






目录
一、引言
在机器学习的广阔领域中,支持向量机(Support Vector Machines, SVM)无疑占据了一个举足轻重的地位。作为一种强大的监督学习算法,SVM以其独特的优势和广泛的应用场景而备受关注。本文将深入探讨SVM的基本原理、求解过程、应用实例以及调优策略,旨在为读者提供一个全面而深入的SVM学习指南。
1. 支持向量机(SVM)的基本概念
支持向量机是一种用于分类和回归问题的机器学习算法。其核心理念在于寻找一个超平面(在二维空间中为一条直线,三维空间中为一个平面,高维空间中则为超平面),该超平面能够将训练数据划分为不同的类别,并且使得划分后的类别间隔最大化。这样的超平面即为最优决策边界,而距离最优决策边界最近的那些数据点被称为支持向量。
2. SVM在机器学习中的重要性及应用领域
SVM之所以重要,是因为它具备以下几个显著的优势:
- 高效性:SVM在处理高维数据时表现出色,能够在数据维度较高的情况下仍然保持较高的分类准确率。
- 鲁棒性:SVM对噪声数据和异常值具有较好的鲁棒性,能够在一定程度上抵抗这些干扰因素对分类结果的影响。
- 通用性:SVM适用于多种类型的数据分布,包括线性可分、线性不可分以及非线性可分的情况。
因此,SVM在诸多领域都得到了广泛的应用,包括但不限于:
- 图像识别:在人脸识别、手写数字识别等图像识别任务中,SVM能够准确地区分不同的图像类别。
- 文本分类:在新闻分类、垃圾邮件过滤等文本处理任务中,SVM能够有效地识别文本的主题和类别。
- 生物信息学:在基因表达数据分析、蛋白质功能预测等生物信息学领域,SVM也发挥了重要作用。
二、SVM理论基础
1. SVM的工作原理
线性可分与线性不可分
支持向量机(SVM)最初是为解决二分类问题而设计的,其核心思想是在特征空间中找到一个最优的分离超平面,该超平面能够将训练数据划分为两个不同的类别,且使得类别之间的间隔最大化。当训练数据线性可分时,可以直接在原始特征空间中找到这样的超平面;然而,当训练数据线性不可分时,SVM则通过引入核函数将数据映射到更高维的空间中,使得数据在新的空间中变得线性可分。
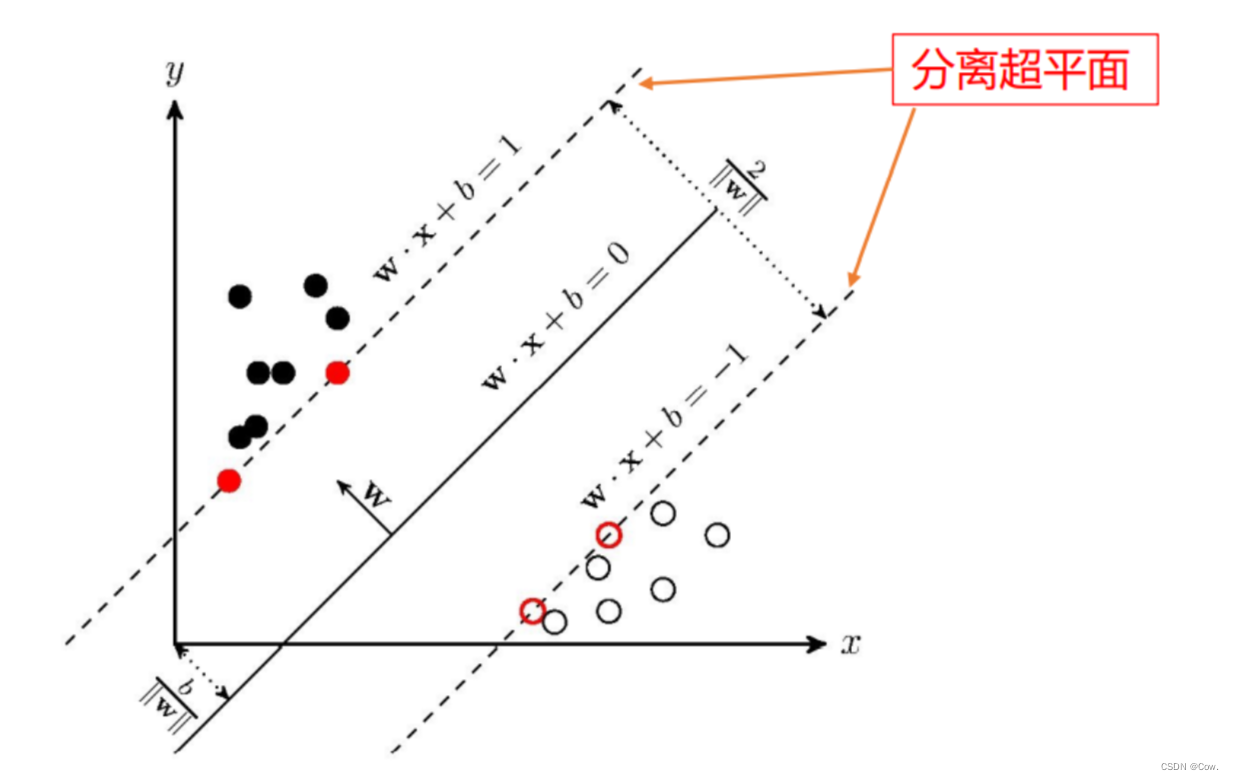
决策边界与间隔
在SVM中,决策边界是指将不同类别的数据分隔开的超平面。对于线性可分的数据,决策边界可以表示为 w^T * x + b = 0,其中 w 是权重向量,x 是输入数据,b 是偏置项。而间隔则是指所有数据点到决策边界的最小距离,这个距离也被称为“几何间隔”。SVM的目标就是找到一个决策边界,使得间隔最大化,从而提高模型的泛化能力。
2. 核函数与非线性SVM
为什么需要核函数
在实际情况中,很多数据并不是线性可分的,这时就需要将数据映射到更高维的空间中,使得数据在新的空间中变得线性可分。而核函数就是实现这种映射的关键工具。通过选择一个合适的核函数,我们可以将数据从原始空间映射到一个新的高维空间,然后在这个新的空间中寻找最优的决策边界。
常见的核函数类型
- 线性核(Linear Kernel):这是最简单的核函数,直接计算输入数据的内积。适用于线性可分的情况。
- 多项式核(Polynomial Kernel):通过多项式函数将数据映射到高维空间。适用于数据分布复杂、需要更高次特征交互的情况。
- 径向基函数(RBF)核(Radial Basis Function Kernel):也称为高斯核,通过高斯函数将数据映射到高维空间。RBF核具有较强的局部性,对数据的局部特性较为敏感。
