







 LibSVM是一款简单易用的支持向量机工具包,包含了C和Java的开发源码。大家可以访问其官网进行了解和下载相关文件。 这里以其官网的第一个数据集a1a 为例,练习使用多项式核和径向基核来对数据集进行分类。1、准备工作 由于从官网下的最新的2015.12月发布的libsvm-3.21版本中已生成的exe文件不支持Windows32位系统,所以使用的之前的一版libsvm-3.20。将其下下来打开
LibSVM是一款简单易用的支持向量机工具包,包含了C和Java的开发源码。大家可以访问其官网进行了解和下载相关文件。 这里以其官网的第一个数据集a1a 为例,练习使用多项式核和径向基核来对数据集进行分类。1、准备工作 由于从官网下的最新的2015.12月发布的libsvm-3.21版本中已生成的exe文件不支持Windows32位系统,所以使用的之前的一版libsvm-3.20。将其下下来打开
LibSVM是一款简单易用的支持向量机工具包,包含了C和Java的开发源码。大家可以访问其官网进行了解和下载相关文件。
这里以其官网的第一个数据集a1a 为例,练习使用多项式核和径向基核来对数据集进行分类。
1、准备工作
由于从官网下的最新的2015.12月发布的libsvm-3.21版本中已生成的exe文件不支持Windows32位系统,所以使用的之前的一版libsvm-3.20。将其下下来打开,里面包含了以下文件:
其中data里面放的是LibSVM分享的数据集a1a;
gnuplot是一个图像绘画工具,可以将数据可视化。直接点击进行安装,路径可以自己选择,本例中安装路径为F:\Program Files\gnuplot。
libsvm-3.20是一个已开发好的集成工具包,我们拿来直接用。将libsvm-3.20压缩包解压,路径可以自己选择,本例中解压路径为F:\Program Files\libsvm-3.20。
打开tools文件夹,然后分别打开easy.py和grid.py,将easy.py中出现在else语句中的gnuplot_exe和 grid.py中self.gnuplot_pathname修改为gnuplot.exe所在路径,如下:
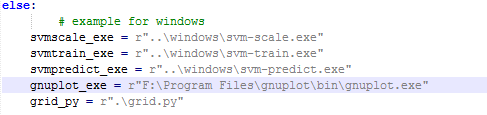

现在还差一个工具,就是python。没有安装python的可以从python官网 下载安装。路径可以自己选择,本例中安装路径为F:\Program Files\Python。
以上几步完成后,准备工作就结束了。
2、LibSVM的使用
0. 如果数据集较小的话,可以直接在libsvm-3.20中的tools 文件夹下使用命令:python easy.py training_file [testing_file]。否则处理过程如下:
1. 使用网格搜索grid.py训练出最优参数惩罚因子C和参数g,g也就是核函数公式中的 γ 。 步骤如下:
首先将data中的两个数据集文件复制到刚解压的libsvm-3.20中的tools 文件夹下,然后打开cmd命令行,通过cd进入到tools文件夹下,输入如下命令,如图:
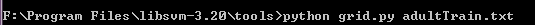
按回车后,程序开始执行,执行结束后,会出现如下结果:
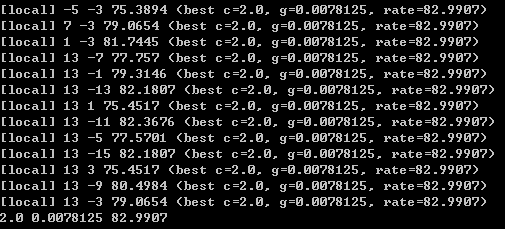
最后一行三个数字分别表示,寻找到的最优参数C=2.0,g=0.0078125,准确率=82.9907。
同时会在tools文件夹下生成一个gnuplot画出结果图片,如下:
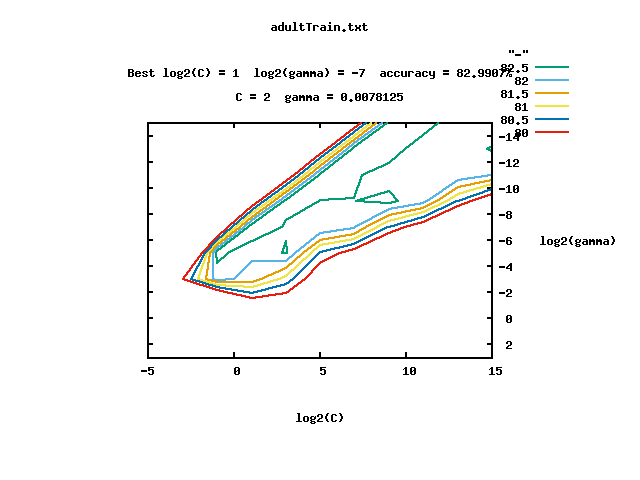
可以看到,gnuplot是对数据的可视化表示。
2 训练模型
在获得最优参数后,我们就可以对训练数据集进行训练,来获得训练模型,步骤如下:
首先从cmd命令行中进入libsvm-3.20中的windows文件夹,可以看到文件夹中有svm-toy.exe、svm-scale.exe、svm-train.exe、svm-predict.exe四个可执行文件,其中:
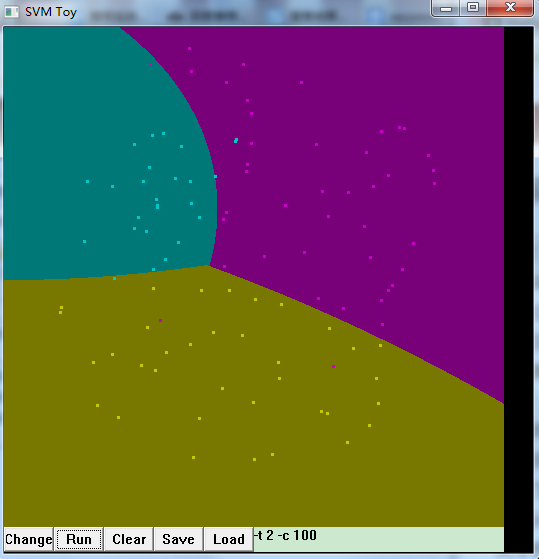
svm-toy.exe是一个可视化应用程序,显示了对平面中数据点的分类。有change、run、clear、save、load及参数设置框,默认最大分类数为3,大家可以点点看,效果如下:
svm-scale.exe是对输入的数据特征进行归一化缩放,从而避免某些过大或过小特征值对分类效果的影响。使用方式如下:
svm-scale [options] data_filename,其中options列表有以下几种:
-l lower : x缩放最小值,默认为-1
-u upper : x缩放最大值,默认为1
-y y_lower y_upper : y scaling limits (default: no y scaling)
-s save_filename : save scaling parameters to save_filename
-r restore_filename : restore scaling parameters from restore_filename
svm-train.exe对训练集训练,产生训练模型。使用方式如下:
svm-train [options] training_set_file [model_file],其中常用options列表有以下几种:
-s svm_type : SVM类型 (默认0)
0 – C-SVC (多类分类器)
1 – nu-SVC (多类分类器)
2 – one-class SVM
3 – epsilon-SVR (回归)
4 – nu-SVR (回归)
-t kernel_type : 核函数类型 (默认 2)
0 – 线性核:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 975
975

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









