









文章目录
- 博主精品专栏导航
- 第三章、项目实战
- (一)银行卡号识别 —— cv2.morphologyEx()、cv2.getStructuringElement()、cv2.threshold()、cv2.findContours()、cv2.drawContours()、cv2.boundingRect()
- (二)文档扫描与OCR识别 —— cv2.getPerspectiveTransform()、cv2.warpPerspective()
- (三)答题卡识别与判卷 —— cv2.putText()、cv2.countNonZero()
- (四)全景拼接 —— detectAndDescribe()、matchKeypoints()、cv2.findHomography()、cv2.warpPerspective()、drawMatches()
- (五)图像分类(DNN) —— cv2.dnn.blobFromImage()、cv2.dnn.blobFromImages()
- (六)背景减法(实时目标识别) —— cv2.createBackgroundSubtractorMOG2()
- (七)光流估计(实时目标跟踪) —— cv2.goodFeaturesToTrack()、cv2.calcOpticalFlowPyrLK()
- (八)图像分割
- (九)图像增强:灰度反转、对比度拉伸、对比度和亮度增强、指数变换、伽马变换、对数变换
- (十)噪声模拟:均匀噪声、高斯噪声、椒盐噪声、泊松噪声、瑞利噪声、伽马噪声、乘性噪声
- (十一)基于核函数的卷积操作:滤波器、形态学变化、边缘检测算子
- (十二)添加水印
- 第零章、环境配置
- 第一章、图像的基本操作
- 第二章、图像的高级操作
- 2.0、主程序判断:if __ name __ == ' __ main __ '
- 2.1、通道分离 + 通道合并 —— cv2.split() + cv.merge()
- 2.2、边缘填充 —— cv2.copyMakeBorder()
- 2.3、图像融合 —— cv2.add() + cv2.addWeighted()
- 2.4、对比度和亮度调整 —— cv2.convertScaleAbs()
- 2.5、色彩空间转换 —— cv2.cvtColor()
- 2.6、阈值处理
- 2.7、滤波器
- 2.8、腐蚀与膨胀(迭代次数) —— cv2.erode() + cv2.dilate()
- 2.9、形态学变化(腐蚀 + 膨胀 + 开运算 + 闭运算 + 梯度计算 + 顶帽 + 黑帽) —— cv2.morphologyEx()
- 2.10、边缘检测算子 —— cv2.sobel()、cv2.Scharr()、cv2.Laplacian()、cv2.Canny()
- 2.11、图像金字塔
- 2.12、轮廓检测
- (1)提取轮廓 + 绘制轮廓 —— cv2.findContours()、cv2.drawContours()
- (2)轮廓的基本属性(轮廓面积 + 轮廓周长) —— cv2.contourArea()、cv2.arcLength()
- (3)轮廓的外接边界框(多边形近似 + 凸包 + 最小外接矩形 + 最小旋转外接矩形 + 最小外接圆 + 最小外接三角形) —— cv2.approxPolyDP()、cv2.convexHull()、cv2.boundingRect()、cv2.minAreaRect()、cv2.minEnclosingCircle()、cv2.minEnclosingTriangle()
- (4)轮廓的最优拟合(拟合椭圆 + 拟合直线) —— cv2.fitEllipse()、cv2.fitLine()
- (5)轮廓的最大内接圆(自定义实现)
- 2.13、模板匹配 —— cv2.matchTemplate()、cv2.minMaxLoc()
- 2.14、直方图 + 直方图均衡化 + 自适应 —— cv2.calcHist()、cv2.equalizeHist()、cv2.createCLAHE()
- 2.15、傅里叶变换 + 低通滤波 + 高通滤波 —— cv2.dft()、cv2.idft()、np.fft.fftshift()、np.fft.ifftshift()、cv2.magnitud()
- 2.16、Harris角点检测 —— cv2.cornerHarris() + cv2.KeyPoint() + cv2.drawKeypoints()
- 2.17、SIFT尺度不变特征检测 —— cv2.xfeatures2d.SIFT_create()、sift.detectAndCompute()、cv2.drawKeypoints()
- 2.18、暴力特征匹配 —— cv2.BFMatcher_create()、bf.match()、bf_knn.knnMatch()、cv2.drawMatches()
- 2.19、特征点检测器 + 特征点描述符
- 2.20、几何变换
- (0)图像平移 - 上下左右(自定义实现)
- (1)图像缩放 —— cv2.resize()
- (2)图像翻转 —— cv2.flip()
- (3)图像旋转 —— cv2.rotate()
- (4)图像转置 —— cv2.transpose()
- (5)图像重映射 —— cv2.remap():扭曲 + 缩放 / 平移 / 旋转 / 翻转 / 变换
- (6)图像错切 + 图像平移 + 图像旋转 + 仿射变换 + 透视变换 —— np.float32() + cv2.getRotationMatrix2D() + cv2.getAffineTransform() + cv2.getPerspectiveTransform() + cv2.warpAffine() + cv2.warpPerspective()
- (7)投影变换
博主精品专栏导航
第三章、项目实战
(一)银行卡号识别 —— cv2.morphologyEx()、cv2.getStructuringElement()、cv2.threshold()、cv2.findContours()、cv2.drawContours()、cv2.boundingRect()
数据下载:模板图像+银行卡图像
银行卡号识别的详细步骤
- (1)提取模板图像中每个数字(0~9)
- 11、读取模板图像、灰度化、二值化
- 22、轮廓检测、绘制轮廓、轮廓排序
- 33、提取模板图像的所有轮廓(每一个数字)
- (2)提取银行卡的所有轮廓
- 11、读取卡图像、灰度化、顶帽运算、sobel算子、闭运算、二值化、二次膨胀+腐蚀
- 22、轮廓检测、绘制轮廓
- (3)提取银行卡《四个数字一组》轮廓,然后每个轮廓与模板的每一个数字进行匹配,得到最大匹配结果,并在原图上绘制结果
- 11、在所有轮廓中,识别出《四个数字一组》的轮廓(共有四个),并进行阈值化、轮廓检测和轮廓排序
- 22、在《四个数字一组》中,提取每个数字的轮廓以及坐标,并进行模板匹配得到最大匹配结果
- 33、在原图像上,用矩形画出《四个数字一组》,并在原图上显示所有的匹配结果



备注:传统图像处理的硬伤,需要根据实际情况(不同类型的银行卡)调整处理策略。
import numpy as np
import cv2 # opencv读取图像默认为BGR
import matplotlib.pyplot as plt # matplotlib显示图像默认为RGB
def sort_contours(cnt_s, method="left-to-right"):
"""排序轮廓(从左到右或者从上到下)"""
reverse = False
ii_myutils = 0
# 判断排序方式
if method == "right-to-left" or method == "bottom-to-top":
reverse = True
if method == "top-to-bottom" or method == "bottom-to-top":
ii_myutils = 1
# 获取每个轮廓的外接矩形,并按指定方向排序
bounding_boxes = [cv2.boundingRect(cc_myutils) for cc_myutils in cnt_s]
(cnt_s, bounding_boxes) = zip(*sorted(zip(cnt_s, bounding_boxes), key=lambda b: b[1][ii_myutils], reverse=reverse))
return cnt_s, bounding_boxes
def resize(image, width=None, height=None, inter=cv2.INTER_AREA):
"""调整图像尺寸"""
dim_myutils = None
(h_myutils, w_myutils) = image.shape[:2]
# 若没有指定宽度或高度,直接返回原图像
if width is None and height is None:
return image
if width is None:
r_myutils = height / float(h_myutils)
dim_myutils = (int(w_myutils * r_myutils), height)
else:
r_myutils = width / float(w_myutils)
dim_myutils = (width, int(h_myutils * r_myutils))
resized = cv2.resize(image, dim_myutils, interpolation=inter)
return resized
def extract_template(image):
"""(1)提取模板图像中每个数字(0~9)"""
ref_gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) # 灰度化图像
ref_BINARY = cv2.threshold(ref_gray, 10, 255, cv2.THRESH_BINARY_INV)[1] # 二值化图像
refCnts, hierarchy = cv2.findContours(ref_BINARY.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE) # 找到轮廓
####################################################################################################
img_Contours = image.copy()
cv2.drawContours(img_Contours, refCnts, -1, (0, 0, 255), 3) # 绘制轮廓
# 绘制图像
plt.subplot(221), plt.imshow(image, 'gray'), plt.title('(0)ref'), plt.axis('off')
plt.subplot(222), plt.imshow(ref_gray, 'gray'), plt.title('(1)ref_gray'), plt.axis('off')
plt.subplot(223), plt.imshow(ref_BINARY, 'gray'), plt.title('(2)ref_BINARY'), plt.axis('off')
plt.subplot(224), plt.imshow(img_Contours, 'gray'), plt.title('(3)img_Contours'), plt.axis('off')
plt.show()
####################################################################################################
# 排序所有轮廓(从左到右,从上到下)
refCnts = sort_contours(refCnts, method="left-to-right")[0]
# 提取所有轮廓
digits = {} # 保存每个模板的数字
for (index, region) in enumerate(refCnts):
(x, y, width, height) = cv2.boundingRect(region) # 得到轮廓(数字)的外接矩形的左上角的(x, y)坐标、宽度和长度
roi = ref_BINARY[y:y + height, x:x + width] # 获得外接矩形的坐标
roi = cv2.resize(roi, (57, 88)) # 将感兴趣区域的图像(数字)resize相同的大小
digits[index] = roi
return digits
def extract_card(image):
"""(2)提取银行卡的所有轮廓"""
rect_Kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (9, 3))
square_Kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (5, 5))
image_tophat = cv2.morphologyEx(image_gray, cv2.MORPH_TOPHAT, rect_Kernel) # 礼帽运算 ———— 用于突出亮区域
image_gradx = cv2.Sobel(image_tophat, ddepth=cv2.CV_32F, dx=1, dy=0, ksize=-1) # 求x方向上的梯度
image_gradx = np.absolute(image_gradx) # 计算x方向上的梯度
(minVal, maxVal) = (np.min(image_gradx), np.max(image_gradx)) # 计算最大最小边界差值
image_gradx = (255 * ((image_gradx - minVal) / (maxVal - minVal))) # 归一化处理(0~1)
image_gradx = image_gradx.astype("uint8") # 数据类型转换
# 闭运算(先膨胀,再腐蚀)———— 将银行卡分成四个部分,每个部分的四个数字连在一起
image_CLOSE = cv2.morphologyEx(image_gradx, cv2.MORPH_CLOSE, square_Kernel)
image_thresh = cv2.threshold(image_CLOSE, 0, 255, cv2.THRESH_BINARY | cv2.THRESH_OTSU)[1] # 阈值分割
# (二次)闭运算 ———— 将四个连在一起的数字进行填充形成一个整体。
image_2_dilate = cv2.dilate(image_thresh, square_Kernel, iterations=2) # 膨胀(迭代次数2次)
image_1_erode = cv2.erode(image_2_dilate, square_Kernel, iterations=1) # 腐蚀(迭代次数1次)
image_2_CLOSE = image_1_erode
threshCnts, hierarchy = cv2.findContours(image_2_CLOSE.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE) # 轮廓检测
####################################################################################################
image_Contours = image.copy()
cv2.drawContours(image_Contours, threshCnts, -1, (0, 0, 255), 3) # 绘制轮廓
# 绘制图像
plt.subplot(241), plt.imshow(cv2.cvtColor(image, cv2.COLOR_BGR2RGB)), plt.title('(0)image_card'), plt.axis('off')
plt.subplot(242), plt.imshow(cv2.cvtColor(image_gray, cv2.COLOR_BGR2RGB)), plt.title('(1)image_gray'), plt.axis('off')
plt.subplot(243), plt.imshow(cv2.cvtColor(image_tophat, cv2.COLOR_BGR2RGB)), plt.title('(2)image_tophat'), plt.axis('off')
plt.subplot(244), plt.imshow(cv2.cvtColor(image_gradx, cv2.COLOR_BGR2RGB)), plt.title('(3)image_gradx'), plt.axis('off')
plt.subplot(245), plt.imshow(cv2.cvtColor(image_CLOSE, cv2.COLOR_BGR2RGB)), plt.title('(4)image_CLOSE'), plt.axis('off')
plt.subplot(246), plt.imshow(cv2.cvtColor(image_thresh, cv2.COLOR_BGR2RGB)), plt.title('(5)image_thresh'), plt.axis('off')
plt.subplot(247), plt.imshow(cv2.cvtColor(image_2_CLOSE, cv2.COLOR_BGR2RGB)), plt.title('(6)image_2_CLOSE'), plt.axis('off')
plt.subplot(248), plt.imshow(cv2.cvtColor(image_Contours, cv2.COLOR_BGR2RGB)), plt.title('(7)image_Contours'), plt.axis('off')
plt.show()
####################################################################################################
return threshCnts
def extract_digits(image_gray, threshCnts, digits):
"""3311、识别出四个数字一组的所有轮廓(理论上是四个)"""
locs = [] # 保存四个数字一组的轮廓坐标
for (index, region) in enumerate(threshCnts): # 遍历轮廓
(x, y, wight, height) = cv2.boundingRect(region) # 计算矩形
ar = wight / float(height) # (四个数字一组)的长宽比
# 匹配(四个数字为一组)轮廓的大小 ———— 根据实际图像调整
if 2.0 < ar < 4.0:
if (35 < wight < 60) and (10 < height < 20):
locs.append((x, y, wight, height))
locs = sorted(locs, key=lambda x: x[0]) # 排序(从左到右)
"""3322、在四个数字一组中,提取每个数字的轮廓坐标并进行模板匹配"""
output_all_group = [] # 保存(所有组)匹配结果
for (ii, (gX, gY, gW, gH)) in enumerate(locs):
"""遍历银行卡的每个组(理论上是四组)"""
image_group = image_gray[gY - 5:gY + gH + 5, gX - 5:gX + gW + 5] # 坐标索引每个组图像,并将每个轮廓的结果放大一些,避免信息丢失
image_group_threshold = cv2.threshold(image_group, 0, 255, cv2.THRESH_BINARY | cv2.THRESH_OTSU)[1] # 二值化处理
digitCnts, hierarchy = cv2.findContours(image_group_threshold, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE) # 获取轮廓
digitCnts_sort = sort_contours(digitCnts, method="left-to-right")[0] # 排序
"""遍历每个组中的每个数字(理论上每个组是四个数字)"""
output_group = [] # 保存(每个组)匹配结果
for jj in digitCnts_sort:
(x, y, wight, height) = cv2.boundingRect(jj) # 获取数字的轮廓
image_digit = image_group[y:y + height, x:x + wight] # 获取数字的坐标
image_digit = cv2.resize(image_digit, (57, 88)) # 图像缩放(保持与模板图像中的数字图像一致)
cv2.imshow("Image", image_digit)
cv2.waitKey(200) # 延迟200ms
"""遍历模板图像的每个数字,并计算(轮廓数字)和(模板数字)匹配分数(理论上模板的十个数字))"""
scores = [] # 计算匹配分数:(轮廓中的数字)和(模板中的数字)
for (kk, digitROI) in digits.items():
result = cv2.matchTemplate(image_digit, digitROI, cv2.TM_CCOEFF)
(_, max_score, _, _) = cv2.minMaxLoc(result) # max_score表示最大值
scores.append(max_score)
output_group.append(str(np.argmax(scores))) # 将最大匹配分数对应的数字保存下来
# 在绘制矩形 ———— 在原图上,用矩形将" 四个数字一组 "画出来(理论上共有四个矩形,对应四个组)
cv2.rectangle(image_resize, (gX - 5, gY - 5), (gX + gW + 5, gY + gH + 5), (0, 0, 255), 1)
cv2.putText(image_resize, "".join(output_group), (gX, gY - 15), cv2.FONT_HERSHEY_SIMPLEX, 0.65, (0, 0, 255), 2)
output_all_group.extend(output_group)
return "".join(output_all_group)
if __name__ == "__main__":
"""11、提取模板图像中每个数字模板(0~9)"""
image_template = cv2.imread(r'ocr_a_reference.png')
digits = extract_template(image_template)
"""22、提取信用卡的所有轮廓"""
image_card = cv2.imread(r'credit_card_01.png')
image_resize = resize(image_card, width=300)
image_gray = cv2.cvtColor(image_resize, cv2.COLOR_BGR2GRAY)
threshCnts = extract_card(image_resize)
"""33、提取银行卡" 四个数字一组 "轮廓,然后每个轮廓与模板的每一个数字进行匹配,得到最大匹配结果,并在原图上绘制结果"""
result = extract_digits(image_gray, threshCnts, digits)
print(f"识别结果: {result}")
cv2.imshow("Image", image_resize)
cv2.waitKey(0)
# -*- coding: utf-8 -*-
# 作者: 胖墩会武术
# 日期: 1994-08-21
# OpenCV图像处理: https://blog.csdn.net/shinuone/article/details/126022763
深究 Pycharm shadows name ‘xxxx’ from outer scope 警告
(二)文档扫描与OCR识别 —— cv2.getPerspectiveTransform()、cv2.warpPerspective()
在进行 OCR 之前,通常会进行一些图像预处理,如去噪、二值化等,来提高识别准确性。

import numpy as np
import cv2 # opencv 读取图像默认为BGR
import matplotlib.pyplot as plt # matplotlib显示图像默认为RGB
def order_points(pts):
"""对输入的四个点进行排序,返回左上、右上、右下、左下的顺序"""
rect = np.zeros((4, 2), dtype="float32")
# 按顺序找到对应坐标:左上、右上、右下、左下
s = pts.sum(axis=1)
rect[0] = pts[np.argmin(s)] # 左上
rect[2] = pts[np.argmax(s)] # 右下
diff = np.diff(pts, axis=1)
rect[1] = pts[np.argmin(diff)] # 右上
rect[3] = pts[np.argmax(diff)] # 左下
return rect
def four_point_transform(image, pts):
"""执行四点透视变换,得到矩形的透视图"""
rect = order_points(pts)
(tl, tr, br, bl) = rect
# 计算最大宽度和高度
widthA = np.sqrt(((br[0] - bl[0]) ** 2) + ((br[1] - bl[1]) ** 2))
widthB = np.sqrt(((tr[0] - tl[0]) ** 2) + ((tr[1] - tl[1]) ** 2))
maxWidth = max(int(widthA), int(widthB))
heightA = np.sqrt(((tr[0] - br[0]) ** 2) + ((tr[1] - br[1]) ** 2))
heightB = np.sqrt(((tl[0] - bl[0]) ** 2) + ((tl[1] - bl[1]) ** 2))
maxHeight = max(int(heightA), int(heightB))
# 变换后的目标坐标
dst = np.array([[0, 0], [maxWidth - 1, 0], [maxWidth - 1, maxHeight - 1], [0, maxHeight - 1]], dtype="float32")
# 计算齐次变换矩阵
M = cv2.getPerspectiveTransform(rect, dst)
# 执行透视变换
warped = cv2.warpPerspective(image, M, (maxWidth, maxHeight))
return warped
def generate_sample_image():
"""创建一个简单的图像模拟收据或文档"""
image = np.ones((600, 500, 3), dtype=np.uint8) * 255 # 创建一个白色背景的图像
pts = np.array([[50, 100], [450, 100], [400, 500], [100, 500]], np.int32) # 定义一个多边形
pts = pts.reshape((-1, 1, 2))
# 填充多边形的内部为红色
cv2.fillPoly(image, [pts], (0, 0, 255))
# 添加一些斜体文本,确保它们位于多边形内部
font = cv2.FONT_HERSHEY_SIMPLEX # 使用普通字体
cv2.putText(image, 'Sample Receipt', (150, 200), font, 1, (255, 255, 255), 2, cv2.LINE_AA) # 白色文本
cv2.putText(image, 'Total: $123.45', (180, 450), font, 1, (255, 255, 255), 2, cv2.LINE_AA) # 白色文本
return image
if __name__ == '__main__':
# input_image = generate_sample_image() # 生成图像
input_image = cv2.imread(r'receipt2.jpg') # 读取图像
cv2.imshow("image", input_image)
cv2.waitKey(0)
cv2.destroyAllWindows()
ratio = input_image.shape[0] / 500.0 # 记录图像的缩放比例
original_image = input_image.copy()
input_image = cv2.resize(original_image, (int(original_image.shape[1] * 500.0 / original_image.shape[0]), 500))
# 图像预处理:灰度化 + 高斯模糊 + 边缘检测
gray_image = cv2.cvtColor(input_image, cv2.COLOR_BGR2GRAY)
gray_image = cv2.GaussianBlur(gray_image, (5, 5), 0)
edge_detected_image = cv2.Canny(gray_image, 75, 200)
# 轮廓检测
contours, _ = cv2.findContours(edge_detected_image.copy(), cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE)
contours = sorted(contours, key=cv2.contourArea, reverse=True)[:5]
# 提取具有四个角的轮廓
for contour in contours:
perimeter = cv2.arcLength(contour, True)
approx_contour = cv2.approxPolyDP(contour, 0.02 * perimeter, True)
if len(approx_contour) == 4:
contour_approx = approx_contour
break
# 在原图上画出检测得到的轮廓
cv2.drawContours(input_image, [contour_approx], -1, (0, 255, 0), 2)
# 透视变换:从原图中提取文档区域
perspective_transformed_image = four_point_transform(original_image, contour_approx.reshape(4, 2) * ratio)
perspective_transformed_image = cv2.cvtColor(perspective_transformed_image, cv2.COLOR_BGR2GRAY)
scanned_document = cv2.threshold(perspective_transformed_image, 100, 255, cv2.THRESH_BINARY)[1]
scanned_document = cv2.resize(scanned_document, (int(scanned_document.shape[1] * 500.0 / scanned_document.shape[0]), 500))
# 使用Matplotlib显示图像
original_rgb = cv2.cvtColor(original_image, cv2.COLOR_BGR2RGB)
edge_detected_rgb = cv2.cvtColor(edge_detected_image, cv2.COLOR_BGR2RGB)
input_rgb = cv2.cvtColor(input_image, cv2.COLOR_BGR2RGB)
scanned_rgb = cv2.cvtColor(scanned_document, cv2.COLOR_BGR2RGB)
plt.subplot(1, 4, 1), plt.imshow(original_rgb), plt.title('Original'), plt.gca().get_xaxis().set_visible(False), plt.gca().get_yaxis().set_visible(False)
plt.subplot(1, 4, 2), plt.imshow(edge_detected_rgb), plt.title('Edged'), plt.gca().get_xaxis().set_visible(False), plt.gca().get_yaxis().set_visible(False)
plt.subplot(1, 4, 3), plt.imshow(input_rgb), plt.title('Contour'), plt.gca().get_xaxis().set_visible(False), plt.gca().get_yaxis().set_visible(False)
plt.subplot(1, 4, 4), plt.imshow(scanned_rgb), plt.title('Scanned'), plt.gca().get_xaxis().set_visible(False), plt.gca().get_yaxis().set_visible(False)
plt.show()
# -*- coding: utf-8 -*-
# 作者: 胖墩会武术
# 日期: 1994-08-21
# OpenCV图像处理: https://blog.csdn.net/shinuone/article/details/126022763

要实现文档扫描并进行 OCR(光学字符识别),需要安装Tesseract,Tesseract 是一个非常流行的开源 OCR 引擎,用于提取图像中的文本。共需要安装以下两个组件:
- (1)Tesseract 引擎:这是 OCR 引擎本身。你需要在操作系统中安装它。官网安装教程:tesseract-ocr/tesseract
- (2)Pytesseract:这是 Tesseract 的 Python 包装器,用于与 Tesseract 引擎交互。
pip install pytesseract
以下是一个简单的 OCR 示例,展示如何用 pytesseract 对图像进行 OCR 识别:
import cv2
import pytesseract
# 设置 tesseract 可执行文件的路径(如果已安装并且路径不在环境变量中)
# 对于 Windows 用户,可能需要设置 tesseract.exe 的完整路径
# pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe'
image = cv2.imread('path_to_your_image.jpg')
gray_image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) # 将图像转为灰度图,增加 OCR 识别的准确性
text = pytesseract.image_to_string(gray_image) # 使用 OCR 进行识别
print(f"识别的文本内容:{text}")
(三)答题卡识别与判卷 —— cv2.putText()、cv2.countNonZero()

import numpy as np
import cv2 # opencv读取图像默认为BGR
import matplotlib.pyplot as plt # matplotlib显示图像默认为RGB
def order_points(pts):
# 一共4个坐标点
rect = np.zeros((4, 2), dtype="float32")
# 按顺序找到对应坐标0123分别是 左上,右上,右下,左下
# 计算左上,右下
s = pts.sum(axis=1)
rect[0] = pts[np.argmin(s)]
rect[2] = pts[np.argmax(s)]
# 计算右上和左下
diff = np.diff(pts, axis=1)
rect[1] = pts[np.argmin(diff)]
rect[3] = pts[np.argmax(diff)]
return rect
def four_point_transform(image, pts):
# 获取输入坐标点
rect = order_points(pts)
(tl, tr, br, bl) = rect
# 计算输入的w和h值
widthA = np.sqrt(((br[0] - bl[0]) ** 2) + ((br[1] - bl[1]) ** 2))
widthB = np.sqrt(((tr[0] - tl[0]) ** 2) + ((tr[1] - tl[1]) ** 2))
maxWidth = max(int(widthA), int(widthB))
heightA = np.sqrt(((tr[0] - br[0]) ** 2) + ((tr[1] - br[1]) ** 2))
heightB = np.sqrt(((tl[0] - bl[0]) ** 2) + ((tl[1] - bl[1]) ** 2))
maxHeight = max(int(heightA), int(heightB))
# 变换后对应坐标位置
dst = np.array([[0, 0], [maxWidth - 1, 0], [maxWidth - 1, maxHeight - 1], [0, maxHeight - 1]], dtype="float32")
# 计算变换矩阵
M = cv2.getPerspectiveTransform(rect, dst) # 计算齐次变换矩阵:cv2.getPerspectiveTransform(rect, dst)
warped = cv2.warpPerspective(image, M, (maxWidth, maxHeight)) # 透视变换:(将输入矩形乘以(齐次变换矩阵),得到输出矩阵)
return warped
def sort_contours(cnts, method="left-to-right"):
reverse = False
i = 0
if method == "right-to-left" or method == "bottom-to-top":
reverse = True
if method == "top-to-bottom" or method == "bottom-to-top":
i = 1
boundingBoxes = [cv2.boundingRect(c) for c in cnts]
(cnts, boundingBoxes) = zip(*sorted(zip(cnts, boundingBoxes), key=lambda b: b[1][i], reverse=reverse))
return cnts, boundingBoxes
# 需给定每张图像对应选项的正确答案(字典:键对应行,值对应每行的答案)
ANSWER_KEY = {0: 1, 1: 4, 2: 0, 3: 3, 4: 1}
# 图像预处理
image = cv2.imread(r"images/test_01.png")
contours_img = image.copy()
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) # 转换为灰度图
blurred = cv2.GaussianBlur(gray, (5, 5), 0) # 高斯滤波-去除噪音
edged = cv2.Canny(blurred, 75, 200) # Canny算子边缘检测
cnts, hierarchy = cv2.findContours(edged.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE) # 轮廓检测
cv2.drawContours(contours_img, cnts, -1, (0, 0, 255), 3) # 画出轮廓(答题卡)
###################################################################
# 提取答题卡并进行透视变化
docCnt = None
if len(cnts) > 0:
cnts = sorted(cnts, key=cv2.contourArea, reverse=True) # 根据轮廓大小进行排序
for c in cnts: # 遍历每一个轮廓
peri = cv2.arcLength(c, True) # 计算轮廓的长度
approx = cv2.approxPolyDP(c, 0.02*peri, True) # 找出轮廓的多边形拟合曲线
if len(approx) == 4: # 找到的轮廓是四边形(对应四个顶点)
docCnt = approx
break
warped = four_point_transform(gray, docCnt.reshape(4, 2)) # 透视变换(齐次变换矩阵)
warped1 = warped.copy()
thresh = cv2.threshold(warped, 0, 255, cv2.THRESH_BINARY_INV | cv2.THRESH_OTSU)[1] # 0:表示系统自动判断;THRESH_OTSU:自适应阈值设置
###############################
thresh_Contours = thresh.copy()
cnts, hierarchy = cv2.findContours(thresh.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE) # 找到每一个圆圈轮廓
cv2.drawContours(thresh_Contours, cnts, -1, (0, 0, 255), 3) # 画出所有轮廓
###################################################################
# 提取答题卡中所有的有效选项(圆圈)
questionCnts = [] # 提取每个选项的轮廓
for c in cnts:
(x, y, w, h) = cv2.boundingRect(c) # 获取轮廓的尺寸
ar = w / float(h) # 计算比例
if w >= 20 and h >= 20 and 0.9 <= ar <= 1.1: # 自定义设置大小(根据实际情况)
questionCnts.append(c)
questionCnts = sort_contours(questionCnts, method="top-to-bottom")[0] # 按照从上到下对所有的选项进行排序
###############################
correct = 0
for (q, i) in enumerate(np.arange(0, len(questionCnts), 5)): # 每排有5个选项
cnts = sort_contours(questionCnts[i:i + 5])[0] # 对每一排进行排序
bubbled = None
for (j, c) in enumerate(cnts): # 遍历每一排对应的五个结果
mask = np.zeros(thresh.shape, dtype="uint8") # 使用mask来判断结果(全黑:0)表示涂写答案正确
cv2.drawContours(mask, [c], -1, 255, -1) # -1表示填充
# cv_show('mask', mask) # 展示每个选项
mask = cv2.bitwise_and(thresh, thresh, mask=mask) # mask=mask表示要提取的区域(可选参数)
total = cv2.countNonZero(mask) # 通过计算非零点数量来算是否选择这个答案
if bubbled is None or total > bubbled[0]: # 记录最大数
bubbled = (total, j)
color = (0, 0, 255) # 对比正确答案
k = ANSWER_KEY[q]
# 判断正确
if k == bubbled[1]:
color = (0, 255, 0)
correct += 1
cv2.drawContours(warped, [cnts[k]], -1, color, 3) # 画出轮廓
###################################################################
# 展示结果
score = (correct / 5.0) * 100 # 计算总得分
print("[INFO] score: {:.2f}%".format(score))
cv2.putText(warped, "{:.1f}%".format(score), (10, 30), cv2.FONT_HERSHEY_SIMPLEX, 0.9, (0, 0, 255), 2)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) # opencv读取的格式是BGR,Matplotlib是RGB
contours_img = cv2.cvtColor(contours_img, cv2.COLOR_BGR2RGB)
plt.subplot(241), plt.imshow(image, cmap='gray'), plt.axis('off'), plt.title('image')
plt.subplot(242), plt.imshow(blurred, cmap='gray'), plt.axis('off'), plt.title('cv2.GaussianBlur')
plt.subplot(243), plt.imshow(edged, cmap='gray'), plt.axis('off'), plt.title('cv2.Canny')
plt.subplot(244), plt.imshow(contours_img, cmap='gray'), plt.axis('off'), plt.title('cv2.findContours')
plt.subplot(245), plt.imshow(warped1, cmap='gray'), plt.axis('off'), plt.title('cv2.warpPerspective')
plt.subplot(246), plt.imshow(thresh_Contours, cmap='gray'), plt.axis('off'), plt.title('cv2.findContours')
plt.subplot(247), plt.imshow(warped, cmap='gray'), plt.axis('off'), plt.title('cv2.warpPerspective')
plt.show()
# -*- coding: utf-8 -*-
# 作者: 胖墩会武术
# 日期: 1994-08-21
# OpenCV图像处理: https://blog.csdn.net/shinuone/article/details/126022763
(四)全景拼接 —— detectAndDescribe()、matchKeypoints()、cv2.findHomography()、cv2.warpPerspective()、drawMatches()
将多张具有重叠区域的图像拼接为一张无缝的全景图

import cv2
import numpy as np
class Stitcher:
def __init__(self, feature_detector='SIFT'):
# 支持不同的特征检测器
if feature_detector == 'ORB':
self.descriptor = cv2.ORB_create()
self.matcher_type = cv2.NORM_HAMMING # ORB 的匹配类型为 NORM_HAMMING
elif feature_detector == 'AKAZE':
self.descriptor = cv2.AKAZE_create()
self.matcher_type = cv2.NORM_HAMMING
else:
self.descriptor = cv2.xfeatures2d.SIFT_create()
self.matcher_type = cv2.NORM_L2 # SIFT 的匹配类型为 NORM_L2
def stitch(self, images, ratio=0.75, reprojThresh=4.0, showMatches=False):
(imageB, imageA) = images
(kpsA, featuresA) = self.detectAndDescribe(imageA)
(kpsB, featuresB) = self.detectAndDescribe(imageB)
# 检查特征描述符是否有效
if featuresA is None or featuresB is None:
print("特征点描述符无效,无法继续拼接。")
return None
M = self.matchKeypoints(kpsA, kpsB, featuresA, featuresB, ratio, reprojThresh)
if M is None:
return None
(matches, H, status) = M
image_perspective = cv2.warpPerspective(imageA, H, (imageA.shape[1] + imageB.shape[1], imageA.shape[0]))
image_comparison = image_perspective.copy()
image_comparison[0:imageB.shape[0], 0:imageB.shape[1]] = imageB
if showMatches:
image_matches = self.drawMatches(imageA, imageB, kpsA, kpsB, matches, status)
return (image_matches, image_perspective, image_comparison)
return image_perspective
def detectAndDescribe(self, image):
# gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) # 将彩色图片转换成灰度图
descriptor = cv2.xfeatures2d.SIFT_create() # 建立SIFT生成器
"""############################################################################
# 若OpenCV3.X,则用cv2.xfeatures2d.SIFT_create方法来实现DoG关键点检测和SIFT特征提取。
# 若OpenCV2.4,则用cv2.FeatureDetector_create方法来实现关键点的检测(DoG)。
############################################################################"""
(kps, features) = descriptor.detectAndCompute(image, None) # 检测SIFT特征点,并计算描述子
kps = np.float32([kp.pt for kp in kps]) # 将结果转换成NumPy数组
return (kps, features) # 返回特征点集,及对应的描述特征
def matchKeypoints(self, kpsA, kpsB, featuresA, featuresB, ratio, reprojThresh):
matcher = cv2.BFMatcher()
rawMatches = matcher.knnMatch(featuresA, featuresB, 2)
matches = []
for m in rawMatches:
if len(m) == 2 and m[0].distance < m[1].distance * ratio:
matches.append((m[0].trainIdx, m[0].queryIdx))
if len(matches) > 4:
ptsA = np.float32([kpsA[i] for (_, i) in matches])
ptsB = np.float32([kpsB[i] for (i, _) in matches])
(H, status) = cv2.findHomography(ptsA, ptsB, cv2.RANSAC, reprojThresh)
return (matches, H, status)
return None
def drawMatches(self, imageA, imageB, kpsA, kpsB, matches, status):
(hA, wA) = imageA.shape[:2]
(hB, wB) = imageB.shape[:2]
vis = np.zeros((max(hA, hB), wA + wB, 3), dtype="uint8")
vis[0:hA, 0:wA] = imageA
vis[0:hB, wA:] = imageB
for ((trainIdx, queryIdx), s) in zip(matches, status):
if s == 1:
ptA = (int(kpsA[queryIdx][0]), int(kpsA[queryIdx][1]))
ptB = (int(kpsB[trainIdx][0]) + wA, int(kpsB[trainIdx][1]))
cv2.line(vis, ptA, ptB, (0, 255, 0), 1)
return vis
if __name__ == '__main__':
imageA = cv2.imread('../image/scene_left.jpg')
imageB = cv2.imread('../image/scene_right.jpg')
stitcher = Stitcher(feature_detector='ORB') # 使用ORB特征
(image_matches, image_perspective, image_comparison) = stitcher.stitch([imageA, imageB], showMatches=True)
if image_comparison is not None:
cv2.imshow("image_left", imageA)
cv2.imshow("image_right", imageB)
cv2.imshow("image_matches", image_matches)
cv2.imshow("image_perspective", image_perspective)
cv2.imshow("image_comparison", image_comparison)
cv2.waitKey(0)
cv2.destroyAllWindows()
else:
print("拼接失败。")
# -*- coding: utf-8 -*-
# 作者: 胖墩会武术
# 日期: 1994-08-21
# OpenCV图像处理: https://blog.csdn.net/shinuone/article/details/126022763
(五)图像分类(DNN) —— cv2.dnn.blobFromImage()、cv2.dnn.blobFromImages()

import utils_paths
import numpy as np
import cv2
##################################################################
# 提取标签文件中每一行的内容
# (1)训练模型标签文件:"synset_words.txt"
# (2)使用open().read() :打开并读取txt文件中所有的字符串
# (3)strip() :删除字符串两端的空格
# (4)split('\n') :提取每一行的内容
rows = open("synset_words.txt").read().strip().split("\n")
##################################################################
# 提取出每行第一个空格后的字符串
# (1)对每一行的内容进行遍历,遍历之后找每一行的空格(r.find(' '))。
# (2)找到位置后让位置+1,然后r提取到+1的位置一直到最后
# (3)以所有逗号为分隔符然后删除他们,取分割的第一个值
classes = [r[r.find(" ") + 1:].split(",")[0] for r in rows]
##################################################################
# 加载Caffe所需文件
# (1)配置文件:"bvlc_googlenet.prototxt"
# (2)训练好的权重参数:"bvlc_googlenet.caffemodel"
net = cv2.dnn.readNetFromCaffe("bvlc_googlenet.prototxt", "bvlc_googlenet.caffemodel")
##################################################################
# 读取图像路径
# (1)utils_paths.py中的list_images()是提取images文件夹中所有图片的绝对路径,
# (2)将所有绝对路径作为元素组成迭代器
# (3)使用sorted()进行排序。 这个是字符串之间的排序:先比首字母,再比第二个字母,都相同时比长度。
imagePaths = sorted(list(utils_paths.list_images("images/")))
##################################################################
# (单个)图像预测
image = cv2.imread(imagePaths[0]) # 先读取第0张图片
resized = cv2.resize(image, (224, 224)) # 保持训练模型与测试模型数据大小相同
blob = cv2.dnn.blobFromImage(resized, 1, (224, 224), (104, 117, 123))
print("First Blob: {}".format(blob.shape))
net.setInput(blob) # 输入数据
preds = net.forward() # 前向传播得到结果(向量形式)
# 排序,取分类可能性最大的 ———— 该Imagenet是一个千分类模型,它会有1000个值对应1000个分类的概率
# np.argsort()是从小到大排序,故逆序[::-1],然后取第一个值(最大值的索引)
idx = np.argsort(preds[0])[::-1][0]
# 获取要写的内容:(1)该索引对应的标签值(2)pred[0]的值,乘以100,然后保留其两位小数,最后在后面加个百分号
text = "Label: {}, {:.2f}%".format(classes[idx], preds[0][idx] * 100)
# 将要写的内容写在未经处理的图片上
cv2.putText(image, text, (5, 25), cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 0, 255), 2)
# 显示预测结果
cv2.imshow("Image", image)
cv2.waitKey(0)
##################################################################
##################################################################
# 预测(其余的所有图) ———— 方法与上述一样,但数据是一个batch。
images = [] # 定义一个空列表存图
# 处理除第0张外的所有图片
for p in imagePaths[1:]:
image = cv2.imread(p)
image = cv2.resize(image, (224, 224))
images.append(image)
blob = cv2.dnn.blobFromImages(images, 1, (224, 224), (104, 117, 123))
print("Second Blob: {}".format(blob.shape))
net.setInput(blob) # 输入数据
preds = net.forward() # 前向传播得到结果(向量形式)
# 首先读进来图,之后找到对应预测结果中最大的,然后写上标签与概率
for (i, p) in enumerate(imagePaths[1:]): # i是序号,p是图片路径
image = cv2.imread(p)
idx = np.argsort(preds[i])[::-1][0]
text = "Label: {}, {:.2f}%".format(classes[idx], preds[i][idx] * 100)
cv2.putText(image, text, (5, 25), cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 0, 255), 2)
cv2.imshow("Image", image)
cv2.waitKey(0)
"""#####################################################################################################################
# 函数功能:将单张图像转换为 blob 格式。
# 函数说明:cv2.dnn.blobFromImage(image, scalefactor=1.0, size=(0, 0), mean=(0, 0, 0), swapRB=True, crop=False)
# 参数说明:
# image:输入的图像,可以是 numpy 数组,通常是 cv2.imread() 加载的图像。
# scalefactor:缩放因子,图像像素值会乘以该因子(默认值为 1.0)。通常用于归一化,比如设置为 1/255 将像素值归一化到 [0, 1]。
# size:输出图像的尺寸(宽,高),例如 (224, 224)。指定后图像会被调整到这个大小。
# mean:均值,用于均值减法,通常是一个包含 BGR 三个通道均值的元组(如 (104, 117, 123))。
# swapRB:是否交换 R 和 B 通道,默认值为 True,适用于从 BGR 转换为 RGB。
# crop:是否裁剪图像。如果为 True,则会在缩放后裁剪以匹配目标大小。
# 返回参数:
# 返回一个四维张量(NCHW 格式),即 [1, C, H, W],其中:
# 1 是批量大小。
# C 是通道数(通常为 3,即 RGB)。
# H 和 W 是图像的高度和宽度。
#####################################################################################################################"""
"""#####################################################################################################################
# 函数功能:将多张图像同时转换为 blob 格式。
# 函数说明:cv2.dnn.blobFromImages(images, scalefactor=1.0, size=(0, 0), mean=(0, 0, 0), swapRB=True, crop=False)
# 参数说明:
# images:包含多张图像的列表或数组(如 [img1, img2, ...])。
# scalefactor:缩放因子,图像像素值会乘以该因子(默认值为 1.0)。通常用于归一化,比如设置为 1/255 将像素值归一化到 [0, 1]。
# size:输出图像的尺寸(宽,高),例如 (224, 224)。指定后图像会被调整到这个大小。
# mean:均值,用于均值减法,通常是一个包含 BGR 三个通道均值的元组(如 (104, 117, 123))。
# swapRB:是否交换 R 和 B 通道,默认值为 True,适用于从 BGR 转换为 RGB。
# crop:是否裁剪图像。如果为 True,则会在缩放后裁剪以匹配目标大小。
# 返回参数:
# 返回一个四维张量 [N, C, H, W],其中:
# N 是图像数量。
# C 是通道数。
# H 和 W 是图像的高度和宽度。
#####################################################################################################################"""
# -*- coding: utf-8 -*-
# 作者: 胖墩会武术
# 日期: 1994-08-21
# OpenCV图像处理: https://blog.csdn.net/shinuone/article/details/126022763
(六)背景减法(实时目标识别) —— cv2.createBackgroundSubtractorMOG2()


