






Momentum Contrast (MoCo):革新无监督视觉表征学习的动态字典方法
在深度学习领域,无监督学习一直是研究的热点,尤其是在自然语言处理(NLP)中取得了显著成功(如 GPT 和 BERT)。然而,在计算机视觉领域,无监督方法与监督预训练相比仍存在较大差距。Facebook AI Research (FAIR) 的研究团队在论文《Momentum Contrast for Unsupervised Visual Representation Learning》中提出了 Momentum Contrast (MoCo),一种创新的无监督视觉表征学习方法。本篇博客将面向深度学习研究者,深入剖析 MoCo 的创新点及其解决的问题,并提供一些研究洞察。
下文中图片来自于原论文:https://arxiv.org/pdf/1911.05722
背景与问题
视觉表征学习的目标是从数据中提取有意义的特征,这些特征可以迁移到下游任务(如目标检测、分割等)。传统的监督预训练依赖于大量标注数据(如 ImageNet),但标注成本高昂且难以扩展到更大规模的未标注数据集。与此同时,视觉信号空间是连续且高维的,缺乏类似语言中的离散单元(如单词),这使得构建适用于无监督学习的“字典”成为一大挑战。
近年来,基于对比损失(contrastive loss)的无监督方法(如 [61, 46, 36])显示出潜力。这些方法通过训练编码器,使其能够区分“查询”(query)和匹配的“键”(key),从而学习表征(详细解释请见下文)。然而,现有方法在字典的规模和一致性上存在局限:
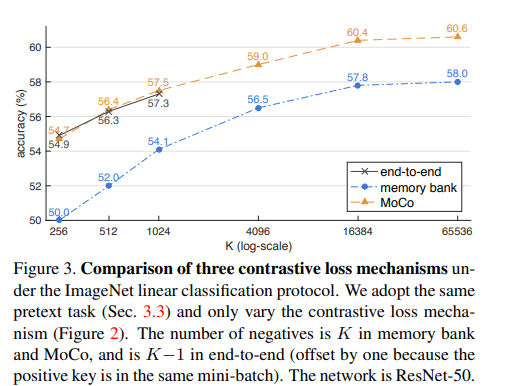
- 端到端方法:字典大小受限于 mini-batch 大小(受 GPU 内存限制),无法充分利用大规模数据。(下文有详细解释)
- 记忆库方法:虽然支持更大的字典,但键的表征来自不同时期的编码器,缺乏一致性,导致性能下降。(下文有详细解释)
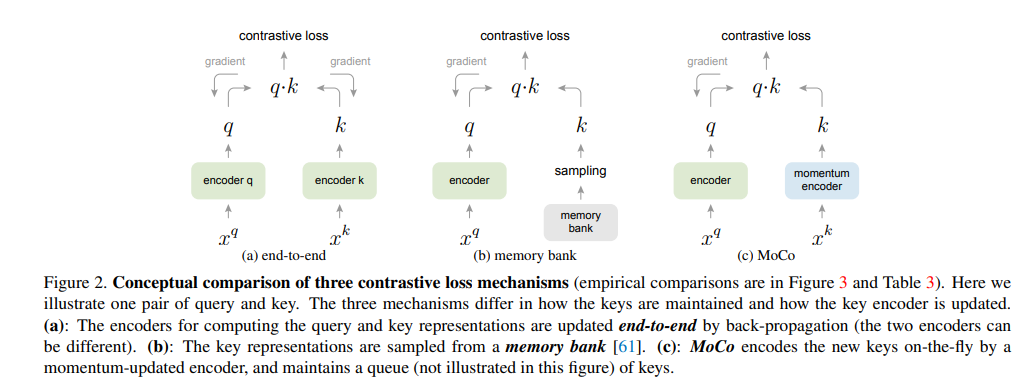
MoCo 的核心问题在于:如何构建一个既大规模又一致的动态字典,以提升对比学习的效果?
MoCo 的创新点
MoCo 提出了一种新颖的机制,通过队列形式的动态字典和动量更新的编码器解决了上述问题。以下是其主要创新点:
- 队列形式的字典
- 创新:MoCo 将字典设计为一个队列,当前 mini-batch 的编码表征入队,最旧的 mini-batch 出队。这种设计将字典大小与 mini-batch 大小解耦,允许字典规模远超单次 mini-batch。
- 解决的问题:传统端到端方法受限于 mini-batch 大小(例如最大 1024),而 MoCo 的队列机制支持更大的字典(如 65536 个负样本),更好地覆盖高维视觉空间。
- Insight:更大的字典意味着更多的负样本,这在对比学习中至关重要。实验表明(图 3),字典越大,表征质量越高,这为研究者提示了一个方向:如何进一步扩展字典规模而不增加计算成本?
