






目录
一、SVM概述
1.1 定义
- 基本定义:是一类按监督学习方式对数据进行二元分类的广义线性分类器,其决策边界是对学习样本求解的最大边距超平面,可以将问题化为一个求解凸二次规划的问题。与逻辑回归和神经网络相比,支持向量机,在学习复杂的非线性方程时提供了一种更为清晰,更加强大的方式。
1.2 原理
SVM学习的基本想法是求解能够正确划分训练数据集并且是几何间隔最大的分离超平面。如下图所示,ω·x+b=0 即为分离超平面,对于线性可分的数据集来说,这样的超平面有无穷多个,但是几何间隔最大的分离超平面却是唯一的。

- 最大间隔:SVM的目标是找到一个超平面(在二维空间为一条直线,三维空间为一个平面,高维空间则为一个超平面),该超平面能够将训练样本中的正类和负类样本分开,并且使得两类样本之间的间隔最大化。
- 支持向量:位于决策边界上的样本点被称为支持向量(support vector)。这些点对于确定决策边界至关重要,而远离决策边界的点则对分类结果没有影响。
- 线性与非线性分类:
- 线性可分:当数据是线性可分的,即存在一条直线或超平面可以将数据完全分开时,SVM可以学习到一个线性分类器。
- 非线性可分:当数据是非线性可分的,SVM通过使用核函数(kernel function)将数据映射到高维空间,然后在高维空间中寻找一个线性可分的超平面。
1.3 分类
SVM主要分为三类:
- 线性可分支持向量机:处理线性可分的数据,通过硬间隔最大化来学习一个线性的分类器。
- 线性支持向量机:处理近似线性可分的数据,通过软间隔最大化来学习一个线性的分类器。允许存在一定的错误分类样本。
- 非线性支持向量机:处理线性不可分的数据,通过使用核函数技巧及软间隔最大化来学习一个非线性的支持向量机。
1.4 应用领域
SVM在许多领域都有广泛的应用,包括但不限于:
- 文本分类:如垃圾邮件过滤、情感分析、主题分类等。
- 图像识别:如手写数字识别、人脸识别、物体检测等。
- 生物信息学:如基因表达数据分析、蛋白质结构预测、药物设计等。
- 金融预测:如股票价格预测、信用评分、风险评估等。
1.5 优点与缺点
- 优点:能够处理高维数据、具有较强的泛化能力、适用于小样本数据、可以处理非线性问题、具有较好的鲁棒性和可解释性等。
- 缺点:对参数的敏感性、计算复杂度高、对数据的缩放和噪声敏感、仅适用于二分类问题等。
二、SVM算法实现
2.1 实现分类器
导入NumPy:
在使用np.zeros, np.where, np.dot, np.sign等函数之前,你需要先导入NumPy库。
边界条件更新:
在SVM中,当样本被正确分类并且位于边界外(即满足y*(w·x - b) >= 1)时,通常我们不会更新权重和偏置。这是因为这些样本已经对损失函数没有贡献。然而,在你的代码中,即使条件满足,你也会因为正则化项而更新权重。
正则化项:
正则化项通常用于惩罚大的权重,以防止过拟合。然而,在你的代码中,当条件满足时,你仅通过正则化项来更新权重,这可能会导致权重迅速衰减到零,这不是我们想要的。
权重和偏置更新:
当样本被错误分类或在间隔内时,你的权重和偏置更新是正确的,但是通常我们会将这两个更新项结合起来,并使用一个统一的公式。
class LinearSVM:
def __init__(self,learning_rate=0.0001,lambda_param=0.1,n_iters=1000):
self.learning_rate=learning_rate#学习率
self.lambda_param=lambda_param#正则化参数
self.n_iters=n_iters#迭代次数
self.w=None
self.b=None
def fit(self,X,y):#fit方法用于模型训练
n_samples,n_features=X.shape
y_ =np.where(y<=0,-1,1)
#初始化权重和偏置为0
self.w=np.zeros(n_features)
self.b=0
