







NLP发展历史
•
20
世纪五十年代开始,与计算机的诞生几乎同时
•
始于机器翻译任务
•
两种路线:
1.基于规则的理性主义
主张建立符号处理系统,由人工整理和编写初始的 语言知识表示体系,构造相应的推理程序
2.基于统计的经验主义
主张通过建立特定的数学模型来学习复杂的、广泛的语言结构,利用统计、模式识别、机器学习等方法来训练模型
•
机器学习



•
20
世纪
20
年代
-60
年代
•
经验主义处于主导地位,人们在研究语言的应用规律是进行统计、分析和归纳,并建立相应的分析或处理系统
•
20
世纪
60
年代
-80
年代
•
语言学、心理学、人工智能和
NLP
等领域的研究几乎都是遵循理性主义研究方法。人们通过建立很多小系统来模拟智能
•
20
世纪
80
年代后期
•
人们更多的关注工程化、实用化的解决问题,经验主义被人们重新认识并且引入到
NLP
研究中,并快速发展
•
20
世纪
80
年代末
-
9
0
年代
•
围绕经验主义和理性主义发生了很多激烈争论,但人们逐渐达成共识,无论哪一种方法都不可能完全解决自然语言处理这一复杂问题。两种方法开始从对立走向融合
•
21
世纪
以来
•
机器学习快速崛起。在图像、语言、文本领域都有大量的数据集被建立起来,这种资源大幅度推动了基于统计的机器学习相关算法的发展。随着
AlphaGo
的出现,人工智能领域获得前所未有的关注度。
NLP
也飞快的追赶着其他领域发展。
机器学习
•
#
常用概念
#
•
1.
训练集
用于模型训练的训练数据集合
•
2.
验证集
对于每种任务一般都有多种算法可以选择,一般会使用验证集验证用于对比不同算法的效果差异
•
3.
测试集
最终用于评判算法模型效果的数据集合
•
4.K
折交叉验证(
K fold cross validation
)
初始采样分割成K个子样本,一个单独的子样本被保留作为验证模型的数据,其他K-1个样本用来训练。交叉验证重复K次,每个子样本验证一次,平均K次的结果
•
#
常用概念
#
•
1.
过拟合
•
模型失去了泛化能力。如果模型在训练集和验证集上都有很好的表现,但在测试集上表现很差,一般认为是发生了过拟合
•
2.
欠拟合
•
模型没能建立起合理的输入输出之间的映射。当输入训练集中的样本时,预测结果与标注结果依然相差很大
•
#
常用概念
#
•
评价指标
•
为了评价算法效果的好坏,需要找到一种评价模型效果的计算指标。不同的任务会使用不同的评价指标。常用的评价指标有:
•
1
)准确率
•
2
)召回率
•
3
)
F1
值
•
4
)
TopK
•
5
)
BLEU…
•
#
常用概念
#
•
1.
回归问题
•
预测值为数值型(连续值)。如预测房价。
•
2.
分类问题
•
预测值为类别(离散值)或在类别上的概率的分布。
•
•
#
常用概念
#
•
1.
特征
•
模型输入需要数值化,对于较为抽象的输入,如声音,文字,情绪等信息,需要将其转化为数值,才能输入模型。转化后的输入,被称作特征。
•
2.
特征工程
•
筛选哪些信息值得(以特征的形式)输入模型,以及应当以何种形式输入的工作过程。对于机器学习而言非常重要。模型的输入,决定了模型能力的上限。
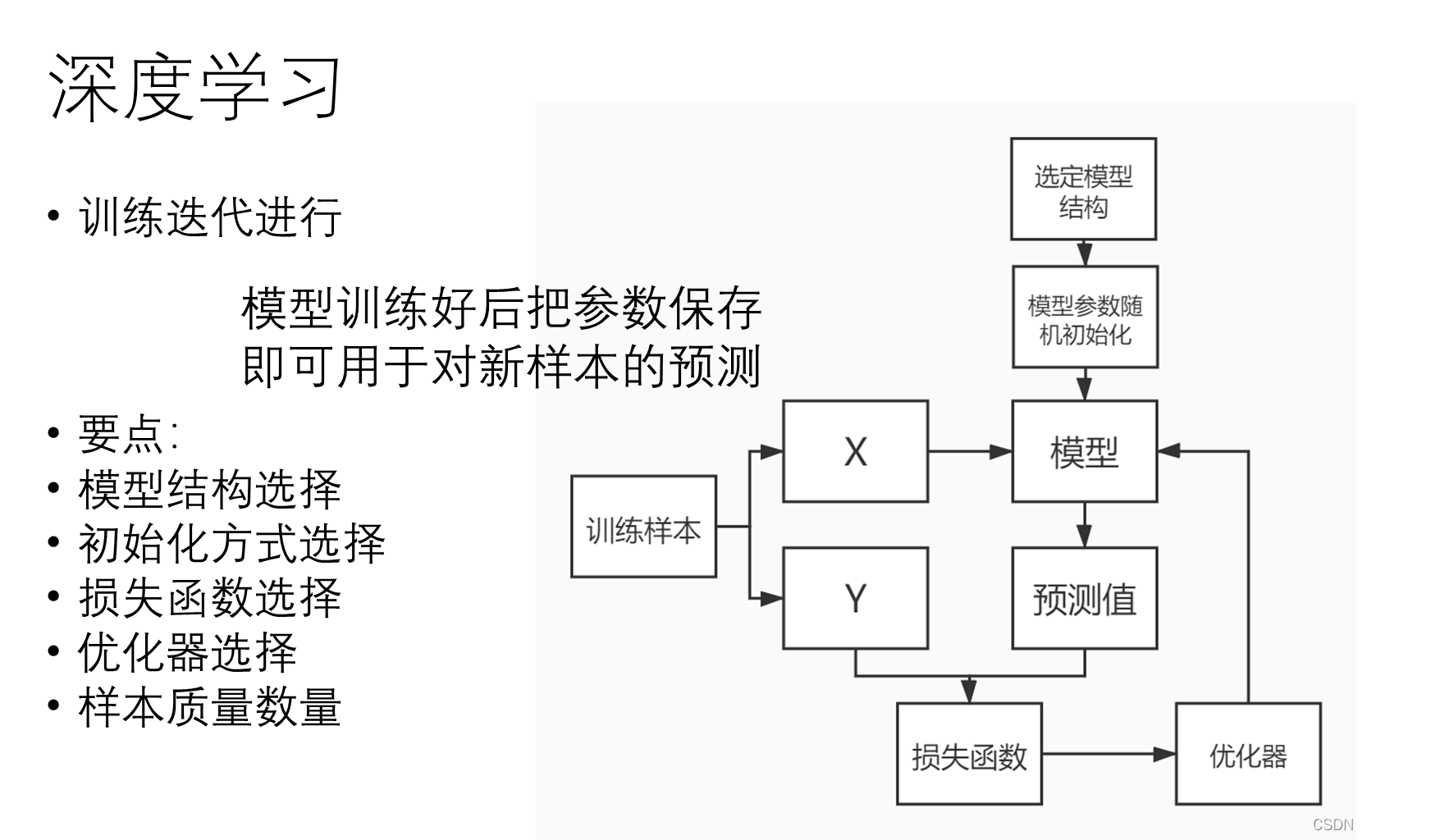
深度学习
•
首先
B
随便猜一个数
----
模型随机初始化
•
