







 本文详细解析了深度学习中衡量性能的几个关键概念,包括MIPS、DMIPS、MFLOPS和TOPS,以及它们之间的差异。文章还讨论了这些指标在评估CPU和神经网络推理效率中的作用,并强调了在实际应用中考虑模型、图像大小和批量大小的重要性。
本文详细解析了深度学习中衡量性能的几个关键概念,包括MIPS、DMIPS、MFLOPS和TOPS,以及它们之间的差异。文章还讨论了这些指标在评估CPU和神经网络推理效率中的作用,并强调了在实际应用中考虑模型、图像大小和批量大小的重要性。
1.概述
在深度学习对应的神经推理中经常涉及几个重要概念,TOPS、MIPS、DMIPS,MFLOPS,下文对其做对比说明。
2.概念对比
2.1 MIPS
Million Instructions Per Second的缩写,每秒处理的百万级的机器语言instructions。这是衡量处理速度的一个指标。比如一个Intel 80386 电脑可以每秒处理3 million到5 million机器语言指令,那么我们就说80386是3~5MIPS的CPU。MIPS只是衡量CPU性能的指标。注意:这里的instructions指的是任意类型的,可能有取数据、译码、decimal numbers相关等。
与此同时,MIPS还是一家美国著名的芯片设计公司,是一家设计制造高性能、高档次及嵌入式32位和64位处理器的厂商,它采用精简指令系统计算结构(RISC)来设计芯片。和英特尔采用的复杂指令系统计算结构(CISC)相比,RISC具有设计更简单、设计周期更短等优点,并可以应用更多先进的技术,开发更快的下一代处理器。MIPS是出现最早的商业RISC架构芯片之一,新的架构集成了所有原来MIPS指令集,并增加了许多更强大的功能。1984年,MIPS计算机公司成立。1992年,SGI收购了MIPS计算机公司。1998年,MIPS脱离SGI,成为MIPS技术公司。
MIPS公司设计RISC处理器始于1980s年代初,1986年推出R2000处理器,1988年推R3000处理器,1991年推出第一款64位商用微处器R4000。之后又陆续推出R8000(于1994年)、R10000(于1996年)和R12000(于1997年)等型号。
随后,MIPS公司的战略发生变化,把重点放在嵌入式系统。1999年,MIPS公司发布MIPS32和MIPS64架构标准,为未来MIPS处理器的开发奠定了基础。新的架构集成了所有原来NIPS指令集,并且增加了许多更强大的功能。MIPS公司陆续开发了高性能、低功耗的32位处理器内核 (core)MIPS324Kc与高性能64位处理器内核MIPS64 5Kc。2000年,MIPS公司发布了针对MIPS32 4Kc的版本以及64位MIPS 64 20Kc处理器内核。
2.2 DMIPS
DMIPS是D-MIPS的组合。具体来说:D是Dhrystone的缩写,表示了在Dhrystone这样一种测试方法下的MIPS,Dhrystone是一种整数运算测试程序。以下是在FOLDOC上的解释:
Dhrystone
A short synthetic benchmark program by Reinhold Weicker , intended to be representative of system (integer) programming. It is available in ADA, Pascal and C.The current version is Dhrystone 2.1. The author says, "Relying on MIPS V1.1 (the result of V1.1) numbers can be hazardous to your professional health."
Due to its small size, the memory system outside the cache is not tested. Compilers can too easily optimise for Dhrystone. String operations are somewhat over-represented.
(2002-03-26)
(c) Copyright 1993 by Denis Howe
2.3 MFLOPS
MFLOPS在FOLDOC上的解释如下:
A benchmark which attemps to estimate a system's floating-point "MFLOPS" rating for specific FADD, FSUB, FMUL and FDIV instruction mixes.
是一种基于浮点运算的CPU测试程序,当然,这种测试的结果也以 MFLOPS来加以表示,代表了CPU处理浮点运算的能力。
