






最近刚接触图文多模态大模型,想在这儿记录下看过的模型。
自去年底ChatGPT发布后,大模型技术呈井喷式发展态势,学术界和工业界几乎每天都在刷新各个方向的SOTA榜单。随着大模型技术的发展,人们逐渐意识到多模态将是大模型发展的必经之路。其中,图文多模态大模型是一种结合了图像和文本两种模态信息的深度学习模型,本文将重点回顾这一领域的关键进展。
纵观多模态大模型的技术演进,也完全遵循了预训练-微调的整体方案。根据预训练模型中图文模态的交互方式,主要分为以下两种:
双塔结构:代表架构是 CLIP。双塔即一个视觉 Encoder 建模图片信息,一个文本 Encoder 建模文本信息,图像和文本的特征向量可以预先计算和存储,模态交互是通过图像和文本特征向量的余弦相似度来处理。这类模型的优点是处理多模态检索任务,但无法处理复杂的分类任务;
单塔结构:代表架构是ViLT。单塔即一个视觉-文本 Encoder 同时建模图片信息和文本信息,使用 Transformer 模型对图像和文本特征进行交互。这类模型的优点是可以充分地将多模态的信息融合,更擅长做多模态分类任务,检索任务较慢。
CLIP
论文连接:https://arxiv.org/pdf/2103.00020
代码:https://github.com/OpenAI/CLIP
详细论文解读:https://zhuanlan.zhihu.com/p/625165635?utm_id=0
比较好的讲解:https://juejin.cn/post/7264503343996747830
个人理解主要一下工作:
CLIP模型主要由两部分组成:Text Encoder 和 Image Encoder。这两部分可以分别理解成文本和图像的特征编码器。CLIP的预训练过程如下所示
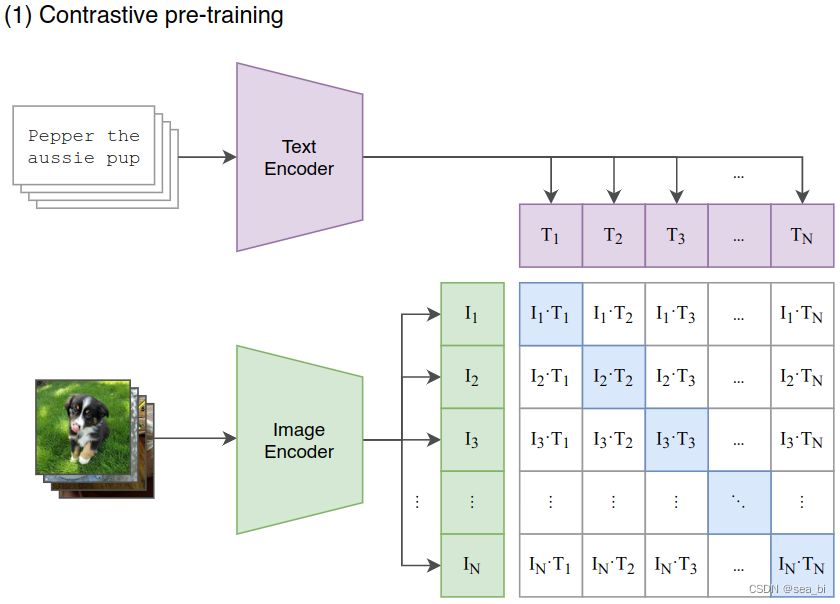