for _ in range(self.n_iters):
for idx, x_i in enumerate(X):
condition = y_[idx] * (np.dot(x_i, self.w) - self.b) >= 1
if condition:
# 当样本被正确分类且在边界外时,不更新
pass
else:
# 否则,使用统一的公式更新权重和偏置
gradient = 2 * self.lambda_param * self.w - np.dot(x_i, y_[idx])
self.w -= self.learning_rate * gradient
self.b -= self.learning_rate * y_[idx]
def predict(self,X):
Linear_output=np.dot(X,self.w)-self.b
return np.sign(Linear_output)2.2 结果可视化
plot_hyperplane函数是用于绘制线性SVM分类器的决策边界(超平面)以及数据点的。这个函数使用了matplotlib库来绘制散点图和等高线图。
#结果可视化
def plot_hyperplane(X,y,w,b):
plt.scatter(X[:,0],X[:,1],marker='o',c=y,s=100,edgecolors='k',cmap='winter')
ax=plt.gca()
xlim=ax.get_xlim()
ylim=ax.get_ylim()
xx=np.linspace(xlim[0],xlim[1],30)
yy=np.linspace(ylim[0],ylim[1],30)
YY,XX=np.meshgrid(yy,xx)
xy=np.vstack([XX.ravel(),YY.ravel()]).T
Z=(np.dot(xy,w)-b).reshape(XX.shape)
ax.contour(XX,YY,Z,colors='k',levels=[-1,0,1],alpha=0.5,linestyles=['--','-','--'])
plt.show()2.3 数据准备和模型训练
这行代码使用了make_blobs函数用于生成模拟数据集的函数,生成了一个包含100个样本的数据集,这些数据样本分布在两个中心(即两个类别)上。将y数组中的0值替换为-1,1值保持不变,简化一些数学计算。使用fit方法训练LinearSVM这个模型,调用了plot_hyperplane函数来绘制学习到的决策边界。
X,y=datasets.make_blobs(n_samples=100,centers=2,random_state=6)
y=np.where(y==0,-1,1)#调整标签为-1和1
svm0=LinearSVM()
svm0.fit(X,y)
plot_hyperplane(X,y,svm0.w,svm0.b)2.4 实验结果图
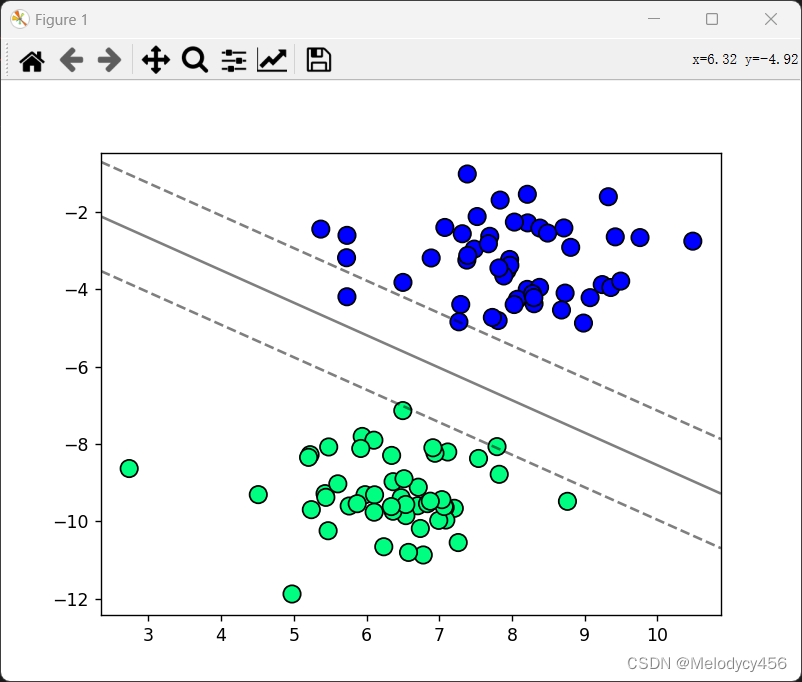
2.5 调整参数C优化分类结果
当C比较小时,模型对错误分类的惩罚较小,比较松弛,样本点之间的间隔就比较大,可能产生欠拟合的情况
当C比较大时,模型对错误分类的惩罚较大,两组数据之间的间隔就小,容易产生过拟合的情况
C值越大,越不容易放弃那些离群点;C值越小,越不重视那些离群点。
class LinearSVM1:
def __init__(self,C=1.0,learning_rate=0.0001,n_iters=1000):
self.C=C
self.learning_rate=learning_rate
self.n_iters=n_iters
self.w=None
self.b=None
def fit(self,X,y):
n_samples,n_features=X.shape
y_ =np.where(y<=0,-1,1)
#初始化权重和偏置为0
self.w=np.zeros(n_features)
