







- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊 | 接辅导、项目定制
- 🚀 文章来源:K同学的学习圈子
学习记录
残差网络的提出主要是为了解决模型训练中的梯度爆炸和梯度消失问题。其核心思想是通过恒等映射来解决传统神经网络的深层次问题。具体来说,残差结构通过在前向传播过程中引入shortcut连接,使得输入信息可以直接流向输出,而不会经过任何变换。在实际操作中,这种结构通常以残差块的形式出现。一般需要两到三个卷积块组成。值得注意的是,由于在进行卷积操作时,输入和输出的Feature Map的数量可能会不一样,这时就需要使用 1x1 卷积进行升维或者降维。
ResNet-50顾名思义就是有五十层其中有49个卷积层和一个全连接层。ResNet-50的结构可以被分成四个大部分,每个部分都包含不同数量的卷积层。具体来说,这四个部分分别包含3, 4, 6, 3个小的卷积层块。除此之外,这个网络结构在最开始还有一个单独的卷积层。所以,总的来看,ResNet-50的结构可以表示为:(3+4+6+3)*3+1=49个卷积层和1个全连接层。
我的感觉是,将本来要走的路选择性的跳过一部分,这样就不会太累。我个人感觉残差网络就是在做这件事。
在图像分类和物体识别上,CNN的出现让这个领域出现了高度的繁荣,同时在发展的同时也必然会面临新的挑战。故而残差网络出现了。
就像在目标检测领域的YOLO模块一样,不断更迭,不断解决新出现的问题。
YOLOv1:这是最初的版本,引入了全卷积网络Darknet-19作为其基本架构,并使用softmax分类器处理预选框的类别。
YOLOv2:在v2中,作者提出了Darknet-19,增加了7个新的卷积层,使网络更深更复杂。同时,还引入了anchor box的概念来预测物体的位置。
YOLOv3:在v3中,网络结构进一步扩展到了Darknet-53,而且引入了多尺度预测和三个不同大小的特征图进行检测。
YOLOv4:在v4版本中,模型结构进一步优化为CSPDarknet53,使用了Mish、CIOU_loss等新特性,并在训练策略上进行了一些改进。
YOLOv5的网络结构主要由三部分组成:骨干网络(Backbone)、颈部网络(Neck)和头部网络(Head)。
骨干网络(Backbone):YOLOv5在骨干网络部分使用了新的CSP-Darknet53,它的主要作用是提取特征并不断缩小特征图。这个过程中,通过使用Conv模块、C3模块、SPPF模块等技术手段来提升特征的提取能力。
颈部网络(Neck):颈部网络采用了FPN+PAN的结构,其中FPN用于增强特征的语义信息,PAN则用于提升多尺度特征融合的能力。值得注意的是,Yolov5刚推出时只使用了FPN结构,后来才增加了PAN结构。
头部网络(Head):这部分与YOLOv4中的设计相同,都采用了YOLOv3 Head。其主要功能是对检测目标进行分类和位置预测。
通过对比可以感受出每种模型在对应各自领域的精妙的设计和提出者不断追求更高性能的努力
一、前期准备
1.设置GPU
import tensorflow as tf
gpus = tf.config.list_physical_devices("GPU")
if gpus:
tf.config.experimental.set_memory_growth(gous[0],True)
tf.config.set_visible_devices([gpus[0]],"GPU")
2.导入数据
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
import os,PIL,pathlib
import numpy as np
from tensorflow import keras
from tensorflow.keras import layers,models
data_dir = './J1/'
data_dir = pathlib.Path(data_dir)
3.查看数据
image_count = len(list(data_dir.glob('*/*')))
print("图片总数为: ",image_count)
图片总数为: 565
二、数据预处理
1.加载数据
batch_size = 8
img_height = 224
img_width = 224
train_ds = tf.keras.preprocessing.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="training",
seed = 123,
image_size = (img_height,img_width),
batch_size=batch_size)
Found 565 files belonging to 4 classes.
Using 452 files for training.
val_ds = tf.keras.preprocessing.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="validation",
seed=123,
image_size = (img_height,img_width),
batch_size=batch_size)
Found 565 files belonging to 4 classes.
