








 超级会员免费看
超级会员免费看

 本文详细介绍了凝聚点动态聚类算法的实现过程,对比了它与模糊聚类在处理大数据量分类时的优缺点。该算法基于距离,通过不断重新计算类别中心并扩大聚类半径来实现分组。文中提供了Matlab版的实现,并讨论了初始化凝聚点的选择、距离计算方法等关键点。
本文详细介绍了凝聚点动态聚类算法的实现过程,对比了它与模糊聚类在处理大数据量分类时的优缺点。该算法基于距离,通过不断重新计算类别中心并扩大聚类半径来实现分组。文中提供了Matlab版的实现,并讨论了初始化凝聚点的选择、距离计算方法等关键点。
http://blog.csdn.net/emilmatthew/article/details/1293608
凝聚點動態聚類算法實現
EmilMatthew (EmilMatthew@126.com)
[ 類別 ]統計分析 , 算法實現
[推薦指數]★★★
[ 摘要 ]本文主要介紹了凝聚點動態聚類算法的實現過程,並分析了其較模糊聚類分析在處理大數據量分類時的一些優點。
[ 關鍵詞 ]凝聚點, 聚類
[Classify] Statistics Analysis , Algorithm Implementation
[ Level ] ★★★
[Abstract] This article mainly introduces the dynamic clustering algorithm based on the condensation points , and also compares its effects with the fuzzy clustering method when encountered with large data sets problem.
[Key Words] Condensation Points , Clustering Method
[0引言]
對於多指標的數據分類問題,有許多種行之有效的分類方法,其中,以基於統計分析的分類方法和基於模糊集理論的模糊聚類分析[1]最為著名。經過實踐表明,模糊聚類分析在應對大數據量(需分類個體>100)分類情況時,若分類指標過小,則會呈現出大類包含元素過多,而小類包含過少元素的不利局面,這樣的分類情況,對於想從大數據量中挑出迥異數據(有可能是無效的測量數據)的情況是有利的,但是不利於需要切實有效分成若干類的正常分類要求。而統計分類方法中有一種凝聚點分類方法,不僅簡單易行,而且分類效果好,可以根據指定的類別個數將數據進行合理的分類,如文本的動態分類等(參[3])。
[1凝聚點聚類算法的描述]
凝聚點聚類算法,仍是一個基於「距離」,並在相應的維度空間上對數據進行分類的算法,此處的「動態」特性指:在聚類的過程中,某已知類別的聚類中心在聚類過程中不斷進行重新計算,逐步擴大聚類半徑,直至聚類完畢。
算法:凝聚點分類算法