模型训练
https://blog.csdn.net/weixin_44791964/article/details/129941386
VIT(Vision Transformer)
论文连接:https://arxiv.org/abs/2010.11929
代码:https://zhuanlan.zhihu.com/p/640013974
比较好的讲解:https://juejin.cn/post/7254341178258489404
https://blog.csdn.net/qq_37541097/article/details/118242600?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522165495405516781683939853%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fblog.%2522%257D&request_id=165495405516781683939853&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2blogfirst_rank_ecpm_v1~rank_v31_ecpm-1-118242600-null-null.nonecase&utm_term=vit&spm=1018.2226.3001.4450
VIT模型架构
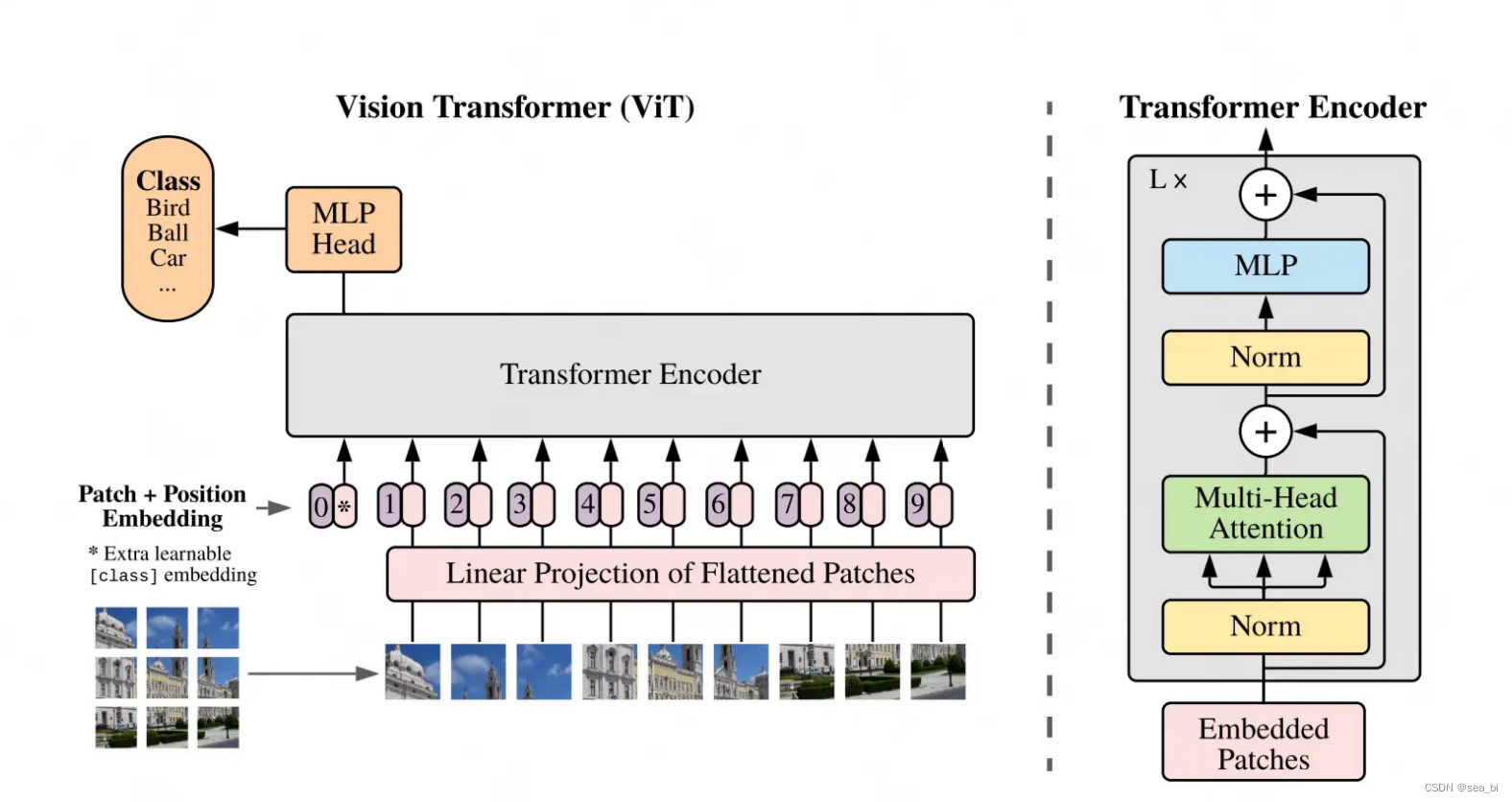
我们先来看左侧部分。
Patch:对于输入图片,首先将它分成几个patch(例如图中分为9个patch),每个patch就类似于NLP中的一个token(具体如何将patch转变为token向量,在下文会细说)。
Position Embedding:每个patch的位置向量,用于指示对应patch在原始图片中的位置。和Bert一样,这个位置向量是learnable的,而并非原始Transformer中的函数式位置向量。同样,我们会在下文详细讲解这一块。
Input: 最终传入模型的Input = patching_emebdding + position embedding,同样,在输入最开始,我们也加一个分类符,在bert中,这个分类符是作为“下一句预测”中的输入,来判断两个句子是否真实相连。在VIT中,这个分类符作为分类任务的输入,来判断原始图片中物体的类别。
右侧部分则详细刻画了Transformer Encoder层的架构,它由L块这样的架构组成。图片已刻画得很详细,这里不再赘述。
总结起来,VIT的训练其实就在做一件事:把图片打成patch,送入Transformer Encoder,然后拿对应位置的向量,过一个简单的softmax多分类模型,去预测原始图片中描绘的物体类别即可。
InternVL
论文解读:https://juejin.cn/post/7355798869110554643?searchId=20240507221443957AC3971BE4EEB1C5C2
Qwen-VL
论文解读:https://arxiv.org/pdf/2308.12966.pdf
比较好的讲解:
https://zhuanlan.zhihu.com/p/653388699
https://blog.csdn.net/qq_35812205/article/details/136586866


















 872
872

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









