







以下内容为结合李沐老师的课程和教材补充的学习笔记,以及对课后练习的一些思考,自留回顾,也供同学之人交流参考。
本节课程地址:10 多层感知机 + 代码实现 - 动手学深度学习v2_哔哩哔哩_bilibili
本节教材地址:4.2. 多层感知机的从零开始实现 — 动手学深度学习 2.0.0 documentation (d2l.ai)
本节开源代码:...>d2l-zh>pytorch>chapter_multilayer-perceptrons>mlp-scratch.ipynb
多层感知机的从零开始实现
我们已经在 4.1节 中描述了多层感知机(MLP), 现在让我们尝试自己实现一个多层感知机。 为了与之前softmax回归(3.6节) 获得的结果进行比较, 我们将继续使用Fashion-MNIST图像分类数据集 (3.5节)。
import torch
from torch import nn
from d2l import torch as d2l
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)初始化模型参数
回想一下,Fashion-MNIST中的每个图像由 28×28=784 个灰度像素值组成。 所有图像共分为10个类别。 忽略像素之间的空间结构, 我们可以将每个图像视为具有784个输入特征 和10个类的简单分类数据集。 首先,我们将[实现一个具有单隐藏层的多层感知机, 它包含256个隐藏单元]。 注意,我们可以将这两个变量都视为超参数。 通常,我们选择2的若干次幂作为层的宽度。 因为内存在硬件中的分配和寻址方式,这么做往往可以在计算上更高效。
我们用几个张量来表示我们的参数。 注意,对于每一层我们都要记录一个权重矩阵和一个偏置向量。 跟以前一样,我们要为损失关于这些参数的梯度分配内存。
num_inputs, num_outputs, num_hiddens = 784, 10, 256
# 1个隐藏层,包含256个隐藏单元,均为超参数
W1 = nn.Parameter(torch.randn(
num_inputs, num_hiddens, requires_grad=True) * 0.01)
"""* 0.01,可以将生成的随机张量缩小为原来的1/100倍,即进行了一个缩放操作,
这样可以使得随机初始化的参数具有较小的初始值,并且更接近于0。
有助于提高训练的稳定性和效果。"""
b1 = nn.Parameter(torch.zeros(num_hiddens, requires_grad=True))
W2 = nn.Parameter(torch.randn(
num_hiddens, num_outputs, requires_grad=True) * 0.01)
b2 = nn.Parameter(torch.zeros(num_outputs, requires_grad=True))
# 权重W必须设置为随机,如果初始化为0或1,则隐藏层接收到的输入H相同,并产生相同的输出
# 并且权重的梯度为0,导致反向传播过程权重没有更新,不能进行有效学习
params = [W1, b1, W2, b2]激活函数
为了确保我们对模型的细节了如指掌, 我们将[实现ReLU激活函数], 而不是直接调用内置的relu函数。
def relu(X):
a = torch.zeros_like(X)
return torch.max(X, a)模型
因为我们忽略了空间结构, 所以我们使用reshape将每个二维图像转换为一个长度为num_inputs的向量。 只需几行代码就可以(实现我们的模型)。
def net(X):
X = X.reshape((-1, num_inputs))
# -1为自动获取batch_size
H = relu(X@W1 + b1) # 这里“@”代表矩阵乘法
return (H@W2 + b2)损失函数
由于我们已经从零实现过softmax函数( 3.6节), 因此在这里我们直接使用高级API中的内置函数来计算softmax和交叉熵损失。 回想一下我们之前在 3.7.2节 中 对这些复杂问题的讨论。 我们鼓励感兴趣的读者查看损失函数的源代码,以加深对实现细节的了解。
loss = nn.CrossEntropyLoss(reduction='none')训练
幸运的是,[多层感知机的训练过程与softmax回归的训练过程完全相同]。 可以直接调用d2l包的train_ch3函数(参见 3.6节 ), 将迭代周期数设置为10,并将学习率设置为0.1.
