






在我最近发布关于如何构建自己的 RAG 并在本地运行它的帖子之后。今天,我们更进一步,不仅实现了大型语言模型的对话能力,还增加了听力和口语能力。这个想法很简单:我们将创建一个语音助手,让人想起标志性钢铁侠电影中的贾维斯或星期五,它可以在你的计算机上离线运行。
由于这是一个入门教程,我将用 Python 实现它,并使其足够简单,适合初学者。最后,我将提供一些关于如何扩展应用程序的指导。
完整代码可在github找到。

NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - AI模型在线查看 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割
1、Techstack
首先,设置一个虚拟 Python 环境。我们有多种选择,包括 pyenv、virtualenv、poetry 和其他具有类似用途的库。就我个人而言,由于个人喜好,我将在本教程中使用 Poetry。
以下是需要安装的几个关键库:
- rich:用于视觉上吸引人的控制台输出。
- openai-whisper:用于语音到文本转换的强大工具。
- suno-bark:用于文本到语音合成的尖端库,确保高质量的音频输出。
- langchain:用于与大型语言模型 (LLM) 交互的简单库。
- sounddevice、pyaudio 和 Speechrecognition:用于音频录制和播放的必备工具。
有关依赖项的详细列表,请参阅此处的链接。
这里最关键的组件是大型语言模型 (LLM) 后端,我们将使用 Ollama。Ollama 被广泛认为是一种流行的离线运行和服务 LLM 的工具。基本上,你只需下载 Ollama 应用程序,提取喜欢的模型,然后运行它即可。
2、架构
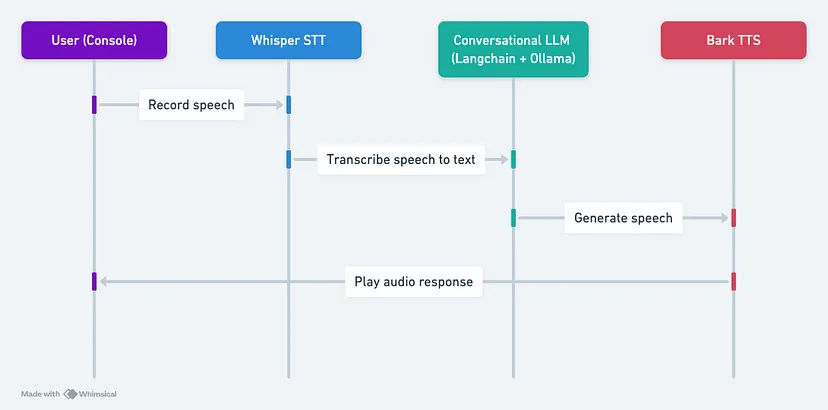
好的,如果一切设置完毕,让我们继续下一步。以下是我们应用程序的总体架构,它基本上包含 3 个主要组件:
- 语音识别:利用 OpenAI 的 Whisper,我们将口语转换为文本。Whisper 对各种数据集的训练确保了它能够熟练处理各种语言和方言。
- 对话链:对于对话功能,我们将使用 Llama-2 模型的 Langchain 接口,该模型使用 Ollama 提供服务。此设置可确保无缝且引人入胜的对话流程。
- 语音合成器:文本到语音的转换是通过 Bark 实现的,Bark 是 Suno AI 最先进的模型,以其逼真的语音制作而闻名。
工作流程很简单:录制语音、转录为文本、使用 LLM 生成响应,并使用 Bark 发出响应的声音。
2、实现
实施首先要基于 Bark 制作 TextToSpeechService,结合从文本合成语音的方法以及无缝处理较长文本输入的方法,如下所示:
import nltk
import torch
import warnings
import numpy as np
from transformers import AutoProcessor, BarkModel
warnings.filterwarnings(
"ignore",
message="torch.nn.utils.weight_norm is deprecated in favor of torch.nn.utils.parametrizations.weight_norm.",
)
class TextToSpeechService:
def __init__(self, device: str = "cuda" if torch.cuda.is_available() else "cpu"):
"""
Initializes the TextToSpeechService class.
Args:
device (str, optional): The device to be used for the model, either "cuda" if a GPU is available or "cpu".
Defaults to "cuda" if available, otherwise "cpu".
"""
self.device = device
self.processor = AutoProcessor.from_pretrained("suno/bark-small")
self.model = BarkModel.from_pretrained("suno/bark-small")
self.model.to(self.device)
def synthesize(self, text: str, voice_preset: str = "v2/en_speaker_1"):
"""
Synthesizes audio from the given text using the specified voice preset.
Args:
text (str): The input text to be synthesized.
voice_preset (str, optional): The voice preset to be used for the synthesis. Defaults to "v2/en_speaker_1".
Returns:
tuple: A tuple containing the sample rate and the generated audio array.
