







基本概念:泛指优一群生长失去正常调控的细胞形成的新生物(neoplasm)。肿瘤细胞是一个累积了不同基因突变的体细胞(这些突变共同导致了细胞增殖的失控,结果形成大量细胞的集合——肿瘤)。肿瘤遗传学是研究肿瘤与遗传关系以及肿瘤发病遗传机理的一门学科。
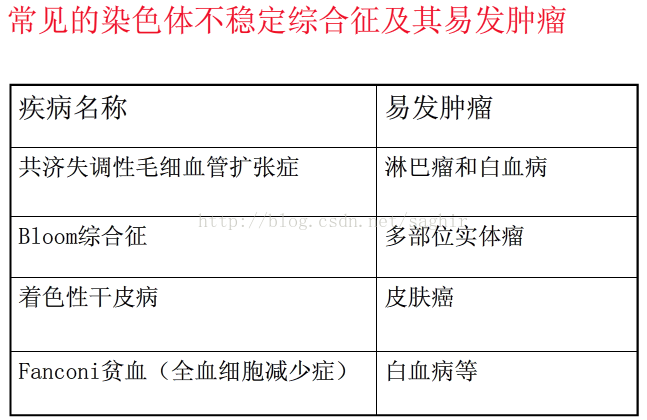
某些遗传性缺陷或疾病具有肿瘤遗传易感性;染色体不稳定综合征的特征:易发生chr断裂和重排;具有AR、AD和XR的遗传特性;具有不同程度的易患肿瘤的倾向。
癌基因(oncogene)是指正常人体和东吴细胞以及致癌病毒体内所固有的能引起细胞恶性转化的核苷酸序列(DNA片段或RNA片段)。细胞癌gene的分类:生长因子类(growth factor)
;信息转导蛋白类(single transduction protein);蛋白激酶类(protein kinase);核内转录因子类(transcription factor)。癌基因可能的激活方式或途径有多重形式:病毒诱导;点突变;癌基因扩增;染色体易位。
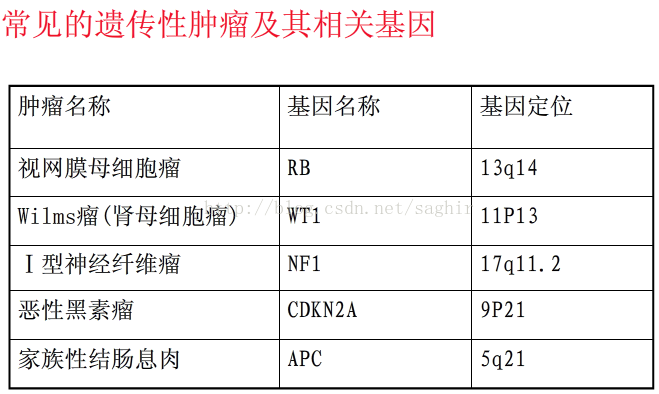
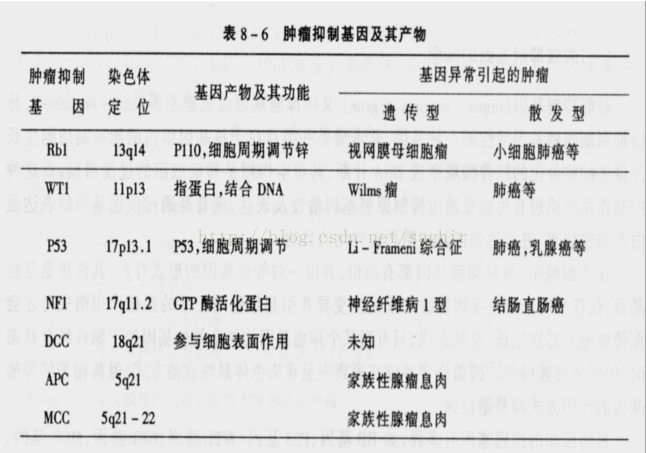
肿瘤抑制基因的种类:Rb、P53、WT、NF1、DCC、APC、MCC等,大多涉及细胞周期调节。抑癌基因是一对等位gene的形式存在;抑癌gene的致癌方式——杂合性丢失(LOH)
1:霍奇金淋巴瘤-免疫疗法
2:卵巢癌-药物组合疗法
3:胃癌-靶向疗法
4:前列腺癌-化疗
5:遗传识别-基因测序
目前常用的癌症检测方法是检测肿瘤标志物:
相关肿瘤
肿瘤标志物
相关肿瘤
肿瘤标志物
相关肿瘤
AFP(甲胎蛋白)
肝细胞癌
CEA (癌胚抗原)
常见的癌症
CA125(癌抗原125)
卵巢癌
CA199(糖基抗原)
胰腺癌、胆管癌、结直肠癌
CA153
乳腺癌
CA724
胃癌
CA50
胰腺、结直肠癌
NSE
小细胞癌
PSA
前列腺癌
SCCA
宫颈鳞癌
CA242
胰腺癌、胃癌
CYFRA21-1
肺鳞癌、宫颈癌、食管癌
基因芯片技术是近年来分子生物学及医学诊断技术的重要进展,该技术是通过把巨大数量的寡核苷酸,肽核苷酸或cDNA固定在一块面积很小的硅片、玻片或尼龙膜上而构成基因芯片。它主要是基于近年来的一种全新的DNA测序方法——杂交测序法应运而生的。由于该技术同时将大量的探针固定于支持物上,所以可以一次性对大量序列进行检测和基因分析,解决了传统的核酸印迹杂交操作复杂,操作序列数量少等缺点。基因芯片技术的突出特点在于其高度的并行性、多样化、微型化和自动化。
目前基因芯片的制备主要采用三种方法:即光蚀刻合成法,压电印刷法,点样法。要了解整个癌变过程中的基因改变,以及癌变在各个阶段中细胞全部基因表达的动态变化,需要研究的不是一个或几个基因,而是整个基因组在从正常到肿瘤的各个阶段中上千个基因表达的动态变化。为抗肿瘤药物作用机制筛查、抗肿瘤药物筛选、抗肿瘤药物毒理学研究、药物基因组学、肿瘤诊断、寻找肿瘤相关基因等各个肿瘤热点领域提供理论依据和技术支持。基因芯片开展癌症诊断也有弊端。首先,DNA芯片上原位合成探针难以避免会有错误核苷酸及杂质混入,使背景信号过高,降低特异性;其次,NOrthern杂交出才差异基因经基因芯片筛选会有漏检;此外,由于缺乏足够的生物信息学支持,目前正确的分析所得到的大量信息仍存在一些困难;基因芯片不能解释蛋白质水平的病理;基因芯片价格昂贵(曹明楠等,2014)。
癌症基因组测序的特定目标(要解决的特定问题):1 发现驱动突变;2描述克隆进化。癌症基因组测序的研究方法(方法学要素):1 匹配的正常基因组;2 研究SNVs的覆盖度;3 双末端读取检测结构变异;重测序验证。癌症基因组的研究类型:1 单样本研究;2 基因组的群体研究;3 多组学研究;4 验证和扩展研究(安云鹤等 2014)。
———————————————————————————————————————
乳腺癌化疗中蒽环类化疗药耐药监测新指标
Desmedt C, Di Leo A, de Azambuja E, et al. Multifactorial approach to predicting resistance to anthracyclines[J]. Journal of clinical oncology, 2011, 29(12): 1578-1586.
