








1.问题描述

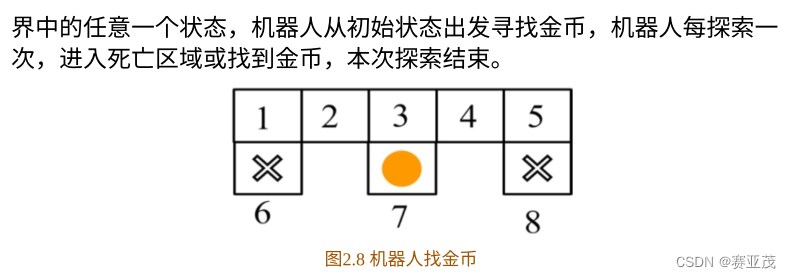
2. 环境建模

3. 游戏环境类roadenv()设计
class roadenv():
def __init__(self,epsilon=0.5,gamma=0.8):
# 状态空间-动作空间
self.states = [1, 2, 3, 4, 5, 6, 7, 8]
self.actions = ['n', 'e', 's', 'w']
# 回报函数
self.rewards = dict()
self.rewards['1_s'] = -1
self.rewards['3_s'] = 1
self.rewards['5_s'] = -1
# 状态转移概率
self.t = dict()
self.t['1_s'] = 6
self.t['1_e'] = 2
self.t['2_w'] = 1
self.t['2_e'] = 3
self.t['3_s'] = 7
self.t['3_w'] = 2
self.t['3_e'] = 4
self.t['4_w'] = 3
self.t['4_e'] = 5
self.t['5_s'] = 8
self.t['5_w'] = 4
# 当前状态
self.state = 1
# 动作价值函数
self.q = np.zeros(((len(self.states) + 1),len(self.actions)))
self.qn = np.zeros(((len(self.states) + 1),len(self.actions)))
self.policy = np.zeros(len(self.states) + 1)
self.epsilon = epsilon
self.gamma = gamma
def reset(self):
state = self.states[int(random.random()*len(self.states))]
self.state = state
return self.state
def step(self, action):
state = self.state
if (state == 6) or (state == 8):
return state,-1,True,{}
elif state == 7:
return state,1,True,{}
key = '%d_%s'%(state,action)
if key in self.t:
next_state = self.t[key]
else:
next_state = state
self.state = next_state
is_terminal = False
if (next_state == 6)or(next_state == 7) or(next_state == 8):
is_terminal = True
if key not in self.rewards:
r = 0
else:
r = self.rewards[key]
return next_state,r,is_terminal,{}
4.MonteCarlo采样轨迹
# 下面是蒙特卡洛方法(每次访问异策回合更新)的采样
def gen_random_sample(self,num=100):
# num:采样次数
state_sample = []
action_sample = []
reward_sample = []
for i in range(num):
# 用来存储临时的(s,a,r)
s_temp = []
a_temp = []
r_temp = []
# 初始化每个回合的开始状态(试探性出发假设)
s = self.states[int(random.random()*(len(self.states)-0))]
# 结束标记
flag = False
while flag == False:
# 每回合开始随机产生动作
a = self.actions[int(random.random()*(len(self.actions)-0))]
# 在当前(s)状态下采样a
self.state = s
next_s,r,flag,_ = self.step(a)
s_temp.append(s)
a_temp.append(a)
r_temp.append(r)
s = next_s
state_sample.append(s_temp)
action_sample.append(a_temp)
reward_sample.append(r_temp)
return state_sample,action_sample,reward_sample
5.决策过程
采用贪心策略( ε \varepsilon ε-greedy策略)采样:
# 决策过程(epsiolon-greedy)
def decide(self,state):
if np.random.rand()<self.epsilon:
return self.actions[int(random.random()*len(self.actions))]
else:
return self.actions[int(self.policy[state])]
6.策略评估与策略改进
# 蒙特卡洛评估动作价值函数q(s,a)
def evaluate_q(self,state_sample, action_sample, reward_sample):
# state_sample,action_sample,reward_sample都是一维数组
G = 0 # 初始化回报
action_map = {'n':0, 'e':1, 's':2, 'w':3}
for t in range(len(state_sample)-1,-1,-1):
s_t = state_sample[t]
# if s_t >= 8:
# print("s_t>=8,s_t:{}".format(s_t))
r_t = reward_sample[t]
a_t = action_sample[t]
a_t_index = action_map[a_t]
# 下面是MonteCarlo更新
G = self.gamma*G + r_t
self.qn[s_t,a_t_index] += 1
self.q[s_t,a_t_index] += (G - self.q[s_t,a_t_index])/self.qn[s_t,a_t_index]
# 策略改进
def impove_policy(self):
for state in range(len(self.states)):
a_s_index = np.argmax(self.q[state])
self.policy[state] = a_s_index
7. 学习算法
# 同策回合更新(学习)过程-给出决策policy
def learn(self,epsiodes=100):
epsiode_array = []
reward_array = []
for epsiode in range(epsiodes):
s_sample,a_sample,r_sample = [],[],[]
# 下面是试探性出发假设
s = self.states[int(len(self.states)*random.random())]
a = self.actions[int(len(self.actions)*random.random())]
flag = False # 结束标记
# 下面将用贪心策略产生轨迹
while flag == False:
# 当前状态设置为s
self.state = s
# 设置转移
next_s,r,flag,_ = self.step(a)
# 贪心策略生成新的策略
a = self.decide(next_s)
s = next_s
# 保存轨迹
s_sample.append(next_s)
a_sample.append(a)
r_sample.append(r)
# 策略评估
self.evaluate_q(s_sample,a_sample,r_sample)
# 策略改进
self.impove_policy()
reward_array.append(np.sum(r_sample))
# 下面将策略进行转码
policy_symbol = []
for state in self.states:
policy_symbol.append(self.actions[int(self.policy[int(state)])])
return policy_symbol,reward_array
8.主函数
if __name__ == "__main__":
print("------下面是同策回合更新---------")
game = roadenv(epsilon=0.1,gamma=0.8)
game.reset()
policy,reward_array = game.learn(epsiodes=100)
print(policy)
plt.plot(reward_array)
plt.waitforbuttonpress()
9.结果
------下面是同策回合更新---------
['e', 'e', 's', 'w', 'w', 'n', 'n', 'n']