"""
inputs = self.processor(text, voice_preset=voice_preset, return_tensors="pt")
inputs = {k: v.to(self.device) for k, v in inputs.items()}
with torch.no_grad():
audio_array = self.model.generate(**inputs, pad_token_id=10000)
audio_array = audio_array.cpu().numpy().squeeze()
sample_rate = self.model.generation_config.sample_rate
return sample_rate, audio_array
def long_form_synthesize(self, text: str, voice_preset: str = "v2/en_speaker_1"):
"""
Synthesizes audio from the given long-form text using the specified voice preset.
Args:
text (str): The input text to be synthesized.
voice_preset (str, optional): The voice preset to be used for the synthesis. Defaults to "v2/en_speaker_1".
Returns:
tuple: A tuple containing the sample rate and the generated audio array.
"""
pieces = []
sentences = nltk.sent_tokenize(text)
silence = np.zeros(int(0.25 * self.model.generation_config.sample_rate))
for sent in sentences:
sample_rate, audio_array = self.synthesize(sent, voice_preset)
pieces += [audio_array, silence.copy()]
return self.model.generation_config.sample_rate, np.concatenate(pieces)- 初始化 (
__init__):该类采用可选的设备参数,该参数指定要用于模型的设备(如果有 GPU,则为 cuda,否则为 cpu)。它从suno/bark-small预训练模型加载 Bark 模型和相应的处理器。您也可以通过为模型加载器指定suno/bark来使用大型版本。 - 合成 (
synthesize):此方法采用文本输入和voice_preset参数,该参数指定要用于合成的语音。可以在此处查看其他voice_preset值。它使用处理器准备输入文本和语音预设,然后使用model.generate()方法生成音频数组。生成的音频数组将转换为 NumPy 数组,并随音频数组一起返回采样率。 - 长格式合成 (long_form_synthesize):此方法用于合成较长的文本输入。它首先使用
nltk.sent_tokenize函数将输入文本标记为句子。对于每个句子,它都会调用synthesize方法来生成音频数组。然后,它将生成的音频数组连接起来,并在每个句子之间添加短暂的静音(0.25 秒)。
现在我们已经设置了 TextToSpeechService,我们需要为大型语言模型 (LLM) 服务准备 Ollama 服务器。为此,我们需要遵循以下步骤:
- 提取最新的 Llama-2 模型:运行以下命令从 Ollama 存储库下载最新的 Llama-2 模型:
ollama pull llama2。 - 启动 Ollama 服务器:如果服务器尚未启动,请执行以下命令来启动它:
ollama serve。
完成这些步骤后,你的应用程序将能够使用 Ollama 服务器和 Llama-2 模型来生成对用户输入的响应。
接下来,我们将转到主要应用程序逻辑。首先,我们需要初始化以下组件:
- Rich Console:我们将使用 Rich 库在终端内为用户创建更好的交互式控制台。
- Whisper Speech-to-Text:我们将初始化 Whisper 语音识别模型,这是 OpenAI 开发的最先进的开源语音识别系统。我们将使用基本英语模型 (
base.en) 转录用户输入。 - Bark Text-to-Speech:我们将初始化上面实现的 Bark Text-to-Speech 合成器实例。
- 对话链:我们将使用 Langchain 库中的内置 ConversationalChain,它提供了管理对话流的模板。我们将配置它以使用带有 Ollama 后端的 Llama-2 语言模型。
import time
import threading
import numpy as np
import whisper
import sounddevice as sd
from queue import Queue
from rich.console import Console
from langchain.memory import ConversationBufferMemory
from langchain.chains import ConversationChain
from langchain.prompts import PromptTemplate
from langchain_community.llms import Ollama
from tts import TextToSpeechService
console = Console()
stt = whisper.load_model("base.en")
tts = TextToSpeechService()
template = """
You are a helpful and friendly AI assistant. You are polite, respectful, and aim to provide concise responses of less
than 20 words.
The conversation transcript is as follows:
{history}
And here is the user's follow-up: {input}
Your response:
"""
PROMPT = PromptTemplate(input_variables=["history", "input"], template=template)
chain = ConversationChain(
prompt=PROMPT,
verbose=False,
memory=ConversationBufferMemory(ai_prefix="Assistant:"),
llm=Ollama(),
)现在,让我们定义必要的函数:
record_audio:此函数在单独的线程中运行,使用sounddevice.RawInputStream从用户的麦克风捕获音频数据。每当有新的音频数据可用时,就会调用回调函数,并将数据放入data_queue中以供进一步处理。transcribe:此函数利用 Whisper 实例将data_queue中的音频数据转录为文本。get_llm_response:此函数将当前对话上下文提供给 Llama-2 语言模型(通过 Langchain的ConversationalChain)并检索生成的文本响应。play_audio:此函数获取 Bark 文本转语音引擎生成的音频波形,并使用声音播放库(例如 sounddevice)将其播放给用户。
def record_audio(stop_event, data_queue):
"""
Captures audio data from the user's microphone and adds it to a queue for further processing.