num_epochs, lr = 10, 0.1
updater = torch.optim.SGD(params, lr=lr)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, updater)
为了对学习到的模型进行评估,我们将[在一些测试数据上应用这个模型]。
d2l.predict_ch3(net, test_iter)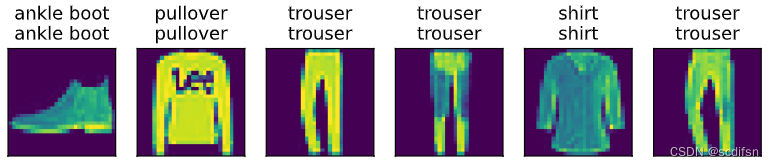
小结
- 手动实现一个简单的多层感知机是很容易的。然而如果有大量的层,从零开始实现多层感知机会变得很麻烦(例如,要命名和记录模型的参数)。
练习
- 在所有其他参数保持不变的情况下,更改超参数
num_hiddens的值,并查看此超参数的变化对结果有何影响。确定此超参数的最佳值。
解:
较小的隐藏层大小可能导致欠拟合,测试准确率较低。
适中的隐藏层大小可能使得模型能够较好地拟合数据,测试准确率相对较高。
过大的隐藏层大小可能导致过度拟合,测试准确率下降。
代码如下:
def net(X):
X = X.reshape((-1, num_inputs))
# -1为自动获取batch_size
H = relu(X@W1 + b1)
return (H@W2 + b2)
import torch
from torch import nn
from d2l import torch as d2l
import matplotlib.pyplot as plt
num_inputs, num_outputs = 784, 10
batch_size = 256
# 定义固定超参数
num_epochs, lr, hidden_layers = 10, 0.1, 1
# 定义可变超参数
num_hiddens = [32, 64, 128, 256, 512, 1024, 2048]
best_num_hiddens = 0
accuracies = []
test_acc = 0
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
for i, hiddens in enumerate(num_hiddens):
W1 = nn.Parameter(torch.randn(
num_inputs, hiddens, requires_grad=True) * 0.01)
b1 = nn.Parameter(torch.zeros(hiddens, requires_grad=True))
W2 = nn.Parameter(torch.randn(
hiddens, num_outputs, requires_grad=True) * 0.01)
b2 = nn.Parameter(torch.zeros(num_outputs, requires_grad=True))
params = [W1, b1, W2, b2]
loss = nn.CrossEntropyLoss(reduction='none')
trainer = torch.optim.SGD(params, lr=lr)
for epoch in range(num_epochs):
d2l.train_epoch_ch3(net, train_iter, loss, trainer)
accuracy = d2l.evaluate_accuracy(net, test_iter)
accuracies.append(accuracy)
# 找到最佳的num_hiddens
if accuracy > test_acc:
test_acc = accuracy
best_num_hiddens = hiddens
plt.figure(figsize=(10, 5))
plt.xlim([0, 2200])
plt.xlabel('num_hiddens')
plt.ylabel('Accuracy')
plt.title('Test accuracy in different num_hiddens')
plt.plot(num_hiddens, accuracies, label='test_acc')
plt.show()
print("Best num_hiddens:", best_num_hiddens)
print("Best test accuracy of best num_hiddens:", test_acc)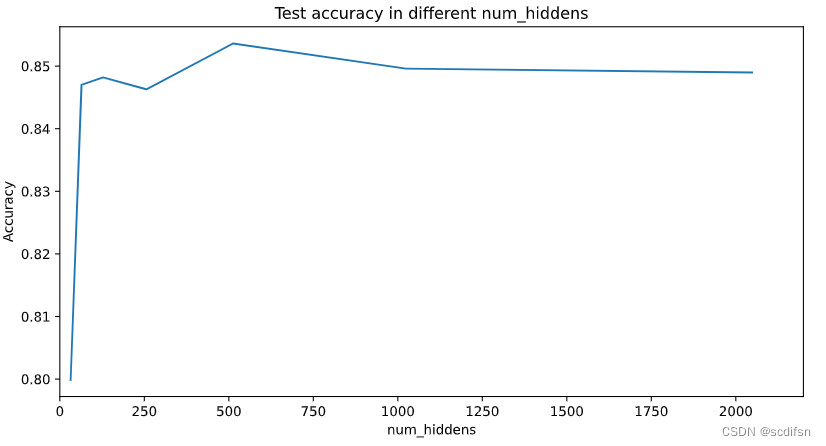
输出结果:
Best num_hiddens: 512
Best test accuracy of best num_hiddens: 0.8536
2. 尝试添加更多的隐藏层,并查看它对结果有何影响。
解:
浅层网络:仅使用一层隐藏层的浅层网络可能无法捕捉到输入数据中的复杂结构和模式。 这可能导致模型的预测能力较弱。
中等层数目:适当增加隐藏层数目可以提高模型的表达能力,使其能够更好地拟合训练数据。 这有助于提高模型的准确性和泛化能力,并在一定程度上避免欠拟合。