OpenCV提供了演示数据:https://github.com/opencv/opencv/tree/master/samples/data
"""##########################################################################
背景建模是实时目标识别中一个非常关键的技术,它通过创建并不断更新背景模型来从视频流中提取出动态变化的物体(即前景目标)。
(1)通过背景建模(使用高斯混合模型cv2.createBackgroundSubtractorMOG2)来提取视频中的前景目标
(2)形态学操作去除噪声
(3)轮廓检测识别动态物体
常用于监控、视频分析等领域,用于检测视频中的运动物体。
##########################################################################"""
import cv2
# 视频文件路径
video_path = r"D:\opencv-master\opencv-master\samples\data\vtest.avi"
cap = cv2.VideoCapture(video_path) # 初始化视频捕捉对象
# 检查视频是否成功打开
if not cap.isOpened():
print(f"Error: Unable to open video file at {video_path}")
exit()
# 创建背景减除器 (MOG2) 用于提取前景
fgbg = cv2.createBackgroundSubtractorMOG2(history=500, varThreshold=16, detectShadows=True)
# 定义形态学操作结构元素
kernel = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (3, 3))
# 主循环,逐帧处理视频
while True:
ret, frame = cap.read() # 读取视频帧
if not ret:
print("Failed to grab frame or video ended.")
break
# 获取前景掩码(背景0,前景1)
fgmask = fgbg.apply(frame)
# 形态学开运算,去除噪声
fgmask = cv2.morphologyEx(fgmask, cv2.MORPH_OPEN, kernel)
# 查找前景中的轮廓
contours, _ = cv2.findContours(fgmask, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
# 遍历轮廓并绘制矩形框
for contour in contours:
perimeter = cv2.arcLength(contour, True) # 计算轮廓的周长
if perimeter > 188: # 根据轮廓周长过滤掉小物体
x, y, w, h = cv2.boundingRect(contour) # 获取外接矩形
cv2.rectangle(frame, (x, y), (x + w, y + h), (0, 255, 0), 2) # 绘制矩形框
# 显示当前帧和前景掩码
cv2.imshow('Frame', frame) # 当前帧图像
cv2.imshow('Foreground Mask', fgmask) # 当前运动目标的前景掩码
# 按 'Esc' 键退出
if cv2.waitKey(10) & 0xFF == 27:
break
# 释放资源并关闭所有窗口
cap.release()
cv2.destroyAllWindows()
"""#############################################################################################
# 函数功能:创建一个背景建模器,用于从视频流中分离前景与背景。
# 函数说明:cv2.createBackgroundSubtractorMOG2(history=500, varThreshold=16, detectShadows=True)
# 参数说明:
# history:用于计算背景模型的历史帧数。默认为500帧,表示背景模型根据过去500帧数据进行更新。较大的值可以提高背景建模的稳定性,但会增加计算开销。
# varThreshold:用于背景建模时阈值的标准差,用于区分前景和背景。通常情况下,前景和背景之间的差异小于该阈值,且前景像素的标准差大于此阈值时会被识别为前景。默认值为16。
# detectShadows:布尔值,是否检测阴影。默认为 True,启用阴影检测。如果启用,前景对象的阴影会被识别为另一种类型的前景像素并进行处理。
# 返回值:
# 返回一个 `cv2.BackgroundSubtractorMOG2` 对象,用于对每一帧进行前景提取。
# 功能描述:
# - `cv2.createBackgroundSubtractorMOG2()` 创建一个高斯混合模型(Gaussian Mixture Model, GMM)背景减除器,常用于从视频流中提取前景物体。
# - 背景建模算法会根据时间推移不断学习视频中的背景,实时更新背景模型,并将不同于背景的部分(如运动物体)标记为前景。
# - 可以通过 `apply()` 方法应用到每一帧图像上,获取前景图像。
# - 该方法适用于光照变化较小、背景相对稳定的场景,特别用于运动检测、行人跟踪等应用。
# 常用方法:
# - `apply(frame, learningRate=None)`:对每一帧图像进行前景检测。返回一个二值图像,前景像素为白色(255),背景像素为黑色(0)。
# `learningRate` 参数控制模型更新速度(默认为 -1,表示自动调整)。
# - `getBackgroundImage()`:获取当前背景图像。返回背景图像(如果设置了阴影检测,会包括阴影区域)。
# - `getShadowThreshold()`:获取阴影检测的阈值。
#############################################################################################"""
# -*- coding: utf-8 -*-
# 作者: 胖墩会武术
# 日期: 1994-08-21
# OpenCV图像处理: https://blog.csdn.net/shinuone/article/details/126022763
(七)光流估计(实时目标跟踪) —— cv2.goodFeaturesToTrack()、cv2.calcOpticalFlowPyrLK()

OpenCV提供了演示数据:https://github.com/opencv/opencv/tree/master/samples/data
"""##########################################################################
本项目实现了基于 Lucas-Kanade光流法(Lucas-Kanade Optical Flow Method)的目标跟踪系统,能够在视频流中实时追踪运动目标。
光流方法通过分析视频帧之间像素点的运动,从而估计物体的速度和运动轨迹。
该方法主要利用了图像的连续性与时间域上的变化,计算每个角点的位移,从而进行目标的跟踪。
##########################################################################"""
import numpy as np
import cv2
# 视频路径
video_path = r"D:\opencv-master\opencv-master\samples\data\vtest.avi"
cap = cv2.VideoCapture(video_path) # 初始化视频捕捉对象
# 获取视频中的第一帧,设置为跟踪的基准帧
ret, old_frame = cap.read()
if not ret:
print("Failed to read the video.")
cap.release()
exit()
mask = np.zeros_like(old_frame) # 用于绘制轨迹图mask
color = np.random.randint(0, 255, (100, 3)) # 随机颜色用于绘制轨迹
###############################################################################################
# 利用 Shi-Tomasi角点检测算法(cv2.goodFeaturesToTrack)选择图像中的显著特征点作为跟踪的基础。
old_gray = cv2.cvtColor(old_frame, cv2.COLOR_BGR2GRAY) # 转为灰度图像
feature_params = dict(maxCorners=150, qualityLevel=0.3, minDistance=12) # ShiTomasi角点检测的参数
p0 = cv2.goodFeaturesToTrack(old_gray, mask=None, **feature_params)
###############################################################################################
while True:
ret, frame = cap.read() # 获取当前帧
if not ret:
break
###############################################################################################
# 使用 Lucas-Kanade光流法(cv2.calcOpticalFlowPyrLK)来计算特征点在相邻帧之间的位移。
frame_gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) # 转为灰度图像
lk_params = dict(winSize=(15, 15), maxLevel=2) # Lucas-Kanade光流法的参数
p1, st, err = cv2.calcOpticalFlowPyrLK(old_gray, frame_gray, p0, None, **lk_params)
# 选择状态为1的特征点,表示成功跟踪的点
good_new = p1[st == 1]
good_old = p0[st == 1]
# 绘制光流轨迹
for i, (new, old) in enumerate(zip(good_new, good_old)):
a, b = new.ravel() # 当前特征点的坐标
c, d = old.ravel() # 上一帧特征点的坐标
mask = cv2.line(mask, (int(a), int(b)), (int(c), int(d)), color[i].tolist(), 2) # 绘制光流线
frame = cv2.circle(frame, (int(a), int(b)), 5, color[i].tolist(), -1) # 绘制光流点
###############################################################################################
# 将轨迹线与当前帧图像合成
img = cv2.add(frame, mask)
cv2.imshow('Optical Flow Tracking', img)
k = cv2.waitKey(50) & 0xff
if k == 27: # 按Esc键退出
break
# 更新前一帧和特征点
old_gray = frame_gray.copy()
p0 = good_new.reshape(-1, 1, 2) # 更新特征点位置
# 处理目标丢失情况:如果跟踪失败,重新检测角点
if len(good_new) < 10: # 如果跟踪的点少于10个,认为目标丢失
p0 = cv2.goodFeaturesToTrack(old_gray, mask=None, **feature_params) # 重新选择特征点
mask = np.zeros_like(frame) # 重置mask
cap.release()
cv2.destroyAllWindows()
"""#############################################################################################
# 函数功能:用于在图像中检测最好的角点特征,通常用于后续的光流估计或物体跟踪等应用。
# 函数说明:cv2.goodFeaturesToTrack(image, mask=None, maxCorners=100, qualityLevel=0.3, minDistance=7, blockSize=3)
# 参数说明:
# image:输入图像,必须为灰度图像(单通道)。
# mask:可选的掩膜图像,指定在何处寻找角点。如果为None,则在整个图像上寻找角点。
# maxCorners:要检测的最大角点数目。默认值为100,表示最多返回100个角点。
# qualityLevel:角点质量的阈值,取值范围为 [0, 1],表示角点的最小质量。值越大,返回的角点越“好”。默认值为0.3。
# minDistance:检测到的角点之间的最小距离。如果两个角点距离小于此值,则认为它们是重复的。默认值为7。
# blockSize:用于计算角点的邻域大小。默认值为3。
# 返回值:
# 返回一个包含角点位置的 NumPy 数组,数组大小为 (N, 1, 2),其中 N 是检测到的角点数量,每个角点的坐标为 (x, y)。
# 功能描述:
# - `cv2.goodFeaturesToTrack()` 使用 Shi-Tomasi 角点检测算法检测图像中的“最佳”角点,适用于跟踪和运动分析等应用。
# - 该算法通过计算局部图像区域的自相关矩阵,并通过其特征值来评估区域的稳定性,选择“最强”的角点。
# - 检测到的角点是图像中变化最强的部分,因此通常包含了显著的物体边缘或角落信息。
# 常用应用:
# - 在光流估计中,使用检测到的角点来追踪运动。
# - 用于物体跟踪、场景重建等应用中。
#############################################################################################"""
"""#############################################################################################
# 函数功能:用于计算两个连续图像帧之间的稀疏光流(Optical Flow),通过金字塔Lucas-Kanade方法(Pyramidal Lucas-Kanade method)跟踪特征点的运动。
# 函数说明:cv2.calcOpticalFlowPyrLK(prevImg, nextImg, prevPts, nextPts=None, winSize=(21, 21), maxLevel=3,
# criteria=(cv2.TERM_CRITERIA_EPS | cv2.TERM_CRITERIA_COUNT, 30, 0.03), flags=0, minEigThreshold=1e-4)
# 参数说明:
# prevImg:前一帧图像,必须为灰度图像。
# nextImg:后一帧图像,必须为灰度图像。
# prevPts:前一帧中的特征点位置,必须为形状为 (N, 1, 2) 的 NumPy 数组,N 是特征点的个数。
# nextPts:返回的特征点的新位置,必须为形状为 (N, 1, 2) 的 NumPy 数组。如果没有给出,函数将会返回空。
# winSize:搜索窗口大小,默认为 (21, 21),即 21x21 像素的窗口。较大的窗口可能会导致计算较慢。
# maxLevel:金字塔的最大层数,默认为3,表示使用三层金字塔进行光流计算。较大的值可以提高精度,但会增加计算时间。
# criteria:用于停止迭代的条件。可以设置为 cv2.TERM_CRITERIA_EPS 或 cv2.TERM_CRITERIA_COUNT。
# 默认为 (cv2.TERM_CRITERIA_EPS | cv2.TERM_CRITERIA_COUNT, 30, 0.03),表示最多迭代 30 次或者直到光流计算的误差小于 0.03。
# flags:标志位,默认为 0,表示不使用任何特殊的标志。可以设置为 cv2.OPTFLOW_USE_INITIAL_FLOW 等。
# minEigThreshold:最小特征值的阈值,用于筛选特征点。默认值为 1e-4。
# 返回值:
# nextPts:特征点的新位置。
# status:一个布尔数组,指示每个特征点是否成功计算了光流,1 表示成功,0 表示失败。
# err:每个特征点的光流估计误差。
# 功能描述:
# - `cv2.calcOpticalFlowPyrLK()` 使用Lucas-Kanade方法计算连续两帧图像之间的光流。通过追踪前一帧图像中的特征点位置来估计它们在后一帧中的位置。
# - 该方法基于图像金字塔算法,通过在不同分辨率下计算光流,可以提高对快速运动物体的跟踪精度。
# - 常用于视频中的目标跟踪、光流估计、运动检测等任务。
# - `prevPts` 和 `nextPts` 都是 (N, 1, 2) 形式的数组,其中 N 是角点数量,每个点的格式是 (x, y),表示像素坐标。
# 常用应用:
# - 在视频中跟踪移动物体。
# - 计算图像的运动场(Optical Flow)。
# - 进行图像稳像或目标跟踪。
#############################################################################################"""
# -*- coding: utf-8 -*-
# 作者: 胖墩会武术
# 日期: 1994-08-21
# OpenCV图像处理: https://blog.csdn.net/shinuone/article/details/126022763
图文详解 OpenCV中光流以及视频特征点追踪(稀疏光流追踪+ 优化版稀疏光流追踪+密集光流追踪)
(八)图像分割
基于深度学习的图像分割(综述):Image Segmentation Using Deep Learning:A Survey
基于深度学习的医生图像分割(综述):Medical image segmentation using deep learning: A survey
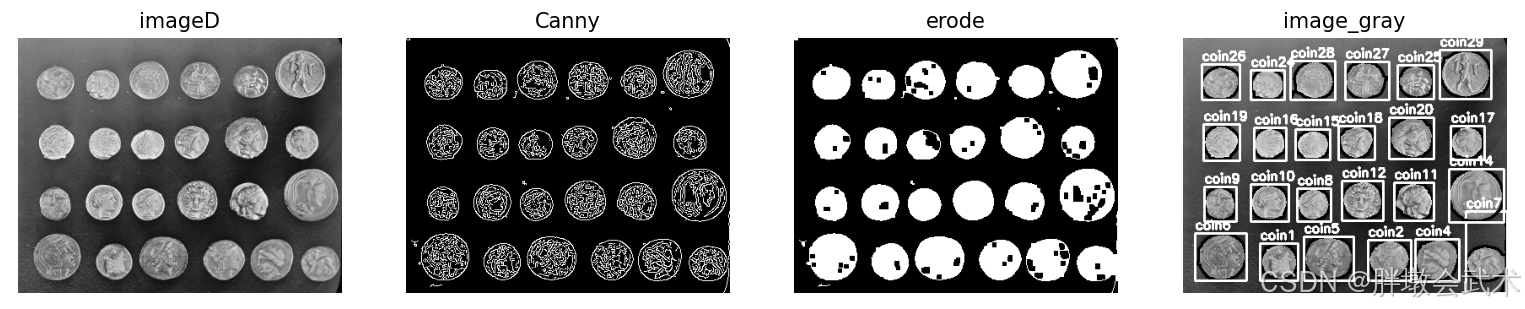
import skimage
import numpy as np
import cv2
import matplotlib.pyplot as plt
# (1)加载图像(硬币图像)
image = skimage.data.coins()
image_gray = image.copy()
# (2)图像处理
# image_blurred = cv2.GaussianBlur(image_gray, (5, 5), 0) # 高斯滤波
edges = cv2.Canny(image_gray, 50, 150) # 边缘检测
kernel = np.ones((3, 3), np.uint8) # 初始化卷积核(np.ones: 生成一个数值全为1的3x3数组)
dilate = cv2.dilate(edges, kernel, iterations=2) # 膨胀
erode = cv2.erode(dilate, kernel, iterations=2) # 腐蚀
# (3)轮廓检测
# _, image_threshold = cv2.threshold(image_gray, 120, 255, cv2.THRESH_BINARY) # 二值化
# _, image_threshold = cv2.threshold(image, 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU)
contours, _ = cv2.findContours(erode, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE) # 轮廓检测
for index, contour in enumerate(contours):
area = cv2.contourArea(contour) # 计算轮廓的面积
print(f"area{index}:{area}")
if 100 < area: # 过滤小轮廓.可根据实际情况调整阈值
cv2.drawContours(image_gray, [contour], -1, (0, 255, 0), 2) # 绘制轮廓
x, y, w, h = cv2.boundingRect(contour) # 计算轮廓的边界框
cv2.rectangle(image_gray, (x, y), (x + w, y + h), (255, 0, 0), 2) # 绘制矩形框
label = f'coin{index}'
cv2.putText(image_gray, label, (x, y - 5), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (255, 255, 255), 2)
# (4)显示结果
plt.subplot(141), plt.imshow(image, cmap='gray'), plt.axis('off'), plt.title('imageD')
plt.subplot(142), plt.imshow(edges, cmap='gray'), plt.axis('off'), plt.title('Canny')
plt.subplot(143), plt.imshow(erode, cmap='gray'), plt.axis('off'), plt.title('erode')
plt.subplot(144), plt.imshow(image_gray, cmap='gray'), plt.axis('off'), plt.title('image_gray')
plt.show()
(九)图像增强:灰度反转、对比度拉伸、对比度和亮度增强、指数变换、伽马变换、对数变换
(十)噪声模拟:均匀噪声、高斯噪声、椒盐噪声、泊松噪声、瑞利噪声、伽马噪声、乘性噪声
https://blog.csdn.net/shinuone/article/details/146089291
(十一)基于核函数的卷积操作:滤波器、形态学变化、边缘检测算子
https://blog.csdn.net/shinuone/article/details/146592095
(十二)添加水印

import cv2
import numpy as np
import matplotlib.pyplot as plt
def add_text_watermark(image_path, text, output_path, visualization_result=True, save_result=True,
count=1, layout=(1, 1), angle=0, font=cv2.FONT_HERSHEY_SIMPLEX,
font_scale=1, color=(0, 0, 255), thickness=2, opacity=0.3):
"""
在图像上添加文本水印
Args:
image_path (str): 输入图像的文件路径
text (str): 水印文本
output_path (str): 输出带水印的图像文件路径
visualization_result (bool): 是否在完成后可视化结果,默认为 True
save_result (bool): 是否保存结果,默认为 True
count (int): 水印的数量,默认为 1
layout (tuple): 水印布局,默认为 (1, 1)
angle (float): 水印旋转角度,默认为 0
font (int): 字体,默认为 cv2.FONT_HERSHEY_SIMPLEX
font_scale (float): 字体缩放因子,默认为 1
color (tuple): 水印颜色,默认为黑色 (0, 0, 0)
thickness (int): 字体线条粗细,默认为 2
opacity (float): 水印透明度,默认为 0.3
"""
# 加载图像
image = cv2.imread(image_path)
# 创建一个原始图像的副本,用于添加水印
image_watermarked = image.copy()
"""根据旋转后的水印大小调整水印比例"""
# 获取文字边界框大小
text_size = cv2.getTextSize(text, font, font_scale, thickness)[0]
# 根据文字大小创建水印
watermark = np.zeros((text_size[1], text_size[0], 3), dtype=np.uint8)
cv2.putText(watermark, text, (0, text_size[1] - 2), font, font_scale, color, thickness)
# 旋转水印
(w, h) = text_size
(cX, cY) = (w // 2, h // 2)
M = cv2.getRotationMatrix2D((cX, cY), angle, 1.0)
cos = np.abs(M[0, 0])
sin = np.abs(M[0, 1])
nW = int((h * sin) + (w * cos))
nH = int((h * cos) + (w * sin))
M[0, 2] += (nW / 2) - cX
M[1, 2] += (nH / 2) - cY
rotated_watermark = cv2.warpAffine(watermark, M, (nW, nH))
# 计算布局的步长
step_x = image.shape[1] // layout[1]
step_y = image.shape[0] // layout[0]
# 添加水印到图像
for i in range(layout[0]):
for j in range(layout[1]):
x_offset = j * step_x
y_offset = i * step_y
for k in range(count):
x_pos = x_offset + k * rotated_watermark.shape[1]
y_pos = y_offset + k * rotated_watermark.shape[0]
if x_pos + rotated_watermark.shape[1] <= image.shape[1] and y_pos + rotated_watermark.shape[0] <= image.shape[0]:
# 使用cv2.addWeighted函数将水印添加到图像上
image_watermarked[y_pos:y_pos + rotated_watermark.shape[0], x_pos:x_pos + rotated_watermark.shape[1]] = \
cv2.addWeighted(src1=image[y_pos:y_pos + rotated_watermark.shape[0], x_pos:x_pos + rotated_watermark.shape[1]], alpha=1.0,
src2=rotated_watermark, beta=opacity, gamma=0)
# 可视化结果
if visualization_result:
# 转换颜色通道顺序(OpenCV默认为BGR,Matplotlib默认为RGB)
image_rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
image_watermarked_rgb = cv2.cvtColor(image_watermarked, cv2.COLOR_BGR2RGB)
# 创建图像窗口
fig, axes = plt.subplots(1, 2, figsize=(12, 6))
# 在第一个子图中绘制原始图像
axes[0].imshow(image_rgb)
axes[0].set_title('Original Image')
axes[0].axis('off')
# 在第二个子图中绘制带水印的图像
axes[1].imshow(image_watermarked_rgb)
axes[1].set_title('Watermarked Image')
axes[1].axis('off')
plt.show() # 显示图像
# 保存结果
if save_result:
cv2.imwrite(output_path, image_watermarked)
if __name__ == '__main__':
image_path = r'image.jpg'
output_path = r'output.jpg'
text = 'Watermark'
add_text_watermark(image_path, text, output_path,
visualization_result=True, save_result=False,
count=50, layout=(2, 5), angle=30, color=(0, 0, 255), opacity=1.0)
第零章、环境配置
conda create --name py39 -y
conda activate py39
conda install python==3.9
pip install opencv-python==4.5.1.48
pip install opencv-contrib-python==4.5.1.48
第一章、图像的基本操作
1.1、图像操作(读取 + 显示 + 保存) —— cv2.imread() + cv2.imshow() + cv2.imwrite()
(1)(在同一个窗口)同时显示多张图 plt.subplot()
(2)cv2.imshow()和plt.imshow()的区别

"""#####################################################################
# cv2是 opencv 在 python 中的缩写;
#
# Matplotlib 是一个 Python 库,用于绘制图形和图表。
# Matplotlib 中的 pyplot 模块,可以控制线条样式,字体属性,格式化轴等功能。
# 且支持各种各样的图形绘制,如直方图,条形图,功率谱,误差图等。
#####################################################################"""
import cv2 # opencv 读取图像默认为BGR
import matplotlib.pyplot as plt # matplotlib显示图像默认为RGB
image_path = r'image.jpg'
######################################################################################
# 读取图像
image = cv2.imread(image_path) # 默认为彩色图像
image_color = cv2.imread(image_path, cv2.IMREAD_COLOR)
image_gray = cv2.imread(image_path, cv2.IMREAD_GRAYSCALE)
image_unchanged = cv2.imread(image_path, cv2.IMREAD_UNCHANGED)
######################################################################################
# 保存图像
cv2.imwrite('image_gray.jpg', image_gray)
######################################################################################
# 显示图像
cv2.imshow('image', image)
cv2.imshow('cv2.IMREAD_COLOR', image_color)
cv2.imshow('cv2.IMREAD_GRAYSCALE', image_gray)
cv2.imshow('cv2.IMREAD_UNCHANGED', image_unchanged)
cv2.waitKey(1000) # 延迟一秒后自动关闭图像
cv2.destroyAllWindows() # (同时)摧毁所有图窗
######################################################################################
# 两者都可以,但需要注意图像格式为RGB,plt显示图像为RGB,而opencv读取图像为BGR。
plt.subplot(141), plt.imshow(cv2.cvtColor(image, cv2.COLOR_BGR2RGB)), plt.title('image_raw')
plt.subplot(142), plt.imshow(cv2.cvtColor(image_color, cv2.COLOR_BGR2RGB)), plt.title('cv2.IMREAD_COLOR')
plt.subplot(143), plt.imshow(image_gray, cmap='gray'), plt.title('cv2.IMREAD_GRAYSCALE')
plt.subplot(144), plt.imshow(cv2.cvtColor(image_unchanged, cv2.COLOR_BGR2RGB)), plt.title('cv2.IMREAD_UNCHANGED')
plt.show()
plt.imshow(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
plt.colorbar()
plt.show()
"""####################################################################################################################
# 函数功能:读取图像(图像格式为RGB,但OpenCV读取图像的默认格式为BGR)
# 函数说明:image = cv2.imread(filename, flags=cv2.IMREAD_COLOR)
# 参数说明:
# filename: 图像路径(若路径错误,则返回None,但不报错),支持多种图像格式:
# - .jpg 常见的压缩图片格式,支持有损压缩和无损压缩,文件体积小,广泛使用。
# - .jpeg 和 .jpg 类似,主要用于图片存储与传输。
# - .png 支持无损压缩,并支持透明通道(Alpha 通道)。
# - .bmp 位图格式,不压缩,文件体积大,适合高精度图像存储。
# - .tiff 高质量图像格式,支持多种压缩方式(如无损 LZW 压缩)。
# - .webp 新型格式,支持高压缩比及透明通道,适用于网络传输。
# - .ppm 一种简单的图像格式,主要用于便携图形文件的存储。
# - .pgm 灰度图像的便携格式,与 .ppm 类似。
# - .pbm 二值图像的便携格式,与 .ppm 类似。
# - .sr Sun Raster 格式。
# - .ras Sun Raster 格式。
# flags: 读取模式
# - cv2.IMREAD_COLOR(1) 加载彩色图像(忽略 Alpha 通道)。
# - cv2.IMREAD_GRAYSCALE(0) 加载灰度图像。
# - cv2.IMREAD_UNCHANGED(-1) 加载原始图像,包括图像的 alpha 通道(透明度)。
# 返回参数:
# 返回一个 Numpy 数组 image,表示读取的图像。
############################################################
# 在Python中,'r' 是一个标志,用来指示字符串是原始字符串(raw string)。原始字符串会忽略其中的转义字符,反而会将反斜杠 '\' 视为普通字符。
############################################################
# 文件命名规范:
# (1)不能出现中文
# (2)不能出现空格
# (3)使用英文字母、数字、下划线或连字符,作为文件或文件夹名,以避免兼容性问题。
############################################################
# 路径表示方法 ———— 注意路径分隔符在Windows系统中是反斜杠('\'),但为了避免转义问题,通常建议使用斜杠('/')或原始字符串(r'...')。
# 绝对路径:path = r'F:/py/image.jpg'
# 相对路径:path = r'image.jpg' # 同级目录(脚本文件和资源文件在同一目录下)
# path = r'./image.jpg' # 同级目录(脚本文件和资源文件在同一目录下) ———— ./ 表示当前目录,但可以省略。
# path = r'../image.jpg' # 上级目录(资源文件在脚本所在目录的上一级) ———— ../ 表示上一级目录
############################################################
# 在Python中,反斜杠 '\' 是一个转义字符,用来表示一些特殊的字符
# (1)'\n': 表示换行符
# (2)'\t': 表示制表符tab
# (3)'\\': 表示单个反斜杠
####################################################################################################################"""
"""####################################################################################################################
# 函数功能:保存图像
# 函数说明:cv2.imwrite(filename, img, params=None)
# 参数说明:
# filename: 要保存的目标文件的路径。
# img: 要保存的图像数据,可以是 Numpy 数组。
# params: 可选参数,用于指定保存图像的额外参数,例如 JPEG 图像的压缩质量。
# 返回参数:
# 如果成功保存图像,则返回 True;否则返回 False。
####################################################################################################################"""
"""####################################################################################################################
# 函数功能:显示图像
# 函数说明:cv2.imshow(winname, image)
# 参数说明:
# winname: 窗口的名称,用于标识窗口。
# image: 要显示的图像,可以是灰度图像或彩色图像,表示为一个 Numpy 数组。
#
# 备注: (1)在显示图像之后,一般会调用 cv2.waitKey() 函数来等待用户按下键盘,否则窗口会立即关闭。
# (2)窗口会自适应图像大小
# (3.1)若指定多个不同的窗口名称,则显示多幅图像;
# (3.2)若指定多个相同的窗口名称,则后一个图像会覆盖前一个图像,从而只产生一个(连续)窗口。如:视频
####################################################################################################################"""
"""########################################################################
# -*- coding: utf-8 -*-
# 作者: 胖墩会武术
# 日期: 1994-08-21
# OpenCV图像处理: https://blog.csdn.net/shinuone/article/details/126022763
# 版权所有 (C) 1994 胖墩会武术
#
# 本文件遵循开源协议,使用、修改、分发时请遵循以下条款:
# 1. 保留本文件头信息,包含版权声明、作者信息及出处。
# 2. 转载或发布衍生作品时,必须注明原作者及出处。
# 3. 未经作者许可,不得用于商业用途。
########################################################################"""
1.2、显示多幅图像
1.2.1、堆叠图像(numpy 水平 + 垂直) —— np.hstack() + np.vstack()
import numpy as np
import cv2 # opencv读取图像默认为BGR
import matplotlib.pyplot as plt # matplotlib显示图像默认为RGB
image = cv2.imread(r"image.jpg")
res_horizontal = np.hstack((image, image)) # 水平方向堆叠图像
res_vertical = np.vstack((image, image)) # 竖直方向堆叠图像
plt.subplot(1, 3, 1), plt.imshow(image), plt.title('image'), plt.axis('off')
plt.subplot(1, 3, 2), plt.imshow(res_horizontal), plt.title('res_horizontal'), plt.axis('off')
plt.subplot(1, 3, 3), plt.imshow(res_vertical), plt.title('res_vertical'), plt.axis('off')
plt.show()
# 常用于数据拼接和组合
"""#############################################################################################
# 函数功能:沿水平方向将数组进行堆叠。
# 函数说明:np.hstack(tup)
# 参数说明:
# tup:一个包含要堆叠的数组的元组或列表。所有输入数组必须具有相同的形状,除了要堆叠的轴(即列数可以不同)。
# 返回值:
# 返回一个新的数组,包含输入数组在水平方向上堆叠的结果。
#############################################################################################"""
"""#############################################################################################
# 函数功能:沿垂直方向将数组进行堆叠。
# 函数说明:np.vstack(tup)
# 参数说明:
# tup:一个包含要堆叠的数组的元组或列表。所有输入数组必须具有相同的形状,除了要堆叠的轴(即行数可以不同)。
# 返回值:
# 返回一个新的数组,包含输入数组在垂直方向上堆叠的结果。
#############################################################################################"""
# -*- coding: utf-8 -*-
# 作者: 胖墩会武术
# 日期: 1994-08-21
# OpenCV图像处理: https://blog.csdn.net/shinuone/article/details/126022763
1.2.2、显示图像(matplotlib 在同一个图窗中) —— plt.imshow()
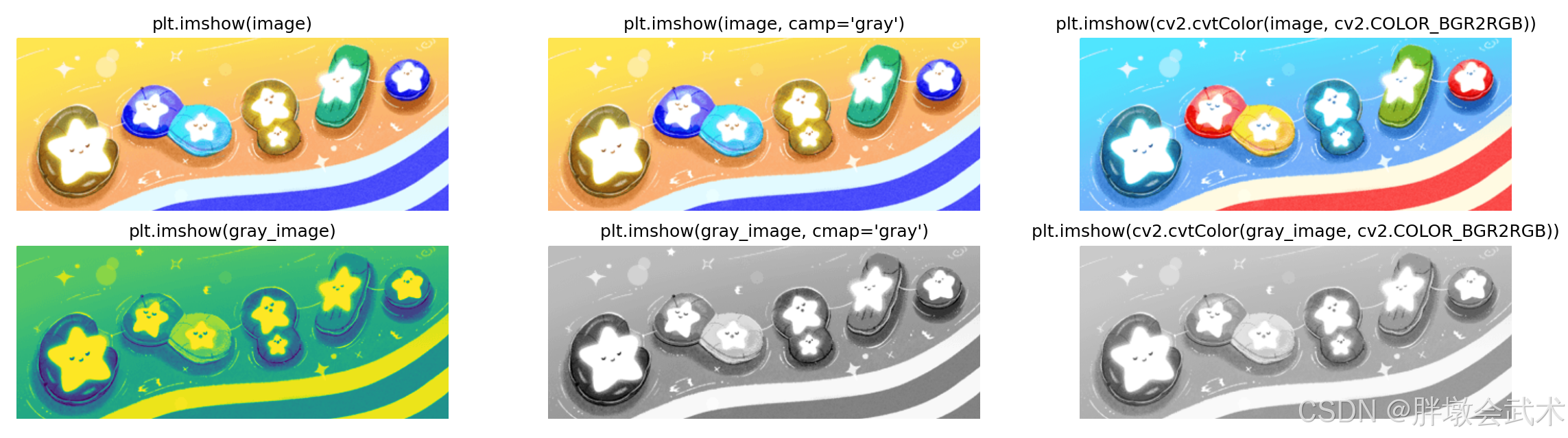
OpenCV读取图像默认为 BGR 格式,matplotlib显示图像默认为RGB。
- 如果图像是彩色图像,但直接使用 plt.imshow(image, cmap=‘gray’),则 plt.imshow 仍然会显示为彩色,因为数据未被正确转换为灰度格式。
- 如果图像是灰度图像,但在使用 plt.imshow 时没有指定 cmap=‘gray’,则 plt.imshow 会将该灰度图像作为 RGB 图像来处理。
import cv2 # opencv读取图像默认为BGR
import matplotlib.pyplot as plt # matplotlib显示图像默认为RGB
image = cv2.imread(r"image.jpg")
gray_image = cv2.imread('image.jpg', cv2.IMREAD_GRAYSCALE)
plt.subplot(2, 3, 1), plt.imshow(image), plt.title("plt.imshow(image)"), plt.axis('off')
plt.subplot(2, 3, 2), plt.imshow(image, cmap='gray'), plt.title("plt.imshow(image, camp='gray')"), plt.axis('off')
plt.subplot(2, 3, 3), plt.imshow(cv2.cvtColor(image, cv2.COLOR_BGR2RGB)), plt.title("plt.imshow(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))"), plt.axis('off')
plt.subplot(2, 3, 4), plt.imshow(gray_image), plt.title("plt.imshow(gray_image)"), plt.axis('off')
plt.subplot(2, 3, 5), plt.imshow(gray_image, cmap='gray'), plt.title("plt.imshow(gray_image, cmap='gray')"), plt.axis('off')
plt.subplot(2, 3, 6), plt.imshow(cv2.cvtColor(gray_image, cv2.COLOR_BGR2RGB)), plt.title("plt.imshow(cv2.cvtColor(gray_image, cv2.COLOR_BGR2RGB))"), plt.axis('off')
plt.show()
"""#############################################################################################
# 函数功能:用于显示图像或矩阵数据,并自动将其展示在一个窗口中。
# 函数说明:plt.imshow(image, cmap=None, norm=None, interpolation=None, origin=None, extent=None, filternorm=True, filterrad=4.0, resample=None, url=None, **kwargs)
# 参数说明:
# image:要显示的图像或矩阵数据,通常是二维或三维数组。对于彩色图像,通常是一个三维数组(高度 x 宽度 x 通道)。
# cmap:用于映射图像颜色的颜色图(colormap),可以为字符串类型的预定义颜色映射名称,如 "gray", "hot", "viridis" 等。
# 如果为 None,默认使用数据类型决定颜色映射。
# norm:用于归一化图像数据的方式,通常为 `matplotlib.colors.Normalize` 类型。用于控制图像色阶的显示。
# interpolation:插值方法,用于图像缩放的插值方式,常见的有:
# - 'nearest':最近邻插值
# - 'bilinear':双线性插值
# - 'bicubic':双三次插值
# - 'spline36':三次样条插值
# - 'hanning'、'hamming'、'hermite' 等其他方法
# origin:设置显示图像时的原点位置。常用值包括:
# - 'upper':图像从上方开始显示
# - 'lower':图像从下方开始显示
# extent:设置图像显示区域的范围,四个数值:`[xmin, xmax, ymin, ymax]`,用于图像显示时的坐标轴限制。
# filternorm:布尔值,指定是否对图像进行归一化处理。
# filterrad:浮动值,控制滤波器的半径。
# resample:布尔值,指定是否启用图像重采样。
# url:设置图像链接,适用于使用网络图像的情况。
# **kwargs:其他 `imshow` 支持的参数,例如 `alpha`、`aspect` 等。
# 返回值:
# 返回一个包含图像对象的句柄(`AxesImage`),可以进一步修改图像显示的属性。
#############################################################################################"""
# -*- coding: utf-8 -*-
# 作者: 胖墩会武术
# 日期: 1994-08-21
# OpenCV图像处理: https://blog.csdn.net/shinuone/article/details/126022763
1.3、视频操作(读取 + 显示 + 获取属性) —— cv2.VideoCapture() + cv2.VideoWriter + cap.get

