






CAAI2024算法挑战赛——无人机视角下的可见光-红外光双光目标检测
算法大赛赛题介绍
背景介绍
基于无人机的车辆检测在智能城市交通管理和救灾工作中发挥着重要作用。配备摄像头的无人机可以收集具有广角视野的图像,这更有助于捕捉地面上的目标。然而,由于背景高度复杂和光照频繁变化,基于航空图像的目标检测仍然是计算机视觉领域中一个活跃且具有挑战性的任务。考虑到红外摄像头在全天时成像中的鲁棒性,本赛道引入了红外图像来为可见光模态提供互补信息,从而形成可见光-红外图像对。本赛道提供无人机视角下的双光目标检测数据集,涵盖了包括城市道路、农村地区、居住区、停车场以及从白天到晚上的多个场景,示例如下图所示。

本文提供的一些思路——针对细粒度的目标检测(像素级的融合+检测)
常见的多模态融合思路
参考如下文章:图像融合方法总结
图像融合的层级划分:

像素级融合
直接对个幅图像的像素点进行信息融合。
像素级融合的局限性:
- 图像原始数据规模导致算法实现费时;
- 对硬件的设施的要求相当高,进行图像融合时,配准的精度要求精确的各传感器数据之间每个像素;
- 因为基于像素计算,像素信息易受污染,噪声等干扰,所以效果不稳定。
- 数据未经处理,传感器原始信息的优缺点会叠加,影响融合效果;
特征级融合
特征级图像融合涉及对图像进行特征抽取,并综合处理边缘、形状、轮廓和局部特征等信息。它主要包括目标状态信息融合和目标特征性融合。该过程涵盖以下模块:源图像获取、图像预处理、图像分割、特征提取、特征数据融合以及目标识别。
特征提取是一种数据处理方式,通过降低数据量同时保留大部分信息,来优化处理效率,尽管在此过程中会损失部分细节信息。原始特征的组合能增加特征维数,提高目标识别准确率。
特征向量可以直接融合,也可以根据特征本身的属性(如边缘、形状、轮廓等)进行重新组合,这些参数的几何变换同样具备特定的特征属性。
目标状态特征融合
特征级图像融合是基于多尺度和多分辨率的目标统计特征,提取图像原始数据状态并经过严格配准,形成包含更丰富信息的图像。其核心在于精确估计多传感器目标状态,并与先验知识关联,广泛应用于目标跟踪等领域。
目标特性融合
特征级图像融合重组图像特征,构建代表性特征向量,通过融合增加维度,提升识别精确度。多传感器信息扩展特征空间,提高识别率。该技术涵盖图像分割、特征提取及特征融合等方面。
决策级融合
决策级融合整合多个传感器识别结果,基于规则综合特征提取和初步决策,形成全局最优决策。它基于目标的认识框架,通过预处理、特征提取和识别后,利用最优化算法融合结果。尽管提高了准确性,但多传感器数据也增加了复杂性和误差风险。设计系统时需考虑传感器性能和决策函数鲁棒性。
决策级融合的优点:
- 数据要求低,刚干扰能力强;
- 高效的兼容了多传感器的环境特征信息;
- 很好的纠错能力,通过适当的融合,消除单个传感器造成的误差,系统还能获得正确的结果。
- 具有很好的实时性、自适应性;
一些图像融合过程中的关键问题及解决思路
Q1: 可见光,红外光两种模态为什么要融合?如何充分利用?
优势互补:可见光图像分辨率和对比度比较高,但在夜间及恶劣天气等弱光条件下成像困难;而红外图像则可以进行全天时的探测,能捕捉到可见光图像无法反映的物体情况。这种互补性使得融合两种图像可以获得对场景更为丰富的语义信息。
增强信息获取的能力:通过融合处理,可以综合利用两种光线的信息,提高图像的质量和细节。红外光可以穿透一些可见光无法穿透的物体,如烟雾、云层等,因此可以提供更多的信息;而可见光则可以提供更多的颜色和纹理信息。
充分利用的方法有图像融合技术:采用像素级、特征级和决策级等不同的融合方法,将多幅图像融合成一幅图像。常用的有基于像素级分析的算法,即将两种信号的每个像素按照比例融合起来;基于区域分析的算法,将图片区域分割为不同的区域,再对区域进行融合;以及基于目标检测分析的算法,将两者的目标检测结果进行融合。
应用拓展:
- 军事领域:用于夜视仪、导弹制导系统等设备,提高目标识别和跟踪的准确性。
- 环境监测:用于火灾监测和空气质量监测,提高监测的精度和效率。
- 医疗领域:用于皮肤病的诊断和治疗,提高医疗的准确性和效果。
- 智能交通:实现对车辆和行人的智能识别和跟踪,提高交通安全和效率。
- 安防监控:提高监控摄像头的图像增强,提高监控的准确性和可靠性。
- 航空航天:用于卫星图像的解译和地球观测,为科学研究和资源管理提供重要支持。
综上所述,可见光与红外光两种模态的融合旨在充分利用两者的互补性,通过图像融合技术提高信息获取的全面性和准确性,并在多个领域实现广泛的应用。
Q2: 语义信息如何进行融合?
本文采用了最方便的融合思路,即像素级融合。对于红外图像和可见光图像的融合,采用了FusionGAN网络,通过把红外和可见光图像分别输入到网络中,经过前向传递,即可得到融合后的图像,该图像汇集了红外图像和可见光图像的语义信息,可以为后续的检测任务作准备。
Q3: 图像的配准问题如何解决?
