型在复杂背景中提高检测精度,减少误报和漏报。
通过这些优化,YOLOv8 在速度、精度、模型复杂度和训练效率上达到了新的平衡,成为目标检测领域中更加可靠和高效的解决方案。
YOLOv8 的特点与创新
-
增强的模型架构
YOLOv8 在基础架构上做了进一步优化,提供了不同的模型变体,适应不同的任务需求和硬件平台。相比于 YOLOv7,YOLOv8 在准确度、推理速度和模型大小之间的平衡做得更好。 -
高效的推理与训练性能
YOLOv8 针对推理和训练的效率进行了优化,模型变得更加高效,尤其是在小型设备和边缘计算设备上的推理速度更快。同时,训练过程更加稳定,能够在较短时间内达到较高的精度。 -
统一的框架与API
YOLOv8 提供了更加简洁和一致的 API,简化了模型的训练和推理过程。用户可以通过简单的命令行接口进行模型的训练和推理,无需过多的配置。 -
自动超参数调整
YOLOv8 提供了 自动超参数调整(Auto Hyperparameter Tuning)的功能,这使得用户可以通过自动化的方式选择最佳的超参数组合,从而提升训练效率和模型表现。 -
增强的目标检测能力
YOLOv8 通过创新的 Backbone 和 Neck 设计,增强了对多尺度物体和小物体的检测能力。尤其在 小物体检测 和 密集目标检测 方面表现得更为优秀。 -
兼容 ONNX 与 TensorRT
YOLOv8 支持将模型导出为 ONNX 格式,可以在多种推理平台(如 TensorRT)上进行高效推理。对于需要高性能推理的场景,YOLOv8 可以通过 TensorRT 提升推理速度,适用于 GPU 加速的工业应用。 -
集成了数据增强和剪枝技术
YOLOv8 在训练中集成了 数据增强 技术,比如 Mosaic、Mixup 等,同时也支持 网络剪枝,使得模型能够更好地适应训练数据,提升泛化能力,并能够在部署时减少模型的计算量。 -
增强的跨平台支持
YOLOv8 在多个平台上表现出色,能够在 CPU、GPU 以及 移动端 等平台上高效运行,适用于各种嵌入式和边缘设备。 -
轻量化与可扩展性
YOLOv8 提供了多种 轻量级版本(例如 YOLOv8-Tiny),特别适用于嵌入式设备和边缘计算设备。这些轻量化版本在保持较高精度的同时,显著降低了模型的计算需求。
YOLOv8 的安装与使用
YOLOv8 提供了与 YOLOv5 类似的简易安装和使用方式。以下是一些常用的安装与使用步骤。
1. 安装 YOLOv8
YOLOv8 通过 PyPI 发布,可以通过 pip 安装:
pip install ultralytics2. 训练 YOLOv8 模型
使用 YOLOv8 进行训练是非常简单的,用户只需通过命令行工具指定训练集和配置文件。以下是一个示例命令:
yolo train data=coco.yaml model=yolov8n.pt epochs=100data:数据集配置文件路径(例如 COCO 数据集)。model:使用的预训练模型(例如 yolov8n.pt 表示 YOLOv8 的轻量版本)。epochs:训练的轮数。
3. 推理(推断)使用 YOLOv8
训练完成后,用户可以使用训练好的模型进行推理。以下是一个简单的推理命令:
yolo predict model=yolov8n.pt source=images/model:训练好的模型路径。source:推理的图像或视频文件夹。
4. 导出模型为 ONNX 格式
YOLOv8 支持将模型导出为 ONNX 格式,方便在其他平台上进行推理优化:
yolo export model=yolov8n.pt format=onnx5. YOLOv8 的轻量化版本(YOLOv8 Tiny)
YOLOv8 提供了多个不同大小的模型,包括轻量级的 YOLOv8-Tiny 版本,适合低功耗设备或嵌入式应用。可以像下面这样进行推理:
yolo predict model=yolov8-tiny.pt source=images/YOLOv8 的优势
-
提高的速度与精度:YOLOv8 进一步提升了推理速度和精度,特别是在小物体检测和多任务学习的场景下,比前版本更具优势。
-
简化的使用体验:YOLOv8 提供了更加简单的 API 和命令行工具,使得训练、推理和模型导出变得更加轻松,适合快速原型开发和部署。
-
增强的兼容性:YOLOv8 支持多种推理平台,包括 TensorRT、ONNX、OpenVINO 等,可以在不同硬件平台上运行。
-
适应广泛的应用场景:YOLOv8 可以广泛应用于自动驾驶、安防监控、工业检测、智能零售等领域,同时也可以应用于边缘设备和移动设备。
YOLOv8 在实际应用中的表现
-
自动驾驶:YOLOv8 能够在自动驾驶系统中进行实时物体检测,识别道路上的车辆、行人、交通标志等,提供准确的视觉感知。
-
智能安防:YOLOv8 可用于视频监控中的实时目标检测,能够快速检测入侵行为、人脸识别等,提高安防效率。
-
工业检测:YOLOv8 可以应用于生产线上的产品质量检测,能够自动检测产品缺陷、标记不合格品,从而提高生产效率和质量。
-
无人机监控:YOLOv8 可以在无人机上进行目标检测,实时检测地面物体,如森林火灾、交通事故等。
-
智能机器人:在机器人视觉感知中,YOLOv8 能够识别目标并进行操作,如自动化仓储和产品分拣。
总结
YOLOv8 是一个高度优化的目标检测模型,继承了 YOLO 系列的高效设计,并在精度、速度、易用性、硬件适配等方面做了显著改进。它不仅适用于高性能计算平台,也能在嵌入式设备和边缘计算设备上运行,为各种实时视觉应用提供了强大的支持。
在未来,YOLOv8 无疑将成为更多领域(如自动驾驶、工业检测、安防监控等)中的标准视觉检测模型,特别是在对实时性和精度要求较高的场景中,YOLOv8 的优势更加突出。


















 3395
3395

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