- 动量更新编码器
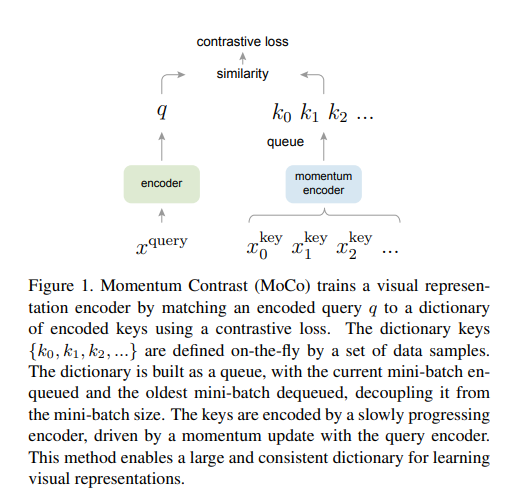
- 创新:MoCo 使用动量更新来维护键编码器(key encoder),其参数通过查询编码器(query encoder)的加权平均缓慢更新:
θ k ← m θ k + ( 1 − m ) θ q \theta_k \leftarrow m \theta_k + (1 - m) \theta_q θk←mθk+(1−m)θq
其中 ( m m m ) 是动量系数(默认 0.999)。只有查询编码器的参数通过反向传播更新。 - 解决的问题:队列中的键来自多个 mini-batch,若直接复制查询编码器会导致一致性缺失,而动量更新使键编码器缓慢演化,确保键表征的一致性。实验表明,较小的 ( m m m )(如 0.9)会导致性能显著下降。
- Insight:一致性比单纯的字典规模更重要。动量更新的平滑性避免了表征的剧烈变化,这启发研究者思考如何在动态系统中平衡更新速度与稳定性。
- 通用性与下游任务迁移
- 创新:MoCo 不依赖特定预训练任务(如拼图或特定网络设计),使用简单的实例区分任务即可实现竞争性结果。更重要的是,其表征在 7 个下游任务(PASCAL VOC、COCO 等)中超越了 ImageNet 监督预训练。
- 解决的问题:传统无监督方法往往需要定制化设计,限制了迁移能力。MoCo 的通用性使其更接近现实应用场景。
- Insight:无需复杂预训练任务也能获得高质量表征,表明对比学习的潜力可能在于损失函数设计而非任务复杂度。这提示研究者可以专注于优化对比机制而非设计新颖任务。
解决的核心问题
MoCo 解决了无监督视觉表征学习中的两大关键问题:
- 字典规模受限:通过队列机制,MoCo 突破了 mini-batch 大小的限制,使字典规模成为可调超参数。
- 表征一致性不足:动量更新确保了队列中键表征的稳定性,避免了因编码器快速变化导致的性能下降。
这些改进使 MoCo 在 ImageNet 线性分类协议下达到 60.6%(ResNet-50)的准确率,并在更大数据集(如 Instagram 1B)上进一步提升下游任务性能,缩小了无监督与监督学习之间的差距。
对深度学习研究者的洞察
-
动态字典的潜力
MoCo 的队列设计表明,动态采样的字典是无监督学习的一个关键方向。研究者可以探索其他数据结构(如优先级队列)或采样策略(如基于难度的负样本选择),以进一步优化字典质量。 -
动量机制的普适性
动量更新不仅适用于视觉任务,也可能在其他领域(如 NLP 或多模态学习)中提升对比学习的稳定性。研究者可以尝试调整 ( m m m ) 的动态调度,或结合其他平滑技术(如 EMA 的变种)。 -
从规模到质量的转变
MoCo 在 IG-1B 数据上的增益虽明显但有限(Sec. 5),提示单纯增加数据规模可能不足以突破瓶颈。未来的工作应关注预训练任务的设计(如掩码自编码)或数据质量的提升。 -
迁移能力的评估
MoCo 在下游任务中的优异表现表明,评估无监督方法时应更重视迁移性而非单一基准(如线性分类)。研究者可以设计更全面的测试集,涵盖多样化的视觉任务。
结语
MoCo 通过创新的动态字典和动量更新机制,为无监督视觉表征学习提供了一个强大而通用的框架。它不仅在理论上解决了字典规模与一致性的矛盾,还在实践中证明了其超越监督预训练的潜力。对于深度学习研究者而言,MoCo 的成功提示我们:简单而优雅的设计往往能带来意想不到的效果。未来的研究可以围绕字典优化、动量机制扩展以及更高效的预训练任务展开,持续推动无监督学习的边界。
代码已开源(https://github.com/facebookresearch/moco),欢迎研究者动手实验,探索更多可能性!
对比损失(Contrastive Loss)原理与“查询”和“键”的含义
近年来,基于对比损失(contrastive loss)的无监督学习方法在计算机视觉领域展现出显著潜力,例如论文中提到的 [61, 46, 36] 等工作。这些方法的核心是通过训练一个编码器,使其能够区分“查询”(query)和匹配的“键”(key),从而学习到鲁棒的视觉表征。以下将详细介绍这一原理,并澄清“查询”(q)和“键”(key)的具体含义,特别是它们是否是图片。
对比损失的基本原理
对比损失最初由 Hadsell 等人 [29] 提出,旨在通过度量样本对在表征空间中的相似性来学习特征。其核心思想是:
- 正样本对:让一对“相似”的样本(比如同一对象的不同视角)在表征空间中靠得更近。
- 负样本对:让“不同”的样本在表征空间中分开得更远。
在无监督学习中,对比损失被用来构造一个“字典查找”任务。具体来说:
- 输入:给定一个样本(例如一张图片),通过编码器生成其表征。
- 目标:训练编码器,使某个“查询”表征(query)与对应的“正键”(positive key)相似,同时与大量“负键”(negative keys)保持差异。
- 损失函数:通常采用 InfoNCE 损失(见论文公式 (1),具体原理可以参考笔者的另一篇博客:深入解析 InfoNCE Loss:对比学习的基石(是在什么背景下提出来的?)),其形式为:
L q = − log exp ( q ⋅ k + / τ ) ∑ i = 0 K exp ( q ⋅ k i / τ ) \mathcal{L}_q = -\log \frac{\exp(q \cdot k_+ / \tau)}{\sum_{i=0}^K \exp(q \cdot k_i / \tau)} Lq=−log∑i=0Kexp(q⋅ki/τ)exp(q⋅k+/τ)
其中:- ( q q q ) 是查询的表征;
- ( k + k_+ k+ ) 是正键的表征;
- ( k i k_i ki ) 是负键的表征(( i = 0 , 1 , . . . , K i = 0, 1, ..., K i=0,1,...,K ));
- ( τ \tau τ ) 是温度超参数,用于控制分布的平滑性。
直观来看,这是一个 softmax 分类问题:目标是将 ( q q q ) 正确分类为 ( k + k_+ k+ ),而非其他 ( K K K ) 个负样本。
“查询”(q)和“键”(key)是什么?是图片吗?
