







从另一种一阶滤波聊起
上一篇文章里,写到一阶滞后滤波器的形式:
在正式引入算术平均滤波器之前,有必要先谈一谈下面这种形式:
粗略一看,和一阶滞后滤波器很像,这也是一种低通滤波器,输出仅与当前以及上一次的输入有关,并对两次输入做了加权。进行初步仿真,将a=0.1和a=0.9带入后,得到两幅频率响应特性图:
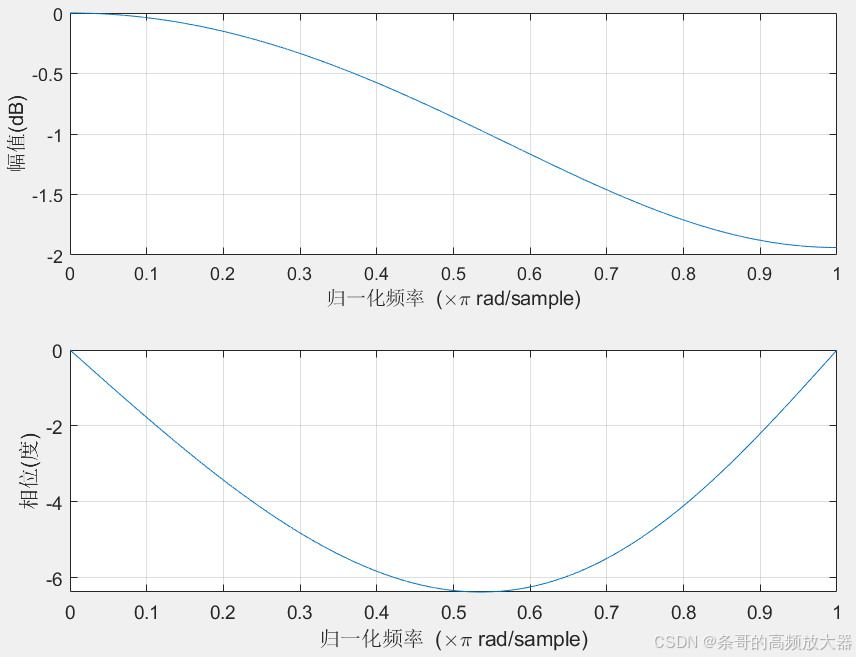
a=0.1时的频率响应曲线
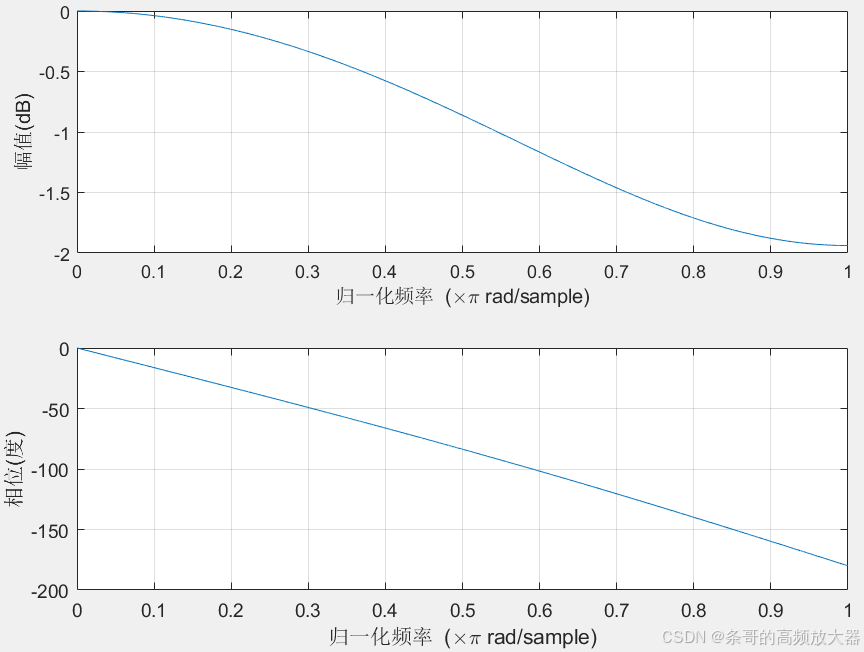
a=0.9时的频率响应曲线
可以看到,这两种情况下的幅度响应几乎一致,只是相位响应有较大差异,其实从时域角度也很容易想到,当前输入仅与最近两次输入有关,那么加权系数无论是1:9还是9:1,由于其对称性,对频率的幅度增益是不影响的。至于相位特性,对当前值强加权的滤波器必然延时是更小的,对历史值高权重的滤波器相对来说时延都会大一些。
继续探究零极点图,先列出该滤波器的系统函数:
