






 OpenAI近期取消了GPT-4Turbo的速率限制,提高了处理能力。文章探讨了速率限制的原因,包括防止滥用、公平访问和管理基础设施负载,并提供了查看和避免速率限制的方法,如指数退避重试策略。
OpenAI近期取消了GPT-4Turbo的速率限制,提高了处理能力。文章探讨了速率限制的原因,包括防止滥用、公平访问和管理基础设施负载,并提供了查看和避免速率限制的方法,如指数退避重试策略。
2月17日,OpenAI在社交平台宣布,取消了GPT-4 Turbo的所有每日限制,并将速率限制提升1倍。现在,每分钟可处理高达150万TPM的数据。
OpenAI这一周的连续王炸组合拳,从ChatGPT增加 “记忆存储”,到视频模型Sora再到GPT-4 Turbo全面取消每日限制,打的谷歌、Meta有点晕头转向抢尽风头。
对于用户来说,只希望巨头之间撕的更凶一些,这样咱们看到的、得到的、用到的也就更多。
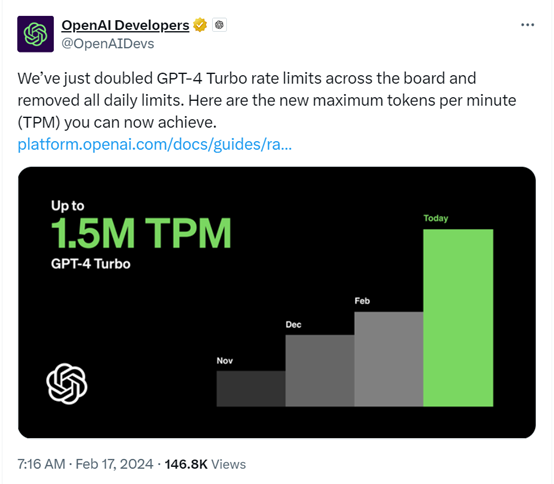
2023年初,OpenAI的估值只有200多亿美元,年底暴涨至800亿美元,很多人认为这也太虚高了。看了前天推出的Sora后,多数人沉默了感觉OpenAI的估值太保守了。
为什么OpenAI要进行速率限制
OpenAI表示,速率限制是其API对开发者或产品用户,在指定时间段内访问OpenAI服务器的次数增加的一种服务限制。这样做主要有以下几个原因。
1)有助于防止 API 被滥用或误用。例如,黑客可能会向 API 提出大量请求,致使服务器超载或宕机。通过设置速率限制,可以防止此类事情发生。
2)速率限制有助于确保,每个人都能公平地访问 API。如果一个人或一个组织频繁提出过多的服务请求,可能会导致其他所有人都无法使用 API。
通过限制单个用户的请求数量,OpenAI 可以确保大多数人都有机会使用 API,而不会出现速度变慢的情况。
3)速率限制可有效帮助 OpenAI 管理其基础设施的总负载。如果对 API 的请求急剧增加,可能会给服务器造成负担,出现服务中断等严重问题。
去年,OpenAI刚发布自定义GPT时,就发生过一次类似事情。
OpenAI的速率限制,有哪些种类
目前,OpenAI一共使用了5种速率限制:RPM(每分钟请求数)、RPD(每天请求数)、TPM(每分钟tokens数量)、TPD(每天tokens数量)和IPM(每分钟图像数量)。

任何一种请求都可能触发速率限制,例如,用户向 ChatCompletions 端点发送 20 个请求,其中只有 100 个tokens,这样就会触发速率限制(假如 RPM 限制是 20);即使你在这20 个请求中没有发送 150k 的tokens。
简单来说,这五种限制,你只要满足一种就会触发。
需要注意的是,速率限制是对组织级别实施的,对个体用户没啥影响。速率限制因所使用的模式而异,组织每月在 API 上的总支出也有"使用限制"。
如何查看自己的限制等级
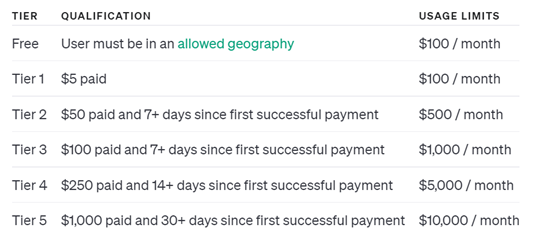
用户可以在账户设置的 "限制 "功能,查看组织的速率和使用限制。
随着你对 OpenAI 的API 的使用以及组织在AP上的费用支出的增加,会自动升级你的使用级别。目前,一共有5个等级。
如何避免速率限制
OpenAI的Cookbook发布了一个攻略,帮助大家避免出现速率限制的错误,以及一个用于在批处理 API 请求时,保持速率限制的示例Python 脚本。
地址:https://cookbook.openai.com/examples/how_to_handle_rate_limits
OpenAI表示,最简单的避免速率限制方法,就是使用“指数退避重试”。
主要通过动态调整重试等待时间,这种机制可有效减少服务器的负载,提高请求成功的可能性,并对系统资源进行高效管理。
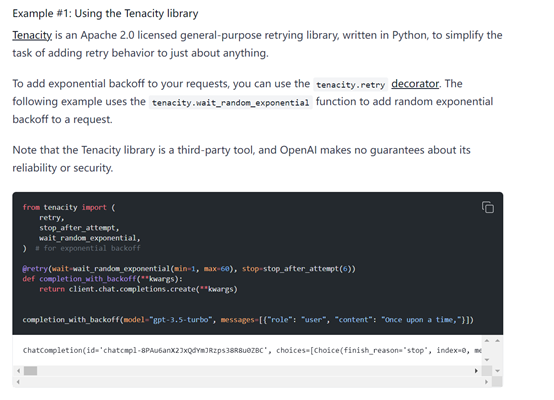
代码展示
指数退避重试能在连续的失败尝试之间引入逐渐增加的延迟,以减少对服务器或网络资源的压力,增加后续尝试成功的可能性。
但使用指数退避重试时,也需要注意几个事项:1)重试次数和最大延迟时间的限制,以防止无休止的重试;2)合理设置最小延迟和倍数,以适应具体应用场景的需求;
3)记录和监控重试事件,以便于故障排查和性能优化;4)考虑请求的幂等性,确保重试不会引起数据错误或不一致。
本文素材来源OpenAI社交平台账号,如有侵权请联系删除

















 911
911

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