Using 113 files for validation.
class_names = train_ds.class_names
print(class_names)
[‘Bananaquit’, ‘Black Skimmer’, ‘Black Throated Bushtiti’, ‘Cockatoo’]
2.可视化数据
plt.figure(figsize=(10,5))
plt.suptitle("公众号:K同学啊")
for images,labels in train_ds.take(1):
for i in range(8):
ax = plt.subplot(2,4,i + 1)
plt.imshow(images[i].numpy().astype("uint8"))
plt.title(class_names[labels[i]])
plt.axis("off")

plt.imshow(images[1].numpy().astype("uint8"))
3.再次检查数据
for image_batch,labels_batch in train_ds:
print(image_batch.shape)
print(labels_batch.shape)
break
(8, 224, 224, 3)
(8,)
4.配置数据集
AUTOTUNE = tf.data.AUTOTUNE #tf.data.AUTOTUNE 是 TensorFlow 中的一个常量,用于设置数据预处理的线程数。
#在加载和预处理大量数据时,使用 tf.data.AUTOTUNE 可以自动调整线程数以优化性能.
train_ds = train_ds.cache().shuffle(500).prefetch(buffer_size=AUTOTUNE)#加速获取数据后打乱,将数据加载到内存中
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)#验证集不用打乱
三、构建残差网络模型
from keras import layers
from keras.layers import Input,Activation,BatchNormalization,Flatten
from keras.layers import Dense,Conv2D,MaxPooling2D,ZeroPadding2D,AveragePooling2D
from keras.models import Model
#定义了identity_block,是一种特殊的卷积块,它的作用是将输入直接传递到输出,而不进行任何变换。
def identity_block(input_tensor,kernel_size,filters,stage,block):
filters1,filters2,filters3 = filters #从filters元组中提取出三个滤波器数量。
name_base = str(stage) + block + '_identity_block_' #根据stage和block生成恒等块的名称前缀。
