







前言
本文主要介绍如何在本地服务器部署无需依托高昂价格的 GPU,也可以在本地运行离线 AI 项目的开源 AI 神器 LoaclAI,并结合 cpolar 内网穿透轻松实现远程使用的超详细教程。
随着 AI 大模型的发展,各大厂商都推出了自己的线上 AI 服务,比如写文章的、文字生成图片或者视频的等等。但是使用这些 AI 软件时,都需要将文件数据传输到商家的服务器上,所以不少用户就会存在这样的担忧:我的数据会泄露吗?我的隐私能得到保护吗?
今天就和大家分享一款可以本地部署的开源 AI 项目,它就是在 github 上已经获得了 27.7Kstar 的明星项目 LocalAI!它可以在本地直接运行大语言模型 LLM、生成图像、音频等。关键是不需要高端昂贵的 GPU,是的,直接在消费级硬件上通过 CPU 就能推理运行,真正降低了 AI 使用的门槛。
LocalAI 的安装方式也非常简单,支持通过 Shell 脚本或 Docker 容器来本地部署。本例中,将通过 docker 来演示如何快速启动 LocalAI 并进行大模型加载与跨网络环境远程使用。
1. Docker 部署
本例使用 Ubuntu 22.04 进行演示,使用 Docker 进行部署,如果没有安装 Docker,可以查看这篇教程进行安装:《Docker 安装教程——Linux、Windows、MacOS》
安装好 Docker 后,打开终端执行这行命令启动容器即可:
sudo docker run -ti --name local-ai -p 8080:8080 localai/localai:latest-cpu
这里使用的镜像是仅使用 CPU 来运行的镜像,如果大家有 Nvidia 显卡的好 GPU,也可以使用下方命令拉取支持 N 卡的镜像来运行容器:
sudo docker run -ti --name local-ai -p 8080:8080 --gpus all localai/localai:latest-gpu-nvidia-cuda-12