图像配准的一般步骤如下:
- 图像获取:首先,获取需要融合的源图像,这些图像可能来自不同的传感器或不同的时间点。
- 特征提取:从源图像中提取特征点或特征区域,这些特征通常用于后续的配准过程。
- 特征匹配:对提取的特征进行匹配,以确定源图像之间的空间变换关系。这通常通过比较特征之间的相似性来实现。
- 空间变换:根据匹配的特征,计算出一个空间变换模型(如仿射变换、投影变换或非线性变换等),将一幅图像映射到另一幅图像的空间上,使它们达到空间上的对齐。
- 插值和重采样:使用插值算法对变换后的图像进行重采样,以生成配准后的图像。
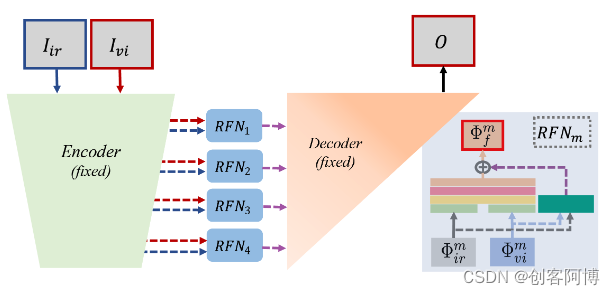
本文像素级融合的实现(RFN-Nest)
在FusionGAN图像融合网络中,一旦源图像经过配准处理,就可以输入到FusionGAN中进行融合。FusionGAN的作用是通过其生成对抗性架构,结合生成器和鉴别器的对抗性游戏,生成具有主要红外强度和额外可见光梯度的融合图像。生成器的目标是生成融合图像,而鉴别器的目标是确保融合图像在可见光图像中具有更多的细节。这样,最终的融合图像能够同时保持红外图像中的热辐射和可见光图像中的纹理。
具体的FusionGAN的实现代码请参照如下地址:
https://github.com/hli1221/imagefusion-rfn-nest
RFN-Nest网络架构
参考如下文章:
图像融合笔记(一):RFN-Nest
RFN-Nest: An end-to-end residual fusion network for infrared and visible images
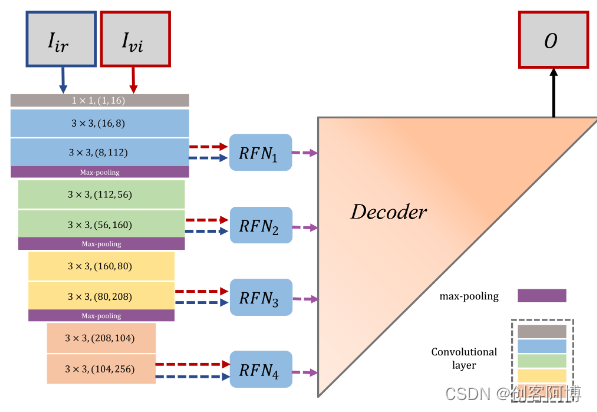
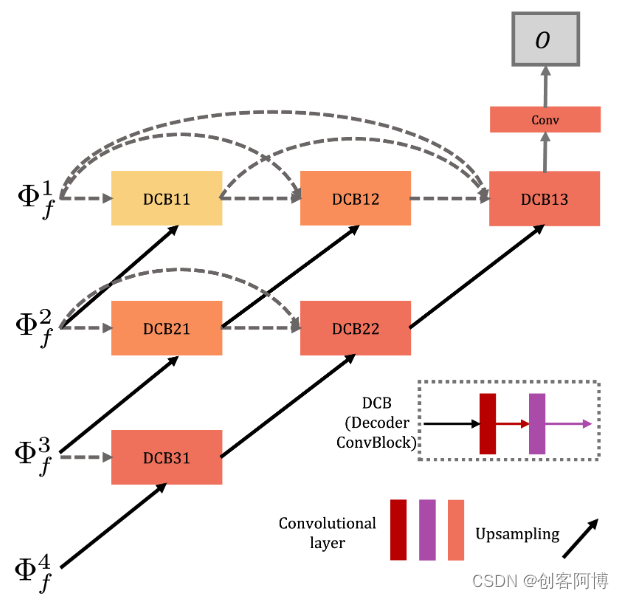
- RFN-Nest包含三个部分:编码器网络、用于提取融合的多尺度深度特征的残差融合网络以及基于nest连接的解码器网络
- 虽然所提出网络的编码器和解码器与NestFuse相似,但融合策略、训练策略和损失函数完全不同。
首先,论文设计了几个简单而高效的可学习的融合网络(RFN),并将其插入到自编码器结构中,而不是融合NestFuse的手工功能。通过RFN,基于自编码的融合网络升级为端到端融合网络。
其次,由于RFN是一个可学习的结构,编码器和解码器具有强大的特征提取和特征重建能力,因此论文开发了一个两阶段训练策略来训练我们的融合网络(编码器、解码器和RFN网络)
在同时保留可见光图像的细节信息和红外图像的显著特征情况下,为了训练提出的RFN网络,论文提出了损失函数—— L R F N L_{RFN} LRFN
融合框架
Decoder架构
训练模块
代码实现
本文是基于官方开源的代码进行了修改,之后进行训练和融合。主要做了多卡训练的修改。
RFN-Nest官方开源地址:hli1221/imagefusion-rfn-nest
修改后的RFN-Nest本文开源地址: https://github.com/shineber/AAAI_2024_Contest
准备数据集(把官方给的数据集转换成RFN-Nest可以训练的格式)
文件夹的目录如下图所示
训练网络(官方开源的RFN-Nest是单卡训练,这里本文做了并行训练的代码)
单卡训练(官方给出)
使用单卡训练网络的这部分主要更改的是train_fusionnet.py这个文件。
# Training a NestFuse network
# auto-encoder
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "0,1"
import sys
import time
from tqdm import tqdm, trange
import scipy.io as scio
import random
import torch
from torch.optim import Adam
from torch.autograd import Variable
import utils
from net import NestFuse_light2_nodense, Fusion_network
from args_fusion import args
import pytorch_msssim
EPSILON = 1e-5
def main():
original_imgs_path, _ = utils.list_images(args.dataset_ir)
train_num = 80000
original_imgs_path = original_imgs_path[:train_num]
random.shuffle(original_imgs_path)
# True - RGB , False - gray
img_flag = False
alpha_list = [700]
w_all_list = [[6.0, 3.0]]
for w_w in w_all_list:
w1, w2 = w_w
for alpha in alpha_list:
train(original_imgs_path, img_flag, alpha, w1, w2)
def train(original_imgs_path, img_flag, alpha, w1, w2):
batch_size = args.batch_size
# load network model
nc = 1
input_nc = nc
output_nc = nc
nb_filter = [64, 112, 160, 208, 256]
f_type = 'res'
with torch.no_grad():
deepsupervision = False
nest_model = NestFuse_light2_nodense(nb_filter, input_nc, output_nc, deepsupervision)