OpenCV提供了演示数据:https://github.com/opencv/opencv/tree/master/samples/data
"""
(1)点击空格键暂停视频播放,再次点击空格键继续播放。
(2)按 Esc 键退出程序
"""
import cv2
# (1)读取视频
video_path = r"D:\opencv-master\opencv-master\samples\data\vtest.avi"
cap = cv2.VideoCapture(video_path) # 初始化视频捕捉对象
# (2)检查视频是否可以打开
if not cap.isOpened():
print("Error: Could not open video.")
exit()
# (3)获取视频属性
frame_width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH)) # 获取视频宽度
frame_height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT)) # 获取视频高度
frame_count = int(cap.get(cv2.CAP_PROP_FRAME_COUNT)) # 总帧数
fps = cap.get(cv2.CAP_PROP_FPS) # 帧率
fourcc = cv2.VideoWriter_fourcc(*'XVID') # 指定视频编码格式
# (4)初始化 VideoWriter
output_path = r"output_video.avi" # 保存路径
isColor = True # 保存图像为灰度图还是彩色图
out = cv2.VideoWriter(filename=output_path, fourcc=fourcc, fps=fps, frameSize=(frame_width, frame_height), isColor=isColor)
# (5)读取帧 + 保存帧 + 显示帧
paused = False # 控制是否暂停播放
while True:
if not paused: # 只有在没有暂停时,才读取和显示新的一帧
ret, frame = cap.read() # 读取帧
if not ret:
print("Error: Failed to read frame or video end reached.")
break
out.write(frame) # 保存帧
cv2.imshow('Video', frame) # 显示帧
## 为什么会产生视频效果? ———— 循环读取每一帧,并将其固定显示在同一个窗口上,则后一帧会覆盖前一帧,就产生了视频效果。
key = cv2.waitKey(100) & 0xFF # 获取按键(控制速度)
if key == 27: # 按Esc键退出
break
elif key == 32: # 按空格键暂停/继续
paused = not paused # 切换暂停状态
# (6)释放资源
cap.release()
out.release()
cv2.destroyAllWindows()
"""#############################################################################################
# 函数功能:用于打开视频文件、摄像头或其他视频设备,并从中读取视频帧。
# 函数说明:cap = cv2.VideoCapture([filename or device index])
# 参数说明:
# filename or device index:输入的视频文件路径或视频设备索引。
# - 如果是文件路径,指定要打开的影片文件(如 'video.mp4')。
# - 如果是设备索引,指定打开的摄像头,通常索引为 0 表示默认摄像头,1 表示第二个摄像头,以此类推。
# - 如果设备不可用或路径无效,函数返回失败。
# 返回值:
# 如果打开成功,返回一个 `cv2.VideoCapture` 对象,用于读取视频帧。如果失败,则返回空对象。
# 常用方法:
# 1. `cap.read()`:从视频流中读取一帧图像,返回两个值,布尔值和帧图像。如果成功读取,布尔值为 True,帧图像为读取的图像矩阵。
# 2. `cap.isOpened()`:检查视频文件或设备是否成功打开。
# 3. `cap.get(propId)`:获取视频文件的属性,例如帧宽度、高度、帧率等。
# 4. `cap.set(propId, value)`:设置视频文件的属性,如设置帧的宽度和高度等。
# 5. `cap.release()` 释放资源。
#############################################################################################"""
"""#############################################################################################
# 函数功能:用于指定视频编解码器的四字符代码(FourCC),FourCC 是一个 4 字节的代码。常用于定义视频保存时的编码格式,例如 AVI、MP4 等。
# 函数说明:fourcc = cv2.VideoWriter_fourcc(c1, c2, c3, c4)
# 参数说明:
# c1, c2, c3, c4:构成 FourCC 编解码器标识符的四个字符。常见的 FourCC 值:
# - 'XVID': OpenDivX 编解码器 文件扩展名:.avi 适用于需要良好兼容性并且对压缩效率要求不高的场景。
# - 'DIVX': DivX 编解码器 文件扩展名:.avi 适用于需要中等压缩质量和高质量视频的应用。支持逐渐下降
# - 'MJPG': Motion JPEG 编解码器 文件扩展名:.avi 或.mp4 适用于需要快速编码且每帧独立,但输出视频文件较大,缺乏帧间压缩。
# - 'MP4V': MPEG-4 编解码器 文件扩展名:.mp4 适用于需要中等压缩效果和较好兼容性的应用,尤其是在较老的设备上使用。
# - 'H264': 高级视频编码标准 文件扩展名:.mp4 适用于需要高压缩效率、文件较小且质量较高的场景。H264 是最常用的现代视频编码标准。
# 返回值:
# 返回一个整数,表示对应的 FourCC 编解码器标识符。
#############################################################################################"""
"""#############################################################################################
# 函数功能:用于创建一个视频写入对象,方便将帧数据保存为视频文件。
# 函数说明:out = cv2.VideoWriter(filename, fourcc, fps, frameSize, isColor=True)
# 参数说明:
# filename:字符串,保存视频的文件名及路径。例如 'output.avi'。
# fourcc:编码器的四字符代码,使用 `cv2.VideoWriter_fourcc()` 创建。
# fps:每秒帧数(帧率),指定视频播放的帧速率。
# frameSize:元组,表示视频帧的宽度和高度,例如 (640, 480)。
# isColor:布尔值,是否保存为彩色视频。默认值为 True(彩色),若为 False,则保存为灰度视频。
# 返回值:
# 返回一个 cv2.VideoWriter 对象,用于向视频文件写入帧。
# 使用步骤:
# 1. 使用 `fourcc = cv2.VideoWriter_fourcc()` 创建编码器标识符。
# 2. 调用 `out = cv2.VideoWriter` 创建视频写入对象。
# 3. 使用 `out.write(frame)` 方法将帧写入视频。
# 4. 调用 `out.release()` 释放资源。
#############################################################################################"""
# -*- coding: utf-8 -*-
# 作者: 胖墩会武术
# 日期: 1994-08-21
# OpenCV图像处理: https://blog.csdn.net/shinuone/article/details/126022763
1.4、图窗事件
1.4.1、窗口设置 —— cv2.namedWindow() + cv2.resizeWindow() + cv2.moveWindow() + cv2.setWindowProperty()
import cv2
window_name = 'projector' # 图窗标题
cv2.namedWindow(window_name, cv2.WINDOW_KEEPRATIO) # 创建命名窗口
cv2.resizeWindow(window_name, 10, 20) # 自定义窗口大小
cv2.moveWindow(window_name, 100, 200) # 设置窗口位置
cv2.setWindowProperty(window_name, cv2.WND_PROP_TOPMOST, 1) # 设置窗口属性(控制窗口总在最前面)
image = cv2.imread('image.jpg') # 读取图像
cv2.imshow(window_name, image) # 显示图像
cv2.waitKey(0) # 等待输入任意键
cv2.destroyAllWindows() # 摧毁所有图窗
"""#############################################################################################
# 函数功能:创建一个窗口,指定窗口名称。窗口可以显示图像,并且可以设置窗口的大小、标志等属性。
# 函数说明:cv2.namedWindow(winname, flags=cv2.WINDOW_NORMAL)
# 参数说明:
# winname:窗口的名称,字符串类型,用于指定窗口的名称。
# flags:窗口的标志,控制窗口的大小、显示模式等。常用标志有:
# cv2.WINDOW_NORMAL:允许调整窗口大小。
# cv2.WINDOW_AUTOSIZE:窗口大小根据图像的尺寸自动调整(不能手动调整大小)。
# cv2.WINDOW_FREERATIO:窗口的宽高比不固定,能够自由调整。
# cv2.WINDOW_KEEPRATIO:窗口的宽高比保持一致。
# cv2.WINDOW_OPENGL 窗口创建的时候会支持OpenGL
# cv2.WINDOW_GUI_EXPANEDE 创建的窗口允许添加工具栏和状态栏。
# cv2.WINDOW_GUI_NORMAL 创建没有状态栏和工具栏窗口。
# cv2.WINDOW_AUTOSIZE 窗口大小自动适应图片大小,并且不可手动更改。
# 返回值:
# 无返回值。此函数仅创建指定的窗口。
#############################################################################################"""
"""#############################################################################################
# 函数功能:调整已创建的窗口大小。
# 函数说明:cv2.resizeWindow(winname, width, height)
# 参数说明:
# winname:窗口的名称,字符串类型,必须是已经创建的窗口的名称。
# width:窗口的宽度,整数类型,单位为像素。
# height:窗口的高度,整数类型,单位为像素。
# 返回值:
# 无返回值。该函数直接修改指定窗口的大小。
#############################################################################################"""
"""#############################################################################################
# 函数功能:移动窗口到指定的位置。
# 函数说明:cv2.moveWindow(winname, x, y)
# 参数说明:
# winname:窗口的名称,字符串类型,必须是已经创建的窗口的名称。
# x:窗口左上角的水平位置,整数类型,单位为像素。
# y:窗口左上角的垂直位置,整数类型,单位为像素。
# 返回值:
# 无返回值。该函数直接将指定窗口移动到目标位置。
#############################################################################################"""
"""#############################################################################################
# 函数功能:设置窗口的属性,例如窗口的透明度、是否固定大小等。
# 函数说明:cv2.setWindowProperty(winname, prop_id, value)
# 参数说明:
# winname:窗口的名称,字符串类型,必须是已经创建的窗口的名称。
# prop_id:窗口属性的标识符,常用值有:
# cv2.WND_PROP_FULLSCREEN:控制窗口是否为全屏。值可以是:
# - cv2.WINDOW_NORMAL:窗口为普通大小
# - cv2.WINDOW_FULLSCREEN:窗口全屏
# cv2.WND_PROP_AUTOSIZE:控制窗口大小是否自动调整,值为:
# - 0:不自动调整
# - 1:自动调整
# cv2.WND_PROP_TOPMOST:控制窗口是否总在最前面,值为:
# - 0:不总是最前
# - 1:总是最前
# cv2.WND_PROP_VISIBLE:控制窗口是否可见,值为:
# - 0:不可见
# - 1:可见
# value:设置的属性值,类型根据不同的属性标识符而变化。
# 返回值:
# 返回设置成功的值,通常为设置的属性值(成功时通常为 `value` 本身)。
#############################################################################################"""
# -*- coding: utf-8 -*-
# 作者: 胖墩会武术
# 日期: 1994-08-21
# OpenCV图像处理: https://blog.csdn.net/shinuone/article/details/126022763
1.4.2、窗口关闭 —— cv2.waitKey() + cv2.destroyAllWindows()
"""#############################################################################################
# 函数功能:等待用户按下键盘按键,函数返回按下的键的ASCII值或其他特定的键值。
# 函数说明:cv2.waitKey([delay])
# 参数说明:
# delay:等待的时间,单位为毫秒。如果 `delay` 为正数,函数会等待指定的时间(毫秒);如果为 0,函数会无限期等待直到用户按下按键。
# - delay > 0:等待指定的毫秒数,函数返回按下的键的ASCII值。
# - delay = 0:无限期等待用户按键,直到用户按下任意键,函数返回按下的键的ASCII值。
# - delay = -1:表示一直等待,通常和按键事件配合使用。
# 返回值:
# 返回按下的键的 ASCII 值,或者如果没有按键按下,则返回 -1。
# 如果用户按下了某些特定的键(例如,'Esc'),可以根据其返回值进行特定处理。
# 功能描述:
# - cv2.waitKey 用于等待键盘输入,通常在使用 `imshow()` 展示图像后调用,用于暂停程序并等待用户的操作。
# - 如果没有按键,且设置了 `delay > 0`,函数会在指定的毫秒后返回 -1;如果用户按下了某个键,函数返回对应的键的ASCII值。
# - 可以配合 `cv2.destroyAllWindows()` 使用,在用户按键后关闭所有窗口。
#############################################################################################"""
"""#############################################################################################
# 函数功能:关闭所有由 OpenCV 创建的窗口。
# 函数说明:cv2.destroyAllWindows()
# 参数说明:
# 此函数没有参数。
# 返回值:
# 无返回值。
# 功能描述:
# - `cv2.destroyAllWindows` 会关闭当前程序中所有通过 `cv2.imshow` 或 `cv2.namedWindow` 打开的窗口。
# - 通常与 `cv2.waitKey()` 配合使用,在用户按下某个键后关闭所有窗口。
# - 即使没有打开窗口,调用此函数也不会报错。
# 注意事项:
# - 在调用此函数之前,应确保程序已经完成所有窗口相关的操作。
# - 如果需要关闭特定窗口,可以使用 `cv2.destroyWindow(windowName)`。
#############################################################################################"""
# -*- coding: utf-8 -*-
# 作者: 胖墩会武术
# 日期: 1994-08-21
# OpenCV图像处理: https://blog.csdn.net/shinuone/article/details/126022763
1.4.3、鼠标事件 —— cv2.setMouseCallback
import time
import cv2
import numpy as np
last_time = 0 # 初始化上次时间
def mouse_callback(event, x, y, flags, param):
"""回调函数,用来处理鼠标事件"""
global last_time
# 处理鼠标移动事件
if event == cv2.EVENT_MOUSEMOVE:
current_time = time.time() # 获取当前时间
# 如果距离上次事件超过3秒,则打印并更新last_time
if current_time - last_time > 3:
print(f"Mouse moved to ({x}, {y})")
last_time = current_time # 更新上次触发时间
# 处理鼠标左键按下事件
elif event == cv2.EVENT_LBUTTONDOWN:
print(f"Left button clicked at ({x}, {y})")
# 处理鼠标左键释放事件
elif event == cv2.EVENT_LBUTTONUP:
print(f"Left button released at ({x}, {y})")
# 处理鼠标右键按下事件
elif event == cv2.EVENT_RBUTTONDOWN:
print(f"Right button clicked at ({x}, {y})")
# 处理鼠标右键释放事件
elif event == cv2.EVENT_RBUTTONUP:
print(f"Right button released at ({x}, {y})")
# 处理鼠标中键按下事件
elif event == cv2.EVENT_MBUTTONDOWN:
print(f"Middle button clicked at ({x}, {y})")
# 处理鼠标中键释放事件
elif event == cv2.EVENT_MBUTTONUP:
print(f"Middle button released at ({x}, {y})")
# 处理鼠标左键双击事件
elif event == cv2.EVENT_LBUTTONDBLCLK:
print(f"Left button double clicked at ({x}, {y})")
# 处理鼠标右键双击事件
elif event == cv2.EVENT_RBUTTONDBLCLK:
print(f"Right button double clicked at ({x}, {y})")
# 处理鼠标中键双击事件
elif event == cv2.EVENT_MBUTTONDBLCLK:
print(f"Middle button double clicked at ({x}, {y})")
# 处理鼠标滚轮事件
elif event == cv2.EVENT_MOUSEWHEEL:
if flags > 0:
print(f"Mouse wheel moved up at ({x}, {y})")
else:
print(f"Mouse wheel moved down at ({x}, {y})")
# 处理鼠标横向滚轮事件
elif event == cv2.EVENT_MOUSEHWHEEL:
if flags > 0:
print(f"Mouse horizontal wheel moved right at ({x}, {y})")
else:
print(f"Mouse horizontal wheel moved left at ({x}, {y})")
if __name__ == "__main__":
image = 255 * np.ones(shape=(500, 500, 3), dtype=np.uint8)
cv2.imshow("Mouse Event", image)
# 设置鼠标事件回调
cv2.setMouseCallback("Mouse Event", mouse_callback)
cv2.waitKey(0)
cv2.destroyAllWindows()
"""##########################################################################
# 函数功能:设置鼠标事件回调函数 ———— 它允许用户为窗口设置一个回调函数,当在该窗口上触发鼠标事件时,回调函数会被调用。
# 函数说明:cv2.setMouseCallback(windowName, MouseCallback, param=None)
# 输入参数:
# windowName: 窗口名称,指定用于设置回调的窗口。
# MouseCallback: 鼠标响应回调函数,当鼠标事件发生时会自动调用该函数。
# param: 传递给回调函数的额外参数,默认为 None。
##########################################################################"""
"""##########################################################################
# 函数功能:鼠标事件回调函数 ———— 这是一个用户自定义的函数,用于处理鼠标事件。
# 函数说明:MouseCallback(int event, int x, int y, int flags, *userdata)
# 输入参数:
# event: 鼠标事件类型,表示鼠标的不同操作(如点击、移动、双击等)。常见的事件类型包括:
# (1) cv2.EVENT_MOUSEMOVE = 0 鼠标移动
# (2) cv2.EVENT_LBUTTONDOWN = 1 左键按下
# (3) cv2.EVENT_RBUTTONDOWN = 2 右键按下
# (4) cv2.EVENT_MBUTTONDOWN = 3 中键按下
# (5) cv2.EVENT_LBUTTONUP = 4 左键释放
# (6) cv2.EVENT_RBUTTONUP = 5 右键释放
# (7) cv2.EVENT_MBUTTONUP = 6 中键释放
# (8) cv2.EVENT_LBUTTONDBLCLK = 7 左键双击
# (9) cv2.EVENT_RBUTTONDBLCLK = 8 右键双击
# (10) cv2.EVENT_MBUTTONDBLCLK = 9 中键双击
# (11) cv2.EVENT_MOUSEWHEEL = 10 滚轮滑动(滚动方向:向上滚动时通常是负值,向下滚动时是正值)
# (12) cv2.EVENT_MOUSEHWHEEL = 11 横向滚轮滑动(较少使用)
# x, y: 鼠标在窗口中的位置,表示鼠标事件发生时的坐标。
# flags: 鼠标按键和键盘修饰符,用于传递额外的信息(如 Ctrl、Shift 或 Alt)。常见的标志包括:
# (1) cv2.EVENT_FLAG_LBUTTON = 1 左键按下标志。与 EVENT_LBUTTONDOWN 一起使用。
# (2) cv2.EVENT_FLAG_RBUTTON = 2 右键按下标志。与 EVENT_RBUTTONDOWN 一起使用。
# (3) cv2.EVENT_FLAG_MBUTTON = 4 中键按下标志。与 EVENT_MBUTTONDOWN 一起使用。
# (4) cv2.EVENT_FLAG_CTRLKEY = 8 Ctrl 键按下标志
# (5) cv2.EVENT_FLAG_SHIFTKEY = 16 Shift 键按下标志
# (6) cv2.EVENT_FLAG_ALTKEY = 32 Alt 键按下标志
# userdata: 可选参数,可用于传递额外的自定义数据给回调函数(例如图像对象等)。
#
# 鼠标事件组合(示例)
# cv2.EVENT_LBUTTONDOWN + cv2.EVENT_FLAG_CTRLKEY 表示鼠标左键按下时同时按下了 Ctrl 键。
# cv2.EVENT_LBUTTONUP + cv2.EVENT_FLAG_ALTKEY 表示鼠标左键松开时按下了 Alt 键。
##########################################################################"""
# -*- coding: utf-8 -*-
# 作者: 胖墩会武术
# 日期: 1994-08-21
# OpenCV图像处理: https://blog.csdn.net/shinuone/article/details/126022763
(1)鼠标 - 绘制线条

import cv2
import numpy as np
def love_path(image):
# 计算爱心形状的路径
heart_points = []
for t in np.linspace(0, 2 * np.pi, 100): # 生成100个点,点数可以根据需要调整
x = 16 * np.sin(t) ** 3
y = 13 * np.cos(t) - 5 * np.cos(2 * t) - 2 * np.cos(3 * t) - np.cos(4 * t)
heart_points.append((int(120 + x * 4), int(100 - y * 4))) # 缩放并平移
# 使用直线连接这些点
for i in range(len(heart_points) - 1):
cv2.line(image, heart_points[i], heart_points[i + 1], (0, 0, 255), 2)
def mouse_callback(event, x, y, flags, param):
"""回调函数,用来处理鼠标事件"""
global ix, iy, drawing, image
# 鼠标左键按下时
if event == cv2.EVENT_LBUTTONDOWN:
drawing = True # 开始绘制
ix, iy = x, y # 记录按下位置
# image = 255 * np.ones(shape=(500, 500, 3), dtype=np.uint8) # 在按下时在图像上清除以前的内容
# 鼠标移动时
elif event == cv2.EVENT_MOUSEMOVE:
if drawing: # 如果正在绘制
# 在按下位置和当前鼠标位置之间画线
temp_image = image.copy() # 防止直接修改图像
cv2.line(temp_image, (ix, iy), (x, y), (0, 0, 255), 2) # 红色线条
cv2.imshow("Mouse Event", temp_image) # 显示更新后的图像
# 鼠标左键释放时
elif event == cv2.EVENT_LBUTTONUP:
drawing = False # 结束绘制
# 在最终位置绘制线条
cv2.line(image, (ix, iy), (x, y), (0, 0, 255), 2) # 红色线条
cv2.imshow("Mouse Event", image) # 显示最终图像
if __name__ == "__main__":
# (1)初始化变量
drawing = False # 是否在绘制线条
ix, iy = -1, -1 # 鼠标按下位置
image = 255 * np.ones(shape=(200, 500, 3), dtype=np.uint8) # 创建一个空白的窗口
love_path(image) # 初始化一个图形
cv2.imshow("Mouse Event", image) # 显示图像(当做一个画布Canvas)
# (2)设置鼠标事件回调
cv2.setMouseCallback("Mouse Event", mouse_callback)
cv2.waitKey(0)
cv2.destroyAllWindows()
# -*- coding: utf-8 -*-
# 作者: 胖墩会武术
# 日期: 1994-08-21
# OpenCV图像处理: https://blog.csdn.net/shinuone/article/details/126022763
(2)鼠标 - 绘制矩形
"""#########################################################################
# 功能:矩形涂鸦画板
# 描述:鼠标左键按下拖动绘制矩形,鼠标左键弹起时完成绘制
# (1)按' c '键清空画板
# (2)按' ESC '键退出
#########################################################################"""
import numpy as np
import cv2
from random import randint
class Painter:
def __init__(self) -> None:
self.mouse_is_pressed = False
self.last_pos = (-1, -1)
self.width = 300
self.height = 512
self.img = np.zeros((self.width, self.height, 3), np.uint8)
self.window_name = 'painter'
self.color = None
def run(self):
print('画板,拖动鼠标绘制矩形框,按ESC退出,按c键清空画板')
cv2.namedWindow(self.window_name)
cv2.setMouseCallback(self.window_name, lambda event, x, y, flags, param: self.on_draw(event, x, y, flags, param))
while True:
cv2.imshow(self.window_name, self.img)
k = cv2.waitKey(1) & 0xFF
if k == ord('c'): # 按' c '键清空画板
self.clean() # (调用自定义函数):清除画板
elif k == 27: # 按' ESC '键退出
break
cv2.destroyAllWindows()
def on_draw(self, event, x, y, flags, param):
# TODO(You): 请正确实现画板事件响应,完成功能
# 触发左键按下 -> 触发鼠标移动 -> 开始画矩形 -> 触发左键抬起 -> 终止画矩形
pos = (x, y) # 鼠标按下的位置坐标
if event == cv2.EVENT_LBUTTONDOWN: # 触发左键按下
self.mouse_is_pressed = True
self.last_pos = pos
elif event == cv2.EVENT_MOUSEMOVE: # 触发鼠标移动
if self.mouse_is_pressed == True: # 判断鼠标是否按下
self.begin_draw_rectangle(self.last_pos, pos) # (调用自定义函数):开始画矩形
elif event == cv2.EVENT_LBUTTONUP: # 触发左键抬起
self.end_draw_rectangle(self.last_pos, pos) # (调用自定义函数):终止画矩形
self.mouse_is_pressed = False
def clean(self):
cv2.rectangle(self.img, (0, 0), (self.height, self.width), (0, 0, 0), -1)
def begin_draw_rectangle(self, pos1, pos2):
if self.color is None: # 设置颜色(每个矩形的颜色都随机)
self.color = (randint(0, 256), randint(0, 256), randint(0, 256)) # 随机生成三通道颜色
cv2.rectangle(self.img, pos1, pos2, self.color, -1)
def end_draw_rectangle(self, pos1, pos2):
self.color = None
if __name__ == '__main__':
p = Painter() # 类的实例化
p.run() # 调用类函数
# -*- coding: utf-8 -*-
# 作者: 胖墩会武术
# 日期: 1994-08-21
# OpenCV图像处理: https://blog.csdn.net/shinuone/article/details/126022763
1.4.4、滑动条 —— cv2.createTrackbar()、cv2.getTrackbarPos()
import cv2
import numpy as np
def on_trackbar(val):
"""回调函数,用来处理滑动条变化事件"""
current_value = cv2.getTrackbarPos("Brightness", "Trackbar Example") # 获取当前滑动条的值
print(f"当前滑动条值:{current_value}")
if __name__ == '__main__':
image = np.zeros((200, 400, 3), dtype=np.uint8)
cv2.imshow("Trackbar Example", image) # 创建窗口
cv2.createTrackbar("Brightness", "Trackbar Example", 0, 255, on_trackbar) # 创建滑动条
cv2.waitKey(0)
cv2.destroyAllWindows()
"""#########################################################################
# 功能说明:创建一个滑动条控件,放置在指定的窗口中,并绑定一个回调函数。———— 当滑动条的值变化时,回调函数会被触发。
# 函数说明: cv2.createTrackbar(Track_name, img, min, max, TrackbarCallback)
# 输入参数:
# Track_name: 滑动条的名称,必须是一个字符串
# img: 滑动条所在的窗口或画布
# min: 滑动条的最小值
# max: 滑动条的最大值
# TrackbarCallback:当滑动条值变化时,被调用的回调函数。此函数必须接受一个参数,表示滑动条当前的值。
#########################################################################"""
"""#########################################################################
# 功能说明:获取滑动条的值
# 函数说明:value = cv2.getTrackbarPos(Track_name, img)
# 输入参数:
# Track_name: 滑动条的名称
# img: 滑动条所在的窗口或画布
# 输出参数:
# 当前滑动条所在位置的数值(整数)
#########################################################################"""
# -*- coding: utf-8 -*-
# 作者: 胖墩会武术
# 日期: 1994-08-21
# OpenCV图像处理: https://blog.csdn.net/shinuone/article/details/126022763
(1)动态二值化图像
import cv2
image = cv2.imread('image.jpg')
cv2.imshow('image', image) # 创建窗口
cv2.createTrackbar('threshold', 'image', 0, 255, lambda x: None) # 创建阈值滑动条
while True:
threshold_value = cv2.getTrackbarPos('threshold', 'image') # 获取滑动条的阈值
threshold_image = cv2.threshold(image, threshold_value, 255, cv2.THRESH_BINARY)[1] # 阈值图像
cv2.imshow('image', threshold_image)
if cv2.waitKey(1) == 27: # Esc退出
break
cv2.destroyAllWindows()
# -*- coding: utf-8 -*-
# 作者: 胖墩会武术
# 日期: 1994-08-21
# OpenCV图像处理: https://blog.csdn.net/shinuone/article/details/126022763
(2)RGB调色板
"""#########################################################################
# (1)滑动条控制R、G、B的值
# (2)开关按钮switch
# 0:画板清除(全黑)
# 1:画板调色(显示当前RGB对应的颜色)
# 2:图形调色(先设置线条颜色,然后绘制图形。注意:选择不一样的线条颜色和画板背景颜色)
#########################################################################"""
import cv2
import numpy as np
def nothing(x):
pass
def mouse_callback(event, x, y, flags, param):
if flags == cv2.EVENT_FLAG_LBUTTON and event == cv2.EVENT_MOUSEMOVE:
cv2.circle(image, (x, y), 1, [b, g, r], 2)
if __name__ == '__main__':
image = np.zeros((200, 400, 3), np.uint8)
cv2.namedWindow('image', cv2.WINDOW_NORMAL) # 设置窗口名称
cv2.createTrackbar('R', 'image', 0, 255, nothing)
cv2.createTrackbar('G', 'image', 0, 255, nothing)
cv2.createTrackbar('B', 'image', 0, 255, nothing)
switch = 'state'
cv2.createTrackbar(switch, 'image', 0, 2, nothing)
while True:
cv2.imshow('image', image) # 创建窗口
key = cv2.waitKey(1)
if key == ord('q'):
break
r = cv2.getTrackbarPos('R', 'image')
g = cv2.getTrackbarPos('G', 'image')
b = cv2.getTrackbarPos('B', 'image')
state = cv2.getTrackbarPos(switch, 'image')
if state == 0: # 画板清除
image[:] = 0
elif state == 1: # 画板调色
image[:] = [b, g, r]
elif state == 2: # 图形调色
cv2.setMouseCallback('image', mouse_callback)
cv2.destroyAllWindows()
# -*- coding: utf-8 -*-
# 作者: 胖墩会武术
# 日期: 1994-08-21
# OpenCV图像处理: https://blog.csdn.net/shinuone/article/details/126022763
1.5、绘制形状
1.5.1、直线 + 箭头线 —— cv2.line() + cv2.arrowedLine()
import numpy as np
import cv2 # opencv读取图像默认为BGR
import matplotlib.pyplot as plt # matplotlib显示图像默认为RGB
image = np.zeros((400, 400, 3), dtype=np.uint8)
"""############################################################"""
image_line = image.copy()
image_arrowedLine = image.copy()
cv2.line(img=image_line, pt1=(50, 50), pt2=(350, 350), color=(0, 255, 0), thickness=3)
cv2.arrowedLine(img=image_arrowedLine, pt1=(50, 50), pt2=(350, 350), color=(0, 255, 0), thickness=3, tipLength=0.1)
"""############################################################"""
# 指定旋转中心和迭代角度,每隔一个角度绘制1条直线或箭头线。
center = (200, 200) # 旋转中心
length = 100 # 线段长度
angle_step = 25 # 角度步长
image_rotated_lines = image.copy()
image_rotated_arrowedLine = image.copy()
for angle in range(0, 240, angle_step):
radian = np.deg2rad(angle) # 将角度转换为弧度
end_x = int(center[0] + length * np.cos(radian)) # 计算终点坐标x
end_y = int(center[1] + length * np.sin(radian)) # 计算终点坐标y
cv2.line(image_rotated_lines, center, (end_x, end_y), (0, 255, 0), 2) # 绘制旋转直线
cv2.arrowedLine(image_rotated_arrowedLine, center, (end_x, end_y), (0, 255, 0), 2) # 绘制旋转直线
"""############################################################"""
plt.subplot(141), plt.imshow(cv2.cvtColor(image_line, cv2.COLOR_BGR2RGB)), plt.title('image_line')
plt.subplot(142), plt.imshow(cv2.cvtColor(image_arrowedLine, cv2.COLOR_BGR2RGB)), plt.title('image_arrowedLine')
plt.subplot(143), plt.imshow(cv2.cvtColor(image_rotated_lines, cv2.COLOR_BGR2RGB)), plt.title('image_rotated_lines')
plt.subplot(144), plt.imshow(cv2.cvtColor(image_rotated_arrowedLine, cv2.COLOR_BGR2RGB)), plt.title('image_rotated_arrowedLine')
plt.show()
"""#############################################################################################
# 函数功能:在图像上,绘制直线
# 函数说明:cv2.line(img, pt1, pt2, color, thickness=None, lineType=None, shift=None)
# 参数说明:
# img:待绘制直线的图像。
# pt1:直线的起始点坐标,格式为 (x, y)。
# pt2:直线的终止点坐标,格式为 (x, y)。
# color:直线颜色,以 BGR 形式表示,如 (255, 0, 0) 表示蓝色。
# thickness:直线的粗细,默认为 1。
# lineType:线型,常用值包括:
# cv2.LINE_4:4 邻接连接线。
# cv2.LINE_8:8 邻接连接线(默认)。
# cv2.LINE_AA:抗锯齿线。
# shift:坐标点小数位精度(默认值为 0),当 shift>0 时,坐标点值被乘以 2^shift。
# 返回值:
# 无返回值,函数直接修改输入图像。
#############################################################################################"""
"""#############################################################################################
# 函数功能:在图像上,绘制箭头线
# 函数说明:cv2.arrowedLine(img, pt1, pt2, color, thickness=None, line_type=None, shift=None, tipLength=None)
# 参数说明:
# img:待绘制箭头的图像。
# pt1:箭头的起始点坐标,格式为 (x, y)。
# pt2:箭头的终止点坐标,格式为 (x, y)。
# color:箭头颜色,以 BGR 形式表示,如 (255, 0, 0) 表示蓝色。
# thickness:箭头的粗细,默认为 1。
# line_type:线型,常用值包括:
# cv2.LINE_4:4 邻接连接线。
# cv2.LINE_8:8 邻接连接线(默认)。
# cv2.LINE_AA:抗锯齿线。
# shift:坐标点小数位精度(默认值为 0),当 shift>0 时,坐标点值被乘以 2^shift。
# tipLength:箭头头部相对于箭头长度的比例,默认值为 0.1。
# 返回值:
# 无返回值,函数直接修改输入图像。
#############################################################################################"""
# -*- coding: utf-8 -*-
# 作者: 胖墩会武术
# 日期: 1994-08-21
# OpenCV图像处理: https://blog.csdn.net/shinuone/article/details/126022763
1.5.2、圆形 + 椭圆 —— cv2.circle() + cv2.ellipse()
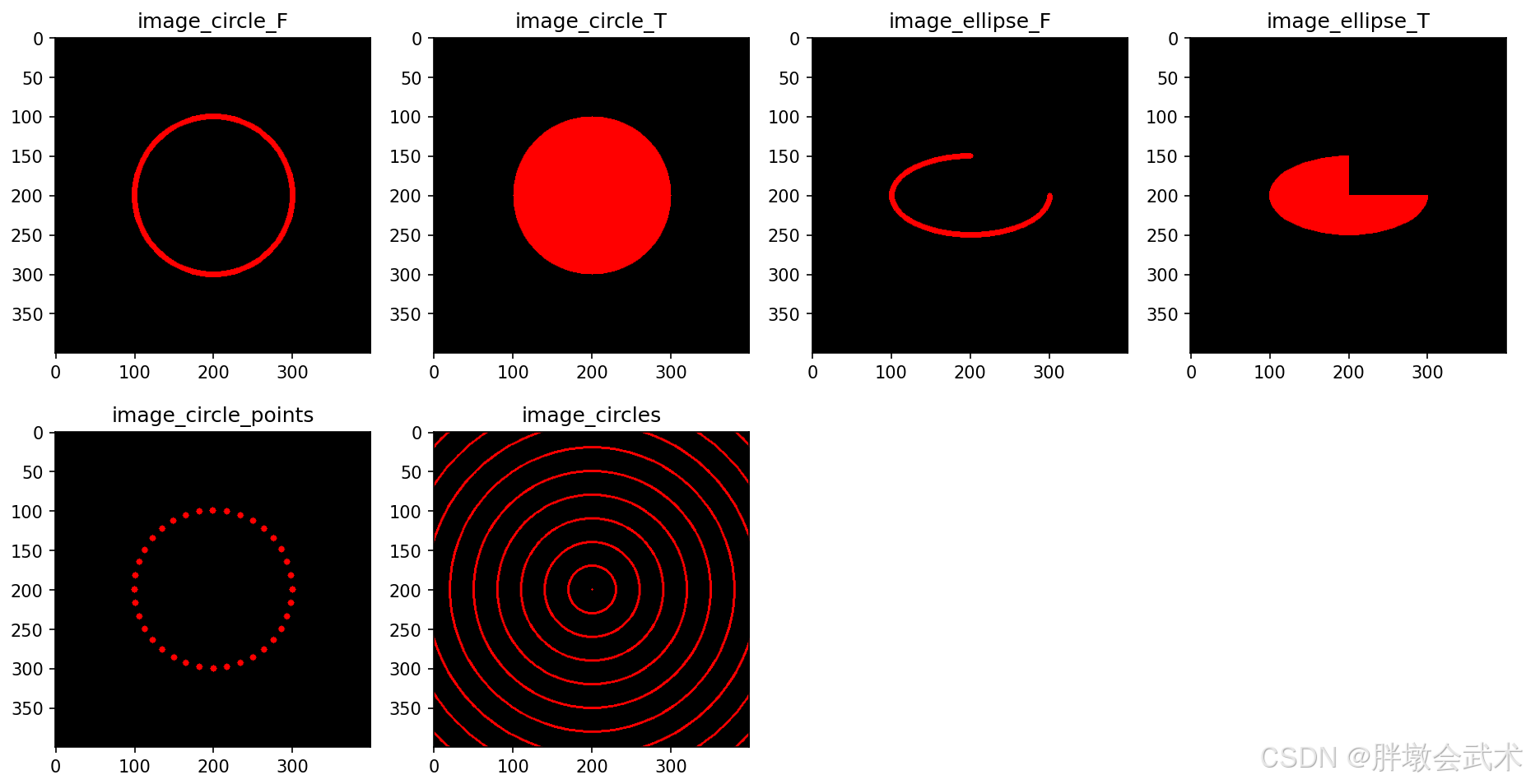
import numpy as np
import cv2 # opencv读取图像默认为BGR
import matplotlib.pyplot as plt # matplotlib显示图像默认为RGB
image = np.zeros((400, 400, 3), dtype=np.uint8)
"""############################################################"""
image_ellipse_T = image.copy() # 实心圆
image_ellipse_F = image.copy() # 空心圆
image_circle_T = image.copy() # 实心椭圆
image_circle_F = image.copy() # 空心椭圆
cv2.ellipse(img=image_ellipse_T, center=(200, 200), axes=(100, 50), angle=0, startAngle=0, endAngle=270, color=(0, 0, 255), thickness=-1)
cv2.ellipse(img=image_ellipse_F, center=(200, 200), axes=(100, 50), angle=0, startAngle=0, endAngle=270, color=(0, 0, 255), thickness=5)
cv2.circle(img=image_circle_T, center=(200, 200), radius=100, color=(0, 0, 255), thickness=-1)
cv2.circle(img=image_circle_F, center=(200, 200), radius=100, color=(0, 0, 255), thickness=5)
"""############################################################"""
image_circle_points = image.copy()
image_circles = image.copy()
# 绘制点图
center = (200, 200)
radius = 100
num_points = 36 # 边缘点数量
angle_step = 360 / num_points
for i in range(num_points):
angle = np.deg2rad(i * angle_step) # 将角度转换为弧度
x = int(center[0] + radius * np.cos(angle))
y = int(center[1] + radius * np.sin(angle))
cv2.circle(image_circle_points, (x, y), 4, (0, 0, 255), -1)
# 绘制同心圆
for r in range(0, 360, 30):
cv2.circle(image_circles, (200, 200), r, (0, 0, 255), 2)
"""############################################################"""
plt.subplot(241), plt.imshow(cv2.cvtColor(image_circle_F, cv2.COLOR_BGR2RGB)), plt.title('image_circle_F')
plt.subplot(242), plt.imshow(cv2.cvtColor(image_circle_T, cv2.COLOR_BGR2RGB)), plt.title('image_circle_T')
plt.subplot(243), plt.imshow(cv2.cvtColor(image_ellipse_F, cv2.COLOR_BGR2RGB)), plt.title('image_ellipse_F')
plt.subplot(244), plt.imshow(cv2.cvtColor(image_ellipse_T, cv2.COLOR_BGR2RGB)), plt.title('image_ellipse_T')
plt.subplot(245), plt.imshow(cv2.cvtColor(image_circle_points, cv2.COLOR_BGR2RGB)), plt.title('image_circle_points')
plt.subplot(246), plt.imshow(cv2.cvtColor(image_circles, cv2.COLOR_BGR2RGB)), plt.title('image_circles')
plt.show()
"""#############################################################################################
# 函数功能:在图像上,绘制圆形
# 函数说明:cv2.circle(img, center, radius, color, thickness=None, lineType=None, shift=None)
# 参数说明:
# img:待绘制圆形的图像。
# center:圆心坐标,格式为 (x, y)。
# radius:圆的半径,以像素为单位。
# color:圆的颜色,以 BGR 形式表示,如 (255, 0, 0) 表示蓝色。
# thickness:圆边界的粗细。默认值为 1;如果设置为 -1,则绘制填充的圆。
# lineType:线型,常用值包括:
# cv2.LINE_4:4 邻接连接线。
# cv2.LINE_8:8 邻接连接线(默认)。
# cv2.LINE_AA:抗锯齿线。
# shift:坐标点小数位精度(默认值为 0),当 shift>0 时,坐标点值被乘以 2^shift。
# 返回值:
# 无返回值,函数直接修改输入图像。
#############################################################################################"""
"""#############################################################################################
# 函数功能:在图像上,绘制椭圆或椭圆弧
# 函数说明:cv2.ellipse(img, center, axes, angle, startAngle, endAngle, color, thickness=None, lineType=None, shift=None)
# 参数说明:
# img:待绘制椭圆的图像。
# center:椭圆中心点坐标,格式为 (x, y)。
# axes:长轴和短轴的长度,格式为 (major_axis_length, minor_axis_length)。
# angle:椭圆的旋转角度,以度为单位。
# startAngle:椭圆弧的起始角度,以度为单位。
# endAngle:椭圆弧的终止角度,以度为单位。
# color:椭圆颜色,以 BGR 形式表示,如 (0, 255, 0) 表示绿色。
# thickness:椭圆边界的粗细,默认为 1;如果设置为 -1,则填充椭圆。
# lineType:线型,常用值包括:
# cv2.LINE_4:4 邻接连接线。
# cv2.LINE_8:8 邻接连接线(默认)。
# cv2.LINE_AA:抗锯齿线。
# shift:坐标点小数位精度(默认值为 0),当 shift>0 时,坐标点值被乘以 2^shift。
# 返回值:
# 无返回值,函数直接修改输入图像。
#############################################################################################"""
# -*- coding: utf-8 -*-
# 作者: 胖墩会武术
# 日期: 1994-08-21
# OpenCV图像处理: https://blog.csdn.net/shinuone/article/details/126022763
1.5.3、矩形 + 多边形 + 填充多边形 —— cv2.rectangle() + cv2.polylines() + cv2.fillPoly()
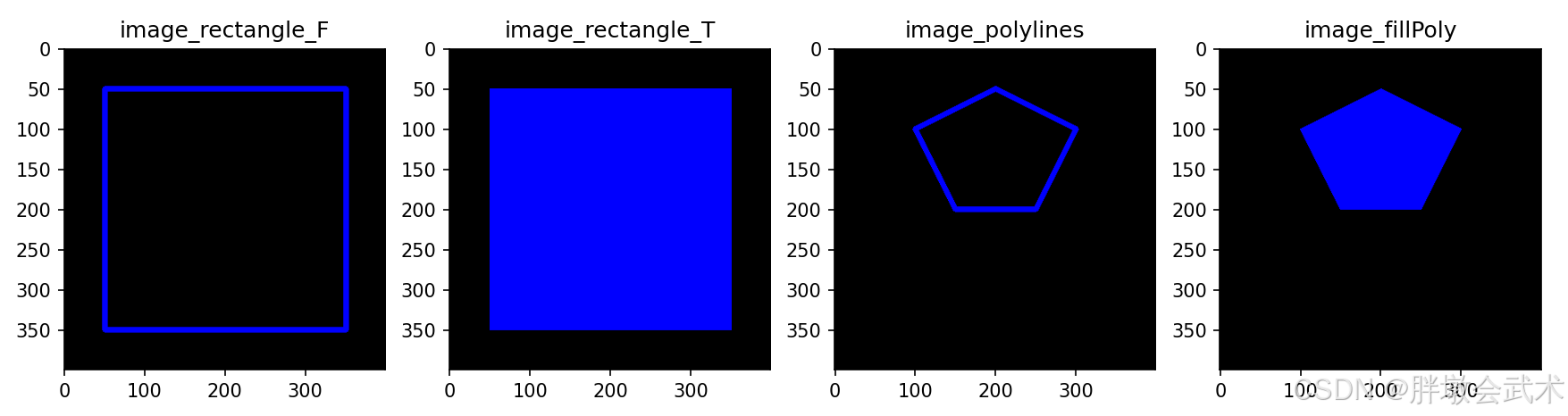
import numpy as np
import cv2 # opencv读取图像默认为BGR
import matplotlib.pyplot as plt # matplotlib显示图像默认为RGB
image = np.zeros((400, 400, 3), dtype=np.uint8)
"""############################################################"""
image_rectangle_F = image.copy() # 空心矩形
image_rectangle_T = image.copy() # 实心矩形
image_polylines = image.copy() # 实心多边形
image_fillPoly = image.copy() # 空心多边形
# pts = np.array([[100, 100], [200, 50], [300, 100]], np.int32) # 三边形
# pts = np.array([[100, 100], [200, 100], [300, 200], [200, 200]], np.int32) # 四边形
pts = np.array([[100, 100], [200, 50], [300, 100], [250, 200], [150, 200]], np.int32) # 五边形
pts = pts.reshape((-1, 1, 2)) # 调整数组形状
cv2.rectangle(img=image_rectangle_F, pt1=(50, 50), pt2=(350, 350), color=(255, 0, 0), thickness=5)
cv2.rectangle(img=image_rectangle_T, pt1=(50, 50), pt2=(350, 350), color=(255, 0, 0), thickness=-1)
cv2.polylines(img=image_polylines, pts=[pts], isClosed=True, color=(255, 0, 0), thickness=5)
cv2.fillPoly(img=image_fillPoly, pts=[pts], color=(255, 0, 0))
"""############################################################"""
plt.subplot(141), plt.imshow(cv2.cvtColor(image_rectangle_F, cv2.COLOR_BGR2RGB)), plt.title('image_rectangle_F')
plt.subplot(142), plt.imshow(cv2.cvtColor(image_rectangle_T, cv2.COLOR_BGR2RGB)), plt.title('image_rectangle_T')
plt.subplot(143), plt.imshow(cv2.cvtColor(image_polylines, cv2.COLOR_BGR2RGB)), plt.title('image_polylines')
plt.subplot(144), plt.imshow(cv2.cvtColor(image_fillPoly, cv2.COLOR_BGR2RGB)), plt.title('image_fillPoly')
plt.show()
"""#############################################################################################
# 函数功能:在图像上,绘制矩形
# 函数说明:cv2.rectangle(img, pt1, pt2, color, thickness=None, lineType=None, shift=None)
# 参数说明:
# img:待绘制矩形的图像。
# pt1:矩形的一个顶点,格式为 (x1, y1)。
# pt2:对角线上的另一个顶点,格式为 (x2, y2)。
# color:矩形边框颜色,以 BGR 形式表示,如 (0, 255, 0) 表示绿色。
# thickness:边框的粗细。默认值为 1;如果设置为 -1,则绘制填充的矩形。
# lineType:线型,常用值包括:
# cv2.LINE_4:4 邻接连接线。
# cv2.LINE_8:8 邻接连接线(默认)。
# cv2.LINE_AA:抗锯齿线。
# shift:坐标点小数位精度(默认值为 0),当 shift>0 时,坐标点值被乘以 2^shift。
# 返回值:
# 无返回值,函数直接修改输入图像。
#############################################################################################"""
"""#############################################################################################
# 函数功能:在图像上,绘制多边形
# 函数说明:cv2.polylines(img, pts, isClosed, color, thickness=None, lineType=None, shift=None)
# 参数说明:
# img:待绘制多边形的图像。
# pts:多边形顶点的列表或数组,每个顶点以 (x, y) 坐标表示。
# 需要使用 `np.array` 形式组织顶点,形状为 [1, 顶点数, 2]。
# isClosed:布尔值,指定多边形是否闭合。
# True 表示闭合;False 表示开放的折线。
# color:线条的颜色,以 BGR 形式表示,例如 (255, 0, 0) 表示蓝色。
# thickness:线条的粗细,默认值为 1。必须是一个非负整数。
# lineType:线型,常用值包括:
# cv2.LINE_4:4 邻接连接线。
# cv2.LINE_8:8 邻接连接线(默认)。
# cv2.LINE_AA:抗锯齿线。
# shift:坐标点的小数位精度(默认值为 0),当 shift>0 时,坐标值被乘以 2^shift。
# 返回值:
# 无返回值,函数直接修改输入图像。
#############################################################################################"""
"""#############################################################################################
# 函数功能:在图像上,填充多边形
# 函数说明:cv2.fillPoly(img, pts, color, mask=None, lineType=None, shift=None)
# 参数说明:
# img:待绘制的图像,通常为空白图像或已有图像。
# pts:多边形的顶点坐标。应为一个包含多边形顶点的数组或列表,格式为 [1, 顶点数, 2],
# 可以使用 `np.array` 创建。
# color:填充多边形的颜色。颜色采用 BGR 格式,示例:(255, 0, 0) 表示蓝色。
# mask:可选参数,指定一个掩膜图像,掩膜控制多边形的填充区域。默认值为 None。
# lineType:可选参数,指定绘制多边形边界时的线型,常用值有:
# cv2.LINE_4:4 邻接线,cv2.LINE_8:8 邻接线(默认),cv2.LINE_AA:抗锯齿线。
# shift:坐标的小数位精度,默认为 0。如果 shift > 0,坐标值将乘以 2^shift。
# 返回值:
# 无返回值。直接修改输入的图像。
#############################################################################################"""
# -*- coding: utf-8 -*-
# 作者: 胖墩会武术
# 日期: 1994-08-21
# OpenCV图像处理: https://blog.csdn.net/shinuone/article/details/126022763
1.5.4、添加文本(英文+中文) —— cv2.putText()
import numpy as np
import cv2 # opencv读取图像默认为BGR
import matplotlib.pyplot as plt # matplotlib显示图像默认为RGB
from PIL import ImageFont, ImageDraw, Image
image = np.zeros((400, 400, 3), dtype=np.uint8)
"""############################################################"""
image_putText_English = image.copy()
image_putText_Chinese = image.copy()
# OpenCV 默认不支持直接在 cv2.putText() 中添加中文文字,因为 cv2.putText() 无法处理 UTF-8 字符。
cv2.putText(img=image_putText_English, text='Hello OpenCV', org=(50, 200), fontFace=cv2.FONT_HERSHEY_SIMPLEX, fontScale=1, color=(255, 255, 255), thickness=2)
cv2.putText(img=image_putText_Chinese, text='你好 OpenCV', org=(50, 200), fontFace=cv2.FONT_HERSHEY_SIMPLEX, fontScale=1, color=(255, 255, 255), thickness=2)
"""############################################################"""
# 在图像上,使用PIL绘制文本(中文),然后将PIL图像转换回OpenCV图像。
pil_image = Image.fromarray(cv2.cvtColor(image, cv2.COLOR_BGR2RGB)) # 转PIL图像
draw = ImageDraw.Draw(pil_image) # 使用 PIL 创建一个可绘制的对象
font = ImageFont.truetype("simhei.ttf", 40) # 加载字体并指定字体大小(注意:要确保系统中有simhei.ttf字体)
draw.text(xy=(50, 200), text="你好 OpenCV", font=font, fill=(255, 255, 255)) # 绘制文本(中文)
image = cv2.cvtColor(np.array(pil_image), cv2.COLOR_RGB2BGR) # 转OpenCV图像
"""############################################################"""
plt.subplot(131), plt.imshow(cv2.cvtColor(image_putText_English, cv2.COLOR_BGR2RGB)), plt.title('image_putText_English')
plt.subplot(132), plt.imshow(cv2.cvtColor(image_putText_Chinese, cv2.COLOR_BGR2RGB)), plt.title('image_putText_Chinese(no)')
plt.subplot(133), plt.imshow(cv2.cvtColor(image, cv2.COLOR_BGR2RGB)), plt.title('image_putText_Chinese(yes)')
plt.show()
"""#############################################################################################
# 函数功能:在图像上,添加文本。
# 函数说明:cv2.putText(img, text, org, fontFace, fontScale, color, thickness=1, lineType=None, bottomLeftOrigin=False)
# 参数说明:
# img:待绘制文本的图像。
# text:要绘制的文本字符串。
# org:文本的左下角坐标。是一个二元组 (x, y),表示文本开始的位置。
# fontFace:字体类型。常用字体有:
# cv2.FONT_HERSHEY_SIMPLEX:标准无衬线字体
# cv2.FONT_HERSHEY_PLAIN:小号字体
# cv2.FONT_HERSHEY_DUPLEX:较为复杂的字体
# cv2.FONT_HERSHEY_COMPLEX:标准复杂字体
# cv2.FONT_HERSHEY_TRIPLEX:带有衬线的标准复杂字体
# cv2.FONT_ITALIC:斜体
# fontScale:字体大小,通常为浮动值。
# color:文本的颜色。格式为 (B, G, R)。
# thickness:文本线条的粗细,默认值为 1。
# lineType:文本的线型,常用值:
# cv2.LINE_4:4 邻接连接线。
# cv2.LINE_8:8 邻接连接线(默认)。
# cv2.LINE_AA:抗锯齿线。
# bottomLeftOrigin:布尔值。指定文本的坐标是否是以左下角为原点。默认为 False,即以左上角为原点。
# 返回值:
# 无返回值。该函数直接在输入的图像上绘制文本。
#############################################################################################"""
# -*- coding: utf-8 -*-
# 作者: 胖墩会武术
# 日期: 1994-08-21
# OpenCV图像处理: https://blog.csdn.net/shinuone/article/details/126022763
第二章、图像的高级操作
2.0、主程序判断:if __ name __ == ’ __ main __ '
在 Python 中,if __name__ == "__main__" 是一种常见的结构,用于判断脚本是直接运行,还是被其他脚本作为模块导入。这是 Python 中模块管理和代码组织的一种重要机制,能够帮助你控制代码的执行方式。
__name__和'__main__':是 Python 中的标准约定,使用这些特殊名称能保证代码的清晰性和一致性。如果你改变这些名称,虽然技术上是可能的,但会破坏 Python 的惯用规则,导致其他开发者理解和使用时的不便。
__name__:是 Python 内置的一个特殊变量,它表示当前模块的名称。
- (1)若当前 .py 文件是直接运行时,
__name__的值会被设置为'__main__'。- (2)若当前 .py 文件作为模块被导入到其他文件时,
__name__的值会被设置为模块名称(即文件名,不包括.py后缀)。- 双重重用性:在一个 .py 文件中,放置一些测试代码或示例代码,这些代码只有在脚本被直接执行时才会运行,而当该脚本作为模块被导入到其他脚本时,这些代码则不会被执行。
# module.py
def say_hello():
print("Hello from module!")
if __name__ == '__main__':
print("Module is being run directly")
say_hello()
else:
print("Module has been imported")
# main.py
import module
print("Main script is running")
- 若执行 module.py,此时
__name__ == '__main__',执行结果如下:
Module is being run directlyHello from module!- 若执行 main.py,此时
__name__ == 'module',执行结果如下:
Module has been importedMain script is running
2.1、通道分离 + 通道合并 —— cv2.split() + cv.merge()
(1)图像分割得到三色图(BGR)
(2)将分割的三色图还原为彩色图
(3)保留R通道 + 保留G通道 + 保留B通道