x = Conv2D(filters1,(1,1),name=name_base + 'conv1')(input_tensor) #使用Conv2D层进行第一个卷积操作,将输入张量通过卷积核进行特征提取。
x = BatchNormalization(name=name_base + 'bn1')(x) #对第一个卷积结果进行批量归一化处理。
x = Activation('relu',name=name_base + 'relu1')(x) #使用ReLU激活函数对批量归一化后的结果进行非线性变换。
x = Conv2D(filters2,(1,1),kernel_size,padding='same',name=name_base + 'conv2')(x) #使用Conv2D层进行第二个卷积操作,将上一步的结果通过卷积核进行特征提取
x = BatchNormalization(name=name_base + 'bn2')(x)
x = Activation('relu',name=name_base + 'relu2')(x)
x = Conv2D(filters3,(1,1),name=name_base + 'conv3')(x)
x = BatchNormalization(name=name_base + 'bn3')(x)
x = layers.add([x,input_tensor],name=name_base + 'add')(x) #将第三个卷积结果与输入张量相加,得到恒等块的输出。
x = Activation('relu',name=name_base + 'relu4')(x)
return x
def conv_block(input_tensor,kernel_size,filters,stage,block,strides = (2,2)):
filters1,filters2,filters3 = filters
res_name_base = str(stage) + block + '_conv_block_res_'
name_base = str(stage) + block + '_conv_block_'
x = Conv2D(filters1, (1,1), strides=strides, name=name_base + 'conv1')(input_tensor) #使用Conv2D层进行第一个卷积操作,将输入张量通过卷积核进行特征提取。
x = BatchNormalization(name=name_base + 'bn1')(x) #对第一个卷积结果进行批量归一化处理。
x = Activation('relu',name=name_base + 'relu1')(x) #使用ReLU激活函数对批量归一化后的结果进行非线性变换。
x = Conv2D(filters2, kernel_size, padding='same', name=name_base + 'conv2')(x)
x = BatchNormalization(name=name_base + 'bn2')(x)
x = Activation('relu',name=name_base + 'relu2')(x)
x = Conv2D(filters3, (1,1), name=name_base + 'conv3')(x)