CPU性能评估采用综合测试程序,较流行的有Whetstone 和 Dhrystone 两种。Dhrystone主要用于测整数计算能力,计算单位就是DMIPS。采用Whetstone 主要用于测浮点计算能力,计算单位就是MFLOPS。
无论是MIPS或MFOPS表示的与decimal numbers相关的指令操作,取数据、译码不包含在内。
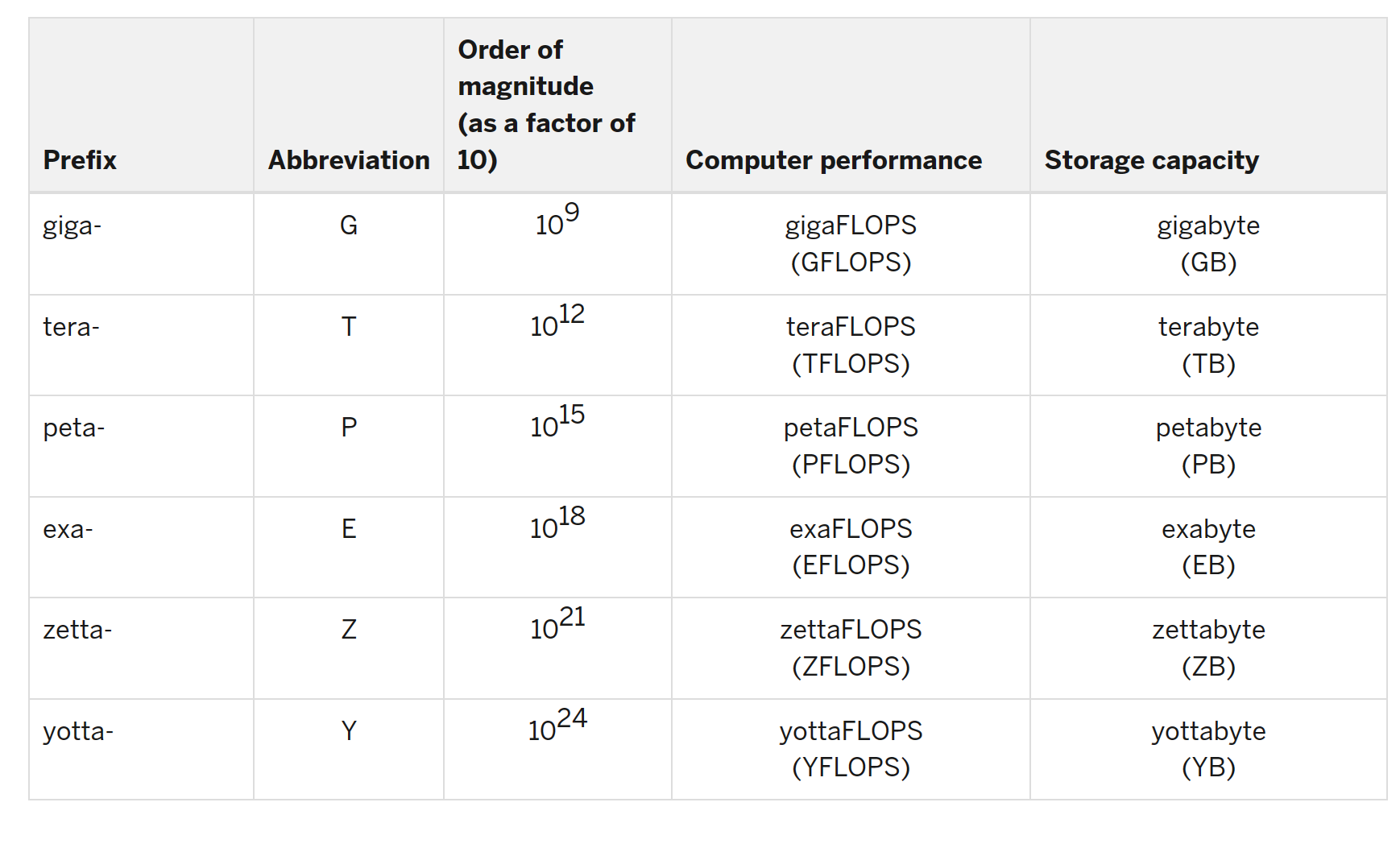
2.4 TOPS
-
TOPS是Tera Operations Per Second的缩写,是计算机的算力单位。1TOPS代表处理器的算力是1s可进行一万亿次(
) 或tera计算操作op,单次运算op,当前一般指矩阵相乘时的乘加运算。
-
与此对应的还有GOPS(Giga Operations Per Second),MOPS(MillionOperation Per Second)算力单位。1GOPS代表处理器每秒钟可进行十亿次(
),1MOPS代表处理器每秒钟可进行一百万次(
)计算操作。
-
TOPS、MOPS、GOPS都是算力单位,都代表每秒钟能计算的次数,可以相互换算。
-
广义上,它可以再任意加上一个数据类型,作为指对在特定数据类型上的处理能力,比如对INT8(8位整型)、FP32(32位双精度)。对于后者这些浮点数类型,单位会增加一个 FL 特指 Float-point,即 TFLOPS。
-
除了表示计算操作的速度快慢,还有类似 TOPS/W 这样的单位来附加说明能耗关系,它表示每瓦电力能产生多少算力。
由于目前市场主流的计算性能对比都在 TOPS (兆亿每秒)这个级别上,所以这个单位被广泛使用。不同算力单位的数量级对比如下。
3.推理效率
目前市场上有数十家公司已经或正在开发用于神经网络推理的 IP 和芯片。几乎每家人工智能公司都提供 TOPS的信息,但几乎没有介绍其他信息。
TOPS是每秒数万亿或万亿次操作。它主要是衡量可实现的最大吞吐量,而不是实际吞吐量的衡量标准。大多数操作是 MAC(multiply/accumulates),因此:
TOPS =(MAC 单元数)x(MAC 操作频率)x 2
因此,更多的 TOPS 意味着更多的硅基面积、更高的成本、更高的功耗,也许还有更高的吞吐量,但这取决于推理加速器的其他方面。
光有TOPS来指代推理效率是不够的。进一步需要知道具体的model、image size、batchsize - 所有这些结合起来才能告诉芯片或 IP 是否满足具体的吞吐量要求。
单位成本的吞吐量Throughput 是给定模型、图像大小、批量大小的推理效率,不同的备选方案之间可以进行综合比较或单项比较。通过查看芯片的市场价格,可以来粗略估算它的推理成本。
所有推理加速器都将有 4 个关键组件,这些组件将构成芯片的大部分:
- MAC(现在假设所有 MAC 都是 INT8,但许多 MAC 都有 INT16 和 BFloat16 选项);
- SRAM(可以是芯片上分布式的或在芯片上是集中式的);
- DRAM(每个 DRAM 需要片上一个 DDR PHY 和大约 100 个额外的 BGA balls);
- 连接计算和内存模块以及控制神经网络模型执行逻辑的互连架构。
更多的MAC、更多的SRAM、更多的DRAM和更多的互连将提高推理效率,但同时也会增加成本。
推理目标是获得最大的推理效率:使用最少的 MAC、SRAM、DRAM 和互连架构,最大限度地提高吞吐量(对于给定模型、图像大小、批量大小)。由于功耗与成本具有大致的相关性:功耗来自MAC、SRAM、DRAM和互连架构 - 其中的每一项增加都将转化为更高的功率。
少量但不是很多公司为其推理加速芯片提供额外的数据:TOPS、DRAM 数量(决定 DRAM 带宽)和 ResNet-50 的吞吐量。单位成本的Throughput可以通过查看Throughput/TOPS、Throughput/SRAM 和Throughput/DRAM 的组合来近似计算得出。
ResNet-50 可能不是最好的测试benchmark ,也没有人在应用程序中实际使用它。但它是唯一有足够数据进行比较的基准。需要注意的是,根据每种体系结构的特征不同,更大的models和更大的图像尺寸的相对性能可能也会发生显著变化。
下面我们将比较 TOPS 从 400(Groq)~0.5 (Jetson Nano)的推理加速性能。由于很难提供想要的全部数据,下表中列出的芯片已发布特定批量大小的 TOPS 和 ResNet-50 性能数据,我们从中也足以看到一些基本的趋势。芯片按从最高 ResNet-50 吞吐量到最低吞吐量的顺序排列,其中两列显示 batch=1 吞吐量和 batch=10++ 吞吐量。如果未给出batch大小,我们假设它是 large batch。