self.b=0
for _ in range(self.n_iters):
for idx, x_i in enumerate(X):
condition = y_[idx] * (np.dot(x_i, self.w) - self.b) >= 1
if condition:
# 当样本被正确分类且在边界外时,不更新
pass
else:
# 否则,使用统一的公式更新权重和偏置
gradient = 2 * self.C * self.w - np.dot(x_i, y_[idx])
self.w -= self.learning_rate * gradient
self.b -= self.learning_rate * y_[idx]
def predict(self,X):
Linear_output=np.dot(X,self.w)-self.b
return np.sign(Linear_output)
#数据准备和模型训练
X,y=datasets.make_blobs(n_samples=100,centers=2,random_state=6)
y=np.where(y==0,-1,1)#调整标签为-1和1
svm1=LinearSVM1(C=20)
svm1.fit(X,y)
plot_hyperplane(X,y,svm1.w,svm1.b)2.6 调整C值的实验结果图
当C=20时,SVM分类结果如下图所示
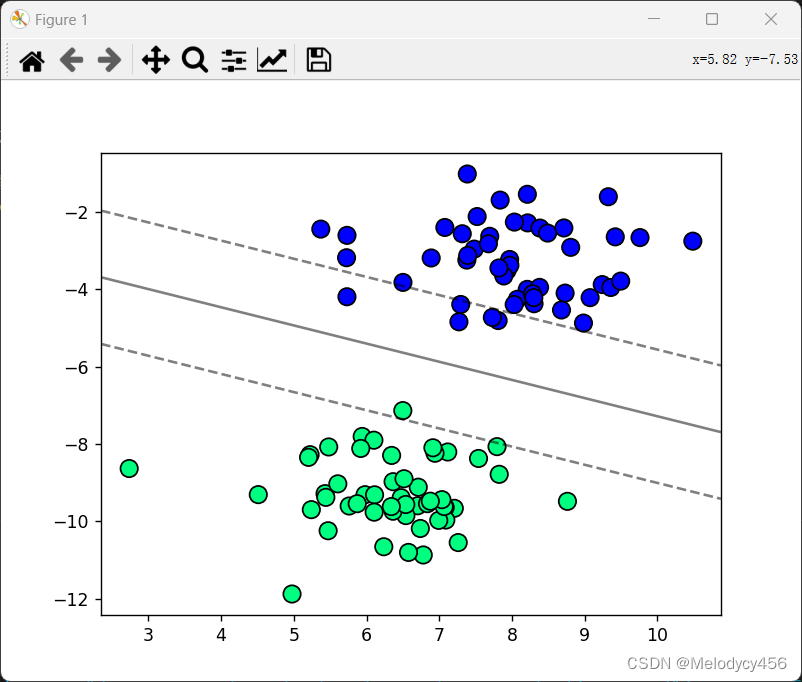
当C=100时,SVM分类结果如下图所示

当C=200时,SVM分类结果如下图所示
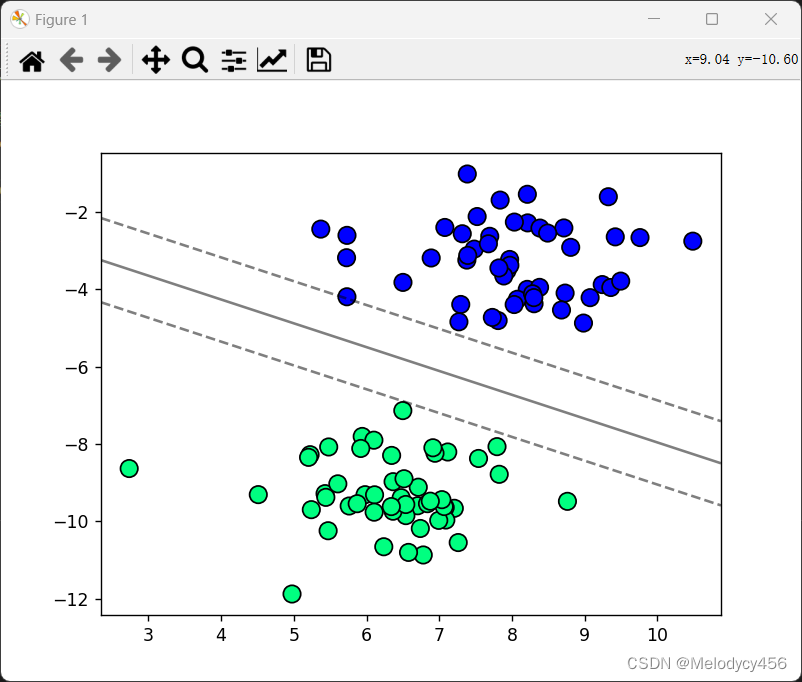
2.7 实验整体代码
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
class LinearSVM:
def __init__(self,learning_rate=0.0001,lambda_param=0.1,n_iters=1000):
self.learning_rate=learning_rate#学习率
self.lambda_param=lambda_param#正则化参数
self.n_iters=n_iters#迭代次数
self.w=None
self.b=None
def fit(self,X,y):#fit方法用于模型训练
n_samples,n_features=X.shape
y_ =np.where(y<=0,-1,1)
#初始化权重和偏置为0
self.w=np.zeros(n_features)
self.b=0
for _ in range(self.n_iters):
for idx, x_i in enumerate(X):
condition = y_[idx] * (np.dot(x_i, self.w) - self.b) >= 1
if condition:
# 当样本被正确分类且在边界外时,不更新
pass
else:
# 否则,使用统一的公式更新权重和偏置
gradient = 2 * self.lambda_param * self.w - np.dot(x_i, y_[idx])
self.w -= self.learning_rate * gradient
self.b -= self.learning_rate * y_[idx]
def predict(self,X):
Linear_output=np.dot(X,self.w)-self.b
return np.sign(Linear_output)
#结果可视化
def plot_hyperplane(X,y,w,b):
plt.scatter(X[:,0],X[:,1],marker='o',c=y,s=100,edgecolors='k',cmap='winter')
ax=plt.gca()