x = BatchNormalization(name=name_base + 'bn3')(x)
shortcut = Conv2D(filters3, (1,1), strides=strides, name=res_name_base + 'conv')(input_tensor)
shortcut = BatchNormalization(name=res_name_base + 'bn')(shortcut)
x = layers.add([x,shortcut],name=name_base + 'add') #将第三个卷积结果与输入张量相加,得到恒等块的输出。
x = Activation('relu',name=name_base + 'relu4')(x)
return x
def ResNet50(input_shape = [224,224,3],classes=1000):
img_input = Input(shape=input_shape)
x = ZeroPadding2D((3,3))(img_input)
x = Conv2D(64, (7,7), strides=(2,2), name='conv1')(x)
x = BatchNormalization(name='bn_conv1')(x)
x = Activation('relu')(x)
x = MaxPooling2D((3,3), strides=(2,2))(x)
x = conv_block(x, 3, [64,64,256], stage=2, block='a', strides=(1,1))
x = identity_block(x, 3, [64,64,256], stage=2, block='b')
x = identity_block(x, 3, [64,64,256], stage=2, block='c')
x = conv_block(x, 3, [128,128,512], stage=3, block='a')
x = identity_block(x, 3, [128,128,512], stage=3, block='b')
x = identity_block(x, 3, [128,128,512], stage=3, block='c')
x = identity_block(x, 3, [128,128,512], stage=3, block='d')
x = conv_block(x, 3, [256,256,1024], stage=4, block='a')
x = identity_block(x, 3, [256,256,1024], stage=4, block='b')
x = identity_block(x, 3, [256,256,1024], stage=4, block='c')
x = identity_block(x, 3, [256,256,1024], stage=4, block='d')
x = conv_block(x, 3, [512,512,2048], stage=5, block='a')