注意,TOPS 和吞吐量具有松相关性,但某些芯片比其他芯片以更少的 TOPS 也可以提供更高的吞吐量。这是因为互联架构、SRAM大小和DRAM数量在决定吞吐量方面也非常重要。
a) Throughput/TOPS:衡量模型使用 MAC 效率的指标
Throughput/TOPS告诉我们芯片使用其MAC的效率如何,至少对于给定的模型而言是这样。
下表中除了 InferX X1 之外,其它芯片都没有表明它们有多少 SRAM(X1 有 8MB)。更多的SRAM和更多的DRAM都将有助于提高MAC的利用率,但需要付出相应代价。因此,最高Throughput/TOPS不一定是最佳单位成本下的Throughput,我们需要知道使用了多少会增加成本的内存。
下表按吞吐量降序显示了 ResNet-50 的Throughput/TOPS。

b) Throughput/DRAM:衡量DRAM利用效率的指标
接下来,可以查看ResNet-50 Throughput/DRAM(DRAM 的数量,而不是千兆位:DRAM 主要用于推理带宽而不是容量)。
下表按 ResNet-50 的Throughput/DRAM 降序排序。

c) Throughput/SRAM:衡量SRAM利用效率的指标
SRAM大小可能与MAC的面积一样大或更大,因此了解SRAM 容量对于估算单位成本Throughput非常重要。不幸的是,很少有芯片提供具体数据:下表中只列出有 2 个,Hailo-8 的 SRAM 大小是微处理器报告的估计值。

通过汇制出Throughput/TOPS vs Throughput/DRAM,以及Throughput/TOPS vs Throughput/SRAM 关系图,可以估算得到单位成本下的Throughput,由此可以得出一些结论。
上述表格中 TOPS 和 DRAM 数据最多——我们在下面绘制了 ResNet-50 batch=1 和 ResNet-50 batch=10+ 的数据。


关于TOPS和SRAM的数据最少,如下图所示,只有 ResNet-50 batch=1对应数据。

4.结论
如何将上述分析方法应用于具体的程序,这主要有三步。
1)首先,需要具体的model-size、image-size和batch-size。
2)然后,通过查看芯片供应商资料手册提供的该model-size、image-size和batch-size下的 INT8 Throughput,以及对应的 TOPSSRAM 的片上megabytes大小和用于实现Throughput的 DRAM 数量。
3)最后,使用上述分析方法绘制结果,可以深入了解应用程序的单位成本对应的Throughput。



















 2387
2387

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











