







🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋
文章目录
在上一章中,您了解了通过推荐准点率较高的航班来改善用户体验的示例业务目标。您已与业务主题专家( SME ) 合作以了解可用数据。在本章中,您将了解该平台如何帮助您从各种来源收集和处理数据。您将看到如何创建按需 Spark 集群,以及如何使用该平台在共享环境中隔离工作负载。新的航班数据可能会经常提供,您将看到该平台如何使您能够自动执行数据管道。
在本章中,您将了解以下主题:
- 为开发自动配置 Spark 集群
- 编写 Spark 数据管道
- 使用 Spark UI 监控您的作业
- 使用 Airflow 构建和执行数据管道
技术要求
本章包括一些动手设置和练习。您将需要一个使用Operator Lifecycle Manager ( OLM )配置的正在运行的 Kubernetes 集群。第 3 章“探索 Kubernetes”中介绍了构建这样的 Kubernetes 环境。在尝试本章中的技术练习之前,请确保您有一个正常工作的 Kubernetes 集群,并且在您的 Kubernetes 集群上安装了开放数据中心( ODH )。第 4 章“机器学习平台剖析”中介绍了 ODH 的安装。
为开发自动配置 Spark 集群
在本节中,您将了解该平台如何使您的团队能够按需配置 Apache Spark 集群。这种按需配置新 Apache Spark 集群的功能使您的组织能够在共享 Kubernetes 集群上运行多个团队使用的多个独立项目,而不会重叠。
该组件的核心是平台内可用的 Spark 运算符。Spark Kubernetes Operator 允许您以声明方式启动 Spark 集群。您可以在本书的 Git 存储库中的manifests/radanalyticsio文件夹下找到必要的配置文件。此运算符的详细信息超出了本书的范围,但我们将向您展示该机制的工作原理。
Spark 运算符定义了一个Kubernetes自定义资源定义( CRD ),它提供了您可以向 Spark 操作员发出的请求的架构。在此模式中,您可以定义许多内容,例如集群的工作节点数量以及分配给集群的主节点和工作节点的资源。
通过此文件,您可以定义以下选项。请注意,这不是一个详尽的列表。如需完整列表,请查看此开源项目的文档,网址为GitHub - radanalyticsio/spark-operator: Operator for managing the Spark clusters on Kubernetes and OpenShift.:
- customImage部分定义了提供 Spark 软件的容器的名称。
- master部分定义了 Spark master 实例的数量和分配给 master Pod 的资源。
- worker部分定义了 Spark worker 实例的数量和分配给 worker Pod 的资源。
- sparkConfiguration部分使您能够添加任何特定的 Spark 配置,例如广播加入阈值。
- env部分使您能够添加 Spark 支持的变量,例如SPARK_WORKER_CORES。
- sparkWebUI部分启用标志并指示操作员为 Spark UI 创建 Kubernetes Ingress。在以下部分中,您将使用此 UI 来调查您的 Spark 代码。
您可以在manifests/radanalyticsio/spark/cluster/base/simple-cluster.yaml找到一个这样的文件,如下图所示。图 9.1显示了simple-cluster.yaml文件的一部分:
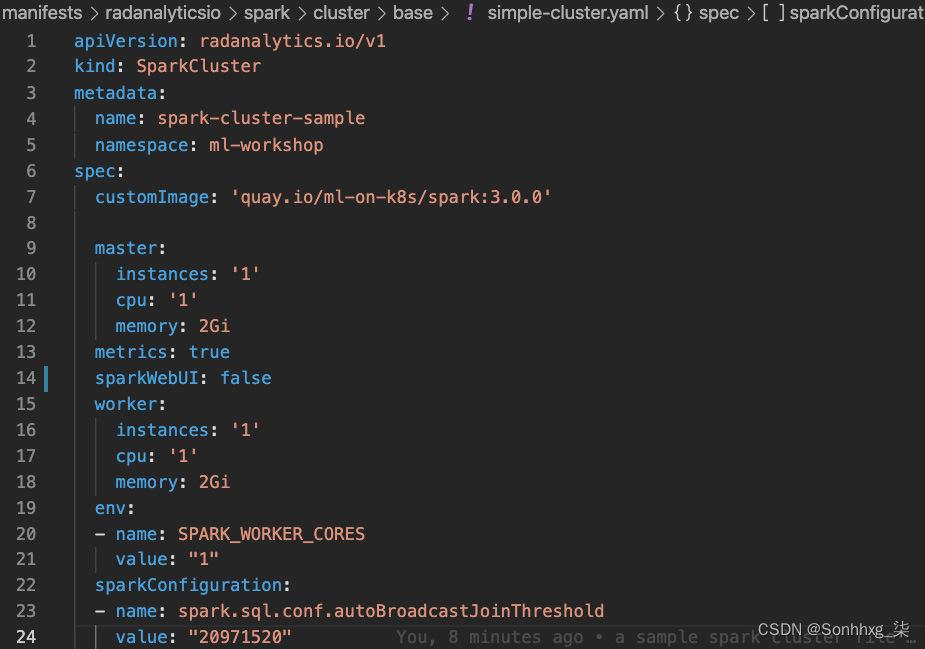
图 9.1 – Spark 算子使用的简单 Spark 自定义资源
现在你知道了在平台上配置 Spark 集群的基本过程。但是,您将在下一节中看到,当您选择Elyra Notebook Image with Spark notebook 镜像时,会为您预置 Spark 集群。这是因为,在平台中,JupyterHub 被配置为提交一个 Spark选择特定笔记本时的集群自定义资源( CR )。此配置可通过两个文件获得。
第一个是manifests/jupyterhub/jupyterhub/overlays/spark3/jupyterhub-singleusers-profiles-configmap.yaml,它将配置文件定义为Spark Notebook。在本节中,平台在images键下配置容器图像的名称,因此每当 JupyterHub 生成此图像的新实例时,它将应用这些设置。带有 Spark 笔记本的Elyra Notebook Image指向一个图像,它与这部分配置中定义的图像相同。此文件包含配置下的配置参数,资源部分指向将与此图像的实例一起创建的资源。图 9.2显示一个jupyterhub -singleusers-profiles-configmap.yaml文件的部分:
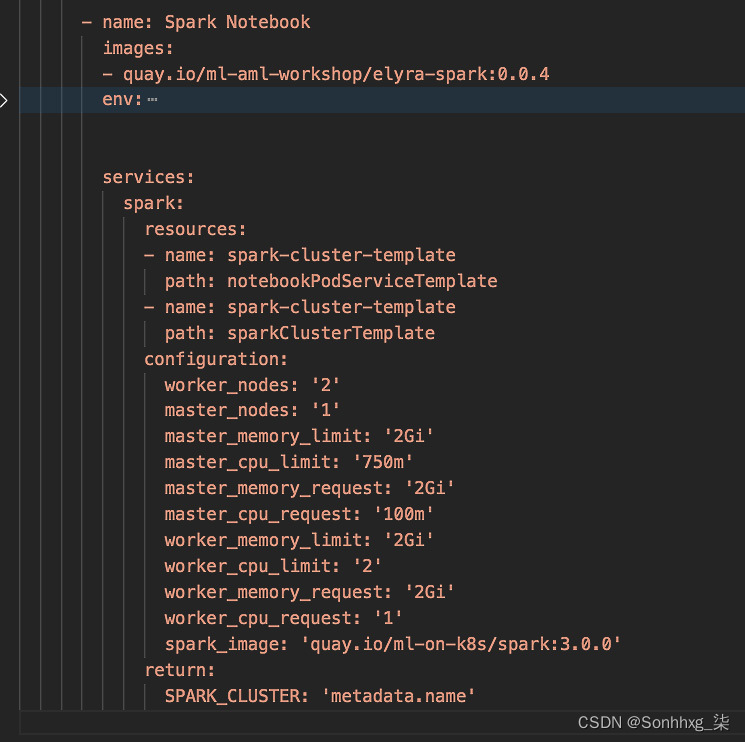
图 9.2 – jupyterhub-singleusers-profiles-configmap.yaml 的一部分
请注意,资源有一个值为sparkClusterTemplate的属性,这会将我们带到我们的第二个文件。
第二个文件manifests/jupyterhub/jupyterhub/base/jupyterhub-spark-operator-configmap.yaml包含sparkClusterTemplate, 它定义了 Spark CR。请注意,此处将使用jupyterhub-singleusers-profiles-configmap.yaml文件中可用的参数。图 9.3显示了jupyterhub-spark-operator-configmap.yaml文件的一部分:
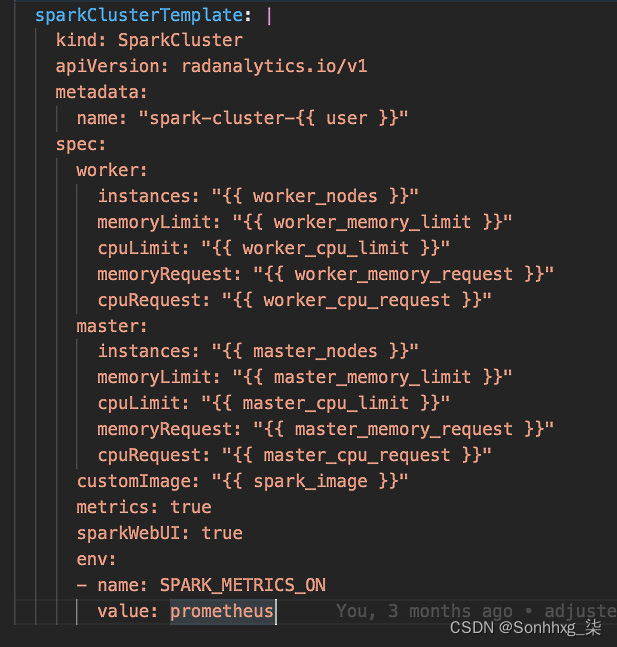
图 9.3 – jupyterhub-spark-operator-configmap.yaml 的一部分
在本节中,您已经了解了平台如何连接不同的组件以使您的生活更轻松团队和组织,您可以根据需要更改和配置这些组件中的每一个,从而发挥开源软件的真正力量。
让我们编写一个数据管道来处理我们的航班数据。
编写 Spark 数据管道
在本节中,您将建立一个真实的数据管道来收集和处理数据集。处理的目标是将数据格式化、清理和转换为可用于模型训练的状态。在编写我们的数据管道之前,我们先来了解一下数据。
准备环境
为了执行在下面的练习中,我们首先需要设置一些东西。您需要设置一个 PostgreSQL 数据库来保存历史航班数据。您需要将文件上传到 MinIO 中的 S3 存储桶。我们同时使用了关系数据库和 S3 存储桶来更好地演示如何从不同的数据源收集数据。
我们准备了一个 Postgres 数据库容器镜像,您可以在 Kubernetes 集群上运行它。容器镜像可在Quay获得。它运行一个 PostgreSQL 数据库,该数据库在名为 flight 的表中预加载了航班数据。
通过以下步骤运行此容器,验证数据库表,并将 CSV 文件上传到 MinIO:
1.通过在运行 minikube 的同一台机器上运行以下命令来运行 Postgres 数据库容器:
kubectl create -f chapter9/deployment-pg-flights-data.yaml -n ml-workshop您应该会看到一条消息,告诉您部署对象已创建。
2.通过运行以下命令,通过服务公开此部署的 Pod:
kubectl create -f chapter9/service-pg-flights-data.yaml -n ml-workshop您应该会看到一条消息,说明服务对象已创建。
3.探索数据库的内容。您可以通过进入 Pod、运行 Postgres 客户端命令行界面( CLI )、psql并运行 SQL 脚本来完成此操作。执行以下命令连接 Postgres Pod 并运行 Postgres 客户端界面:
POD_NAME=$(kubectl get pods -n ml-workshop –l app=pg-flights-data)4.连接到 Pod。您可以通过执行以下命令来执行此操作:
kubectl exec -it $POD_NAME -n ml-workshop -- bash5.运行 Postgres 客户端 CLI、psql并验证表。运行以下命令,从命令行登录 Postgres 数据库:
psql -U postgres6.验证这些表是否存在。应该有一个名为flight的表。从psql shell运行以下命令来验证表的正确性:
select count(1) from flights;这应该会为您提供航班表中的记录数,超过 580 万条,如图 9.4所示:
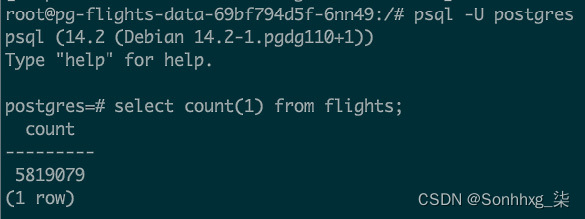
图 9.4 – 航班表中的记录计数
7.将其余数据上传到 MinIO 中的 S3 存储桶。在运行 minikube 的同一台机器上打开浏览器窗口,然后导航到 . 使用用户名minio和密码minio123。请记住将<minikube_ip>替换为您的 minikube 实例的 IP 地址。
8.导航到Buckets,然后点击Create Bucket +按钮。将存储桶命名为airport-data和点击Create Bucket按钮,如图 9.5所示:
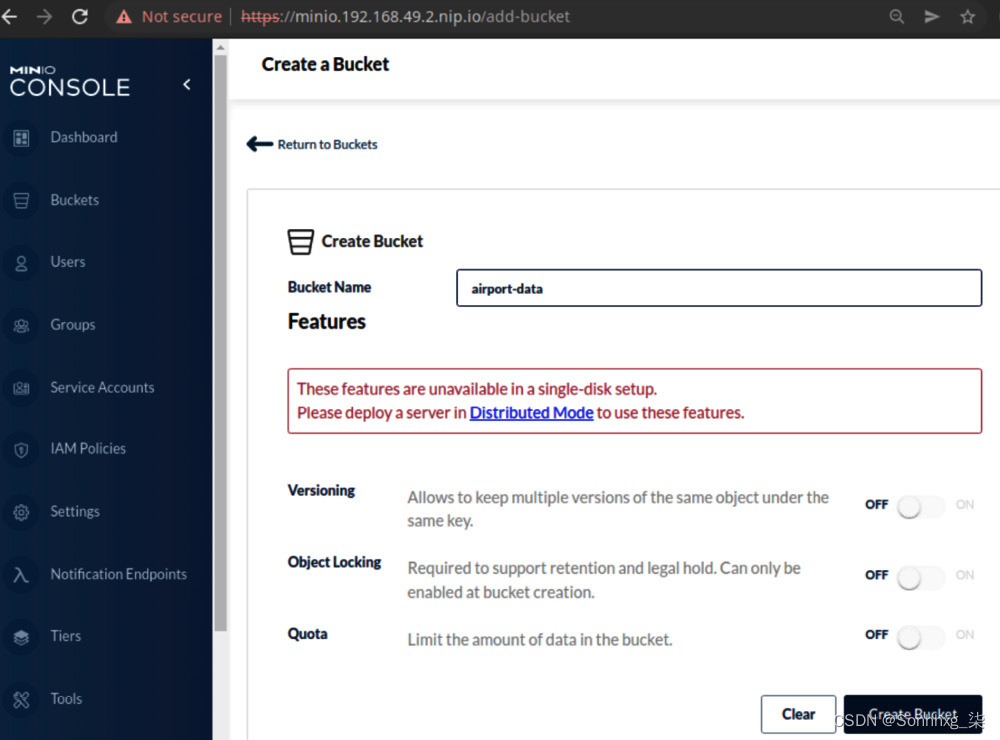
图 9.5 – MinIO 创建存储桶对话框
9.在存储桶内,将来自chapter9/data/文件夹中的两个 CSV 文件上传到airport-data存储桶,如图 9.6所示:
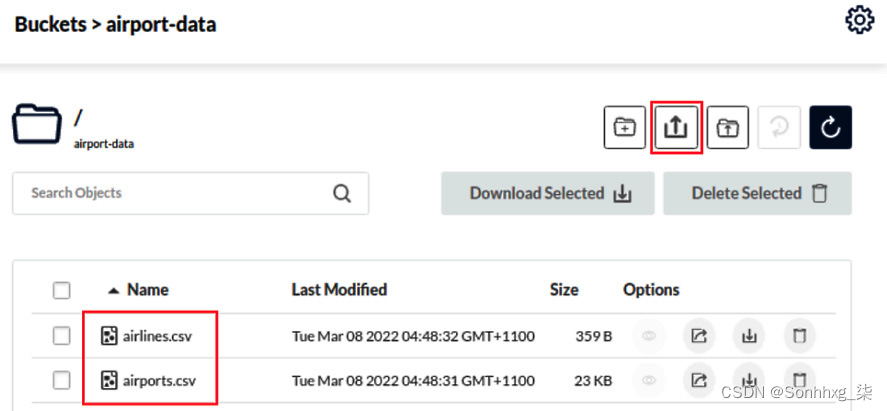
图 9.6 – 机场和航空公司数据文件
在现实世界中,您不需要采取上述步骤。数据源应该已经存在,您需要知道从哪里获取它们。但是,出于以下练习的目的,我们必须将这些数据加载到我们的环境中以使其可用于后续步骤。
您现在已将数据加载到平台。让我们更多地探索和理解数据。
理解数据
了解数据包括以下活动。重要的是要了解所涉及的所有数据集的特征,以便为管道制定策略和设计:
- 知道从哪里收集数据。数据可能来自多种来源。它可能来自关系数据库、对象存储、NoSQL 数据库、图形数据库、数据流、S3 存储桶、HDFS、文件系统或 FTP。有了这些信息,您将能够为数据管道准备所需的连接。在您的情况下,您需要从 PostgreSQL 数据库和 S3 存储桶中收集它。
- 了解数据的格式。数据可以有多种形式和形式。无论是 CSV 文件、SQL 表、Kafka 流、MQ 流、Parquet 文件、Avro 文件,甚至是 Excel 文件,您都需要拥有能够读取此类格式的正确工具。了解格式有助于您准备用于读取这些数据集的工具或库。
- 清理不重要或不相关的数据。了解哪些数据是重要的,哪些是不相关的,可以帮助您以更有效的方式设计您的管道。例如,如果您有一个包含航空公司名和航空公司 ID字段的数据集,您可能希望在最终输出中删除航空公司名称,并仅使用航空公司 ID。这意味着少一个字段被编码为数字,这将提高模型训练的性能。
- 了解不同数据集之间的关系。识别标识符字段或主键,并了解连接键和聚合级别。您需要知道这一点,以便您可以扁平化数据结构并使数据科学家更容易使用您的数据集。
- 知道在哪里存储处理后的数据。您需要知道将处理后的数据写入何处,以便准备连接要求并了解接口。
鉴于之前的活动,您需要一种访问和探索数据的方法来源。下一节将向您展示如何从 Jupyter 笔记本中读取数据库表。