模型函数 :
Y = k * x (
此样本
x = 100)
•
此例子中
B
选择的初始
k
值为
0.6
•
A
计算
B
的猜测与真正答案的差距
----
计算
loss
•
损失函数
= sign(
y_true
–
y_pred
)
•
A
告诉
B
偏大或偏小
----
得到
loss
值
•
B
调整了自己的“模型参数”
----
反向传播
•
参数调整幅度依照
B
自定的策略
----
优化器
&
学习率
•
重复以上过程
•
最终
B
的猜测与
A
的答案一致
----
loss
= 0
•
人工神经网络(
Artificial Neural Networks,
简称
ANNs),
也简称为神经网络(
NN)
。它
是一种模仿动物神经网络行为特征,进行分布式并行信息处理的算法数学模型。
•
#
隐含层
/
中间层
#
•
神经网络模型输入层和输出层之间的部分
•
隐含层可以有不同的结构:
•
RNN
•
CNN
•
DNN
•
LSTM
•
Transformer
•
等等
•
#
随机初始化
#
•
隐含层中会含有很多的权重矩阵,这些矩阵需要有初始值,才能进行运算
•
初始值的选取会影响最终的结果
•
一般情况下,模型会采取随机初始化,但参数会在一定范围内
•
在使用预训练模型一类的策略时,随机初始值被训练好的参数代替
•
#
损失函数
#
•
损失函数(
loss function
或
cost function
)用来计算模型的预测值与真实值之间的误差。
•
模型训练的目标一般是依靠训练数据来调整模型参数,使得损失函数到达最小值。
•
损失函数有很多,选择合理的损失函数是模型训练的必要条件。
•
•
#
导数与梯度
#
•
导数
表示函数曲线上的切线斜率。 除了切线的斜率,导数还表示函数在该点的变化率
。
•
#
梯度下降
#
•
梯度告诉我们函数向哪个方向增长最快,那么他的反方向,就是下降最快的方向
•
•
梯度下降的目的是找到函数的极小值
•
•
为什么要找到函数的极小值?
因为我们最终的目标是损失函数值最小
•
#
优化器
#
•
知道走的方向,还需要知道走多远
•
假如一步走太大,就可能错过最小值,如果一步走太小,又可能困在某个局部低点无法离开
•
学习率(
learning rate
),动量(
Momentum
)都是优化器相关的概念
•
#Mini Batch##epoch#
•
一次训练数据集的一小部分,而不是整个训练集,或单条数据
•
它可以使内存较小、不能同时训练整个数据集的电脑也可以训练模型。
•
它是一个可调节的参数,会对最终结果造成影响
•
不能太大,因为太大了会速度很慢。 也不能太小,太小了以后可能算法永远不会收敛。
•
我们将遍历一次所有样本的行为叫做一个 epoch
•
总结
•
机器学习的本质,是从已知的数据中寻找规律,用来预测未知的样本
•
•
深度学习是机器学习的一种方法
•
•
深度学习的基本思想,是先建立模型,并将模型权重随机初始化,之后将训练样本输入模型,可以得到模型预测值。使用模型预测值和真实标签可以计算
loss
。通过
loss
可以计算梯度,调整权重参数。简而言之,“先蒙后调”















 129
129











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











