







近来研究深度学习,发现里面的trick很多,特地用blog记录下,以免以后忘掉
本文主要介绍常用的的激活函数, Sigmoid, tanh, Relu, Leaky relu
Sigmoid激活函数
sigmoid函数在历史上很受欢迎,因为他很符合神经元的特征,
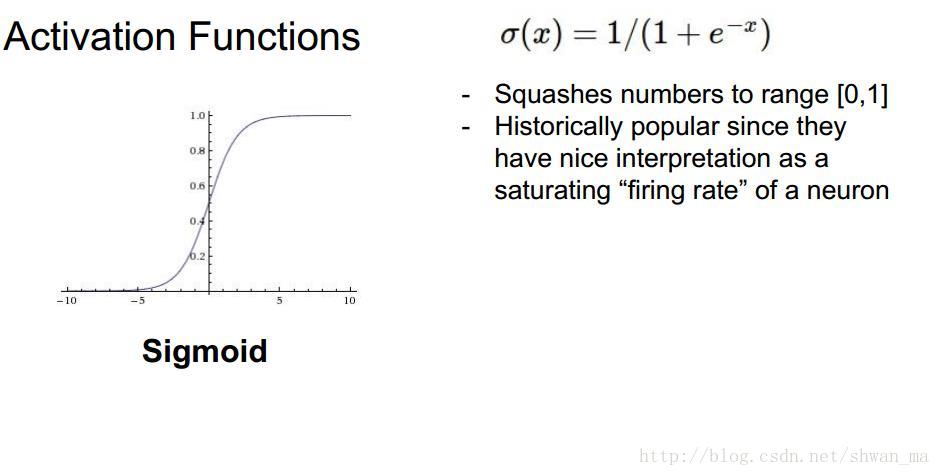
优点是: 能够把输出控制在[0,1]之间, 直观
缺点是:1)他的饱和区和未激活区的梯度均为0,容易造成梯度弥散,比如x = 10时和x = -10时,链式求导的时候,梯度会变得很小导致权重更新很慢
2)非0均值输出。这会引入一个问题,当输入均为正值的时候,由于f = sigmoid(wTx+b)),那么对w求局部梯度则都为正,这样在反向传播的过程中w要么都往正方向更新,要么都往负方向更新,导致有一种捆绑的效果,使得收敛缓慢。
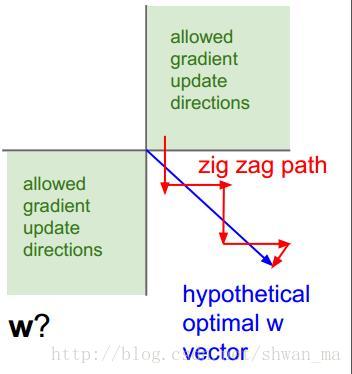
3)计算量比较大,都将把时间放在exp和矩阵点乘上了
tanh激活函数
tanh并没有解决sigmoid的梯度弥散问题,然而却解决了输出是0均值的问题,这使得tanh的收敛速度要比sigmoid要快的多。

Relu激活函数
Relu是目前用的最多的一种激活函数,
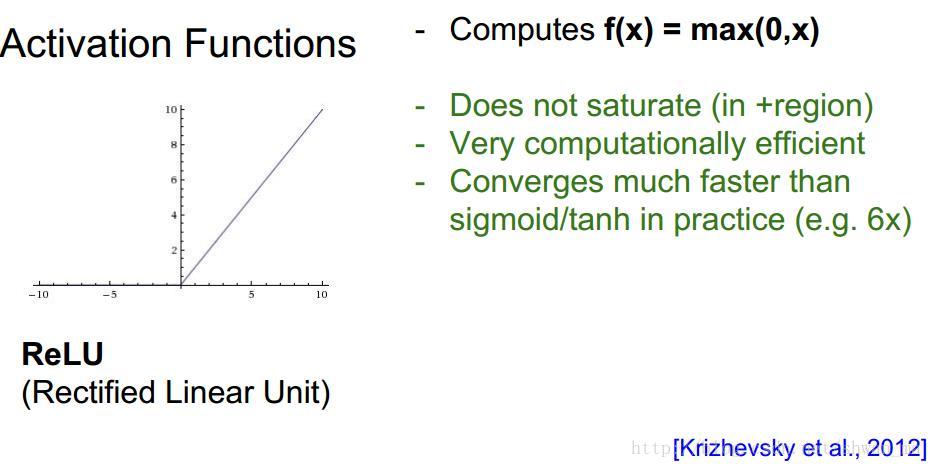
由于在正区域中很好的解决了梯度弥散的问题,而且其计算速度很快(只进行比较操作),在收敛速度上也比sigmoid和tanh要快
然而:其并没有解决负区域的梯度弥散问题,当初始权重设置的比较糟的时候,会导致dead relu,整个网络的权重不会进行更新
而且,relu输出也不是0均值的
(为了弄出一个0均值的relu,好像有个进化版的叫ELU)
Leaky Relu 激活函数
为了解决relu在负区域的梯度弥散问题,leaky relu 被提出

总结
**1.尽量不要用sgmoid,因为其收敛速度比较慢
2.可以去尝试tanh
3.尽量去使用relu,relu的收敛速度块,计算量少**















 3487
3487

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