多层网络:增加更多隐藏层数目可以进一步增强模型的表达能力,使其能够更好地捕捉到数据中的隐藏模式和特征。 这有助于提高模型的准确性和能够处理更复杂的任务。但如果训练数据量有限,增加隐藏层可能会导致过拟合问题。
代码如下:
#创建多层感知器网络
def net(X):
X = X.reshape((-1, num_inputs))
H = relu(X@W[0] + B[0])
for i in range(1, layers):
H = relu(H@W[i] + B[i])
return (H@W[-1] + B[-1])
import torch
from torch import nn
from d2l import torch as d2l
import matplotlib.pyplot as plt
num_inputs, num_outputs = 784, 10
batch_size = 256
# 定义固定超参数
num_epochs, lr, num_hiddens = 10, 0.1, 512
# 定义可变超参数
hidden_layers = [1, 2, 4, 8]
best_num_layers = 0
accuracies = []
test_acc = 0
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
W = []
B = []
for _, layers in enumerate(hidden_layers):
# 清空上一个循环的参数
W.clear()
B.clear()
for i in range(1, layers + 2):
if i == 1:
w = nn.Parameter(torch.randn(
num_inputs, num_hiddens, requires_grad=True) * 0.01)
W.append(w)
b = nn.Parameter(torch.zeros(num_hiddens, requires_grad=True))
B.append(b)
elif i == layers + 2:
w = nn.Parameter(torch.randn(
num_hiddens, num_outputs, requires_grad=True) * 0.01)
W.append(w)
b = nn.Parameter(torch.zeros(num_outputs, requires_grad=True))
B.append(b)
else:
w = nn.Parameter(torch.randn(
num_hiddens, num_hiddens, requires_grad=True) * 0.01)
W.append(w)
b = nn.Parameter(torch.zeros(num_hiddens, requires_grad=True))
B.append(b)
params = []
for w, b in zip(W, B):
params.append(w)
params.append(b)
loss = nn.CrossEntropyLoss(reduction='none')
trainer = torch.optim.SGD(params, lr=lr)
for epoch in range(num_epochs):
d2l.train_epoch_ch3(net, train_iter, loss, trainer)
accuracy = d2l.evaluate_accuracy(net, test_iter)
accuracies.append(accuracy)
# 找到最佳的hidden_layers
if accuracy > test_acc:
test_acc = accuracy
best_num_layers = layers
plt.figure(figsize=(10, 5))
plt.xlim([0, 10])
plt.xlabel('hidden_layers')
plt.ylabel('Accuracy')
plt.title('Test accuracy in different hidden_layers')
plt.plot(hidden_layers, accuracies, label='test_acc')
plt.show()
print("Best hidden_layers:", best_num_layers)
print("Best test accuracy of best hidden_layers:", test_acc)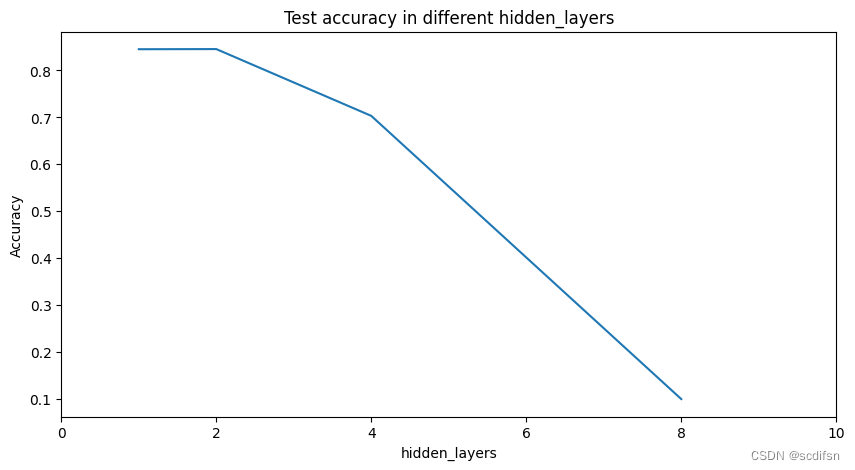
输出结果:
Best hidden_layers: 2
Best test accuracy of best hidden_layers: 0.8452
3. 改变学习速率会如何影响结果?保持模型架构和其他超参数(包括轮数)不变,学习率设置为多少会带来最好的结果?