- Sigmoid核:Sigmoid核类似于神经网络中的激活函数,可以将数据映射到一个类似于神经网络的特征空间中。
核函数如何影响SVM的性能
选择合适的核函数对SVM的性能至关重要。不同的核函数对数据映射的方式不同,从而影响到决策边界的形状和位置。因此,在实际应用中,我们需要根据数据的分布和特性来选择合适的核函数。同时,核函数的参数(如RBF核的γ参数)也会对SVM的性能产生影响,需要通过交叉验证等方式进行调优。
3. 软间隔SVM与正则化
噪声与异常值对SVM的影响
在实际应用中,训练数据往往包含噪声和异常值。这些噪声和异常值可能会对SVM的决策边界产生不良影响,导致模型过拟合或欠拟合。为了解决这个问题,SVM引入了软间隔的概念。
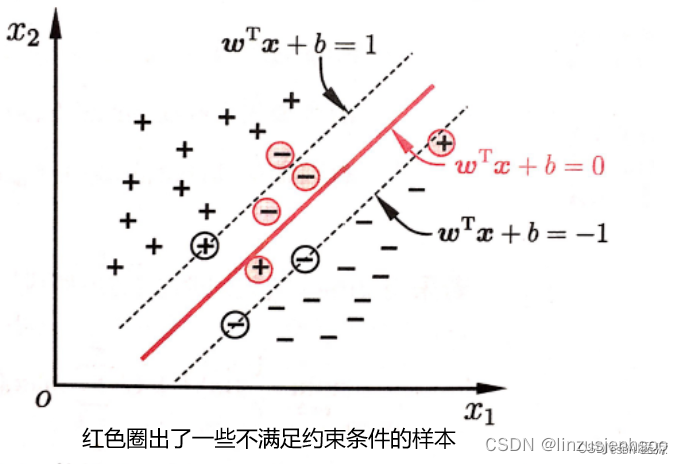
软间隔SVM的引入
在软间隔SVM中,我们允许一些数据点被错误地分类,即这些点到决策边界的距离可以小于间隔。通过引入一个松弛变量和一个惩罚系数C,我们可以控制这种错误分类的程度和代价。具体来说,当数据点被错误分类时,其对应的松弛变量会大于0,而惩罚系数C则决定了对这些错误分类的惩罚力度。通过调整C的值,我们可以平衡模型的复杂度和泛化能力之间的关系。
C参数与正则化强度的关系
在SVM中,C参数实际上是一个正则化参数。它控制着对错误分类的惩罚力度和对模型复杂度的权衡。当C的值较大时,模型会尽量将所有数据点都正确分类,这可能导致过拟合;而当C的值较小时,模型则更注重减小模型的复杂度,可能导致欠拟合。因此,选择合适的C值对于SVM的性能至关重要。在实际应用中,我们通常需要通过交叉验证等方式来选择合适的C值。
三、SVM求解过程
1. 原始问题与对偶问题
在SVM的求解过程中,我们通常会遇到两个问题:原始问题和对偶问题。原始问题直接描述了SVM的目标函数和约束条件,即寻找一个最优的超平面来分隔数据,并使得间隔最大化。然而,直接求解原始问题往往比较困难,因为这是一个凸二次规划问题,涉及到大量的计算。
为了简化求解过程,我们引入了对偶问题的概念。对偶问题是通过拉格朗日乘数法将原始问题转化为一个等价的对偶形式,从而可以利用一些优化算法来高效地求解。对偶问题的求解过程相对简单,且在一些情况下可以得到原始问题的最优解。
2. 序列最小优化(SMO)算法
序列最小优化(Sequential Minimal Optimization, SMO)算法是求解SVM对偶问题的一种高效算法。该算法的基本思想是将大优化问题分解为多个小优化问题来求解,通过每次只优化两个拉格朗日乘数来逐步逼近最优解。
SMO算法的工作流程大致如下:
-
选择两个变量:从所有拉格朗日乘数中选择两个进行优化。通常选择违反KKT条件的两个变量,因为这两个变量对目标函数的贡献最大。
-
解析求解:在选定的两个变量上,通过解析方法求解最优解。由于只涉及两个变量,所以可以直接求解得到最优解。
-
更新拉格朗日乘数:将求解得到的最优解更新到原始的拉格朗日乘数中。
-
检查收敛性:判断算法是否收敛。如果满足收敛条件(如目标函数的值变化小于某个阈值),则停止算法;否则,继续选择两个变量进行优化。
SMO算法通过迭代地优化两个拉格朗日乘数,逐步逼近最优解,从而高效地求解SVM对偶问题。
四、实例分析:鸢尾花分类
加载数据集
这里选择了花瓣长度和花瓣宽度作为特征来绘制散点图,因为这两个特征在鸢尾花数据集中通常是区分不同类别鸢尾花的关键特征。
# 加载鸢尾花数据集
iris = load_iris()