在对比学习中,“查询”(query)和“键”(key)并不是图片本身,而是图片经过编码器处理后的表征向量。让我们逐步澄清:
-
输入是图片:
- 初始输入确实是图片(或图片的某种变换形式,例如裁剪、旋转等)。
- 例如,在 MoCo 的实例区分任务(instance discrimination task)中,输入可能是一张图片的不同视图(比如两次随机裁剪的结果)。
-
编码器生成表征:
- 输入图片被送入编码器(通常是一个深度神经网络,如 ResNet),输出一个低维向量(例如 128 维或 2048 维的特征向量)。
- 查询 ( q q q ) 是编码器对某个输入 ( x q x^q xq ) 的输出:( q = f q ( x q ) q = f_q(x^q) q=fq(xq) );
- 键 ( k k k ) 是编码器对另一个输入 ( x k x^k xk ) 的输出:( k = f k ( x k ) k = f_k(x^k) k=fk(xk) )。
-
正键与负键的定义:
- 正键 ( k + k_+ k+ ):通常是与查询 ( q q q ) 来自同一张原始图片的表征。例如,如果 ( q q q ) 是图片 ( I I I ) 的一个裁剪区域的表征,( k + k_+ k+ ) 可能是同一张图片 ( I I I ) 的另一个裁剪区域的表征。
- 负键 ( k i k_i ki ):是从其他图片(或同一批次中其他样本)生成的表征,与 ( q q q ) 无关。
-
具体到 MoCo:
- 在 MoCo 中,查询 ( q q q ) 和正键 ( k + k_+ k+ ) 是同一张图片的两个增强版本(augmented views)的表征。
- 负键 ( k i k_i ki ) 则来自队列中存储的其他图片的表征,这些图片与查询图片不同。
因此,( q q q ) 和 ( k k k ) 都不是图片,而是图片的特征表示。它们是高维空间中的向量,代表了图片经过编码器提取后的语义信息。
为什么这样设计?
这种“查询”和“键”的设计有以下优势:
-
无监督特性:
- 通过将同一图片的不同视图视为正样本对,无需人工标签即可构造监督信号。
- 负样本则通过随机采样其他图片自然生成,形成对比。
-
字典查找的视角:
- 论文将对比学习类比为字典查找:( q q q ) 是查询,( k + k_+ k+ ) 是字典中匹配的条目,( k i k_i ki ) 是其他不匹配的条目。
- 训练的目标是让编码器学会从“字典”中检索正确的键,从而捕获图片的内在语义。
-
表征的鲁棒性:
- 通过增强(augmentation,如裁剪、颜色抖动),( q q q ) 和 ( k + k_+ k+ ) 虽然来自同一图片,但表面差异较大。迫使编码器聚焦于不变的深层特征(如形状、结构),而不是浅层特征(如颜色)。
MoCo 中的具体实现
在 MoCo 中:
- 查询编码器 ( f q f_q fq ):实时更新,通过反向传播优化。
- 键编码器 ( f k f_k fk ):通过动量更新缓慢演化,保持一致性。
- 字典:以队列形式存储多个 mini-batch 的键表征,支持大规模负样本。
例如:
- 一张图片 ( I I I ) 被增强两次,生成 ( x q x^q xq )(如左上角裁剪)和 ( x k x^k xk )(如右下角裁剪)。
- ( q = f q ( x q ) q = f_q(x^q) q=fq(xq) ) 是查询表征。
- ( k + = f k ( x k ) k_+ = f_k(x^k) k+=fk(xk) ) 是正键表征。
- 队列中的 ( k 0 , k 1 , . . . , k K k_0, k_1, ..., k_K k0,k1,...,kK ) 是之前 mini-batch 中其他图片的表征,作为负样本。
训练时,MoCo 通过对比损失优化 ( f q f_q fq ),使 ( q q q ) 与 ( k + k_+ k+ ) 的点积最大化,与负键的点积最小化。
总结
对比损失的原理是通过区分“查询”和“键”的相似性来学习表征,其中 ( q q q ) 和 ( k k k ) 不是图片,而是图片经过编码器生成的特征向量。在 MoCo 中,这种设计被进一步优化,通过队列和动量更新实现了大规模且一致的字典,从而提升了无监督学习的性能。这一机制的核心在于利用数据本身的结构(如同一图片的多个视图),为研究者提供了一个无需标签即可挖掘视觉语义的强大工具。
端到端方法在对比学习中的原理与限制
在基于对比损失(contrastive loss)的无监督视觉表征学习中,“端到端方法”(end-to-end approach)是一种常见机制,例如在 [29, 46, 36, 63, 2, 35] 等工作中被广泛采用。这种方法通过直接反向传播更新查询编码器和键编码器来训练模型。然而,它的一个显著局限是字典大小受限于 mini-batch 大小,这直接受到 GPU 内存的限制,无法充分利用大规模数据。以下将详细解释其原理、限制原因,并提供代码实现的思路。
端到端方法的原理
端到端方法的核心是将查询(query)和键(key)的编码器作为一个整体,通过反向传播同时更新它们的参数。其工作流程如下:
-
输入:
- 从数据集中采样一个 mini-batch 的图片(例如大小为 ( N N N ) 的批次)。