解:
较小的学习率:较小的学习率可以增加模型训练的稳定性。参数更新的幅度较小,模型更加稳定地收敛到最优解。然而,较小的学习率可能会导致训练过程非常缓慢,尤其是在复杂问题和大型数据集上。
较大的学习率:较大的学习率可以加快模型训练的速度。参数更新的幅度较大,模型可以更快地朝着最优解收敛。然而,如果学习率设置得太大,可能会导致模型在训练过程中发散,无法收敛到最优解。
学习率的选择取决于问题的复杂性、数据集的大小以及模型的架构。
代码如下:
def net(X):
X = X.reshape((-1, num_inputs))
# -1为自动获取batch_size
H = relu(X@W1 + b1) # 这里“@”代表矩阵乘法
return (H@W2 + b2)
import torch
from torch import nn
from d2l import torch as d2l
import matplotlib.pyplot as plt
num_inputs, num_outputs = 784, 10
batch_size = 256
# 定义固定超参数
num_epochs, num_hiddens, hidden_layers = 10, 512, 1
# 定义可变超参数
lrs = [0.01, 0.1, 1, 10]
best_lr = 0
accuracies = []
test_acc = 0
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
for _, lr in enumerate(lrs):
W1 = nn.Parameter(torch.randn(
num_inputs, num_hiddens, requires_grad=True) * 0.01)
b1 = nn.Parameter(torch.zeros(num_hiddens, requires_grad=True))
W2 = nn.Parameter(torch.randn(
num_hiddens, num_outputs, requires_grad=True) * 0.01)
b2 = nn.Parameter(torch.zeros(num_outputs, requires_grad=True))
params = [W1, b1, W2, b2]
loss = nn.CrossEntropyLoss(reduction='none')
trainer = torch.optim.SGD(params, lr=lr)
for epoch in range(num_epochs):
d2l.train_epoch_ch3(net, train_iter, loss, trainer)
accuracy = d2l.evaluate_accuracy(net, test_iter)
accuracies.append(accuracy)
# 找到最佳的lr
if accuracy > test_acc:
test_acc = accuracy
best_lr = lr
plt.figure(figsize=(10, 5))
plt.xlim([0, 11])
plt.xlabel('Learning rate')
plt.ylabel('Accuracy')
plt.title('Test accuracy in different learning rate')
plt.plot(lrs, accuracies, label='test_acc')
plt.show()
print("Best learning rate:", best_lr)
print("Best test accuracy of best learning rate:", test_acc)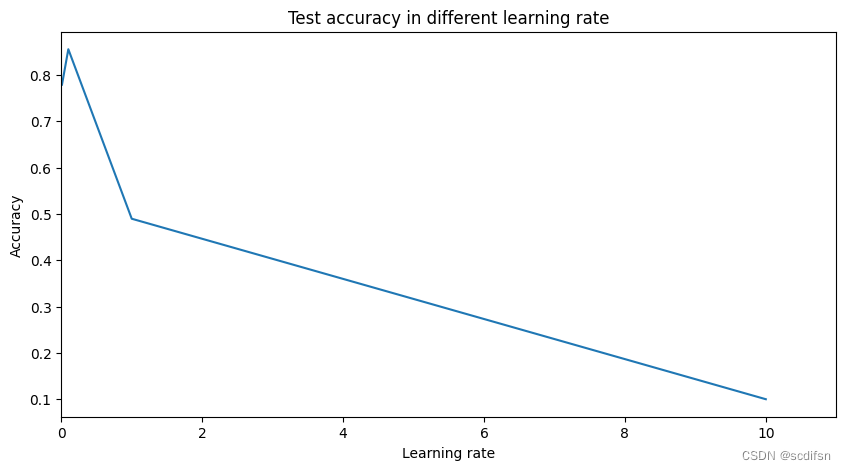
输出结果:
Best learning rate: 0.1
Best test accuracy of best learning rate: 0.8555
4. 通过对所有超参数(学习率、轮数、隐藏层数、每层的隐藏单元数)进行联合优化,可以得到的最佳结果是什么?