[2凝聚點聚類算法的實現(Matlab版)]
關於本算法的實現過程中,有以下幾點值得注意:
2.1對於初始凝聚點的選擇,這裡采用的是找到n維空間中距離空間距原點最近點和最遠點作為兩個類的凝聚點,然後在這兩點之間作線性插值得到其余類的臨時的中間點,再找出實際各點中離臨時中間點最近的點作為其余類的起始凝聚點。顯然,你完全可以根據自己所面對的實際問題中數據的特性以及分類的要求,制定合理的分類策略。這裡的處理方法只是為了使程序更具有通用性。
2.2 程序中重要的數據:
2.2.1)pationGroupLen記錄了各分組內的元素的個數。
2.2.2)indentifyArr則記錄各組中所含元素到應的下標。
分類號由小到大,表示與距所在空間原點的距離由近到遠。
2.3 這裡的距離計算,采用了Eluid距離,當然,還有其它的距離計算方式可以選擇,參[1].
2. 4 顯然,在一次聚類過程中,各類聚集新元素的次序是對聚類結果有影響的。實際問題中可以采取相應的策略,如對於生病者本著從重而不從輕的原則,從較壞的情況開始聚類。這裡為了適應程序通用性,采用的策略是從序號較小類到序號較大類聚類順序。
2.5算法源程序:
%--0.Data Declaration--%
dataArrRow=6;
dataArrCol=4; %attribute num
attributeNum=dataArrCol;
dataNum=dataArrRow;
pationGroupNum=3;
maxLen=1000;
indentifyArr=zeros(pationGroupNum,maxLen);
pationGroupLen=zeros(pationGroupNum);
clusterCenter=zeros(pationGroupNum,attributeNum);
minPoint=zeros(1,attributeNum);
maxPoint=zeros(1,attributeNum);
tmpPoint=zeros(1,attributeNum);
minDis=0;maxDis=0;
minIndex=0;maxIndex=0;
labelArr=zeros(dataNum);
currentClusterRadius=0;
clusterStep=0.05;
clusteredEle=0;
%--1.Normalize the read in data--%
for j=1:dataArrCol
sum = 0;
minVal = dataArr(1, j);
maxVal = dataArr(1, j);
for i = 1 :dataArrRow
sum = sum + dataArr(i, j);
if minVal > dataArr(i, j)
minVal = dataArr(i, j);
elseif maxVal < dataArr(i, j)
maxVal = dataArr(i, j);
end
end
avg = sum / dataArrRow;
s = 0;
for i = 1 : dataArrRow
s = s + (dataArr(i, j) - avg) ^ 2;
end
s = sqrt(s / dataArrRow);
for i = 1 :dataArrRow
dataArr(i, j) = (dataArr(i, j) - avg) / s;
end
minVal = dataArr(1, j);
maxVal = dataArr(1, j);
for i = 1 : dataArrRow
if minVal > dataArr(i, j)
minVal = dataArr(i, j);
elseif maxVal < dataArr(i, j)
maxVal = dataArr(i, j);
end
end
for i = 1 :dataArrRow
dataArr(i, j) = (dataArr(i, j) - minVal) / (maxVal - minVal);
end
end
%--2.Init:Cal For Clustering Center--%
%--2.1 find min and max point out
minPoint=dataArr(1,:);
maxPoint=dataArr(1,:);
minDis=0;
for j=1:attributeNum
minDis=minDis+minPoint(j)^2; %Using Eluid Distance
end
minDis=sqrt(minDis);
maxDis=minDis;
minIndex=1;maxIndex=1;
for i=2:dataNum
tmpDis=0;
for j=1:attributeNum
tmpDis=tmpDis+dataArr(i,j)^2; %Using Eluid Distance
end
tmpDis=sqrt(tmpDis);
if(tmpDis<minDis)
minPoint=dataArr(i,:);
minDis=tmpDis;
minIndex=i;
end
if(tmpDis>maxDis)
maxPoint=dataArr(i,:);
maxDis=tmpDis;
maxIndex=i;
end
end
indentifyArr(1,1)=minIndex;
indentifyArr(pationGroupNum,1)=maxIndex;
labelArr(minIndex)=1;labelArr(maxIndex)=1;
pationGroupLen(1)=1 ;pationGroupLen(pationGroupNum)=1;
