







文章目录
一、简介
CuPy:是一个基于 NVIDIA CUDA 的高效数组处理库,它提供了与 NumPy 类似的 API,但能够利用 GPU 的强大计算能力来加速数组计算。通过将数据加载到 GPU 中,CuPy 可以显著提升一些数值计算、线性代数、傅里叶变换等操作的速度。
核心优势:能够利用 GPU 进行并行计算,从而加速大规模的数值运算。例如,当数组的维度非常大时,CuPy 可以利用 NVIDIA CUDA 加速,而 NumPy 则只能依赖 CPU。
- GPU 加速的数组运算:
- CUDA 内核编程: CuPy 还允许用户编写自定义的 CUDA 内核来执行更加特定的操作。通过 RawKernel 和 ElementwiseKernel,你可以编写 GPU 上运行的高效并行代码。
- CuPy 是一个使用 Python 进行 GPU 加速计算的开源数组库:利用 CUDA Toolkit 库(包括 cuBLAS、cuRAND、cuSOLVER、cuSPARSE、cuFFT、cuDNN 和 NCCL)充分利用 GPU 架构。
- CuPy 的接口与 NumPy 和 SciPy 高度兼容:在大多数情况下,它可以用作直接替换。需要做的只是在 Python 代码中将 numpy 和 scipy 替换为
cupy和cupyx.scipy。
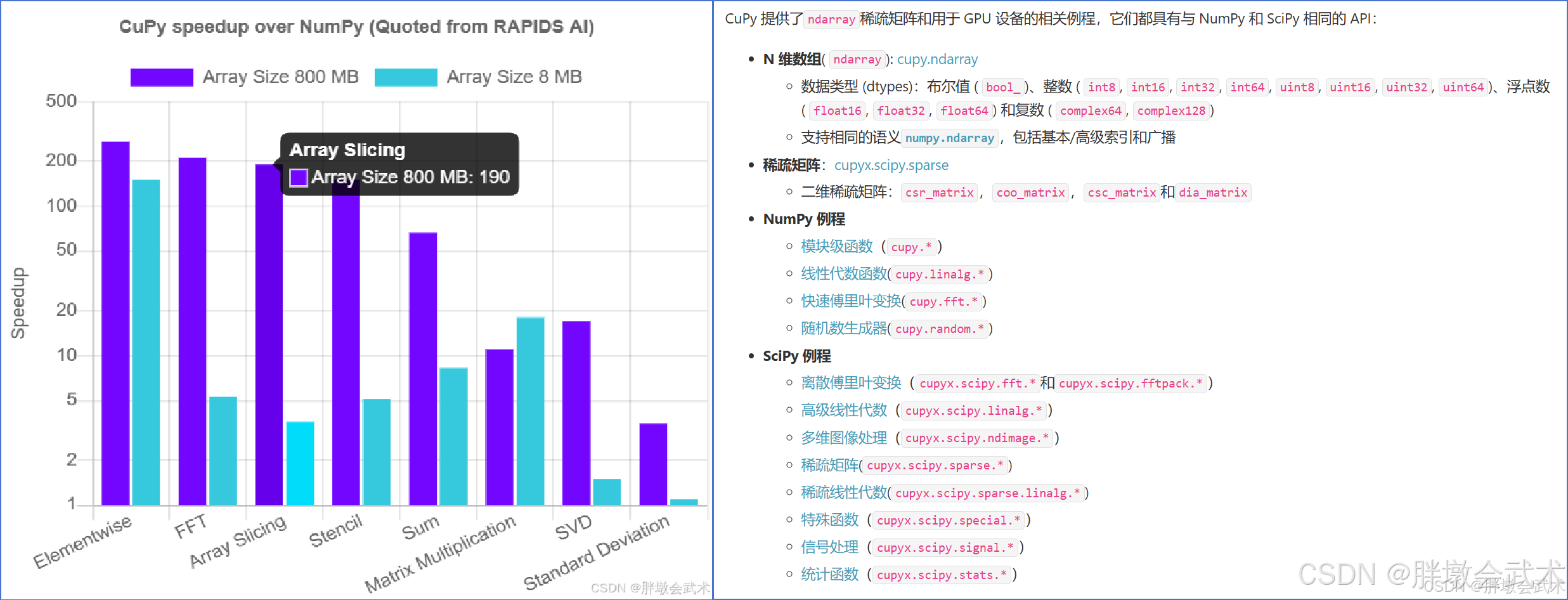
左图中显示了 CuPy 相对于 NumPy 的加速。CuPy 将某些操作的速度提高了 100 倍以上。
二、安装
(不同的 CUDA 版本需要不同的 CuPy 安装包)通过以下命令安装:
pip install cupy-cuda10x—— 用于安装 CUDA 10.x 版本对应的CuPy
pip install cupy-cuda11x—— 用于安装 CUDA 11.x 版本对应的CuPy
pip install cupy-cuda12x—— 用于安装 CUDA 12.x 版本对应的CuPy
三、项目实战
3.1、互相转换(CuPy 与 NumPy )
(1)将一个 CuPy 数组转换为 NumPy 数组,并在 CPU 上继续处理;
(2)将 NumPy 数组转换为 CuPy 数组以便在 GPU 上加速计算。
(1)CuPy 到 NumPy:cp.asnumpy() —— <class ‘numpy.ndarray’>
import cupy as cp
x = cp.array([1, 2, 3])
x_cpu = cp.asnumpy(x) # 转换为 NumPy 数组
print(type(x_cpu)) # 打印 NumPy 数组的类型
"""<class 'numpy.ndarray'>"""
(2)NumPy 到 CuPy:cp.asarray() —— <class ‘cupy.ndarray’>
import cupy as cp
import numpy as np
x_np = np.array([1, 2, 3])
x_gpu = cp.asarray(x_np) # 转换为 CuPy 数组
print(type(x_gpu)) # 打印 NumPy 数组的类型
"""<class 'cupy.ndarray'>"""
3.2、CuPy基础函数
import cupy as cp
x = cp.array([1, 2, 3]) # 在 GPU 上创建一个数组
y = cp.array([4, 5, 6])
z1 = x + y # 计算两个数组的元素级加法
z2 = x[:2] # 获取前两个元素
A = cp.array([[1, 2], [3, 4]])
B = cp.array([[5, 6], [7, 8]])
C = cp.dot(A, B) # 矩阵乘法
cp.linalg.inv(A) # 求矩阵的逆
cp.fft.fft(x) # 傅里叶变换
cp.random.rand(3, 3) # 随机数生成
3.3、CuPy自定义内核(速度更快)
如果想让代码运行得更快,可以轻松制作自定义 CUDA 内核,只需一小段 C++ 代码即可。CuPy 会自动包装并编译它以生成 CUDA 二进制文件。编译后的二进制文件会被缓存并在后续运行中重复使用。
CuPy 提供了几种方法来在 GPU 上定义和运行内核。通过编写 CUDA 内核代码,CuPy 能够直接执行并行计算任务,充分利用 GPU 的计算能力。