![]()
其中极点为z=0,零点为z=1-1/a,随着a从0到1,系统的零点从负无穷到0,如图:
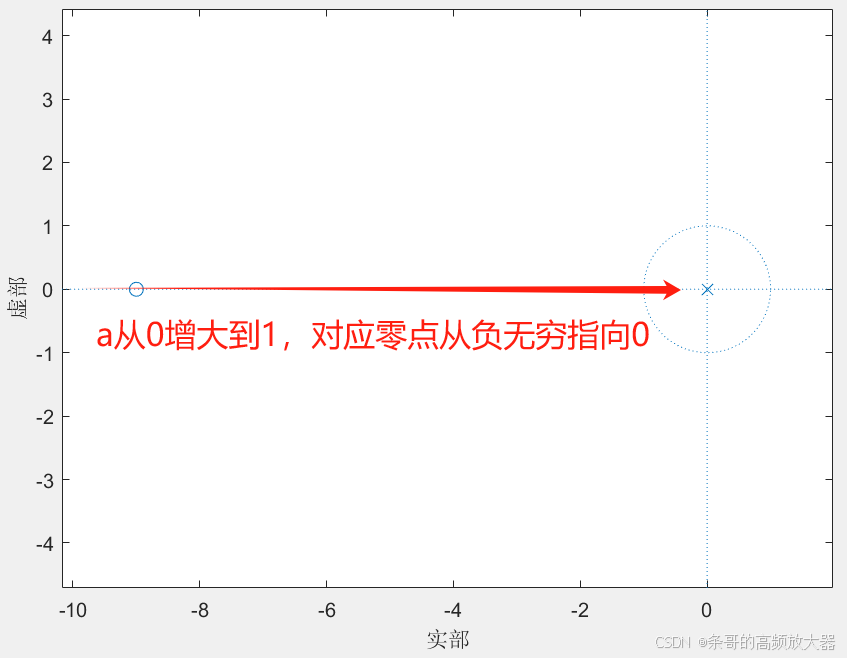
由之前文章的内容可知,该滤波器的幅值响应由零点主导(频率点到极点的距离总是半径1)。当a趋近于0时,系统零点趋向负无穷,此时任意频率点到零点的距离都非常远,则幅值响应也几乎是“全通”的:
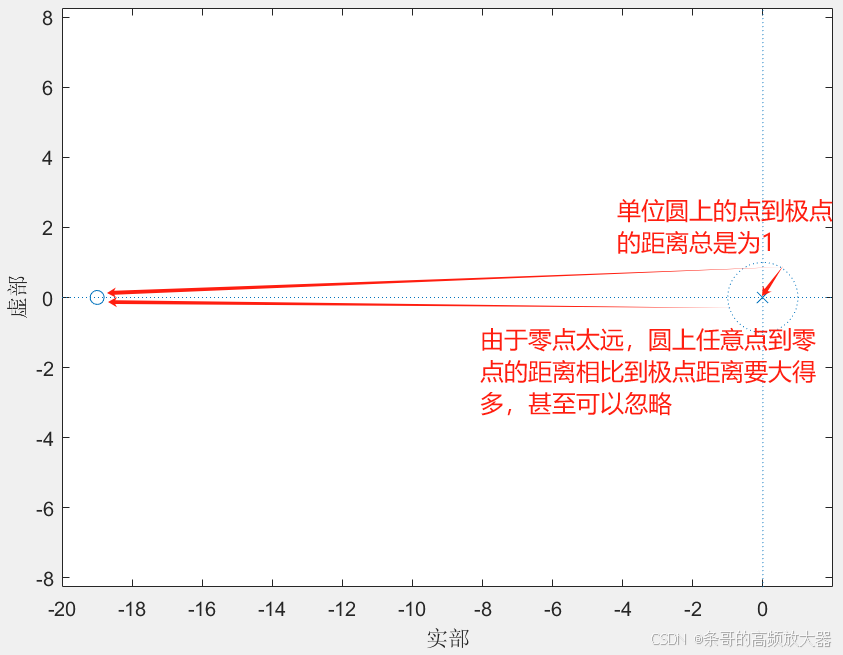
且由于此时频率点到零点的直线与实轴夹角非常小可以忽略,则相位响应由极点主导,随着频率增大,极点相位是跟随的,所以系统的相位响应也是线性的。
同理,当a趋近于1时,系统零点趋近于极点,此时任意频率点到零点和极点的距离非常接近,幅值响应也几乎是“全通”的。
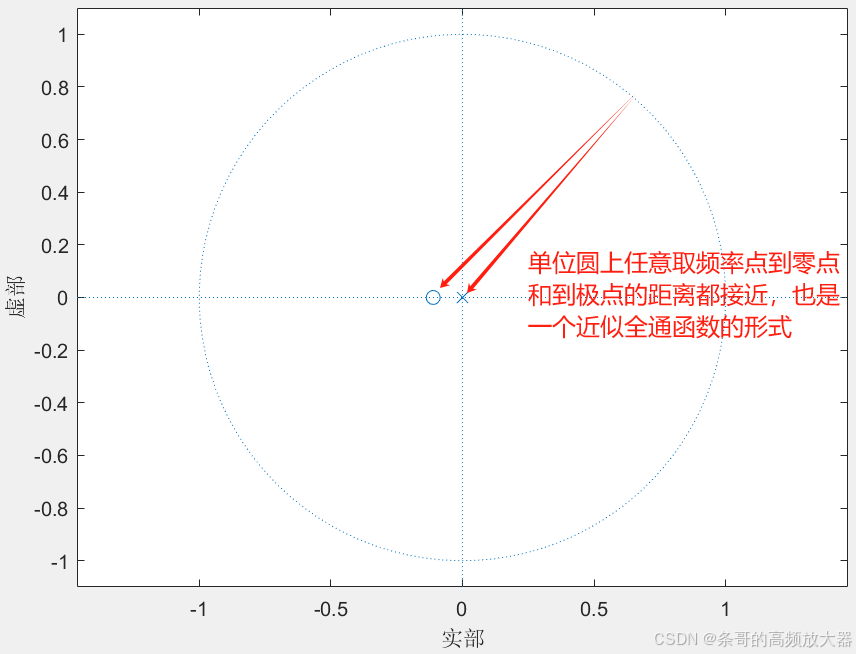
到这里相频响应也就很容易想到了。
引入算术平均滤波