%--2.2In this part ,you have many kinds of choice to determine the init cluster center,
% Here ,I use a very normal solution:linear interplotation.
clusterCenter(1,:)=minPoint;
clusterCenter(pationGroupNum,:)=maxPoint;
%Linear Interplotation
for i=2:pationGroupNum-1
clusterCenter(i,:)=minPoint+(maxPoint-minPoint)*((i-1)/(pationGroupNum-1));
end
%find the mid points.
clusteredEle=2;
for k=2:pationGroupNum-1
minDis=10000;
minIndex=-1;
for i=1:dataNum
if(labelArr(i)==0)
tmpDis=0;
for j=1:attributeNum
tmpDis=tmpDis+(dataArr(i,j)-clusterCenter(k,j))^2; %Using Eluid Distance
end
tmpDis=sqrt(tmpDis);
if(tmpDis<minDis)
minIndex=i;
minDis=tmpDis;
end
end
end
if(minIndex~=-1)
indentifyArr(k,1)=minIndex;
labelArr(minIndex)=1;
pationGroupLen(k)=1;
clusteredEle=clusteredEle+1;
clusterCenter(k,:)=dataArr(minIndex,:);
end
end
%--3.Core:Main Part for Clustering--%
currentClusterRadius=0.01;
clusterStep=0.005;
while(clusteredEle<dataNum)%assert here
for k=1:pationGroupNum
for i=1:dataNum
if(labelArr(i)==0)
tmpDis=0;
for j=1:attributeNum
tmpDis=tmpDis+(dataArr(i,j)-clusterCenter(k,j))^2; %Using Eluid Distance
end
tmpDis=sqrt(tmpDis);
if(tmpDis<=currentClusterRadius)
labelArr(i)=1;
pationGroupLen(k)=pationGroupLen(k)+1;
indentifyArr(k,pationGroupLen(k))=i;
clusteredEle=clusteredEle+1;
end
end
end
end
%Recal Cluster Center
for k=1:pationGroupNum
if(pationGroupLen(k)~=0)
tmpPoint=zeros(1,attributeNum);
for j=1:pationGroupLen(k)
tmpPoint=tmpPoint+dataArr(indentifyArr(k,j),:);
end
tmpPoint=tmpPoint/pationGroupLen(k);
clusterCenter(k,:)=tmpPoint;
end
end
currentClusterRadius=currentClusterRadius+clusterStep;
end
2.5算法測試:
采用了三組數據對算法效果進行測試,顯示出本算法較好的分類能力。
下面給出第二組測試數據(334*2)分類後的聚類效果圖:
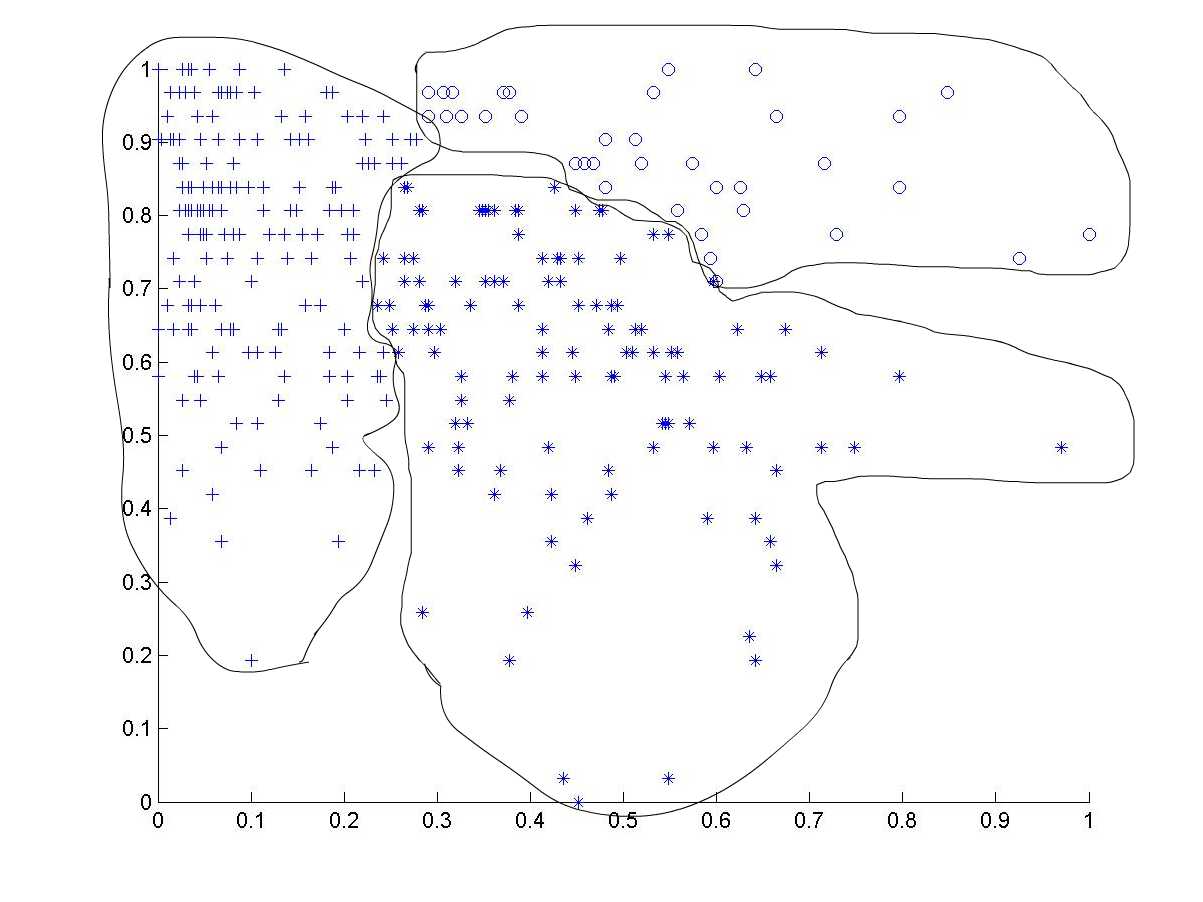
聚類效果圖(+表示第一類,*表示第二類,o表示第三類)
[3後繼工作]
各類之間的相交區域,較難以區分,仍有較大的改進空間。如何通過算法,選擇合理的起始聚類中心,以達到分類效果真實的反映了實際情況,亦有不少的挑戰。(人工神經網絡……)
[參考文獻與網站]
[1] 模糊聚類分析的實現, http://blog.csdn.net/emilmatthew/archive/2006/06/05/774458.aspx
[2] 王式安,數理統計,北京理工大學出版社,1999.
[3] 鄭小慎等,基於凝聚點的文本動態聚類分析,微型機與應用,2004,vol 8.
[4] 肖位樞,模糊數學基礎及其應用,航空工業出版社,1992
程序完成日:06/09/18
文章完成日:06/09/27
[源碼下載]
http://emilmatthew.51.net/EmilPapers/0630CondensationCluster/code.rar
若直接點擊無法下載(或瀏覽),請將下載(或瀏覽)的超鏈接粘接至瀏覽器地( 推薦MYIE或GREENBORWSER)址欄後按回車.若不出意外,此時應能下載.
若下載中出現了問題,請參考:
http://blog.csdn.net/emilmatthew/archive/2006/04/08/655612.aspx
附錄1
本文算法中進行數據歸一化的方法:
















 1349
1349

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