发现最好的奖励是1.0,正好就是直接从7号点出去的路径。
10.附录(完整代码)
import numpy as np
import random
import matplotlib.pyplot as plt
class roadenv():
def __init__(self,epsilon=0.5,gamma=0.8):
# 状态空间-动作空间
self.states = [1, 2, 3, 4, 5, 6, 7, 8]
self.actions = ['n', 'e', 's', 'w']
# 回报函数
self.rewards = dict()
self.rewards['1_s'] = -1
self.rewards['3_s'] = 1
self.rewards['5_s'] = -1
# 状态转移概率
self.t = dict()
self.t['1_s'] = 6
self.t['1_e'] = 2
self.t['2_w'] = 1
self.t['2_e'] = 3
self.t['3_s'] = 7
self.t['3_w'] = 2
self.t['3_e'] = 4
self.t['4_w'] = 3
self.t['4_e'] = 5
self.t['5_s'] = 8
self.t['5_w'] = 4
# 当前状态
self.state = 1
# 动作价值函数
self.q = np.zeros(((len(self.states) + 1),len(self.actions)))
self.qn = np.zeros(((len(self.states) + 1),len(self.actions)))
self.policy = np.zeros(len(self.states) + 1)
self.epsilon = epsilon
self.gamma = gamma
def reset(self):
state = self.states[int(random.random()*len(self.states))]
self.state = state
return self.state
def step(self, action):
state = self.state
if (state == 6) or (state == 8):
return state,-1,True,{}
elif state == 7:
return state,1,True,{}
key = '%d_%s'%(state,action)
if key in self.t:
next_state = self.t[key]
else:
next_state = state
self.state = next_state
is_terminal = False
if (next_state == 6)or(next_state == 7) or(next_state == 8):
is_terminal = True
if key not in self.rewards:
r = 0
else:
r = self.rewards[key]
return next_state,r,is_terminal,{}
# 下面是蒙特卡洛方法(每次访问异策回合更新)的采样
def gen_random_sample(self,num=100):
# num:采样次数
state_sample = []
action_sample = []
reward_sample = []
for i in range(num):
# 用来存储临时的(s,a,r)
s_temp = []
a_temp = []
r_temp = []
# 初始化每个回合的开始状态(试探性出发假设)
s = self.states[int(random.random()*(len(self.states)-0))]
# 结束标记
flag = False
while flag == False:
# 每回合开始随机产生动作
a = self.actions[int(random.random()*(len(self.actions)-0))]
# 在当前(s)状态下采样a
self.state = s
next_s,r,flag,_ = self.step(a)
s_temp.append(s)
a_temp.append(a)
r_temp.append(r)
s = next_s
state_sample.append(s_temp)
action_sample.append(a_temp)
reward_sample.append(r_temp)
return state_sample,action_sample,reward_sample
# 蒙特卡洛评估价值函数v
def evaluate_v(self,state_sample,action_sample,reward_sample):
# 初始化v[s],n[s] = 0
vfunc = dict()
nfunc = dict()
for s in self.states:
vfunc[s] = 0.0
nfunc[s] = 0.0
for epsiode in range(len(state_sample)):
G = 0
# 初始化一个G_array用于后面
G_array = []
for i in range(len(state_sample[epsiode])):
G_array.append(0)
# 从最后一个开始G
for step in range(len(state_sample[epsiode])-1,-1,-1):
G = self.gamma*G + reward_sample[epsiode][step]
G_array[step] = G
s = state_sample[epsiode][step]
nfunc[s] += 1
vfunc[s] += (G_array[step] - vfunc[s])/nfunc[s]