import cv2 # opencv读取图像默认为BGR
import matplotlib.pyplot as plt # matplotlib显示图像默认为RGB
image = cv2.imread(r'F:\py\image.jpg')
b, g, r = cv2.split(image) # 图像分割
image = cv2.merge((b, g, r)) # 图像合并
################################################
# 只保留红色(R)单通道(G and B通道全部置0即可)
cur_img_R = image.copy() # 复制原图,避免改变原图
cur_img_R[:, :, 0] = 0
cur_img_R[:, :, 1] = 0
# 只保留绿色(G)单通道(R and B通道全部置0即可)
cur_img_G = image.copy() # 复制原图,避免改变原图
cur_img_G[:, :, 0] = 0
cur_img_G[:, :, 2] = 0
# 只保留蓝色(B)单通道(R and G通道全部置0即可)
cur_img_B = image.copy() # 复制原图,避免改变原图
cur_img_B[:, :, 1] = 0
cur_img_B[:, :, 2] = 0
################################################
plt.subplot(131), plt.imshow(cur_img_B), plt.title('Red')
plt.subplot(132), plt.imshow(cur_img_G), plt.title('Green')
plt.subplot(133), plt.imshow(cur_img_R), plt.title('Blue')
plt.show()
"""#######################################################################
# 函数功能:用于将多通道图像分离成单通道图像。 ———— 分割后的单通道图像都为灰度图且大小相同。
# 函数说明:b, g, r = channels = cv2.split(src)
# 参数说明:
# src: 输入的多通道图像。
# 返回参数:
# channels: 包含各个通道单独图像的列表。列表的长度等于输入图像的通道数。
#######################################################################"""
"""#######################################################################
# 函数功能:用于将单通道图像合并成多通道图像。 ———— 合并后的通道数是所有输入图像通道数的总和。
# 函数说明:dst = cv2.merge(channels)
# 参数说明:
# channels: 包含单通道图像的列表,列表的长度应该等于图像的通道数。
# 返回参数:
# dst: 合并后的多通道图像。
# 注意:输入图像的通道数可以不相同,但必须具有相同大小和数据类型
#######################################################################"""
# -*- coding: utf-8 -*-
# 作者: 胖墩会武术
# 日期: 1994-08-21
# OpenCV图像处理: https://blog.csdn.net/shinuone/article/details/126022763
2.2、边缘填充 —— cv2.copyMakeBorder()

import cv2 # opencv读取图像默认为BGR
import matplotlib.pyplot as plt # matplotlib显示图像默认为RGB
image = cv2.imread(r'image.jpg')
top_size, bottom_size, left_size, right_size = (50, 50, 50, 50) # 指定边缘(上下左右)需要填充的宽度
replicate = cv2.copyMakeBorder(image, top_size, bottom_size, left_size, right_size, borderType=cv2.BORDER_REPLICATE)
reflect = cv2.copyMakeBorder(image, top_size, bottom_size, left_size, right_size, borderType=cv2.BORDER_REFLECT)
reflect101 = cv2.copyMakeBorder(image, top_size, bottom_size, left_size, right_size, borderType=cv2.BORDER_REFLECT_101)
wrap = cv2.copyMakeBorder(image, top_size, bottom_size, left_size, right_size, borderType=cv2.BORDER_WRAP)
constant = cv2.copyMakeBorder(image, top_size, bottom_size, left_size, right_size, borderType=cv2.BORDER_CONSTANT, value=0)
plt.subplot(231), plt.imshow(image), plt.title('image_raw')
plt.subplot(232), plt.imshow(replicate), plt.title('BORDER_REPLICATE')
plt.subplot(233), plt.imshow(reflect), plt.title('BORDER_REFLECT')
plt.subplot(234), plt.imshow(reflect101), plt.title('BORDER_REFLECT_101')
plt.subplot(235), plt.imshow(wrap), plt.title('BORDER_WRAP')
plt.subplot(236), plt.imshow(constant), plt.title('BORDER_CONSTANT')
plt.show()
"""#####################################################################################################################
# 函数功能:用于在图像的边界周围添加边框。———— 可以在图像的四个边界上分别添加不同大小和类型的边框
# 函数说明:dst = cv2.copyMakeBorder(src, top, bottom, left, right, borderType, value=None)
# 参数说明:
# src: 输入的图像。
# top: 顶部边框的大小(以像素为单位)。
# bottom: 底部边框的大小(以像素为单位)。
# left: 左侧边框的大小(以像素为单位)。
# right: 右侧边框的大小(以像素为单位)。
# borderType:边框类型
# cv2.BORDER_CONSTANT:常数边框,使用 value 参数指定填充值。
# cv2.BORDER_REPLICATE:复制边框。
# cv2.BORDER_REFLECT:反射边框。
# cv2.BORDER_WRAP:包裹边框。
# value: 可选参数,用于指定常数边框的填充值。
#####################################################################################################################"""
# -*- coding: utf-8 -*-
# 作者: 胖墩会武术
# 日期: 1994-08-21
# OpenCV图像处理: https://blog.csdn.net/shinuone/article/details/126022763
2.3、图像融合 —— cv2.add() + cv2.addWeighted()
(1)图像截取
(2)图像加 / 减:常数
(3)图像加 / 减:另一个图像
(4)图像相加:cv2.add()

import cv2 # opencv读取图像默认为BGR
import matplotlib.pyplot as plt # matplotlib显示图像默认为RGB
img_cat = cv2.imread(r'picture\cat.jpg')
img_dog = cv2.imread(r'picture\dog.jpg')
print(img_cat.shape, img_dog.shape)
########################################
# 图像截取
cat_piece = img_cat[100:300, 0:200]
########################################
# 图像加/减一个常数 ———— 即图像的每个像素都加常数值
img_plus = img_cat - 50
########################################
# cv2.add():图像相加/相减 ———— 两个图像的尺寸要一样。
# numpy数组: 如果两个图像相加超过255,将自动减去255,然后得到剩下的值。相当于取余【% 256】
# cv2.add(): 如果两个图像相加超过255,则等于255,否则当前值保留不变;
img_cat = cv2.resize(img_cat, (400, 480))
img_dog = cv2.resize(img_dog, (400, 480))
print(img_cat.shape)
print(img_dog.shape)
res_add1 = img_cat + img_dog
res_add2 = cv2.add(img_cat, img_dog)
########################################
plt.subplot(231), plt.imshow(img_cat), plt.title('img_cat_resize')
plt.subplot(232), plt.imshow(img_dog), plt.title('img_dog_resize')
plt.subplot(233), plt.imshow(cat_piece), plt.title('cat_piece')
plt.subplot(234), plt.imshow(img_plus), plt.title('fig1 - 50')
plt.subplot(235), plt.imshow(res_add1), plt.title('fig1 + fig2')
plt.subplot(236), plt.imshow(res_add2), plt.title('cv2.add')
plt.show()
img_cat = cv2.resize(img_cat, (500, 414)) # 将图像裁剪到指定尺寸
img_dog = cv2.resize(img_dog, (500, 414)) # 将图像裁剪到指定尺寸
res = cv2.addWeighted(img_cat, 0.35, img_dog, 0.65, 2)
plt.imshow(res)
plt.show()
"""#####################################################################
# 图像融合:cv2.addWeighted(src1, alpha, src2, beta, gamma)
# 功能:将两张相同shape的图像按权重进行融合
# 输入参数 src1/src2 图像1与图像2
# alpha/beta 图像1与图像2对应的权重(融合后的图像偏向于权重高的一边)
# gamma 相当于(y=a*x+b)中的截距。用于调节亮度
#
# 计算公式:dst = src1 * alpha + src2 * beta + gamma
#####################################################################"""
# -*- coding: utf-8 -*-
# 作者: 胖墩会武术
# 日期: 1994-08-21
# OpenCV图像处理: https://blog.csdn.net/shinuone/article/details/126022763
2.4、对比度和亮度调整 —— cv2.convertScaleAbs()

import cv2 # opencv读取图像默认为BGR
import matplotlib.pyplot as plt # matplotlib显示图像默认为RGB
image = cv2.imread(r'image.jpg')
output_gray = cv2.convertScaleAbs(image[:, :, 0], alpha=1.5, beta=-50) # 通过调整 alpha 和 beta 来控制图像的对比度和亮度。
output_color = cv2.convertScaleAbs(image, alpha=1.5, beta=50) # 通过调整 alpha 和 beta 来控制图像的对比度和亮度。
plt.subplot(2, 2, 1), plt.imshow(image[:, :, 0], cmap='gray'), plt.title('gray'), plt.axis('off')
plt.subplot(2, 2, 2), plt.imshow(output_gray, cmap='gray'), plt.title('gray + convertScaleAbs'), plt.axis('off')
plt.subplot(2, 2, 3), plt.imshow(image), plt.title('color'), plt.axis('off')
plt.subplot(2, 2, 4), plt.imshow(output_color), plt.title('color + convertScaleAbs'), plt.axis('off')
plt.show()
"""#############################################################################################
# 函数功能:用于对图像像素值按比例缩放(scale)和绝对值计算(abs),并将结果转换为 8 位无符号整数(uint8)。
# 函数说明:result = cv2.convertScaleAbs(src, alpha=1.0, beta=0.0)
# 参数说明:
# src:输入数组,可以是任意维度的 NumPy 数组
# alpha:(可选)缩放系数。控制图像的亮度调整。
# beta:(可选)偏移量。控制图像的对比度调整。若为正值,则所有像素都将向上平移。
# 返回值:
# 返回一个缩放和取绝对值后的 8 位无符号整数数组。
#############################################################################################"""
# 注意事项:常用于将浮点类型或高精度类型的图像转换为 8 位无符号图像。
""" (1)计算公式: output = abs(src * alpha + beta)计算。"""
# (2)绝对值处理:对每个像素进行绝对值计算(因此,不适用于边缘检测等等)
""" (3)像素值范围限制:若像素值不在(0-255)范围内,则截断。即:大于255则为255,小于0则为0。"""
# (4)保持像素范围的一致性:使用 alpha 和 beta,将图像缩放到 uint8 的范围内。
# 如:图像的数据类型为float32,像素值范围为[-1.0, 1.0],需要先将图像数据缩放到[0, 255]。
# (5)数据类型:
# 只支持的数据类型:uint8、int16、float32、float64
# 不支持的数据类型:int32、int64,需要先进行数据类型转换。
# (6)只支持2D图像
# (7)支持单通道和多通道:当处理多通道图像时,它会分别对每个通道执行缩放、取绝对值和类型转换操作。
#############################################################################################
# -*- coding: utf-8 -*-
# 作者: 胖墩会武术
# 日期: 1994-08-21
# OpenCV图像处理: https://blog.csdn.net/shinuone/article/details/126022763
2.5、色彩空间转换 —— cv2.cvtColor()

import cv2 # opencv读取图像默认为BGR
import matplotlib.pyplot as plt # matplotlib显示图像默认为RGB
img_BGR = cv2.imread(r'F:\py\image.jpg')
img_RGB = cv2.cvtColor(img_BGR, cv2.COLOR_BGR2RGB)
img_GRAY = cv2.cvtColor(img_BGR, cv2.COLOR_BGR2GRAY)
img_HSV = cv2.cvtColor(img_BGR, cv2.COLOR_BGR2HSV)
img_YcrCb = cv2.cvtColor(img_BGR, cv2.COLOR_BGR2YCrCb)
img_HLS = cv2.cvtColor(img_BGR, cv2.COLOR_BGR2HLS)
img_XYZ = cv2.cvtColor(img_BGR, cv2.COLOR_BGR2XYZ)
img_LAB = cv2.cvtColor(img_BGR, cv2.COLOR_BGR2LAB)
img_YUV = cv2.cvtColor(img_BGR, cv2.COLOR_BGR2YUV)
plt.subplot(3, 3, 1), plt.imshow(cv2.cvtColor(img_BGR, cv2.COLOR_BGR2RGB)), plt.axis('off'), plt.title('BGR')
plt.subplot(3, 3, 2), plt.imshow(cv2.cvtColor(img_RGB, cv2.COLOR_BGR2RGB)), plt.axis('off'), plt.title('RGB')
plt.subplot(3, 3, 3), plt.imshow(cv2.cvtColor(img_GRAY, cv2.COLOR_BGR2RGB)), plt.axis('off'), plt.title('GRAY')
plt.subplot(3, 3, 4), plt.imshow(cv2.cvtColor(img_HSV, cv2.COLOR_BGR2RGB)), plt.axis('off'), plt.title('HSV')
plt.subplot(3, 3, 5), plt.imshow(cv2.cvtColor(img_YcrCb, cv2.COLOR_BGR2RGB)), plt.axis('off'), plt.title('YcrCb')
plt.subplot(3, 3, 6), plt.imshow(cv2.cvtColor(img_HLS, cv2.COLOR_BGR2RGB)), plt.axis('off'), plt.title('HLS')
plt.subplot(3, 3, 7), plt.imshow(cv2.cvtColor(img_XYZ, cv2.COLOR_BGR2RGB)), plt.axis('off'), plt.title('XYZ')
plt.subplot(3, 3, 8), plt.imshow(cv2.cvtColor(img_LAB, cv2.COLOR_BGR2RGB)), plt.axis('off'), plt.title('LAB')
plt.subplot(3, 3, 9), plt.imshow(cv2.cvtColor(img_YUV, cv2.COLOR_BGR2RGB)), plt.axis('off'), plt.title('YUV')
plt.show()
"""######################################################################################
# 函数功能:用于在不同的颜色空间之间进行转换。
# 函数说明:dst = cv2.cvtColor(src, code, dstCn=None)
# 参数说明:
# src: 输入图像。
# code: 转换码,用于指定要执行的转换类型。
# cv2.COLOR_BGR2GRAY:将彩色图像转换为灰度图像。
# cv2.COLOR_GRAY2BGR:将灰度图像转换为彩色图像(使用灰度值复制通道)。
# cv2.COLOR_BGR2RGB:将 BGR 彩色图像转换为 RGB 彩色图像。
# cv2.COLOR_RGB2BGR:将 RGB 彩色图像转换为 BGR 彩色图像。
# 其他转换码请参考 OpenCV 文档。
# dstCn:可选参数,用于指定输出图像的通道数。
######################################################################################"""
# -*- coding: utf-8 -*-
# 作者: 胖墩会武术
# 日期: 1994-08-21
# OpenCV图像处理: https://blog.csdn.net/shinuone/article/details/126022763
2.6、阈值处理
(1)固定阈值分割:cv2.threshold()

import cv2 # opencv读取图像默认为BGR
import matplotlib.pyplot as plt # matplotlib显示图像默认为RGB
image_gray = cv2.imread('image.jpg', cv2.IMREAD_GRAYSCALE)
# 固定阈值分割
_, thresh1 = cv2.threshold(image_gray, 127, 255, cv2.THRESH_BINARY)
_, thresh2 = cv2.threshold(image_gray, 127, 255, cv2.THRESH_BINARY_INV)
_, thresh3 = cv2.threshold(image_gray, 127, 255, cv2.THRESH_TRUNC)
_, thresh4 = cv2.threshold(image_gray, 127, 255, cv2.THRESH_TOZERO)
_, thresh5 = cv2.threshold(image_gray, 127, 255, cv2.THRESH_TOZERO_INV)
titles = ['image_gray', 'BINARY', 'BINARY_INV', 'TRUNC', 'TOZERO', 'TOZERO_INV']
images = [image_gray, thresh1, thresh2, thresh3, thresh4, thresh5]
for ii in range(6):
plt.subplot(2, 3, ii + 1), plt.imshow(images[ii], 'gray')
plt.title(titles[ii])
plt.axis('off')
plt.show()
"""##########################################################################
# 函数功能:固定阈值分割 ———— 根据阈值将图像的像素分为两个类别:高于阈值的像素和低于阈值的像素。
# 函数说明:ret, dst = cv2.threshold(src, thresh, max_val, type)
# 输入参数:
# src: 输入灰度图像
# thresh: 阈值
# max_val: 阈值上限。通常为255(8-bit)。
# type: 二值化操作的类型,包含以下5种类型:
# (1) cv2.THRESH_BINARY 超过阈值部分取max_val(最大值),否则取0
# (2) cv2.THRESH_BINARY_INV THRESH_BINARY的反转
# (3) cv2.THRESH_TRUNC 大于阈值部分设为阈值,否则不变
# (4) cv2.THRESH_TOZERO 大于阈值部分不改变,否则设为0
# (5) cv2.THRESH_TOZERO_INV THRESH_TOZERO的反转
# 输出参数:
# ret 浮点数,表示最终使用的阈值。
# dst 经过阈值分割操作后的二值图像
##########################################################################"""
# -*- coding: utf-8 -*-
# 作者: 胖墩会武术
# 日期: 1994-08-21
# OpenCV图像处理: https://blog.csdn.net/shinuone/article/details/126022763
(2)自适应阈值分割:cv2.adaptiveThreshold()

import cv2 # opencv读取图像默认为BGR
import matplotlib.pyplot as plt # matplotlib显示图像默认为RGB
image_gray = cv2.imread('image.jpg', cv2.IMREAD_GRAYSCALE)
# 自适应阈值分割
thresh1 = cv2.adaptiveThreshold(image_gray, 255, cv2.ADAPTIVE_THRESH_MEAN_C, cv2.THRESH_BINARY, 11, 2)
thresh2 = cv2.adaptiveThreshold(image_gray, 255, cv2.ADAPTIVE_THRESH_MEAN_C, cv2.THRESH_BINARY_INV, 11, 2)
thresh3 = cv2.adaptiveThreshold(image_gray, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY, 11, 2)
thresh4 = cv2.adaptiveThreshold(image_gray, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY_INV, 11, 2)
titles = ['image_gray', 'mean + binary', 'mean + binary_inv', 'gray Image', 'gaussian + binary', 'gaussian + binary_inv']
images = [image_gray, thresh1, thresh2, image_gray, thresh3, thresh4]
for ii in range(6):
plt.subplot(2, 3, ii + 1), plt.imshow(images[ii], 'gray')
plt.title(titles[ii])
plt.axis('off')
plt.show()
"""##########################################################################
# 函数功能:自适应阈值分割 ———— 根据图像不同区域的像素值来自动确定阈值,从而实现更好的图像分割效果。
# 函数说明:adaptive_threshold = cv2.adaptiveThreshold(src, maxValue, adaptiveMethod, thresholdType, blockSize, C)
# 输入参数:
# src: 输入灰度图像。
# maxValue: 阈值上限。通常为255(8-bit)。
# adaptiveMethod: 自适应方法,包含以下2种:
# (1)cv2.ADAPTIVE_THRESH_MEAN_C(局部均值)
# (2)cv2.ADAPTIVE_THRESH_GAUSSIAN_C(局部高斯加权均值)
# thresholdType: 阈值类型。
# (1)cv2.THRESH_BINARY 超过阈值部分取max_val(最大值),否则取0
# (2)cv2.THRESH_BINARY_INV THRESH_BINARY的反转
# blockSize: 区域大小,用于计算局部阈值。通常是一个奇数,例如 3、5、7 等。
# C: 从均值中减去的常数,用于调整阈值的灵敏度。
# 输出参数:
# adaptive_threshold 自适应阈值
##########################################################################"""
# -*- coding: utf-8 -*-
# 作者: 胖墩会武术
# 日期: 1994-08-21
# OpenCV图像处理: https://blog.csdn.net/shinuone/article/details/126022763
(3)大津阈值分割:cv2.threshold() + cv2.THRESH_OTSU

import cv2 # opencv读取图像默认为BGR
import matplotlib.pyplot as plt # matplotlib显示图像默认为RGB
image_gray = cv2.imread('image.jpg', cv2.IMREAD_GRAYSCALE)
# 大津阈值分割
thresh1, otsu_image1 = cv2.threshold(image_gray, 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU)
thresh2, otsu_image2 = cv2.threshold(image_gray, 0, 255, cv2.THRESH_BINARY_INV + cv2.THRESH_OTSU)
thresh3, otsu_image3 = cv2.threshold(image_gray, 0, 255, cv2.THRESH_TRUNC + cv2.THRESH_OTSU)
thresh4, otsu_image4 = cv2.threshold(image_gray, 0, 255, cv2.THRESH_TOZERO + cv2.THRESH_OTSU)
thresh5, otsu_image5 = cv2.threshold(image_gray, 0, 255, cv2.THRESH_TOZERO_INV + cv2.THRESH_OTSU)
plt.subplot(2, 3, 1), plt.imshow(image_gray, cmap='gray'), plt.title('image_gray'), plt.axis('off')
plt.subplot(2, 3, 2), plt.imshow(otsu_image1, cmap='gray'), plt.title('cv2.THRESH_BINARY + cv2.THRESH_OTSU'), plt.axis('off')
plt.subplot(2, 3, 3), plt.imshow(otsu_image2, cmap='gray'), plt.title('cv2.THRESH_BINARY_INV + cv2.THRESH_OTSU'), plt.axis('off')
plt.subplot(2, 3, 4), plt.imshow(otsu_image3, cmap='gray'), plt.title('cv2.THRESH_TRUNC + cv2.THRESH_OTSU'), plt.axis('off')
plt.subplot(2, 3, 5), plt.imshow(otsu_image4, cmap='gray'), plt.title('cv2.THRESH_TOZERO + cv2.THRESH_OTSU'), plt.axis('off')
plt.subplot(2, 3, 6), plt.imshow(otsu_image5, cmap='gray'), plt.title('cv2.THRESH_TOZERO_INV + cv2.THRESH_OTSU'), plt.axis('off')
plt.show()
"""##########################################################################
# 大津阈值分割: thresh, otsu_image = cv2.threshold(image, 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU)
# 第一个参数是源图像
# 第二个参数是阈值(设置为0表示自动选择)
# 第三个参数是最大值
# 第四个参数是阈值类型(cv2.THRESH_BINARY + cv2.THRESH_OTSU)
##########################################################################"""
# -*- coding: utf-8 -*-
# 作者: 胖墩会武术
# 日期: 1994-08-21
# OpenCV图像处理: https://blog.csdn.net/shinuone/article/details/126022763
(4)大津阈值分割(底层代码实现,效果一致)
import cv2
import numpy as np
import matplotlib.pyplot as plt
def otsu_threshold(gray_image):
# (2)计算直方图
hist = cv2.calcHist([gray_image], [0], None, [256], [0, 256]).ravel() # ravel()转换为一维数组
# (3)计算类间方差
total_pixels = gray_image.size # 获取图像的像素数量
current_max = 0 # 最大类间方差
threshold = 0 # 最大类间方差对应的阈值
total_sigma = [] # 用于存储每个阈值对应的类间方差
for t in range(256):
# 计算类权重
w0 = np.sum(hist[:t + 1]) # 类1的权重(前景): 所有灰度级 <= t 的像素数量
w1 = total_pixels - w0 # 类2的权重(背景): 所有灰度级 > t 的像素数量
# 如果权重为0,则跳过此阈值。
if w0 == 0 or w1 == 0:
continue
# 计算类间方差
m0 = np.sum(np.arange(t + 1) * hist[:t + 1]) / w0 # 类1的加权平均灰度值(前景): 灰度级值乘以该灰度级的像素数
m1 = np.sum(np.arange(t + 1, 256) * hist[t + 1:]) / w1 # 类2的加权平均灰度值(背景): 灰度级值乘以该灰度级的像素数量
sigma = w0 * w1 * (m0 - m1) ** 2 # 类间方差的公式计算
total_sigma.append(sigma) # 将当前的类间方差添加到列表中
# 找到最大类间方差及对应的阈值
if sigma > current_max:
current_max = sigma
threshold = t
plt.subplot(1, 2, 1), plt.plot(hist), plt.title('Histogram'), plt.xlabel('Gray Level'), plt.ylabel('Number of Pixels')
plt.subplot(1, 2, 2), plt.plot(total_sigma), plt.title('Between-Class Variance'), plt.xlabel('Threshold'), plt.ylabel('Variance')
plt.axvline(x=threshold, color='r', linestyle='--', label=f'Threshold: {threshold}')
plt.legend()
plt.show()
return threshold
"""函数功能:在图像的灰度直方图中,寻找一个阈值,使得图像能够分为两个类(前景和背景),并且这两个类之间的类间方差最大。
(1)适用于双峰直方图:在直方图中,图像的灰度分布呈现出两个明显的峰值,通常代表图像中存在两类明显的对象:前景和背景
(2)适用于目标与背景面积相差不大、图像亮度均匀的情况
(3)不受亮度影响:该算法对图像的亮度变化不敏感,能够在不同亮度条件下保持较好的分割效果。
(1)对噪声敏感:当图像中存在大量噪声时,OSTU算法的分割效果会受到影响,容易导致误判。
(2)不适用非双峰直方图:若为单峰,则失效,可能旋转直方图的边缘值作为阈值。
若为多峰,则效果下降,因为多个类可能导致类间方差不够明显。
(3)对小目标分割效果差:在目标与背景灰度差异不明显或目标较小的情况下,OSTU算法可能会产生误判,导致大块白色区域的出现。
备注:OpenCV提供函数支持8bit、16bit等数据类型
"""
if __name__ == '__main__':
# (1)读取图像并转换为灰度图
image = cv2.imread(r"image.jpg", cv2.IMREAD_GRAYSCALE)
# 大津阈值
threshold = otsu_threshold(image) # (自定义)大津阈值
threshold_value1, threshold_image1 = cv2.threshold(image, threshold, 255, cv2.THRESH_BINARY) # 固定阈值
threshold_value2, threshold_image2 = cv2.threshold(image, 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU) # 大津阈值
print(f"threshold={threshold:.2f}, threshold_value1={threshold_value1:.2f}, threshold_value2={threshold_value2:.2f}")
# 显示结果
plt.figure(figsize=(6, 6))
plt.subplot(1, 2, 1), plt.imshow(threshold_image1, cmap='gray'), plt.axis('off')
plt.subplot(1, 2, 2), plt.imshow(threshold_image2, cmap='gray'), plt.axis('off')
plt.show()
2.7、滤波器
(1)图像滤波(方框 + 均值 + 高斯 + 中值) —— cv2.blur() + cv2.boxFilter() + cv2.GaussianBlur() + cv2.medianBlur()

| 滤波方法 | 适用的噪声类型 | 特点与效果 |
|---|---|---|
| 方框滤波 | 随机噪声、均匀噪声 | 处理效果与均值滤波相似,但可能产生较大的边缘效应 |
| 均值滤波 | 均匀分布的随机噪声(轻度 - 盐和胡椒噪声) | 平滑图像,但会模糊边缘和细节,适用于去除轻度噪声 |
| 高斯滤波 | 高斯噪声 | 平滑图像,去除高斯噪声,较好地保留边缘信息 |
| 中值滤波 | 尖峰 - 盐和胡椒噪声 | 不会模糊边缘,能够去除极端的噪声,保留边缘和细节 |
import numpy as np
import cv2 # opencv读取图像默认为BGR
import matplotlib.pyplot as plt # matplotlib显示图像默认为RGB
# image = cv2.imread(r'image.jpg')
image = np.zeros((50, 50, 3), dtype=np.uint8)
cv2.rectangle(image, (5, 5), (45, 45), (255, 255, 255), -1) # 白色矩形
cv2.circle(image, (25, 25), 15, (0, 255, 0), -1) # 绿色圆形
image_box_T = cv2.boxFilter(src=image, ddepth=-1, ksize=(3, 3), normalize=True)
image_box_F = cv2.boxFilter(src=image, ddepth=-1, ksize=(3, 3), normalize=False)
image_blur = cv2.blur(src=image, ksize=(3, 3))
image_gaussian = cv2.GaussianBlur(image, (5, 5), 1)
image_median = cv2.medianBlur(image, 5)
plt.subplot(2, 3, 1), plt.imshow(image), plt.title('image'), plt.axis('off')
plt.subplot(2, 3, 2), plt.imshow(image_box_T), plt.title('image_box_T'), plt.axis('off')
plt.subplot(2, 3, 3), plt.imshow(image_box_F), plt.title('image_box_F'), plt.axis('off')
plt.subplot(2, 3, 4), plt.imshow(image_blur), plt.title('image_blur'), plt.axis('off')
plt.subplot(2, 3, 5), plt.imshow(image_gaussian), plt.title('image_gaussian'), plt.axis('off')
plt.subplot(2, 3, 6), plt.imshow(image_median), plt.title('image_median'), plt.axis('off')
plt.show()
# 方框与均值的区别:滤波核的计算方式和是否进行归一化处理(如上图,方框+归一化=均值滤波)。
"""######################################################################################
# 函数功能:方框滤波 ———— 在滑动窗口内,计算所有像素的均值,来替代窗口中心的像素值
# 函数说明:filtered_image = cv2.boxFilter(src, ddepth, ksize, normalize=True)
# 参数说明:
# src: 输入的图像,数据类型为 uint8 或 float32。
# ddepth: 输出图像的深度,通常为 -1 表示与输入图像相同。
# ksize: 滤波核的大小,表示每个方向的滤波器窗口的大小。通常为一个二元组 (width, height)。
# normalize:一个布尔值,用于指定是否应该对结果进行归一化。如果设置为 True,则对结果进行归一化。
#
# 作用:类似于均值滤波,方框滤波也适用于去除均匀噪声和随机噪声。
######################################################################################"""
"""######################################################################################
# 函数功能:均值滤波 ———— 在滑动窗口内,计算所有像素的均值,来替代窗口中心的像素值
# 函数说明:blurred_image = cv2.blur(src, ksize)
# 参数说明:
# src: 输入的图像。
# ksize: 滤波核的大小,表示每个方向的滤波器窗口的大小。通常为一个二元组 (width, height)。
# 若ksize 的宽度和高度都是奇数,则使用归一化的均值滤波核。
# 若其中一个是偶数, 则生成的核不会归一化,且会产生较少的模糊效果。
#
# 作用:去除均匀噪声,尤其是均匀分布的随机噪声(即 “盐和胡椒噪声” 的较轻版本)。
######################################################################################"""
"""######################################################################################
# 函数功能:高斯滤波 ———— 使用高斯函数对图像进行卷积操作,以降低图像中的噪声并平滑图像
# 函数说明:blurred_image = cv2.GaussianBlur(src, ksize, sigmaX, sigmaY=0, borderType=cv2.BORDER_DEFAULT)
# 参数说明:
# src: 输入的图像。
# ksize: 高斯核的大小,通常为一个二元组 (width, height)。它表示高斯核的宽度和高度,必须为奇数。如果设置为 (0, 0),则根据 sigmaX 和 sigmaY 自动计算核的大小。
# sigmaX: X 方向的高斯核标准差。
# sigmaY: Y 方向的高斯核标准差。如果设置为 0,则默认与 sigmaX 相同。
# sigma 决定了高斯核中各像素点的权重,sigma 越大,远离中心的像素权重越高。
# sigma 越大,高斯函数越平缓,滤波器覆盖范围更广,图像更平滑。
# sigma 越小,高斯函数越陡峭,滤波器覆盖范围更窄,图像细节保留更多。
# borderType:可选参数,表示边界填充方式。默认值为 cv2.BORDER_DEFAULT。
#
# 作用:去除高斯噪声,即具有正态分布的噪声。
######################################################################################"""
"""######################################################################################
# 函数功能:中值滤波 ———— 在滑动窗口内,排序所有像素并取中位数对应的像素值,来替代窗口中所有像素的像素值。
# 函数说明:blurred_image = cv2.medianBlur(src, ksize)
# 参数说明:
# src: 输入的图像。
# ksize: 滤波核的大小,通常为一个奇数。它表示每个方向的滤波器窗口的大小。
#
# 作用:去除盐和胡椒噪声,即图像中像素值突变的情况(黑点和白点的噪声)。
######################################################################################"""
# -*- coding: utf-8 -*-
# 作者: 胖墩会武术
# 日期: 1994-08-21
# OpenCV图像处理: https://blog.csdn.net/shinuone/article/details/126022763
(2)图像锐化(Sharpen) —— cv2.filter2D()
图像锐化的本质:增强边缘信息,即放大像素与周围像素的差异。卷积核的作用是计算中心像素与周围像素的加权和,并用该值替代中心像素的原始值。
- (负数权重)用于去掉边缘的像素值:在锐化滤波器中,周围像素通常采用负数(例如 -1),表示抑制背景或提取边缘。
- (正数权重)用于保留并增强中心像素:中心值代表中心像素的权重增大,用于增强当前像素,使其更突出。
- (归一化)用于保持图像的整体亮度不变:整个核的和应接近 1,以免亮度严重偏移。
import numpy as np
import cv2 # opencv读取图像默认为BGR
import matplotlib.pyplot as plt # matplotlib显示图像默认为RGB
# image = cv2.imread(r"F:\py\image.jpg")
# import tifffile
# image = tifffile.imread(r"F:\py\image.tif")
sharpen_kernel3 = np.array([[0, -0.5, 0],
[-0.5, 3, -0.5],
[0, -0.5, 0]]) # 较弱-锐化核
sharpen_kernel5 = np.array([[0, -1, 0],
[-1, 5, -1],
[0, -1, 0]]) # 正常-锐化核
sharpen_kernel9 = np.array([[-1, -1, -1],
[-1, 9, -1],
[-1, -1, -1]]) # 更强-锐化核
sharpened_image3 = cv2.filter2D(image, -1, sharpen_kernel3)
sharpened_image5 = cv2.filter2D(image, -1, sharpen_kernel5)
sharpened_image9 = cv2.filter2D(image, -1, sharpen_kernel9)
plt.subplot(2, 2, 1), plt.imshow(image, cmap='gray'), plt.title('image'), plt.axis('off')
plt.subplot(2, 2, 2), plt.imshow(sharpened_image3, cmap='gray'), plt.title('Sharpened3'), plt.axis('off')
plt.subplot(2, 2, 3), plt.imshow(sharpened_image5, cmap='gray'), plt.title('Sharpened5'), plt.axis('off')
plt.subplot(2, 2, 4), plt.imshow(sharpened_image9, cmap='gray'), plt.title('Sharpened9'), plt.axis('off')
plt.show()
"""##########################################################################
# 函数功能:图像卷积操作 ———— 使用自定义卷积核对图像进行滤波处理。
# 函数说明:dst = cv2.filter2D(src, ddepth, kernel, dst=None, anchor=(-1, -1), delta=0, borderType=cv2.BORDER_DEFAULT)
# 输入参数:
# src: 输入图像(可以是灰度图或彩色图)。
# ddepth: 目标图像的深度,常用:
# (1)-1:与原图像深度相同
# (2)cv2.CV_8U, cv2.CV_32F 等
# kernel: 自定义卷积核(必须是奇数大小的方阵,如 3×3, 5×5)。
# dst: 输出图像(可选)。
# anchor: 锚点(默认:(-1, -1),表示中心点)。
# delta: 偏移量(默认:0)。
# borderType: 边界处理方式,常用:
# (1)cv2.BORDER_DEFAULT 默认边界填充
# (2)cv2.BORDER_REPLICATE 复制边界像素
# (3)cv2.BORDER_REFLECT 反射填充
# 输出参数:
# dst: 经过滤波后的图像
##########################################################################"""
# -*- coding: utf-8 -*-
# 作者: 胖墩会武术
# 日期: 1994-08-21
# OpenCV图像处理: https://blog.csdn.net/shinuone/article/details/126022763
2.8、腐蚀与膨胀(迭代次数) —— cv2.erode() + cv2.dilate()