试验设计:
ER 阴性病人、无论 HER2是否扩增
时间周期:2003年1月至2008年6月
治疗方案:表柔比星每三周重复一个周期,共4个周期
评估方法:
FISH 法评估 TOP2A(tuopuyigoumei II-α) 的 DNA 扩增和缺失
免疫组织化学法评估 TOP2A 的 蛋白表达量
基因表达谱芯片评估 TOP2A 的 mRNA
基因表达谱芯片评估 TOP2A 共表达基因表达量
ROC 的 AUC判断诊断能力
Gene expression profiles were generated using GeneChip Human
Genome U133 Plus 2.0 (Affymetrix, Santa Clara, CA).
此款芯片包含了47,000个转录本,代表了38,500个明晰的人类基因。数据库来源于GeneBank、dbEST、RefSeq、The sequence clusters在 UniGene database(Build 159 January 25 2003)创建,并通过Washington University EST trace repository和California大学、Santa Cruz Golden-Path人类基因组数据库(April 2001 release)分析比对。此外,有9,921新probe sets代表6,500个新基因,这些基因序列来源于GenBank, dbEST, and RefSeq,Sequence clusters在 UniGene database (Build 159, January 25, 2003)创建,并通过Washington大学EST trace repository 和NCBI human genome assembly(Build 31) 分析比对(博奥生物)。
Affymetrix公司基因表达谱芯片覆盖物种广泛,在真核生物表达谱检测芯片方面产品种类最为齐全。Affymetrix表达谱芯片主要有3’IVT芯片和全转录本芯片,采用短探针(通常25mer长度),多位点设计(对一个基因转录本,设计多个探针,综合起来评价检测信号。
表达谱芯片数据分析
1、数据预处理及归一化
根据不同的芯片平台、芯片类型以及实验设计选择合适的方法进行数据预处理和归一化,常用的方法有RMA,Lowess,percentile等,其目的是消除片内或片间的系统误差,保证芯片内不同点阵间或芯片间具有可比性。
2、样品比较
筛选方法 适用条件 差异表达基因筛选标准
倍数筛选方法 单组样品量小于3的实验 
方差分析或T检验 单组样品量大于等于3的实验 统计检验得到的P value < 0.05且符合倍数筛选规则,并用火山图展示差异基因。
SAM分析 单组样品量大于等于3的实验 FDR<5%且结合倍数筛选方法,用散点图和SAM Plot展示差异表达基因。
3、聚类分析
聚类分析包括监督聚类和非监督聚类,是数据建模和数据挖掘中普遍使用的一种方法,同时也是数据展示的一种手段。它根据数据的数学特征进行分类,并得到样品和基因在表达模式上的关系,从而得出具有生物学意义的结论。聚类分析主要有层次聚类、K 均值聚类等,下图展示了一个层次聚类的结果。
4、趋势分析
趋势分析(时间依赖性基因分析和浓度依赖性基因分析)是一种寻找具有某种表达模式的基因群的分析方法,一般适用于不同时间点或药物浓度梯度等逻辑序列的实验。采用统计检验得到的FDR并结合倍数进行筛选,得到在两组样品中,随时间或浓度梯度而变化的趋势有显著差别的基因群。
5、组织特异性基因分析
组织特异性基因是指仅在某种组织中特异高表达的基因,寻找组织特异性基因可以结合p-value和Fold change筛选出每个组织中特异表达的基因。
6、主成分分析(PCA)
主成分分析是一种多元统计分析方法,采取降维的方式找到各个变量的特征指标,从而对变量进行分类,例如用PCA对组织起源,不同化合物的作用机制或者病理组织类进行分类。















 4597
4597

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