xlim=ax.get_xlim()
ylim=ax.get_ylim()
xx=np.linspace(xlim[0],xlim[1],30)
yy=np.linspace(ylim[0],ylim[1],30)
YY,XX=np.meshgrid(yy,xx)
xy=np.vstack([XX.ravel(),YY.ravel()]).T
Z=(np.dot(xy,w)-b).reshape(XX.shape)
ax.contour(XX,YY,Z,colors='k',levels=[-1,0,1],alpha=0.5,linestyles=['--','-','--'])
plt.show()
X,y=datasets.make_blobs(n_samples=100,centers=2,random_state=6)
y=np.where(y==0,-1,1)#调整标签为-1和1
svm0=LinearSVM()
svm0.fit(X,y)
plot_hyperplane(X,y,svm0.w,svm0.b)
class LinearSVM1:
def __init__(self,C=1.0,learning_rate=0.0001,n_iters=1000):
self.C=C
self.learning_rate=learning_rate
self.n_iters=n_iters
self.w=None
self.b=None
def fit(self,X,y):
n_samples,n_features=X.shape
y_ =np.where(y<=0,-1,1)
#初始化权重和偏置为0
self.w=np.zeros(n_features)
self.b=0
for _ in range(self.n_iters):
for idx,x_i in enumerate(X):
condition = y_[idx]*(np.dot(x_i,self.w)-self.b)>=1 #遍历每个样本,检查分类条件
if condition:
self.w-=self.learning_rate*(2*self.w)#如果样本被正确分类且在正确的间隔外,仅通过正则项更行权重(防止过拟合)
else:
self.w-=self.learning_rate*((2*self.w)-self.C*np.dot(x_i,y_[idx]))#样本被错误分类或者在间隔内,则权重更新包括误差项,同时更新偏置,使样本在未来被正确分类
self.b-=self.learning_rate*self.C*y_[idx]
def predict(self,X):
Linear_output=np.dot(X,self.w)-self.b
return np.sign(Linear_output)
#数据准备和模型训练
X,y=datasets.make_blobs(n_samples=100,centers=2,random_state=6)
y=np.where(y==0,-1,1)#调整标签为-1和1
svm1=LinearSVM1(C=20)
svm1.fit(X,y)
plot_hyperplane(X,y,svm1.w,svm1.b)
三、实验小结
在学习SVM理论时,很多概念和公式看起来抽象且难以理解。但通过实验,我能够直观地看到SVM如何在高维空间中划分数据,并理解支持向量在模型中的关键作用。实验中的参数调整(如C值、核函数的选择等)使我更加明白理论学习中提到的参数对模型性能的影响。在应用SVM之前,对数据进行适当的预处理(如归一化、标准化、去除冗余特征等)是至关重要的。实验让我深刻体会到,不同的数据预处理方式会对模型的性能产生显著影响。适当的特征选择或特征工程能够极大地提高模型的性能,并减少过拟合的风险。















 4874
4874











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









