







第二天下午两大主题:历久弥坚的老话题,分割以及建模
D2-PM-A. Segmentation in Images and Video
【Causal Video Object Segmentation From Persistence of Occlusions】
利用遮挡持续性进行一般物体分割
视频中的物体分割,充分利用遮挡关系。是online算法,按照sequence处理视频帧。


由于利用了遮挡,很小的块(例如橙色车)也不会给漏掉。
每一个分割区域制定一个深度顺序,标记属于哪层0,1,2,3...
occluded很好找,通过光流对比,消失了的部分即为被遮挡。
occluder较难找。
VGA尺寸需要30s。github上有MATLAB代码。
【Semantic Object Segmentation via Detection in Weakly Labeled Video】
弱标定视频中利用检测进行语义对象分割
(北航)
利用视频中粗略的语义tag辅助检测和分割。

基于语义的detector是预先在PASCAL VOC 2007训练好的。
初始化track时,使用min-cost flow。
修正各帧时,使用shape likelihoods,考虑帧间连续性、相同目标见连续性。
是offline方法,长视频处理很慢。
【Fully Convolutional Networks for Semantic Segmentation】
全卷积网络用语语义分割
(UC Berkeley)
best paper candidate
特点:使用fully convolutional网络(FCN,每一层都是卷积网络),输入任意尺寸图像,输出同尺寸分割结果。
由于输出也是一张dense分割图,比用于分类的神经网络慢。
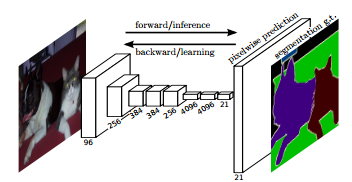
使用Caffe+单个NVIDIA Tesla K40c,提供了模型和代码。
inference时间175ms,比之前文献(50s)大大提高(在服务器上测试)
不知道是怎么把卷积输出变成分割结果的?
【Shape-Tailored Local Descriptors and Their Application to Segmentation and Tracking】
针对形状的局部描述子用于分割和跟踪
一种纹理分割的描述子,对不同尺寸的纹理效果都很好。

每一个像素的描述子是一个m*n的矩阵,其中的每个像素uij通过以下偏微分方程求解:

其中alpha控制纹理的尺度,本方法对alpha鲁棒。
把此种描述子加入到某种分割方法的能量函数中,即可完成分割。
【Deep Filter Banks for Texture Recognition and Segmentation】
深度滤镜集用于纹理识别和分割
用CNN作纹理识别,进而做分割。

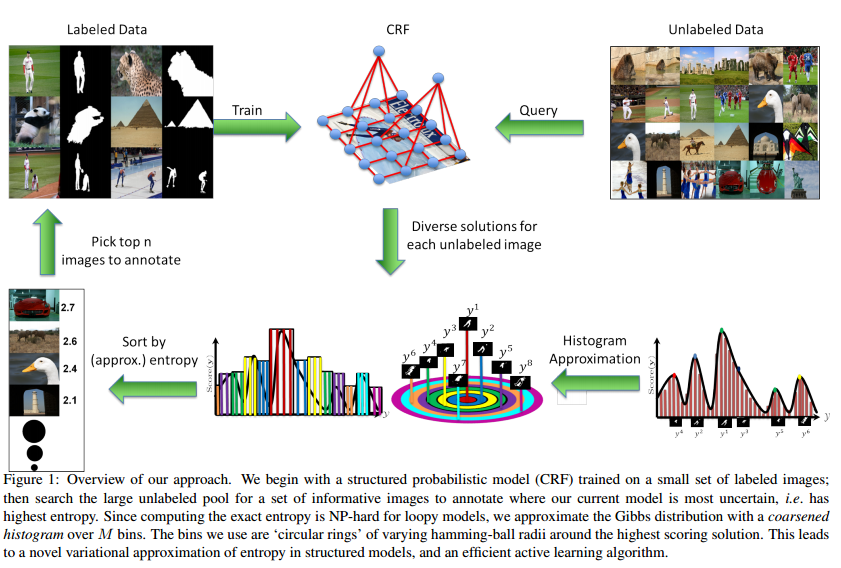
【Active Learning for Structured Probabilistic Models With Histogram Approximation】
主动学习用于直方图近似的概率结构模型
(CMU, Virginia Tech)
结构概率模型(例如CRF)中的active learning问题。
active learning:只需要标定最informative的样本。是一种半监督方法。
学习算法逐步向信息源查询“最不确定”的样本的标定。
用简单的直方图近似Gibbs分布。
只需要10%的标定样本,精度几乎相同。
D2-PM-B. 3D Models and Images
【 Picture: A Probabilistic Programming Language for Scene Perception】
Picture:一种场景感知的概率编程语言
(MIT, Microsoft)
Best Paper
发明了一种语言,解决通用2D/3D场景的识别问题。
遵循概率模型的analysis-by-synthesis方法。
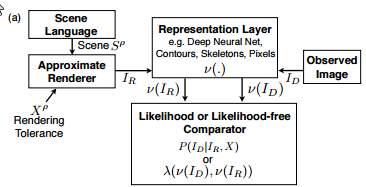
用这个语言编写程序解决了三个问题:人脸重建、3D物体重建,3D人体姿态重建。
【 Rent3D: Floor-Plan Priors for Monocular Layout Estimation】
Rent3D: 平面图辅助单目布局估计
layout estimation:平面图纸+几张照片 -> 3D贴图结构。