Args:
stop_event (threading.Event): An event that, when set, signals the function to stop recording.
data_queue (queue.Queue): A queue to which the recorded audio data will be added.
Returns:
None
"""
def callback(indata, frames, time, status):
if status:
console.print(status)
data_queue.put(bytes(indata))
with sd.RawInputStream(
samplerate=16000, dtype="int16", channels=1, callback=callback
):
while not stop_event.is_set():
time.sleep(0.1)
def transcribe(audio_np: np.ndarray) -> str:
"""
Transcribes the given audio data using the Whisper speech recognition model.
Args:
audio_np (numpy.ndarray): The audio data to be transcribed.
Returns:
str: The transcribed text.
"""
result = stt.transcribe(audio_np, fp16=False) # Set fp16=True if using a GPU
text = result["text"].strip()
return text
def get_llm_response(text: str) -> str:
"""
Generates a response to the given text using the Llama-2 language model.
Args:
text (str): The input text to be processed.
Returns:
str: The generated response.
"""
response = chain.predict(input=text)
if response.startswith("Assistant:"):
response = response[len("Assistant:") :].strip()
return response
def play_audio(sample_rate, audio_array):
"""
Plays the given audio data using the sounddevice library.
Args:
sample_rate (int): The sample rate of the audio data.
audio_array (numpy.ndarray): The audio data to be played.
Returns:
None
"""
sd.play(audio_array, sample_rate)
sd.wait()然后,我们定义主应用程序循环。主应用程序循环引导用户完成对话交互,如下所示:
- 提示用户按 Enter 键开始录制他们的输入。
- 一旦用户按下 Enter 键,就会在单独的线程中调用
record_audio函数来捕获用户的音频输入。 - 当用户再次按下 Enter 键停止录制时,将使用
transcribe函数转录音频数据。 - 然后将转录的文本传递给
get_llm_response函数,该函数使用 Llama-2 语言模型生成响应。 - 生成的响应将打印到控制台并使用
play_audio函数播放给用户。
if __name__ == "__main__":
console.print("[cyan]Assistant started! Press Ctrl+C to exit.")
try:
while True:
console.input(
"Press Enter to start recording, then press Enter again to stop."
)
data_queue = Queue() # type: ignore[var-annotated]
stop_event = threading.Event()
recording_thread = threading.Thread(
target=record_audio,
args=(stop_event, data_queue),
)
recording_thread.start()
input()
stop_event.set()
recording_thread.join()
audio_data = b"".join(list(data_queue.queue))
audio_np = (
np.frombuffer(audio_data, dtype=np.int16).astype(np.float32) / 32768.0
)
if audio_np.size > 0:
with console.status("Transcribing...", spinner="earth"):
text = transcribe(audio_np)
console.print(f"[yellow]You: {text}")
with console.status("Generating response...", spinner="earth"):
response = get_llm_response(text)
sample_rate, audio_array = tts.long_form_synthesize(response)
console.print(f"[cyan]Assistant: {response}")
play_audio(sample_rate, audio_array)
else:
console.print(
"[red]No audio recorded. Please ensure your microphone is working."
)
except KeyboardInterrupt:
console.print("\n[red]Exiting...")
console.print("[blue]Session ended.")3、结果
一旦所有东西都放在一起,我们就可以运行应用程序,如这个视频所示。由于 Bark 模型很大,即使是较小版本,应用程序在我的 MacBook 上运行也相当慢。因此,我稍微加快了视频的速度。对于那些拥有支持 CUDA 的计算机的人来说,它可能会运行得更快。以下是我们应用程序的主要功能:
- 基于语音的交互:用户可以开始和停止录制他们的语音输入,助手通过播放生成的音频来响应。
- 对话上下文:助手保持对话的上下文,从而实现更连贯和相关的响应。使用 Llama-2 语言模型允许助手提供简洁而有针对性的响应。
对于那些旨在将此应用程序提升到生产就绪状态的人,建议进行以下增强:
- 性能优化:结合模型的优化版本,例如 whisper.cpp、llama.cpp 和 bark.cpp,这些版本旨在提高性能,尤其是在低端计算机上。
- 可定制的机器人提示:实现一个系统,允许用户自定义机器人的角色和提示,从而创建不同类型的助手(例如,个人、专业或特定领域)。
- 图形用户界面 (GUI):开发一个用户友好的 GUI 来增强整体用户体验,使应用程序更易于访问且更具视觉吸引力。
- 多模式功能:扩展应用程序以支持多模式交互,例如除了基于语音的响应之外,还能够生成和显示图像、图表或其他视觉内容。
最后,我们完成了简单的语音助手应用程序。语音识别、语言建模和文本转语音技术的结合展示了我们如何构建听起来很难但实际上可以在你的计算机上运行的东西。
原文链接:构建自己的语音助手 - BimAnt















 83
83

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









