







Python与Anaconda安装&&鸢尾花数据集SVM线性分类练习
一、Python与Anaconda安装
这个博客写的很详细,超级推荐
python与anaconda安装(先安装了python后安装anaconda,基于python已存在的基础上安装anaconda)——逼死强迫症、超详解
二、Anaconda简单使用
-
打开Anaconda
-
创建虚拟环境,要等待大概十分钟

-
在虚拟环境下安装 numpy、pandas、sklearn包
-
输入
conda install numpy,我这里是已经安装好numpy了,所以显示是这样
输入
conda install numpy安装有点久,可以换输入pip install numpy试试
pandas、sklearn包同理

三、Anaconda Jupyter notebook 使用
- 安装完成Anaconda后,在同一目录下找到Jupyter notebook点击

- 启动之后自动弹出的页面

如果没有自动弹出:请参考这个博客Jupyter notebook不自动弹出网页
四、鸢尾花数据集SVM线性分类练习
4.1 SVM算法
SVM的全称是Support Vector Machine,即支持向量机,主要用于解决模式识别领域中的数据分类问题,属于有监督学习算法的一种。SVM要解决的问题可以用一个经典的二分类问题加以描述。如图1所示,红色和蓝色的二维数据点显然是可以被一条直线分开的,在模式识别领域称为线性可分问题。然而将两类数据点分开的直线显然不止一条。图1(b)和©分别给出了A、B两种不同的分类方案,其中黑色实线为分界线,术语称为“决策面”。每个决策面对应了一个线性分类器。虽然在目前的数据上看,这两个分类器的分类结果是一样的,但如果考虑潜在的其他数据,则两者的分类性能是有差别的。
4.2 鸢尾花数据集的分类可视化及预测
- 导入本次实验需要的库
#鸢尾花数据集SVM算法二分类
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets, svm
import pandas as pd
from pylab import *
- 对各个变量进行赋值
mpl.rcParams['font.sans-serif'] = ['SimHei']
iris = datasets.load_iris()
iris = datasets.load_iris()
X = iris.data
y = iris.target
X = X[y != 0, :2] # 选择X的前两个特性
y = y[y != 0]
- 排列
n_sample = len(X)
np.random.seed(0)
order = np.random.permutation(n_sample) # 排列,置换
X = X[order]
y = y[order].astype(np.float)
X_train = X[:int(.9 * n_sample)]
y_train = y[:int(.9 * n_sample)]
X_test = X[int(.9 * n_sample):]
y_test = y[int(.9 * n_sample):]
- 运行结果
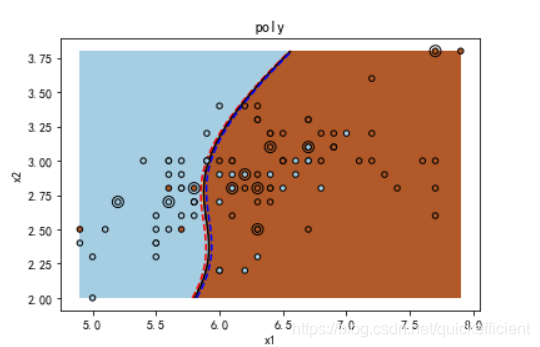
for fig_num, kernel in enumerate(('linear', 'rbf','poly')): # 径向基函数 (Radial Basis Function 简称 RBF),常用的是高斯基函数
clf = svm.SVC(kernel=kernel, gamma=10) # gamma是“rbf”、“poly”和“sigmoid”的核系数。
clf.fit(X_train, y_train)
plt.figure(str(kernel))
plt.xlabel('x1')
plt.ylabel('x2')
plt.scatter(X[:, 0], X[:, 1], c=y, zorder=10, cmap=plt.cm.Paired, edgecolor='k', s=20)
# zorder: z方向上排列顺序,数值越大,在上方显示
# paired两个色彩相近输出(paired)
# 圈出测试数据
plt.scatter(X_test[:, 0], X_test[:, 1], s=80, facecolors='none',zorder=10, edgecolor='k')
plt.axis('tight') #更改 x 和 y 轴限制,以便显示所有数据
x_min = X[:, 0].min()
x_max = X[:, 0].max()
y_min = X[:, 1].min()
y_max = X[:, 1].max()
XX, YY = np.mgrid[x_min:x_max:200j, y_min:y_max:200j]
Z = clf.decision_function(np.c_[XX.ravel(), YY.ravel()]) # 样本X到分离超平面的距离
Z = Z.reshape(XX.shape)
plt.contourf(XX,YY,Z>0,cmap=plt.cm.Paired)
plt.contour(XX, YY, Z, colors=['r', 'k', 'b'],
linestyles=['--', '-', '--'], levels=[-0.5, 0, 0.5]) # 范围
plt.title(kernel)
plt.show()

五、参考资料
基于jupyter notebook的python编程-----机器学习中的线性分类器及相应判定方法(鸢尾花数据集的分类可视化)
基于Jupyter 对鸢尾花数据集和月亮数据集,分别采用线性LDA、k-means和SVM算法进行二分类可视化分析(python)















 878
878











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