从数据库中读取数据
使用 Jupyter笔记本,看看这数据。使用以下步骤开始数据探索,从从 PostgreSQL 数据库读取数据开始。
整个数据探索笔记本可以在本书的 Git 存储库中找到,地址为chapter9/explore_data.ipynb。我们建议您使用此笔记本进行额外的数据探索。可以通过简单地显示字段、计算列中相同值的出现次数以及查找数据源之间的关系来实现:
1.通过导航到https://jupyterhub.<minikube_ip>.nip.io来启动 Jupyter notebook 。如果系统提示您输入登录凭据,则需要使用您创建的 Keycloak 用户登录。用户名是mluser,密码是mluser。使用 Spark notebook启动Elyra Notebook Image,如图 9.7所示。因为我们将读取一个包含 580 万条记录的大型数据集,所以让我们使用大型容器大小。确保在您的环境中,您有足够的运行容量一个大容器。如果您没有足够的容量,请尝试在中等的容器。
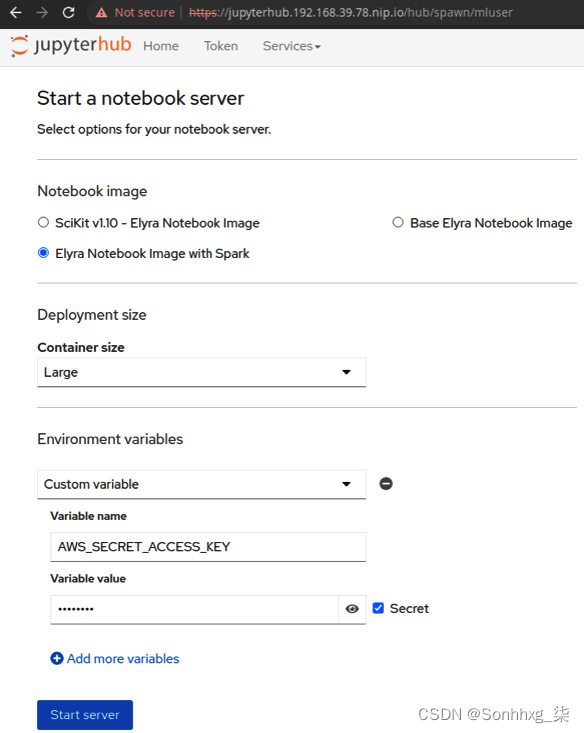
图 9.7 – JupyterHub 启动页面
2.创建一个 Python 3 笔记本。您将使用此笔记本来探索数据。您可以通过选择文件|来执行此操作。新| 笔记本菜单选项。然后,选择Python 3作为内核,如图 9.8所示:
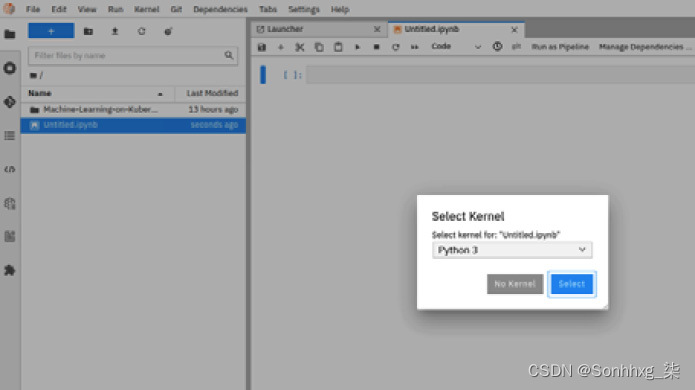
图 9.8 – Elyra 笔记本的内核选择对话框
3.您可以从查看数据库中的航班表开始。最基本的方法访问数据库是通过 PostgreSQL Python 客户端库。使用psycopg2进行练习。您还可以选择不同的客户端库来连接到 PostgreSQL 数据库。图 9.9中的代码片段是最基本的示例:
图 9.9 – 使用 psycopg2 到 PostgreSQL 的基本连接
4.另一个,更多优雅,方式访问数据的方法是通过pandas或PySpark。两个都pandas 和 PySpark 允许您使用权数据,通过数据框利用函数式编程方法,而不是步骤 3中的程序方法。pandas 和 Spark 之间的区别在于 Spark 查询可以以分布式方式执行,使用多台机器或 Pod 执行您的查询。这是大型数据集的理想选择。然而,pandas 提供了比 Spark 更具美感的可视化,这使得 pandas 更适合探索较小的数据集。图 9.10展示了如何通过 pandas 访问数据库的片段:
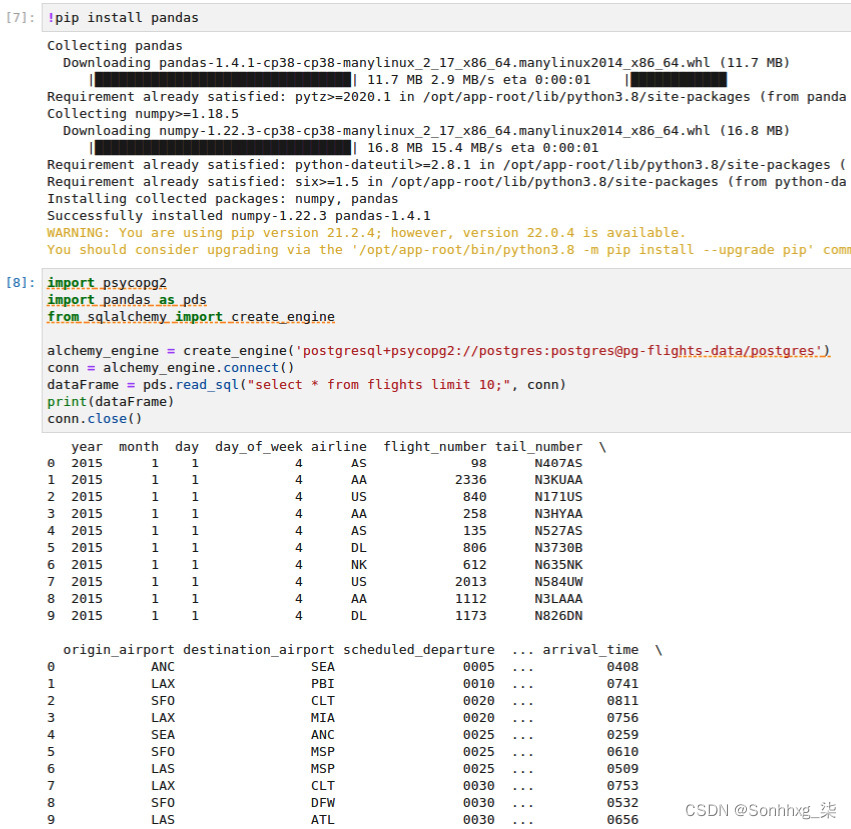
图 9.10 – 使用 pandas 到 PostgreSQL 的基本连接
5.如果您需要转换庞大的数据集,PySpark 将是理想的选择。例如,假设您需要转换和聚合一个包含 1 亿条记录的表。您需要将这项工作分发到多台机器上得到更快的结果。这就是 Spark 发挥重要作用的地方。代码片段图9.11展示了如何通过 PySpark 读取 PostgreSQL 表:
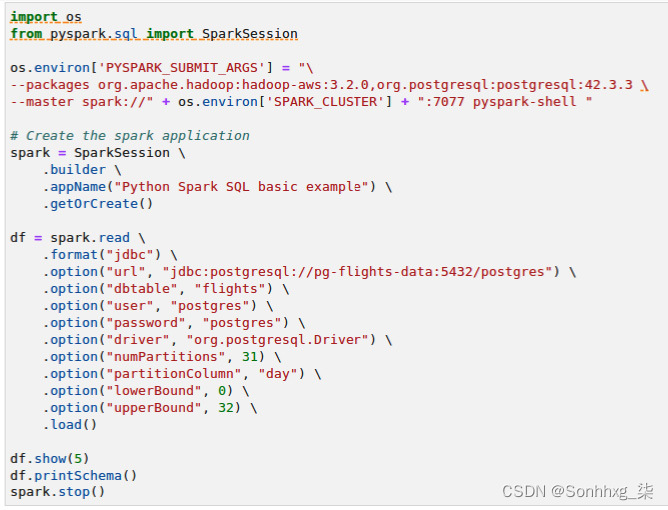
图 9.11 – 通过 PySpark 读取 PostgreSQL 表
由于 Spark 的分布式架构,当从任何关系数据库读取表时,您需要提供分区信息,特别是分区数和分区列。每个分区都会成为 Spark 的白话中的一个任务,每个任务都可以由单个 CPU 核心独立执行。如果未提供分区信息,Spark 将尝试将整个表视为单个分区。您不想这样做,因为该表有 580 万条记录,它可能不适合单个 Spark 工作节点的内存。
您还需要提供有关 Spark 集群的一些信息,例如主 URL 和运行 Spark 应用程序所需的包。在图 9.12的示例中,我们包含了org.postgresql:postgresql:42.3.3包。这是 Spark 连接数据库所需的 PostgreSQL JDBC 驱动程序。Spark 会自动下载这个包从应用程序启动时的 Maven。
从 S3 存储桶读取数据
现在你学到了不一样的方法在从 Jupyter 笔记本访问 PostgreSQL 数据库之后,让我们探索其余的数据。虽然数据库中的航班表包含航班信息,但我们也将机场和航空公司信息作为 CSV 文件提供并托管在 MinIO 的 S3 存储桶中。
Spark 可以通过hadoop-aws库与任何 S3 服务器进行通信。图 9.12显示了如何使用 Spark 从笔记本访问 S3 存储桶中的 CSV 文件:

图 9.12 – 从笔记本读取 S3 存储桶的 Spark 代码
请注意,我们添加了更多 Spark 提交参数。这是为了告诉 Spark 引擎 S3 服务器在哪里以及使用什么驱动程序库。
在探索了数据集之后,您应该已经了解了有关数据的以下事实:
- 航班表包含 5,819,079 条记录。
- airports.csv文件中有 322 个机场。
- Airlines.csv 文件中有 22 家航空公司。
- 机场和航空公司之间没有直接关系。
- 航班表使用机场CSV 文件中的IATA_CODE机场作为特定航班的始发地和目的地机场。
- 航班表使用航空公司CSV 文件中的IATA_CODE航空公司来判断哪个航空公司正在为特定航班提供服务。
- 所有的机场都在美国。这意味着国家列是无用的用于机器学习( ML ) 训练。
- 航班表有SCHEDULED_DEPARTURE、DEPARTURE_TIME和DEPARTURE_DELAY字段,它们表明航班是否延误,我们可以使用它们为我们的 ML 训练生成标签列。
鉴于这些事实,我们可以说我们可以使用机场和航空公司数据来添加额外的机场和航空公司信息这原始航班数据。这个过程是通常称为丰富,可以通过数据框连接来完成。我们还可以使用行计数信息来优化我们的 Spark 代码。
