









- 大模型的定义
大模型是指具有大规模参数和复杂计算结构的机器学习模型。这些模型通常由深度神经网络构建而成,拥有数十亿甚至数千亿个参数。大模型的设计目的是为了提高模型的表达能力和预测性能,能够处理更加复杂的任务和数据。大模型在各种领域都有广泛的应用,包括自然语言处理、计算机视觉、语音识别和推荐系统等。大模型通过训练海量数据来学习复杂的模式和特征,具有更强大的泛化能力,可以对未见过的数据做出准确的预测。
ChatGPT对大模型的解释更为通俗易懂,也更体现出类似人类的归纳和思考能力:大模型本质上是一个使用海量数据训练而成的深度神经网络模型,其巨大的数据和参数规模,实现了智能的涌现,展现出类似人类的智能。
那么,大模型和小模型有什么区别?
小模型通常指参数较少、层数较浅的模型,它们具有轻量级、高效率、易于部署等优点,适用于数据量较小、计算资源有限的场景,例如移动端应用、嵌入式设备、物联网等。
而当模型的训练数据和参数不断扩大,直到达到一定的临界规模后,其表现出了一些未能预测的、更复杂的能力和特性,模型能够从原始训练数据中自动学习并发现新的、更高层次的特征和模式,这种能力被称为“涌现能力”。而具备涌现能力的机器学习模型就被认为是独立意义上的大模型,这也是其和小模型最大意义上的区别。
相比小模型,大模型通常参数较多、层数较深,具有更强的表达能力和更高的准确度,但也需要更多的计算资源和时间来训练和推理,适用于数据量较大、计算资源充足的场景,例如云端计算、高性能计算、人工智能等。
- 大模型相关概念区分:
大模型(Large Model,也称基础模型,即Foundation Model),是指具有大量参数和复杂结构的机器学习模型,能够处理海量数据、完成各种复杂的任务,如自然语言处理、计算机视觉、语音识别等。
超大模型:超大模型是大模型的一个子集,它们的参数量远超过大模型。
大语言模型(Large Language Model):通常是具有大规模参数和计算能力的自然语言处理模型,例如 OpenAI 的 GPT-3 模型。这些模型可以通过大量的数据和参数进行训练,以生成人类类似的文本或回答自然语言的问题。大型语言模型在自然语言处理、文本生成和智能对话等领域有广泛应用。
GPT(Generative Pre-trained Transformer):GPT 和ChatGPT都是基于Transformer架构的语言模型,但它们在设计和应用上存在区别:GPT模型旨在生成自然语言文本并处理各种自然语言处理任务,如文本生成、翻译、摘要等。它通常在单向生成的情况下使用,即根据给定的文本生成连贯的输出。
ChatGPT:ChatGPT则专注于对话和交互式对话。它经过特定的训练,以更好地处理多轮对话和上下文理解。ChatGPT设计用于提供流畅、连贯和有趣的对话体验,以响应用户的输入并生成合适的回复。
- 大模型的发展历程
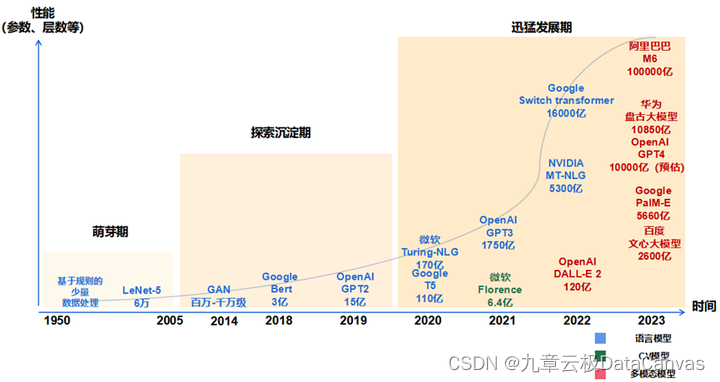
萌芽期(1950-2005):以CNN为代表的传统神经网络模型阶段
· 1956年,从计算机专家约翰·麦卡锡提出“人工智能”概念开始,AI发展由最开始基于小规模专家知识逐步发展为基于机器学习。
· 1980年,卷积神经网络的雏形CNN诞生。
· 1998年,现代卷积神经网络的基本结构LeNet-5诞生,机器学习方法由早期基于浅层机器学习的模型,变为了基于深度学习的模型,为自然语言生成、计算机视觉等领域的深入研究奠定了基础,对后续深度学习框架的迭代及大模型发展具有开创性的意义。
探索沉淀期(2006-2019):以Transformer为代表的全新神经网络模型阶段
· 2013年,自然语言处理模型 Word2Vec诞生,首次提出将单词转换为向量的“词向量模型”,以便计算机更好地理解和处理文本数据。
· 2014年,被誉为21世纪最强大算法模型之一的GAN(对抗式生成网络)诞生,标志着深度学习进入了生成模型研究的新阶段。
· 2017年,Google颠覆性地提出了基于自注意力机制的神经网络结构——Transformer架构,奠定了大模型预训练算法架构的基础。
· 2018年,OpenAI和Google分别发布了GPT-1与BERT大模型,意味着预训练大模型成为自然语言处理领域的主流。在探索期,以Transformer为代表的全新神经网络架构,奠定了大模型的算法架构基础,使大模型技术的性能得到了显著提升。
迅猛发展期(2020-至今):以GPT为代表的预训练大模型阶段
· 2020年,OpenAI公司推出了GPT-3,模型参数规模达到了1750亿,成为当时最大的语言模型,并且在零样本学习任务上实现了巨大性能提升。随后,更多策略如基于人类反馈的强化学习(RHLF)、代码预训练、指令微调等开始出现, 被用于进一步提高推理能力和任务泛化。
· 2022年11月,搭载了GPT3.5的ChatGPT横空出世,凭借逼真的自然语言交互与多场景内容生成能力,迅速引爆互联网。
· 2023年3月,最新发布的超大规模多模态预训练大模型——GPT-4,具备了多模态理解与多类型内容生成能力。在迅猛发展期,大数据、大算力和大算法完美结合,大幅提升了大模型的预训练和生成能力以及多模态多场景应用能力。如ChatGPT的巨大成功,就是在微软Azure强大的算力以及wiki等海量数据支持下,在Transformer架构基础上,坚持GPT模型及人类反馈的强化学习(RLHF)进行精调的策略下取得的。
网络安全学习路线
这是一份网络安全从零基础到进阶的学习路线大纲全览,小伙伴们记得点个收藏!