我们发现,a从0逐渐增大到1,幅值响应经历了一个全通->低通->全通的过程,理论上中间一定有个分界点,该点是滤波器低通效果最好的点。
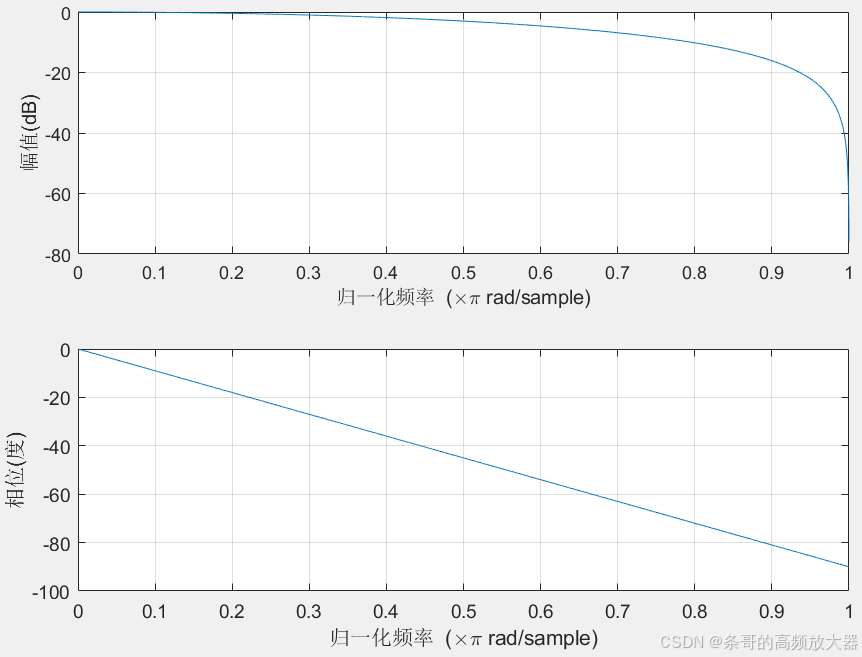
于是当a=0.5时,该系统就变成了一阶算术平均滤波器,此时零点z=-1位于单位圆上,观察频率响应,发现幅频响应初段衰减较慢,有效还原了中低频但对高频成分的抑制十分强烈。另外相频响应很线性,斜率为-0.5,相当于整体延时半个采样周期,对于有实时性要求的系统也可以使用(是的,敏感肌也可以使用)。整体描述就是一个简易效果的低通滤波器,能比较好地还原原信号,并能平滑局部高频噪点。
进一步的,我们可以引申出二阶甚至更高阶的算术平均滤波形式:
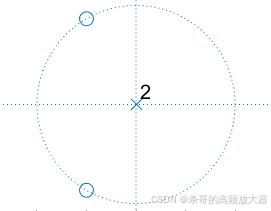
当i=2时,得到一个二阶算术平均滤波器,此时的零点方程变成:
求解得到两个单位圆上对称的共轭零点:
以此类推,随着阶数变高,零点也会变多,并均匀分布在单位圆上(注意观察(1,0)默认被占用,零点均匀将其它区域切分),其中奇次阶数系统会存在一个(-1,0)的零点(其它零点共轭存在),偶次阶数系统零点将全部以共轭零点方式存在。