现在您了解了数据,您可以开始设计和构建您的管道。
设计和建造管道
理解这数据是一回事,设计管道是另一回事。从您在上一节中探索的数据中,您了解到了一些事实。我们将使用这些事实来决定如何构建我们的数据管道。
目标是生成一个单一的、平面的数据集,其中包含可能对 ML 训练有用的所有重要信息。我们之所以说所有重要信息,是因为在我们进行实际的 ML 训练之前,我们不确定哪些字段或特征是重要的。作为一名数据工程师,您可以根据对数据的理解并在 SME 的帮助下做出有根据的猜测,哪些领域重要,哪些领域不重要。在 ML 生命周期中,数据科学家可能会回复您要求更多字段、删除一些字段或对数据执行一些转换。
考虑到生成单个数据集的目标,我们需要使用机场和航空公司数据来丰富航班数据。为了用机场和航空公司数据丰富原始航班数据,我们需要做一个数据框连接操作。我们还需要注意,航班数据有数百万条记录,而机场和航空公司数据少于 50。我们可以使用这些信息来影响 Spark 的连接算法进行优化。
为数据框连接准备笔记本
首先,创建一个新的笔记本执行连接,然后将此笔记本作为阶段添加到管道中。以下步骤将向您展示如何执行此操作:
1.创建一个新笔记本。称它为merge_data.ipynb 。
2.使用 Spark 从 Postgres 和 S3 存储桶收集数据。使用您在上一节中学到的知识。图 9.13显示了 notebook 的数据读取部分。我们还提供了一个实用 Python 文件chapter9/spark_util.py。这包含了 Spark 上下文的创建,以使您的 notebook 更具可读性。图 9.13中的代码片段向您展示了如何使用该实用程序:
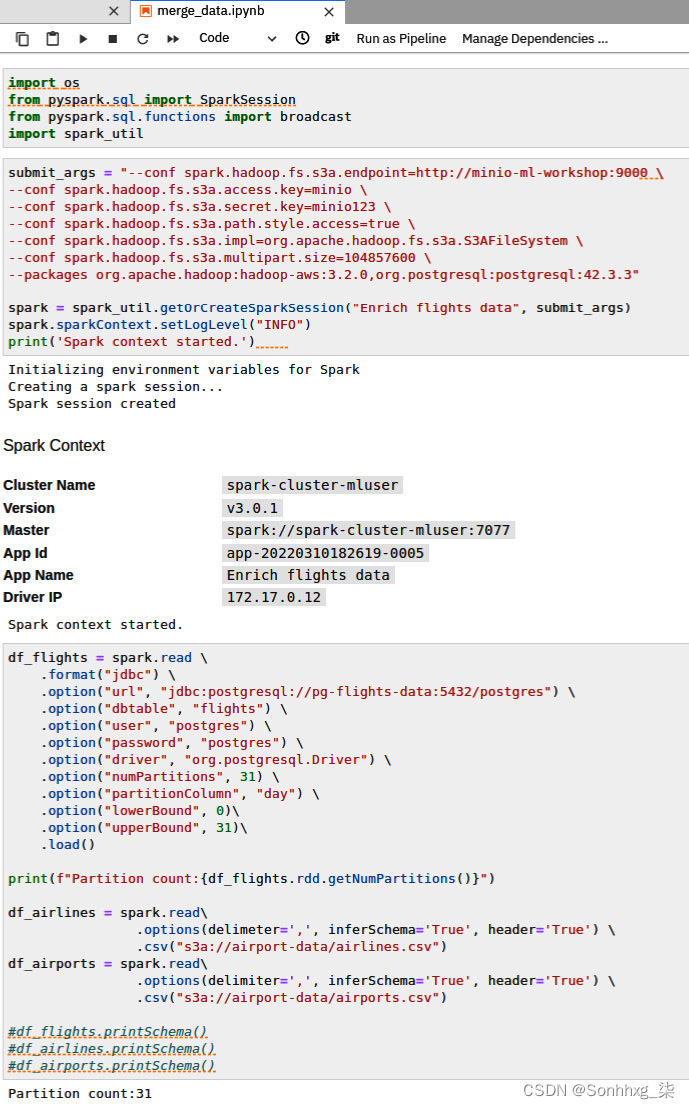
图 9.13 – 用于准备数据帧的 Spark 代码
注意新的 进口 此处为broadcast()声明。您将在下一步中使用此函数进行优化。
3.在 Spark 中执行数据框连接,如图 9.14所示。您需要连接在步骤 2中准备的所有三个数据框。根据我们上一节的理解,机场和航空公司数据都应该以IATA_CODE作为主键进行合并。但首先,让我们加入航空公司数据。注意连接后的结果模式;底部还有两列什么时候比较的到原始架构。这些新列来自Airlines.csv文件:
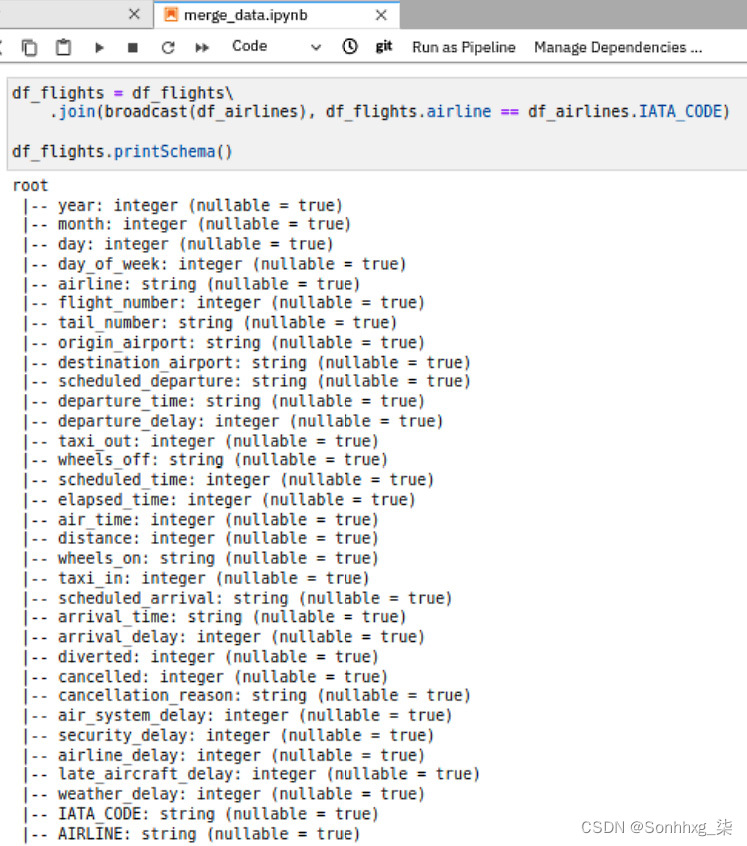
图 9.14 – 基本数据框连接的 Spark 代码
4.加入机场数据有点棘手,因为您必须加入两次:一次到origin_airport,另一次到destination_airport。如果我们只遵循与步骤 3相同的方法,则连接将起作用,并且列将被添加到模式中。问题是很难区分哪些机场字段代表目的地机场,哪些字段代表始发机场。图 9.15显示了字段名称是如何重复的:
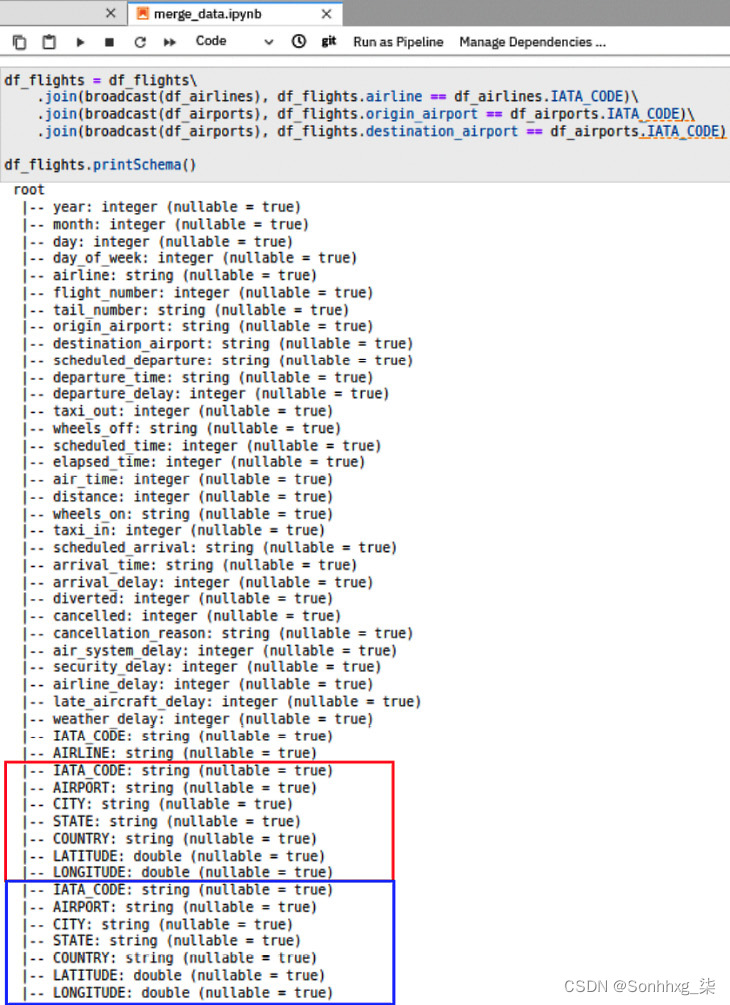
图 9.15 – 连接后的重复列
5.这最简单的解决方法这是为了创建带有前缀字段名称的新数据框(ORIG_用于始发机场,DEST_用于目的地机场)。您也可以对航空公司字段执行相同的操作。图 9.16显示了如何做到这一点:
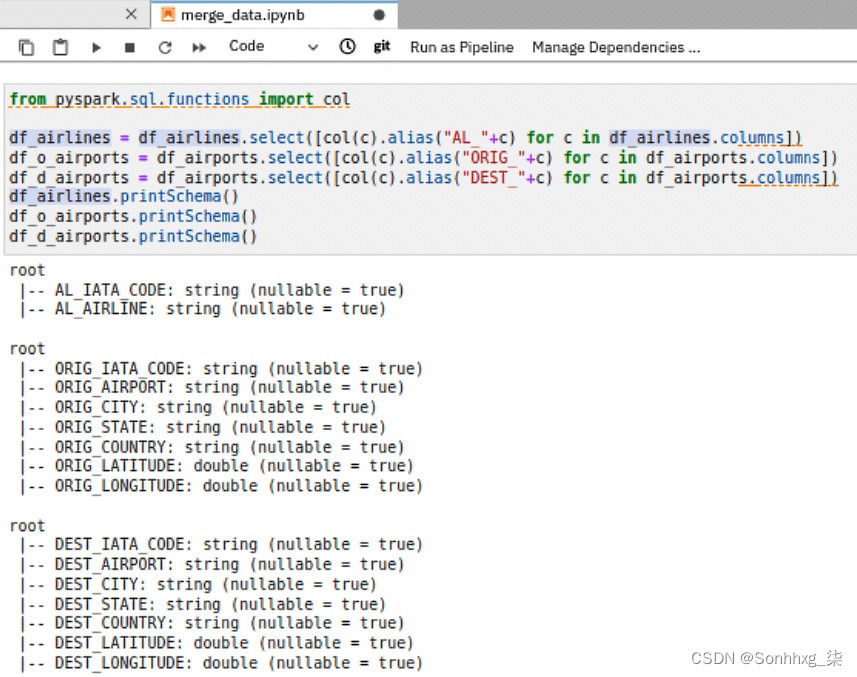
图 9.16 – 为字段名称添加前缀
6.代替df_airports数据_带有df_o_airports和df_d_airports的框架你的join语句,如图 9.17所示。现在,您有了一个更具可读性的数据框:
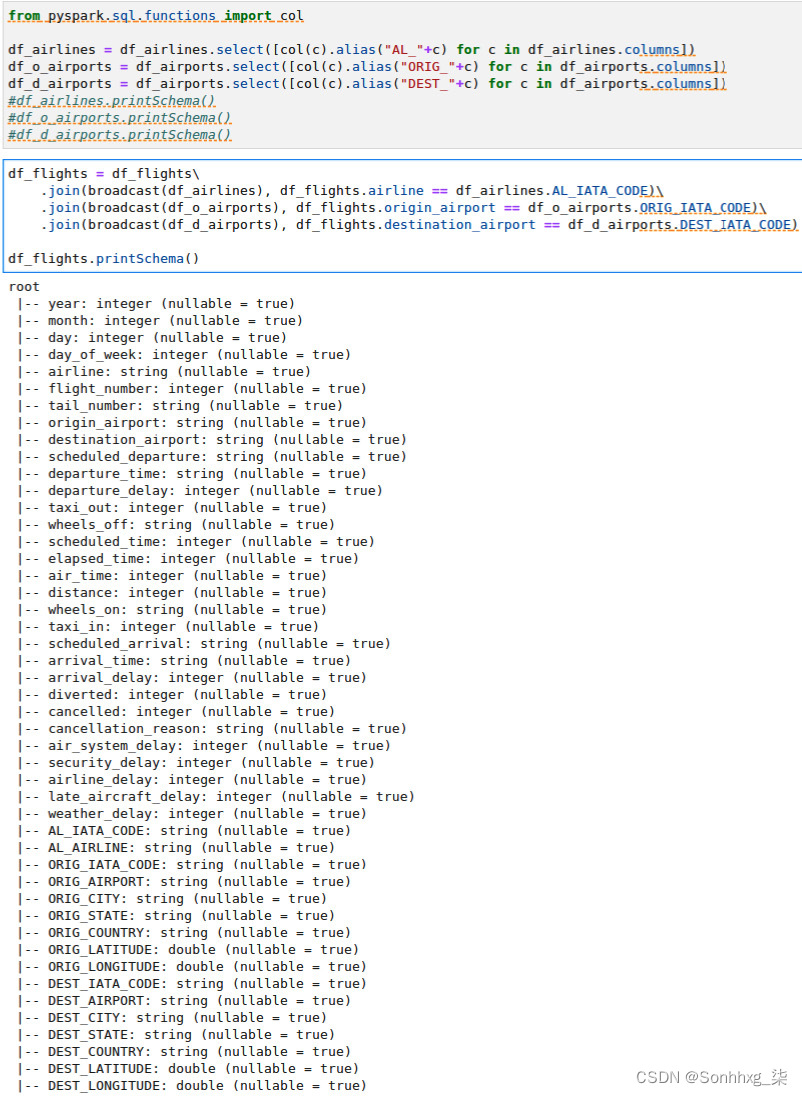
图 9.17 – 更新了带有前缀数据框的连接语句
一件事笔记在join语句是broadcast ()函数。在上一节中,我们讨论了了解数据集大小以便优化代码的重要性。broadcast()函数向Spark 引擎提示应该广播给定的数据帧,并且连接操作必须使用广播连接算法。这意味着在执行之前,Spark 会将df_airlines、df_o_airports和df_d_airports数据帧的副本分发给每个 Spark 执行程序,以便它们可以连接到每个分区的记录中。为了使广播加入有效,您需要选择较小的数据帧进行广播。如果您想了解更多相关信息,请参阅以下 URL 中的 Spark 性能调优文档:https ://spark.apache.org/docs/latest/sql-performance-tuning.html 。
您刚刚学习了如何使用 PySpark 连接数据框。因为 PySpark 语句是惰性求值的,连接操作的实际执行并没有发生然而。那是为什么printSchema ()执行速度很快。Spark 仅在需要实际数据时才执行处理。一种这样的情况是当您将实际数据保存到存储中时。
持久化数据框
得到结果的连接,你需要打开数据帧转化为物理数据。您将数据帧写入 S3 存储,以便数据管道的下一阶段可以读取它。图 9.18显示了将连接的航班数据帧写入 MinIO 中的 CSV 文件的代码片段:

图 9.18 – 将数据帧写入 S3 存储桶
执行这将需要一些时间,因为这是实际处理 580 万条记录的地方。在此运行过程中,您可以查看 Spark 集群中发生的情况。当您启动 notebook 时,它会在 Kubernetes 中创建一个 Spark 集群,将用户mluser专用于您。Spark GUI 在 https://spark-cluster-mluser.<minikube_ip>.nip.io 中公开。导航到此 URL 以监控 Spark 应用程序并检查应用程序作业的状态。您应该会看到一个名为Enrich flight data的正在运行的应用程序。单击此应用程序名称将带您进入正在处理的作业的更详细视图,如图 9.19所示:
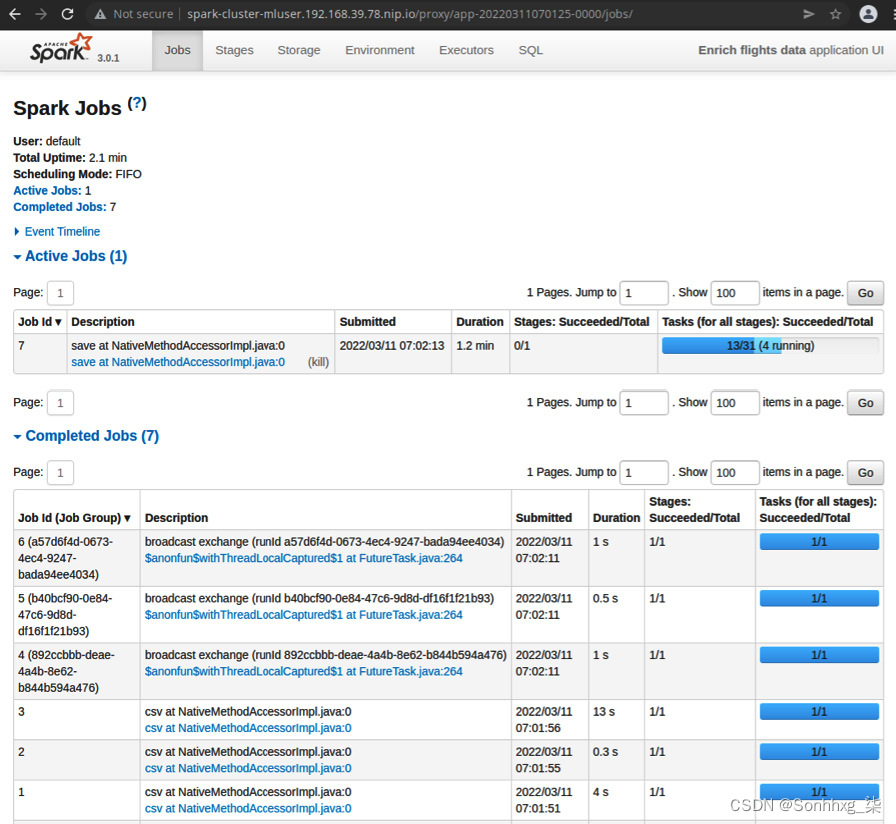
图 9.19 – Spark 应用程序 UI