解:
代码如下:
#创建多层感知器网络
def net(X):
X = X.reshape((-1, num_inputs))
H = relu(X@W[0] + B[0])
for i in range(1, layers):
H = relu(H@W[i] + B[i])
return (H@W[-1] + B[-1])
import torch
from torch import nn
from d2l import torch as d2l
import itertools
import matplotlib.pyplot as plt
# 定义固定超参数
num_inputs, num_outputs = 784, 10
batch_size = 256
# 定义超参数的搜索范围
lrs = [0.01, 0.1, 1]
num_epochs = [1, 10, 50]
hidden_layers = [1, 2, 3]
num_hiddens = [128, 256, 512]
accuracies = []
hyperparameters = []
best_accuracy = 0
best_hyperparameters = {}
best_iteration = 0
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
W = []
B = []
# 使用嵌套循环遍历所有超参数组合
for i, (lr, epochs, layers, hiddens) in enumerate(itertools.product(
lrs, num_epochs, hidden_layers, num_hiddens)):
# 清空上一个循环的参数
W.clear()
B.clear()
for i in range(1, layers + 2):
if i == 1:
w = nn.Parameter(torch.randn(
num_inputs, hiddens, requires_grad=True) * 0.01)
W.append(w)
b = nn.Parameter(torch.zeros(hiddens, requires_grad=True))
B.append(b)
elif i == layers + 2:
w = nn.Parameter(torch.randn(
hiddens, num_outputs, requires_grad=True) * 0.01)
W.append(w)
b = nn.Parameter(torch.zeros(num_outputs, requires_grad=True))
B.append(b)
else:
w = nn.Parameter(torch.randn(
hiddens, hiddens, requires_grad=True) * 0.01)
W.append(w)
b = nn.Parameter(torch.zeros(hiddens, requires_grad=True))
B.append(b)
params = []
for w, b in zip(W, B):
params.append(w)
params.append(b)
loss = nn.CrossEntropyLoss(reduction='none')
trainer = torch.optim.SGD(params, lr=lr)
for epoch in range(epochs):
d2l.train_epoch_ch3(net, train_iter, loss, trainer)
accuracy = d2l.evaluate_accuracy(net, test_iter)
accuracies.append(accuracy)
hyperparameters.append({'learning_rate': lr,
'num_epochs': epochs,
'hidden_layers': layers,
'num_hiddens': hiddens})
# 更新最佳结果
if accuracy > best_accuracy:
best_accuracy = accuracy
best_hyperparameters = {'learning_rate': lr,
'num_epochs': epochs,
'hidden_layers': layers,
'num_hiddens': hiddens}
best_iteration = i
# 绘制准确性图表
plt.plot(range(len(accuracies)), accuracies)
plt.xlabel('Iteration')
plt.ylabel('Accuracy')
plt.title('Accuracy over Iterations')
plt.show()
print("Best iteration:", best_iteration)
print("Best hyperparameters:", best_hyperparameters)
print("Best accuracy:", best_accuracy)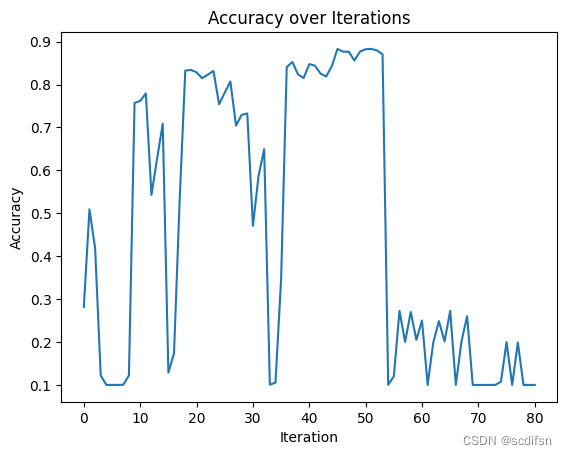
输出结果:
Best iteration: 4
Best hyperparameters: {'learning_rate': 0.1, 'num_epochs': 50, 'hidden_layers': 3, 'num_hiddens': 128}
Best accuracy: 0.8829