阶段一:基础入门
该阶段学完即可年薪15w+
网络安全导论
渗透测试基础
网络基础
操作系统基础
Web安全基础
数据库基础
编程基础
CTF基础

阶段二:技术进阶(到了这一步你才算入门)
该阶段学完年薪25w+
弱口令与口令爆破
XSS漏洞
CSRF漏洞
SSRF漏洞
XXE漏洞
SQL注入
任意文件操作漏洞
业务逻辑漏洞

阶段三:高阶提升
该阶段学完即可年薪30w+
反序列化漏洞
RCE
综合靶场实操项目
内网渗透
流量分析
日志分析
恶意代码分析
应急响应
实战训练

阶段四:蓝队课程
攻防兼备,年薪收入可以达到40w+
蓝队基础
蓝队进阶
该部分主攻蓝队的防御,即更容易被大家理解的网络安全工程师。

阶段五:面试指南&阶段六:升级内容

需要上述路线图对应的网络安全配套视频、源码以及更多网络安全相关书籍&面试题等内容
同学们可以扫描下方二维码获取哦!

学习教程
第一阶段:零基础入门系列教程

第二阶段:学习书籍

第三阶段:实战文档

尾言
最后,我其实要给部分人泼冷水,因为说实话,上面讲到的资料包获取没有任何的门槛。
但是,我觉得很多人拿到了却并不会去学习。
大部分人的问题看似是“如何行动”,其实是“无法开始”。
几乎任何一个领域都是这样,所谓“万事开头难”,绝大多数人都卡在第一步,还没开始就自己把自己淘汰出局了。
如果你真的确信自己喜欢网络安全/黑客技术,马上行动起来,比一切都重要。

特别声明:
此教程为纯技术分享!本书的目的决不是为那些怀有不良动机的人提供及技术支持!也不承担因为技术被滥用所产生的连带责任!本书的目的在于最大限度地唤醒大家对网络安全的重视,并采取相应的安全措施,从而减少由网络安全而带来的经济损失。!!!


















 1609
1609

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