X = iris.data[:, [2, 3]] # 只选择花瓣长度(第三列)和花瓣宽度(第四列)
y = (iris.target != 0) * 1 # 二元分类,将类别0作为-1,类别1和2作为1
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)构建SVM分类器:
class LinearSVM:
def __init__(self, learning_rate=0.01, n_iter=1000, regularization=1.0):
self.lr = learning_rate
self.n_iter = n_iter
self.regularization = regularization
self.w = None
self.b = None
def fit(self, X, y):
# 验证输入数据
X, y = check_X_y(X, y, accept_sparse='csr', dtype=np.float64, order='C')
# 添加偏置项(bias term)
n_samples, n_features = X.shape
X = np.hstack((np.ones((n_samples, 1)), X))
# 初始化权重和偏置
self.w = np.zeros(n_features + 1)
self.b = 0
# 使用随机梯度下降进行训练
for _ in range(self.n_iter):
indices = np.random.permutation(n_samples)
X_random = X[indices]
y_random = y[indices]
for xi, yi in zip(X_random, y_random):
# 计算梯度(这里我们使用了Hinge Loss的梯度)
condition = yi * (np.dot(self.w, xi) + self.b)
if condition < 1:
gradient = -yi * xi
self.w -= self.lr * gradient
self.b -= self.lr * yi
# 加上L2正则项(权重衰减)
self.w -= self.lr * self.regularization * self.w
def predict(self, X):
# 添加偏置项(bias term)
X = np.hstack((np.ones((X.shape[0], 1)), X))
# 计算决策函数
linear_output = np.dot(X, self.w)
# 应用符号函数得到预测结果
y_pred = np.sign(linear_output)
# 由于sign函数返回-1或1,你可能需要将其转换为0或1(取决于你的标签编码)
y_pred[y_pred == -1] = 0
return y_pred
def decision_function(self, X):
# 添加偏置项(bias term)
X = np.hstack((np.ones((X.shape[0], 1)), X))
# 计算决策函数值
decision_values = np.dot(X, self.w)
return decision_values
分类结果:
Predictions: [1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1.
1. 1. 1. 1. 1. 1.]