model_path = args.resume_nestfuse
# load auto-encoder network
print('Resuming, initializing auto-encoder using weight from {}.'.format(model_path))
nest_model.load_state_dict(torch.load(model_path))
nest_model.eval()
# fusion network
fusion_model = Fusion_network(nb_filter, f_type)
if args.resume_fusion_model is not None:
print('Resuming, initializing fusion net using weight from {}.'.format(args.resume_fusion_model))
fusion_model.load_state_dict(torch.load(args.resume_fusion_model))
optimizer = Adam(fusion_model.parameters(), args.lr)
mse_loss = torch.nn.MSELoss()
ssim_loss = pytorch_msssim.msssim
if args.cuda:
nest_model.cuda()
fusion_model.cuda()
tbar = trange(args.epochs)
print('Start training.....')
# creating save path
temp_path_model = os.path.join(args.save_fusion_model)
temp_path_loss = os.path.join(args.save_loss_dir)
if os.path.exists(temp_path_model) is False:
os.mkdir(temp_path_model)
if os.path.exists(temp_path_loss) is False:
os.mkdir(temp_path_loss)
temp_path_model_w = os.path.join(args.save_fusion_model, str(w1))
temp_path_loss_w = os.path.join(args.save_loss_dir, str(w1))
if os.path.exists(temp_path_model_w) is False:
os.mkdir(temp_path_model_w)
if os.path.exists(temp_path_loss_w) is False:
os.mkdir(temp_path_loss_w)
Loss_feature = []
Loss_ssim = []
Loss_all = []
count_loss = 0
all_ssim_loss = 0.
all_fea_loss = 0.
for e in tbar:
print('Epoch %d.....' % e)
# load training database
image_set_ir, batches = utils.load_dataset(original_imgs_path, batch_size)
fusion_model.train()
count = 0
for batch in range(batches):
image_paths_ir = image_set_ir[batch * batch_size:(batch * batch_size + batch_size)]
img_ir = utils.get_train_images(image_paths_ir, height=args.HEIGHT, width=args.WIDTH, flag=img_flag)
image_paths_vi = [x.replace('lwir', 'visible') for x in image_paths_ir]
img_vi = utils.get_train_images(image_paths_vi, height=args.HEIGHT, width=args.WIDTH, flag=img_flag)
count += 1
optimizer.zero_grad()
img_ir = Variable(img_ir, requires_grad=False)
img_vi = Variable(img_vi, requires_grad=False)
if args.cuda:
img_ir = img_ir.cuda()
img_vi = img_vi.cuda()
# get fusion image
# encoder
en_ir = nest_model.encoder(img_ir)
en_vi = nest_model.encoder(img_vi)
# fusion
f = fusion_model(en_ir, en_vi)
# decoder
outputs = nest_model.decoder_eval(f)
# resolution loss: between fusion image and visible image
x_ir = Variable(img_ir.data.clone(), requires_grad=False)
x_vi = Variable(img_vi.data.clone(), requires_grad=False)
######################### LOSS FUNCTION #########################
loss1_value = 0.
loss2_value = 0.
