










深入探索多头注意力机制:深度学习的关键创新
在近年来的自然语言处理(NLP)和其他序列模型任务中,多头注意力机制已成为一项关键的技术。它首次在2017年的论文《Attention is All You Need》中被提出,此论文同时引入了Transformer模型,该模型和它的变体如BERT和GPT系列已经彻底改变了NLP的领域。本篇博客将详尽地探讨多头注意力机制的起源、工作原理、结构以及它的核心数学公式,帮助读者全面理解这一技术的强大功能和广泛应用。
多头注意力机制的起源
多头注意力机制最早由Google的研究团队在2017年发表的论文《Attention is All You Need》中提出。这一机制是为了解决自注意力(Self-Attention)在处理序列时可能忽视的信息冗余问题。通过并行地使用多个注意力“头”,多头注意力机制能够让模型在不同的子空间中学习到数据的不同表示,从而捕获信息的多个方面。
多头注意力机制的工作原理
基本概念
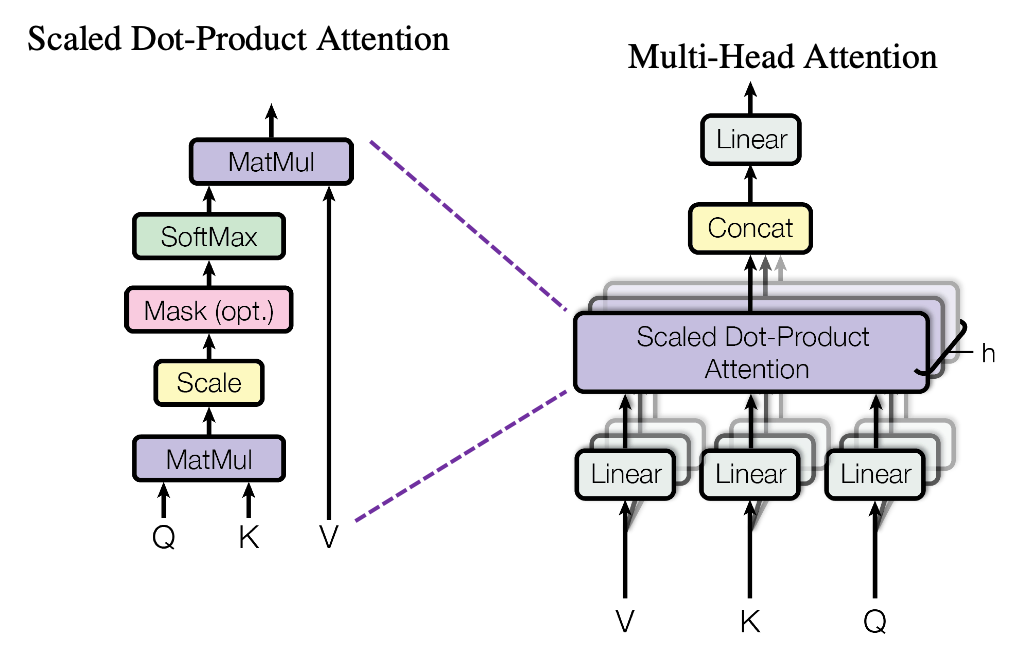
多头注意力机制的核心思想是将注意力层分裂成多个头(head),每个头独立地进行学习和输出,然后将这些输出合并。这种结构允许模型在不同的表示子空间中并行捕捉信息,增强了模型的学习能力。
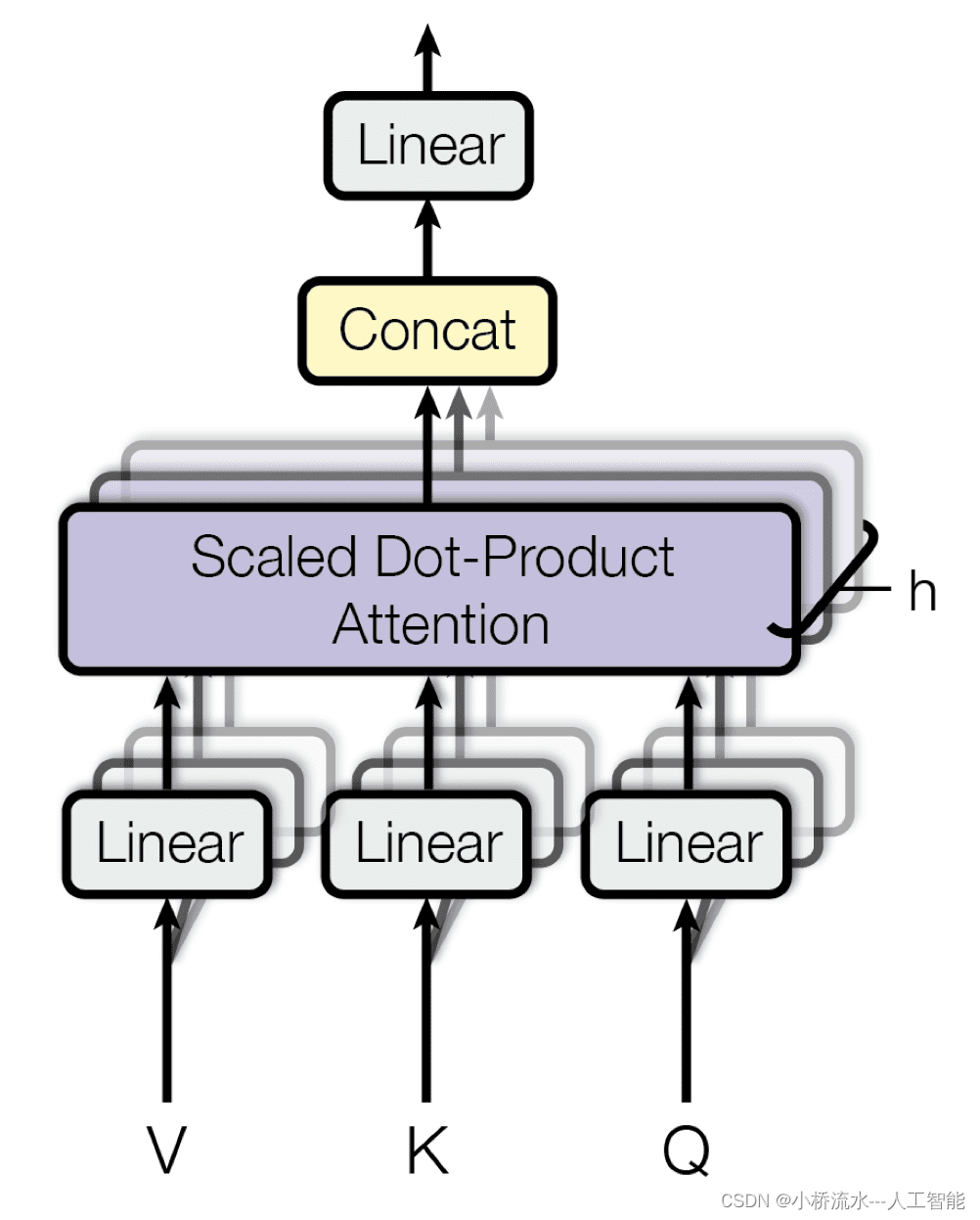
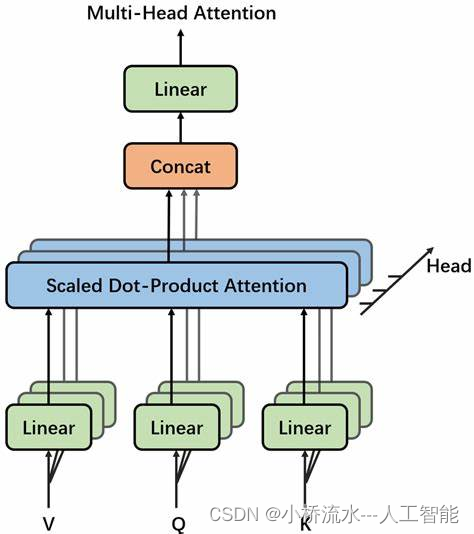
结构细节
在多头注意力机制中,输入首先通过线性变换生成对应每个头的查询(Query)、键(Key)和值(Value)向量。然后,每个头独立地计算注意力得分和加权的输出。最后,所有头的输出被拼接并再次线性变换,以生成最终的输出。
公式表达
假设输入 ( X ) 经过线性变换得到每个头的查询 ( Q )、键 ( K ) 和值 ( V ):
Q i = X W i Q , K i = X W i K , V i = X W i V Q_i = XW_i^Q, \quad K_i = XW_i^K, \quad V_i = XW_i^V Qi=XWiQ,Ki=XWiK,Vi=XWiV