更多项目配置与使用详情大家也可以访问作者的 github 主页进行查看:https://github.com/mudler/LocalAI
2. 简单使用演示
容器启动后,我们在 Ubuntu 中使用浏览器访问 http://localhost:8080 即可打开 LocalAI 的 Web UI 页面:
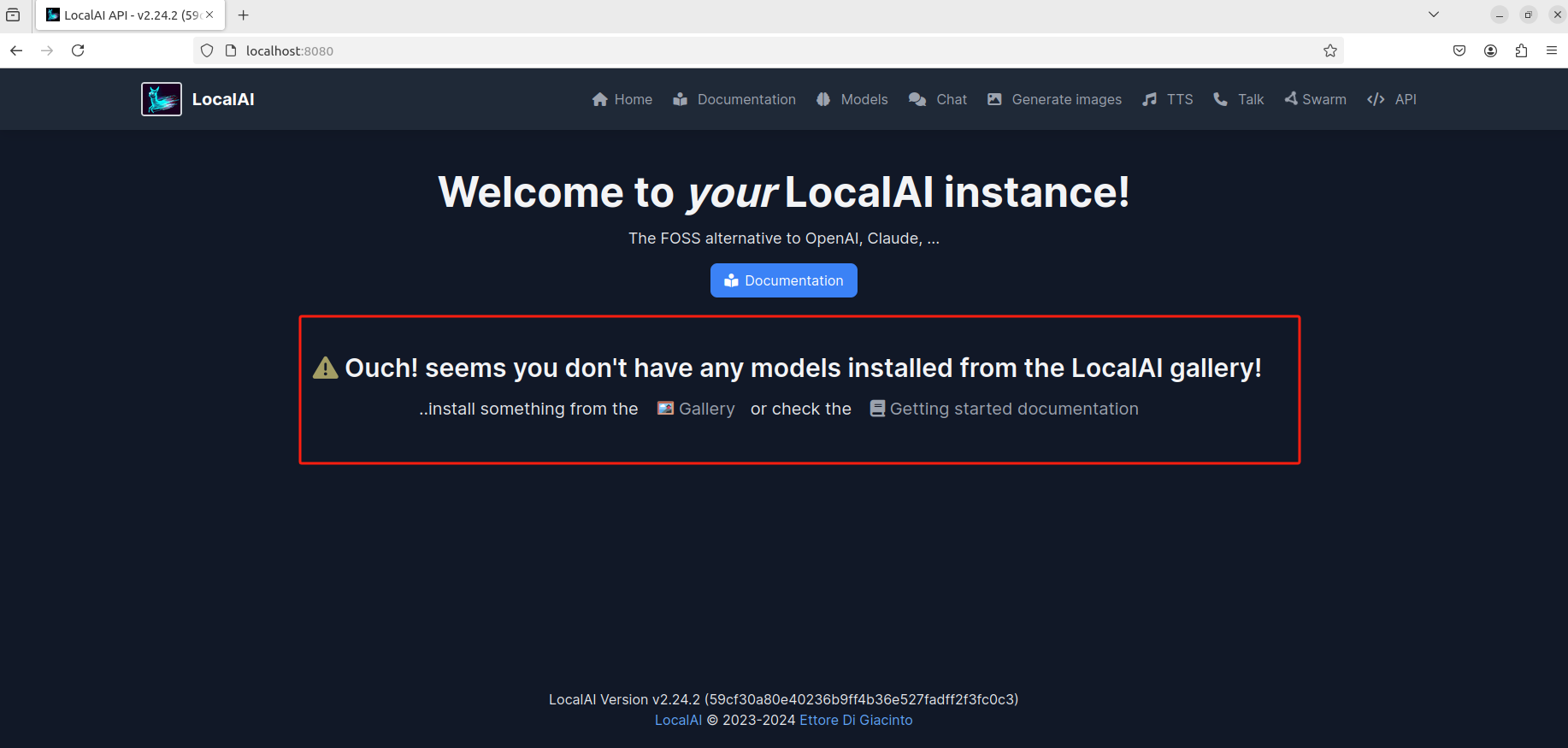
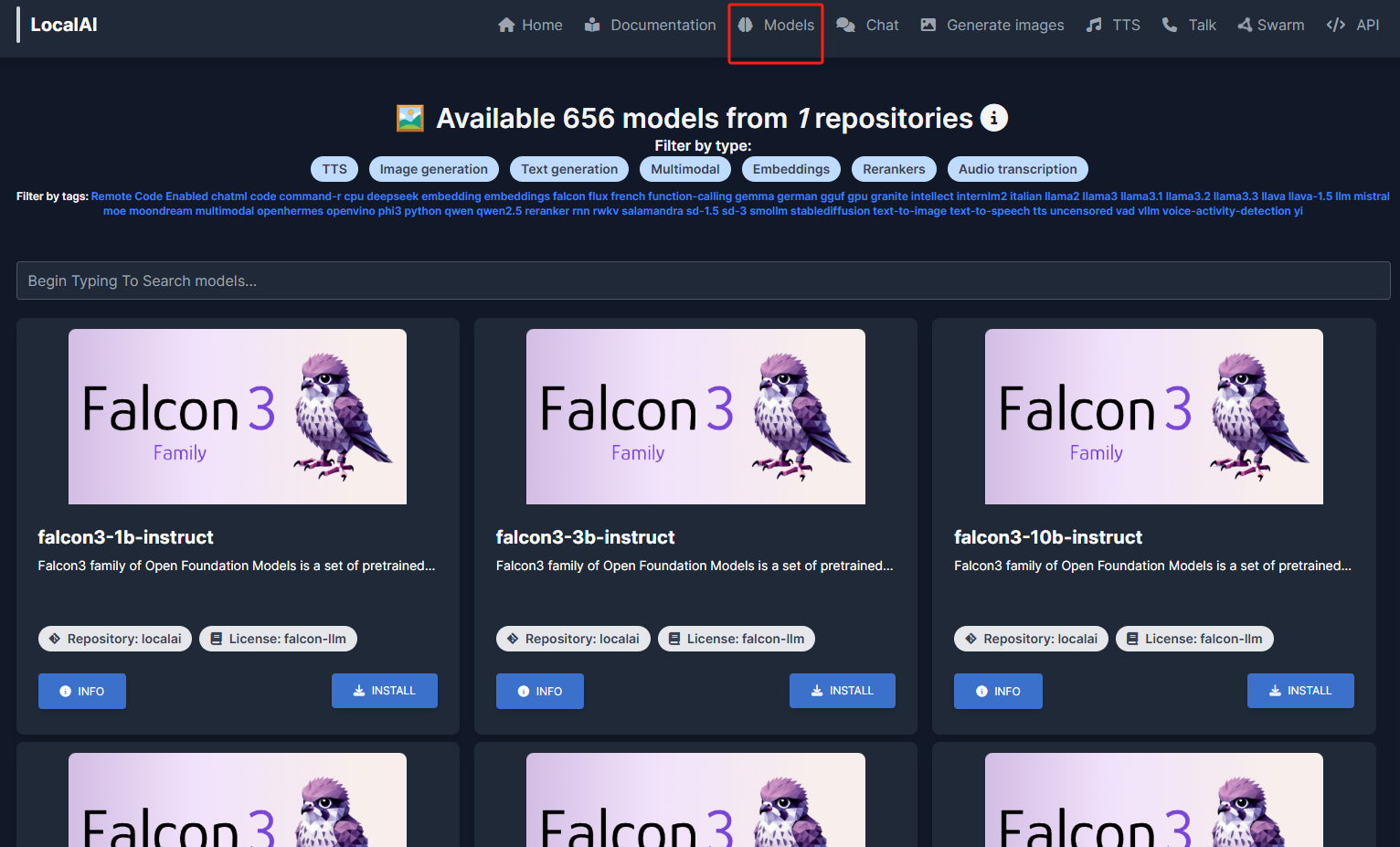
能看到页面中央提示我们现在还没有添加大模型,我们可以点击 Gallery,在跳转页面选择一个大模型:
可以看到在这个界面中有 600 多个大模型,并且可以根据用途标签(文字转语音、图片生成、文章生成等等)进行筛选或者在下方输入框搜索指定的模型:
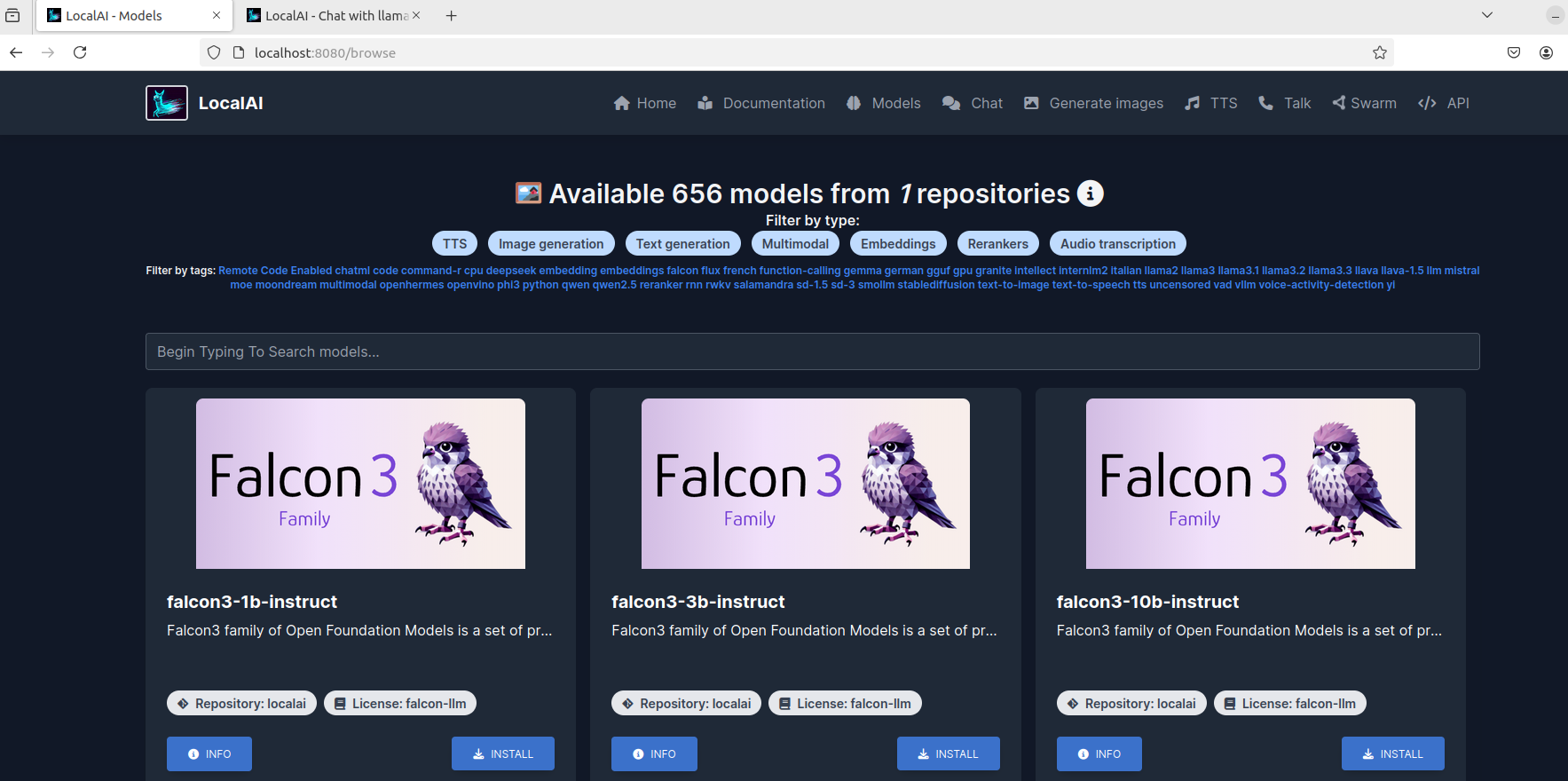
我这里以添加 llama-3.2-1b 模型来进行演示:点击 install 按钮安装等待完成即可