for output in outputs:
output = (output - torch.min(output)) / (torch.max(output) - torch.min(output) + EPSILON)
output = output * 255
# ---------------------- LOSS IMAGES ------------------------------------
# detail loss
# ssim_loss_temp1 = ssim_loss(output, x_ir, normalize=True)
ssim_loss_temp2 = ssim_loss(output, x_vi, normalize=True)
loss1_value += alpha * (1 - ssim_loss_temp2)
# feature loss
g2_ir_fea = en_ir
g2_vi_fea = en_vi
g2_fuse_fea = f
# w_ir = [3.5, 3.5, 3.5, 3.5]
w_ir = [w1, w1, w1, w1]
w_vi = [w2, w2, w2, w2]
w_fea = [1, 10, 100, 1000]
for ii in range(4):
g2_ir_temp = g2_ir_fea[ii]
g2_vi_temp = g2_vi_fea[ii]
g2_fuse_temp = g2_fuse_fea[ii]
(bt, cht, ht, wt) = g2_ir_temp.size()
loss2_value += w_fea[ii]*mse_loss(g2_fuse_temp, w_ir[ii]*g2_ir_temp + w_vi[ii]*g2_vi_temp)
loss1_value /= len(outputs)
loss2_value /= len(outputs)
# total loss
total_loss = loss1_value + loss2_value
total_loss.backward()
optimizer.step()
all_fea_loss += loss2_value.item() #
all_ssim_loss += loss1_value.item() #
if (batch + 1) % args.log_interval == 0:
mesg = "{}\t Alpha: {} \tW-IR: {}\tEpoch {}:\t[{}/{}]\t ssim loss: {:.6f}\t fea loss: {:.6f}\t total: {:.6f}".format(
time.ctime(), alpha, w1, e + 1, count, batches,
all_ssim_loss / args.log_interval,
all_fea_loss / args.log_interval,
(all_fea_loss + all_ssim_loss) / args.log_interval
)
tbar.set_description(mesg)
Loss_ssim.append( all_ssim_loss / args.log_interval)
Loss_feature.append(all_fea_loss / args.log_interval)
Loss_all.append((all_fea_loss + all_ssim_loss) / args.log_interval)
count_loss = count_loss + 1
all_ssim_loss = 0.
all_fea_loss = 0.
if (batch + 1) % (200 * args.log_interval) == 0:
# save model
fusion_model.eval()
fusion_model.cpu()
save_model_filename = "Epoch_" + str(e) + "_iters_" + str(count) + "_alpha_" + str(alpha) + "_wir_" + str(w1) + "_wvi_" + str(w2) + ".model"
save_model_path = os.path.join(temp_path_model, save_model_filename)
torch.save(fusion_model.state_dict(), save_model_path)
# save loss data
# pixel loss
loss_data_ssim = Loss_ssim
loss_filename_path = temp_path_loss_w + "/loss_ssim_epoch_" + str(args.epochs) + "_iters_" + str(count) + "_alpha_" + str(alpha) + "_wir_" + str(w1) + "_wvi_" + str(w2) + ".mat"
scio.savemat(loss_filename_path, {'loss_ssim': loss_data_ssim})
# SSIM loss
loss_data_fea = Loss_feature
loss_filename_path = temp_path_loss_w + "/loss_fea_epoch_" + str(args.epochs) + "_iters_" + str(count) + "_alpha_" + str(alpha) + "_wir_" + str(w1) + "_wvi_" + str(w2) + ".mat"
scio.savemat(loss_filename_path, {'loss_fea': loss_data_fea})
# all loss
loss_data = Loss_all
loss_filename_path = temp_path_loss_w + "/loss_all_epoch_" + str(args.epochs) + "_iters_" + str(count) + "_alpha_" + str(alpha) + "_wir_" + str(w1) + "_wvi_" + str(w2) + ".mat"
scio.savemat(loss_filename_path, {'loss_all': loss_data})
fusion_model.train()
fusion_model.cuda()
tbar.set_description("\nCheckpoint, trained model saved at", save_model_path)
# ssim loss
loss_data_ssim = Loss_ssim
loss_filename_path = temp_path_loss_w + "/Final_loss_ssim_epoch_" + str(
args.epochs) + "_alpha_" + str(alpha) + "_wir_" + str(w1) + "_wvi_" + str(w2) + ".mat"
scio.savemat(loss_filename_path, {'final_loss_ssim': loss_data_ssim})
loss_data_fea = Loss_feature
loss_filename_path = temp_path_loss_w + "/Final_loss_2_epoch_" + str(
args.epochs) + "_alpha_" + str(alpha) + "_wir_" + str(w1) + "_wvi_" + str(w2) + ".mat"
scio.savemat(loss_filename_path, {'final_loss_fea': loss_data_fea})
# SSIM loss
loss_data = Loss_all
loss_filename_path = temp_path_loss_w + "/Final_loss_all_epoch_" + str(
args.epochs) + "_alpha_" + str(alpha) + "_wir_" + str(w1) + "_wvi_" + str(w2) + ".mat"
scio.savemat(loss_filename_path, {'final_loss_all': loss_data})
# save model
fusion_model.eval()
fusion_model.cpu()
save_model_filename = "Final_epoch_" + str(args.epochs) + "_alpha_" + str(alpha) + "_wir_" + str(
w1) + "_wvi_" + str(w2) + ".model"
save_model_path = os.path.join(temp_path_model_w, save_model_filename)
torch.save(fusion_model.state_dict(), save_model_path)
print("\nDone, trained model saved at", save_model_path)
def check_paths(args):
try:
if not os.path.exists(args.vgg_model_dir):
os.makedirs(args.vgg_model_dir)
if not os.path.exists(args.save_model_dir):
os.makedirs(args.save_model_dir)
except OSError as e:
print(e)
sys.exit(1)
if __name__ == "__main__":
main()
多卡训练(本文基于官方的单卡训练修改,可直接使用)