图 9.19显示丰富航班数据应用程序的详细信息。每个应用程序由作业组成,作业是操作。在屏幕底部,您可以看到已完成的作业部分,其中包括广播操作。您还可以看出广播操作大约需要 1 秒。在Active Jobs部分下,您会看到当前正在运行的操作,在我们的例子中,这是实际的处理过程,包括从数据库中读取航班数据、重命名列、连接数据帧以及将输出写入S3 存储桶。这是针对数据帧的每个分区执行的,其中转换为Spark 中的任务。在Active Jobs部分的最右侧列中,您可以看到任务及其进度。因为我们按天对航班数据帧进行了分区,所以有 31 个分区。火花也创建了 31 个并行处理任务。这些任务中的每一个都计划在Spark executors上运行。在图 9.19中,详细说明在最后 1.2 分钟的处理过程中,31 个任务中有 13 个成功完成,当前有 4 个正在运行。
您可能还会发现在某些情况下失败的任务。Spark 会自动将失败的任务重新调度到另一个执行器。默认情况下,如果同一任务连续失败四次,整个应用程序将被终止并标记为失败。发生任务失败的原因有多种。其中一些包括网络中断或资源拥塞,例如内存不足异常或超时。这就是为什么重要的是要了解数据,以便您可以微调分区逻辑。这是需要注意的基本规则:分区数越大,分区大小越小。较小的分区大小将减少内存不足异常的机会,但它也会增加更多的 CPU 开销来调度。Spark 机制比这复杂得多,但它是理解分区、任务、作业和执行程序之间关系的良好开端。
几乎一半的数据工程工作实际上都花在了优化数据管道上。有很多技术可以优化 Spark 应用程序,包括代码优化、分区和执行程序大小调整。我们不会在本书中详细讨论这个话题。但是,如果您想了解更多有关此主题的信息,可以随时参考 Spark 的性能调优文档。
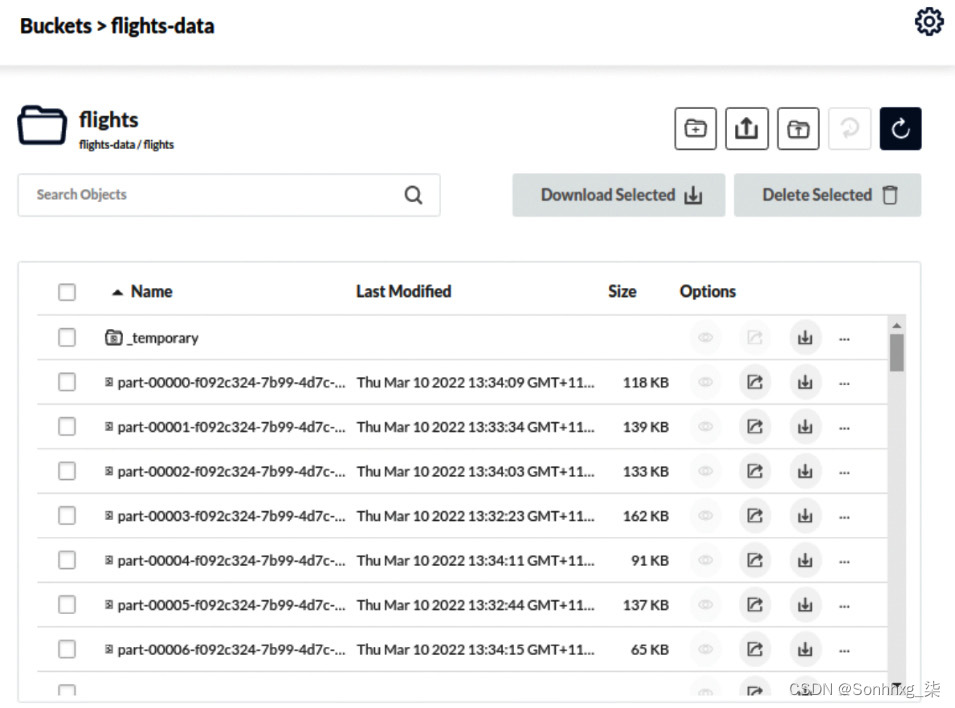
图 9.20 – 带有 Parquet 文件的 S3 存储桶
Spark应用完成后,需要将数据写入S3的多个文件中,一个文件代表一个Parquet格式的分区,如图9.20所示。镶木地板文件format 是一种列式数据格式,这意味着数据是按列组织的,而不是像典型的 CSV 文件那样按行组织。Parquet 的主要优点是您可以挑选要读取的列,而无需扫描整个数据集。这使得 Parquet 成为分析、报告和数据清理的理想选择,什么你需要做下一步。
您可以在本书的 Git 存储库中的chapter9文件夹下找到完整的merge_data.ipynb笔记本。但是,我们强烈建议您从头开始创建自己的笔记本,以最大限度地提高学习体验。
清理数据集
你现在有一个航班数据集的平面和丰富版本。这下一步是清理数据、删除不需要的字段、删除不需要的行、同质化字段值、派生新字段,并可能转换一些字段。
首先,创建一个新笔记本并使用此笔记本读取我们生成的 Parquet 文件,并将其写入数据集的清理版本。以下步骤将引导您完成该过程:
1.创建一个名为clean_data.ipynb的新笔记本。
2.从 flight -data/flights S3 存储桶加载航班数据 Parquet 文件,如图 9.21所示。验证架构和行数。行数应略小于原始数据集。这是因为前面的步骤中执行的join操作是inner join,在里面有记录原始航班数据不有机场或航空公司的参考资料。
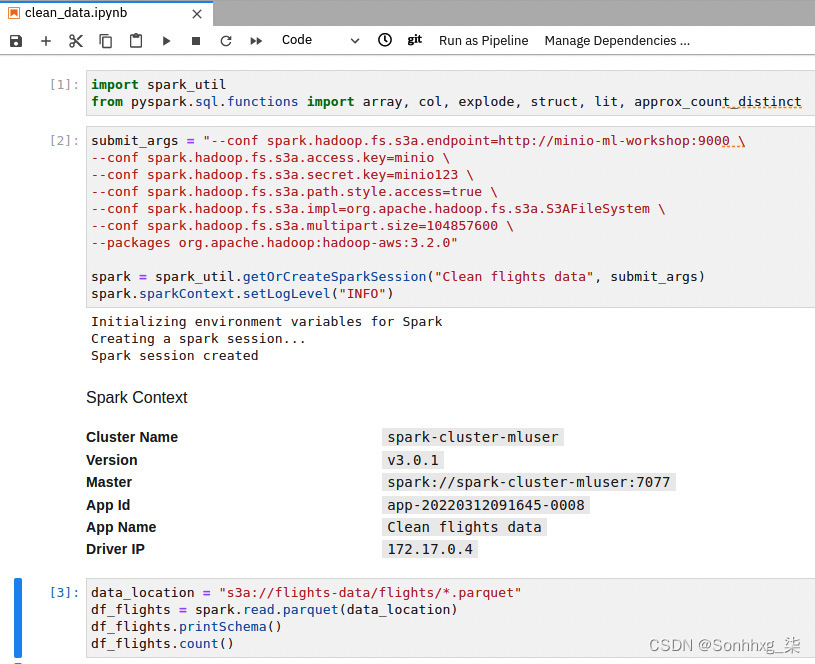
图 9.21 – 从 S3 读取 Parquet 数据
3.删除不需要或重复的字段,删除在整个数据集中具有相同值的字段,并创建一个名为DELAYED的派生布尔字段,其值为1表示延误航班,0表示非延误航班。假设我们仅将航班延误 15 分钟或更长时间视为延误。您可以随时根据需要更改此设置。让我们慢慢来。放下首先是不需要的列,如如图9.22所示:
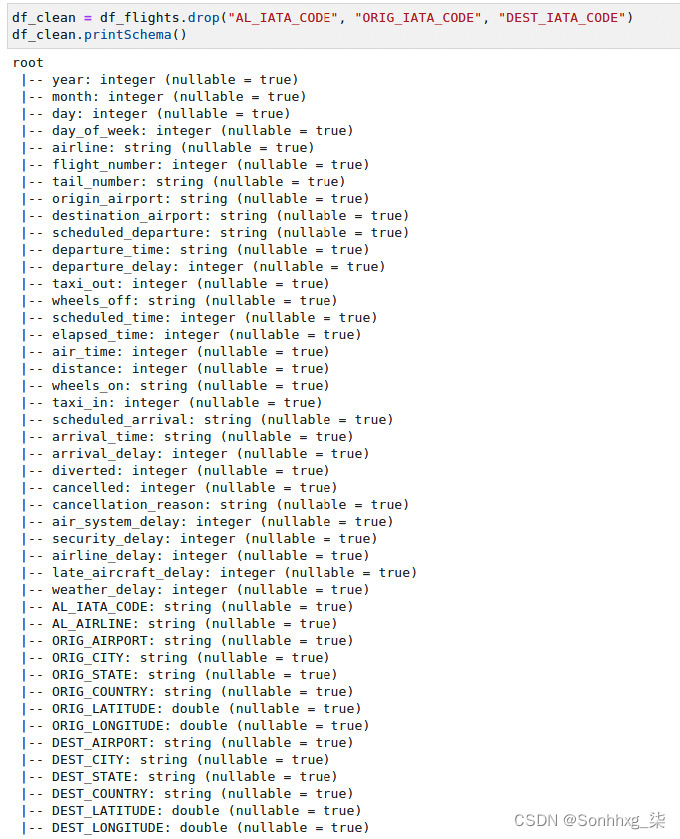
图 9.22 – 删除不需要的列
我们不需要AI_IATA_CODE、ORIG_IATA_CODE和DEST_IATA_CODE ,因为它们分别与airport、origin_airport和destination_airport列相同。
4.寻找具有相同值的列数据集是一项昂贵的操作。这意味着您需要计算 500 万条记录的每列的不同值。幸运的是,Spark 提供了approx_count_distinct()函数,它非常快。图 9.23中的代码片段显示了如何找到具有统一值的列:
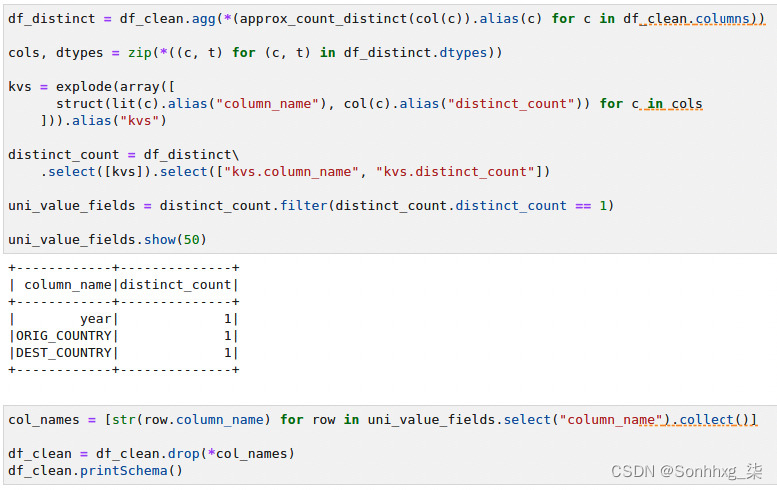
图 9.23 – 删除所有行中具有统一值的列
5.最后,创建确定航班是否延误的标签字段。数据科学家可以使用这个字段作为训练的标签。但是,数据科学家也可以使用模拟范围,例如离开延迟,这取决于所选择的算法。因此,让我们将离开延迟字段与基于离开延迟的 15 分钟阈值的新布尔字段保持在一起。我们称这个新字段为 DELAYED:
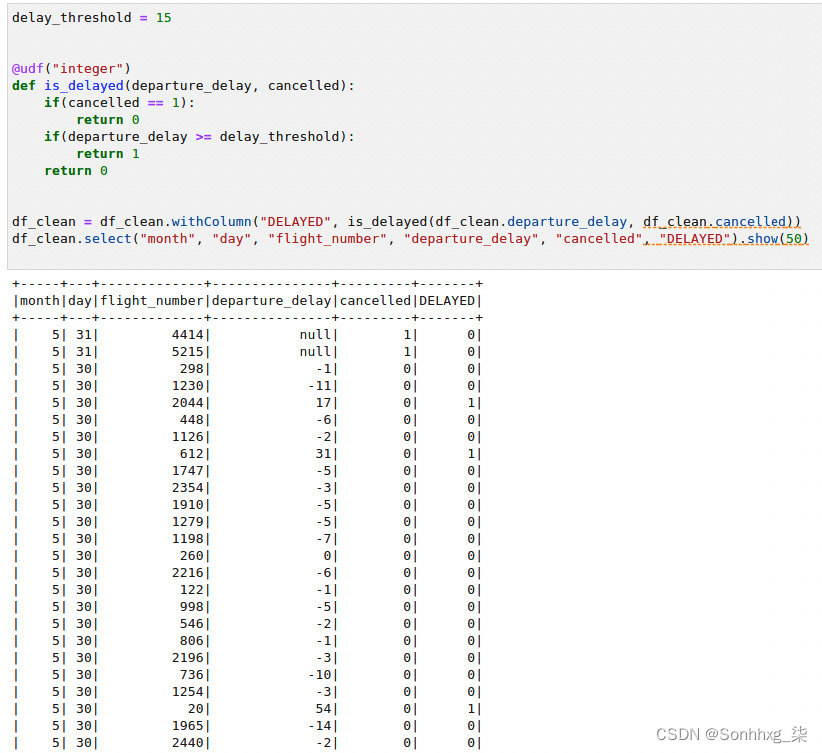
图 9.24 – 创建 DELAYED 列
图 9.24显示了用于创建派生列的代码片段。通过使用show()函数运行一个简单的查询来测试列创建逻辑。
6.现在,写物理数据到同一个 S3在航班清洁路径下的桶。我们还想用 Parquet 编写输出(见图 9.25):
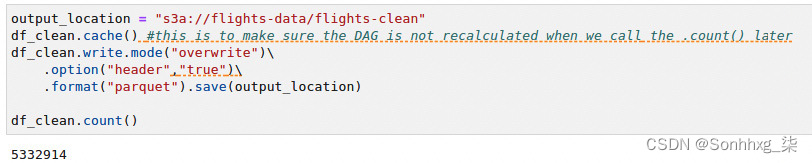
图 9.25 – 将最终数据帧写入 S3
作为数据工程师,您需要就输出格式与数据科学家达成一致。一些数据科学家可能希望获得一个巨大的 CSV 文件数据集,而不是多个 Parquet 文件。在我们的例子中,假设数据科学家更喜欢读取多个 Parquet 文件。
7.第 6 步可能需要相当长的时间。您可以访问 Spark UI 来监控应用程序的执行。