import numpy as np
import cv2 # opencv读取图像默认为BGR
import matplotlib.pyplot as plt # matplotlib显示图像默认为RGB
image_gray = cv2.imread(r'image.jpg', flags=0)
kernel = np.ones((3, 3), np.uint8) # 初始化卷积核(np.ones: 生成一个数值全为1的3x3数组)
dilate_1 = cv2.dilate(image_gray, kernel, iterations=1) # 膨胀(迭代次数1次)
dilate_2 = cv2.dilate(image_gray, kernel, iterations=5) # 膨胀
dilate_3 = cv2.dilate(image_gray, kernel, iterations=10) # 膨胀
erosion_1 = cv2.erode(image_gray, kernel, iterations=1) # 腐蚀(迭代次数1次)
erosion_2 = cv2.erode(image_gray, kernel, iterations=5) # 腐蚀
erosion_3 = cv2.erode(image_gray, kernel, iterations=10) # 腐蚀
plt.subplot(2, 4, 1), plt.imshow(image_gray, 'gray'), plt.title('image_gray'), plt.axis('off')
plt.subplot(2, 4, 2), plt.imshow(dilate_1, 'gray'), plt.title('dilate_1'), plt.axis('off')
plt.subplot(2, 4, 3), plt.imshow(dilate_2, 'gray'), plt.title('dilate_2'), plt.axis('off')
plt.subplot(2, 4, 4), plt.imshow(dilate_3, 'gray'), plt.title('dilate_3'), plt.axis('off')
plt.subplot(2, 4, 6), plt.imshow(erosion_1, 'gray'), plt.title('erosion_1'), plt.axis('off')
plt.subplot(2, 4, 7), plt.imshow(erosion_2, 'gray'), plt.title('erosion_2'), plt.axis('off')
plt.subplot(2, 4, 8), plt.imshow(erosion_3, 'gray'), plt.title('erosion_3'), plt.axis('off')
plt.show()
"""####################################################################################################################
# 函数功能:腐蚀操作 ———— 腐蚀是一种图像形态学操作,它通过移动滑动结构元素(也称为内核)在图像上,将内核覆盖区域的像素值设置为该区域内的最小像素值,从而使图像中的前景对象缩小或被消除。
# 函数说明:eroded_image = cv2.erode(src, kernel, iterations=1, borderType=cv2.BORDER_CONSTANT, borderValue=0)
# 参数说明:
# src: 输入的图像,通常为二值图像(黑白图像)。
# kernel: 腐蚀操作的内核,决定了腐蚀的效果。可以使用 cv2.getStructuringElement() 函数创建一个结构元素。
# iterations: 可选参数,表示腐蚀操作的迭代次数。默认值为 1。
# borderType: 可选参数,表示边界填充方式。默认值为 cv2.BORDER_CONSTANT。
# borderValue: 可选参数,表示边界填充的像素值。默认值为 0。
####################################################################################################################"""
"""####################################################################################################################
# 函数功能:膨胀操作 ———— 膨胀是一种图像形态学操作,它通过移动滑动结构元素(也称为内核)在图像上,将内核覆盖区域的像素值设置为该区域内的最大像素值,从而使图像中的前景对象增大或扩展。
# 函数说明:dilated_image = cv2.dilate(src, kernel, iterations=1, borderType=cv2.BORDER_CONSTANT, borderValue=0)
# 参数说明:
# src: 输入的图像,通常为二值图像(黑白图像)。
# kernel: 膨胀操作的内核,决定了膨胀的效果。可以使用 cv2.getStructuringElement() 函数创建一个结构元素。
# iterations: 可选参数,表示膨胀操作的迭代次数。默认值为 1。
# borderType: 可选参数,表示边界填充方式。默认值为 cv2.BORDER_CONSTANT。
# borderValue: 可选参数,表示边界填充的像素值。默认值为 0。
####################################################################################################################"""
# -*- coding: utf-8 -*-
# 作者: 胖墩会武术
# 日期: 1994-08-21
# OpenCV图像处理: https://blog.csdn.net/shinuone/article/details/126022763
2.9、形态学变化(腐蚀 + 膨胀 + 开运算 + 闭运算 + 梯度计算 + 顶帽 + 黑帽) —— cv2.morphologyEx()

import numpy as np
kernel = np.ones((3, 3), dtype=np.uint8)
"""形态学变化中的核函数通常设置为全1的矩阵(如 np.ones)"""
# 例如:
# 较小的核函数(如3x3)通常用于处理小的噪声,
# 较大的核函数(如5x5或7x7)适用于较大区域的处理。
# 举例:
# 【腐蚀】作用:用于去除图像中的小噪点、减少白色区域、突出结构元素的主要形状。
# 【腐蚀】计算:使用一个核函数作为滑动窗口,遍历图像的每个像素,并计算该像素及其邻域的最小值。
# 对于二值图像:如果核覆盖区域中的所有“1”像素都匹配原图中的“1”,则中心像素保持“1”;否则,中心像素变为“0”。
# 对于灰度图像:将核覆盖区域中的所有像素取最小值,并赋值给中心像素。
import numpy as np
import cv2 # opencv读取图像默认为BGR
import matplotlib.pyplot as plt # matplotlib显示图像默认为RGB
image_gray = cv2.imread(r'image.jpg', flags=0)
kernel = np.ones((11, 11), np.uint8) # 初始化卷积核(np.ones: 生成一个数值全为1的3x3数组)
image_erode = cv2.morphologyEx(image_gray, cv2.MORPH_ERODE, kernel) # 腐蚀
image_dilate= cv2.morphologyEx(image_gray, cv2.MORPH_DILATE, kernel) # 膨胀
image_open = cv2.morphologyEx(image_gray, cv2.MORPH_OPEN, kernel) # 开运算
image_close = cv2.morphologyEx(image_gray, cv2.MORPH_CLOSE, kernel) # 闭运算
image_grad = cv2.morphologyEx(image_gray, cv2.MORPH_GRADIENT, kernel) # 梯度计算
image_top = cv2.morphologyEx(image_gray, cv2.MORPH_TOPHAT, kernel) # 顶帽运算
image_black = cv2.morphologyEx(image_gray, cv2.MORPH_BLACKHAT, kernel) # 黑帽运算
plt.subplot(2, 4, 1), plt.imshow(image_gray, 'gray'), plt.title('image_gray'), plt.axis('off')
plt.subplot(2, 4, 2), plt.imshow(image_erode, 'gray'), plt.title('cv2.MORPH_ERODE'), plt.axis('off')
plt.subplot(2, 4, 3), plt.imshow(image_dilate, 'gray'), plt.title('cv2.MORPH_DILATE'), plt.axis('off')
plt.subplot(2, 4, 4), plt.imshow(image_open, 'gray'), plt.title('cv2.MORPH_OPEN'), plt.axis('off')
plt.subplot(2, 4, 5), plt.imshow(image_close, 'gray'), plt.title('cv2.MORPH_CLOSE'), plt.axis('off')
plt.subplot(2, 4, 6), plt.imshow(image_grad, 'gray'), plt.title('cv2.MORPH_GRADIENT'), plt.axis('off')
plt.subplot(2, 4, 7), plt.imshow(image_top, 'gray'), plt.title('cv2.MORPH_TOPHAT'), plt.axis('off')
plt.subplot(2, 4, 8), plt.imshow(image_black, 'gray'), plt.title('cv2.MORPH_BLACKHAT'), plt.axis('off')
plt.show()
"""#################################################################################################################
# 函数功能:用于对图像进行形态学操作,如腐蚀、膨胀、开运算、闭运算等。
# 函数说明:dst = cv2.morphologyEx(src, op, kernel)
# 参数说明:
# src: 输入图像,通常是灰度图像或二值图像。
# op: 形态学操作类型,可以是以下几种之一:
# cv2.MORPH_ERODE: 腐蚀操作。 使物体边缘收缩,去除小噪声,细小物体会消失。
# cv2.MORPH_DILATE: 膨胀操作。 使物体边缘扩展,填补空洞,连接物体。
# cv2.MORPH_OPEN: 开运算(先腐蚀后膨胀)。 去除小噪声、细节部分保留。
# cv2.MORPH_CLOSE: 闭运算(先膨胀后腐蚀)。 填补图像中的小孔洞或黑点,前景更加连续。
# cv2.MORPH_GRADIENT: 形态学梯度(膨胀图像减去腐蚀图像)。 增强图像边缘,突出物体轮廓。
# cv2.MORPH_TOPHAT: 顶帽运算(原始图像减去开运算图像)。 提取小的亮区或细节。
# cv2.MORPH_BLACKHAT: 黑帽运算(闭运算图像减去原始图像)。 提取小的暗区或缺失区域。
# kernel: 结构元素,用于指定形态学操作的形状和大小。
#################################################################################################################"""
"""##########################################################
# morphology
# n. (生物)形态学;(语言学中的)词法,形态学;结构,形态
# morph
# n. 形素,语素;形态;图像变换
# v. (使)图像变形;将(图像)进行合成处理;改变,变化,变形
##########################################################"""
# -*- coding: utf-8 -*-
# 作者: 胖墩会武术
# 日期: 1994-08-21
# OpenCV图像处理: https://blog.csdn.net/shinuone/article/details/126022763
2.10、边缘检测算子 —— cv2.sobel()、cv2.Scharr()、cv2.Laplacian()、cv2.Canny()
(1)以sobel算子为例,计算x和y方向的导数以及梯度幅值。

import cv2 # opencv读取图像默认为BGR
import matplotlib.pyplot as plt # matplotlib显示图像默认为RGB
image_gray = cv2.imread(r'image.jpg', cv2.IMREAD_GRAYSCALE)
############################################################################################
# (不建议)同时对x和y进行求导,会导致部分信息丢失。
sobel_xy = cv2.Sobel(image_gray, cv2.CV_64F, 1, 1, ksize=3)
sobel_xy_Abs = cv2.convertScaleAbs(sobel_xy)
############################################################################################
# (1)左边减右边(2)白到黑是正数,黑到白就是负数,且所有的负数会被截断成0,所以要取绝对值。
sobel_x = cv2.Sobel(image_gray, cv2.CV_64F, 1, 0, ksize=3) # 计算x方向的导数
sobel_y = cv2.Sobel(image_gray, cv2.CV_64F, 0, 1, ksize=3) # 计算y方向的导数
sobel_magnitude = cv2.magnitude(sobel_x, sobel_y) # 计算梯度幅值
sobel_magnitude_Abs = cv2.convertScaleAbs(sobel_magnitude) # 计算绝对值
############################################################################################
plt.subplot(3, 3, 1), plt.imshow(image_gray, cmap='gray'), plt.title('image_gray'), plt.axis('off')
plt.subplot(3, 3, 2), plt.imshow(sobel_xy, cmap='gray'), plt.title('sobel_xy'), plt.axis('off')
plt.subplot(3, 3, 3), plt.imshow(sobel_xy_Abs, cmap='gray'), plt.title('sobel_xy_Abs'), plt.axis('off')
plt.subplot(3, 3, 5), plt.imshow(sobel_x, cmap='gray'), plt.title('sobel_x'), plt.axis('off')
plt.subplot(3, 3, 6), plt.imshow(sobel_y, cmap='gray'), plt.title('sobel_y'), plt.axis('off')
plt.subplot(3, 3, 8), plt.imshow(sobel_magnitude, cmap='gray'), plt.title('sobel_magnitude'), plt.axis('off')
plt.subplot(3, 3, 9), plt.imshow(sobel_magnitude_Abs, cmap='gray'), plt.title('sobel_magnitude_Abs'), plt.axis('off')
plt.show()
"""#############################################################################################
# 函数功能:计算每个像素点的幅度(大小),通常用于图像处理中的梯度计算。
# 函数说明:magnitude = cv2.magnitude(x, y)
# 参数说明:
# x:输入图像的 x 方向梯度图,通常是使用 Sobel 或 Scharr 算子计算得到的。
# y:输入图像的 y 方向梯度图,通常是使用 Sobel 或 Scharr 算子计算得到的。
# 返回值:
# 返回与输入图像相同大小的幅度图像,图像类型为浮点型(CV_32F),包含每个像素点的幅度值。
# 功能描述:
# - cv2.magnitude 函数用于计算输入图像在 x 和 y 方向上的梯度大小。它根据每个像素的 x 和 y 方向的梯度值,计算幅度的平方根。
# - 计算公式为:magnitude = √(x² + y²),可以用于获取边缘或特征的强度。
#############################################################################################"""
"""#############################################################################################
# 函数功能:对输入图像进行缩放和绝对值计算,通常用于图像处理中的亮度调整和类型转换。
# 函数说明:dst = cv2.convertScaleAbs(src, alpha=1, beta=0)
# 参数说明:
# src:输入图像,可以是单通道或多通道图像。
# alpha:缩放因子,用于调整图像的亮度,默认为1。通过调整alpha可以增加或减少图像的亮度。
# beta:加值,默认为0。此值将加到每个像素上,可以用来进一步调整图像的亮度。
# 返回值:
# 返回处理后的图像,图像类型为无符号8位整型(CV_8U)。
# 功能描述:
# - cv2.convertScaleAbs 函数用于图像的缩放与转换,特别是在对浮点型图像进行处理后,可以通过该函数将结果转换为8位无符号整数格式。
# - 常用于处理图像中的梯度或滤波结果,以便将结果显示在窗口中。
#############################################################################################"""
# -*- coding: utf-8 -*-
# 作者: 胖墩会武术
# 日期: 1994-08-21
# OpenCV图像处理: https://blog.csdn.net/shinuone/article/details/126022763
(2)不同算子的差异:Sobel算子、Scharr算子、Laplacian算子
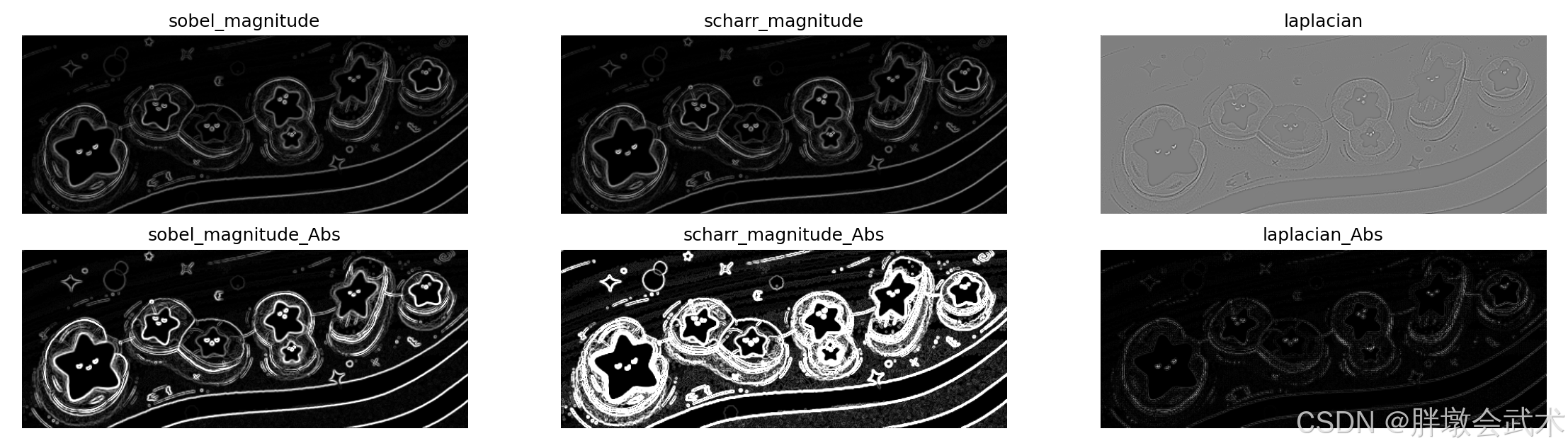
import cv2 # opencv读取图像默认为BGR
import matplotlib.pyplot as plt # matplotlib显示图像默认为RGB
image_gray = cv2.imread(r'image.jpg', cv2.IMREAD_GRAYSCALE)
################################################################################
sobel_x = cv2.Sobel(image_gray, cv2.CV_64F, 1, 0, ksize=3) # 计算x方向的导数
sobel_y = cv2.Sobel(image_gray, cv2.CV_64F, 0, 1, ksize=3) # 计算y方向的导数
sobel_magnitude = cv2.magnitude(sobel_x, sobel_y) # 计算梯度幅值
sobel_magnitude_Abs = cv2.convertScaleAbs(sobel_magnitude)
################################################################################
scharr_x = cv2.Scharr(image_gray, cv2.CV_64F, 1, 0) # 计算x方向的导数
scharr_y = cv2.Scharr(image_gray, cv2.CV_64F, 0, 1) # 计算y方向的导数
scharr_magnitude = cv2.magnitude(scharr_x, scharr_y) # 计算梯度幅值
scharr_magnitude_Abs = cv2.convertScaleAbs(scharr_magnitude) # 计算绝对值
################################################################################
laplacian = cv2.Laplacian(image_gray, cv2.CV_64F)
laplacian_Abs = cv2.convertScaleAbs(laplacian)
################################################################################
plt.subplot(2, 3, 1), plt.imshow(sobel_magnitude, cmap='gray'), plt.title('sobel_magnitude'), plt.axis('off')
plt.subplot(2, 3, 2), plt.imshow(scharr_magnitude, cmap='gray'), plt.title('scharr_magnitude'), plt.axis('off')
plt.subplot(2, 3, 3), plt.imshow(laplacian, cmap='gray'), plt.title('laplacian'), plt.axis('off')
plt.subplot(2, 3, 4), plt.imshow(sobel_magnitude_Abs, cmap='gray'), plt.title('sobel_magnitude_Abs'), plt.axis('off')
plt.subplot(2, 3, 5), plt.imshow(scharr_magnitude_Abs, cmap='gray'), plt.title('scharr_magnitude_Abs'), plt.axis('off')
plt.subplot(2, 3, 6), plt.imshow(laplacian_Abs, cmap='gray'), plt.title('laplacian_Abs'), plt.axis('off')
plt.show()
"""#############################################################################################
# 函数功能:计算图像的Sobel导数,常用于边缘检测和图像梯度计算。
# 函数说明:sobel = cv2.Sobel(src, ddepth, dx, dy, ksize=3, scale=1, delta=0, borderType=cv2.BORDER_DEFAULT)
# 参数说明:
# src:输入图像,可以是单通道或多通道图像。
# ddepth:输出图像的深度,可以是 cv2.CV_8U, cv2.CV_16S, cv2.CV_32F 等。常用的值包括:
# - cv2.CV_8U:8位无符号整数
# - cv2.CV_16S:16位有符号整数
# - cv2.CV_32F:32位浮点数
# dx:可选参数,x方向的导数阶数。取值为0表示不计算x方向的导数,取值为1表示计算一阶导数。
# dy:可选参数,y方向的导数阶数。取值为0表示不计算y方向的导数,取值为1表示计算一阶导数。
# ksize:可选参数,Sobel算子的大小。默认值为3,取值可以为1、3、5或7。卷积核必须是奇数。
# scale:可选参数,缩放系数,默认为1。用于调整输出值的比例。
# delta:可选参数,值的偏移量,默认为0。添加到输出结果中的常数。
# borderType:可选参数,边界处理模式,默认为 cv2.BORDER_DEFAULT。可选值包括 cv2.BORDER_CONSTANT、cv2.BORDER_REPLICATE 等。
# 返回值:
# 返回与输入图像相同大小的图像,表示Sobel导数计算后的结果。
# 功能描述:
# - cv2.Sobel 函数用于计算图像在x或y方向上的梯度,强调图像的边缘和纹理。
# - 通过组合dx和dy的结果,可以计算图像的整体梯度幅值和方向。
#############################################################################################"""
"""#############################################################################################
# 函数功能:计算图像的Scharr导数,常用于边缘检测和图像梯度计算。
# 函数说明:scharr = cv2.Scharr(src, ddepth, dx, dy, scale=1, delta=0, borderType=cv2.BORDER_DEFAULT)
# 参数说明:
# src:输入图像,可以是单通道或多通道图像。
# ddepth:输出图像的深度,可以是 cv2.CV_8U, cv2.CV_16S, cv2.CV_32F 等。常用的值包括:
# - cv2.CV_8U:8位无符号整数
# - cv2.CV_16S:16位有符号整数
# - cv2.CV_32F:32位浮点数
# dx:可选参数,x方向的导数阶数。取值为0表示不计算x方向的导数,取值为1表示计算一阶导数。
# dy:可选参数,y方向的导数阶数。取值为0表示不计算y方向的导数,取值为1表示计算一阶导数。
# scale:可选参数,缩放系数,默认为1。用于调整输出值的比例。
# delta:可选参数,值的偏移量,默认为0。添加到输出结果中的常数。
# borderType:可选参数,边界处理模式,默认为 cv2.BORDER_DEFAULT。可选值包括 cv2.BORDER_CONSTANT、cv2.BORDER_REPLICATE 等。
# 返回值:
# 返回与输入图像相同大小的图像,表示Scharr导数计算后的结果。
# 功能描述:
# - cv2.Scharr 函数用于计算图像在x或y方向上的梯度,强调图像的边缘和纹理。
# - Scharr算子比Sobel算子具有更高的精度,尤其是在处理斜率较大的边缘时。
#############################################################################################"""
"""#############################################################################################
# 函数功能:拉普拉斯边缘检测
# 函数说明:laplacian = cv2.Laplacian(src, ddepth, ksize=3, scale=1, delta=0, borderType=cv2.BORDER_DEFAULT)
# 参数说明:
# src:输入图像,可以是单通道或多通道图像。
# ddepth:输出图像的深度,可以是 cv2.CV_8U, cv2.CV_16S, cv2.CV_32F 等。常用的值包括:
# - cv2.CV_8U:8位无符号整数
# - cv2.CV_16S:16位有符号整数
# - cv2.CV_32F:32位浮点数
# ksize:可选参数,卷积核的大小。默认值为3,取值可以为1、3、5或7。卷积核必须是奇数。
# scale:可选参数,缩放系数,默认为1。用于调整输出值的比例。
# delta:可选参数,值的偏移量,默认为0。添加到输出结果中的常数。
# borderType:可选参数,边界处理模式,默认为 cv2.BORDER_DEFAULT。可选值包括 cv2.BORDER_CONSTANT、cv2.BORDER_REPLICATE 等。
# 返回值:
# 返回与输入图像相同大小的图像,表示拉普拉斯变换后的结果。
# 功能描述:
# - cv2.Laplacian 函数通过计算图像的二阶导数,强调边缘和轮廓,通常用于图像处理中的边缘检测。
# - 拉普拉斯变换对于噪声敏感,因此在使用前通常会先进行平滑处理(如高斯模糊)。
#############################################################################################"""
# -*- coding: utf-8 -*-
# 作者: 胖墩会武术
# 日期: 1994-08-21
# OpenCV图像处理: https://blog.csdn.net/shinuone/article/details/126022763
(3)Canny算子(参数经验)