5. 描述为什么涉及多个超参数更具挑战性。
解:涉及多个超参数的问题更具挑战性,主要有以下几个原因:
1)组合爆炸:每个超参数都有一定数量的可选值,当超参数的数量增加时,可能的组合数量会呈指数级增长。这导致搜索空间变得非常庞大,需要更多的计算资源和时间才能进行全面搜索。
2)交互效应:超参数之间可能存在交互效应,即它们的组合可能会对模型的性能产生非线性的影响。因此,找到最佳的超参数组合并不仅仅是每个超参数的最佳取值,还需要考虑它们之间的相互作用。
3)评估开销:对于每个超参数组合,都需要进行模型的训练和评估。如果搜索空间很大,需要评估大量的模型,这将带来巨大的计算开销。特别是对于计算资源有限的情况下,可能需要进行合理的优化策略来加速搜索过程。
4)噪声和不确定性:模型的性能很可能受到噪声的影响,即在相同的超参数组合下,多次运行可能会得到不同的结果。因此,在选择最佳超参数时,需要考虑到这种噪声和不确定性。
6. 如果想要构建多个超参数的搜索方法,请想出一个聪明的策略。
解:
代码如下:
import itertools
# 定义超参数的搜索范围
lrs = [0.001, 0.01, 0.1]
num_epochs = [50, 100, 200]
hidden_layers = [1, 2, 3]
num_hiddens = [32, 64, 128]
hyper_params = itertools.product(lrs, num_epochs, hidden_layers, num_hiddens)
# itertools的product函数可以用于计算多个可迭代对象的笛卡尔积。
# 笛卡尔积是指从每个可迭代对象中取一个元素,组合成一个新的元组,所有可能的组合形成一个新的可迭代对象。
for hyper_param in hyper_params:
print(hyper_param)输出结果:
(0.001, 50, 1, 32)
(0.001, 50, 1, 64)
(0.001, 50, 1, 128)
(0.001, 50, 2, 32)
(0.001, 50, 2, 64)
(0.001, 50, 2, 128)
(0.001, 50, 3, 32)
(0.001, 50, 3, 64)
(0.001, 50, 3, 128)
(0.001, 100, 1, 32)
(0.001, 100, 1, 64)
(0.001, 100, 1, 128)
(0.001, 100, 2, 32)
(0.001, 100, 2, 64)
(0.001, 100, 2, 128)
(0.001, 100, 3, 32)
(0.001, 100, 3, 64)
(0.001, 100, 3, 128)
(0.001, 200, 1, 32)
(0.001, 200, 1, 64)
(0.001, 200, 1, 128)
(0.001, 200, 2, 32)
(0.001, 200, 2, 64)
(0.001, 200, 2, 128)
(0.001, 200, 3, 32)
(0.001, 200, 3, 64)
(0.001, 200, 3, 128)
(0.01, 50, 1, 32)
(0.01, 50, 1, 64)
(0.01, 50, 1, 128)
(0.01, 50, 2, 32)
(0.01, 50, 2, 64)
(0.01, 50, 2, 128)
(0.01, 50, 3, 32)
(0.01, 50, 3, 64)
(0.01, 50, 3, 128)
(0.01, 100, 1, 32)
(0.01, 100, 1, 64)
(0.01, 100, 1, 128)
(0.01, 100, 2, 32)
(0.01, 100, 2, 64)
(0.01, 100, 2, 128)
(0.01, 100, 3, 32)
(0.01, 100, 3, 64)
(0.01, 100, 3, 128)
(0.01, 200, 1, 32)
(0.01, 200, 1, 64)
(0.01, 200, 1, 128)
(0.01, 200, 2, 32)
(0.01, 200, 2, 64)
(0.01, 200, 2, 128)
(0.01, 200, 3, 32)
(0.01, 200, 3, 64)
(0.01, 200, 3, 128)
(0.1, 50, 1, 32)
(0.1, 50, 1, 64)
(0.1, 50, 1, 128)
(0.1, 50, 2, 32)
(0.1, 50, 2, 64)
(0.1, 50, 2, 128)
(0.1, 50, 3, 32)
(0.1, 50, 3, 64)
(0.1, 50, 3, 128)
(0.1, 100, 1, 32)
(0.1, 100, 1, 64)
(0.1, 100, 1, 128)
(0.1, 100, 2, 32)
(0.1, 100, 2, 64)
(0.1, 100, 2, 128)
(0.1, 100, 3, 32)
(0.1, 100, 3, 64)
(0.1, 100, 3, 128)
(0.1, 200, 1, 32)
(0.1, 200, 1, 64)
(0.1, 200, 1, 128)
(0.1, 200, 2, 32)
(0.1, 200, 2, 64)
(0.1, 200, 2, 128)
(0.1, 200, 3, 32)
(0.1, 200, 3, 64)
(0.1, 200, 3, 128)

















 2003
2003

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