你可以找到完整的 clean_data.ipynb笔记本在本书的 Git 存储库中的chapter9文件夹下。但是,我们强烈建议您从头开始创建自己的笔记本,以最大限度地提高学习体验。
使用 Spark UI 监控您的数据管道
在跑步的时候Spark 应用程序,您可以想要更深入地了解 Spark 实际在做什么以优化您的管道。Spark UI 提供了非常有用的信息。master 的登录页面显示工作节点和应用程序的列表,如图 9.26所示:
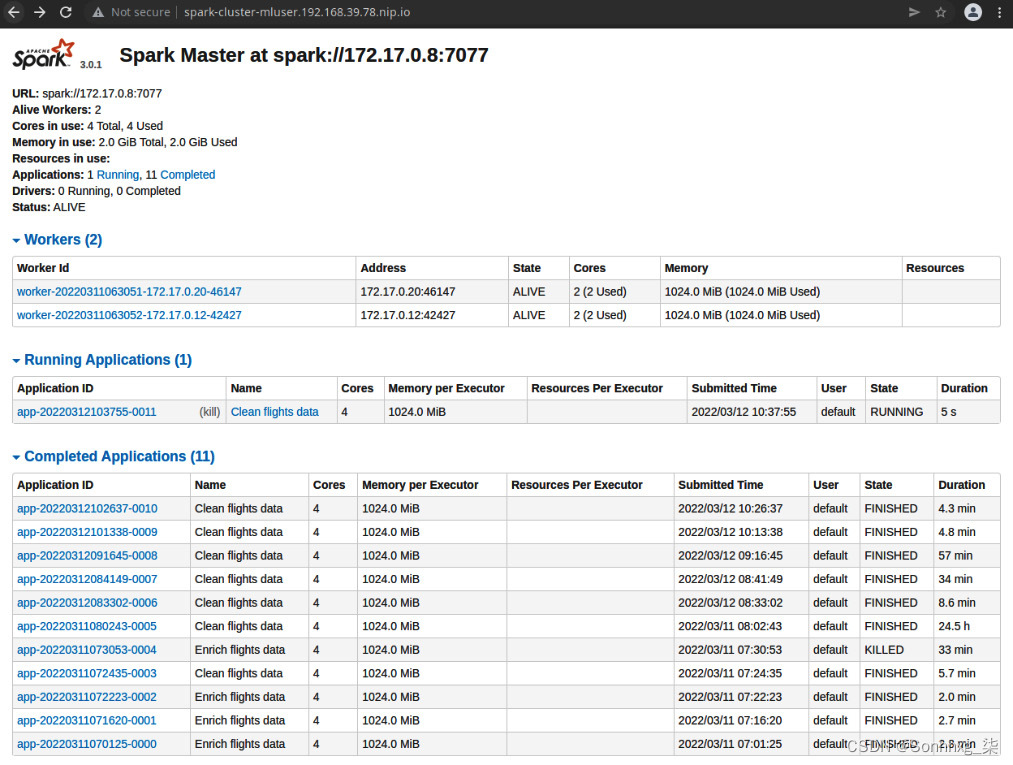
图 9.26 – Spark 集群登陆页面
登录页面还显示历史应用程序运行。通过单击已完成的应用程序 ID 之一,您可以查看已完成的应用程序的一些详细信息。然而,我们对跑步更感兴趣监控应用程序时的应用程序。让我们进一步了解 UI 中的信息。
探索工人页面
工作人员是机器是 Spark 集群的一部分。他们的主要职责是运行执行者。在我们的在这种情况下,工作节点是 Kubernetes Pod,具有worker在其中运行的Java 虚拟机( JVM )。每个 Worker 可以托管一个或多个 executor。但是,在 Kubernetes 上运行 Spark 工作程序时,这不是一个好主意,因此您应该将执行程序配置为只有一个执行程序可以在工作程序中运行:
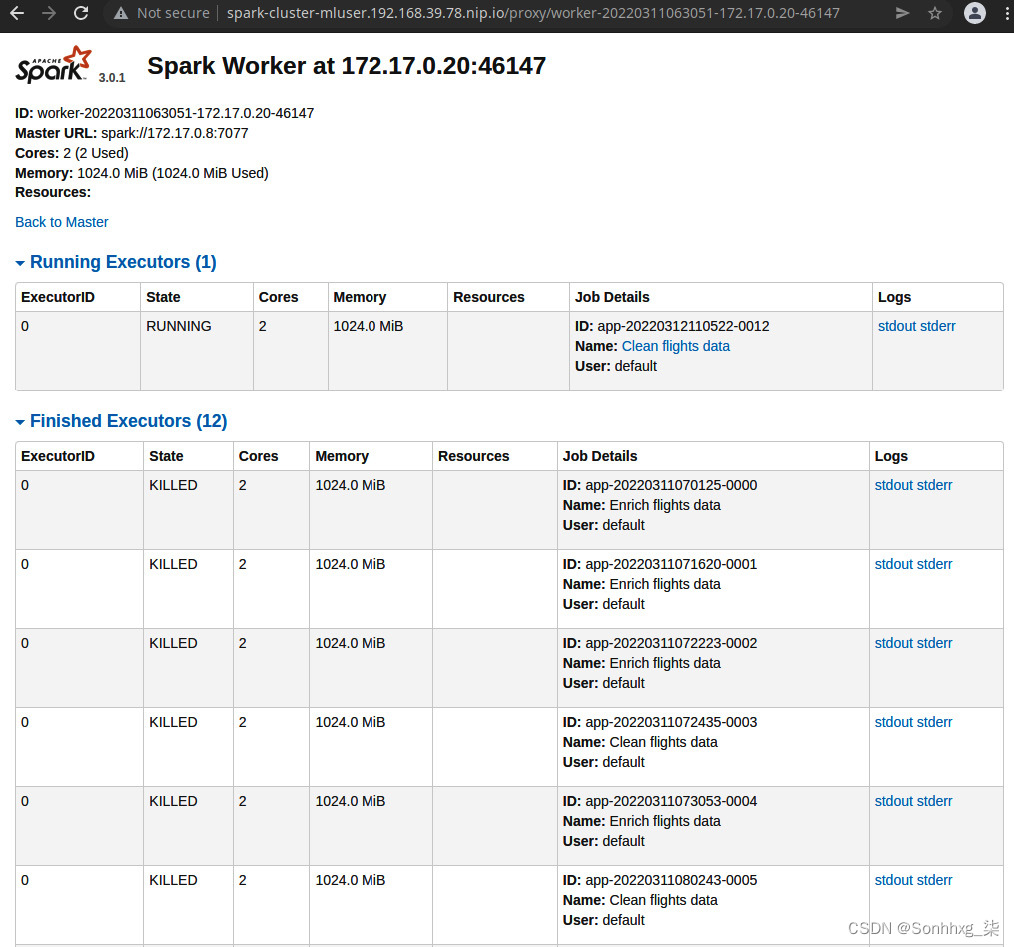
图 9.27 – Spark Worker 视图
单击 UI 中的其中一个工作程序将带您进入工作程序 UI,您可以在其中看到该工作程序已运行或当前正在运行的所有执行程序。您还可以查看哪个应用程序拥有这执行人。你可以看到分配给它的 CPU 或内存,甚至可以看到每个 executor 的日志。
探索执行者页面
执行者是流程在工作节点内运行。他们的主要职责是执行任务。执行器只不过是在工作节点上运行的 Java 或 JVM 进程。worker JVM 进程管理同一主机内的执行器实例。转到 http://spark-cluster-mluser.<minikube_ip>.nip.io/proxy/<application_id>/executors/ 将带您进入Executors页面,该页面将列出属于当前应用程序的所有 executor,如图所示在图 9.28中:
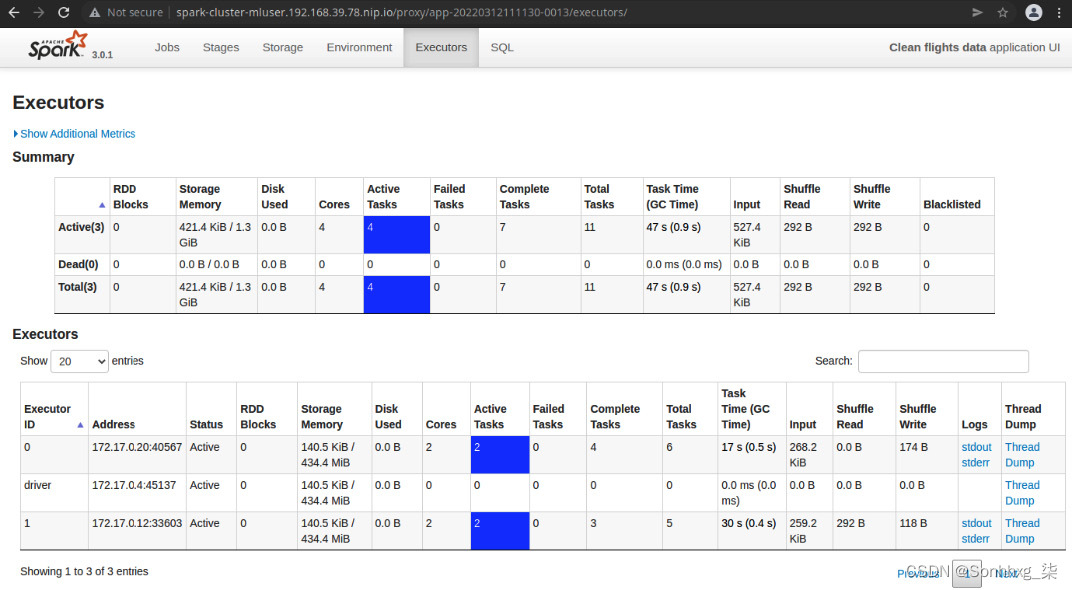
图 9.28 – Spark Executors 页面
在此页面上,您将找到对微调和优化应用程序很重要的有用指标。例如,您可以查看资源使用情况、垃圾收集时间以及洗牌。洗牌是在多个执行器之间交换数据,这将发生在什么时候例如,您执行聚合函数。你想保持这个尽可能小。
探索应用程序页面
应用在火花是拥有 Spark 上下文的任何进程。它可以是正在运行的 Java、Scala 或 Python 应用程序,它创建了 Spark 会话或 Spark 上下文并将其提交到 Spark 主 URL。应用程序不一定要在 Spark 集群中运行。只要它可以连接到 Spark 主服务器,它就可以位于网络中的任何位置。但是,还有一种模式,应用程序(也称为驱动程序应用程序)在其中一个 Spark 执行程序中执行。在我们的例子中,驱动程序应用程序是在 Spark 集群之外运行的 Jupyter 笔记本。这就是为什么在图 9.28中,您可以看到一个名为driver的执行程序,而不是实际的执行程序 ID。
从登录页面单击正在运行的应用程序的应用程序名称将带您进入应用程序 UI 页面。此页面显示属于当前应用程序的所有作业。作业是更改数据帧的操作。每个作业都由一个或多个任务组成。任务是数据帧的一对操作和分区。这是分配给执行者的工作单元。在计算机科学中,这相当于一个闭包。这些作为二进制文件通过网络传送到工作节点为了执行人来执行。图 9.29显示了应用程序 UI 页面:
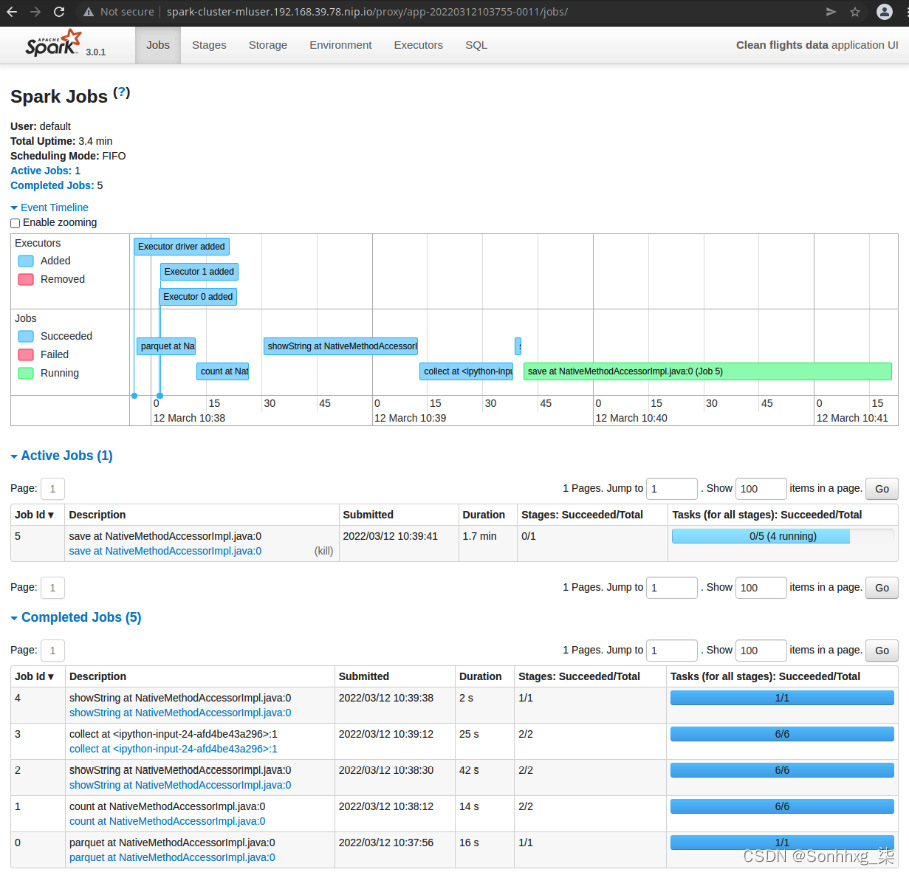
图 9.29 – Spark 应用程序 UI
在图 9.29的示例中,您可以看到活动作业5有五个任务,其中有四个任务正在运行。Tasks的并行度取决于分配给应用程序的 CPU 内核数。您还可以更深入地了解特定工作。如果您访问 http://spark-cluster-mluser.<minikube_ip>.nip.io/proxy/<application_id>/jobs/job/?id=<job_id>,您应该会看到作业的阶段和 DAG每个阶段的。
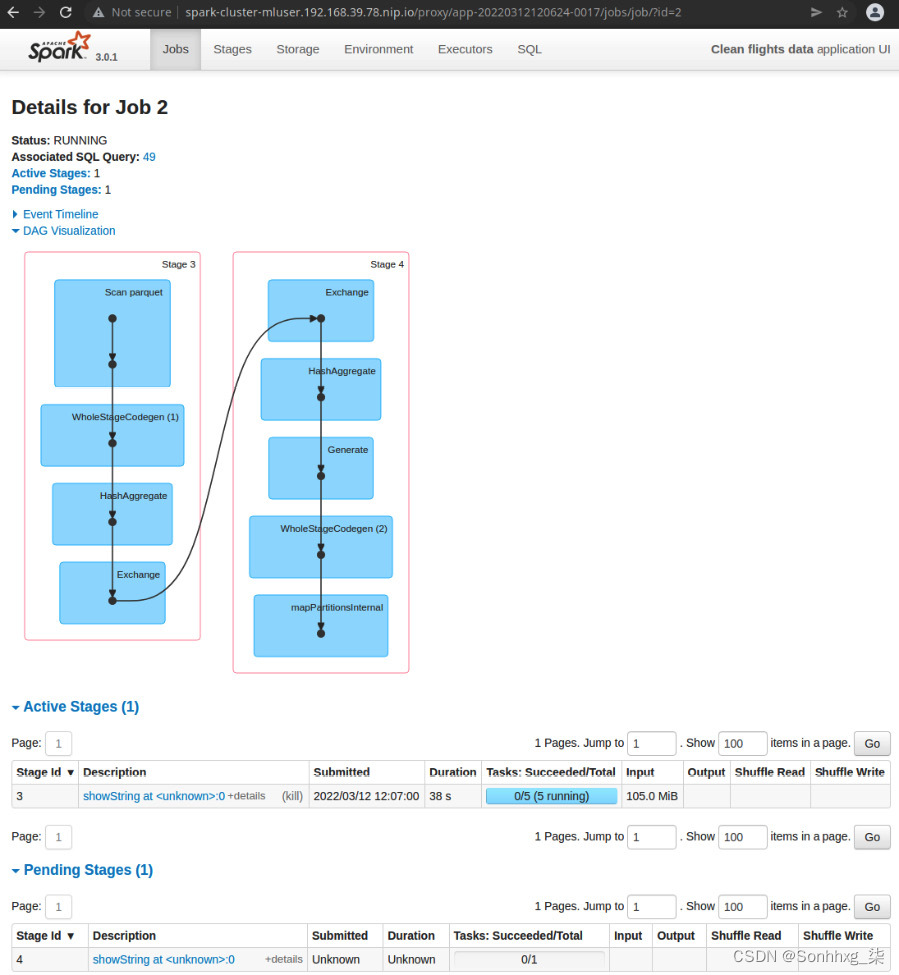
图 9.30 – Spark 作业详细信息页面
Spark GUI 是极其在执行诊断和微调复杂的数据处理应用程序时很有用。Spark 也有很好的文档记录,我们建议您通过以下链接访问 Spark 的文档:https ://spark.apache.org/docs/3.0.0 。
现在您已经创建了一个用于丰富航班数据的笔记本和另一个用于清理数据集的笔记本,以便为 ML 项目生命周期的下一阶段准备数据集,让我们看看如何自动执行这些笔记本。
使用 Airflow 构建和执行数据管道
在里面前部分,你已经建立了你的数据管道摄取和处理数据。想象一下,每周有一次新的航班数据可用,您需要重复处理新数据。一种方法是手动运行数据管道;但是,这种方法可能不会随着数据管道数量的增长而扩展。数据工程师的时间将更有效地用于编写新管道,而不是重复运行旧管道。第二个问题是安全性。您可能已经在示例数据上编写了数据管道,而您的团队可能无法访问生产数据来执行数据管道。
自动化为这两个问题提供了解决方案。您可以安排数据管道在数据工程师从事更有趣的工作时根据需要运行。您的自动化管道可以连接到生产数据,而无需开发团队的任何参与,这将提高安全性。