使用多卡训练网络的这部分主要更改的是train_fusionnet_parrel.py这个文件。直接运行这个文件即可。具体的参数在args_fusion.py里面配置数据集路径、model文件,这个基本不需要你改。
# Training a NestFuse network
# auto-encoder
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "0,1"
# from torch.nn.parallel import DataParallel
import torch.nn as nn
import sys
import time
from tqdm import tqdm, trange
import scipy.io as scio
import random
import torch
from torch.optim import Adam
from torch.autograd import Variable
import utils
from net import NestFuse_light2_nodense, Fusion_network
from args_fusion import args
import pytorch_msssim
EPSILON = 1e-5
def main():
original_imgs_path, _ = utils.list_images(args.dataset_ir)
train_num = 80000
original_imgs_path = original_imgs_path[:train_num]
random.shuffle(original_imgs_path)
# True - RGB , False - gray
img_flag = False
alpha_list = [700]
w_all_list = [[6.0, 3.0]]
for w_w in w_all_list:
w1, w2 = w_w
for alpha in alpha_list:
train(original_imgs_path, img_flag, alpha, w1, w2)
def train(original_imgs_path, img_flag, alpha, w1, w2):
batch_size = args.batch_size
# load network model
nc = 1
input_nc = nc
output_nc = nc
nb_filter = [64, 112, 160, 208, 256]
f_type = 'res'
with torch.no_grad():
deepsupervision = False
nest_model = NestFuse_light2_nodense(nb_filter, input_nc, output_nc, deepsupervision)
# nest_model = DataParallel(nest_model, device_ids=[0, 1])
nest_model = nn.DataParallel(nest_model).cuda()
model_path = args.resume_nestfuse
# load auto-encoder network
#//zsb
state_dict = torch.load(model_path)
new_state_dict = {}
for key, value in state_dict.items():
new_key = key
if not key.startswith('module.'):
new_key = 'module.' + key
new_state_dict[new_key] = value
nest_model.load_state_dict(new_state_dict)
print('Resuming, initializing auto-encoder using weight from {}.'.format(model_path))
# nest_model.load_state_dict(torch.load(model_path))
nest_model.eval()
# fusion network
fusion_model = Fusion_network(nb_filter, f_type)
# fusion_model = DataParallel(fusion_model, device_ids=[0,1])
fusion_model = nn.DataParallel(fusion_model).cuda()
if args.resume_fusion_model is not None:
print('Resuming, initializing fusion net using weight from {}.'.format(args.resume_fusion_model))
fusion_model.load_state_dict(torch.load(args.resume_fusion_model))
optimizer = Adam(fusion_model.parameters(), args.lr)
mse_loss = torch.nn.MSELoss()
ssim_loss = pytorch_msssim.msssim
if args.cuda:
nest_model.cuda()
fusion_model.cuda()
tbar = trange(args.epochs)
print('Start training.....')
# creating save path
temp_path_model = os.path.join(args.save_fusion_model)
temp_path_loss = os.path.join(args.save_loss_dir)
if os.path.exists(temp_path_model) is False:
os.mkdir(temp_path_model)
if os.path.exists(temp_path_loss) is False:
os.mkdir(temp_path_loss)
temp_path_model_w = os.path.join(args.save_fusion_model, str(w1))
temp_path_loss_w = os.path.join(args.save_loss_dir, str(w1))
if os.path.exists(temp_path_model_w) is False:
os.mkdir(temp_path_model_w)
if os.path.exists(temp_path_loss_w) is False:
os.mkdir(temp_path_loss_w)
Loss_feature = []
Loss_ssim = []
Loss_all = []
count_loss = 0
all_ssim_loss = 0.
all_fea_loss = 0.
for e in tbar:
print('Epoch %d.....' % e)
# load training database
image_set_ir, batches = utils.load_dataset(original_imgs_path, batch_size)
fusion_model.train()
count = 0
for batch in range(batches):
image_paths_ir = image_set_ir[batch * batch_size:(batch * batch_size + batch_size)]
img_ir = utils.get_train_images(image_paths_ir, height=args.HEIGHT, width=args.WIDTH, flag=img_flag)
image_paths_vi = [x.replace('lwir', 'visible') for x in image_paths_ir]
img_vi = utils.get_train_images(image_paths_vi, height=args.HEIGHT, width=args.WIDTH, flag=img_flag)
count += 1
optimizer.zero_grad()
img_ir = Variable(img_ir, requires_grad=False)
img_vi = Variable(img_vi, requires_grad=False)
if args.cuda:
img_ir = img_ir.cuda()
img_vi = img_vi.cuda()
# get fusion image
# encoder//zsb
en_ir = nest_model.module.encoder(img_ir)
en_vi = nest_model.module.encoder(img_vi)
# en_ir = nest_model.encoder(img_ir)
# en_vi = nest_model.encoder(img_vi)
# fusion
f = fusion_model(en_ir, en_vi)
# decoder//zsb
outputs = nest_model.module.decoder_eval(f)
# outputs = nest_model.decoder_eval(f)
# resolution loss: between fusion image and visible image
x_ir = Variable(img_ir.data.clone(), requires_grad=False)
x_vi = Variable(img_vi.data.clone(), requires_grad=False)
######################### LOSS FUNCTION #########################
loss1_value = 0.
loss2_value = 0.