- (1)
ElementwiseKernel(向量计算):是一种简化的 API,适用于逐元素操作。
- 用户只需要提供一个简单的 CUDA 内核代码,系统将自动管理网格和线程块。
- (2)
RawKernel(矩阵计算):是一个更加底层的 API,适用于需要自定义并行计算任务(如矩阵乘法、卷积等)。
- 用户需要直接编写 CUDA C++ 内核代码(通常是使用
__global__或__device__修饰符),且需要手动管理网格和线程块。
import cupy as cp
import time
N = 10000
x = cp.random.rand(N).astype(cp.float32)
y = cp.random.rand(N).astype(cp.float32)
kernel = '''
if (x - 2 > y) {
z = x * y;
} else {
z = x + y;
}
'''
kernel = cp.ElementwiseKernel('float32 x, float32 y', 'float32 z', kernel, 'my_kernel')
for i in range(10):
start = time.time()
c = kernel(x, y)
print(f"i = {i}, 时耗: {time.time() - start:.8f}秒")
"""
i = 0, 时耗: 0.00099659秒
i = 1, 时耗: 0.00000000秒
i = 2, 时耗: 0.00000000秒
i = 3, 时耗: 0.00000000秒
i = 4, 时耗: 0.00000000秒
i = 5, 时耗: 0.00000000秒
i = 6, 时耗: 0.00000000秒
i = 7, 时耗: 0.00000000秒
i = 8, 时耗: 0.00000000秒
i = 9, 时耗: 0.00000000秒
"""
3.4、速度测试(矩阵计算)
(1)【NumPy】np.dot(A, B) —— 时耗 5.6 秒
import numpy as np
import time
A = np.random.rand(10000, 10000)
B = np.random.rand(10000, 10000)
for i in range(10):
start = time.time()
C = np.dot(A, B) # 在 CPU 上执行矩阵乘法
print(f"i = {i}, 时耗: {time.time() - start:.8f}秒")
"""
i = 0, 时耗: 5.59134936秒
i = 1, 时耗: 5.66079187秒
i = 2, 时耗: 5.63619781秒
i = 3, 时耗: 5.62660122秒
i = 4, 时耗: 5.64722443秒
i = 5, 时耗: 5.57355118秒
i = 6, 时耗: 5.59616947秒
i = 7, 时耗: 5.63257861秒
i = 8, 时耗: 5.80971384秒
i = 9, 时耗: 5.62141252秒
"""
(2)【CuPy】cp.dot(A, B) —— 时耗 0.058 秒
import cupy as cp
import time
A = cp.random.rand(10000, 10000)
B = cp.random.rand(10000, 10000)
for i in range(10):
start = time.time()
C = cp.dot(A, B) # 在 GPU 上执行矩阵乘法
print(f"i = {i}, 时耗: {time.time() - start:.8f}秒")
"""
i = 0, 时耗: 0.05804682秒
i = 1, 时耗: 0.00100160秒
i = 2, 时耗: 0.00000000秒
i = 3, 时耗: 0.00000000秒
i = 4, 时耗: 0.00000000秒
i = 5, 时耗: 0.00000000秒
i = 6, 时耗: 0.00000000秒
i = 7, 时耗: 0.00000000秒
i = 8, 时耗: 0.00000000秒
i = 9, 时耗: 0.00000000秒
"""
