







1. 引言
尽管在过去的一年里大模型在计算机视觉领域取得了令人瞩目的快速发展,但是考虑到大模型的训练成本和对算力的依赖,更多切实的思考是如果在我们特定的小规模落地场景下的来辅助我们提升开发和落地效率。本文从相关数据集构造,预刷和生成方向进行相关大模型落地的切入和思考。
闲话少说,我们直接开始吧!
2. 构造数据集
使用这些新的大模型的一个切实想法是保留我们的之前标准训练流程框架,举个栗子,通常在检测领域我们使用的 Yolo 检测器中,我们可以通过生成新的训练图像或生成新的标注来改进我们的训练数据集。具体流程如下:

如上图所示:
-
标准数据集由一组人工标注好的训练集和验证集组成
-
数据集扩充将使用强大的通用大模型来添加自动化标注:
- 对未标记图像进行新的标注 ⇒ 这需要一个已经适合该任务的模型。一般来说大家可以使用一个非常大的通用模型,需要大家提供小样本标注示例或文本提示词,来执行零样本或小样本自动化标注,甚至从现有的人工标注数据中微调非常大的模型。
- 当前已标注文件中添加新任务的标注信息。例如对于2D检测任务可以利用SAM模型来对2D框添加语义分割的mask作为标注信息,可以在训练的时候添加额外的分割监督头。
-
生成式的数据集将由生成的图像及其对应的标注组成。当你构建了一个由图像或文本组成的语义提示后,可以用以生成成千上万个图像及其对应的标注。我们可以直接使用大模型的API生成这些带标注的图像(与人工收集和人工标注相比,成本应该很小)
当我们需要验证训练好的模型在人工标注的数据集上的实际性能时,将验证集与生成或扩充的数据集分开是至关重要的。这意味着,在实践中,即使我们选择了新的生成技术或基础模型,我们仍然需要对真实图像进行一些人工手动标注。
3. 扩充数据集
这个想法是从现有的图像开始,通过丰富标注的标签或使其更容易标注来改进标注结果。一些数据标注平台现在通常使用SAM或DINOv2,通过预先分割图片中的对象来提升标注的效率。

Annotation Tool using SAM

Anylabeling
更多细节可以访问附录里的相关链接。
4. 生成数据集
虽然生成数据集的想法已经存在很长时间了,并最先被广泛应用于训练 LLM,但实际上要针对小规模应用程序开发利用高效生成的数据(自动化标注或纯合成数据)是相当具有挑战性的。
● 不使用基础大模型,而是使用简单的渲染pipeline,例如合成数据集生成示例,通常做法是使用 python 脚本对感兴趣的对象进行裁剪,之后进行随机缩放、旋转并添加到背景中;对应的标注文件也是使用同一处理流程进行创建。在这种方法下,我们创建的图像不完全是真实的照片,但这些图像上的对象和背景是 100% 真实的。

● 许多人使用类似3D 渲染来生成数据,例如如下流程:

基于图像渲染仿真系统,将 3D 模型作为输入,并生成一组训练图像作为输出,通过给定多个渲染参数 θ,该系统将使用3D模型生成多个图像,从所有可能的视角、不同尺寸大小、不同照明条件、不同遮挡量和不同背景等角度来对输出进行建模。相关示例如下:

● 使用人工来进行图像收集和标注既费时又费力。相比之下,合成数据集可以使用生成式模型(例如,DALL-E、Stable Diffusion)免费获得。在本文中,我们展示了可以自动获得由预训练的稳定扩散生成式模型来生成图像的准确语义掩码,该稳定扩散模型在训练过程中仅使用文本-图像对。

上述方法称之为 DiffuMask,它利用了文本和图像之间交叉注意力映射的潜力,这是自然和无缝的,可以将文本驱动的图像合成技术扩展到语义掩码生成。DiffuMask 使用文本引导的交叉注意力信息来定位特定类别的区域,并将其与实用技术相结合,以创建一种新颖的高分辨率像素掩码。这些方法显然有助于降低数据收集和人工标注成本。
5. 注意事项
这里值得一提的是使用 CV 合成技术来构建数据集(例如,将对象粘贴到背景以执行分割任务)的问题在于,数据的质量很大程度上取决于生成图像的质量,因此大家必须投入大量精力来构建正确的渲染步骤。
使用纯生成式模型来生成数据集的成功例子(DeepDetectionModels)还不多,但考虑到最近图像生成式 AI模型的渲染质量和可操纵性,这只是时间的问题。从现有的分割或轮廓开始,可以使用ControlNet来生成我们已经有标签的新图片,但目前尚不清楚它是否适用于分布外的类别(即不是标准的COCO类),或者成像质量是否足够好。
论文(Segmentation-ControlNet)提出了一个类似的想法,即修改现有的标记图片,以生成共享分割掩码的新图片,从而实现超强的语义数据增强。

