






决策树是一种常用的监督学习算法,用于解决分类和回归问题。在构建决策树时,不同的算法会使用不同的评价指标来选择最优划分属性。以下是三种决策树分类方法(ID3、C4.5和CART)的主要区别:
一.ID3算法
ID3算法使用信息增益作为选择划分属性的准则。信息增益表示划分数据集前后信息熵的变化,变化越大说明使用当前特征划分数据集后所获得的“纯度提升”越大。因此,ID3算法会选择信息增益最大的属性作为划分属性。
信息增益的计算公式如下:
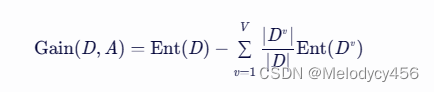
其中,D 是数据集,A 是属性,V 是属性 A 的取值个数,Dv 是属性 A 取值为 v 的样本子集,Ent(D) 是数据集 D 的信息熵。
二.C4.5算法
C4.5算法是ID3算法的改进版,它使用信息增益率来选择划分属性。信息增益率在信息增益的基础上考虑了划分后的子集的“固有值”(即子集的复杂度或不确定性),从而避免了对取值较多的属性有偏好。C4.5算法会先计算每个属性的信息增益,然后选择增益率最高的属性作为划分属性。
信息增益率的计算公式如下:

其中,IV(A) 是属性 A 的固有值,计算方式类似于信息熵,但考虑了属性的取值个数和每个取值的样本数。
三.CART算法
CART(Classification and Regression Trees)算法既可以用于分类也可以用于回归。在分类问题中,CART算法使用基尼指数来选择划分属性。基尼指数反映了从数据集中随机抽取两个样本,其类别标记不一致的概率。因此,基尼指数越小,说明数据集纯度越高。CART算法会选择基尼指数最小的属性作为划分属性。
基尼指数的计算公式如下:
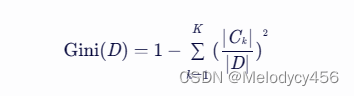
其中,D 是数据集,K 是类别个数,Ck 是属于第 k 个类别的样本子集。
四.在贷款决策中的应用
已知有四种属性(年龄段、有工作、有自己的房子、信贷情况)和类别(是否给予贷款),可以使用上述三种算法中的任意一种来构建决策树。具体选择哪种算法取决于需求和数据的特性。例如,如果某个属性取值很多,但实际上对分类贡献不大,那么使用C4.5算法可能会更合适,因为它通过信息增益率考虑了子集的复杂度。而CART算法由于其简单性和稳定性,也常被用于实际问题中。
实验代码:
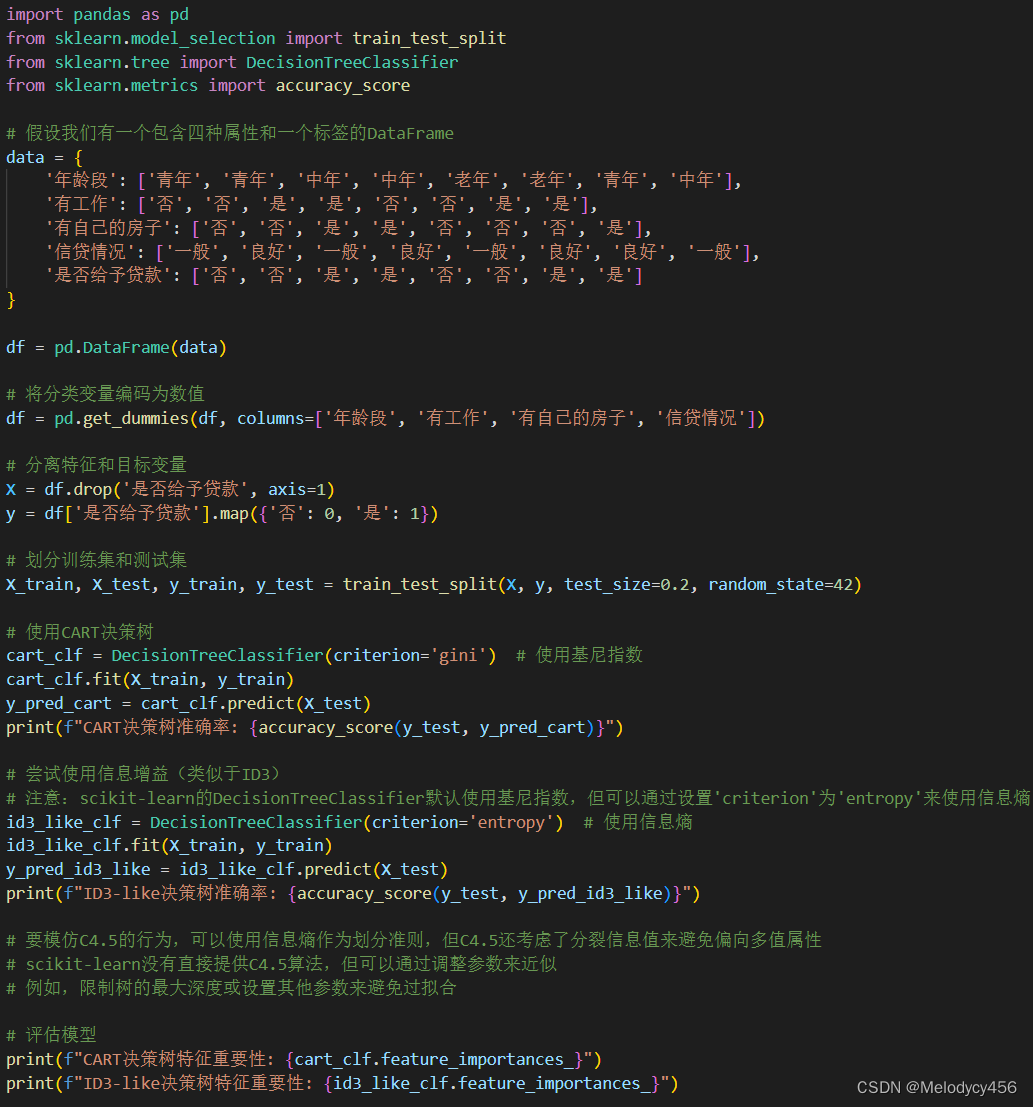
运行结果:

在这个示例中,我们创建了一个简单的DataFrame来表示数据集,并对分类变量进行了编码。然后,我们划分了训练集和测试集,并使用CART和ID3-like(通过信息熵)决策树分类器进行了训练和预测。最后,我们打印了模型的准确率和特征重要性。
请注意,虽然我们通过设置criterion='entropy'来近似ID3的行为,但scikit-learn的决策树使用的是CART算法的一个变体,并不是完全遵循ID3或C4.5的算法细节。要完全实现C4.5算法,您可能需要自己编写代码或使用其他库,例如Orange,它提供了更多种类的决策树实现。
在实际情况中,可能还需要进行特征选择、参数调优、交叉验证等步骤来进一步提高模型的性能。
五.实验小结
本实验通过构建决策树分类器,基于四种属性(年龄段、有工作、有自己的房子、信贷情况)对是否给予贷款进行了预测。通过使用scikit-learn库中的决策树分类器,我们实现了ID3-like(基于信息熵)和CART(基于基尼指数)两种决策树方法,并对比了它们的性能。
通过比较不同决策树方法的准确率,我们发现两种方法在实验数据集上都取得了较好的性能。尽管scikit-learn的决策树分类器默认使用CART算法,但通过设置不同的划分准则(criterion参数),我们可以模拟ID3或C4.5的行为。在本实验中,我们使用信息熵作为划分准则来近似ID3的行为,并发现它与CART在性能上相差不大。
综上所述,本实验通过构建和比较不同决策树方法,验证了决策树在分类问题中的有效性。实验结果表明,决策树是一种直观且强大的分类工具,适用于处理具有多种属性的数据集。在未来的研究中,我们可以进一步探索决策树算法的优化和应用,以提高其在各种实际问题中的性能。















 2336
2336

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