print("价值函数{}".format(vfunc))
return vfunc
# 蒙特卡洛评估动作价值函数q(s,a)
def evaluate_q(self,state_sample, action_sample, reward_sample):
# state_sample,action_sample,reward_sample都是一维数组
G = 0 # 初始化回报
action_map = {'n':0, 'e':1, 's':2, 'w':3}
for t in range(len(state_sample)-1,-1,-1):
s_t = state_sample[t]
# if s_t >= 8:
# print("s_t>=8,s_t:{}".format(s_t))
r_t = reward_sample[t]
a_t = action_sample[t]
a_t_index = action_map[a_t]
# 下面是MonteCarlo更新
G = self.gamma*G + r_t
self.qn[s_t,a_t_index] += 1
self.q[s_t,a_t_index] += (G - self.q[s_t,a_t_index])/self.qn[s_t,a_t_index]
# 策略改进
def impove_policy(self):
for state in range(len(self.states)):
a_s_index = np.argmax(self.q[state])
self.policy[state] = a_s_index
# 决策过程(epsiolon-greedy)
def decide(self,state):
if np.random.rand()<self.epsilon:
return self.actions[int(random.random()*len(self.actions))]
else:
return self.actions[int(self.policy[state])]
# 同策回合更新(学习)过程-给出决策policy
def learn(self,epsiodes=100):
epsiode_array = []
reward_array = []
for epsiode in range(epsiodes):
s_sample,a_sample,r_sample = [],[],[]
# 下面是试探性出发假设
s = self.states[int(len(self.states)*random.random())]
a = self.actions[int(len(self.actions)*random.random())]
flag = False # 结束标记
# 下面将用贪心策略产生轨迹
while flag == False:
# 当前状态设置为s
self.state = s
# 设置转移
next_s,r,flag,_ = self.step(a)
# 贪心策略生成新的策略
a = self.decide(next_s)
s = next_s
# 保存轨迹
s_sample.append(next_s)
a_sample.append(a)
r_sample.append(r)
# 策略评估
self.evaluate_q(s_sample,a_sample,r_sample)
# 策略改进
self.impove_policy()
reward_array.append(np.sum(r_sample))
# 下面将策略进行转码
policy_symbol = []
for state in self.states:
policy_symbol.append(self.actions[int(self.policy[int(state)])])
return policy_symbol,reward_array
# 下面是主函数
if __name__ == "__main__":
# game = roadenv(epsilon=0.1)
# game.reset()
# game.state = 2
# print("当前状态为:"+str(game.state))
# next_state,r,is_terminal,_ = game.step('w')
# print('现在状态为:{}'.format(next_state))
# print("------下面开始测试蒙特卡洛采样--------")
# state_sample,action_sample,reward_sample = game.gen_random_sample()
# print("state_sample:{}".format(state_sample))
# print("action_sample:{}".format(action_sample))
# print("reward_sample:{}".format(reward_sample))
# # print("------下面开始进行评估价值函数--------")
# # vfunc = game.evaluate_v(state_sample,action_sample,reward_sample)
print("------下面是同策回合更新---------")
game = roadenv(epsilon=0.1,gamma=0.8)
game.reset()
policy,reward_array = game.learn(epsiodes=100)
print(policy)
plt.plot(reward_array)
plt.waitforbuttonpress()
















 599
599











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