x = identity_block(x, 3, [512,512,2048], stage=5, block='b')
x = identity_block(x, 3, [512,512,2048], stage=5, block='c')
x = AveragePooling2D((7,7),name='avg_pool')(x)
x = Flatten()(x)
x = Dense(classes, activation='softmax',name='fc1000')(x)
model = Model(img_input, x, name='resnet50')
model.load_weights("resnet50_weights_tf_diim_ordering_tf_kernels.h5")
return model
model = ResNet50()
model.summery()
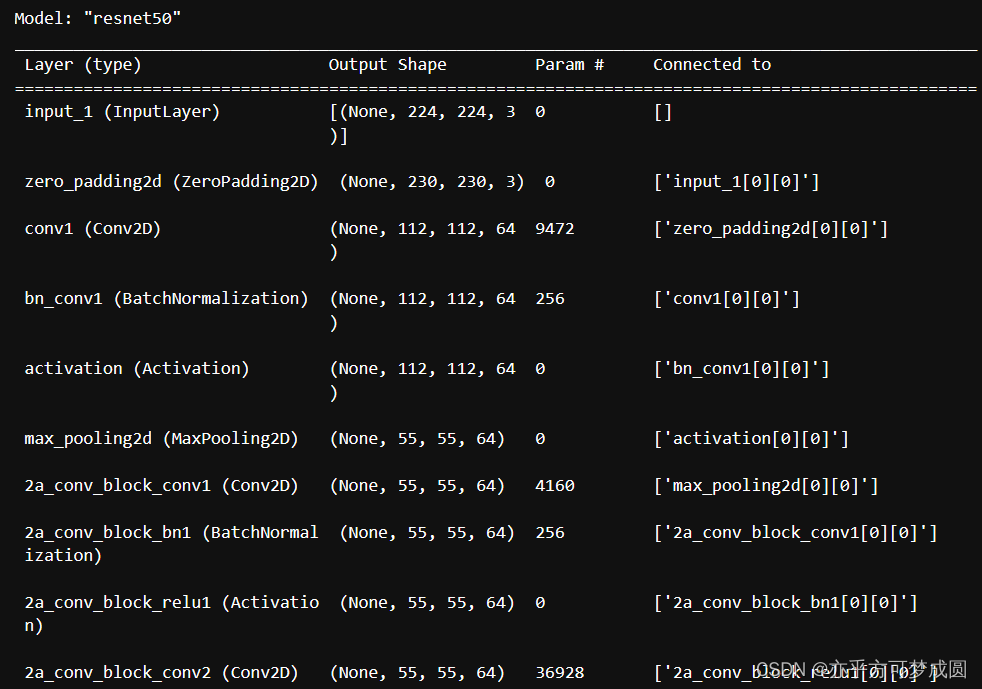
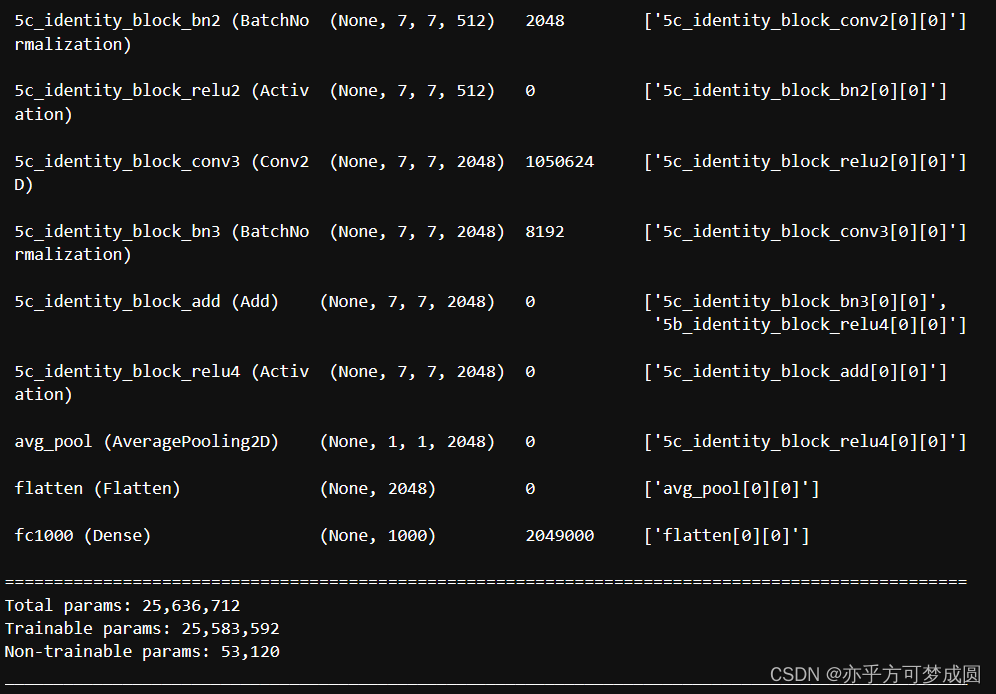
在这里就只截取开始和结尾部分了,因为真的是太太太长了。
四、编译
opt = tf.keras.optimizers.SGD(learning_rate=1e-1)#这里使用了SGD优化器是因为我感觉Adam优化器
#真的很慢,调学习率改变不大,应该是因为数据量太小的原因。个人总结感觉小模型小数据适合用SGD,大模型大数据量适合用Adam。
model.compile(optimizer='sgd',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
SGD优化器的优点包括实现简单,计算效率高,并且对学习率等参数的调整非常敏感,可以快速地收敛到局部最小值点。然而,SGD的缺点也十分明显,例如可能会陷入鞍点,而不是局部极小值点,此外,SGD对初始权值和动量的选择十分敏感,需要人为设定学习率和动量等超参数。因此,SGD优化器通常更适用于数据规模较小、噪声较多或者非凸优化问题。
相比之下,Adam优化器具有许多优点,如自适应学习率、不需要手动设置动量等超参数,能够快速收敛到全局最优解。然而,Adam优化器也有其缺点,例如可能会在训练初期产生震荡,也可能导致超参数调整困难。因此,Adam优化器通常更适用于大规模数据集和复杂模型的训练。
此外,我了解到一个优化器叫RMSprop,兼具Adam和SGD的性能,能自动调节学习率,但是对稀疏特征不太友好。
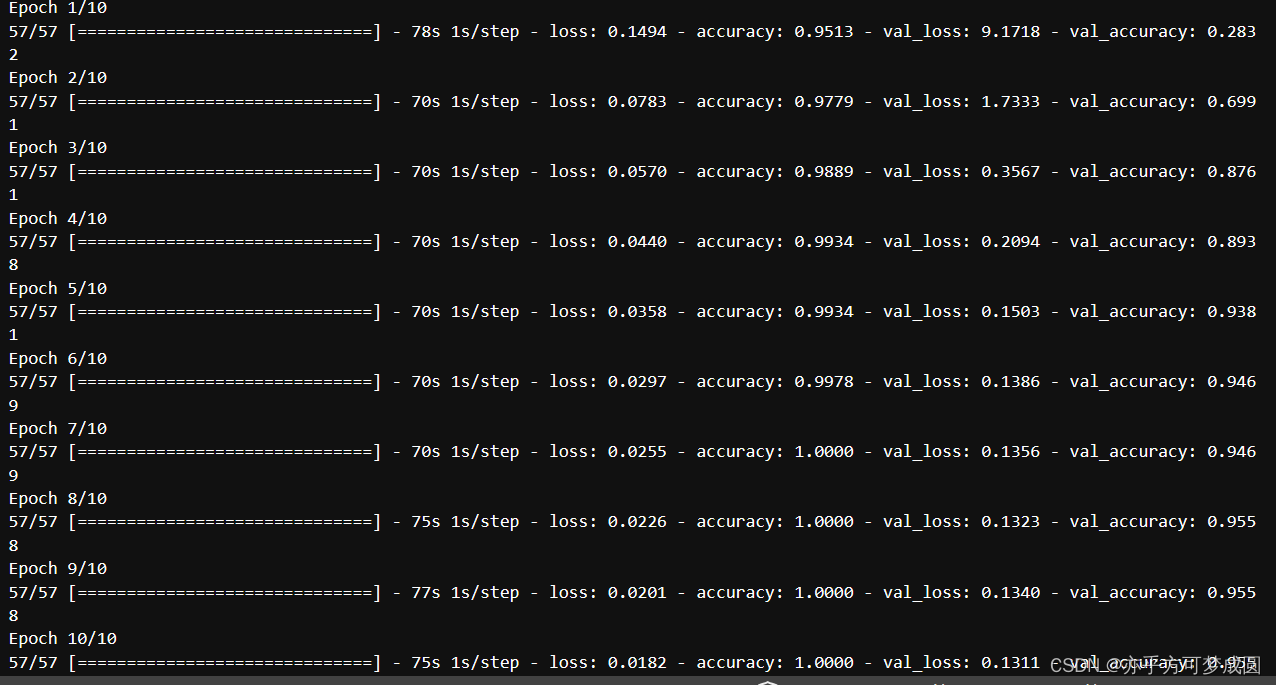
五、训练模型
epochs = 10
history = model.fit(
train.ds,
validation_data=val_ds,
epochs=epochs
)
六、模型评估
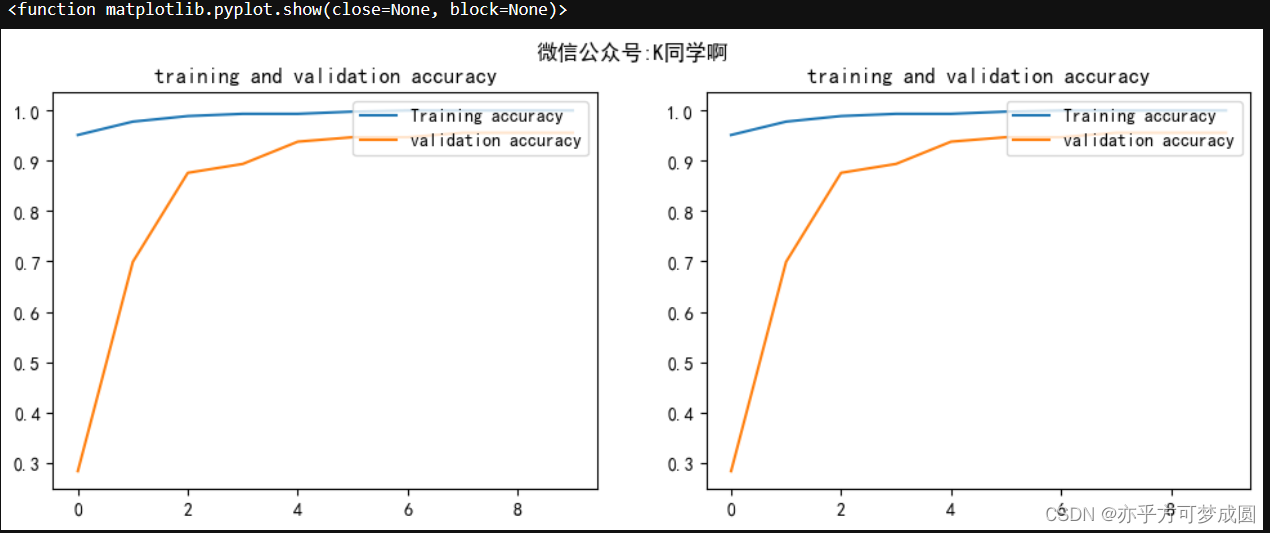
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs_range = range(epochs)
plt.figure(figsize = (12,4))
plt.subplot(1,2,1)