- 对每张图片应用两次随机增强(augmentation),生成两个视图:查询视图 ( x q x^q xq ) 和键视图 ( x k x^k xk )。
-
编码:
- 查询视图 ( x q x^q xq ) 通过查询编码器 ( f q f_q fq ) 生成表征 ( q = f q ( x q ) q = f_q(x^q) q=fq(xq) )。
- 键视图 ( x k x^k xk ) 通过键编码器 ( f k f_k fk ) 生成表征 ( k = f k ( x k ) k = f_k(x^k) k=fk(xk) )。
-
对比损失:
- 对于每个查询 ( q i q_i qi )(来自第 ( i i i ) 张图片的查询视图),其正键 ( k i k_i ki ) 是同一张图片的键视图的表征。
- 负键则是当前 mini-batch 中其他图片的键表征(即 ( k j k_j kj ),其中 ( j ≠ i j \neq i j=i ))。
- 计算 InfoNCE 损失:
L q = − log exp ( q i ⋅ k i / τ ) ∑ j = 0 N − 1 exp ( q i ⋅ k j / τ ) \mathcal{L}_q = -\log \frac{\exp(q_i \cdot k_i / \tau)}{\sum_{j=0}^{N-1} \exp(q_i \cdot k_j / \tau)} Lq=−log∑j=0N−1exp(qi⋅kj/τ)exp(qi⋅ki/τ)
这里,字典大小为 ( N N N )(mini-batch 大小),包含 1 个正样本和 ( N − 1 N-1 N−1 ) 个负样本。
-
优化:
- 通过反向传播计算损失对 ( f q f_q fq ) 和 ( f k f_k fk ) 参数的梯度,同时更新两个编码器。
-
一致性:
- 因为 ( f q f_q fq ) 和 ( f k f_k fk ) 是实时更新的,且通常共享参数(即 ( f q = f k f_q = f_k fq=fk )),当前 mini-batch 中的所有键表征是一致的(由同一组参数生成)。
这种方法直观且易于实现,因为它完全依赖当前 mini-batch 的数据进行训练,无需额外的存储结构(如队列或记忆库)。
为什么字典大小受限于 mini-batch 大小?
在端到端方法中,字典大小(即负样本的数量加上正样本)直接等于 mini-batch 大小 ( N N N )。这一限制的根本原因在于计算和内存需求:
-
计算需求:
- InfoNCE 损失要求对每个查询 ( q i q_i qi ) 计算其与所有键 ( k j k_j kj )(包括正键和负键)的相似度(通常是点积)。
- 对于一个 mini-batch 大小为 ( N N N ) 的批次,每个查询需要与 ( N N N ) 个键计算相似度,总计算复杂度为 ( O ( N 2 ) O(N^2) O(N2) )。
- 如果字典大小超过 mini-batch 大小(例如引入外部样本),则需要额外的计算和存储,这会打破端到端的实时更新特性。
-
GPU 内存限制:
- 在深度学习中,神经网络的训练依赖 GPU 加速。mini-batch 中的所有输入图片、编码器参数、中间特征图和梯度都需要存储在 GPU 内存中。
- 假设编码器输出表征的维度为 ( D D D )(如 128 或 2048),则一个 mini-batch 的查询和键表征需要 ( 2 × N × D × sizeof(float) 2 \times N \times D \times \text{sizeof(float)} 2×N×D×sizeof(float) ) 的内存(乘以 2 是因为有查询和键两组表征)。
- 对于较大的 ( N N N )(如 1024),内存需求迅速增加。例如,若 ( D = 128 D = 128 D=128 ),( N = 1024 N = 1024 N=1024 ),则表征矩阵占用约 ( 2 × 1024 × 128 × 4 ≈ 1 MB 2 \times 1024 \times 128 \times 4 \approx 1 \text{MB} 2×1024×128×4≈1MB ),加上模型参数和中间计算(如卷积层的激活),总内存需求可能达到数 GB。
- 高端 GPU(如 Volta 32GB)能支持的最大 mini-batch 大小通常在 1024 左右,进一步增加 ( N N N ) 会超出内存容量。
-
实时更新的要求:
- 端到端方法要求所有键表征由当前编码器生成并参与损失计算。如果字典包含来自之前 mini-batch 的键(如同 MoCo 的队列),这些键的编码器参数已过时,无法通过当前梯度更新,导致一致性问题。
- 因此,字典只能局限于当前 mini-batch,避免引入额外的复杂性。
总结:字典大小受限于 mini-batch 大小,是因为端到端方法需要在单次前向传播中计算所有查询和键的相似度,并通过反向传播更新编码器,而 GPU 内存限制了可处理的样本数量。论文中提到,即使使用 8 个 Volta 32GB GPU,最大 mini-batch 也仅为 1024,远小于 MoCo 的 65536。
为什么无法充分利用大规模数据?