ML 平台包含 Airflow,它可以自动执行和调度数据管道。有关 Airflow 的介绍,请参阅第 7 章,模型部署和自动化以及可视化编辑器如何允许数据工程师从他们用于编写数据管道的同一 IDE 构建数据管道。该集成为数据工程团队提供了以自助和独立方式工作的能力,从而进一步提高了团队的效率。
在下一部分中,您将为您在上一部分中构建的项目自动化数据管道。
了解数据管道 DAG
我们先来了解一下运行您构建的数据管道所涉及的内容。一旦您掌握了正确的信息,就可以轻松实现流程自动化。
当您开始在 JupyterHub 中编写数据管道时,您将从 JupyterHub 登录页面中的Elyra Notebook Image with Spark notebook 开始。在笔记本中,您连接到 Apache Spark 集群并开始编写数据管道。ML平台知道,对于Elyra Notebook Image with Spark image,需要启动一个新的Spark集群才能在notebook中使用。完成工作后,关闭 Jupyter 环境,这会导致 ML 平台关闭 Apache Spark 集群。
- 启动 Spark 集群。
- 运行数据管道笔记本。
- 停止 Spark 集群。
图 9.31显示了 DAG 的各个阶段:

图 9.31 – 航班项目的气流 DAG
这些阶段中的每一个都将由 Airflow 作为离散步骤执行。Airflow 将 Kubernetes Pod 旋转到运行每个阶段,同时提供运行每个阶段所需的 Pod 映像。Pod 运行在 Airflow 管道中为该阶段定义的代码。
让我们看看 DAG 中的每个阶段负责什么。
启动 Spark 集群
在这个阶段,一个将配置新的 Spark 集群。该集群将专用于运行一个 Airflow DAG。自动化的作用是将新 Spark 集群的请求作为 CR 提交给 Kubernetes。然后,Spark 运算符将提供集群,该集群可用于 DAG 中的下一步。
一旦 Airflow 引擎提交了创建 Spark 集群的请求,它将开始运行第二阶段。
运行数据管道
在这个阶段,您在本章前面编写的一组笔记本(merge_data和clean_data)将由 Airflow DAG 执行。回顾第 7 章,模型部署和自动化,Airflow 使用不同的算子来运行自动化管道的各个阶段(请注意,Airflow 算子与 Kubernetes 算子不同)。Airflow 提供了一个笔记本操作符来运行 Jupyter 笔记本。
自动化的作用是使用笔记本操作符运行您的数据管道笔记本。数据管道完成代码执行后,Airflow 引擎将进入下一个阶段。
停止 Spark 集群
在这个阶段,一个 Spark集群将被破坏。自动化的作用是删除在这个 DAG 的第一阶段创建的 Spark 集群 CR。然后,Spark 操作员将终止用于在前一阶段执行数据管道的集群。
接下来是定义 Airflow 将用于执行每个阶段的容器映像。
注册容器镜像以执行 DAG
你刚刚构建你的自动化 DAG 来运行你的数据管道,并且这个 DAG 的每个阶段都将通过为每个阶段运行一个单独的 Pod 来执行:
1.要注册容器镜像,首先,打开 JupyterHub IDE 并单击左侧菜单栏上的Runtime Images选项。您将看到以下屏幕:
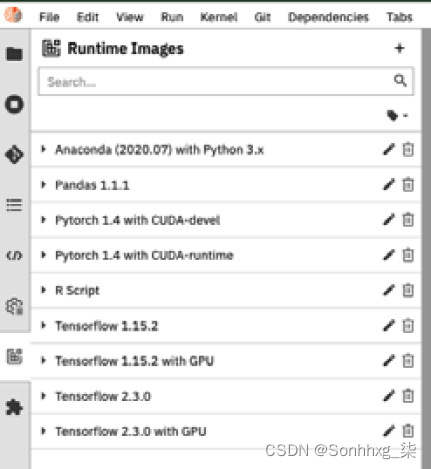
图 9.32 – JupyterHub IDE 中的容器运行时映像注册
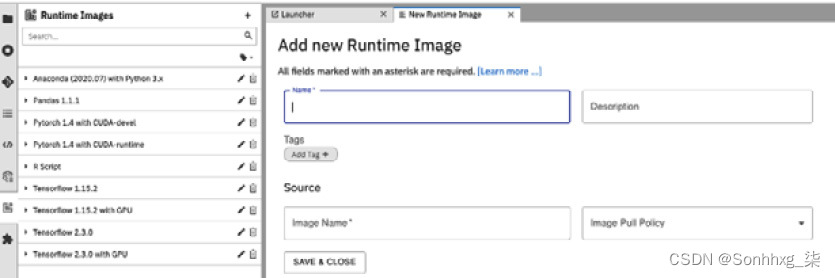
图 9.33 – JupyterHub IDE 中的容器运行时映像注册详细信息
对于航班数据管道 DAG,您将需要以下两个容器:
3.第一个容器映像将使 Airflow 能够运行 Python 代码。使用以下详细信息填充屏幕(如图9.33所示),然后单击标题为SAVE & CLOSE的按钮:
- 名称:AirFlow Python Runner
- 描述:一个带有 Python 运行时的容器
- 来源: quay.io/ml-on-k8s/airflow-python-runner: 0.0.11
- 图片拉取政策:IfNotPresent
4.第二个容器映像将使 Airflow 能够运行数据管道笔记本。使用以下详细信息填写图 9.33所示的屏幕,然后单击标题为SAVE & CLOSE的按钮:
- 名称: AirFlow PySpark Runner
- 描述:一个带有 notebook 和 pyspark 的容器,用于执行 PySpark 代码
- 来源:quay.io/ml-on-k8s/elyra-spark :0.0.4
- 图片拉取政策:IfNotPresent
在下一节中,您将使用 Airflow 构建和执行这三个阶段。
构建和运行 DAG
在本节中,您将使用 ML 平台构建和部署 DAG。您将首先使用拖放编辑器构建 DAG,然后修改生成的代码以进一步自定义 DAG。
使用可视化编辑器构建 Airflow DAG
在本节中,您为您的数据构建 DAG处理流程。您将看到 JupyterHub 如何使用拖放功能帮助您构建 DAG:
1.首先在平台上登录 JupyterHub。
2.通过选择File |创建一个新管道。新| PipelineEditor菜单选项。您将获得一个新的空管道:
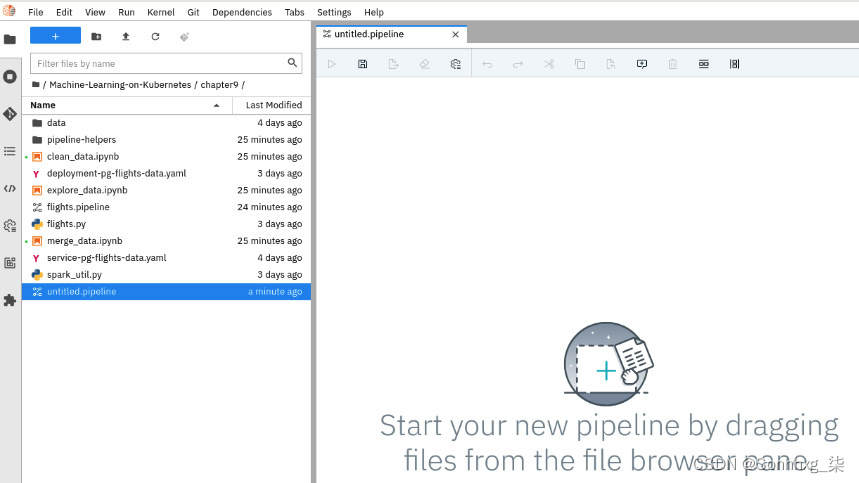
图 9.34 – 一个空的 Airflow DAG
3.如前面的屏幕截图所示,您可以首先从编辑器左侧的文件浏览器中拖动管道所需的文件。对于我们的航班DAG,第一步是启动一个新的 Spark 集群。你会看见一个在浏览器上名为pipeline-helpers/start-spark-cluster的文件。将其从浏览器中拖放到您的管道上:
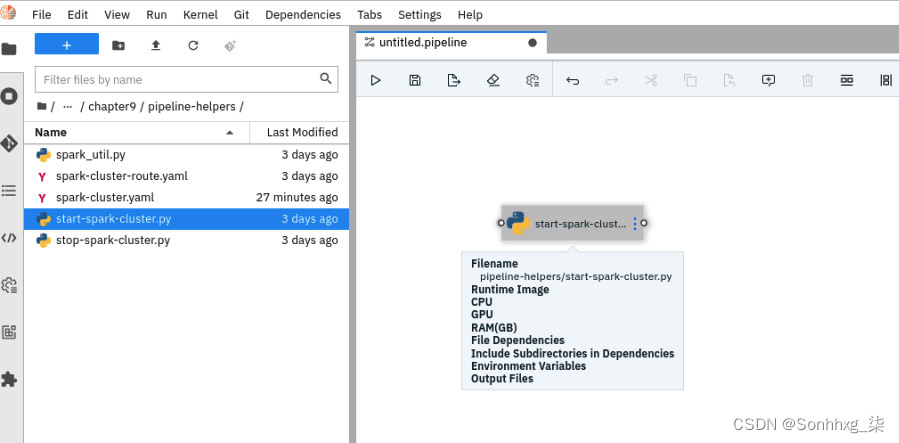
图 9.35 – 使用拖放构建 DAG 阶段
4.通过添加您需要的文件来完成您的管道。航班数据的完整 DAG可在下一步中获得。