True labels: [1 0 1 1 1 0 1 1 1 1 1 0 0 0 0 1 1 1 1 1 0 1 0 1 1 1 1 1 0 0]引入正则化强度参数C(正则化:在一定程度上抑制过拟合,使模型获得抗噪声能力,提升模型对未知样本的预测性能的手段,即提高范化性)
# 定义不同的C值
C_values = [0.1, 1, 100]
plt.figure(figsize=(15, 5))
for i, C in enumerate(C_values, 1):
# 训练SVM模型
svm = SVC(kernel='linear', C=C, random_state=42)
svm.fit(X_train, y_train)
# 绘制决策边界和支持向量
plt.subplot(1, len(C_values), i)
plt.scatter(X_test[y_test == 0][:, 0], X_test[y_test == 0][:, 1], label='Class 0 (Iris-setosa)')
plt.scatter(X_test[y_test == 1][:, 0], X_test[y_test == 1][:, 1],
label='Class 1 (Iris-versicolour, Iris-virginica)')
# 绘制决策边界和间隔
ax = plt.gca()
xlim = ax.get_xlim()
ylim = ax.get_ylim()
XX, YY = np.meshgrid(np.linspace(xlim[0], xlim[1], 30), np.linspace(ylim[0], ylim[1], 30))
xy = np.vstack([XX.ravel(), YY.ravel()]).T
Z = svm.decision_function(xy).reshape(XX.shape)
ax.contour(XX, YY, Z, colors='k', levels=[-1, 0, 1], alpha=0.5, linestyles=['--', '-', '--'])
plt.title(f'SVM with C={C}')
plt.xlabel('Petal length')
plt.ylabel('Petal width')
plt.legend()
plt.tight_layout()
plt.show()不同C值的结果如下: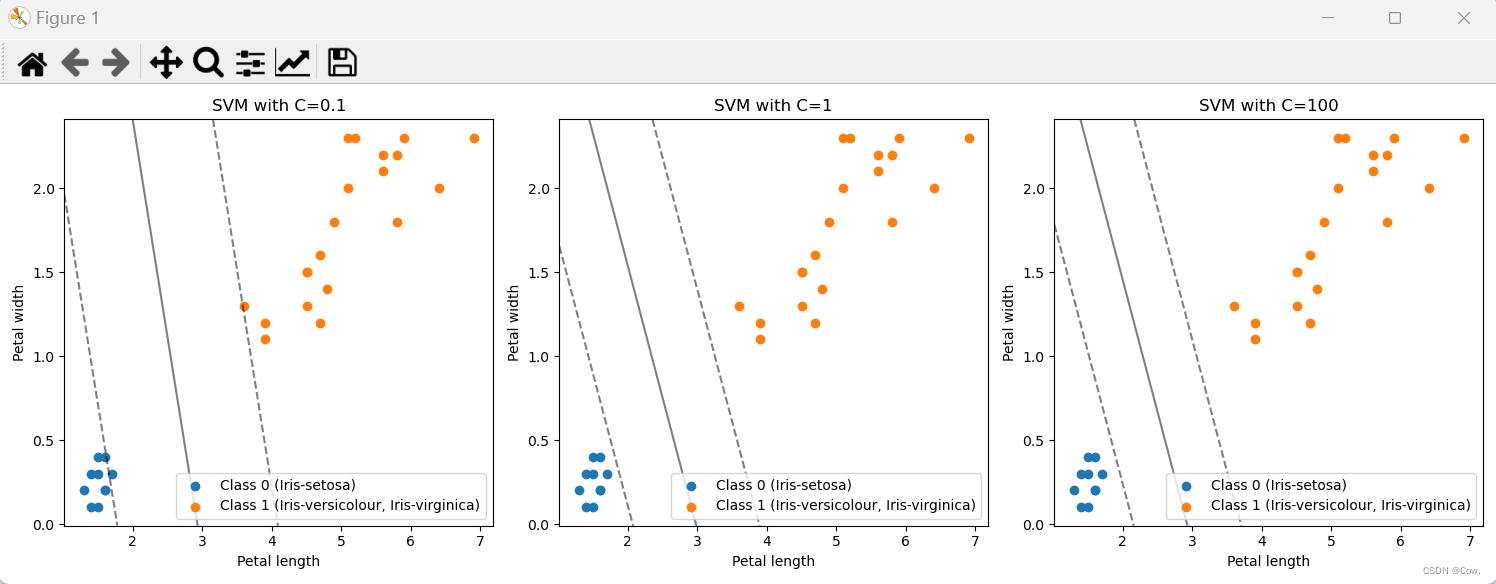
如图所示:C过小时导致分类间隔过大,可能使得结果欠拟合;C过大时导致分类间隔过小,可能使得结果过拟合。因此,选择合适的C值对于SVM的性能至关重要。
完整代码:
import numpy as np
from sklearn.datasets import load_iris
from sklearn.utils import check_X_y
class LinearSVM:
def __init__(self, learning_rate=0.01, n_iter=1000, regularization=1.0):
self.lr = learning_rate
self.n_iter = n_iter
self.regularization = regularization
self.w = None
self.b = None
def fit(self, X, y):
# 验证输入数据
X, y = check_X_y(X, y, accept_sparse='csr', dtype=np.float64, order='C')
# 添加偏置项(bias term)
n_samples, n_features = X.shape
X = np.hstack((np.ones((n_samples, 1)), X))
# 初始化权重和偏置
self.w = np.zeros(n_features + 1)
self.b = 0
# 使用随机梯度下降进行训练
for _ in range(self.n_iter):
indices = np.random.permutation(n_samples)
X_random = X[indices]
y_random = y[indices]
for xi, yi in zip(X_random, y_random):
# 计算梯度(这里我们使用了Hinge Loss的梯度)
condition = yi * (np.dot(self.w, xi) + self.b)
if condition < 1:
gradient = -yi * xi
self.w -= self.lr * gradient
self.b -= self.lr * yi
# 加上L2正则项(权重衰减)
self.w -= self.lr * self.regularization * self.w
def predict(self, X):