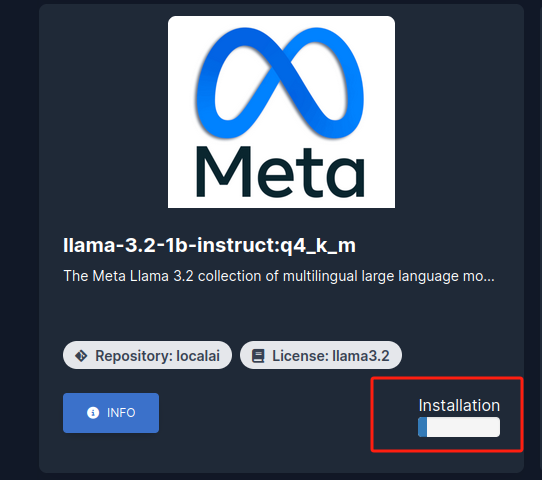
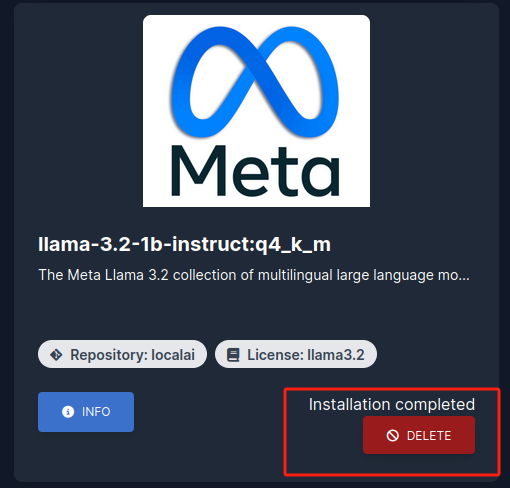
安装完成后,点击页面上方导航条中的 HOME 回到主页即可发现刚刚添加的 llama-3.2 模型:
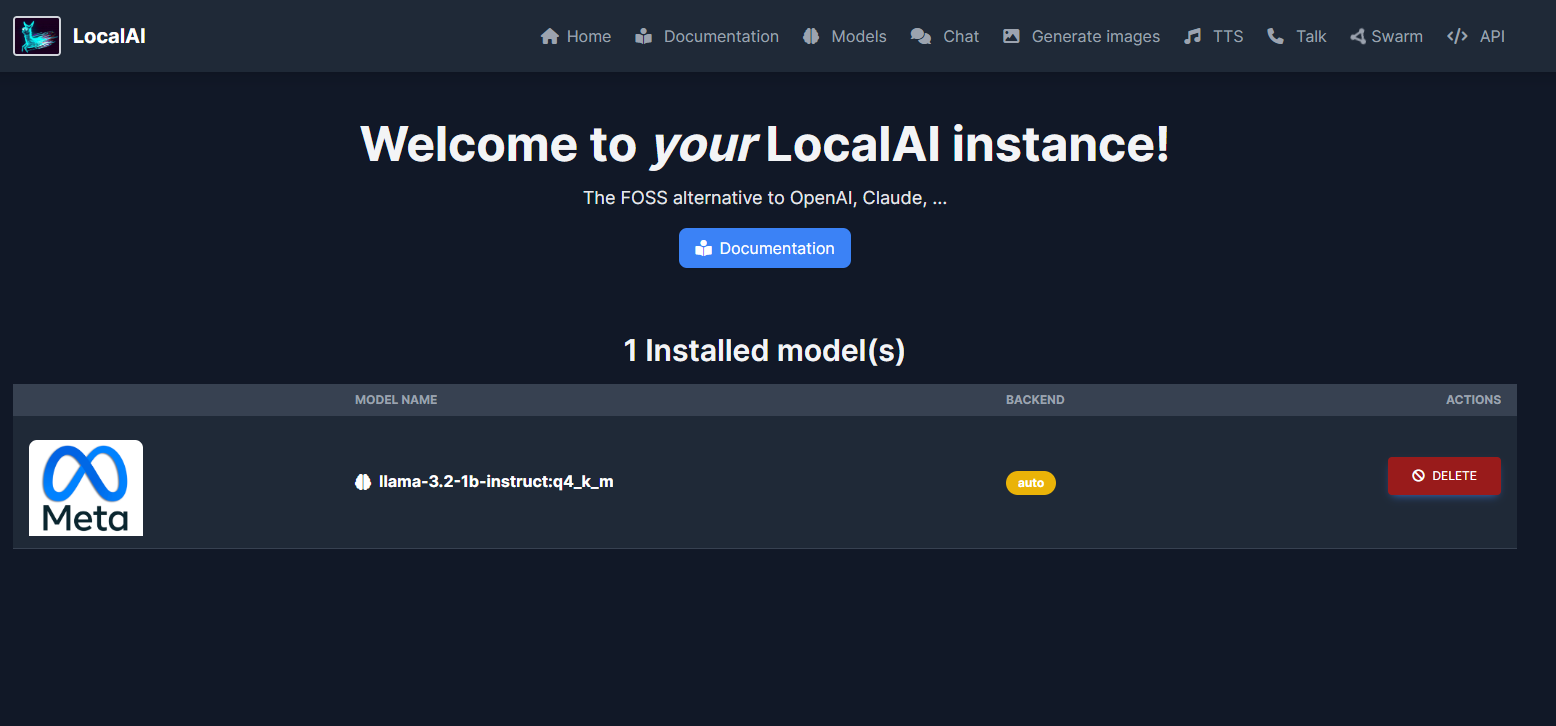
想要使用这个 AI 大模型,点击上方导航中的 chat 即可与它聊天了:
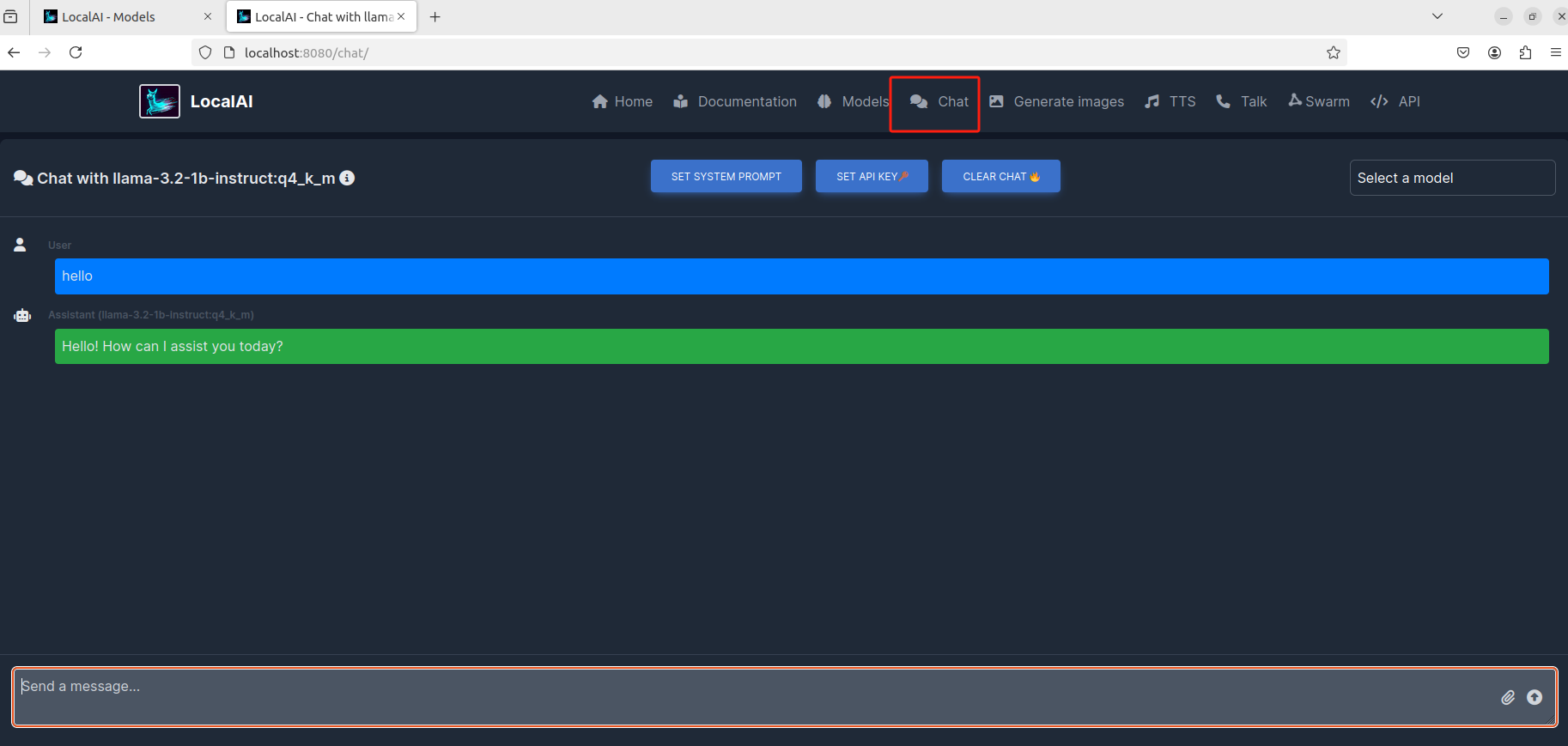
点击右侧的模型选择,下拉框中会显示你已经安装的大模型:
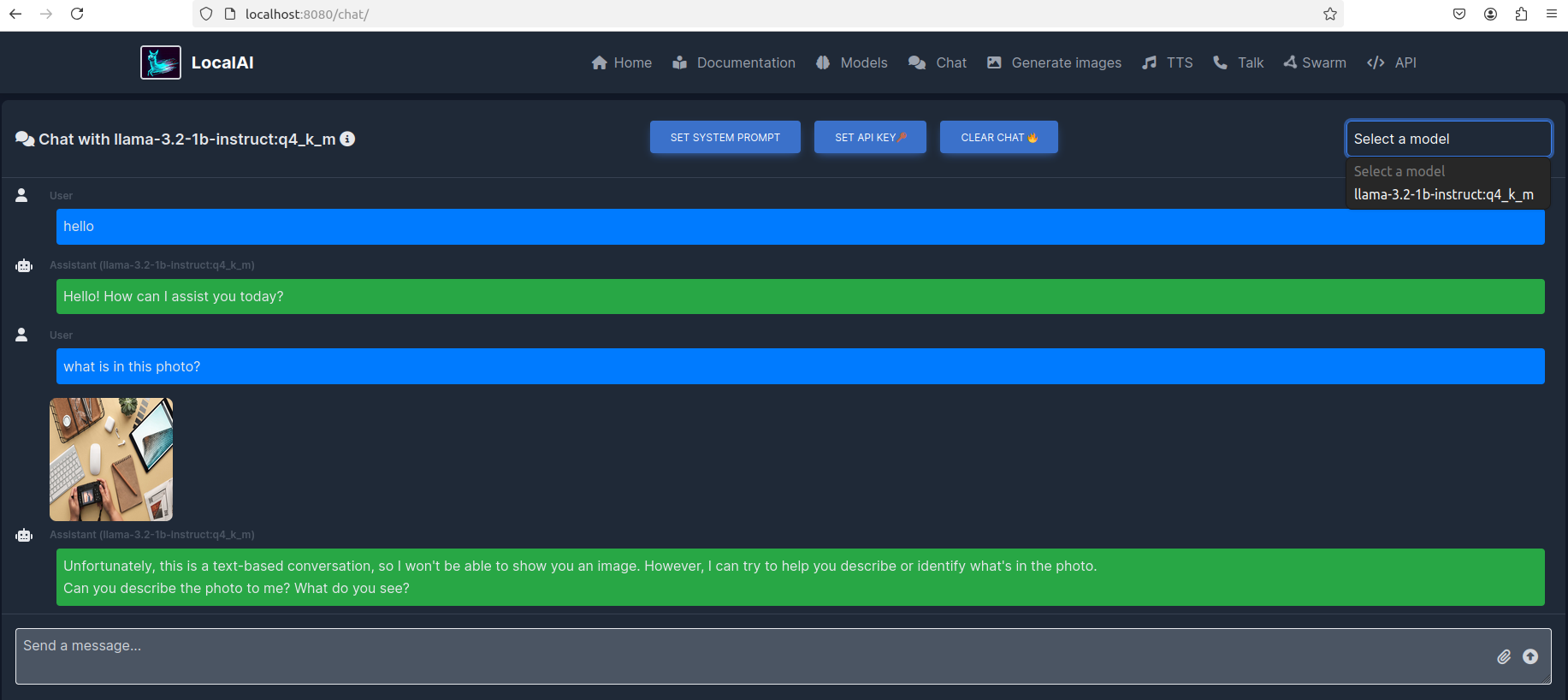
目前我只安装了这一个,如果想继续安装其他大模型,可以点击页面上方导航栏中的 Models 进行选择:(跳转的就是首次挑选模型安装的那个页面)
3. 安装 cpolar 内网穿透