plt.suptitle("微信公众号:K同学啊")
plt.plot(epoch_range, acc, label = "Training accuracy")
plt.plot(epoch_range,val_acc, label = "validation accuracy")
plt.legend(loc = 'uppper right')
plt.title("training and validation accuracy")
plt.subplot(1,2,2)
plt.plot(epoch_range, acc, label = "Training accuracy")
plt.plot(epoch_range,val_acc, label = "validation accuracy")
plt.legend(loc = 'uppper right')
plt.title("training and validation accuracy")
plt.show
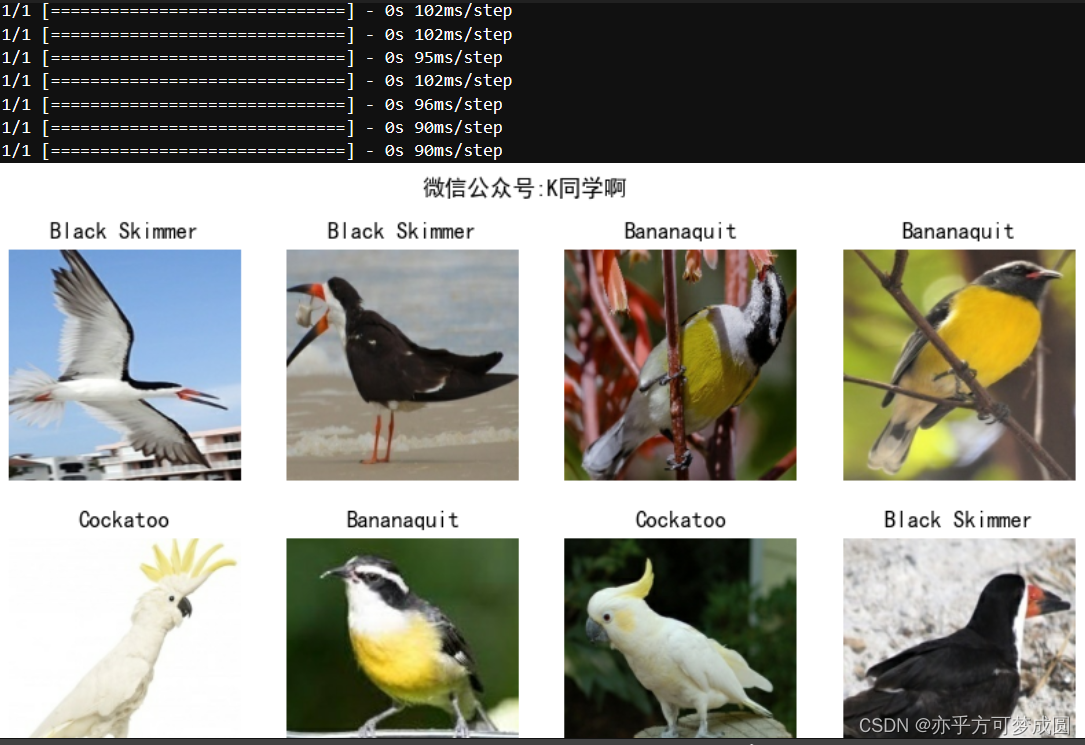
七、预测
plt.figure(figsize=(10,5))
plt.suptitle("微信公众号:K同学啊")
for images,labels in val_ds.take():
for i in range(8):
ax = plt.subplot(2,4,i+1)
plt.imshow(images[i].numpy().astype("unit8"))
img_array = tf.expand_dims(images[i],0)
predictions = model.predict(img_array)
plt.title(class_names[np.argmax(predictions)])
plt.axis("off")
在刚开始训练时,老是挂内核,清理内存根本没效果,算是体验到为什么TensorFlow是适合工业级应用的了。不过好在后来多方打听采取各种措施,这才解决了挂内核的问题。同时也勾起我对TensorFlow和pytorch根本特性不同点的好奇。
首先,从编程范式上看,PyTorch采用命令式编程,可见及所得,调试起来比较方便,对初学者比较友好。相比之下,TensorFlow采用静态图编程,这使得其在大规模分布式训练上有优势,但在一些情况下可能会导致内核挂起的问题。
其次,两者的生态系统不同。PyTorch和TensorFlow都提供了易于部署、管理、分布式训练的工具,从建模的角度讲都是能力很强的框架。然而,它们在生态系统方面的差异可能会影响其在实际应用中的稳定性。
最后,部署阶段的问题也可能影响到内核的稳定性。例如,在将PyTorch模型部署到无Python环境的步骤中,需要使用torchscript,这是一个特殊的语言。这个过程可能会引入新的问题,导致内核挂起。
所以其实还是看自己的选择和理解,用的好,理解到位,根据情况选择的话,各有各的不可替代的优点。















 1359
1359











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