由于字典大小受限于 mini-batch,端到端方法无法充分利用大规模数据集的丰富多样性:
- 负样本数量有限:负样本的数量直接影响表征的质量。更大的字典(更多负样本)能更好地覆盖高维视觉空间,但端到端方法最多只有 ( N − 1 N-1 N−1 ) 个负样本。
- 采样不足:mini-batch 是数据集的一个小随机子集(例如 ImageNet 的 1M 张图片中,1024 张仅占 0.1%),无法代表全局分布。
- 优化难度:论文提到,大 mini-batch 训练需要线性学习率缩放规则 [25],否则准确率下降约 2%。但大 mini-batch 优化本身是一个开放问题,难以扩展到更大规模。
相比之下,MoCo 通过队列机制将字典大小扩展到数万,充分利用了更多数据,显著提升了表征质量。
代码实现示例
以下是一个简化的端到端对比学习实现的伪代码(基于 PyTorch),以实例区分任务为例:
import torch
import torch.nn as nn
import torch.nn.functional as F
# 定义编码器(简单使用 ResNet)
class Encoder(nn.Module):
def __init__(self):
super().__init__()
self.backbone = torch.hub.load('pytorch/vision', 'resnet18', pretrained=False)
self.backbone.fc = nn.Linear(512, 128) # 输出 128 维表征
def forward(self, x):
return self.backbone(x)
# InfoNCE 损失函数
def info_nce_loss(q, k, temperature=0.2):
# q: [N, D], k: [N, D], N 是 mini-batch 大小,D 是表征维度
N = q.size(0)
logits = torch.matmul(q, k.T) / temperature # [N, N] 相似度矩阵
labels = torch.arange(N).to(q.device) # 正样本标签为对角线
return F.cross_entropy(logits, labels)
# 训练循环
def train_end_to_end():
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
encoder = Encoder().to(device)
optimizer = torch.optim.SGD(encoder.parameters(), lr=0.03, momentum=0.9, weight_decay=1e-4)
# 假设数据加载器返回 mini-batch 的两个视图
data_loader = ... # 提供 (img1, img2) 对,img1 和 img2 是同一图片的增强视图
for epoch in range(200):
for img1, img2 in data_loader:
img1, img2 = img1.to(device), img2.to(device) # [N, C, H, W]
# 生成查询和键表征
q = encoder(img1) # [N, 128]
k = encoder(img2) # [N, 128]
# 计算损失
loss = info_nce_loss(q, k)
# 反向传播更新编码器
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f"Epoch {epoch}, Loss: {loss.item()}")
if __name__ == "__main__":
train_end_to_end()
代码说明:
- 编码器:使用 ResNet18,将输入图片映射到 128 维表征。
- 损失计算:( q q q ) 和 ( k k k ) 是 mini-batch 中 ( N N N ) 个样本的表征,相似度矩阵 ( [ N , N ] [N, N] [N,N] ) 的对角线元素对应正样本。
- 优化:通过反向传播同时更新编码器参数,字典大小固定为 ( N N N )。
限制体现:
- 负样本数量为 ( N − 1 N-1 N−1 ),由 mini-batch 大小决定。
- 若 ( N N N ) 过大(如 2048),GPU 内存可能不足,导致程序崩溃。
总结
端到端方法的字典大小受限于 mini-batch 大小,是因为它依赖当前批次内的样本计算对比损失并实时更新编码器,而 GPU 内存限制了批次规模。这种设计虽然简单且一致性高,但无法扩展到大规模数据。MoCo 通过队列和动量更新突破了这一瓶颈,为研究者提供了更灵活的替代方案。代码实现中,mini-batch 大小的选择直接决定了字典的规模,凸显了硬件约束对算法设计的深远影响。
记忆库方法(Memory Bank Approach)在对比学习中的原理与局限
在基于对比损失(contrastive loss)的无监督视觉表征学习中,“记忆库方法”(memory bank approach)是一种重要的机制,最早由 Wu 等人 [61] 提出。与端到端方法不同,记忆库方法通过维护一个大规模的表征存储(memory bank)来支持更大的字典,从而克服了 mini-batch 大小的限制。然而,它的局限在于键的表征来自不同时期的编码器,缺乏一致性,导致性能下降。以下将详细解释其原理、为何只更新查询编码器,以及如何通过代码实现。
记忆库方法的原理
记忆库方法的设计初衷是构建一个包含数据集所有样本表征的“记忆库”,从而支持大规模的负样本字典。其工作流程如下:
-
记忆库初始化:
- 为数据集中的每一张图片分配一个表征向量,存储在一个记忆库中(例如大小为 ( M × D M \times D M×D ),其中 ( M M M ) 是数据集样本数,( D D D ) 是表征维度)。
- 初始时,这些表征可以随机生成,或通过预训练编码器一次性计算。
-
输入与编码:
- 在每个训练步骤中,从数据集中采样一个 mini-batch(大小为 ( N N N ))。
- 对每张图片应用增强生成查询视图 ( x q x^q xq ),通过查询编码器 ( f q f_q fq ) 生成查询表征 ( q = f q ( x q ) q = f_q(x^q) q=fq(xq) )。
-
正键与负键:
- 正键 ( k + k_+ k+ ):通常是同一张图片的另一个增强视图的表征,可以通过当前编码器实时计算,或者从记忆库中提取(取决于具体实现)。
- 负键 ( k i k_i ki ):从记忆库中随机采样一组表征(例如 ( K K K ) 个负样本),这些表征由之前的编码器生成并存储。
-
对比损失:
- 使用 InfoNCE 损失计算:
L q = − log exp ( q ⋅ k + / τ ) exp ( q ⋅ k + / τ ) + ∑ i = 0 K exp ( q ⋅ k i / τ ) \mathcal{L}_q = -\log \frac{\exp(q \cdot k_+ / \tau)}{\exp(q \cdot k_+ / \tau) + \sum_{i=0}^{K} \exp(q \cdot k_i / \tau)} Lq=−logexp(q⋅k+/τ)+∑i=0Kexp(q⋅ki/τ)exp(q⋅k+/τ)
这里,字典大小为 ( K + 1 K + 1 K+1 )(1 个正样本 + ( K K K ) 个负样本),( K K K ) 可以远大于 mini-batch 大小 ( N )。
- 使用 InfoNCE 损失计算:
-
更新:
- 查询编码器 ( f q f_q fq ):通过反向传播更新其参数。
- 记忆库:对于当前 mini-batch 中的图片,用 ( f q f_q fq ) 的输出更新记忆库中对应位置的表征(通常采用动量更新或直接替换)。
-
一致性问题:
- 记忆库中的表征来自不同训练阶段的编码器。例如,某个键可能在第 1 个 epoch 生成,而另一个键在第 50 个 epoch 更新。由于编码器随训练不断变化,这些键表征缺乏一致性。
为什么只用梯度下降更新查询编码器,记忆库中的键不需要更新?