不过我们目前只能在本地局域网内访问刚刚部署的 LocalAI 来使用 AI 大模型聊天,如果想不在同一局域网内时,也能在外部网络环境使用手机、平板、电脑等设备远程访问与使用它,应该怎么办呢?我们可以使用 cpolar 内网穿透工具来实现远程访问的需求。无需公网 IP,也不用设置路由器那么麻烦。
下面是安装 cpolar 步骤:
Cpolar 官网地址: https://www.cpolar.com
使用一键脚本安装命令:
sudo curl https://get.cpolar.sh | sh
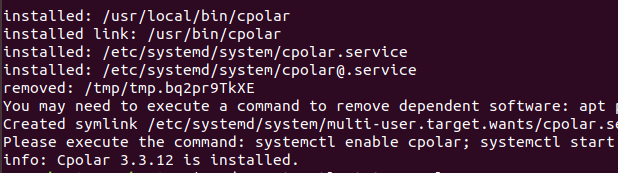
安装完成后,执行下方命令查看 cpolar 服务状态:(如图所示即为正常启动)
sudo systemctl status cpolar

Cpolar 安装和成功启动服务后,在浏览器上输入 ubuntu 主机 IP 加 9200 端口即:【http://localhost:9200】访问 Cpolar 管理界面,使用 Cpolar 官网注册的账号登录,登录后即可看到 cpolar web 配置界面,接下来在 web 界面配置即可:
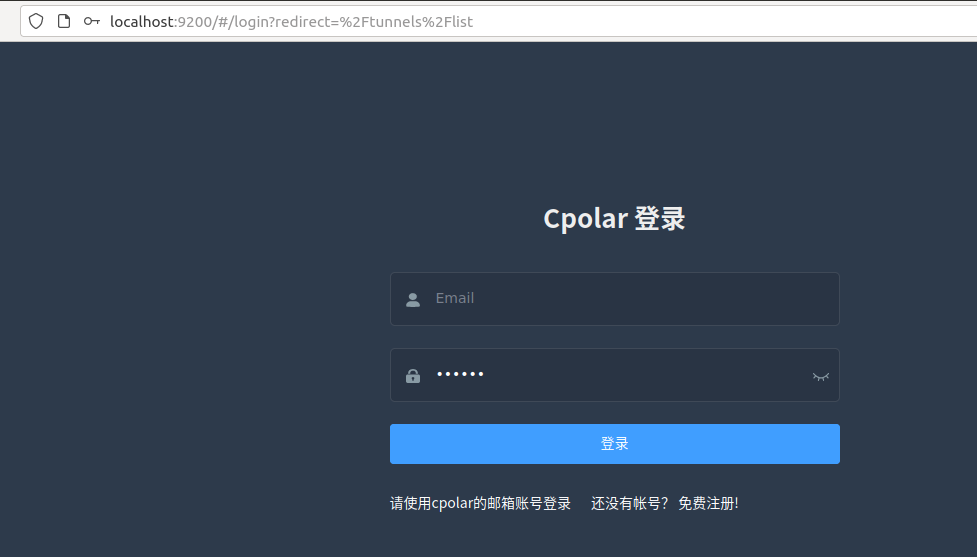
4. 配置公网地址
登录 cpolar web UI 管理界面后,点击左侧仪表盘的隧道管理——创建隧道:
- 隧道名称:可自定义,本例使用了: localai ,注意不要与已有的隧道名称重复
- 协议:http
- 本地地址:8080
- 域名类型:随机域名
- 地区:选择 China Top
点击创建:
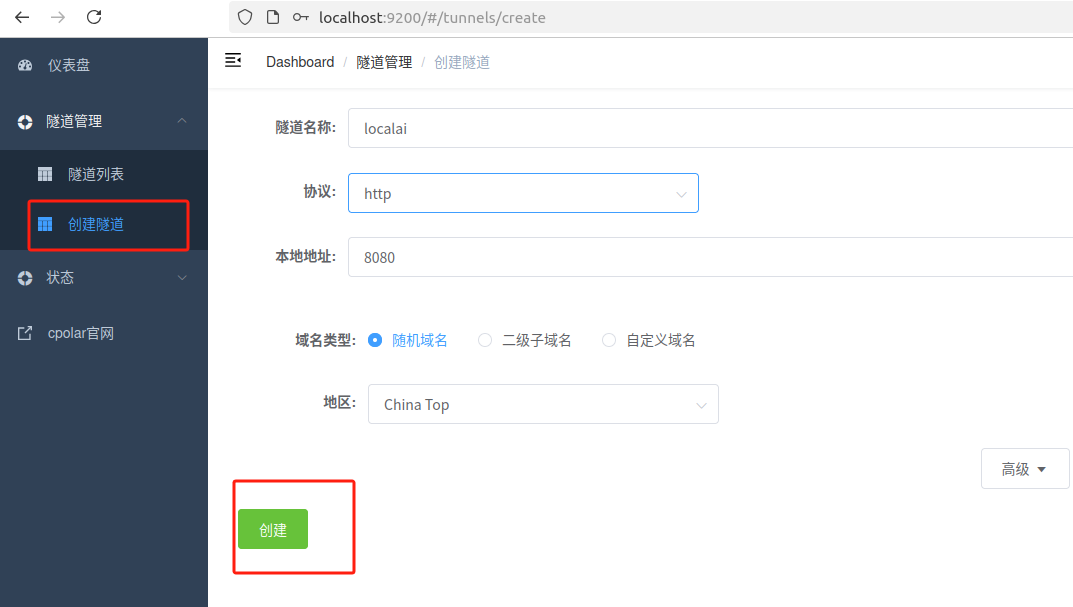
创建成功后,打开左侧在线隧道列表,可以看到刚刚通过创建隧道生成了两个公网地址,接下来就可以在其他电脑或者移动端设备(异地)上,使用任意一个地址在浏览器中访问即可。
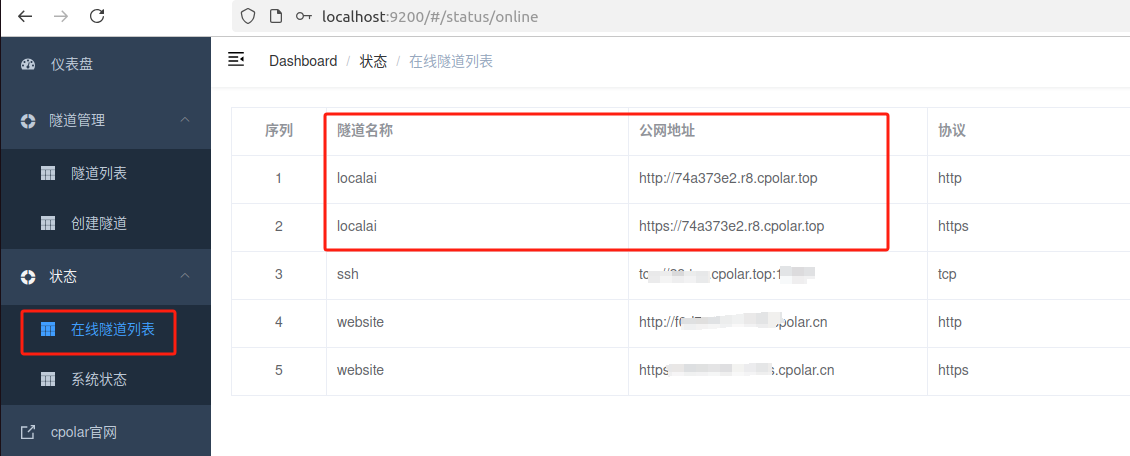
如图所示,现在就已经成功实现使用公网地址异地远程访问本地部署的 LocalAI 来用 AI 大模型聊天啦!