论文DeepDetectionModels 提出了一个通过微调预训练的稳定扩散模型来生成合成数据集的框架,然后对合成数据集进行手动注释,并用于训练各种目标检测模型。图示如下:

6. 知识蒸馏
我们通过使用人类手动标注数据集训练模型来进行现代计算机视觉的方式即将被新的大型基础模型彻底改变。大型基础模型有时具有轻量级的版本,专为在低端服务器甚至嵌入式应用程序上进行推理而设计。然而,对于许多应用程序来说,它们仍然太大了。在短期实时应用上,我们不会使用超过 500M+ 参数量的视觉 `transformer` ,而是使用更小、更专业的模型。 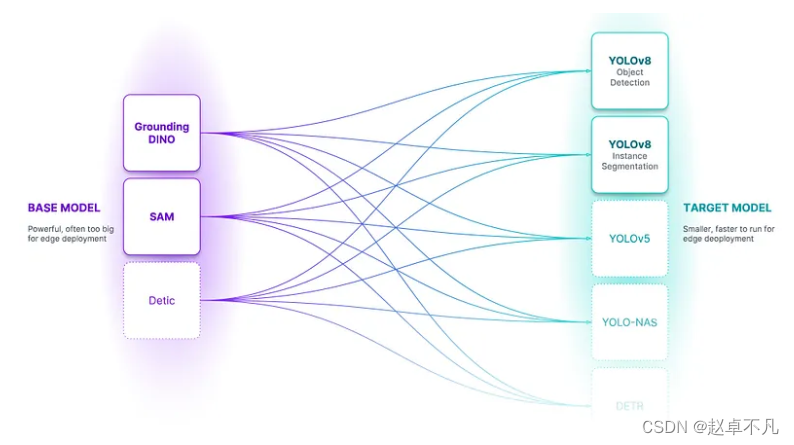
尽管如此,即使是小规模推理和低算力资源上的开发,我们也会利用大型基础模型来作为辅助,要么通过使用 API/本地推理直接调用这些模型,要么使用其中一些模型学到的先验知识。今天介绍的主要是通过数据标注来展开,其实也可以通过其他知识转移的方式——例如通过蒸馏或 LoRA。对于检测或分割任务,没有标准流程或广泛的首选方法来从这些大型或生成式模型中转移这些知识,但它可能会在 2024 年普及!
7. CNN和Transformer之争
大多数小规模的 CV 应用程序都涉及 CNN(卷积神经网络),而最近所有大型 AI 系统都涉及 Transformers。我们是否应该从CNN换到Transformer呢?
- 首先上述问题并没有确定的答案。Transformer 无处不在,因为它们可以更好地随着数据量大小和参数数量的扩展而扩展,这是所有新的大型生成式 AI 系统的先决条件。此外,它们还可以更好地集成多模态输入,因为我们可以轻松地将文本信息和图像特征进行融合,并让交叉注意力机制混合这些信息以产生良好的输出。最后,LoRA 等技术的发展也需要transformer架构。
- 其次对于低端设备上的大多数实时应用来说,这些大型transformer模型在效率方面还不具备与经典卷积网络相比的竞争力!然而,由于许多人正试图加速边缘设备上transformer结构的推理,这种情况可能会在不久的将来发生改变。
8. 总结
本文重点介绍了在大模型发展背景下,如何在日常开发中合理利用大模型的能力来构建合成数据集和丰富数据集的标注类别等应用,同时随着技术的发展,未来大模型在日常开发中会带来更多的应用和落地点,希望大家也可以结合自己具体的业务来思考如何和现有大模型进行结合。
您学废了嘛?
















 287
287

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