在记忆库方法中,只有查询编码器 ( f q f_q fq ) 通过梯度下降更新,而记忆库中的键表征不直接参与反向传播。原因如下:
-
计算不可行性:
- 记忆库通常包含整个数据集的表征(例如 ImageNet 的 1M 张图片),规模远超 mini-batch。如果对所有键表征计算梯度并更新编码器,计算成本和内存需求将不可承受。
- 例如,若 ( M = 1 , 000 , 000 M = 1,000,000 M=1,000,000 ),每次训练需要为 1M 个表征计算梯度,这在当前硬件条件下几乎不可能。
-
设计选择:
- 记忆库方法将键编码器视为“静态”的历史记录,不参与实时梯度计算。负键 ( k i k_i ki ) 是从记忆库中采样的已有表征,仅用于对比损失的计算,不需要更新其生成时的编码器。
- 正键 ( k + k_+ k+ ) 可以选择实时计算(用 ( f q f_q fq )),但为了保持一致性,Wu 等人 [61] 建议直接从记忆库中提取。
-
记忆库的更新策略:
- 虽然键表征不通过梯度更新,但记忆库会随着训练逐步刷新。例如,对于当前 mini-batch 中的图片 (
x
i
x_i
xi ),其表征 (
q
i
q_i
qi ) 会以某种方式(如直接替换或动量更新)写入记忆库对应位置:
v i ← α v i + ( 1 − α ) q i v_i \leftarrow \alpha v_i + (1 - \alpha) q_i vi←αvi+(1−α)qi
其中 ( v i v_i vi ) 是记忆库中第 ( i i i ) 张图片的表征,( α \alpha α ) 是动量系数(通常接近 1)。 - 这种更新是“被动”的,不涉及梯度下降,而是依赖查询编码器的最新输出。
- 虽然键表征不通过梯度更新,但记忆库会随着训练逐步刷新。例如,对于当前 mini-batch 中的图片 (
x
i
x_i
xi ),其表征 (
q
i
q_i
qi ) 会以某种方式(如直接替换或动量更新)写入记忆库对应位置:
-
一致性缺陷:
- 因为记忆库中的表征由不同时期的编码器生成(例如,一个表征可能在训练初期生成,另一个在后期),它们之间的差异会导致对比损失的计算不一致。论文中提到,这种不一致性使记忆库方法在性能上落后于 MoCo(例如 58.0% vs. 60.6% 的 ImageNet 线性分类准确率)。
总结:记忆库方法只更新 ( f q f_q fq ),是因为键表征来自一个静态存储,其更新通过替换或动量方式完成,而非梯度下降。这种设计支持了大规模字典,但牺牲了表征一致性。
代码实现示例
以下是一个简化的记忆库方法实现(基于 PyTorch),以实例区分任务为例:
import torch
import torch.nn as nn
import torch.nn.functional as F
# 定义编码器
class Encoder(nn.Module):
def __init__(self):
super().__init__()
self.backbone = torch.hub.load('pytorch/vision', 'resnet18', pretrained=False)
self.backbone.fc = nn.Linear(512, 128) # 输出 128 维表征
def forward(self, x):
return self.backbone(x)
# 记忆库类
class MemoryBank:
def __init__(self, size, dim, device):
# size: 数据集样本数,dim: 表征维度
self.bank = torch.randn(size, dim).to(device) # 随机初始化
self.bank = F.normalize(self.bank, dim=1) # L2 归一化
def update(self, indices, features):
# 更新记忆库中对应位置的表征
with torch.no_grad():
self.bank[indices] = F.normalize(features, dim=1)
def sample(self, num_samples):
# 随机采样负样本
indices = torch.randperm(self.bank.size(0))[:num_samples]
return self.bank[indices]
# InfoNCE 损失函数
def info_nce_loss(q, k_pos, k_neg, temperature=0.2):
# q: [N, D], k_pos: [N, D], k_neg: [K, D]
pos_logits = (q * k_pos).sum(dim=1, keepdim=True) / temperature # [N, 1]
neg_logits = torch.matmul(q, k_neg.T) / temperature # [N, K]
logits = torch.cat([pos_logits, neg_logits], dim=1) # [N, 1 + K]
labels = torch.zeros(q.size(0), dtype=torch.long).to(q.device) # 正样本标签为 0
return F.cross_entropy(logits, labels)
# 训练循环
def train_memory_bank():
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
encoder = Encoder().to(device)
optimizer = torch.optim.SGD(encoder.parameters(), lr=0.03, momentum=0.9, weight_decay=1e-4)
# 假设数据集有 10000 张图片
memory_bank = MemoryBank(size=10000, dim=128, device=device)
data_loader = ... # 提供 (img, index) 对,img 是增强视图,index 是图片在数据集中的索引
for epoch in range(200):
for img, indices in data_loader:
img = img.to(device) # [N, C, H, W]
indices = indices.to(device) # [N]
# 生成查询表征
q = encoder(img) # [N, 128]
# 正键从记忆库中提取(或实时计算,此处用记忆库)
k_pos = memory_bank.bank[indices] # [N, 128]
# 从记忆库中采样负样本
K = 4096 # 负样本数量
k_neg = memory_bank.sample(K) # [K, 128]
# 计算损失
loss = info_nce_loss(q, k_pos, k_neg)
# 只更新查询编码器
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 更新记忆库
memory_bank.update(indices, q)
print(f"Epoch {epoch}, Loss: {loss.item()}")
if __name__ == "__main__":
train_memory_bank()
代码说明:
- 记忆库:
MemoryBank类维护一个 ( M × D M \times D M×D ) 的表征矩阵,初始随机生成。 - 正键:从记忆库中提取当前图片的表征(也可实时计算)。
- 负键:从记忆库中随机采样 ( K K K ) 个表征(例如 4096),远大于 mini-batch 大小。
- 更新:训练时只更新 ( f q f_q fq ),用 ( q q q ) 替换记忆库中对应位置的表征。
- 一致性问题:
k_neg和k_pos可能来自不同时期的编码器,导致相似度计算不一致。
局限与性能下降原因
记忆库方法支持更大的字典(例如 ( K = 65536 K = 65536 K=65536 )),但性能不如 MoCo(58.0% vs. 60.6%)。主要原因在于:
- 不一致性:记忆库中的表征跨越整个训练过程,由不同阶段的编码器生成。编码器参数的变化使键表征的分布不一致,影响对比损失的有效性。
- 更新滞后:记忆库的刷新速度慢(每个样本只在 mini-batch 中出现时更新一次),早期表征可能过时。
MoCo 通过动量更新键编码器和队列机制解决了这一问题,确保键表征的一致性,同时保持大规模字典的优势。
总结
记忆库方法通过存储所有样本的表征支持大规模字典,只用梯度下降更新查询编码器,而键表征通过被动替换更新。这种设计降低了计算成本,但因缺乏一致性导致性能下降。代码实现展示了其核心逻辑,研究者可通过改进采样策略或引入一致性约束进一步优化这一方法。
Momentum Contrast (MoCo) 的实现原理与代码
Momentum Contrast (MoCo) 是论文《Momentum Contrast for Unsupervised Visual Representation Learning》中提出的无监督视觉表征学习方法,旨在解决端到端方法和记忆库方法的局限性。它通过队列形式的动态字典和动量更新的键编码器构建了一个既大规模又一致的字典,显著提升了对比学习的性能。以下将详细解释 MoCo 的实现原理,并提供一个基于 PyTorch 的代码实现。
MoCo 的实现原理
MoCo 的核心思想是将对比学习视为字典查找任务,通过以下机制实现:
-
队列形式的字典:
- 维护一个固定大小的队列(例如 65536),存储之前 mini-batch 的键表征。
- 每次训练时,当前 mini-batch 的键表征入队,最旧的 mini-batch 出队。
- 字典大小与 mini-batch 大小解耦,可灵活调整为超参数,支持大规模负样本。
-
动量更新的键编码器:
- 使用两个编码器:查询编码器 ( f q f_q fq ) 和键编码器 ( f k f_k fk )。
- ( f q f_q fq ) 通过反向传播实时更新。
- (
f
k
f_k
fk ) 通过动量更新缓慢演化,其参数更新公式为:
θ k ← m θ k + ( 1 − m ) θ q \theta_k \leftarrow m \theta_k + (1 - m) \theta_q θk←mθk+(1−m)θq
其中 ( m m m ) 是动量系数(默认 0.999),确保 ( f k f_k fk ) 的变化平滑。
-
对比损失:
- 对于每个查询 ( q = f q ( x q ) q = f_q(x^q) q=fq(xq) )(来自图片的增强视图),正键 ( k + = f k ( x k ) k_+ = f_k(x^k) k+=fk(xk) ) 是同一图片的另一个增强视图的表征。
- 负键从队列中获取,包含之前 mini-batch 的表征。
- 使用 InfoNCE 损失:
L q = − log exp ( q ⋅ k + / τ ) exp ( q ⋅ k + / τ ) + ∑ i = 0 K exp ( q ⋅ k i / τ ) \mathcal{L}_q = -\log \frac{\exp(q \cdot k_+ / \tau)}{\exp(q \cdot k_+ / \tau) + \sum_{i=0}^{K} \exp(q \cdot k_i / \tau)} Lq=−logexp(q⋅k+/τ)+∑i=0Kexp(q⋅ki/τ)exp(q⋅k+/τ)
其中 ( K K K ) 是队列中的负样本数量。
-
一致性与规模的平衡:
- 队列支持大规模字典(例如 65536),覆盖更多负样本。
- 动量更新使队列中的键表征保持一致性,避免记忆库方法中表征分布不一致的问题。
优势:
- 相比端到端方法,MoCo 的字典大小不受 mini-batch 限制。
- 相比记忆库方法,MoCo 的键表征由缓慢更新的 ( f k f_k fk ) 生成,保持一致性。
MoCo 的训练流程
- 输入:采样 mini-batch(大小 ( N N N )),对每张图片生成两个增强视图 ( x q x^q xq ) 和 ( x k x^k xk )。
- 编码:
- ( q = f q ( x q ) q = f_q(x^q) q=fq(xq) ):查询表征,由 ( f q f_q fq ) 生成。
- ( k = f k ( x k ) k = f_k(x^k) k=fk(xk) ):键表征,由 ( f k f_k fk ) 生成。
- 损失计算:
- 正键:( k + k_+ k+ ) 是 ( k k k ) 中的对应表征。
- 负键:从队列中提取 ( K K K ) 个表征。
- 计算 InfoNCE 损失。
- 更新:
- 通过梯度下降更新 ( f q f_q fq )。
- 用动量更新 ( f k f_k fk )。
- 将当前 mini-batch 的 ( k k k ) 入队,移除最旧的表征。
- 迭代:重复以上步骤,直至收敛。
代码实现
以下是 MoCo 的简化实现(基于 PyTorch),以实例区分任务为例:
import torch
import torch.nn as nn
import torch.nn.functional as F
from collections import deque
# 定义编码器
class Encoder(nn.Module):
def __init__(self):
super().__init__()
self.backbone = torch.hub.load('pytorch/vision', 'resnet18', pretrained=False)
self.backbone.fc = nn.Linear(512, 128) # 输出 128 维表征
def forward(self, x):
return self.backbone(x)
# MoCo 类
class MoCo(nn.Module):
def __init__(self, dim=128, K=4096, m=0.999, T=0.2):
super().__init__()
self.K = K # 队列大小
self.m = m # 动量系数
self.T = T # 温度参数
# 查询编码器和键编码器
self.encoder_q = Encoder()
self.encoder_k = Encoder()
# 初始化键编码器参数与查询编码器一致
for param_q, param_k in zip(self.encoder_q.parameters(), self.encoder_k.parameters()):
param_k.data.copy_(param_q.data)
param_k.requires_grad = False # 键编码器不参与梯度更新
