







 超级会员免费看
超级会员免费看
 本文详细介绍了CELT音频编码器的工作原理,包括MDCT变换的线性映射特性,加窗处理以提高变换性质,以及如何通过预加重和感知预滤波器减少谱泄露。CELT编码器利用MDCT和窗函数实现低延迟和高效能,适用于音乐网络传输。
本文详细介绍了CELT音频编码器的工作原理,包括MDCT变换的线性映射特性,加窗处理以提高变换性质,以及如何通过预加重和感知预滤波器减少谱泄露。CELT编码器利用MDCT和窗函数实现低延迟和高效能,适用于音乐网络传输。
本文谢绝任何形式转载,谢谢。
第三章 CELT编码器
CELT基于音频信号谱包络是声音感知的最重要部分,CELT通过显式编码一组近似于听觉系统临界频带的频带的能量来保持这一包络。Bark子带就是人耳对不同频率成份听觉灵敏度(基于心理声学)的一种子带划分方法。相对于LPC编码,CELT编码的延迟短,编码带宽宽,因而CELT编码器常用于音乐网络场景。CELT基于MDCT频域编码方法,其编码语音的时频信息,这种编码方法对于长时稳态类型信号(如各类乐器声)非常适用。
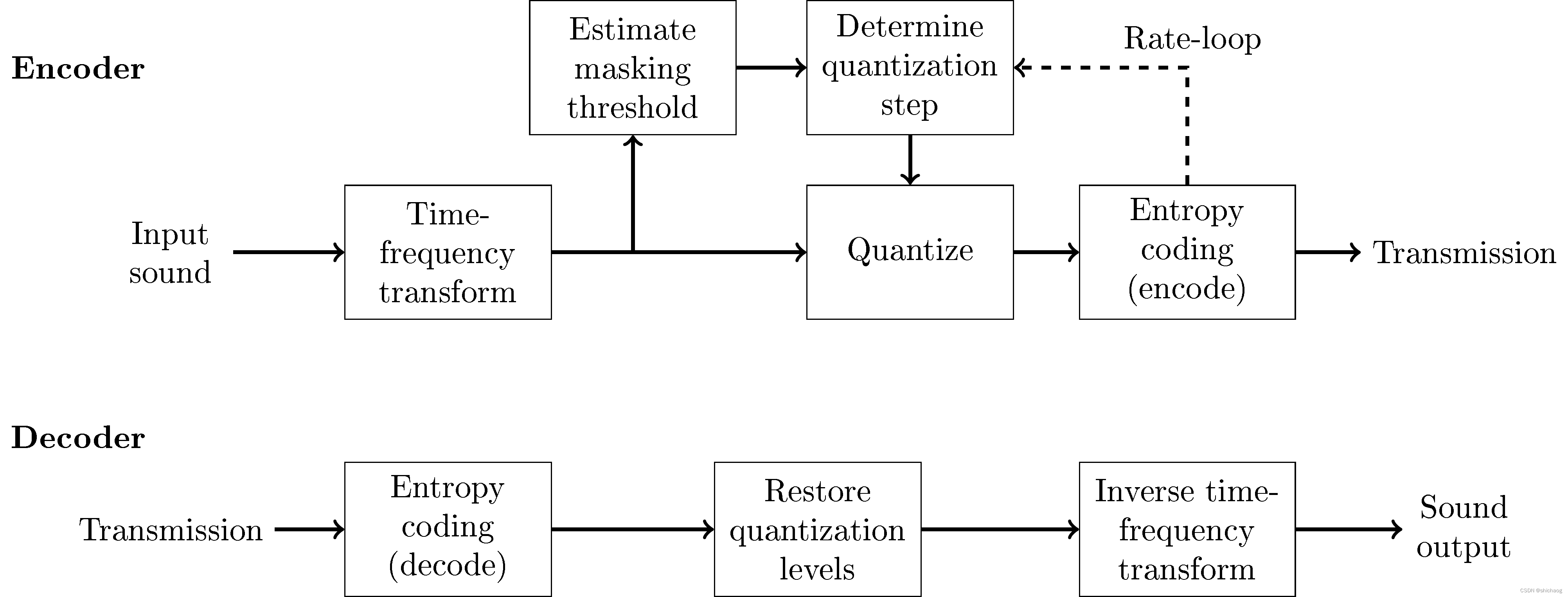
音频信号通常是短时平稳的,因而常采用分段加窗方法截取小段进行处理,小段内信号可以认为是静态的,这正是大多数谱分析方法对信号特征的要求之一,分段也提高了信号实时性,但是由于为了无失真重构原始音频信号,通常而采用分段重叠加窗方法做STFT运算,这一重叠使得连续小段之间存在重复信息,因而直接编码STFT信息存在冗余,实时语音应用场景期望用尽可能少的比特率编码信号,因而常采用无这里冗余问题的MDCT编码方法,MDCT在重叠处使用投影的方法使得连续窗口中信息彼此正交以达到无信息冗余。
MDCT方法提

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 1146
1146

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