for output in outputs:
output = (output - torch.min(output)) / (torch.max(output) - torch.min(output) + EPSILON)
output = output * 255
# ---------------------- LOSS IMAGES ------------------------------------
# detail loss
# ssim_loss_temp1 = ssim_loss(output, x_ir, normalize=True)
ssim_loss_temp2 = ssim_loss(output, x_vi, normalize=True)
loss1_value += alpha * (1 - ssim_loss_temp2)
# feature loss
g2_ir_fea = en_ir
g2_vi_fea = en_vi
g2_fuse_fea = f
# w_ir = [3.5, 3.5, 3.5, 3.5]
w_ir = [w1, w1, w1, w1]
w_vi = [w2, w2, w2, w2]
w_fea = [1, 10, 100, 1000]
for ii in range(4):
g2_ir_temp = g2_ir_fea[ii]
g2_vi_temp = g2_vi_fea[ii]
g2_fuse_temp = g2_fuse_fea[ii]
(bt, cht, ht, wt) = g2_ir_temp.size()
loss2_value += w_fea[ii]*mse_loss(g2_fuse_temp, w_ir[ii]*g2_ir_temp + w_vi[ii]*g2_vi_temp)
loss1_value /= len(outputs)
loss2_value /= len(outputs)
# total loss
total_loss = loss1_value + loss2_value
total_loss.backward()
optimizer.step()
all_fea_loss += loss2_value.item() #
all_ssim_loss += loss1_value.item() #
if (batch + 1) % args.log_interval == 0:
mesg = "{}\t Alpha: {} \tW-IR: {}\tEpoch {}:\t[{}/{}]\t ssim loss: {:.6f}\t fea loss: {:.6f}\t total: {:.6f}".format(
time.ctime(), alpha, w1, e + 1, count, batches,
all_ssim_loss / args.log_interval,
all_fea_loss / args.log_interval,
(all_fea_loss + all_ssim_loss) / args.log_interval
)
tbar.set_description(mesg)
Loss_ssim.append( all_ssim_loss / args.log_interval)
Loss_feature.append(all_fea_loss / args.log_interval)
Loss_all.append((all_fea_loss + all_ssim_loss) / args.log_interval)
count_loss = count_loss + 1
all_ssim_loss = 0.
all_fea_loss = 0.
if (batch + 1) % (200 * args.log_interval) == 0:
# save model
fusion_model.eval()
fusion_model.cpu()
save_model_filename = "Epoch_" + str(e) + "_iters_" + str(count) + "_alpha_" + str(alpha) + "_wir_" + str(w1) + "_wvi_" + str(w2) + ".model"
save_model_path = os.path.join(temp_path_model, save_model_filename)
torch.save(fusion_model.state_dict(), save_model_path)
# save loss data
# pixel loss
loss_data_ssim = Loss_ssim
loss_filename_path = temp_path_loss_w + "/loss_ssim_epoch_" + str(args.epochs) + "_iters_" + str(count) + "_alpha_" + str(alpha) + "_wir_" + str(w1) + "_wvi_" + str(w2) + ".mat"
scio.savemat(loss_filename_path, {'loss_ssim': loss_data_ssim})
# SSIM loss
loss_data_fea = Loss_feature
loss_filename_path = temp_path_loss_w + "/loss_fea_epoch_" + str(args.epochs) + "_iters_" + str(count) + "_alpha_" + str(alpha) + "_wir_" + str(w1) + "_wvi_" + str(w2) + ".mat"
scio.savemat(loss_filename_path, {'loss_fea': loss_data_fea})
# all loss
loss_data = Loss_all
loss_filename_path = temp_path_loss_w + "/loss_all_epoch_" + str(args.epochs) + "_iters_" + str(count) + "_alpha_" + str(alpha) + "_wir_" + str(w1) + "_wvi_" + str(w2) + ".mat"
scio.savemat(loss_filename_path, {'loss_all': loss_data})
fusion_model.train()
fusion_model.cuda()
tbar.set_description("\nCheckpoint, trained model saved at", save_model_path)
# ssim loss
loss_data_ssim = Loss_ssim
loss_filename_path = temp_path_loss_w + "/Final_loss_ssim_epoch_" + str(
args.epochs) + "_alpha_" + str(alpha) + "_wir_" + str(w1) + "_wvi_" + str(w2) + ".mat"
scio.savemat(loss_filename_path, {'final_loss_ssim': loss_data_ssim})
loss_data_fea = Loss_feature
loss_filename_path = temp_path_loss_w + "/Final_loss_2_epoch_" + str(
args.epochs) + "_alpha_" + str(alpha) + "_wir_" + str(w1) + "_wvi_" + str(w2) + ".mat"
scio.savemat(loss_filename_path, {'final_loss_fea': loss_data_fea})
# SSIM loss
loss_data = Loss_all
loss_filename_path = temp_path_loss_w + "/Final_loss_all_epoch_" + str(
args.epochs) + "_alpha_" + str(alpha) + "_wir_" + str(w1) + "_wvi_" + str(w2) + ".mat"
scio.savemat(loss_filename_path, {'final_loss_all': loss_data})
# save model
fusion_model.eval()
fusion_model.cpu()
save_model_filename = "Final_epoch_" + str(args.epochs) + "_alpha_" + str(alpha) + "_wir_" + str(
w1) + "_wvi_" + str(w2) + ".model"
save_model_path = os.path.join(temp_path_model_w, save_model_filename)
torch.save(fusion_model.state_dict(), save_model_path)
print("\nDone, trained model saved at", save_model_path)
def check_paths(args):
try:
if not os.path.exists(args.vgg_model_dir):
os.makedirs(args.vgg_model_dir)
if not os.path.exists(args.save_model_dir):
os.makedirs(args.save_model_dir)
except OSError as e:
print(e)
sys.exit(1)
if __name__ == "__main__":
main()
训练出的权重文件
训练得到的model文件在models/train/fusionnet文件夹里面,训练的loss在models/train/loss_fusionnet文件夹里面,这个可以在args_fusion.py里面修改save_loss_dir和save_fusion_model即可
测试集可见光-红外图像融合
这一步将赛题官方所给的可见光-红外的test集图片进行融合。融合的结果可以在outputs文件夹里面找到。这一步主要改的文件是test_40pairs.py