"""############################################################################################
# 边缘检测Canny算子
# (1)图像平滑:使用高斯滤波器对图像进行平滑,以减少噪声。
# (2)计算梯度:计算图像的梯度,以确定强度变化的方向和幅度。通常使用Sobel算子来计算x和y方向的导数。
# (3)非极大值抑制:对梯度幅值进行非极大值抑制,保留局部最大值并抑制其他值。保留大值,去除小值。用于细化边缘,将边缘宽度缩小到1个像素。
# (4)双阈值处理:根据设置的低阈值和高阈值对非极大值抑制后的图像进行阈值处理。将强边缘像素标记为255,弱边缘像素标记为1,其他像素设为0。
# (5)边缘连接:通过连接弱边缘和强边缘来确定最终的边缘。任何与强边缘相连的弱边缘都会被保留,其他的弱边缘将被抑制。
############################################################################################"""
import cv2 # opencv读取图像默认为BGR
import matplotlib.pyplot as plt # matplotlib显示图像默认为RGB
image_gray = cv2.imread(r'image.jpg', cv2.IMREAD_GRAYSCALE)
################################################################################
# 低阈值:检测出来的特征越多(可能是假边界值)
# 高阈值:检测出来的特征越少。高阈值应设置为低阈值的2~3倍。
image_canny50_100 = cv2.Canny(image_gray, 50, 100)
image_canny100_200 = cv2.Canny(image_gray, 100, 200)
plt.subplot(1, 3, 1), plt.imshow(image_gray, cmap='gray'), plt.title('image_gray'), plt.axis('off')
plt.subplot(1, 3, 2), plt.imshow(image_canny50_100, cmap='gray'), plt.title('image_canny50_100'), plt.axis('off')
plt.subplot(1, 3, 3), plt.imshow(image_canny100_200, cmap='gray'), plt.title('image_canny100_200'), plt.axis('off')
plt.show()
"""#############################################################################################
# 函数功能:Canny边缘检测
# 函数说明:edges = cv2.Canny(image, threshold1, threshold2, apertureSize=3, L2gradient=False)
# 参数说明:
# image:输入的灰度图像。Canny边缘检测算法要求输入为单通道图像。
# threshold1:第一个阈值,用于边缘连接(低阈值)。如果某个像素的强度高于这个值,它被视为弱边缘。
# threshold2:第二个阈值,用于边缘连接(高阈值)。如果某个像素的强度高于这个值,它被视为强边缘。
# apertureSize:可选参数,Sobel算子的大小。默认为3,取值可以为1、3、5或7。
# L2gradient:可选参数,布尔值。默认为False。如果设置为True,则使用L2范数计算梯度幅值;否则使用L1范数。
# 返回值:
# 返回一个与输入图像大小相同的二值图像,表示检测到的边缘。
# 参数建议:
# - 低阈值:通常设置得较低,以捕捉到更多可能的边缘。
# - 高阈值:通常设置得较高,以确保只有强边缘被认为是有效的。高阈值应设置为低阈值的2~3倍。
# - 自动阈值:将大津法计算出的阈值作为低阈值,然后设置高阈值为低阈值的1.5~3倍(具体倍数取决于图像的特性)。
#############################################################################################"""
# -*- coding: utf-8 -*-
# 作者: 胖墩会武术
# 日期: 1994-08-21
# OpenCV图像处理: https://blog.csdn.net/shinuone/article/details/126022763
opencv边缘检测sobel算子
opencv边缘检测Canny
2.11、图像金字塔
高斯金字塔:对图像进行平滑+降采样,用于多尺度分析、图像缩放、特征提取
拉普拉斯金字塔:高斯金字塔相邻层之差,用于图像复原、特征增强、图像合成
(1)上采样(Upsampling) + 下采样(Downsampling) —— cv2.pyrUp()、cv2.pyrDown()
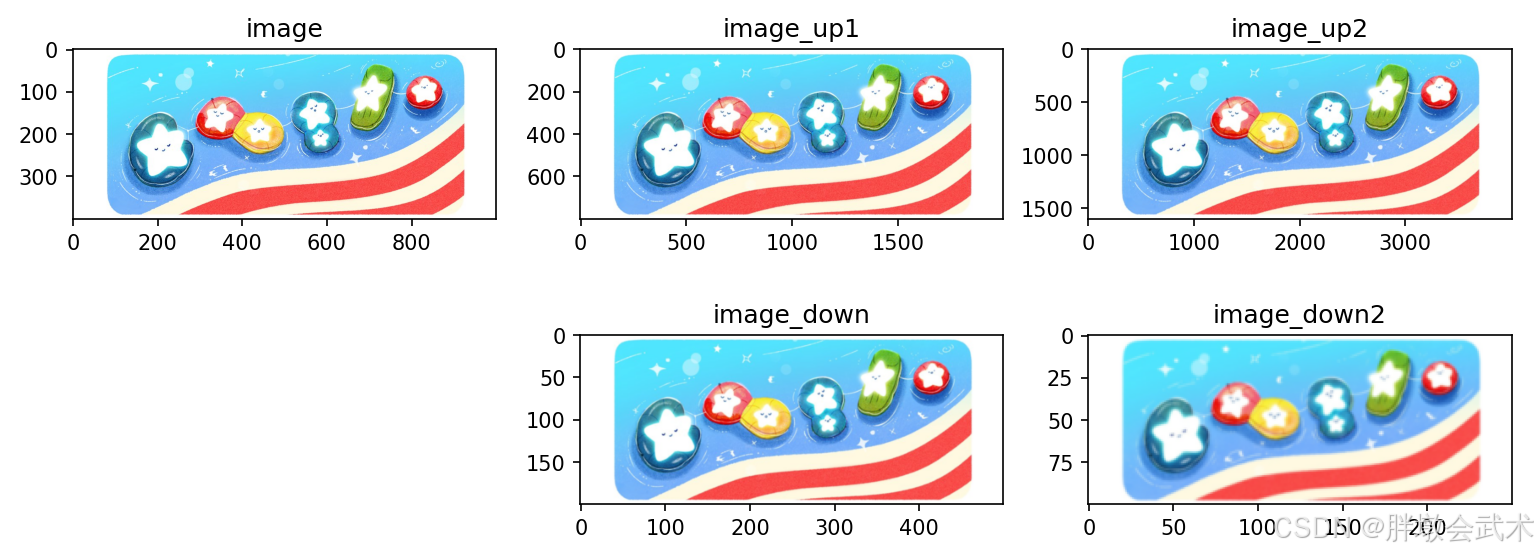
import cv2 # opencv读取图像默认为BGR
import matplotlib.pyplot as plt # matplotlib显示图像默认为RGB
image = cv2.imread(r'image.jpg')
image_up1 = cv2.pyrUp(image) # 图像上采样(放大2倍)
image_up2 = cv2.pyrUp(image_up1) # 图像上采样(放大4倍)
#############################################################################
image_down1 = cv2.pyrDown(image) # 图像下采样(缩小2倍)
image_down2 = cv2.pyrDown(image_down1) # 图像下采样(缩小4倍)
#############################################################################
plt.subplot(2, 3, 1), plt.imshow(cv2.cvtColor(image, cv2.COLOR_BGR2RGB)), plt.title('image')
plt.subplot(2, 3, 2), plt.imshow(cv2.cvtColor(image_up1, cv2.COLOR_BGR2RGB)), plt.title('image_up1')
plt.subplot(2, 3, 3), plt.imshow(cv2.cvtColor(image_up2, cv2.COLOR_BGR2RGB)), plt.title('image_up2')
plt.subplot(2, 3, 5), plt.imshow(cv2.cvtColor(image_down1, cv2.COLOR_BGR2RGB)), plt.title('image_down')
plt.subplot(2, 3, 6), plt.imshow(cv2.cvtColor(image_down2, cv2.COLOR_BGR2RGB)), plt.title('image_down2')
plt.show()
"""#############################################################################################
# 函数功能:图像下采样 ———— 将图像的宽度和高度缩小一半(高斯模糊)
# 函数说明:dst = cv2.pyrDown(src, dstsize=None, borderType=cv2.BORDER_DEFAULT)
# 参数说明:
# src:输入图像,通常为单通道或多通道图像。
# dstsize:输出图像的大小,可选项,默认为 None。若为 None,则输出图像大小为输入图像的一半。
# borderType:边界类型,用于指定图像边界的填充方式,默认为 cv2.BORDER_DEFAULT。
# 返回值:
# 返回下采样后的图像,分辨率通常是输入图像的一半。
# 功能描述:
# - 通常用于构建图像金字塔(pyramid)时,生成较低分辨率的图像。
# - 该函数对输入图像进行高斯模糊后缩小尺寸,适用于图像金字塔构建或图像缩小。
#############################################################################################"""
"""#############################################################################################
# 函数功能:图像上采样 ———— 将图像的宽度和高度扩大一倍(双线性插值)
# 函数说明:dst = cv2.pyrUp(src, dstsize=None, borderType=cv2.BORDER_DEFAULT)
# 参数说明:
# src:输入图像,通常为单通道或多通道图像。
# dstsize:输出图像的大小,可选项,默认为 None。若为 None,则输出图像大小为输入图像的两倍。
# borderType:边界类型,用于指定图像边界的填充方式。默认值为 cv2.BORDER_DEFAULT。
# 返回值:
# 返回上采样后的图像,分辨率通常是输入图像的两倍。
# 功能描述:
# - 通常用于构建图像金字塔(pyramid)时,生成较高分辨率的图像。
# - 该函数对输入图像进行双线性插值,扩展图像的大小,并适用于金字塔重建或图像放大。
#############################################################################################"""
# -*- coding: utf-8 -*-
# 作者: 胖墩会武术
# 日期: 1994-08-21
# OpenCV图像处理: https://blog.csdn.net/shinuone/article/details/126022763
(2)高斯金字塔(Gaussian Pyramid):逐层下采样
- 作用:通过重复高斯模糊+下采样逐层降低图像分辨率,形成金字塔结构。主要用于图像金字塔匹配、图像分割、目标检测等任务。
- 高斯金字塔构建
通过 cv2.pyrDown() 进行下采样,逐步生成低分辨率版本的图像。
通过 cv2.pyrUp() 进行上采样(但信息会损失)。
import cv2
# (1)读取图像
image = cv2.imread(r"F:\py\image.jpg")
image = image[50:250, 100:400, ]
# 构建高斯金字塔(多层)
gaussian_pyramid = [image] # 存储金字塔
for i in range(3): # 生成 2 层金字塔
image = cv2.pyrDown(image)
gaussian_pyramid.append(image)
# 显示结果
for i, img in enumerate(gaussian_pyramid):
cv2.imshow(f"Level {i}", img)
cv2.waitKey(0)
cv2.destroyAllWindows()
# 第 0 层是原图像,后面每一层分辨率逐渐降低。
# -*- coding: utf-8 -*-
# 作者: 胖墩会武术
# 日期: 1994-08-21
# OpenCV图像处理: https://blog.csdn.net/shinuone/article/details/126022763
(2)拉普拉斯金字塔(Laplacian Pyramid):基于高斯金字塔逐层上采样,并计算差值。
- 作用:通过高斯金字塔计算图像的细节信息,用于图像合成、超分辨率重建等任务。
- 拉普拉斯金字塔构建
- (1)构建高斯金字塔。
- (2)计算拉普拉斯金字塔
多分辨率的拉普拉斯金字塔(由低到高)
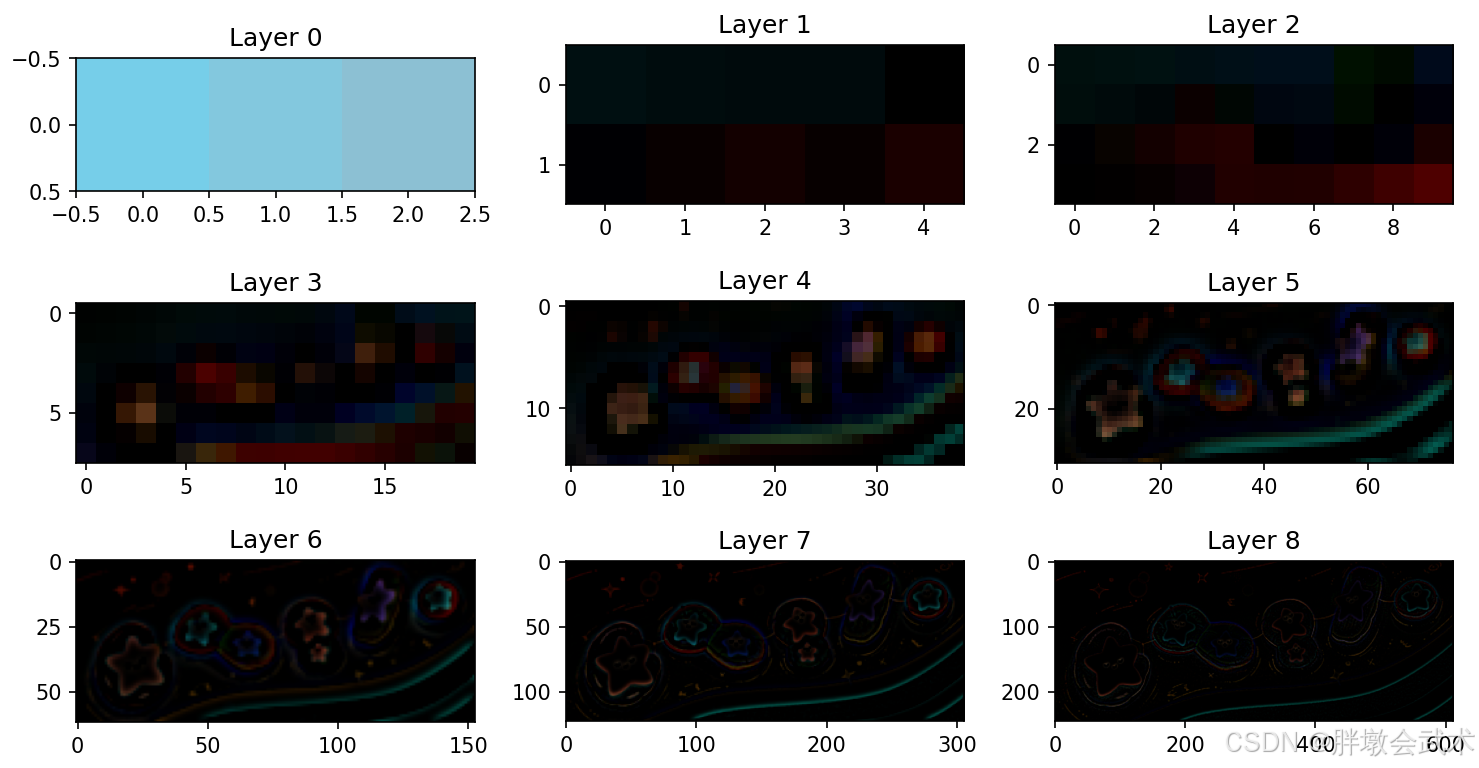
####################################################################################################
# 拉普拉斯金字塔
# image_down = cv2.pyrDown(image) # 图像下采样
# image_down_up = cv2.pyrUp(image_down) # 图像上采样
# image_down_up_resize = cv2.resize(image_down_up, (image.shape[1], image.shape[0])) # 确保尺度一致
# image_down_up_laplacian = cv2.subtract(image, image_down_up_resize) # 计算差值
####################################################################################################
import cv2 # opencv读取图像默认为BGR
import matplotlib.pyplot as plt # matplotlib显示图像默认为RGB
image = cv2.imread(r'image.jpg')
# (1)构建高斯金字塔
gaussian_pyramid = [image]
for i in range(8): # 生成6层
image = cv2.pyrDown(image)
gaussian_pyramid.append(image)
laplacian_pyramid = [gaussian_pyramid[-1]] # 最底层为高斯金字塔的最后一层
# (2)构建拉普拉斯金字塔
for i in range(len(gaussian_pyramid) - 1, 0, -1): # 顺序是从最后一层到第二层
# 将上一层的高斯金字塔图像上采样
gaussian_expanded = cv2.pyrUp(gaussian_pyramid[i])
# 确保大小匹配(差值计算需要确保尺寸一致)
if gaussian_expanded.shape[0] != gaussian_pyramid[i - 1].shape[0] or gaussian_expanded.shape[1] != gaussian_pyramid[i - 1].shape[1]:
gaussian_expanded = cv2.resize(gaussian_expanded, (gaussian_pyramid[i - 1].shape[1], gaussian_pyramid[i - 1].shape[0]))
# 计算拉普拉斯金字塔图像
laplacian = cv2.subtract(gaussian_pyramid[i - 1], gaussian_expanded)
laplacian_pyramid.append(laplacian)
plt.figure(figsize=(10, 6))
for i, layer in enumerate(laplacian_pyramid):
plt.subplot(3, 3, i + 1)
plt.imshow(cv2.cvtColor(layer, cv2.COLOR_BGR2RGB))
plt.title(f'Layer {i}')
plt.tight_layout()
plt.show()
# -*- coding: utf-8 -*-
# 作者: 胖墩会武术
# 日期: 1994-08-21
# OpenCV图像处理: https://blog.csdn.net/shinuone/article/details/126022763
OpenCV计算机视觉学习 —— 图像金字塔(高斯金字塔,拉普拉斯金字塔,图像缩放resize函数)
2.12、轮廓检测
(1)提取轮廓 + 绘制轮廓 —— cv2.findContours()、cv2.drawContours()
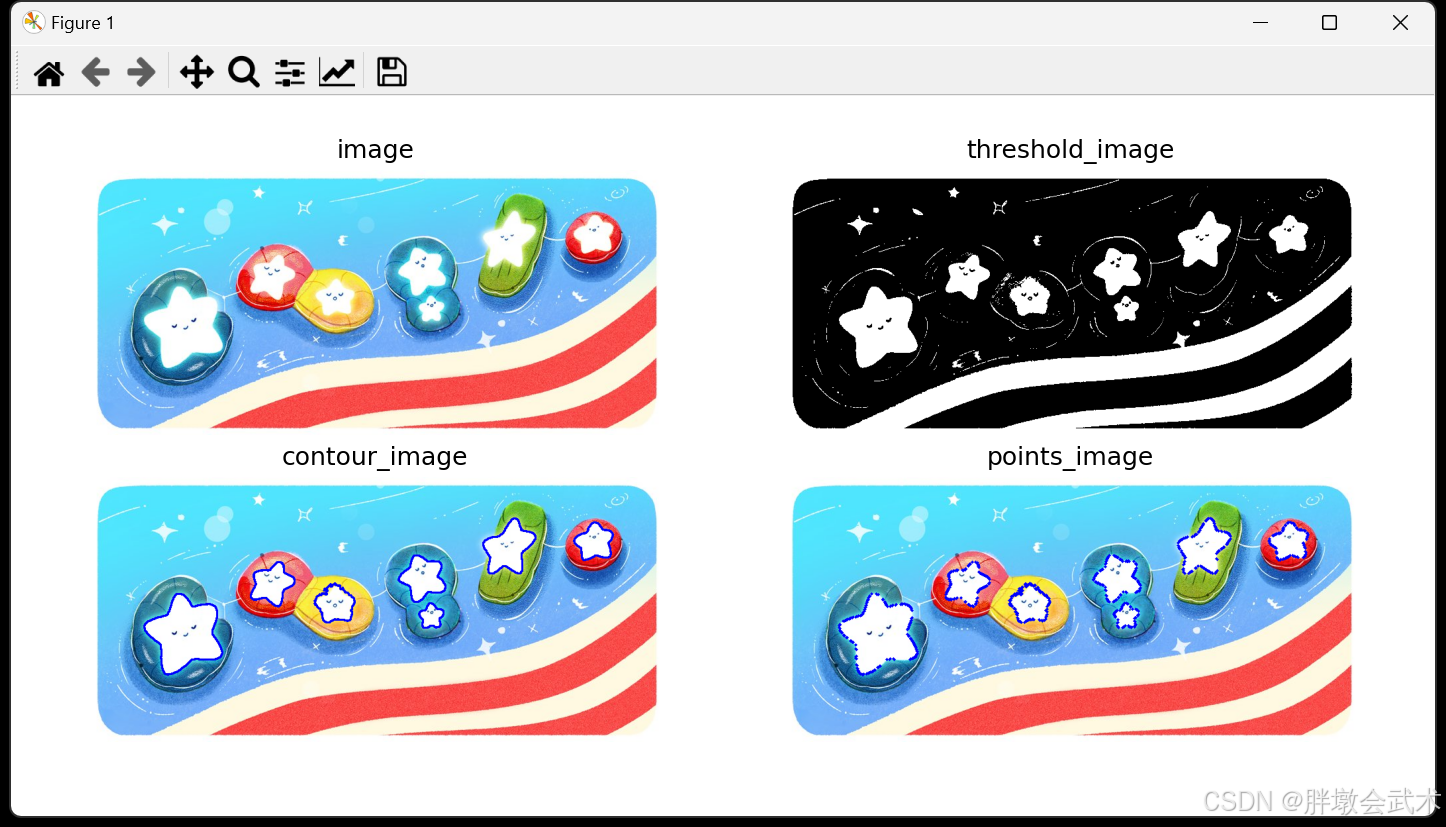
| 轮廓(Contour) | 边缘(Edge) | |
|---|---|---|
| 定义 | 图像中物体的外部边界,通常是连通的闭合曲线 | 图像中像素值变化剧烈的区域,包括物体边缘、纹理、阴影等 |
| 计算方法 | 二值化 + 轮廓检测 | 通过梯度运算(如Sobel、Canny)检测像素变化 |
| 数据表示 | 轮廓由点集组成,通常是一个封闭的路径 | 边缘是像素级的变化,不一定连通 |
| 是否封闭 | 封闭的(闭合曲线) | 可能是开放的(不一定形成闭合形状) |
| 噪声影响 | 对噪声较敏感,可能提取到错误的轮廓 | 受噪声影响较大,需平滑处理 |
| 应用场景 | 目标检测、形状分析、物体识别、分割 | 纹理分析、特征提取、边缘检测 |
import cv2 # opencv读取图像默认为BGR
import matplotlib.pyplot as plt # matplotlib显示图像默认为RGB
# 读取图像和预处理
image = cv2.imread(r"F:\py\image.jpg")
image_gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
_, threshold_image = cv2.threshold(image_gray, 225, 255, cv2.THRESH_BINARY)
# 轮廓检测
contours, _ = cv2.findContours(threshold_image, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
# 原图的不同绘制效果副本
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
contour_image = image.copy() # 完整轮廓绘制
points_image = image.copy() # 轮廓点
for cnt in contours:
area = cv2.contourArea(cnt)
length = cv2.arcLength(cnt, True)
if 10000 > area > 500: # 只处理较大的轮廓
print(area)
# 完整轮廓
cv2.drawContours(contour_image, [cnt], -1, (0, 0, 255), 2)
# 轮廓点绘制
for point in cnt:
x, y = point[0]
cv2.circle(points_image, (x, y), 2, (0, 0, 255), -1)
# 显示结果
plt.subplot(2, 2, 1), plt.imshow(image), plt.title("image"), plt.axis('off')
plt.subplot(2, 2, 2), plt.imshow(threshold_image, cmap='gray'), plt.title("threshold_image"), plt.axis('off')
plt.subplot(2, 2, 3), plt.imshow(contour_image), plt.title("contour_image"), plt.axis('off')
plt.subplot(2, 2, 4), plt.imshow(points_image), plt.title("points_image"), plt.axis('off')
plt.tight_layout()
plt.show()
# 轮廓: 将连续的点(连着边界)连在一起的曲线,具有相同的颜色或者灰度。轮廓在形状分析和物体的检测和识别中很有用。
"""#################################################################################################################
# 函数功能:用于在二值图像中轮廓检测
# 函数说明:contours, hierarchy = cv2.findContours(image, mode, method)
# 参数说明:
# image: 输入的二值图像,通常为灰度图像或者是经过阈值处理后的图像。
# mode: 轮廓检索模式,指定轮廓的层次结构。
# cv2.RETR_EXTERNAL: 仅检测外部轮廓。
# cv2.RETR_LIST: 检测所有轮廓,不建立轮廓层次。
# cv2.RETR_CCOMP: 检测所有轮廓,将轮廓分为两级层次结构。
# cv2.RETR_TREE: 检测所有轮廓,建立完整的轮廓层次结构。
# method: 轮廓逼近方法,指定轮廓的近似方式。
# cv2.CHAIN_APPROX_NONE: 存储所有的轮廓点,相邻的点之间不进行抽稀。
# cv2.CHAIN_APPROX_SIMPLE: 仅存储轮廓的端点,相邻的点之间进行抽稀,以减少存储容量。
# cv2.CHAIN_APPROX_TC89_L1: 使用 Teh-Chin 链逼近算法中的 L1 范数,以减少存储容量。
# cv2.CHAIN_APPROX_TC89_KCOS: 使用 Teh-Chin 链逼近算法中的 KCOS 范数,以减少存储容量。
# 输出参数:
# contours: 检测到的轮廓列表,每个轮廓是一个点的列表。
# 轮廓点没有固定是左上、右下或某个角,而是自上而下、从左到右扫描整个图像。找到前景区域的第一个边界点(通常是白色255区域)
# hierarchy: 轮廓的层次结构,一般用不到,可以忽略。
#
# 备注2:函数在opencv2只返回两个值:contours, hierarchy。
# 备注3:函数在opencv3会返回三个值:image, countours, hierarchy
#################################################################################################################"""
"""#################################################################################################################
# 函数功能:用于在图像上绘制轮廓。
# 函数说明:cv2.drawContours(image, contours, contourIdx, color, thickness=1, lineType=cv2.LINE_8, hierarchy=None, maxLevel=None, offset=None)
# 参数说明:
# image: 要绘制轮廓的图像,可以是单通道或多通道的图像。
# contours: 要绘制的轮廓列表,通常通过 cv2.findContours 函数获取。
# contourIdx: 要绘制的轮廓索引,如果为负数则绘制所有轮廓。
# color: 轮廓的颜色,通常是一个元组,如 (0, 255, 0) 表示绿色。
# thickness: 轮廓线的粗细,如果为负数或 cv2.FILLED 则填充轮廓区域。
# lineType: 线的类型
# cv2.LINE_4:4连接线。
# cv2.LINE_8:8连接线。
# cv2.LINE_AA:抗锯齿线。
# hierarchy: 轮廓的层级结构,一般由 cv2.findContours 函数返回,可选参数。
# maxLevel: 要绘制的轮廓的最大层级,一般由 cv2.findContours 函数返回,可选参数。
# offset: 轮廓偏移量,一般不需要设置,可选参数。
#################################################################################################################"""
# -*- coding: utf-8 -*-
# 作者: 胖墩会武术
# 日期: 1994-08-21
# OpenCV图像处理: https://blog.csdn.net/shinuone/article/details/126022763
(2)轮廓的基本属性(轮廓面积 + 轮廓周长) —— cv2.contourArea()、cv2.arcLength()
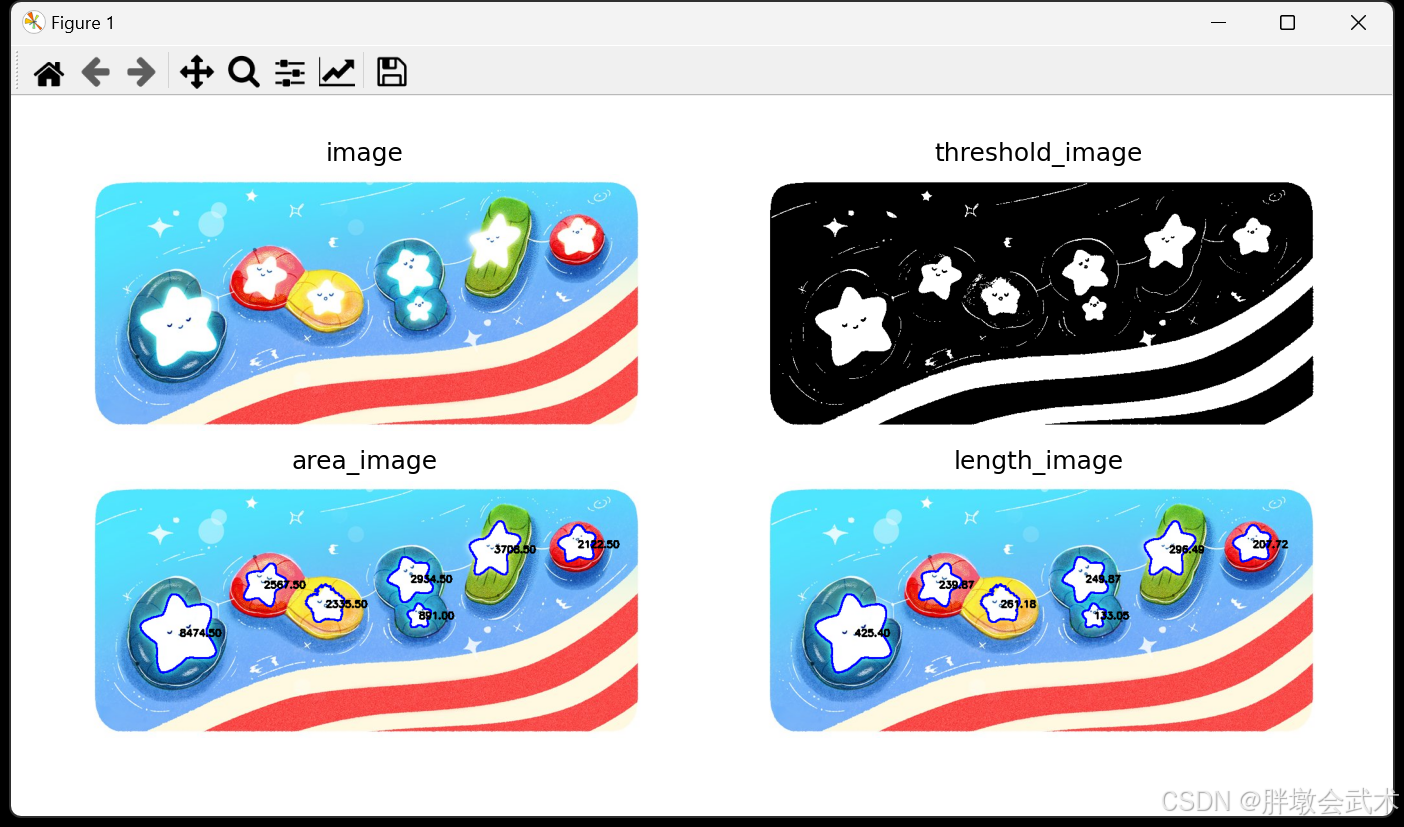
import cv2 # opencv读取图像默认为BGR
import matplotlib.pyplot as plt # matplotlib显示图像默认为RGB
# 读取图像和预处理
image = cv2.imread(r"F:\py\image.jpg")
image_gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
_, threshold_image = cv2.threshold(image_gray, 225, 255, cv2.THRESH_BINARY)
# 轮廓检测
contours, _ = cv2.findContours(threshold_image, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
print("Contours:", len(contours))
# 用于matplotlib显示的图像
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
area_image = image.copy() # 拟合椭圆
length_image = image.copy() # 拟合直线
#######################################################
# 从contours列表中,找到面积最大的轮廓(即最大的封闭区域)。
largest_contour = max(contours, key=cv2.contourArea)
largest_area = cv2.contourArea(largest_contour)
largest_length = cv2.arcLength(largest_contour, True)
print("Largest contour area:", largest_area, "Largest contour length:", largest_length)
# 面积最大 ≠ 周长最大(可能不是同一个轮廓)
#######################################################
num = 0 # 计数器
for cnt in contours:
area = cv2.contourArea(cnt)
length = cv2.arcLength(cnt, True)
if 10000 > area > 500: # 只处理较大的轮廓
num += 1
print("num:", num, "Contour area:", area, "Contour length:", length)
# 完整轮廓
cv2.drawContours(area_image, [cnt], -1, (0, 0, 255), 2)
cv2.drawContours(length_image, [cnt], -1, (0, 0, 255), 2)
# 计算轮廓的质心
M = cv2.moments(cnt)
if M["m00"] != 0:
cx = int(M["m10"] / M["m00"])
cy = int(M["m01"] / M["m00"])
else:
cx, cy = 0, 0
# 绘制文本(面积和周长)
cv2.putText(img=area_image, text=f'{area:.2f}', org=(cx, cy + 5), fontFace=cv2.FONT_HERSHEY_SIMPLEX, fontScale=0.5, color=(0, 0, 0), thickness=2)
cv2.putText(img=length_image, text=f'{length:.2f}', org=(cx, cy + 5), fontFace=cv2.FONT_HERSHEY_SIMPLEX, fontScale=0.5, color=(0, 0, 0), thickness=2)
# 显示结果
plt.subplot(2, 2, 1), plt.imshow(image), plt.title("image"), plt.axis('off')
plt.subplot(2, 2, 2), plt.imshow(threshold_image, cmap='gray'), plt.title("threshold_image"), plt.axis('off')
plt.subplot(2, 2, 3), plt.imshow(area_image), plt.title("area_image"), plt.axis('off')
plt.subplot(2, 2, 4), plt.imshow(length_image), plt.title("length_image"), plt.axis('off')
plt.tight_layout()
plt.show()
"""
Contours: 91
Largest contour area: 12721.0 Largest contour length: 1179.7787796258926
num: 1 Contour area: 3099.0 Contour length: 397.5634878873825
num: 2 Contour area: 4682.5 Contour length: 316.49242067337036
num: 3 Contour area: 1221.5 Contour length: 152.12489020824432
num: 4 Contour area: 1400.5 Contour length: 172.26702535152435
num: 5 Contour area: 1591.0 Contour length: 182.50966584682465
num: 6 Contour area: 1135.5 Contour length: 147.2964631319046
num: 7 Contour area: 2051.5 Contour length: 219.3797231912613
"""
#################################################################################################################
# 函数功能:计算轮廓的面积。
# 函数说明:area = cv2.contourArea(contour, oriented=False)
# 参数说明:
# contour: 输入的轮廓,可以是一个点的列表或numpy数组。
# oriented: 布尔值,指示是否返回带有方向的面积。如果为 True,则返回带方向的面积;如果为 False,则返回无方向的面积(绝对值)。
# 返回参数:
# area: 轮廓的面积,单位为像素²。
#################################################################################################################
#################################################################################################################
# 函数功能:用于计算轮廓的周长或曲线的长度。
# 函数说明:length = cv2.arcLength(curve, closed)
# 参数说明:
# curve: 输入的轮廓或曲线,通常是一个包含点的列表。
# closed: 一个布尔值,指示曲线是否闭合。如果是闭合曲线(如多边形轮廓),则设置为 True,否则设置为 False。
# 返回参数:
# length 轮廓的长度(周长)。
#################################################################################################################
# -*- coding: utf-8 -*-
# 作者: 胖墩会武术
# 日期: 1994-08-21
# OpenCV图像处理: https://blog.csdn.net/shinuone/article/details/126022763
(3)轮廓的外接边界框(多边形近似 + 凸包 + 最小外接矩形 + 最小旋转外接矩形 + 最小外接圆 + 最小外接三角形) —— cv2.approxPolyDP()、cv2.convexHull()、cv2.boundingRect()、cv2.minAreaRect()、cv2.minEnclosingCircle()、cv2.minEnclosingTriangle()
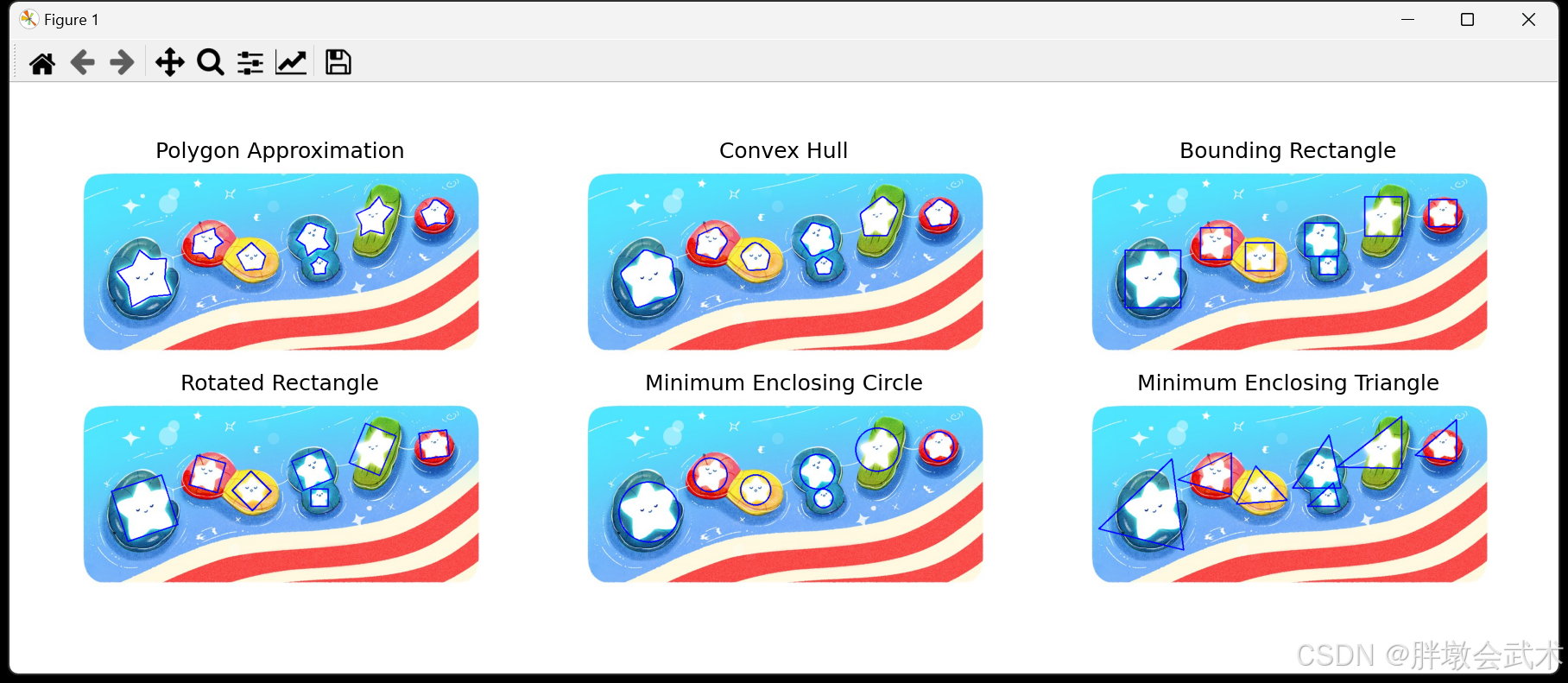
import numpy as np
import cv2 # opencv读取图像默认为BGR
import matplotlib.pyplot as plt # matplotlib显示图像默认为RGB
# 读取图像和预处理
image = cv2.imread(r"F:\py\image.jpg")
image_gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
_, threshold_image = cv2.threshold(image_gray, 225, 255, cv2.THRESH_BINARY)
# 轮廓检测
contours, _ = cv2.findContours(threshold_image, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
# 原图的不同绘制效果副本
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
approx_poly_image = image.copy() # 多边形近似
convex_hull_image = image.copy() # 凸包
min_rect_image = image.copy() # 最小外接矩形
rot_rect_image = image.copy() # 最小旋转外接矩形
min_circle_image = image.copy() # 最小外接圆
min_triangle_image = image.copy() # 最小外接三角形
for cnt in contours:
area = cv2.contourArea(cnt)
length = cv2.arcLength(cnt, True)
if 10000 > area > 500: # 只处理较大的轮廓
print(area)
# 多边形近似
epsilon = 0.02 * cv2.arcLength(cnt, True)
approx = cv2.approxPolyDP(cnt, epsilon, True)
cv2.drawContours(approx_poly_image, [approx], -1, (0, 0, 255), 2)
# 凸包
hull = cv2.convexHull(cnt)
cv2.drawContours(convex_hull_image, [hull], -1, (0, 0, 255), 2)
# 最小外接矩形
x, y, w, h = cv2.boundingRect(cnt)
cv2.rectangle(min_rect_image, (x, y), (x + w, y + h), (0, 0, 255), 2)
# 最小旋转外接矩形
rot_rect = cv2.minAreaRect(cnt)
box = cv2.boxPoints(rot_rect)
box = np.int0(box)
cv2.drawContours(rot_rect_image, [box], 0, (0, 0, 255), 2)
# 最小外接圆
(x, y), radius = cv2.minEnclosingCircle(cnt)
center = (int(x), int(y))
radius = int(radius)
cv2.circle(min_circle_image, center, radius, (0, 0, 255), 2)
# 最小外接三角形
ret, triangle = cv2.minEnclosingTriangle(cnt)
cv2.drawContours(min_triangle_image, [np.int32(triangle)], -1, (0, 0, 255), 2)
# 显示结果
plt.subplot(2, 3, 1), plt.imshow(approx_poly_image), plt.title("Polygon Approximation"), plt.axis('off')
plt.subplot(2, 3, 2), plt.imshow(convex_hull_image), plt.title("Convex Hull"), plt.axis('off')
plt.subplot(2, 3, 3), plt.imshow(min_rect_image), plt.title("Bounding Rectangle"), plt.axis('off')
plt.subplot(2, 3, 4), plt.imshow(rot_rect_image), plt.title("Rotated Rectangle"), plt.axis('off')
plt.subplot(2, 3, 5), plt.imshow(min_circle_image), plt.title("Minimum Enclosing Circle"), plt.axis('off')
plt.subplot(2, 3, 6), plt.imshow(min_triangle_image), plt.title("Minimum Enclosing Triangle"), plt.axis('off')
plt.tight_layout()
plt.show()
#################################################################################################################
# 函数功能:用于对轮廓进行多边形近似曲线。
# 函数说明:approximated_contour = cv2.approxPolyDP(curve, epsilon, closed)
# 输入参数:
# curve: 输入的轮廓,通常是一个包含点的列表。
# epsilon: 逼近精度参数,表示逼近结果与原始曲线之间的最大距离。较小的 epsilon 值会产生更精确的逼近结果。
# closed: 一个布尔值,指示轮廓是否闭合。如果是闭合轮廓(如多边形轮廓),则设置为 True,否则设置为 False。
# 返回参数:
# approximated_contour:逼近后的多边形轮廓。
#################################################################################################################
"""#################################################################################################################
# 函数功能:计算轮廓的凸包。
# 函数说明:hull = cv2.convexHull(points, hull=None, clockwise=False, returnPoints=True)
# 参数说明:
# points: 输入的轮廓点列表。
# hull: 生成的凸包点的列表,可选参数。
# clockwise:如果为 True,则输出的凸包按顺时针方向排列;如果为 False,则按逆时针方向排列。
# returnPoints:如果为 True,返回凸包的点;如果为 False,返回凸包的索引。
# 返回参数:
# hull 凸包点列表或索引列表。
#################################################################################################################"""
"""#################################################################################################################
# 函数功能:计算最小外接矩形。
# 函数说明:x, y, w, h = cv2.boundingRect(points)
# 参数说明:
# points: 输入的轮廓点列表。
# 返回参数:
# x,y: 矩形左上角的坐标。
# w,h: 矩形的宽和高。
#################################################################################################################"""
"""#################################################################################################################
# 函数功能:计算最小外接旋转矩形。
# 函数说明:rotRect = cv2.minAreaRect(points)
# 参数说明:
# points: 输入的轮廓点列表。
# 返回参数:
# rotRect 包含矩形中心坐标、宽高和旋转角度的元组。
#################################################################################################################"""
#################################################################################################################
# 函数功能:计算最小外接圆。
# 函数说明:center, radius = cv2.minEnclosingCircle(points)
# 参数说明:
# points: 输入的轮廓点列表。
# 返回参数:
# center: 圆心坐标。
# radius: 圆的半径。
#################################################################################################################
#################################################################################################################
# 函数功能:计算最小外接三角形。
# 函数说明:ret, triangle = cv2.minEnclosingTriangle(points)
# 参数说明:
# points: 输入的轮廓点列表。
# 返回参数:
# ret: 布尔值,指示计算是否成功。
# triangle: 包含三角形顶点坐标的数组。
#################################################################################################################
# -*- coding: utf-8 -*-
# 作者: 胖墩会武术
# 日期: 1994-08-21
# OpenCV图像处理: https://blog.csdn.net/shinuone/article/details/126022763
(4)轮廓的最优拟合(拟合椭圆 + 拟合直线) —— cv2.fitEllipse()、cv2.fitLine()
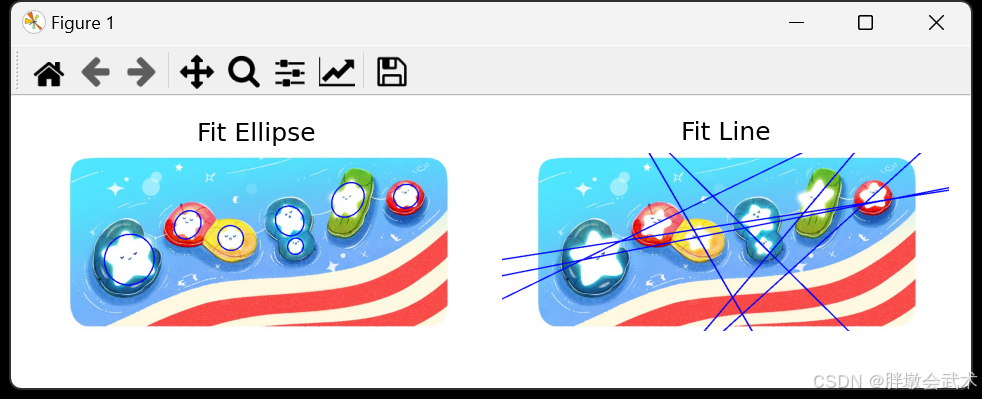
import cv2 # opencv读取图像默认为BGR
import matplotlib.pyplot as plt # matplotlib显示图像默认为RGB
# 读取图像和预处理
image = cv2.imread(r"F:\py\image.jpg")
image_gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
_, threshold_image = cv2.threshold(image_gray, 225, 255, cv2.THRESH_BINARY)
# 轮廓检测
contours, _ = cv2.findContours(threshold_image, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
# 原图的不同绘制效果副本
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
ellipse_image = image.copy() # 拟合椭圆
line_image = image.copy() # 拟合直线
for cnt in contours:
area = cv2.contourArea(cnt)
length = cv2.arcLength(cnt, True)
if 10000 > area > 500: # 只处理较大的轮廓
print(area)
# 最优拟合椭圆
if len(cnt) >= 5: # 拟合椭圆需要至少5个点
ellipse = cv2.fitEllipse(cnt)
cv2.ellipse(ellipse_image, ellipse, (0, 0, 255), 2)
# 拟合直线
if len(cnt) >= 2: # 拟合直线需要至少2个点
line = cv2.fitLine(cnt, cv2.DIST_L2, 0, 0.01, 0.01)
vx, vy, x0, y0 = line
left_point = (int(x0 - 1000 * vx), int(y0 - 1000 * vy))
right_point = (int(x0 + 1000 * vx), int(y0 + 1000 * vy))
cv2.line(line_image, left_point, right_point, (0, 0, 255), 2)
# 显示结果
plt.subplot(1, 2, 1), plt.imshow(ellipse_image), plt.title("Fit Ellipse"), plt.axis('off')
plt.subplot(1, 2, 2), plt.imshow(line_image), plt.title("Fit Line"), plt.axis('off')
plt.tight_layout()
plt.show()
#################################################################################################################
# 函数功能:拟合椭圆。
# 函数说明:ellipse = cv2.fitEllipse(points)
# 参数说明:
# points: 输入的轮廓点列表。
# 返回参数:
# ellipse: 包含椭圆参数的元组。
#################################################################################################################
#################################################################################################################
# 函数功能:拟合直线。
# 函数说明:line = cv2.fitLine(points, distType, param, reps, aeps)
# 参数说明:
# points: 输入的轮廓点列表。
# distType: 距离类型,通常使用 cv2.DIST_L2。
# param: 与距离类型相关的参数,一般设置为0。
# reps: 设置线段的精度。
# aeps: 设置点的精度。
# 返回参数:
# line: 拟合的直线参数。
#################################################################################################################
# -*- coding: utf-8 -*-
# 作者: 胖墩会武术
# 日期: 1994-08-21
# OpenCV图像处理: https://blog.csdn.net/shinuone/article/details/126022763
(5)轮廓的最大内接圆(自定义实现)

最大内接圆(Maximum Inscribed Circle):是在一个给定的形状(通常是一个轮廓或多边形)内,最大可能的圆,该圆完全位于该形状内,且与形状的边界相切。
import cv2
import numpy as np
def draw_maximum_inscribed_circle(image, contour, hierarchy, text, font_size=0.4, thickness=1, font_color=(255, 255, 255)):
"""
在给定的轮廓内绘制最大内接圆,并将文本绘制在圆心处,排除内部空心的干扰。
"""
# 创建一个掩膜,用于计算距离变换
mask = np.zeros_like(image)
cv2.drawContours(mask, [contour], -1, 255, thickness=cv2.FILLED)
########################################################################################
mask = mask.astype(np.uint8) # 确保类型为 8 位
if mask.ndim == 3: # 如果是多通道,转换为单通道
mask = cv2.cvtColor(mask, cv2.COLOR_BGR2GRAY)
########################################################################################
# 计算距离变换
dist_transform = cv2.distanceTransform(mask, cv2.DIST_L2, 5)
# 获取最大内接圆的圆心和半径
min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(dist_transform) # 最大值位置即为圆心
radius = max_val # 半径
center = max_loc # 圆心
# 在原图上绘制圆
cv2.circle(image, center, int(radius), font_color, thickness)
# 计算文本的大小和位置
(text_width, text_height), baseline = cv2.getTextSize(text, cv2.FONT_HERSHEY_SIMPLEX, font_size, thickness)
text_x = center[0] - text_width // 2 # 计算文本位置,使其居中
text_y = center[1] + text_height // 2
cv2.putText(image, text, (text_x, text_y), cv2.FONT_HERSHEY_SIMPLEX, font_size, font_color, thickness, cv2.LINE_AA)
return image
if __name__ == '__main__':
image = cv2.imread(r"F:\py\image.jpg")
image_gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
_, threshold_image = cv2.threshold(image_gray, 225, 255, cv2.THRESH_BINARY)
contours, hierarchy = cv2.findContours(threshold_image, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
for i, cnt in enumerate(contours):
area = cv2.contourArea(cnt)
length = cv2.arcLength(cnt, True)
if 10000 > area > 500: # 只处理较大的轮廓
print(area)
text = f"" # 绘制文本
image = draw_maximum_inscribed_circle(image, cnt, hierarchy, text, font_size=0.4, thickness=1, font_color=(255, 0, 0))
cv2.imshow("Result", image)
cv2.waitKey(0)
cv2.destroyAllWindows()
(5.1)距离变换:cv2.distanceTransform
import cv2
import numpy as np
# 创建一个简单的二值图像
binary_image = np.zeros((100, 100), dtype=np.uint8)
cv2.circle(binary_image, (50, 50), 30, 255, -1) # 绘制一个白色圆形
# 计算距离变换
distance_image = cv2.distanceTransform(binary_image, distanceType=cv2.DIST_L2, maskSize=5)
import matplotlib.pyplot as plt
plt.subplot(121), plt.imshow(binary_image), plt.title('binary_image')
plt.subplot(122), plt.imshow(distance_image), plt.title('distance_image')
plt.show()
"""#############################################################################################
# 函数功能:计算二值图像中每个非零像素到最近零像素的距离变换。
# 函数说明:cv2.distanceTransform(src, distanceType, maskSize)
# 参数说明:
# src:输入图像。必须是8位单通道二值图像,其中非零像素被视为前景,零像素被视为背景。
# distanceType:距离类型,用于指定计算距离的方法。常见的取值包括:
# - cv2.DIST_L1:使用 L1 距离(“曼哈顿”距离)。
# - cv2.DIST_L2:使用 L2 距离(“欧氏”距离)。
# - cv2.DIST_C:使用棋盘距离。
# maskSize:使用的距离变换掩模的大小。常见的值为 3 或 5。对于 cv2.DIST_L1 或 cv2.DIST_C,可以设置为 0。
# 返回值:
# 返回一个与输入图像大小相同的单通道浮点图像,其中每个像素的值表示到最近零像素的距离。
#############################################################################################"""
(5.2)排除内孔洞
import cv2
import numpy as np
def draw_maximum_inscribed_circle(image, contour, hierarchy, text, font_size=0.4, font_color=(255, 255, 255)):
"""
在给定的轮廓内绘制最大内接圆,并将文本绘制在圆心处,排除内部空心的干扰。
"""
# 创建一个掩膜,用于计算距离变换
mask = np.zeros_like(image)
cv2.drawContours(mask, [contour], -1, 255, thickness=cv2.FILLED)
########################################################################################
# 排除内孔洞
if hierarchy is not None:
child_index = hierarchy[0][0][2] # 获取当前轮廓的子轮廓索引
while child_index != -1:
# 填充子轮廓(内孔洞)
cv2.drawContours(mask, [contours[child_index]], -1, 0, thickness=cv2.FILLED)
child_index = hierarchy[0][child_index][0] # 移动到下一个子轮廓
########################################################################################
# 计算距离变换
dist_transform = cv2.distanceTransform(mask, cv2.DIST_L2, 5)
# 获取最大内接圆的圆心和半径
min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(dist_transform) # 最大值位置即为圆心
radius = max_val # 半径
center = max_loc # 圆心
# 在原图上绘制圆
cv2.circle(image, center, int(radius), (0, 255, 0), 2) # 绿色圆
# 计算文本的大小和位置
(text_width, text_height), baseline = cv2.getTextSize(text, cv2.FONT_HERSHEY_SIMPLEX, font_size, 1)
text_x = center[0] - text_width // 2 # 计算文本位置,使其居中
text_y = center[1] + text_height // 2
# 绘制文本
cv2.putText(image, text, (text_x, text_y), cv2.FONT_HERSHEY_SIMPLEX, font_size, font_color, 1, cv2.LINE_AA)
return image
# 示例使用
if __name__ == "__main__":
# 创建一个示例月牙形状的二值图像
mask = np.zeros((500, 800), dtype=np.uint8)
cv2.ellipse(mask, (150, 150), (100, 50), 0, 0, 270, 255, -1)
cv2.ellipse(mask, (400, 150), (50, 50), 0, 0, 180, 255, -1)
cv2.ellipse(mask, (150, 250), (200, 200), 0, 0, 90, 255, -1)
cv2.ellipse(mask, (550, 250), (200, 200), 0, 0, 90, 255, -1)
cv2.ellipse(mask, (650, 350), (50, 50), 0, 0, 90, 0, -1)
# 找到所有轮廓及其层级关系
contours, hierarchy = cv2.findContours(mask, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE) # 用于排除内孔洞
# contours, hierarchy = cv2.findContours(mask, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
# 在每个轮廓中绘制最大内接圆并显示文本
result_image = mask.copy()
for i, contour in enumerate(contours):
# 排除面积过小的轮廓
if cv2.contourArea(contour) > 200:
text = f"Shape {i + 1}"
result_image = draw_maximum_inscribed_circle(result_image, contour, hierarchy, text, font_size=0.6,
font_color=(0, 255, 255))
# 显示结果
cv2.imshow("Result", result_image)
cv2.waitKey(0)
cv2.destroyAllWindows()
2.13、模板匹配 —— cv2.matchTemplate()、cv2.minMaxLoc()