其中 W i Q W_i^Q WiQ, W i K W_i^K WiK, W i V W_i^V WiV 是可学习的权重矩阵,下标 ( i ) 表示第 ( i ) 个头。
每个头的注意力输出 h e a d i head_i headi 通过以下公式计算:
h e a d i = Attention ( Q i , K i , V i ) = softmax ( Q i K i T d k ) V i head_i = \text{Attention}(Q_i, K_i, V_i) = \text{softmax}\left(\frac{Q_iK_i^T}{\sqrt{d_k}}\right)V_i headi=Attention(Qi,Ki,Vi)=softmax(dkQiKiT)Vi
其中 d k d_k dk 是键向量的维度。
所有头的输出被拼接 c o n c a t e n a t e concatenate concatenate并通过另一个线性变换得到最终输出:
MultiHead ( Q , K , V ) = Concat ( h e a d 1 , … , h e a d h ) W O \text{MultiHead}(Q, K, V) = \text{Concat}(head_1, \ldots, head_h)W^O MultiHead(Q,K,V)=Concat(head1,…,headh)WO
其中 W O W^O WO 是另一个可学习的权重矩阵,( h ) 是头的总数。
多头注意力机制的应用
多头注意力机制已被广泛应用于许多领域,尤其是在自然语言处理领域。以下是一些显著的应用例子:
- 机器翻译:Transformer模型利用多头注意力在编码器和解码器中捕捉复杂的单词依赖关系,显著提高翻译质量。
- 文本生成:GPT-3等模型使用多头注意力来生成连贯和相关的文本。
- 语音识别:多头注意力机制帮助模型更好地理解语音的上下文信息,提高识别的准确性。

结论
多头注意力机制是深度学习特别是在处理复杂序列任务中的一项创新技术。 它通过并行处理多个表示子空间中的信息,不仅增强了模型的表示能力,也提高了信息处理的效率和效果。

















 7685
7685

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