这里主要修改output_path_root(即输出路径)和test_path(测试集路径)
代码如下
# test phase
import os
import torch
from torch.autograd import Variable
from net import NestFuse_light2_nodense, Fusion_network, Fusion_strategy
import utils
from args_fusion import args
import numpy as np
def load_model(path_auto, path_fusion, fs_type, flag_img):
if flag_img is True:
nc = 3
else:
nc =1
input_nc = nc
output_nc = nc
nb_filter = [64, 112, 160, 208, 256]
nest_model = NestFuse_light2_nodense(nb_filter, input_nc, output_nc, deepsupervision=False)
nest_model.load_state_dict(torch.load(path_auto))
fusion_model = Fusion_network(nb_filter, fs_type)
fusion_model.load_state_dict(torch.load(path_fusion))
fusion_strategy = Fusion_strategy(fs_type)
para = sum([np.prod(list(p.size())) for p in nest_model.parameters()])
type_size = 4
print('Model {} : params: {:4f}M'.format(nest_model._get_name(), para * type_size / 1000 / 1000))
para = sum([np.prod(list(p.size())) for p in fusion_model.parameters()])
type_size = 4
print('Model {} : params: {:4f}M'.format(fusion_model._get_name(), para * type_size / 1000 / 1000))
nest_model.eval()
fusion_model.eval()
nest_model.cuda()
fusion_model.cuda()
return nest_model, fusion_model, fusion_strategy
def run_demo(nest_model, fusion_model, fusion_strategy, infrared_path, visible_path, output_path_root, name_ir, fs_type, use_strategy, flag_img, alpha):
img_ir, h, w, c = utils.get_test_image(infrared_path, flag=flag_img) # True for rgb
img_vi, h, w, c = utils.get_test_image(visible_path, flag=flag_img)
# dim = img_ir.shape
if c is 1:
if args.cuda:
img_ir = img_ir.cuda()
img_vi = img_vi.cuda()
img_ir = Variable(img_ir, requires_grad=False)
img_vi = Variable(img_vi, requires_grad=False)
# encoder
en_r = nest_model.encoder(img_ir)
en_v = nest_model.encoder(img_vi)
# fusion net
if use_strategy:
f = fusion_strategy(en_r, en_v)
else:
f = fusion_model(en_r, en_v)
# decoder
img_fusion_list = nest_model.decoder_eval(f)
else:
# fusion each block
img_fusion_blocks = []
for i in range(c):
# encoder
img_vi_temp = img_vi[i]
img_ir_temp = img_ir[i]
if args.cuda:
img_vi_temp = img_vi_temp.cuda()
img_ir_temp = img_ir_temp.cuda()
img_vi_temp = Variable(img_vi_temp, requires_grad=False)
img_ir_temp = Variable(img_ir_temp, requires_grad=False)
en_r = nest_model.encoder(img_ir_temp)
en_v = nest_model.encoder(img_vi_temp)
# fusion net
if use_strategy:
f = fusion_strategy(en_r, en_v)
else:
f = fusion_model(en_r, en_v)
# decoder
img_fusion_temp = nest_model.decoder_eval(f)
img_fusion_blocks.append(img_fusion_temp)
img_fusion_list = utils.recons_fusion_images(img_fusion_blocks, h, w)
# ########################### multi-outputs ##############################################
output_count = 0
for img_fusion in img_fusion_list:
file_name = 'fused_' + str(alpha) + '_' + name_ir
output_path = output_path_root + file_name
output_count += 1
# save images
utils.save_image_test(img_fusion, output_path)
print(output_path)
def main():
# False - gray
flag_img = False
# ################# gray scale ########################################
test_path = "images/40_pairs_tno_vot/ir/"
path_auto = args.resume_nestfuse
output_path_root = "./outputs/alpha_1e4_40/"
if os.path.exists(output_path_root) is False:
os.mkdir(output_path_root)
fs_type = 'res' # res (RFN), add, avg, max, spa, nuclear
use_strategy = False # True - static strategy; False - RFN
path_fusion_root = args.fusion_model
with torch.no_grad():
alpha_list = [700]
w_all_list = [[6.0, 3.0]]
for alpha in alpha_list:
for w_all in w_all_list:
w, w2 = w_all
temp = 'rfnnest_' + str(alpha) + '_wir_' + str(w) + '_wvi_' + str(w2)
output_path_list = 'fused_' + temp + '_40'
output_path1 = output_path_root + output_path_list + '/'
if os.path.exists(output_path1) is False:
os.mkdir(output_path1)
output_path = output_path1
# load network
path_fusion = path_fusion_root + str(w) + '/' + 'Final_epoch_2_alpha_' + str(alpha) + '_wir_' + str(
w) + '_wvi_' + str(w2) + '_ssim_vi.model'
model, fusion_model, fusion_strategy = load_model(path_auto, path_fusion, fs_type, flag_img)
imgs_paths_ir, names = utils.list_images(test_path)
num = len(imgs_paths_ir)
for i in range(num):
name_ir = names[i]
infrared_path = imgs_paths_ir[i]
visible_path = infrared_path.replace('ir/', 'vis/')
if visible_path.__contains__('IR'):
visible_path = visible_path.replace('IR', 'VIS')
else:
visible_path = visible_path.replace('i.', 'v.')
run_demo(model, fusion_model, fusion_strategy, infrared_path, visible_path, output_path, name_ir, fs_type, use_strategy, flag_img, temp)
print('Done......')