# 添加偏置项(bias term)
X = np.hstack((np.ones((X.shape[0], 1)), X))
# 计算决策函数
linear_output = np.dot(X, self.w)
# 应用符号函数得到预测结果
y_pred = np.sign(linear_output)
# 由于sign函数返回-1或1,你可能需要将其转换为0或1(取决于你的标签编码)
y_pred[y_pred == -1] = 0
return y_pred
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 加载鸢尾花数据集
iris = load_iris()
X = iris.data[:, [2, 3]] # 只选择花瓣长度(第三列)和花瓣宽度(第四列)
y = (iris.target != 0) * 1 # 二元分类,将类别0作为-1,类别1和2作为1
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
import matplotlib.pyplot as plt
# 实例化SVM对象并训练模型
svm = LinearSVM(learning_rate=0.01, n_iter=1000, regularization=1.0)
svm.fit(X_train, y_train)
# 预测测试集并评估性能
predictions = svm.predict(X_test)
# 打印预测结果
print("Predictions:", predictions)
# 打印真实标签
print("True labels:", y_test)
# 计算准确率并打印
accuracy = accuracy_score(y_test, predictions)
print("Accuracy:", accuracy)
plt.figure(figsize=(12, 6))
# 绘制训练数据点
plt.subplot(1, 2, 1)
plt.scatter(X_train[y_train == 0][:, 0], X_train[y_train == 0][:, 1], color='red', marker='o', label='Setosa')
plt.scatter(X_train[y_train == 1][:, 0], X_train[y_train == 1][:, 1], color='blue', marker='x', label='Versicolor')
plt.title('Training Set')
plt.xlabel('Petal Length')
plt.ylabel('Petal Width')
plt.legend()
# 绘制测试数据点
plt.subplot(1, 2, 2)
plt.scatter(X_test[y_test == 0][:, 0], X_test[y_test == 0][:, 1], color='red', marker='o', label='Setosa')
plt.scatter(X_test[y_test == 1][:, 0], X_test[y_test == 1][:, 1], color='blue', marker='x', label='Versicolor')
plt.title('Test Set')
plt.xlabel('Petal Length')
plt.ylabel('Petal Width')
plt.legend()
# 绘制最大间隔超平面
w = svm.w
b = svm.b
xx = np.linspace(0, 10)
yy = -(w[0] * xx + b) / w[1]
margin = 1 / np.sqrt(np.sum(svm.w ** 2)) # 计算间隔大小
yy_up = yy + margin
yy_down = yy - margin
plt.plot(xx, yy, color='black', label='Decision Boundary')
plt.plot(xx, yy_up, color='black', linestyle='--', label='Margin Boundary')
plt.plot(xx, yy_down, color='black', linestyle='--')
plt.tight_layout()
plt.show()
五、总结
SVM作为一种强大的机器学习算法,在分类和回归问题中都表现出了很好的性能。通过理解SVM的核心概念、核函数、应用和优缺点,我们可以更好地使用SVM来解决实际问题。同时,也需要注意在实际应用中根据数据的特点和需求来选择合适的参数和核函数。















 3122
3122











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









