










SENet这篇文章是CNN based,目前在推荐领域应用也很广泛,正好前几天看了MaskNet的论文,回头看这篇论文时候,发现SE block的作用和Mask block作用相似,顺便记录一下~
SENet论文中给出的结构如下,由于论文是在CNN模型中提出的SE block
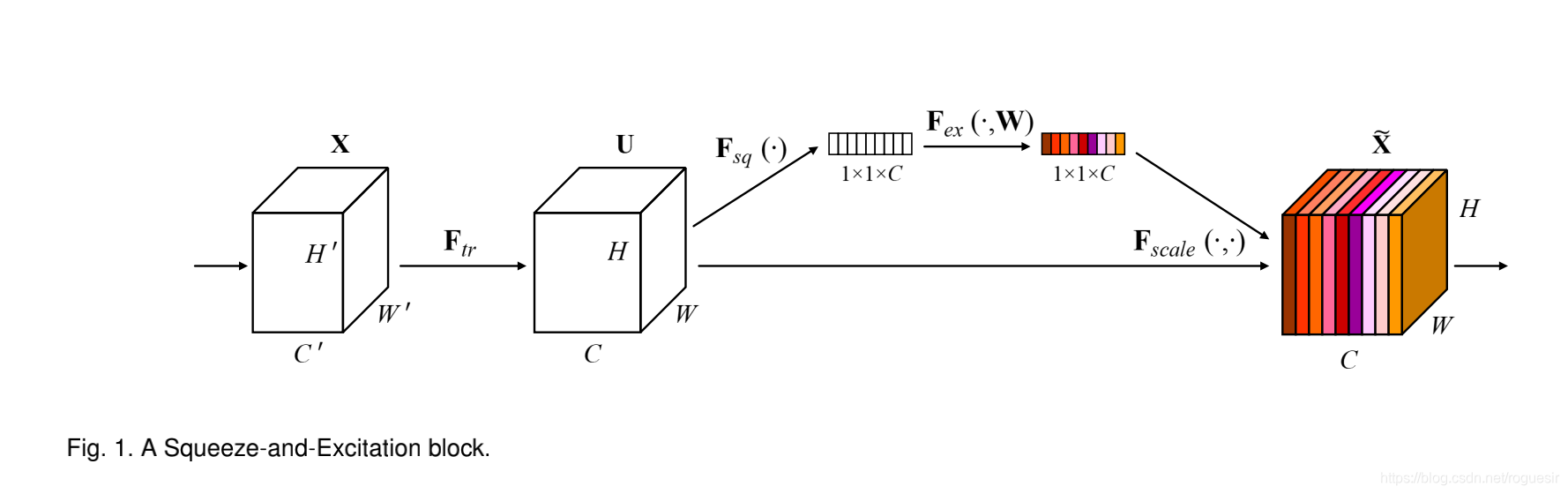
基本的流程如下:
z
c
=
F
s
q
(
u
c
)
=
1
H
×
W
∑
i
=
1
H
∑
j
=
1
W
u
c
(
i
,
j
)
z_c=F_{sq}(u_c)=\frac{1}{H \times W}\sum_{i=1}^{H}{\sum_{j=1}^{W}{u_c(i,j)}}
zc=Fsq(uc)=H×W1i=1∑Hj=1∑Wuc(i,j)
s
=
F
e
x
(
z
,
W
)
=
σ
(
g
(
z
,
W
)
)
=
σ
(
W
2
δ
(
W
1
z
)
)
s=F_{ex}(z,W)=\sigma(g(z,W))=\sigma(W_2\delta(W_1z))
s=Fex(z,W)=σ(g(z,W))=σ(W2δ(W1z))
下面主要介绍应用在推荐系统中的调整版本:
Squeeze
主要作用:Global Information Embedding
在Squeeze阶段,我们对每个特征的Embedding向量进行数据压缩与信息汇总,如下:
z
i
=
F
s
q
(
v
i
)
=
1
k
∑
t
=
1
k
v
i
t
z_i=F_{sq}(v_i)=\frac{1}{k}\sum_{t=1}^{k}{v_i^t}
zi=Fsq(vi)=k1t=1∑kvit
假设某个特征 是k维大小的Embedding,那么我们对Embedding里包含的k维数字求均值,得到能够代表这个特征汇总信息的数值 ,也就是说,把第i个特征的Embedding里的信息压缩到一个数值。
通过Squeeze阶段,对于每个特征
v
i
v_i
vi,都压缩成了单个数值
z
i
z_i
zi ,假设特征Embedding层有
f
f
f个特征,就形成了Squeeze向量
Z
Z
Z,向量大小为
f
f
f 。
Excitation
capture feature-wise dependencies
S
=
F
e
x
(
Z
,
W
)
=
δ
(
W
2
δ
(
W
1
Z
)
)
S=F_{ex}(Z,W)=\delta(W_2\delta(W_1Z))
S=Fex(Z,W)=δ(W2δ(W1Z)) 每个特征以一个Bit来表征,通过MLP来进行交互,通过交互,得出结果:对于当前所有输入的特征,通过相互发生关联,来动态地判断哪些特征重要,哪些特征不重要。这个就和Mask block的目的想通了,都是通过构建一种运算方式,来动态的强化重要特征,弱化噪声或不重要的特征。
因为假设Embedding层有f个特征,那么我们需要保证输出f个权重值,而第二个MLP就是起到将大小映射到f个数值大小的作用。这样,经过两层MLP映射,就会产生f个权重数值,第i个数值对应第i个特征Embedding的权重
a
i
a_i
ai 。我们把每个特征对应的权重
a
i
a_i
ai ,再乘回到特征对应的Embedding里,就完成了对特征重要性的加权操作。
a
i
a_i
ai 数值大,说明SENet判断这个特征在当前输入组合里比较重要,
a
i
a_i
ai 数值小,说明SENet判断这个特征在当前输入组合里没啥用。
所谓动态,指的是比如对于某个特征,在某个输入组合里可能是没用的,但是换一个输入组合,很可能是重要特征。它重要不重要,不是静态的,而是要根据当前输入,动态变化的。

















 4907
4907

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