if __name__ == '__main__':
main()
结果如下(在output_path_root里面找)
两种模态融合图像的检测(YOLO-V9)
对于融合之后的图像进行目标检测,使用的是YOLO-V9检测网络。官方的代码地址如下: https://github.com/WongKinYiu/yolov9
YOLO-V9的架构
训练前的准备工作
数据集转换成YOLO格式
Environment和相关依赖的安装(官方给出的是Docker方式,本文给出的是conda方式)
基于Docker的方式安装(官方给出)
# create the docker container, you can change the share memory size if you have more.
nvidia-docker run --name yolov9 -it -v your_coco_path/:/coco/ -v your_code_path/:/yolov9 --shm-size=64g nvcr.io/nvidia/pytorch:21.11-py3
# apt install required packages
apt update
apt install -y zip htop screen libgl1-mesa-glx
# pip install required packages
pip install seaborn thop
# go to code folder
cd /yolov9
本文的方式(直接安装requirements.txt)
环境创建
conda create -n aaai2024 python = 3.7
conda activate aaai2024
依赖的安装
pip install -r requirements.txt
训练过程(本文已经整合成sh文件,直接运行即可,不需要像官方代码那样运行)
命令行可以参考官方给出的,后面是本文自己实现之后对于这些参数的介绍。
python train_dual.py --workers 8 --device 0 --batch 16 --data data/coco.yaml --img 640 --cfg models/detect/yolov9-c.yaml --weights '' --name yolov9-c --hyp hyp.scratch-high.yaml --min-items 0 --epochs 500 --close-mosaic 15
在训练的时候需要配置下列的参数:epochs、batch-size、weights、data、device,其实这里你不需要怎么修改,可以直接使用,超参数可以先不用管。
测试集的推理过程(这里介绍可视化的结果,后文有官方要求结果的本文实现方式)
训练完网络之后,我们对测试集进行推理,可参考官方的命令。本文使用detect_dual.py,尽量不要使用detect.py,至于为什么,网上有篇帖子有踩过雷,暂时忘了是哪篇帖子了。
python detect_dual.py --source './data/images/horses.jpg' --img 640 --device 0 --weights './yolov9-c.pt' --name yolov9_c_640_detect
测试集的目标检测部分结果展示(细粒度的检测效果一般,会出现误检的问题,目前没有想到更好的解决办法)


测试结果的提交(官方要求JSON格式,因此本文做了YOLO输出的bbox转换成指定的JSON格式)
本文得出的结果格式(先输出txt的文件,最后进行JSON格式的转化,官方并未给出)
输出txt文件是在yolov9官方源码中进行修改的,具体的修改方式如下(最方便的方式)
直接运行detect程序时候声明参数即可,输入如下的命令:
python detect_dual.py --save-txt --save-conf
- 一些说明:从左到右每一列代表的内容:图片id、类别id、bbox的四个参数、置信度

YOLO格式的bbox转换成COCO格式的bbox(bbox意义不一样)
注意:你需要改的是Labels_txt_Dir,其他的不需要改,本文提供的代码均已实现。
all_possible_image_ids = set(range(1001)) # 从0到1000
# 初始化一个空列表来存储最终的字典
label_dicts = []
# 读取labels.txt文件并收集存在的image_id
Labels_txt_Dir = '/Users/shineber/Desktop/Master_Period/Contest/CAAI_drone_detection/result/final_labels/V3.txt' # 替换为你的txt文件路径
existing_image_ids = set()
with open(Labels_txt_Dir, 'r') as file:
for line in file:
elements = line.strip().split()
if len(elements) == 7:
image_id = int(elements[0])
existing_image_ids.add(image_id)
# 提取其他信息并添加到字典中
category_id = int(elements[1])
x = round(float(elements[2]), 1)
y = round(float(elements[3]), 1)
width = round(float(elements[4]), 1)
height = round(float(elements[5]), 1)
score = round(float(elements[6]), 2)
label_dicts.append({
"image_id": image_id,
"category_id": category_id,
"bbox": [x, y, width, height],
"score": score
})
# 找出不存在的image_id并添加到字典列表中
for image_id in all_possible_image_ids - existing_image_ids:
label_dicts.append({
"image_id": image_id,
"category_id": None,
"bbox": None,
"score": None
})
# 将最终的字典列表写入JSON文件
with open('output_V3.json', 'w') as file:
import json
json.dump(label_dicts, file, indent=4)
print("Done")
本文的思路一些局限性的猜想
针对误检问题(细粒度目标检测比较常见的问题)
对于误检本身,可能的原因出现在了图像融合的方面(Image Fusion),由于本文是像素级融合,针对的是图像本身,可能红外光和可见光的信息并没有得到充分的互补,图像的语义信息并没有得到很好的提取。细粒度检测本身对于特征的要求比较高。
可能的解决方法
- 采用特征级融合
- 采用决策级融合
- 利用可见光和红外光分别进行检测,做个集成学习(针对打榜一个常用的策略)。
针对漏检问题(同样是细粒度目标检测比较常见的问题)
可能的原因(赛题所给数据集本身的问题——类别不平衡)
针对数据集本身,是具有一定局限性的。因为数据集中的各种车辆的类别并不均衡,这会使得网络在进行学习的时候,更多的学到了数量占比较大的车辆的模式,而忽略了类别占比较小的车辆的模式。
可能的解决方法
- 从数据集不平衡的方面入手
**方法1:**可以加入一些权重因子,让各个类别的车辆在训练过程中更加均衡。
**方法2:**进行数据集的扩增,比如对于类别少的车辆进行一些transform,使类别在数量上至少是差不多均衡的。
针对上述的一些猜想后序本文会做一些改进,同时会在github开源相关代码。
















 204
204

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