(3)【CuPy】自定义内核 —— 时耗 0.039 秒
######################################################################################################
# extern "C": 修饰符用于告诉编译器函数按照 C 语言的调用约定进行编译,而不是 C++ 的默认调用约定。
# C 语言的调用约定使得生成的符号(函数名)具有 C 风格的符号名称,避免 C++ 编译器引入名字重载和名称修饰。
# __global__: 这是 CUDA 编程中的关键字,用来定义一个 CUDA 内核函数(即 GPU 上执行的代码)。
# 带有 __global__ 的函数将会在 GPU 上执行,并且这些函数必须是从主机(CPU)代码中调用的。
# 它定义了 GPU 的并行线程模型,__global__ 函数可以通过线程块和网格进行并行化执行。
######################################################################################################
import cupy as cp
import time
A = cp.random.rand(10000, 10000)
B = cp.random.rand(10000, 10000)
for i in range(10):
# (1)定义内核:(矩阵乘法)将每个元素的计算作为一个线程
kernel = """
extern "C" __global__ void matmul_kernel(const float* A, const float* B, float* C, int N)
{
int row = blockIdx.y * blockDim.y + threadIdx.y;
int col = blockIdx.x * blockDim.x + threadIdx.x;
if (row < N && col < N)
{
float value = 0.0f;
for (int k = 0; k < N; ++k)
{
value += A[row * N + k] * B[k * N + col];
}
C[row * N + col] = value;
}
}
"""
# (2)编译内核,并创建 RawKernel 对象
matmul_kernel = cp.RawKernel(kernel, 'matmul_kernel')
# (3)运行内核
#########################################################################
# 设置网格和块的大小
N = A.shape[0]
block_size = (32, 32) # 每个 block 中的线程数
grid_size = (N // block_size[0] + 1, N // block_size[1] + 1) # 网格大小
# 创建输出矩阵
C = cp.zeros_like(A)
start = time.time()
matmul_kernel((grid_size), (block_size), (A, B, C, N))
print(f"i = {i}, 时耗: {time.time() - start:.8f}秒")
#########################################################################
"""
i = 0, 时耗: 0.03830218秒
i = 1, 时耗: 0.00000000秒
i = 2, 时耗: 0.00000000秒
i = 3, 时耗: 0.00000000秒
i = 4, 时耗: 0.00000000秒
i = 5, 时耗: 0.00000000秒
i = 6, 时耗: 0.00000000秒
i = 7, 时耗: 0.00000000秒
i = 8, 时耗: 0.00000000秒
i = 9, 时耗: 0.00000000秒
"""


















 224
224

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