############################################################################################
# 模板匹配:在原始图像上,通过滑动匹配的方式,计算模板与(模板覆盖的图像)的相似程度;
#
# 原图形大小: AxB; 而模板大小: axb; 则输出结果的矩阵大小: (A-a+1)x(B-b+1)
############################################################################################
import cv2 # opencv读取图像默认为BGR
import matplotlib.pyplot as plt # matplotlib显示图像默认为RGB
image = cv2.imread(r'F:\py\image', 0) # 读取目标图像
template = cv2.imread(r'F:\py\image', 0) # 读取模板图像
height, width = template.shape[::1] # 获得模板图像的高宽尺寸
#############################################################
# 如果模板匹配方法是平方差或者归一化平方差,要用min_loc; 其余用max_loc
#############################################################
"""模板匹配模式:cv2.TM_SQDIFF"""
res1 = cv2.matchTemplate(image, template, cv2.TM_SQDIFF)
min_val1, max_val1, min_loc1, max_loc1 = cv2.minMaxLoc(res1)
top_left1 = min_loc1
bottom_right1 = (top_left1[0] + width, top_left1[1] + height)
"""模板匹配模式:cv2.TM_CCORR"""
res2 = cv2.matchTemplate(image, template, cv2.TM_CCORR)
min_val2, max_val2, min_loc2, max_loc2 = cv2.minMaxLoc(res2)
top_left2 = max_loc2
bottom_right2 = (top_left2[0] + width, top_left2[1] + height)
"""模板匹配模式:cv2.TM_CCOEFF"""
res3 = cv2.matchTemplate(image, template, cv2.TM_CCOEFF)
min_val3, max_val3, min_loc3, max_loc3 = cv2.minMaxLoc(res3)
top_left3 = max_loc3
bottom_right3 = (top_left3[0] + width, top_left3[1] + height)
"""模板匹配模式:cv2.TM_SQDIFF_NORMED"""
res4 = cv2.matchTemplate(image, template, cv2.TM_SQDIFF_NORMED)
min_val4, max_val4, min_loc4, max_loc4 = cv2.minMaxLoc(res4)
top_left4 = min_loc4
bottom_right4 = (top_left4[0] + width, top_left4[1] + height)
"""模板匹配模式:cv2.TM_CCORR_NORMED"""
res5 = cv2.matchTemplate(image, template, cv2.TM_CCORR_NORMED)
min_val5, max_val5, min_loc5, max_loc5 = cv2.minMaxLoc(res5)
top_left5 = max_loc5
bottom_right5 = (top_left5[0] + width, top_left5[1] + height)
"""模板匹配模式:cv2.TM_CCOEFF_NORMED"""
res6 = cv2.matchTemplate(image, template, cv2.TM_CCOEFF_NORMED)
min_val6, max_val6, min_loc6, max_loc6 = cv2.minMaxLoc(res6)
top_left6 = max_loc6
bottom_right6 = (top_left6[0] + width, top_left6[1] + height)
# 绘制矩形
image1 = image.copy(); image2 = image.copy(); image3 = image.copy()
image4 = image.copy(); image5 = image.copy(); image6 = image.copy()
cv2.rectangle(image1, top_left1, bottom_right1, 255, 2)
cv2.rectangle(image2, top_left2, bottom_right2, 255, 2)
cv2.rectangle(image3, top_left3, bottom_right3, 255, 2)
cv2.rectangle(image4, top_left4, bottom_right4, 255, 2)
cv2.rectangle(image5, top_left5, bottom_right5, 255, 2)
cv2.rectangle(image6, top_left6, bottom_right6, 255, 2)
##############################################
plt.subplot(231), plt.imshow(image1, cmap='gray'), plt.axis('off'), plt.title('cv2.TM_SQDIFF')
plt.subplot(232), plt.imshow(image2, cmap='gray'), plt.axis('off'), plt.title('cv2.TM_CCORR')
plt.subplot(233), plt.imshow(image3, cmap='gray'), plt.axis('off'), plt.title('cv2.TM_CCOEFF')
plt.subplot(234), plt.imshow(image4, cmap='gray'), plt.axis('off'), plt.title('cv2.TM_SQDIFF_NORMED')
plt.subplot(235), plt.imshow(image5, cmap='gray'), plt.axis('off'), plt.title('cv2.TM_CCORR_NORMED')
plt.subplot(236), plt.imshow(image6, cmap='gray'), plt.axis('off'), plt.title('cv2.TM_CCOEFF_NORMED')
plt.show()
"""#########################################################################################################
# 函数功能:模板匹配 ———— 在输入图像上滑动目标模板,并计算目标模板与图像的匹配程度来实现目标检测。
# 函数说明:cv2.matchTemplate(image, template, method)
# 参数说明:
# image: 输入图像,需要在其中搜索目标模板。
# templ: 目标模板,需要在输入图像中匹配的部分。
# method: 匹配方法
# cv2.TM_SQDIFF: 计算平方差。 计算结果越接近0,越相关
# cv2.TM_CCORR: 计算相关性。 计算结果越大,越相关
# cv2.TM_CCOEFF: 计算相关系数。 计算结果越大,越相关
# cv2.TM_SQDIFF_NORMED: 计算(归一化)平方差。 计算结果越接近0,越相关
# cv2.TM_CCORR_NORMED: 计算(归一化)相关性。 计算结果越接近1,越相关
# cv2.TM_CCOEFF_NORMED: 计算(归一化)相关系数。 计算结果越接近1,越相关
# 备注:归一化效果更好
#########################################################################################################"""
"""#########################################################################################################
# 函数功能:用于找到数组中的最小值和最大值,以及它们的位置。
# 函数说明:min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(ret)
# 输入参数:
# ret cv2.matchTemplate函数返回的矩阵,即匹配结果图像。
# 返回参数:
# min_val:匹配结果图像中的最小值。
# max_val:匹配结果图像中的最大值。
# min_loc:最小值对应的位置(x,y)。
# max_loc:最大值对应的位置(x,y)。
#
# 备注:如果模板匹配方法是平方差或者归一化平方差,则使用min_loc; 否则使用max_loc
#########################################################################################################"""
# -*- coding: utf-8 -*-
# 作者: 胖墩会武术
# 日期: 1994-08-21
# OpenCV图像处理: https://blog.csdn.net/shinuone/article/details/126022763
2.14、直方图 + 直方图均衡化 + 自适应 —— cv2.calcHist()、cv2.equalizeHist()、cv2.createCLAHE()

import cv2 # opencv读取图像默认为BGR
import matplotlib.pyplot as plt # matplotlib显示图像默认为RGB
# (1)单通道的直方图(两种绘制方法)
gray_image = cv2.imread(r'F:\py\image.jpg', 0) # 0表示灰度图
hist = cv2.calcHist([gray_image], [0], None, [256], [0, 256]) # 计算直方图
# image.ravel() 将图片转化成一维数组; 256 是BIN的数目
plt.subplot(121), plt.hist(gray_image.ravel(), 256), plt.title('Gray Image Histogram(plt.hist)')
plt.subplot(122), plt.plot(hist), plt.title('Gray Image Histogram(plt.plot)')
plt.show()
# (2)多通道的直方图
color_image = cv2.imread(r'F:\py\image.jpg', 1) # 1表示彩色图
hist_b = cv2.calcHist([color_image], [0], None, [256], [0, 256]) # 蓝色通道
hist_g = cv2.calcHist([color_image], [1], None, [256], [0, 256]) # 绿色通道
hist_r = cv2.calcHist([color_image], [2], None, [256], [0, 256]) # 红色通道
plt.plot(hist_b, color='b', label='hist_b')
plt.plot(hist_g, color='g', label='hist_g')
plt.plot(hist_r, color='r', label='hist_r')
plt.title('Color Image Histogram')
plt.legend() # 添加图例
plt.show()
#################################################################################
# (3)直方图均衡化
equ = cv2.equalizeHist(gray_image)
# (4)自适应直方图均衡化
clahe = cv2.createCLAHE(clipLimit=2.0, tileGridSize=(8, 8))
res_clahe = clahe.apply(gray_image)
#################################################################################
equ_hist = cv2.calcHist([equ], [0], None, [256], [0, 256]) # 计算直方图
clahe_hist = cv2.calcHist([res_clahe], [0], None, [256], [0, 256]) # 计算直方图
plt.plot(hist, color='b', label='hist')
plt.plot(equ_hist, color='g', label='equ_hist')
plt.plot(clahe_hist, color='r', label='clahe_hist')
plt.title('Histogram')
plt.legend() # 添加图例
plt.show()
plt.subplot(131), plt.imshow(gray_image, cmap='gray'), plt.title('gray_image')
plt.subplot(132), plt.imshow(equ, cmap='gray'), plt.title('cv2.equalizeHist')
plt.subplot(133), plt.imshow(res_clahe, cmap='gray'), plt.title('cv2.createCLAHE')
plt.show()
"""####################################################################################################################
# 函数功能:用于计算图像的直方图。
# 函数说明:hist = cv2.calcHist(images, channels, mask, histSize, ranges)
# 参数说明:
# images:输入图像,可以是一个图像列表或单个图像。
# channels:要计算直方图的通道索引,通常是一个列表,指定图像的哪一通道(如灰度图像为 [0])。
# mask:掩模,指定计算直方图的区域。可以为 None,表示计算整个图像的直方图。
# histSize:每个通道的直方图的箱子数量,通常是一个列表,例如 [256] 表示 256 个箱子。
# ranges:直方图计算的值范围,通常是一个列表,例如 [0, 256]。
# 返回值:
# hist:计算出的直方图,类型为 NumPy 数组,形状为 (histSize[0])。
# 功能描述:
# - 直方图是一种统计图表,用于表示图像中各个像素灰度级别的分布情况。
# - 直方图可以用来描述图像的亮度分布、对比度等特征,常用于图像增强和阈值分割等。
####################################################################################################################"""
# 直方图均衡化(HE,Histogram Equalization)
"""####################################################################################################################
# 函数功能:直方图均衡化 ———— 通过均匀分布像素值,提高图像的对比度,特别是对于光照条件不均匀的图像。
# 函数说明:equalized_img = cv2.equalizeHist(src)
# 参数说明:
# src:只支持 8 位单通道图像(即灰度)。
# 返回值:
# equalized_img:均衡化后的灰度图像,图像的对比度得到增强。
# 功能描述:
# - 使得图像在视觉上更加清晰,细节更加明显。
# - 适用于图像预处理,特别是在后续处理(如特征提取和物体检测)之前。
####################################################################################################################"""
# 限制对比度自适应直方图均衡化(CLAHE,Contrast Limited Adaptive Histogram Equalization)
"""####################################################################################################################
# 函数功能:创建一个 CLAHE 对象 ———— 通过将图像分为多个小块,独立处理每个小块的直方图。用于提升局部区域的对比度和细节,同时避免过度增强(如噪声放大)。
# 函数说明:clahe = cv2.createCLAHE(clipLimit=2.0, tileGridSize=(8, 8))
# 参数说明:
# clipLimit:对比度限制阈值,限制了每个小块中直方图的最大累积频率,防止噪声放大。默认值为 2.0。
# (1)低 clipLimit 值:会导致对比度增强较少,因为更多的局部区域直方图会被剪切,从而保持灰度值的平滑过渡。
# (2)高 clipLimit 值:会增强对比度,允许更多的局部细节被突出,但可能导致图像中的噪声也被放大,引入伪影。
# tileGridSize:每个小块的大小,指定分块的网格大小。默认值为 (8, 8),表示将图像分为 8x8 的小块。
# 返回值:
# 返回一个 CLAHE 对象,可以用来对图像进行局部直方图均衡化。
#
# 工作原理:
# (1)图像分块:将图像划分为多个小块(称为“tiles”)
# (2)计算直方图:对每个小块计算其灰度值的直方图。
# (3)频率截断:在每个小块的直方图中,若某个灰度值的频率超过了clipLimit,则将该频率截断到 clipLimit,并记录超出的部分。
# (4)频率重分配:将截断的多余频率(比例或平均)分配到当前小块的其他灰度值上,确保频率的总和保持一致。
# (5)重新计算直方图:经过重分配后的直方图会被用来计算新的累积分布函数(CDF),以便用于映射原始图像的像素值。
# (6)像素值映射:使用更新后的 CDF,将每个小块的原始像素值映射到新的灰度值,得到均衡化后的图像块。
# (7)合成输出:将所有处理过的小块合成最终的均衡化图像。
####################################################################################################################
# 函数功能:对输入图像应用 CLAHE 对象
# 函数说明:output = clahe.apply(src)
# 参数说明:
# src:输入的单通道 8 位灰度图像。
# 返回值:
# output:经过 CLAHE 处理后的图像,图像的对比度得到增强。
####################################################################################################################"""
# -*- coding: utf-8 -*-
# 作者: 胖墩会武术
# 日期: 1994-08-21
# OpenCV图像处理: https://blog.csdn.net/shinuone/article/details/126022763
2.15、傅里叶变换 + 低通滤波 + 高通滤波 —— cv2.dft()、cv2.idft()、np.fft.fftshift()、np.fft.ifftshift()、cv2.magnitud()
傅里叶变换
- 时域分析:以时间作为参照来观察动态世界的方法。
- 世间万物都在随着时间不停的改变,并且永远不会静止下来。但在频域中,你会发现世界是静止的、永恒不变的。
- 傅里叶告诉我们:任何周期函数,都可以看作是不同振幅,不同相位正弦波的叠加。
- 举例:利用对不同琴键不同力度,不同时间点的敲击,可以组合出任何一首乐曲。
- 傅里叶分析可分为傅里叶级数(Fourier Serie)和傅里叶变换(Fourier Transformation)。
傅里叶变换的作用
(1)高频:变化剧烈的灰度分量,例如:边界/图像的轮廓
(2)低频:变化缓慢的灰度分量,例如:一片大海
滤波器
(1)低通滤波器:通低频阻高频(图像模糊)
(2)高通滤波器:阻低频通高频(图像细节增强)

import numpy as np
import cv2 # opencv读取图像默认为BGR
import matplotlib.pyplot as plt # matplotlib显示图像默认为RGB
# (1)频谱图像设计
img = cv2.imread(r'F:\py\image.jpg', 0) # 0表示灰度图
dft = cv2.dft(np.float32(img), flags=cv2.DFT_COMPLEX_OUTPUT) # 傅里叶变换(np.float32 格式)
dft_shift = np.fft.fftshift(dft) # 移动到中心位置
magnitude_spectrum = 20*np.log(cv2.magnitude(dft_shift[:, :, 0],dft_shift[:, :, 1])) # 理解为固定公式即可
# 频谱:最中心的频率最小,像圆一样向外扩散,越来越大。# 备注:20*np.log(cv2.magnitude())
# (2)低通滤波设计
rows, cols = img.shape
crow, ccol = int(rows/2), int(cols/2) # 获取图像中心位置
mask_low = np.zeros((rows, cols, 2), np.uint8)
mask_low[crow-30:crow+30, ccol-30:ccol+30] = 1
fshift_low = dft_shift * mask_low
f_ishift_low = np.fft.ifftshift(fshift_low)
img_low = cv2.idft(f_ishift_low) # 逆傅里叶变换
img_low = cv2.magnitude(img_low[:, :, 0], img_low[:, :, 1]) # 频谱图像转灰度图像
# (3)高通滤波设计
mask_high = np.ones((rows, cols, 2), np.uint8)
mask_high[crow-30:crow+30, ccol-30:ccol+30] = 0
fshift_high = dft_shift * mask_high
f_ishift_high = np.fft.ifftshift(fshift_high)
img_high = cv2.idft(f_ishift_high) # 逆傅里叶变换
img_high = cv2.magnitude(img_high[:, :, 0], img_high[:, :, 1]) # 频谱图像转灰度图像
# (4)显示图像
plt.subplot(141), plt.imshow(img, cmap='gray'), plt.title('image_raw'), plt.xticks([]), plt.yticks([])
plt.subplot(142), plt.imshow(magnitude_spectrum, cmap='gray'), plt.title('image_Magnitude_Spectrum'), plt.xticks([]), plt.yticks([])
plt.subplot(143), plt.imshow(img_low, cmap='gray'), plt.title('image_Low_pass_filter'), plt.xticks([]), plt.yticks([])
plt.subplot(144), plt.imshow(img_high, cmap='gray'), plt.title('image_High_pass_filter'), plt.xticks([]), plt.yticks([])
plt.show()
"""#####################################################################################################
# 在OpenCV中,我们通过cv2.dft()来实现傅里叶变换,使用cv2.idft()来实现逆傅里叶变换。
# 注意1:变换后得到原始图像的频谱信息。其中:频率为0的部分(零分量)会在左上角,需要使用numpy.fft.fftshift()函数,将其移动到中间位置。
# 注意2:变换后的频谱图像是双通道的(实部,虚部)。需要使用cv2.magnitude函数,将幅度映射到灰度空间[0,255]内,使其以灰度图像显示出来。
##################################################
# 傅里叶变换:cv2.dft(np.float32, cv2.DFT_COMPLEX_OUTPUT)
# 输入参数:
# (1)输入图像需要先转换成np.float32 格式。
# (2)转换标识 - cv2.DFT_COMPLEX_OUTPUT - 用来输出一个复数阵列
##################################################
# 逆傅里叶变换:cv2.idft(dft_shift)
# 输入参数:
# 傅里叶变换后并位置转换后的频谱图像。
##################################################
# 频谱图像:cv2.magnitude(x-实部, y-虚部)
# 输入参数:
# (1)浮点型x坐标值(实部)
# (2)浮点型y坐标值(虚部)
# 备注:两个参数的必须具有相同的大小(size)
#####################################################################################################"""
# -*- coding: utf-8 -*-
# 作者: 胖墩会武术
# 日期: 1994-08-21
# OpenCV图像处理: https://blog.csdn.net/shinuone/article/details/126022763
2.16、Harris角点检测 —— cv2.cornerHarris() + cv2.KeyPoint() + cv2.drawKeypoints()

OpenCV提供了演示数据:https://github.com/opencv/opencv/tree/master/samples/data
import numpy as np
import cv2 # opencv读取图像默认为BGR
import matplotlib.pyplot as plt # matplotlib显示图像默认为RGB
# (1)加载图像
image = cv2.imread(r'picture/Black_and_white_chess.jpg')
image_gray = cv2.cvtColor(src=image, code=cv2.COLOR_BGR2GRAY) # 将图像转换为灰度图像
# (2)角点检测
image_harris = cv2.cornerHarris(src=image_gray, blockSize=2, ksize=3, k=0.04) # 创建 Harris 角点检测器对象
value = 0.01 * image_harris.max() # 最佳阈值因图而异
points = np.argwhere(image_harris > value).astype(np.float16) # 找到检测到的角点(若角点 > 角点最大值*0.001,则判断为角点)
keypoints = [cv2.KeyPoint(x[1], x[0], 1) for x in points] # 创建带有指定大小的关键点
image_result = cv2.drawKeypoints(image, keypoints, None, color=(0, 0, 255), flags=cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS) # 绘制检测到的角点
# (3)显示图像
print('image.shape:', image.shape)
print('image_harris.shape:', image_harris.shape)
plt.subplot(121), plt.imshow(cv2.cvtColor(image, cv2.COLOR_BGR2RGB)), plt.title('image')
plt.subplot(122), plt.imshow(cv2.cvtColor(image_result, cv2.COLOR_BGR2RGB)), plt.title('image_result')
plt.show()
"""#############################################################################################
# 函数功能:对图像进行 Harris 角点检测。
# 函数说明:dst = cv2.cornerHarris(src, blockSize, ksize, k, dst=None, borderType=None)
# 参数说明:
# src:输入图像,应为灰度图像(单通道图像)。
# blockSize:指定计算导数时要考虑的领域大小。它是用于 Sobel 求导的窗口大小,常为 3、5、7 等。一般取值为奇数,默认为 3。
# ksize:指定 Sobel 滤波器的孔径大小,常为 3。必须大于 1。默认为 3。
# k:Harris 角点检测参数,取值范围为 [0.04, 0.06],表示角点响应函数中的自由参数 k。默认为 0.04。
# dst:可选参数,用于存储输出角点响应图像。如果为 None,则函数会创建一个与输入图像相同大小和类型的图像。默认为 None。
# borderType:可选参数,用于指定图像边界的填充方式。默认为 None,表示使用默认的边界填充方式(cv2.BORDER_DEFAULT)。
# 返回值:
# dst:输出角点响应图像,数据类型为单通道浮点型。
#############################################################################################"""
"""#############################################################################################
# 函数功能:表示图像中的一个关键点。
# 函数说明:keypoint = cv2.KeyPoint(x, y, _size, _angle=-1, _response=0, _octave=0, _class_id=-1)
# 参数说明:
# x:关键点的 x 坐标。
# y:关键点的 y 坐标。
# _size:关键点的特征尺度。
# _angle:可选参数,表示关键点的方向。默认为 -1,表示未指定方向。
# _response:可选参数,表示关键点的响应值。默认为 0。
# _octave:可选参数,表示关键点所在金字塔组和组内层级的信息。默认为 0。
# _class_id:可选参数,表示关键点所属的类别 ID。默认为 -1,表示未指定类别。
# 返回值:
# keypoint:表示图像中的一个关键点。
#############################################################################################"""
"""#############################################################################################
# 函数功能:在图像上绘制关键点。
# 函数说明:image_with_keypoints = cv2.drawKeypoints(image, keypoints, outImage=None, color=(0, 255, 0), flags=cv2.DRAW_MATCHES_FLAGS_DEFAULT)
# 参数说明:
# image:输入图像,可以是灰度图像或者彩色图像(但是颜色通道顺序为 BGR)。
# keypoints:关键点列表,每个关键点是一个 cv2.KeyPoint 对象。
# outImage:可选参数,用于指定输出图像,如果不为 None,则将关键点绘制在此图像上。默认为 None,表示在输入图像上绘制。
# color:可选参数,绘制关键点的颜色,默认为 (0, 255, 0),表示绿色。
# flags:可选参数,绘制关键点的标志,默认为 cv2.DRAW_MATCHES_FLAGS_DEFAULT。其他可选值包括 cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS 和 cv2.DRAW_MATCHES_FLAGS_NOT_DRAW_SINGLE_POINTS。
# 返回值:
# image_with_keypoints:绘制了关键点的图像。
#############################################################################################"""
# -*- coding: utf-8 -*-
# 作者: 胖墩会武术
# 日期: 1994-08-21
# OpenCV图像处理: https://blog.csdn.net/shinuone/article/details/126022763
2.17、SIFT尺度不变特征检测 —— cv2.xfeatures2d.SIFT_create()、sift.detectAndCompute()、cv2.drawKeypoints()

OpenCV提供了演示数据:https://github.com/opencv/opencv/tree/master/samples/data
"""#########################################################
# 尺度不变特征变换(Scale-invariant feature transform,SIFT)
# 特点:具有尺度不变性、旋转不变性、光照不变性;且对于局部遮挡或变形仍可以提取有效特征
# 缺点:计算复杂度高,内存消耗大,专利限制,参数敏感
#
# Harris角点检测
# 特点:对较小范围的噪声有一定的鲁棒性
# 缺点:尺度不变性差、旋转不变性差、对较大范围的噪声敏感,灰度变化敏感,参数敏感
#########################################################
# 在 OpenCV 中,SIFT 函数的 3.4.3 版本及以上涉及到专利保护,故需要进行 OpenCV 降版本。
# 卸载旧版本:pip uninstall opencv-python pip uninstall opencv-contrib-python
# 安装新版本:pip install opencv-python==3.4.1.15 pip install opencv-contrib-python==3.4.1.15
#########################################################"""
import numpy as np
import cv2 # opencv读取图像默认为BGR
import matplotlib.pyplot as plt # matplotlib显示图像默认为RGB
image = cv2.imread('picture/house.jpg') # (1)读取图像
image_gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) # (2)灰度化
sift = cv2.xfeatures2d.SIFT_create() # (3)创建 SIFT 特征检测器
key_points, des = sift.detectAndCompute(image_gray, None) # (4)检测图像中的关键点并计算描述符
image_result = cv2.drawKeypoints(image_gray, key_points, image.copy()) # (5)绘制检测到的关键点
# (6)显示图像
plt.subplot(121), plt.imshow(cv2.cvtColor(image, cv2.COLOR_BGR2RGB)), plt.title('image')
plt.subplot(122), plt.imshow(cv2.cvtColor(image_result, cv2.COLOR_BGR2RGB)), plt.title('image_result')
plt.show()
"""#############################################################################################
# 函数功能:创建 SIFT(尺度不变特征变换)特征检测器对象。
# 函数说明:sift = cv2.xfeatures2d.SIFT_create(nfeatures=0, nOctaveLayers=3, contrastThreshold=0.04, edgeThreshold=10, sigma=1.6)
# 参数说明:
# nfeatures:可选参数,表示要提取的特征点的数量。默认为 0,表示提取所有特征点。
# nOctaveLayers:可选参数,表示每个金字塔组的层数。默认为 3。
# contrastThreshold:可选参数,表示特征点的对比度阈值。默认为 0.04。
# edgeThreshold:可选参数,表示特征点的边缘阈值。默认为 10。
# sigma:可选参数,表示高斯滤波器的方差。默认为 1.6。
# 返回值:
# sift:SIFT 特征检测器对象。
#############################################################################################"""
"""#############################################################################################
# 函数功能:检测图像中的关键点并计算描述符。
# 函数说明:keypoints, descriptors = sift.detectAndCompute(image, mask=None, descriptors=None, useProvidedKeypoints=False)
# 参数说明:
# image:输入图像,应为灰度图像或者彩色图像(但是颜色通道顺序为 BGR)。
# mask:可选参数,掩膜,用于指定在哪些区域内进行关键点检测。默认为 None,表示对整个图像进行检测。
# descriptors:可选参数,指定输入的描述符数组,如果不为空,则检测关键点时将忽略输入图像,而直接使用输入的关键点。
# useProvidedKeypoints:可选参数,布尔值,指定是否使用提供的关键点进行计算描述符。默认为 False。
# 返回值:
# keypoints:检测到的关键点列表,每个关键点是一个 cv2.KeyPoint 对象。
# descriptors:计算得到的描述符数组,每行是一个关键点的描述符向量。如果未能计算描述符,则返回 None。
#############################################################################################"""
"""#############################################################################################
# 函数功能:在图像上绘制关键点。
# 函数说明:image_with_keypoints = cv2.drawKeypoints(image, keypoints, outImage=None, color=(0, 255, 0), flags=cv2.DRAW_MATCHES_FLAGS_DEFAULT)
# 参数说明:
# image:输入图像,可以是灰度图像或者彩色图像(但是颜色通道顺序为 BGR)。
# keypoints:关键点列表,每个关键点是一个 cv2.KeyPoint 对象。
# outImage:可选参数,用于指定输出图像,如果不为 None,则将关键点绘制在此图像上。默认为 None,表示在输入图像上绘制。
# color:可选参数,绘制关键点的颜色,默认为 (0, 255, 0),表示绿色。
# flags:可选参数,绘制关键点的标志,默认为 cv2.DRAW_MATCHES_FLAGS_DEFAULT。其他可选值包括 cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS 和 cv2.DRAW_MATCHES_FLAGS_NOT_DRAW_SINGLE_POINTS。
# 返回值:
# image_with_keypoints:绘制了关键点的图像。
#############################################################################################"""
# -*- coding: utf-8 -*-
# 作者: 胖墩会武术
# 日期: 1994-08-21
# OpenCV图像处理: https://blog.csdn.net/shinuone/article/details/126022763
2.18、暴力特征匹配 —— cv2.BFMatcher_create()、bf.match()、bf_knn.knnMatch()、cv2.drawMatches()

OpenCV提供了演示数据:https://github.com/opencv/opencv/tree/master/samples/data
#############################################################################################
# 暴力特征匹配主要流程
# (1)先在查询描述符中取一个关键点的描述符,将其与训练描述符中的所有关键点描述符进行比较。
# (2)每次比较后会计算出一个距离值,距离最小的值对应最佳匹配结果。
# (3)所有描述符比较完后,匹配器返回匹配结果列表。
#############################################################################################
# 在 OpenCV 中,SIFT 函数的 3.4.3 版本及以上涉及到专利保护,故需要进行 OpenCV 降版本。
# 卸载旧版本:pip uninstall opencv-python pip uninstall opencv-contrib-python
# 安装新版本:pip install opencv-python==3.4.1.15 pip install opencv-contrib-python==3.4.1.15
#############################################################################################
import numpy as np
import cv2 # opencv读取图像默认为BGR
import matplotlib.pyplot as plt # matplotlib显示图像默认为RGB
# (1)读取图像
image1 = cv2.imread(r'picture\box.png') # 匹配图像
image2 = cv2.imread(r'picture\box_in_scene.png') # 待匹配图像
# (2)检测并计算关键点和描述符
sift = cv2.xfeatures2d.SIFT_create() # 创建SIFT特征检测器
# 检测并计算图像:关键点kp1 + 特征向量des1
kp1, des1 = sift.detectAndCompute(image1, None)
kp2, des2 = sift.detectAndCompute(image2, None)
# 暴力匹配器的匹配函数只支持描述符的类型为 np.uint8和np.float32。
des1 = des1.astype(np.float32)
des2 = des2.astype(np.float32)
# (3)使用暴力匹配器,并获取最佳结果
"""方法一:使用match()匹配指定数量的最佳匹配结果"""
bf = cv2.BFMatcher(cv2.NORM_L2, crossCheck=False) # 创建暴力匹配器对象
matches = bf.match(des1, des2) # 使用match()方法进行特征匹配,返回匹配结果
matches = sorted(matches, key=lambda x: x.distance) # 根据距离对所有匹配结果进行排序
result = cv2.drawMatches(image1, kp1, image2, kp2, matches[:15], None) # 绘制前15个匹配结果
"""方法二:使用knnMatch()匹配指定数量的最佳结果"""
bf_knn = cv2.BFMatcher(cv2.NORM_L2, crossCheck=False) # 创建暴力匹配器对象
ms_knn = bf_knn.knnMatch(des1, des2, k=2) # 使用knnMatch()方法进行k近邻匹配,每个描述符返回2个最佳匹配结果
# 应用比例测试选择要使用的匹配结果
results = []
for m, n in ms_knn:
if m.distance < 0.75 * n.distance:
results.append(m)
# 绘制不同方式的匹配结果
image_DEFAUL = cv2.drawMatches(image1, kp1, image2, kp2, results[:20], None, flags=cv2.DrawMatchesFlags_DEFAULT)
image_NO_POINTS = cv2.drawMatches(image1, kp1, image2, kp2, results[:20], None, flags=cv2.DrawMatchesFlags_NOT_DRAW_SINGLE_POINTS)
image_KEYPOINTS = cv2.drawMatches(image1, kp1, image2, kp2, results[:20], None, flags=cv2.DrawMatchesFlags_DRAW_RICH_KEYPOINTS)
# (4)可视化结果
plt.subplot(231), plt.imshow(cv2.cvtColor(image1, cv2.COLOR_BGR2RGB)), plt.title('raw_image1')
plt.subplot(232), plt.imshow(cv2.cvtColor(image2, cv2.COLOR_BGR2RGB)), plt.title('raw_image2')
plt.subplot(233), plt.imshow(cv2.cvtColor(result, cv2.COLOR_BGR2RGB)), plt.title('match_result')
plt.subplot(234), plt.imshow(cv2.cvtColor(image_DEFAUL, cv2.COLOR_BGR2RGB)), plt.title('knnMatch_DEFAUL')
plt.subplot(235), plt.imshow(cv2.cvtColor(image_NO_POINTS, cv2.COLOR_BGR2RGB)), plt.title('knnMatch_NO_POINTS')
plt.subplot(236), plt.imshow(cv2.cvtColor(image_KEYPOINTS, cv2.COLOR_BGR2RGB)), plt.title('knnMatch_KEYPOINTS')
plt.show()
"""#############################################################################################
# 函数功能:用于创建一个暴力匹配器(Brute-Force Matcher)。暴力匹配器在特征匹配中逐一比较两个图像的每个描述符之间的距离,找到最相似的一对特征点。
# 函数说明:bf = cv2.BFMatcher_create(normType=cv2.NORM_L2, crossCheck=False)
# 参数说明:
# normType:指定用于测量描述符之间距离的度量方法。常见的取值包括:
# cv2.NORM_L1:使用 L1 范数(曼哈顿距离)。
# cv2.NORM_L2:使用 L2 范数(欧氏距离),适用于 SIFT 和 SURF 特征描述符。
# cv2.NORM_HAMMING:适用于二进制描述符,例如 ORB、BRIEF、BRISK 等。
# cv2.NORM_HAMMING2:适用于 ORB 描述符(WTA_K=3 或 4 时)。
# crossCheck:布尔值。默认为 False。如果设置为 True,则匹配器只返回那些在两个方向上都满足条件的匹配结果,即查询描述符 A 与训练描述符 B 互为最佳匹配。
# 返回值
# 返回一个 cv2.BFMatcher 对象。
#############################################################################################"""
"""#############################################################################################
# 函数功能:用于匹配查询描述符与训练描述符,返回每个查询描述符的最佳匹配结果。
# 函数说明:matches = bf.match(des1, des2)
# 参数说明:
# des1:查询描述符(第一幅图像的描述符),类型应为 np.ndarray。
# des2:训练描述符(第二幅图像的描述符),类型应为 np.ndarray。
# 返回值:
# matches:DMatch 对象的列表。每个 DMatch 对象包含以下属性:
# - queryIdx:查询描述符的索引(对应 des1 中的索引)。
# - trainIdx:训练描述符的索引(对应 des2 中的索引)。
# - imgIdx:图像索引,仅在多图像匹配时使用。
# - distance:描述符之间的距离,距离越小表示匹配度越高。
#############################################################################################"""
"""#############################################################################################
# 函数功能:用于进行 k 近邻匹配,返回每个查询描述符的 k 个最佳匹配结果。
# 函数说明:matches = bf.knnMatch(des1, des2, k[, mask[, compactResult[, crossCheck]]])
# 参数说明:
# des1:查询描述符(第一幅图像的描述符),类型应为 np.ndarray。
# des2:训练描述符(第二幅图像的描述符),类型应为 np.ndarray。
# k:返回的最佳匹配个数。
# mask:可选参数,掩膜,用于决定对哪些查询描述符进行匹配,默认为 None。
# compactResult:可选参数,布尔值,指定是否返回紧凑的结果列表,默认为 True。
# crossCheck:可选参数,布尔值,默认为 False。如果设置为 True,则匹配器只返回那些在两个方向上都满足条件的匹配结果,即查询描述符 A 与训练描述符 B 互为最佳匹配。
# 返回值:
# matches:匹配结果列表,每个元素是一个列表,包含 k 个 DMatch 对象。如果设置了 compactResult 参数为 False,则返回每个查询描述符的 k 个最佳匹配结果。
#############################################################################################"""
"""#############################################################################################
# 函数功能:绘制特征匹配结果图像,将两幅图像中匹配的关键点用连线连接起来,并可选择绘制关键点。
# 函数说明:outImg = cv2.drawMatches(img1, keypoints1, img2, keypoints2, matches1to2[, matchColor[, singlePointColor[, matchesMask[, flags]]]])
# 参数说明:
# img1:第一幅图像,类型应为 np.ndarray,通常是匹配时的查询图像。
# keypoints1:第一幅图像的关键点列表,每个关键点是一个 cv2.KeyPoint 对象。
# img2:第二幅图像,类型应为 np.ndarray,通常是匹配时的训练图像。
# keypoints2:第二幅图像的关键点列表,每个关键点是一个 cv2.KeyPoint 对象。
# matches1to2:匹配结果列表,每个元素是一个 DMatch 对象,表示一对匹配的关键点。
# matchColor:可选参数,用于绘制匹配关键点之间连线的颜色,默认为随机颜色。
# singlePointColor:可选参数,用于绘制单个关键点的颜色,默认为随机颜色。
# matchesMask:可选参数,掩膜,用于决定绘制哪些匹配结果,默认为空,表示绘制所有匹配结果。
# flags:可选参数,标志,用于设置绘制方式,默认为 cv2.DrawMatchesFlags_DEFAULT。
# 可选取值为:
# - cv2.DrawMatchesFlags_DEFAULT:绘制两个源图像、匹配项和单个关键点,没有围绕关键点的圆以及关键点的大小和方向。
# - cv2.DrawMatchesFlags_NOT_DRAW_SINGLE_POINTS:不会绘制单个关键点。
# - cv2.DrawMatchesFlags_DRAW_RICH_KEYPOINTS:在关键点周围绘制具有关键点大小和方向的圆圈。
# 返回值:
# outImg:返回的绘制结果图像,图像中查询图像与训练图像中匹配的关键点之间的连线为彩色。
#############################################################################################"""
# -*- coding: utf-8 -*-
# 作者: 胖墩会武术
# 日期: 1994-08-21
# OpenCV图像处理: https://blog.csdn.net/shinuone/article/details/126022763
OpenCV特征匹配 SIFT demo(图解)
OpenCV特征检测之SIFT算法(原理详解)
OpenCV特征检测之特征匹配方式详解
2.19、特征点检测器 + 特征点描述符

import numpy as np
import cv2 # opencv读取图像默认为BGR
import matplotlib.pyplot as plt # matplotlib显示图像默认为RGB
# (1)读取图像
image = cv2.imread('image.jpg', cv2.IMREAD_GRAYSCALE)
# (2)转换为彩色图像(用于LUCID等需要彩色图像的描述符)
color_image = cv2.cvtColor(image, cv2.COLOR_GRAY2BGR)
#######################################################################################################################
# (3)创建不同的特征检测器和描述符
detectors = {
# 特征点检测器(Feature Detectors) ———— 用于从图像中检测具有显著性的特征点。例如角点、斑点或边缘等。
'Harris': cv2.GFTTDetector_create(), # Harris 角点检测器:用于检测图像中的角点,对图像中的角落和交点非常敏感。缺点:对尺度和旋转不变性较差。
'GFTT': cv2.GFTTDetector_create(), # GFTT 角点检测器:Good Features to Track,常用于跟踪特征点,性能与 Harris 类似。缺点:对尺度和旋转不变性差。
'FAST': cv2.FastFeatureDetector_create(), # FAST 快速角点检测器,适用于实时应用。缺点:对尺度和旋转不变性较差。
# 'SIFT': cv2.SIFT_create(), # 确保OpenCV是非免费版
# 'SURF': cv2.xfeatures2d.SURF_create(), # 确保OpenCV是非免费版
'KAZE': cv2.KAZE_create(), # KAZE 特征点检测器和描述符:处理图像中的非线性尺度变化,适合处理纹理丰富的图像。缺点:计算复杂度较高,速度较慢。
'AKAZE': cv2.AKAZE_create(), # AKAZE 特征点检测器和描述符:改进的 KAZE,速度更快,适用于低对比度图像。缺点:计算复杂度仍然较高,但比 KAZE 更快。
'ORB': cv2.ORB_create(), # ORB 特征点检测器和描述符:结合了FAST检测器和BRIEF描述符,计算高效且对旋转不变。缺点:对尺度不变性较差。
'BRISK': cv2.BRISK_create(), # BRISK 特征点检测器和描述符:具有尺度和旋转不变性,适用于实时应用。缺点:对光照变化敏感。
'MSER': cv2.MSER_create(), # MSER 特征点检测器:用于检测图像中的极值区域,适用于变化大的图像。缺点:对噪声较敏感,计算复杂度较高。
'Star': cv2.xfeatures2d.StarDetector_create(), # Star 特征点检测器:用于检测图像中的星状特征点,适合高噪声图像。缺点:计算复杂度相对较高。
'AGAST': cv2.AgastFeatureDetector_create(), # AGAST 特征点检测器:比 FAST 更具尺度不变性,适用于快速处理。缺点:对光照变化较敏感。
'Blob': cv2.SimpleBlobDetector_create(), # Blob 特征点检测器:用于检测图像中的斑点,适合检测规则的圆形区域。缺点:对图像的形状和大小变化较敏感。
'LSD': cv2.createLineSegmentDetector(), # LSD 线段检测器:用于检测图像中的直线段,适合处理有直线特征的图像。缺点:不适合检测小的特征点。
# 特征点描述符(Feature Descriptors) ———— 用于描述检测到的特征点周围的局部图像区域,以便于后续的匹配和识别。
'BRIEF': cv2.xfeatures2d.BriefDescriptorExtractor_create(), # BRIEF 描述符:二进制描述符,速度快但对尺度和旋转不变性差。缺点:对尺度和旋转不变性较差。
'FREAK': cv2.xfeatures2d.FREAK_create(), # FREAK 描述符:用于描述特征点的局部区域,具有较好的描述能力和效率。缺点:对图像的变化有一定的敏感性。
'LUCID': cv2.xfeatures2d.LUCID_create(), # LUCID 描述符:局部特征描述符,处理速度较快。缺点:对尺度和旋转不变性较差。
'LATCH': cv2.xfeatures2d.LATCH_create(), # LATCH 描述符:基于局部特征的二进制描述符,适用于高效匹配。缺点:对光照变化较敏感。
'DAISY': cv2.xfeatures2d.DAISY_create(), # DAISY 描述符:提供强的局部特征描述,适用于对旋转和尺度不变的描述。缺点:计算复杂度较高。
'VGG': cv2.xfeatures2d.VGG_create(), # VGG 描述符:基于 VGG 网络的特征描述,适合深度学习应用。缺点:计算复杂度高
'BoostDesc': cv2.xfeatures2d.BoostDesc_create(), # BoostDesc 描述符:具有较强的描述能力,适用于高维特征匹配。缺点:计算复杂度较高。
'PCTSignatures': cv2.xfeatures2d.PCTSignatures_create(), # PCTSignatures 描述符:基于图像的局部特征,适合描述纹理丰富的区域。缺点:对光照变化较敏感。
# 特征点描述符(匹配器) ———— 用于匹配不同图像中的特征点,以找到它们之间的对应关系。
'LATCH Matcher': cv2.xfeatures2d.LATCH_create(), # LATCH 描述符(匹配器):用于匹配具有局部特征的描述符,效率高。缺点:对图像中的变化较敏感。
}
#######################################################################################################################
# (4)特征检测并绘制
results = [] # 保存每个检测器的结果
for name, detector in detectors.items():
try:
if name in ['Harris', 'GFTT', 'FAST', 'KAZE', 'AKAZE', 'ORB', 'MSER', 'Star', 'AGAST']:
keypoints = detector.detect(image)
output = cv2.drawKeypoints(image, keypoints, None, (0, 255, 0), cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS)
elif name in ['SIFT', 'SURF', 'BRISK']:
keypoints, descriptors = detector.detectAndCompute(image, None)
output = cv2.drawKeypoints(image, keypoints, None, (0, 255, 0), cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS)
elif name in ['BRIEF', 'FREAK', 'LUCID', 'LATCH', 'DAISY', 'VGG', 'BoostDesc', 'LATCH Matcher']:
# 用于描述特征点的算法,通常与ORB、KAZE 或 AKAZE等特征点检测器来生成描述符。
temp_detector = cv2.ORB_create()
keypoints = temp_detector.detect(image, None)
keypoints, descriptors = detector.compute(color_image, keypoints) # 使用彩色图像
output = cv2.drawKeypoints(image, keypoints, None, (0, 255, 0), cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS)
elif name in 'PCTSignatures':
# PCTSignatures 特征检测器它只返回关键点,不支持描述符计算
temp_detector = cv2.ORB_create()
keypoints = temp_detector.detect(image, None)
# AttributeError: 'cv2.xfeatures2d.PCTSignatures' object has no attribute 'compute'
output = image
elif name == 'Blob':
# Blob 特征检测器它只返回关键点,不支持描述符计算
keypoints = detector.detect(image)
output = cv2.drawKeypoints(image, keypoints, None, (0, 255, 0), cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS)
elif name == 'LSD':
# LSD 特征检测器它只返回关键点,不支持描述符计算。特殊处理
lines = detector.detect(image)[0]
output = cv2.cvtColor(image, cv2.COLOR_GRAY2BGR)
for line in lines:
for x1, y1, x2, y2 in line:
cv2.line(output, (int(x1), int(y1)), (int(x2), int(y2)), (0, 255, 0), 1)
else:
output = image # 如果无法处理,显示原图像
except cv2.error as e:
print(f"Error with {name}: {e}")
output = image
results.append((name, output))
#######################################################################################################################
# (5)可视化
N = 4 # 行数
M = 6 # 列数
# 确保不会超出最大数量的子图
if len(detectors) > N * M:
print(f"Warning: More detectors than available subplots ({N * M}). Showing only the first {N * M} detectors.")
detectors = dict(list(detectors.items())[:N * M])
# 创建一个画布来显示所有结果
fig, axes = plt.subplots(N, M, figsize=(6, 4))
axes = axes.flatten() # 将二维数组展平成一维,方便索引
# 绘制所有结果
for ax, (name, output) in zip(axes, results):
ax.imshow(cv2.cvtColor(output, cv2.COLOR_BGR2RGB))
ax.set_title(name)
ax.axis('off')
# 关闭多余的子图
for i in range(len(results), len(axes)):
axes[i].axis('off')
plt.tight_layout()
plt.show()
# -*- coding: utf-8 -*-
# 作者: 胖墩会武术
# 日期: 1994-08-21
# OpenCV图像处理: https://blog.csdn.net/shinuone/article/details/126022763
2.20、几何变换
(0)图像平移 - 上下左右(自定义实现)
NumPy 索引切片:支持整数偏移,速度最快。OpenCV warpAffine:支持高质量的浮点数偏移,速度快 。
如果需要填充边界,可结合 copyMakeBorder。
import numpy as np
import cv2
def shift_image(image, vertical_offset=0, horizontal_offset=0):
"""读取 TIFF 图像,并根据给定的垂直和水平偏移量进行偏移处理。
参数:
image (np.ndarray): 输入图像。
vertical_offset (int): 垂直方向偏移量。
- 正值:丢弃图像顶部的若干行,并将剩余部分上移填充;
- 负值:丢弃图像底部的若干行,并将剩余部分下移填充。
horizontal_offset (int): 水平方向偏移量。
- 正值:丢弃图像左侧的若干列,并将剩余部分左移填充;
- 负值:丢弃图像右侧的若干列,并将剩余部分右移填充。
返回:
shifted_image (np.ndarray): 偏移后的图像数据。
"""
# (1)获取图像维度
if image.ndim == 2:
H, W = image.shape
image = image.reshape(H, W, 1) # 统一处理为三维
else:
H, W, C = image.shape
# (2)创建零填充的目标图像
shifted = np.zeros_like(image)
# (3)计算垂直方向的源区域和目标区域
if vertical_offset >= 0:
row_src_start = vertical_offset
row_src_end = H
row_dst_start = 0
row_dst_end = H - vertical_offset
else:
row_src_start = 0
row_src_end = H + vertical_offset
row_dst_start = -vertical_offset
row_dst_end = H
# (4)计算水平方向的源区域和目标区域
if horizontal_offset >= 0:
col_src_start = horizontal_offset
col_src_end = W
col_dst_start = 0
col_dst_end = W - horizontal_offset
else:
col_src_start = 0
col_src_end = W + horizontal_offset
col_dst_start = -horizontal_offset
col_dst_end = W
# (5)复制偏移后的图像
shifted[row_dst_start:row_dst_end, col_dst_start:col_dst_end, :] = \
image[row_src_start:row_src_end, col_src_start:col_src_end, :]
# (6)如果原图是二维,则返回二维结果
if image.ndim == 2:
shifted = shifted.reshape(H, W)
return shifted
if __name__ == "__main__":
# (1)读取图像
image = cv2.imread("image.jpg")
# (2)定义垂直和水平偏移量(可正可负)
vertical_offset = 100 # 正值(向上移动):丢弃图像顶部 N 行
horizontal_offset = -200 # 负值(向右移动):丢弃图像右侧 M 列
# (3)应用偏移
shifted_image = shift_image(image, vertical_offset, horizontal_offset)
print("偏移后的图像形状:", shifted_image.shape)
# (4)显示图像
cv2.imshow('image', image)
cv2.imshow('shifted_image', shifted_image)
cv2.waitKey(0)
cv2.destroyAllWindows()
(1)图像缩放 —— cv2.resize()
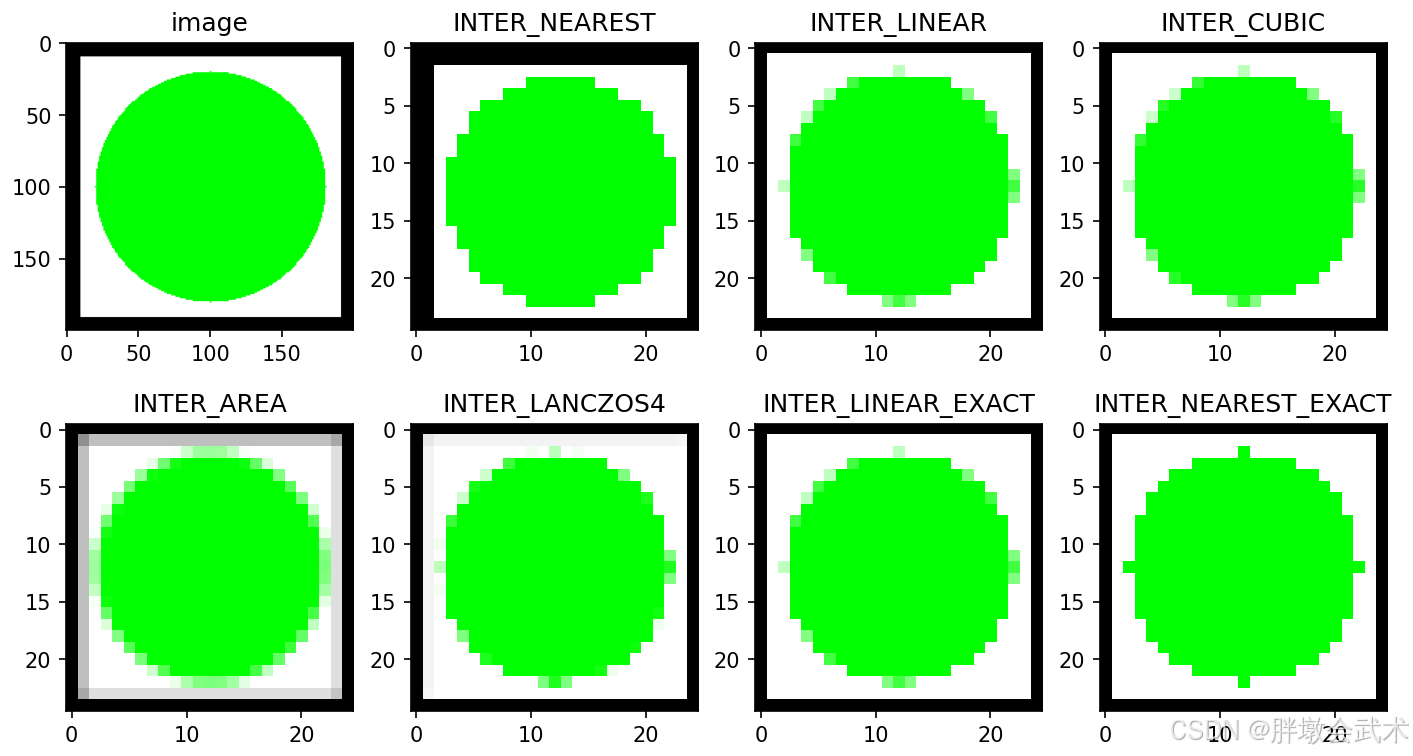
import numpy as np
import cv2 # opencv读取图像默认为BGR
import matplotlib.pyplot as plt # matplotlib显示图像默认为RGB
# image = cv2.imread(r'image.jpg')
image = np.zeros((200, 200, 3), dtype=np.uint8)
cv2.rectangle(image, (10, 10), (190, 190), (255, 255, 255), -1) # 白色矩形
cv2.circle(image, (100, 100), 80, (0, 255, 0), -1) # 绿色圆形
height, width, channels = image.shape
image_Height = int(height / 8)
image_Width = int(width / 8)
INTER_NEAREST = cv2.resize(src=image, dsize=(image_Width, image_Height), interpolation=cv2.INTER_NEAREST)
INTER_LINEAR = cv2.resize(src=image, dsize=(image_Width, image_Height), interpolation=cv2.INTER_LINEAR)
INTER_CUBIC = cv2.resize(src=image, dsize=(image_Width, image_Height), interpolation=cv2.INTER_CUBIC)
INTER_AREA = cv2.resize(src=image, dsize=(image_Width, image_Height), interpolation=cv2.INTER_AREA)
INTER_LANCZOS4 = cv2.resize(src=image, dsize=(image_Width, image_Height), interpolation=cv2.INTER_LANCZOS4)
INTER_LINEAR_EXACT = cv2.resize(src=image, dsize=(image_Width, image_Height), interpolation=cv2.INTER_LINEAR_EXACT)
INTER_NEAREST_EXACT = cv2.resize(src=image, dsize=(image_Width, image_Height), interpolation=cv2.INTER_NEAREST_EXACT)
plt.subplot(241), plt.imshow(image), plt.title('image')
plt.subplot(242), plt.imshow(INTER_NEAREST), plt.title('INTER_NEAREST')
plt.subplot(243), plt.imshow(INTER_LINEAR), plt.title('INTER_LINEAR')
plt.subplot(244), plt.imshow(INTER_CUBIC), plt.title('INTER_CUBIC')
plt.subplot(245), plt.imshow(INTER_AREA), plt.title('INTER_AREA')
plt.subplot(246), plt.imshow(INTER_LANCZOS4), plt.title('INTER_LANCZOS4')
plt.subplot(247), plt.imshow(INTER_LINEAR_EXACT), plt.title('INTER_LINEAR_EXACT')
plt.subplot(248), plt.imshow(INTER_NEAREST_EXACT), plt.title('INTER_NEAREST_EXACT')
plt.show()
"""#####################################################################################################################
# 函数功能:图像缩放 ———— 可以将图像缩放到指定的尺寸,也可以根据缩放比例进行缩放。
# 函数说明:resized_image = cv2.resize(src, dsize, fx=0, fy=0, interpolation=cv2.INTER_LINEAR)
# 参数说明:
# src 要调整大小的输入图像。
# dsize 输出图像的大小
# (1)矩阵参数缩放到指定大小(width,height); 例如:cv2.resize(img_dog, (500, 414))
# (2)矩阵参数为(0,0),原图像缩放倍数通过fx, fy来控制; 例如:cv2.resize(img_dog, (0, 0), fx=4, fy=4)
# fx: 水平方向的缩放比例。
# fy: 垂直方向的缩放比例。
# interpolation: 插值方法,用于指定图像缩放时的插值算法
# cv2.INTER_NEAREST: 0最近邻插值 图像的细节丢失较多,可能会看到锯齿状的边缘。
# cv2.INTER_LINEAR: 1双线性插值(默认) 边缘平滑,但可能有一些模糊。
# cv2.INTER_CUBIC: 2双立方插值 通常提供更平滑的缩放效果,边缘可能更加清晰。
# cv2.INTER_AREA: 3像素区域关系重采样 在缩小图像时表现较好,可以保留更多细节,常用于图像缩小。
# cv2.INTER_LANCZOS4: 4Lanczos插值 对图像进行高质量的重采样,尤其在图像放大时效果显著。
# cv2.INTER_LINEAR_EXACT: 5更精确的线性插值
# cv2.INTER_NEAREST_EXACT: 6更精确的最近邻插值
#####################################################################################################################"""
# -*- coding: utf-8 -*-
# 作者: 胖墩会武术
# 日期: 1994-08-21
# OpenCV图像处理: https://blog.csdn.net/shinuone/article/details/126022763
(2)图像翻转 —— cv2.flip()