亮点:利用了平面图纸信息作为prior。包括房间的尺寸对比,窗和墙的尺寸关系。
训练使用structural SVM。推测利用Markove Random Field,每套房屋约需若干ms。
首先判断照片拍摄于哪个房间,之后判断照片朝向那面墙,最后估计角度。
数据集提供下载。
【 The Stitched Puppet: A Graphical Model of 3D Human Shape and Pose 】
缝纫布偶:3D人体形状姿态图模型

传统人体模型两种,a:高精度,但参数合为一体,解空间高维;b:低精度,但参数少。
本文提出模型c:每个组件高精度,独立参数控制形变(下左),各组件之间通过stitching cost连接(下右)。


可以用于精细3D姿态估计和重建。
【3D Shape Estimation From 2D Landmarks: A Convex Relaxation Approach】
2D关键点估计3D形状:凸松弛解法
2D恢复3D有二义性。传统方法是利用已有的形状建立可能的解空间,需要解一个非凸优化问题。
本文提出一种Convex表达式,能够用凸优化求解。

MATLAB,500次迭代,每帧0.33秒。
【Holistic 3D Scene Understanding From a Single Geo-Tagged Image】
经由单张地理标定照片的3D全景理解
(Univ. of Toronto)
利用OSM2World(一个公开的三维地图)分析场景prior(rendering, depth, label)。
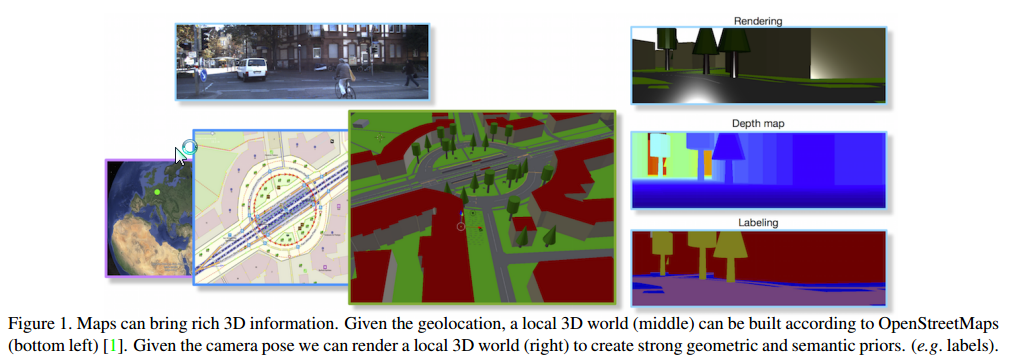
之后给定一张照片和一个地理坐标,可以做细致的场景分析。
举例:下图如果仅从2D图片分析,得到的车辆位置如右图。存在不合理之处:重叠、偏离道路等。利用场景先验则可以纠正这些问题。

【Joint SFM and Detection Cues for Monocular 3D Localization in Road Scenes】
综合“运动形状估计”和检测的单目道路景观定位
车载摄像头,目标的3D定位。综合利用SFM(Shape From Motion )和物体检测。
















 5562
5562

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