小结
为了方便演示,我们在上边的操作过程中使用 cpolar 生成的 HTTP 公网地址隧道,其公网地址是随机生成的。这种随机地址的优势在于建立速度快,可以立即使用。然而,它的缺点是网址是随机生成,这个地址在 24 小时内会发生随机变化,更适合于临时使用。
如果有长期使用 LocalAI,或者异地访问与使用其他本地部署的服务的需求,但又不想每天重新配置公网地址,还想让公网地址好看又好记并体验更多功能与更快的带宽,那我推荐大家选择使用固定的二级子域名方式来配置公网地址。
5. 配置固定公网地址
由于以上使用 cpolar 所创建的隧道使用的是随机公网地址,24 小时内会随机变化,不利于长期远程访问。因此我们可以为其配置二级子域名,该地址为固定地址,不会随机变化。
点击左侧的预留,选择保留二级子域名,地区选择 china top,然后设置一个二级子域名名称,我这里演示使用的是mylocal,大家可以自定义。填写备注信息,点击保留。
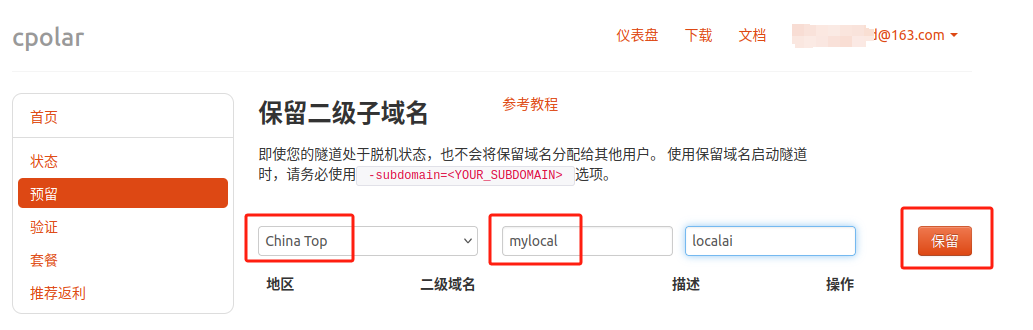
保留成功后复制保留的二级子域名地址:
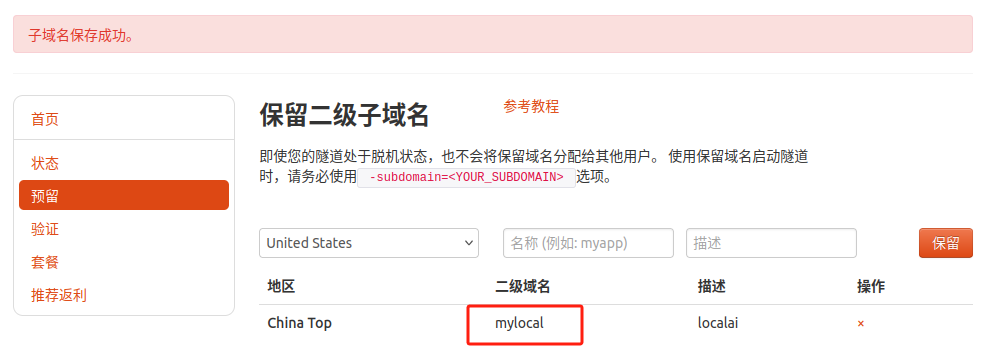
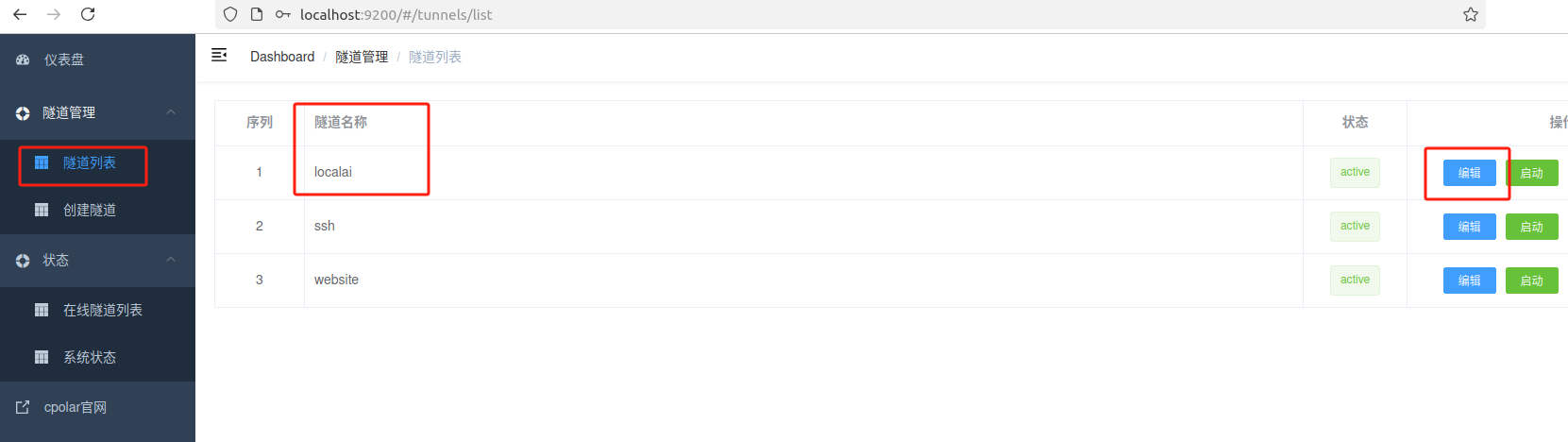
登录 cpolar web UI 管理界面,点击左侧仪表盘的隧道管理——隧道列表,找到所要配置的隧道localai,点击右侧的编辑。