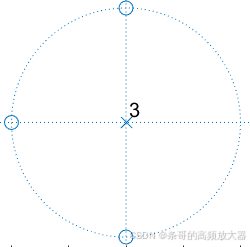
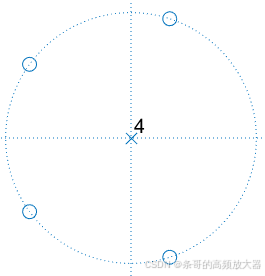
查看这些系统的频率响应,与响应也与零极点不谋而合,由于这些零点均分布在单位圆上,因此零点对应频率点的幅值响应为0,该点以陷波形式呈现:
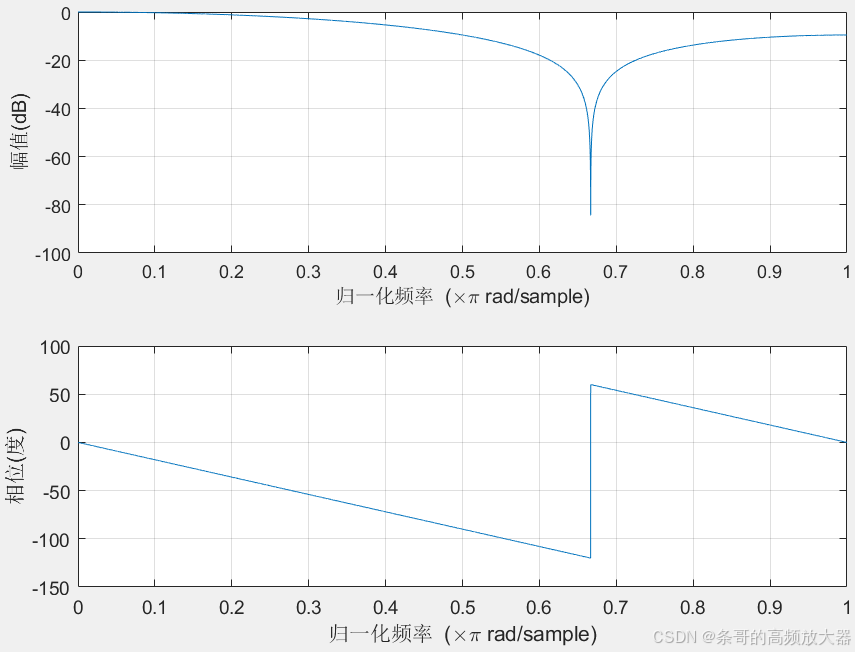
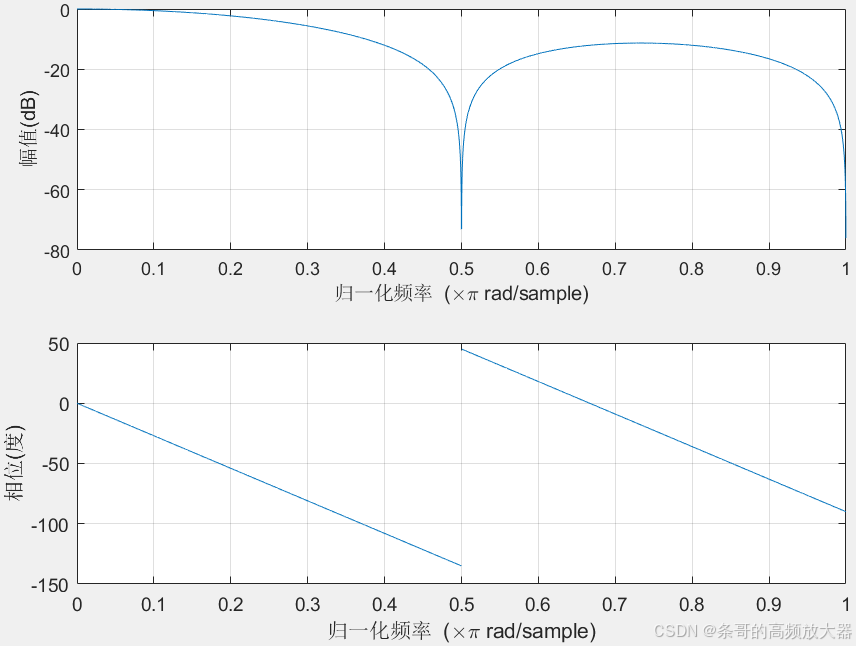
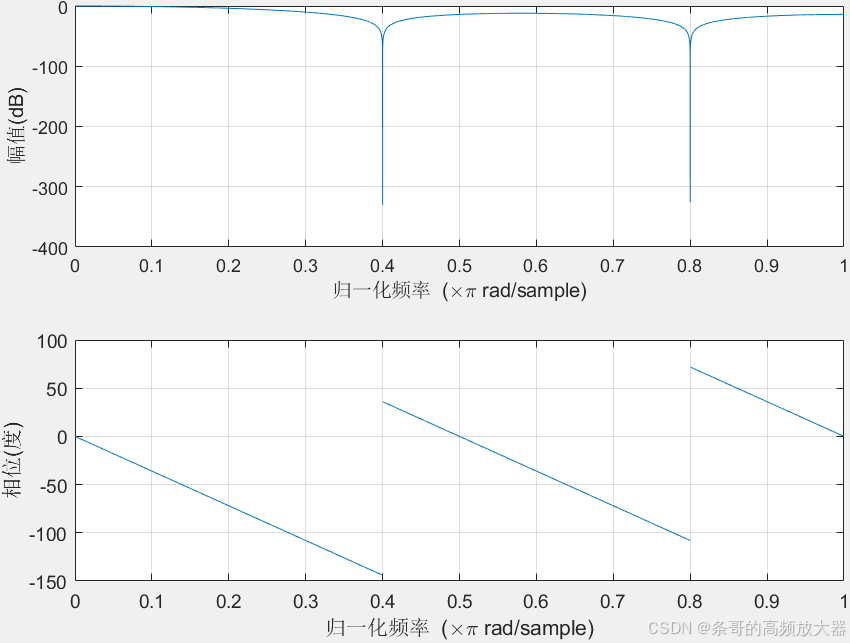
随着阶数增加,初段衰减会加快,滤波器的低通效果也越明显,这也符合我们对时域表现的直观感觉(越多数据样本,计算结果越平滑越趋于真实平均值)。但相对的相位滞后会加大,比如二阶滤波器低通部分的平均时延为1个采样周期,三阶继续增大到1.5个采样周期。即每增加一阶,时延就会多出0.5个采样周期!
对于高频部分,偶次滤波器由于不存在(-1,0)的零点,对高频部分的增益不会形成陷波,过滤效果不如奇次。但陷波后整体增益普遍也小于10dB,大部分场合可以忽略不计。
和一阶滞后滤波器的对比
最后来和一阶滞后滤波器进行比较:
①一阶滞后滤波是零点固定在原点,极点随着系数移动的,通过调整系数可以获得较好的低通效果和阻带衰减,且计算量比较小(仅需维护一个历史输出值),缺点是时延比较大,不容易控制相位;
②算术平均滤波是极点固定在原点,零点在单位圆上分布,且零点数量随着滤波器阶数增大而增多,优点是时延线性好控制,缺点是需要比较高的阶数才能有较窄的低频通带,过渡带不够陡峭,阻带衰减也不彻底。且随着阶数提高,所需的内存和计算量会增大,一般仅用低阶算术平均滤波做简单处理;

















 2070
2070

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