# 初始化队列
self.register_buffer("queue", torch.randn(K, dim))
self.queue = F.normalize(self.queue, dim=1)
self.queue_ptr = 0
@torch.no_grad()
def _momentum_update_key_encoder(self):
# 动量更新键编码器
for param_q, param_k in zip(self.encoder_q.parameters(), self.encoder_k.parameters()):
param_k.data = param_k.data * self.m + param_q.data * (1. - self.m)
@torch.no_grad()
def _dequeue_and_enqueue(self, keys):
# 更新队列
batch_size = keys.size(0)
ptr = int(self.queue_ptr)
assert self.K % batch_size == 0 # 简化实现,假设队列大小是 batch_size 的整数倍
# 将当前 mini-batch 的键入队
self.queue[ptr:ptr + batch_size] = keys
ptr = (ptr + batch_size) % self.K # 更新指针
self.queue_ptr = ptr
def forward(self, im_q, im_k):
# im_q: 查询图片 [N, C, H, W]
# im_k: 键图片 [N, C, H, W]
# 计算查询表征
q = self.encoder_q(im_q) # [N, 128]
q = F.normalize(q, dim=1)
# 计算键表征(无梯度)
with torch.no_grad():
self._momentum_update_key_encoder() # 更新键编码器
k = self.encoder_k(im_k) # [N, 128]
k = F.normalize(k, dim=1)
# 计算 InfoNCE 损失
pos_logits = torch.sum(q * k, dim=1, keepdim=True) / self.T # [N, 1]
neg_logits = torch.matmul(q, self.queue.T) / self.T # [N, K]
logits = torch.cat([pos_logits, neg_logits], dim=1) # [N, 1 + K]
labels = torch.zeros(q.size(0), dtype=torch.long).to(q.device)
loss = F.cross_entropy(logits, labels)
# 更新队列
self._dequeue_and_enqueue(k)
return loss
# 训练循环
def train_moco():
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = MoCo(dim=128, K=4096, m=0.999, T=0.2).to(device)
optimizer = torch.optim.SGD(model.encoder_q.parameters(), lr=0.03, momentum=0.9, weight_decay=1e-4)
# 数据加载器返回两个增强视图
data_loader = ... # 提供 (img_q, img_k) 对
for epoch in range(200):
for img_q, img_k in data_loader:
img_q, img_k = img_q.to(device), img_k.to(device)
# 计算损失
loss = model(img_q, img_k)
# 只更新查询编码器
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f"Epoch {epoch}, Loss: {loss.item()}")
if __name__ == "__main__":
train_moco()
代码说明
-
MoCo 类:
- 编码器:
encoder_q和encoder_k初始参数相同,但encoder_k的参数不参与梯度计算。 - 队列:使用
register_buffer定义一个 ( K × D K \times D K×D ) 的张量,作为动态字典。 - 动量更新:
_momentum_update_key_encoder方法实现 ( θ k ← m θ k + ( 1 − m ) θ q \theta_k \leftarrow m \theta_k + (1 - m) \theta_q θk←mθk+(1−m)θq )。 - 队列更新:
_dequeue_and_enqueue方法将当前 mini-batch 的键表征入队,并移除最旧的表征。
- 编码器:
-
前向传播:
- 计算 ( q q q ) 和 ( k k k ) 的表征,分别由 ( f q f_q fq ) 和 ( f k f_k fk ) 生成。
- 正样本相似度为 ( q ⋅ k + q \cdot k_+ q⋅k+ ),负样本相似度为 ( q q q ) 与队列中所有表征的点积。
- 返回 InfoNCE 损失。
-
训练:
- 只优化
encoder_q,encoder_k通过动量更新。 - 队列在每次迭代后更新,保持动态性。
- 只优化
与端到端和记忆库的对比
-
端到端方法:
- 字典大小:受限于 mini-batch 大小(例如 1024)。
- 更新:( f q f_q fq ) 和 ( f k f_k fk ) 同时通过梯度更新。
- 一致性:高,但规模受限。
-
记忆库方法:
- 字典大小:支持大规模(例如 65536),但表征来自不同时期的编码器。
- 更新:只更新 ( f q f_q fq ),记忆库被动刷新。
- 一致性:低,导致性能下降。
-
MoCo:
- 字典大小:通过队列支持大规模(例如 65536)。
- 更新:( f q f_q fq ) 通过梯度更新,( f k f_k fk ) 通过动量更新。
- 一致性:高,键表征由缓慢演化的 ( f k f_k fk ) 生成。
实现中的关键点
- 队列大小 ( K K K ):论文中设为 65536,可根据硬件调整。更大的 ( K K K ) 通常提升性能(见图 3)。
- 动量 ( m m m ):默认 0.999,实验表明较大值(如 0.99-0.9999)效果更好(Sec. 4.1),太小(如 0.9)会导致性能下降。
- 温度 ( T T T ):控制相似度分布的平滑性,默认 0.2。
总结
MoCo 通过队列和动量更新的巧妙设计,实现了大规模且一致的字典,克服了端到端方法的规模限制和记忆库方法的一致性问题。代码实现展示了其核心逻辑,研究者可通过调整 ( K K K )、( m m m ) 或引入更复杂的增强策略进一步优化。MoCo 的成功证明了动态字典和一致性在对比学习中的重要性,为无监督学习提供了一个强大框架。
后记
2025年3月31日15点38分于上海,在grok 3大模型辅助下完成。

















 7256
7256

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