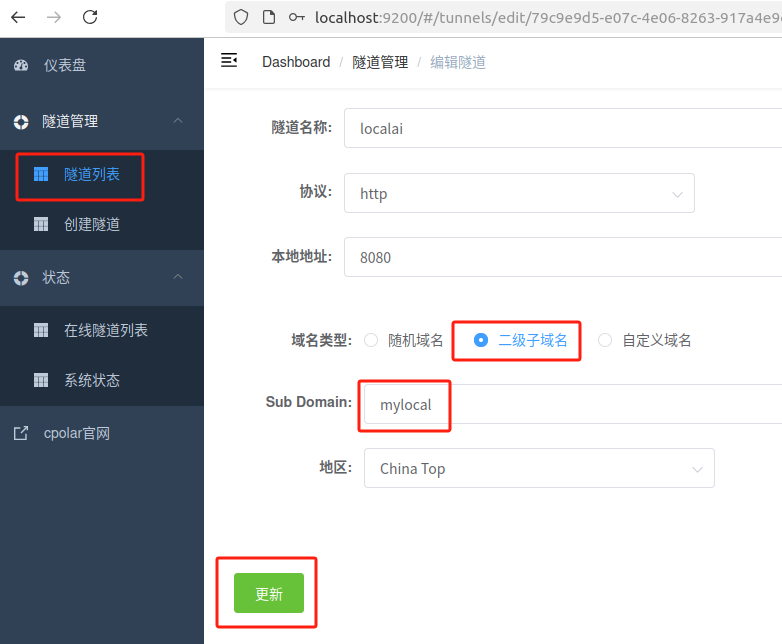
修改隧道信息,将保留成功的二级子域名配置到隧道中
- 域名类型:选择二级子域名
- Sub Domain:填写保留成功的二级子域名
- 地区: China Top
点击更新
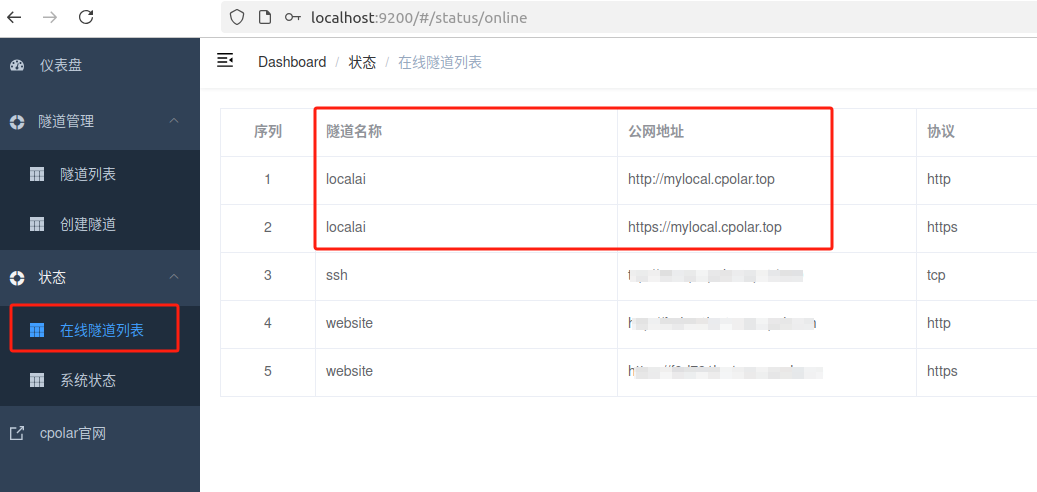
更新完成后,打开在线隧道列表,此时可以看到随机的公网地址已经发生变化,地址名称也变成了保留和固定的二级子域名名称。
最后,我们使用固定的公网地址在任意设备的浏览器中访问,可以看到成功访问本地部署的 LocalAI Web UI 页面,这样一个永久不会变化的二级子域名公网网址即设置好了。
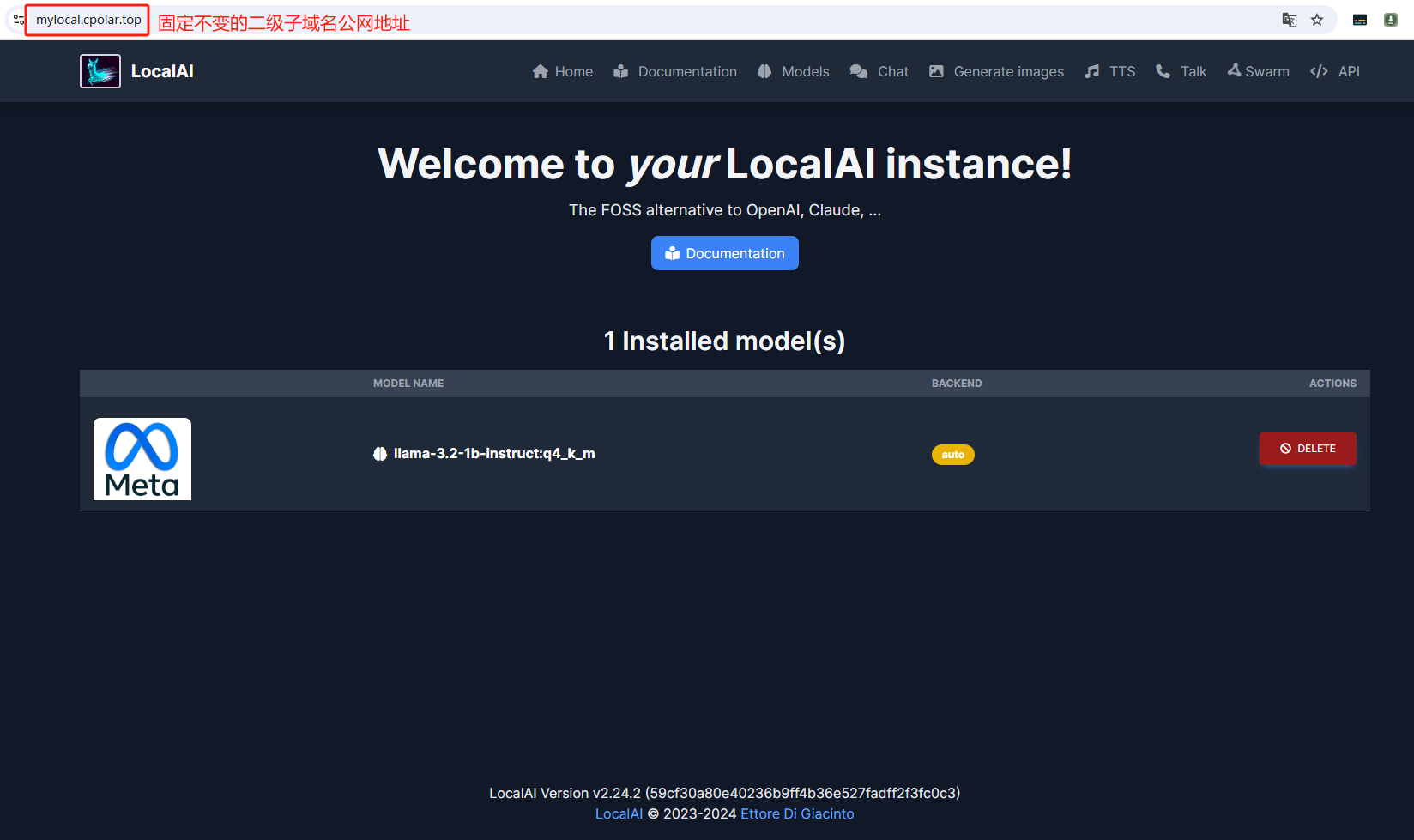
以上就是如何在本地 Ubuntu 系统使用 Docker 快速部署开源 AI 服务 LocalAI,并安装 cpolar 内网穿透工具配置固定不变的二级子域名公网地址,实现随时随地远程在线与 AI 大模型交互的全部流程,感谢您的观看,有任何问题欢迎留言交流。


















 1610
1610

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