import cv2 # opencv读取图像默认为BGR
import matplotlib.pyplot as plt # matplotlib显示图像默认为RGB
image = cv2.imread(r"image.jpg")
flipped_horizontal = cv2.flip(image, 1) # 水平翻转
flipped_vertical = cv2.flip(image, 0) # 垂直翻转
flipped_both = cv2.flip(image, -1) # 水平翻转 + 垂直翻转
plt.subplot(141), plt.imshow(image), plt.title('image')
plt.subplot(142), plt.imshow(flipped_horizontal), plt.title('flipped_horizontal')
plt.subplot(143), plt.imshow(flipped_vertical), plt.title('flipped_vertical')
plt.subplot(144), plt.imshow(flipped_both), plt.title('flipped_both')
plt.show()
"""#############################################################################################
# 函数功能:图像翻转
# 函数说明:flipped_image = cv2.flip(src, flipCode)
# 参数说明:
# src:输入图像,必须是一个 NumPy 数组。
# flipCode:翻转标志,用于指定翻转方向。取值包括:
# - 0:垂直翻转(上下翻转)。
# - 1:水平翻转(左右翻转)。
# - -1:同时进行垂直和水平翻转(即旋转 180 度)。
# 返回值:
# 返回翻转后的图像,是一个 NumPy 数组。
#############################################################################################"""
# -*- coding: utf-8 -*-
# 作者: 胖墩会武术
# 日期: 1994-08-21
# OpenCV图像处理: https://blog.csdn.net/shinuone/article/details/126022763
(3)图像旋转 —— cv2.rotate()

只支持90°的整数倍旋转(直角旋转) ———— 当且仅当旋转角度为 90,180,270 度时
实际上是通过矩阵转置实现的,因此速度很快。
import cv2 # opencv读取图像默认为BGR
import matplotlib.pyplot as plt # matplotlib显示图像默认为RGB
image = cv2.imread('image.jpg')
rotated_90_clockwise = cv2.rotate(image, cv2.ROTATE_90_CLOCKWISE) # 顺时针旋转 90 度
rotated_90_counterclockwise = cv2.rotate(image, cv2.ROTATE_90_COUNTERCLOCKWISE) # 逆时针旋转 90 度
rotated_180 = cv2.rotate(image, cv2.ROTATE_180) # 旋转 180 度
plt.subplot(141), plt.imshow(image), plt.title('image')
plt.subplot(142), plt.imshow(rotated_90_clockwise), plt.title('rotated_90_clockwise')
plt.subplot(143), plt.imshow(rotated_90_counterclockwise), plt.title('rotated_90_counterclockwise')
plt.subplot(144), plt.imshow(rotated_180), plt.title('rotated_180')
plt.show()
"""#############################################################################################
# 函数功能:对图像进行旋转操作。
# 函数说明:result = cv2.rotate(src, rotateCode)
# 参数说明:
# src:输入图像,通常是一个 NumPy 数组。
# rotateCode:旋转代码,指定旋转角度。常见取值如下:
# cv2.ROTATE_90_CLOCKWISE:顺时针旋转 90 度。
# cv2.ROTATE_90_COUNTERCLOCKWISE:逆时针旋转 90 度。
# cv2.ROTATE_180:旋转 180 度。
# 返回值:
# 返回旋转后的图像,数据类型和输入图像相同。
# 功能描述:
# - cv2.rotate 只支持简单的旋转操作,限定为 90 度的整数倍旋转。
# - 当需要任意角度旋转时,建议使用 cv2.warpAffine 或其他库函数。如:PIL.Image.rotate()、scipy.ndimage.rotate()
#############################################################################################"""
# -*- coding: utf-8 -*-
# 作者: 胖墩会武术
# 日期: 1994-08-21
# OpenCV图像处理: https://blog.csdn.net/shinuone/article/details/126022763
(4)图像转置 —— cv2.transpose()

图像转置 = 图像旋转(顺时针旋转 90 度) + 图像翻转(水平)
import cv2 # opencv读取图像默认为BGR
import matplotlib.pyplot as plt # matplotlib显示图像默认为RGB
image = cv2.imread("image.jpg")
transposed_image = cv2.transpose(image)
rotated_90_clockwise = cv2.rotate(image, cv2.ROTATE_90_CLOCKWISE) # 顺时针旋转 90 度
rotated_image = cv2.flip(rotated_90_clockwise, flipCode=1) # flipCode=1 表示水平翻转
plt.subplot(131), plt.imshow(image), plt.title('image')
plt.subplot(132), plt.imshow(transposed_image), plt.title('transposed_image')
plt.subplot(133), plt.imshow(transposed_image), plt.title('cv2.rotate() + cv2.flip()')
plt.show()
"""#############################################################################################
# 函数功能:图像转置 ———— 将图像矩阵沿对角线翻转,相当于图像的 90 度旋转。
# 函数说明:dst = cv2.transpose(src)
# 参数说明:
# src:输入图像,可以是单通道或多通道图像。
# 返回值:
# 返回转置后的图像,即宽高互换的图像。
#############################################################################################"""
# -*- coding: utf-8 -*-
# 作者: 胖墩会武术
# 日期: 1994-08-21
# OpenCV图像处理: https://blog.csdn.net/shinuone/article/details/126022763
(5)图像重映射 —— cv2.remap():扭曲 + 缩放 / 平移 / 旋转 / 翻转 / 变换

import cv2
import numpy as np
image = cv2.imread("image.jpg")
h, w = image.shape[:2]
#######################################################################################################################
"""(1)畸变校正:相机拍摄的图像可能会因为镜头的原因出现畸变"""
# 相机内参矩阵
fx, fy = 800, 800 # fx 和 fy:相机在 x 和 y 方向的焦距,单位通常是像素。
cx, cy = 320, 240 # cx 和 cy:相机的主点坐标,通常接近图像的中心。
camera_matrix = np.array([[fx, 0, cx],
[0, fy, cy],
[0, 0, 1]])
# 畸变系数
k1, k2, k3 = -0.2, 0.1, 0.0 # k1, k2, k3:径向畸变系数,用于描述图像中心到边缘的畸变程度。
p1, p2 = 0.01, 0.01 # p1, p2:切向畸变系数,表示由于相机的对齐误差,图像中点的偏移。
dist_coeffs = np.array([k1, k2, p1, p2, k3])
map1, map2 = cv2.initUndistortRectifyMap(camera_matrix, dist_coeffs, None, camera_matrix, (w, h), cv2.CV_32FC1)
undistorted_img = cv2.remap(image, map1, map2, interpolation=cv2.INTER_LINEAR)
# cv2.imshow("undistorted_img", undistorted_img)
# cv2.waitKey(0)
# cv2.destroyAllWindows()
#######################################################################################################################
"""(2)图像扭曲(自定义变形效果) ———— 例如,可以使用正弦波或其他函数来调整图像坐标,产生波浪形或其他效果。"""
mapx, mapy = np.meshgrid(np.arange(w), np.arange(h))
mapx = mapx + 15 * np.sin(mapy / 20) # X 方向添加正弦波
mapy = mapy + 15 * np.cos(mapx / 20) # Y 方向添加余弦波
distorted_img = cv2.remap(image, mapx.astype(np.float32), mapy.astype(np.float32), interpolation=cv2.INTER_LINEAR)
cv2.imshow("distorted_img", distorted_img)
cv2.waitKey(0)
cv2.destroyAllWindows()
#######################################################################################################################
"""(3.1)图像缩放"""
scale = 2 # 放大2倍
mapx, mapy = np.indices((w * scale, h * scale), dtype=np.float32)
mapx = mapx / scale
mapy = mapy / scale
resized_img = cv2.remap(image, mapx, mapy, interpolation=cv2.INTER_LINEAR)
# cv2.imshow("resized_img", resized_img)
# cv2.waitKey(0)
# cv2.destroyAllWindows()
#######################################################################################################################
"""(3.2)图像平移"""
mapx, mapy = np.indices((w, h), dtype=np.float32)
mapx = mapx + 10 # 水平平移100个像素
mapy = mapy + 50 # 垂直平移50个像素
translated_img = cv2.remap(image, mapx, mapy, interpolation=cv2.INTER_LINEAR)
# cv2.imshow("translated_img", translated_img)
# cv2.waitKey(0)
# cv2.destroyAllWindows()
#######################################################################################################################
"""(3.3)图像旋转"""
# center_x, center_y = w // 2, h // 2 # 旋转中心点(中心点)
center_x, center_y = 0, 0 # 旋转中心点(原点)
angle = np.radians(30) # 旋转45度
mapx, mapy = np.meshgrid(np.arange(w), np.arange(h))
new_x = (mapx - center_x) * np.cos(angle) - (mapy - center_y) * np.sin(angle) + center_x
new_y = (mapx - center_x) * np.sin(angle) + (mapy - center_y) * np.cos(angle) + center_y
rotated_img = cv2.remap(image, new_x.astype(np.float32), new_y.astype(np.float32), interpolation=cv2.INTER_LINEAR)
# cv2.imshow("Rotated Image", rotated_img)
# cv2.waitKey(0)
# cv2.destroyAllWindows()
#######################################################################################################################
"""(3.4)透视变换"""
src_points = np.float32([[0, 0], [w - 1, 0], [0, h - 1], [w - 1, h - 1]])
dst_points = np.float32([[50, 50], [w - 50, 50], [50, h - 50], [w - 50, h - 50]])
M = cv2.getPerspectiveTransform(src_points, dst_points)
mapx, mapy = cv2.initUndistortRectifyMap(M, None, None, None, (w, h), cv2.CV_32FC1)
perspective_img = cv2.remap(image, mapx, mapy, interpolation=cv2.INTER_LINEAR)
# cv2.imshow("perspective_img", perspective_img)
# cv2.waitKey(0)
# cv2.destroyAllWindows()
#######################################################################################################################
"""(3.5)图像翻转(水平、垂直或对角线)"""
mapx_horiz, mapy_horiz = np.meshgrid(np.arange(w-1, -1, -1), np.arange(h), indexing='xy') # 水平翻转
mapx_vert, mapy_vert = np.meshgrid(np.arange(w), np.arange(h-1, -1, -1), indexing='xy') # 垂直翻转
mapx_diag, mapy_diag = np.meshgrid(np.arange(w), np.arange(h)) # 对角线翻转
mapx_diag = mapx_diag.T # x 坐标和 y 坐标交换,即对角线翻转
mapy_diag = mapy_diag.T # x 坐标和 y 坐标交换,即对角线翻转
flipped_horiz = cv2.remap(image, mapx_horiz.astype(np.float32), mapy_horiz.astype(np.float32), interpolation=cv2.INTER_LINEAR)
flipped_vert = cv2.remap(image, mapx_vert.astype(np.float32), mapy_vert.astype(np.float32), interpolation=cv2.INTER_LINEAR)
flipped_diag = cv2.remap(image, mapx_diag.astype(np.float32), mapy_diag.astype(np.float32), interpolation=cv2.INTER_LINEAR)
# import matplotlib.pyplot as plt
# plt.subplot(141), plt.imshow(image), plt.title('image')
# plt.subplot(142), plt.imshow(flipped_horiz), plt.title('flipped_horiz')
# plt.subplot(143), plt.imshow(flipped_vert), plt.title('flipped_vert')
# plt.subplot(144), plt.imshow(flipped_diag), plt.title('flipped_diag')
# plt.show()
###############################################################################
"""#############################################################################################
# 函数功能:图像重映射
# 函数说明:dst = cv2.remap(src, map1, map2, interpolation[, borderMode[, borderValue]])
# 参数说明:
# src:输入图像,可以是单通道或多通道图像。
# map1:水平映射信息的矩阵(mapx),大小与输入图像相同,表示输出图像中每个像素对应的输入图像的横坐标。
# map2:垂直映射信息的矩阵(mapy),大小与输入图像相同,表示输出图像中每个像素对应的输入图像的纵坐标。
# interpolation:插值方法,可选参数如下:
# cv2.INTER_LINEAR:双线性插值(默认)。
# cv2.INTER_NEAREST:最邻近插值。
# cv2.INTER_CUBIC:三次样条插值。
# cv2.INTER_LANCZOS4:Lanczos插值。
# borderMode:边界填充模式,可选参数如下:
# cv2.BORDER_CONSTANT:常熟(默认)。
# cv2.BORDER_REFLECT:边界反射。
# cv2.BORDER_WRAP:边界环绕。
# cv2.BORDER_REPLICATE:边界复制。
# borderValue:边界填充值,仅在 borderMode 为 cv2.BORDER_CONSTANT 时生效,默认为0。
# 返回值:
# 返回重映射后的图像。
#
# 重映射(remapping):是指通过特定的映射关系,将图像中的每个像素重新映射到新的位置,从而实现图像的几何变换。
# 映射表(Mapping Table):是一个由 mapx 和 mapy 组成的二维矩阵,分别表示图像中每个像素的新水平和垂直坐标。
# 插值(Interpolation):当新的像素位置不对应图像中的一个精确像素时,cv2.remap() 会使用插值算法来计算新位置的像素值。
#############################################################################################"""
# -*- coding: utf-8 -*-
# 作者: 胖墩会武术
# 日期: 1994-08-21
# OpenCV图像处理: https://blog.csdn.net/shinuone/article/details/126022763
(6)图像错切 + 图像平移 + 图像旋转 + 仿射变换 + 透视变换 —— np.float32() + cv2.getRotationMatrix2D() + cv2.getAffineTransform() + cv2.getPerspectiveTransform() + cv2.warpAffine() + cv2.warpPerspective()
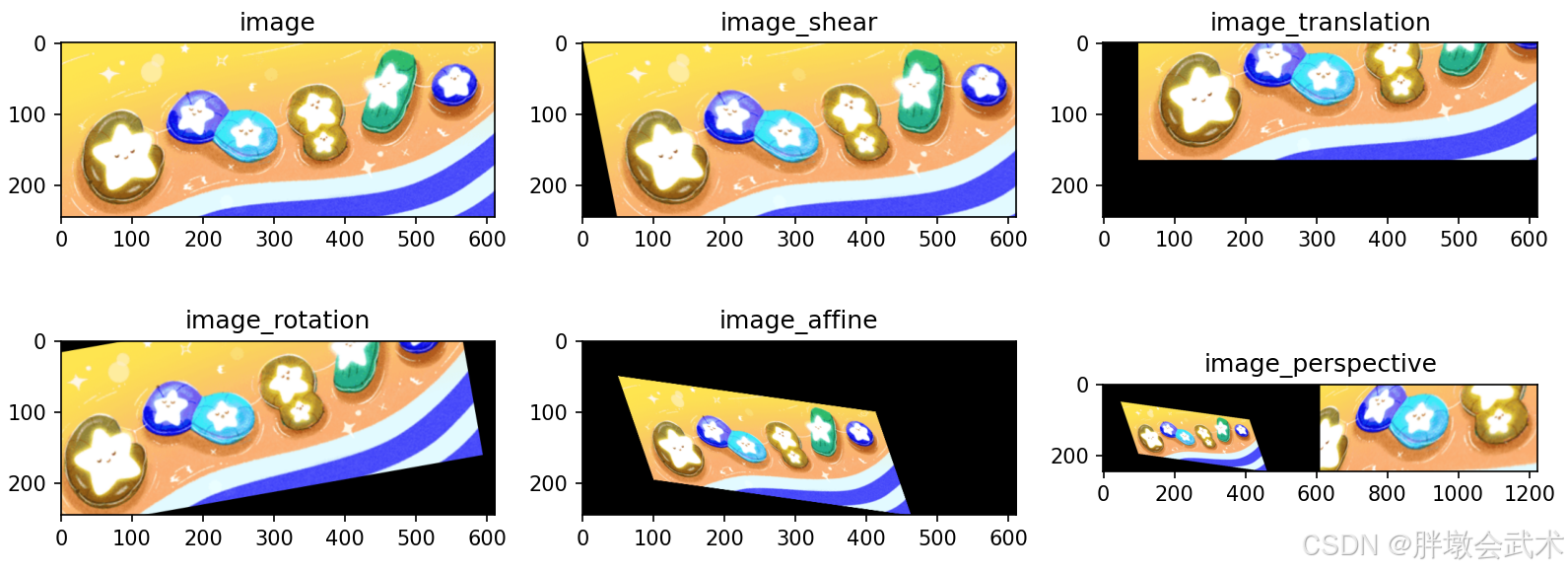
import numpy as np
import cv2 # opencv读取图像默认为BGR
import matplotlib.pyplot as plt # matplotlib显示图像默认为RGB
"""读取图像"""
image = cv2.imread(r"image.jpg") # flags=cv2.IMREAD_GRAYSCALE
height, width, channels = image.shape
"""############################## 图像错切(错切矩阵:2x3)"""
matShear = np.float32([[1, 0.2, 0], [0, 1, 0]]) # 获取错切矩阵2x3
image_shear = cv2.warpAffine(image, matShear, (width, height)) # 仿射变换
"""############################## 图像平移(平移矩阵:2x3)"""
matTranslation = np.float32([[1, 0, 50], [0, 1, -80]]) # 获取平移矩阵2x3
image_translation = cv2.warpAffine(image, matTranslation, (width, height)) # 仿射变换
"""############################## 图像旋转(旋转矩阵:2x3)"""
matRotation = cv2.getRotationMatrix2D(center=(height//2, width//2), angle=10, scale=1) # 获取旋转矩阵2x3
image_rotation = cv2.warpAffine(src=image, M=matRotation, dsize=(width, height)) # 仿射变换
"""############################## 仿射变换(仿射矩阵:2x3)"""
matSrc_A = np.float32([[0, 0], [0, height-1], [width-1, 0]]) # 输入图像的三个点坐标
matDst_A = np.float32([[50, 50], [100, height-50], [width-200, 100]]) # 仿射变换的三个点坐标
matAffine = cv2.getAffineTransform(matSrc_A, matDst_A) # 获取仿射变换矩阵2x3
image_affine = cv2.warpAffine(src=image, M=matAffine, dsize=(width, height)) # 仿射变换
"""############################## 透视变换(透视矩阵:3x3) ##############################"""
matSrc_P = np.float32([[50, 50], [100, height-50], [width-200, 100], [width-200, height-50]]) # 输入图像的四个点坐标
matDst_P = np.float32([[0, 0], [0, height-1], [width-1, 0], [width-1, height-1]]) # 透视变换的四个点坐标
matWarp = cv2.getPerspectiveTransform(src=matSrc_P, dst=matDst_P) # 获取透视变换矩阵3x3
image_perspective = cv2.warpPerspective(src=image, M=matWarp, dsize=(width, height)) # 透视变换
image_perspective_hstack = np.hstack(tup=(image_affine, image_perspective))
plt.subplot(231), plt.imshow(image), plt.title('image')
plt.subplot(232), plt.imshow(image_shear), plt.title('image_shear')
plt.subplot(233), plt.imshow(image_translation), plt.title('image_translation')
plt.subplot(234), plt.imshow(image_rotation), plt.title('image_rotation')
plt.subplot(235), plt.imshow(image_affine), plt.title('image_affine')
plt.subplot(236), plt.imshow(image_perspective_hstack), plt.title('image_perspective')
plt.show()
# cv2.warpAffine : 错切矩阵np.float32()
# 平移矩阵np.float32()
# 旋转矩阵cv2.getRotationMatrix2D
# 仿射矩阵cv2.getAffineTransform
# cv2.warpPerspective: 透视矩阵cv2.getPerspectiveTransform
"""####################################################################################################################
# 函数功能:计算错切变换矩阵 ———— 根据给定的错切因子计算错切变换矩阵。
# 函数说明:M = np.float32([[1, shx, 0], [shy, 1, 0]])
# 参数说明:
# shx:水平方向的错切因子,类型为 float,表示在 x 方向的错切程度。
# shy:垂直方向的错切因子,类型为 float,表示在 y 方向的错切程度。
# 返回值:
# M: 2x3 错切变换矩阵,类型为 numpy.ndarray。可以用于 cv2.warpAffine 函数进行图像错切。
# 功能描述:
# - 通过错切因子 (shx, shy) 计算出的矩阵 M 可以实现图像的错切操作。
# - 错切变换会将图像中的每个点沿 x 轴或 y 轴进行倾斜,从而产生透视效果。
####################################################################################################################"""
"""####################################################################################################################
# 函数功能:计算平移变换矩阵 ———— 根据给定的平移向量计算平移矩阵。
# 函数说明:M = np.float32([[1, 0, tx], [0, 1, ty]])
# 参数说明:
# tx:沿 x 轴的移动距离,类型为 float。正值表示向右平移,负值表示向左平移。
# ty:沿 y 轴的移动距离,类型为 float。正值表示向下平移,负值表示向上平移。
# 返回值:
# M: 2x3 平移变换矩阵,类型为 numpy.ndarray。可以用于 cv2.warpAffine 函数进行图像平移。
# 功能描述:
# - 通过平移向量 (tx, ty) 计算出的矩阵 M 可以实现图像的平移操作。
# - 平移变换会将图像中的每个点沿 x 和 y 轴移动指定的距离。
####################################################################################################################"""
"""####################################################################################################################
# 函数功能:计算旋转变换矩阵 ———— 根据指定的中心点、旋转角度和缩放因子计算旋转矩阵。
# 函数说明:M = cv2.getRotationMatrix2D(center, angle, scale)
# 参数说明:
# center: 旋转中心,类型为 tuple,格式为 (x, y),表示旋转的中心点坐标。
# angle: 旋转角度,类型为 float,单位为度(逆时针方向为正)。
# scale: 缩放因子,类型为 float,表示图像的缩放比例:1.0表示不缩放、<1.0表示缩小、>1.0表示放大。
# 返回值:
# M: 2x3 旋转变换矩阵,类型为 numpy.ndarray。可以用于 cv2.warpAffine 函数进行图像旋转。
####################################################################################################################"""
"""####################################################################################################################
# 函数功能:计算仿射变换矩阵 ———— 根据源图像和目标图像中的三个点的对应关系计算仿射变换矩阵。
# 函数说明:M = cv2.getAffineTransform(srcPoints, dstPoints)
# 参数说明:
# srcPoints: 源图像中的三个点,类型为 numpy.ndarray,形状为 (3, 2)。点的顺序不固定,但必须是不同的三对点。每个点的坐标值为 (x, y)。
# dstPoints: 目标图像中的三个点,类型为 numpy.ndarray,形状为 (3, 2)。点的顺序应与 srcPoints 一致,表示变换后图像中的对应位置。
# 返回值:
# M: 2x3 仿射变换矩阵,类型为 numpy.ndarray。可以用于 cv2.warpAffine 函数进行图像变换。
####################################################################################################################"""
"""####################################################################################################################
# 函数功能:计算透视变换矩阵 ———— 根据源图像和目标图像中的四个点的对应关系计算透视变换矩阵。
# 函数说明:M = cv2.getPerspectiveTransform(srcPoints, dstPoints)
# 参数说明:
# srcPoints: 源图像中的四个点,类型为 numpy.ndarray,形状为 (4, 2)。点的顺序应为左上角、右上角、右下角、左下角,坐标值为 (x, y)。
# dstPoints: 目标图像中的四个点,类型为 numpy.ndarray,形状为 (4, 2)。点的顺序应与 srcPoints 一致,表示变换后图像中的对应位置。
# 返回值:
# M: 3x3 透视变换矩阵,类型为 numpy.ndarray。可以用于 cv2.warpPerspective 函数进行图像变换。
####################################################################################################################"""
#######################################################################################################################
# 函数功能:仿射变换 ———— 根据给定的仿射变换矩阵对图像进行平移、旋转、缩放和错切等操作,保留图像中的平行性和比例关系。适用于图像校正、特征提取等任务。
# 函数说明:dst = cv2.warpAffine(src, M, dsize, dst=None, flags=cv2.INTER_LINEAR, borderMode=cv2.BORDER_CONSTANT, borderValue=0)
# 参数说明:
# src: 输入图像(可以是彩色或灰度图像)。
# M: 2x3 仿射变换矩阵,通常可以通过 cv2.getAffineTransform 计算得到。
# 矩阵形式为: M = [[a, b, tx],
# [c, d, ty]]
# 其中 (a, b, c, d) 控制旋转和缩放,(tx, ty) 控制平移。
# dsize: 输出图像的大小(宽度,高度),类型为 tuple。
# dst: 输出图像(可选),可以为 None。若提供,图像将写入此变量。
# flags: 插值方法,决定如何估算新像素的值。常见的取值包括:
# cv2.INTER_NEAREST:最近邻插值
# cv2.INTER_LINEAR:双线性插值(默认)
# cv2.INTER_CUBIC:双三次插值
# cv2.INTER_AREA:区域插值,适用于图像缩小
# borderMode:边界填充模式,定义当变换后的图像超出边界时的处理方式。常见取值包括:
# cv2.BORDER_CONSTANT:常数填充(默认),由 borderValue 指定填充值。
# cv2.BORDER_REPLICATE:复制边缘像素,超出部分与边缘像素相同。
# cv2.BORDER_REFLECT:反射边缘像素,生成的图像边缘是其反射。
# cv2.BORDER_REFLECT_101:类似于 BORDER_REFLECT,但不包括边缘的第一个像素。
# cv2.BORDER_WRAP:用图像的对立边界填充。
# borderValue:边界填充值(默认值为 0),用于 cv2.BORDER_CONSTANT 模式下。
# 对于彩色图像,可以指定为三个值的元组,例如 (b, g, r),表示填充颜色的 BGR 值。
# 返回值:
# dst: 仿射变换后的输出图像,类型为 numpy.ndarray。
#######################################################################################################################
#######################################################################################################################
# 函数功能:透视变换 ———— 对图像进行投影、旋转、缩放等操作,常用于校正图像的透视畸变或者进行图像矫正。
# 函数说明:dst = cv2.warpPerspective(src, M, dsize, dst=None, flags=cv2.INTER_LINEAR, borderMode=cv2.BORDER_CONSTANT, borderValue=0)
# 参数说明:
# src: 输入图像(可以是彩色或灰度图像)。
# M: 3x3 变换矩阵。可以通过 cv2.getPerspectiveTransform 或 cv2.findHomography 计算得到。
# dsize: 输出图像的大小(宽度,高度),类型为 tuple。
# dst: 输出图像(可选),可以为 None。若提供,图像将写入此变量。
# flags: 插值方法,决定如何估算新像素的值。常见的取值包括:
# cv2.INTER_NEAREST:最近邻插值
# cv2.INTER_LINEAR:双线性插值(默认)
# cv2.INTER_CUBIC:双三次插值
# cv2.INTER_AREA:区域插值,适用于图像缩小
# cv2.INTER_LANCZOS4:Lanczos插值,适用于高质量缩放
# borderMode:边界填充模式,定义当变换后的图像超出边界时的处理方式。常见取值包括:
# cv2.BORDER_CONSTANT:常数填充(默认),由 borderValue 指定填充值。
# cv2.BORDER_REPLICATE:复制边缘像素,超出部分与边缘像素相同。
# cv2.BORDER_REFLECT:反射边缘像素,生成的图像边缘是其反射。
# cv2.BORDER_REFLECT_101:类似于 BORDER_REFLECT,但不包括边缘的第一个像素。
# cv2.BORDER_WRAP:用图像的对立边界填充。
# cv2.BORDER_TRANSPARENT:保持透明,适用于图像有 alpha 通道的情况。
# borderValue:边界填充值(默认值为 0),用于 cv2.BORDER_CONSTANT 模式下。
# 对于彩色图像,可以指定为三个值的元组,例如 (b, g, r),表示填充颜色的 BGR 值。
# 返回值:
# dst: 透视变换后的输出图像,类型为 numpy.ndarray。
#######################################################################################################################
# -*- coding: utf-8 -*-
# 作者: 胖墩会武术
# 日期: 1994-08-21
# OpenCV图像处理: https://blog.csdn.net/shinuone/article/details/126022763
(7)投影变换
(7.1)基于(仿射变换)的边界填充模式完成投影变换

import skimage
import numpy as np
import cv2 # opencv读取图像默认为BGR
import matplotlib.pyplot as plt # matplotlib显示图像默认为RGB
# (1)加载图像(硬币图像)
img = skimage.data.coins()
h, w = img.shape[:2] # 图片的高度和宽度
# (2)计算仿射变换矩阵
pointSrc = np.float32([[0, 0], [w, 0], [0, h]]) # 原始图像中的 3点坐标
pointDst = np.float32([[int(w / 3), int(h / 3)], [int(w * 2 / 3), int(h / 4)], [0, h]]) # 变换图像中的 3点坐标
M = cv2.getAffineTransform(pointSrc, pointDst) # 计算变换矩阵 M
# (3)仿射变换
imgA1 = cv2.warpAffine(img, M, (w, h), flags=cv2.INTER_AREA, borderMode=cv2.BORDER_CONSTANT)
imgA2 = cv2.warpAffine(img, M, (w, h), flags=cv2.INTER_AREA, borderMode=cv2.BORDER_REPLICATE)
imgA3 = cv2.warpAffine(img, M, (w, h), flags=cv2.INTER_AREA, borderMode=cv2.BORDER_REFLECT)
imgA4 = cv2.warpAffine(img, M, (w, h), flags=cv2.INTER_AREA, borderMode=cv2.BORDER_REFLECT_101)
imgA5 = cv2.warpAffine(img, M, (w, h), flags=cv2.INTER_AREA, borderMode=cv2.BORDER_WRAP)
# (4)显示图像
plt.subplot(161), plt.imshow(cv2.cvtColor(img, cv2.COLOR_BGR2RGB)), plt.title("Original"), plt.axis('off')
plt.subplot(162), plt.imshow(cv2.cvtColor(imgA1, cv2.COLOR_BGR2RGB)), plt.title("Affine (Constant)"), plt.axis('off')
plt.subplot(163), plt.imshow(cv2.cvtColor(imgA2, cv2.COLOR_BGR2RGB)), plt.title("Affine (Replicate)"), plt.axis('off')
plt.subplot(164), plt.imshow(cv2.cvtColor(imgA3, cv2.COLOR_BGR2RGB)), plt.title("Affine (Reflect)"), plt.axis('off')
plt.subplot(165), plt.imshow(cv2.cvtColor(imgA4, cv2.COLOR_BGR2RGB)), plt.title("Affine (Reflect_101)"), plt.axis('off')
plt.subplot(166), plt.imshow(cv2.cvtColor(imgA5, cv2.COLOR_BGR2RGB)), plt.title("Affine (Wrap)"), plt.axis('off')
plt.show()
# -*- coding: utf-8 -*-
# 作者: 胖墩会武术
# 日期: 1994-08-21
# OpenCV图像处理: https://blog.csdn.net/shinuone/article/details/126022763
(7.2)基于(透视变换)的边界填充模式完成投影变换

import skimage
import numpy as np
import cv2 # opencv读取图像默认为BGR
import matplotlib.pyplot as plt # matplotlib显示图像默认为RGB
# (1)加载图像(硬币图像)
img = skimage.data.coins()
h, w = img.shape[:2] # 图片的高度和宽度
# (2)计算透视变换矩阵
pointSrc = np.float32([[0, 0], [w, 0], [0, h], [w, h]]) # 原始图像中的 4点坐标
pointDst = np.float32([[int(w / 3), int(h / 3)], [int(w * 2 / 3), int(h / 3)], [0, h], [w, h]]) # 变换图像中的 4点坐标
M = cv2.getPerspectiveTransform(pointSrc, pointDst) # 计算变换矩阵 M
# (3)透视变换
imgP1 = cv2.warpPerspective(img, M, (w, h), flags=cv2.INTER_AREA, borderMode=cv2.BORDER_CONSTANT)
imgP2 = cv2.warpPerspective(img, M, (w, h), flags=cv2.INTER_AREA, borderMode=cv2.BORDER_REPLICATE)
imgP3 = cv2.warpPerspective(img, M, (w, h), flags=cv2.INTER_AREA, borderMode=cv2.BORDER_REFLECT)
imgP4 = cv2.warpPerspective(img, M, (w, h), flags=cv2.INTER_AREA, borderMode=cv2.BORDER_REFLECT_101)
imgP5 = cv2.warpPerspective(img, M, (w, h), flags=cv2.INTER_AREA, borderMode=cv2.BORDER_WRAP)
# (4)显示图像
plt.subplot(161), plt.imshow(cv2.cvtColor(img, cv2.COLOR_BGR2RGB)), plt.title("Original"), plt.axis('off')
plt.subplot(162), plt.imshow(cv2.cvtColor(imgP1, cv2.COLOR_BGR2RGB)), plt.title("Projective (CONSTANT)"), plt.axis('off')
plt.subplot(163), plt.imshow(cv2.cvtColor(imgP2, cv2.COLOR_BGR2RGB)), plt.title("Projective (REPLICATE)"), plt.axis('off')
plt.subplot(164), plt.imshow(cv2.cvtColor(imgP3, cv2.COLOR_BGR2RGB)), plt.title("Projective (REFLECT)"), plt.axis('off')
plt.subplot(165), plt.imshow(cv2.cvtColor(imgP4, cv2.COLOR_BGR2RGB)), plt.title("Projective (REFLECT_101)"), plt.axis('off')
plt.subplot(166), plt.imshow(cv2.cvtColor(imgP5, cv2.COLOR_BGR2RGB)), plt.title("Projective (WRAP)"), plt.axis('off')
plt.show()
# -*- coding: utf-8 -*-
# 作者: 胖墩会武术
# 日期: 1994-08-21
# OpenCV图像处理: https://blog.csdn.net/shinuone/article/details/126022763



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