5.我们添加了一个预建的供您用作参考。转到名为Chapter 9/的文件夹,然后打开flight.pipeline文件。你可以看到那里是处理航班数据所需的三个阶段:
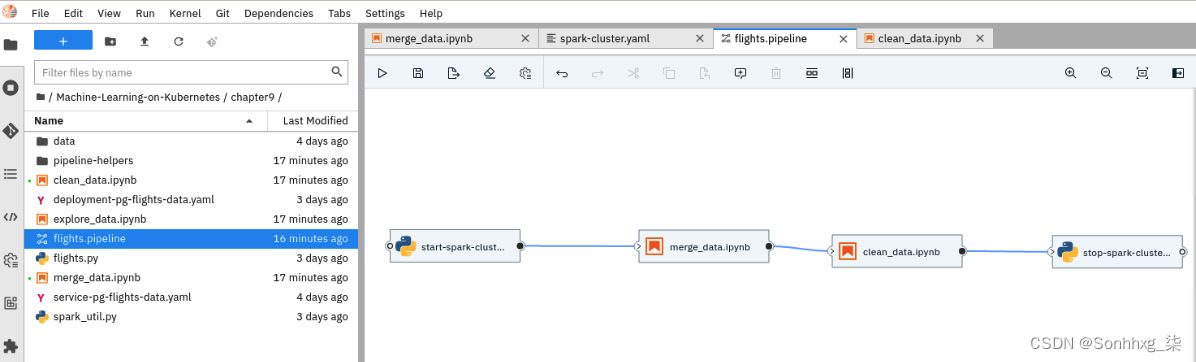
图 9.36 – JupyterHub IDE 中的 DAG 视图
6.单击名为start-spark-cluster的 DAG 的第一个元素。右键单击此元素并选择Properties:
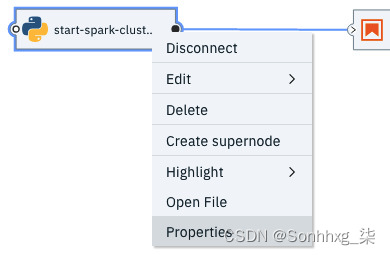
图 9.37 – 选择 DAG 中第一阶段的属性
7.在右侧窗口中,您可以看到此阶段的属性:
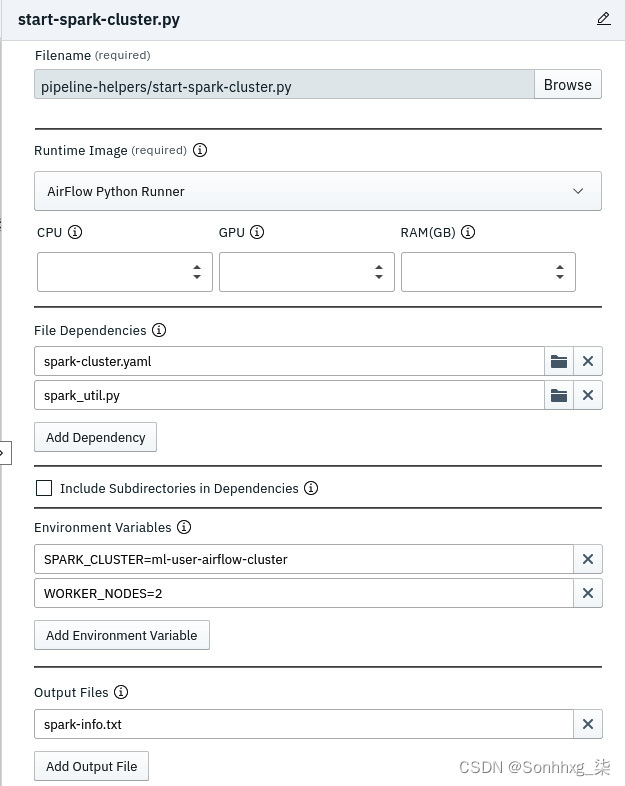
图 9.38 – start-spark.py 阶段的属性
以下列表描述了每个属性:
- 文件名部分定义了文件 ( start-spark-cluster.py ) 将在此阶段由 Airflow 执行。
- 运行时映像部分定义将用于执行上一步中提到的文件的映像。这是您在前面部分中注册的容器映像。对于 Python 阶段,您将使用AirFlow Python Runner容器映像。
- File Dependencies部分定义了此阶段所需的文件。spark-cluster.yaml定义了 Spark 集群的配置。spark_util.py文件是我们创建的作为与 Spark 集群通信的辅助实用程序的文件。请注意,在 DAG 中与此阶段关联的文件将打包在 DAG 中,并且在 Airflow 执行阶段时可供您的阶段使用。所有这些文件都在存储库中可用。
- 环境变量部分定义环境变量。在这种情况下,文件start-spark-cluster.py将有权访问这些环境变量。将这些变量视为可用于管理文件行为的配置。例如,SPARK_CLUSTER变量用于命名创建的 Spark 集群。WORKER_NODES定义将创建多少个工作 Pod 作为 Spark 工作人员。因此,对于更大的作业,您可以选择更改此参数以拥有更多节点。打开start-spark-cluster.py文件,你会看到这它正在读取两个环境变量。图 9.39显示了文件:
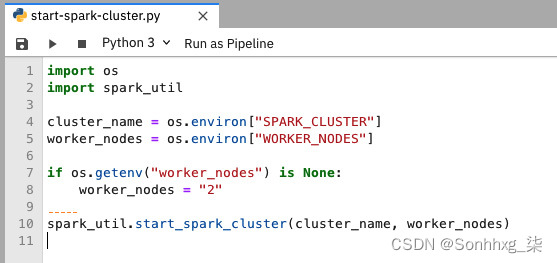
图 9.39 – 读取环境变量的 start-spark.py 文件
输出文件部分定义由 DAG 的这个阶段创建的任何文件。Airflow 将为 DAG 的所有其他阶段复制此文件。通过这种方式,您可以在 DAG 的多个阶段共享信息。在这个例子中,spark_util.py文件打印了 Spark 集群的位置;将其视为集群正在侦听的网络名称。其他阶段(例如数据管道笔记本)可以使用此名称连接到 Spark 集群。Airflow 中还有其他选项可用于在阶段之间共享数据,您可以探索并确定最适合您的用例的数据。
8.单击名为merge_data.ipynb的 DAG 的第二个元素。右键单击此元素并选择Properties。您将看到在此阶段,运行时映像已更改为AirFlow PySpark Runner。您会注意到与此阶段关联的文件是 Jupyter 笔记本文件。这与您用于开发数据管道的文件相同。这才是真正的灵活性一体化这将使您的代码在任何环境中运行。

图 9.40 – DAG 中的 Spark notebook 阶段
添加第二个笔记本clean_data.ipynb作为 DAG 的下一阶段,设置与merge_data.ipynb类似。我们将数据管道分解为多个笔记本,以便于维护和代码管理。
9.此 DAG 的最后一个阶段是停止 Spark 集群。请注意,此阶段的Runtime Image再次是AirFlow Python Runner,因为代码是基于 Python 的。
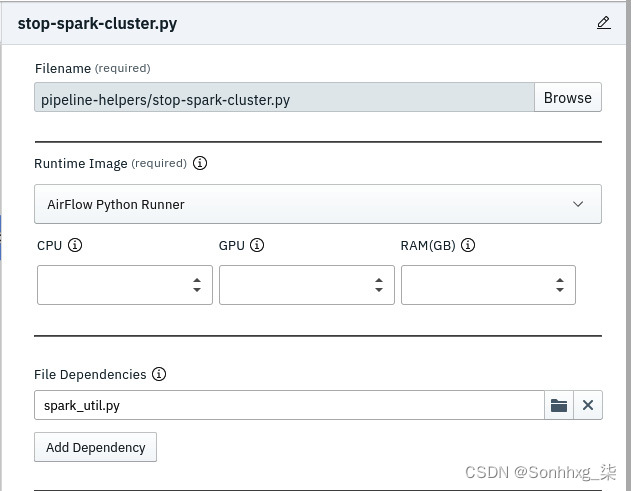
图 9.41 - stop-spark-cluster.py 阶段的属性
10.如果您对其进行任何更改,请确保保存flight.pipeline文件。
您现在已经完成了第一个 DAG。重要的是,作为一名数据工程师,您自己构建了 DAG,并且您构建的数据管道代码在管道中被使用。这个能力将增加速度和让您的数据工程团队自主和自给自足。
在下一阶段,您将在平台上运行此 DAG。
运行和验证 DAG
在本节中,您将运行您在上一节中构建的 DAG。我们假设您已经完成了第 7 章,模型部署和自动化,在介绍 Airflow部分中提到的步骤:
1.在 JupyterHub IDE 中加载flight.pipeline文件并点击Run pipeline图标。图标是图标栏上的一个小播放按钮。您将获得以下运行管道屏幕:
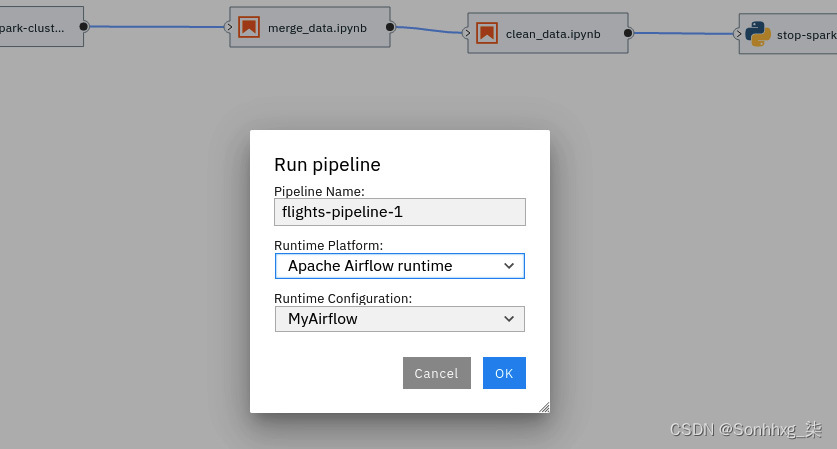
图 9.42 – Airflow DAG 提交对话框
为管道命名,选择Apache Airflow 运行时作为运行时平台选项,然后根据您的设置选择运行时配置选项。如果您已按照第 7 章,模型部署和自动化中的说明进行操作,则该值为MyAirflow。
3.您将看到以下屏幕,验证管道已提交到平台中的 Airflow 引擎:
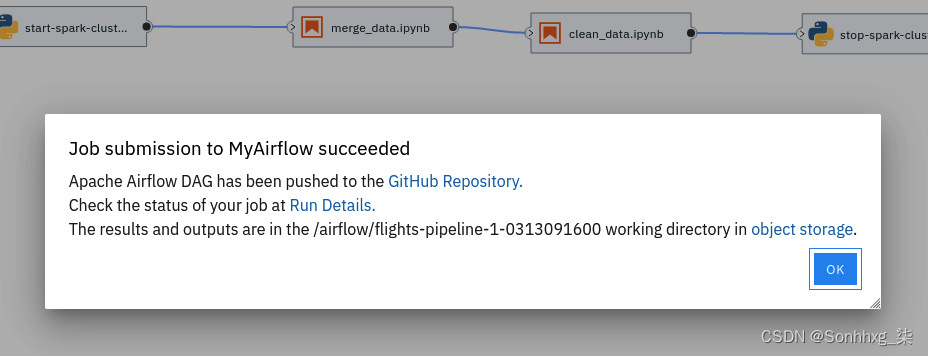
图 9.43 – Airflow DAG 提交确认
4.打开airflow用户界面。您可以通过https://airflow.<IP 地址>.nip.io访问 UI 。IP 地址是您的 minikube 环境的地址。您会发现管道显示在 Airflow GUI 中:
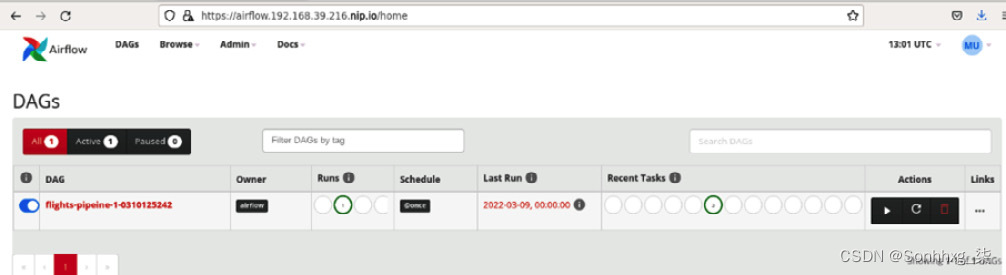
图 9.44 – Airflow GUI 中的 DAG 列表
5.单击 DAG,然后单击Graph View链接。您将获得详细信息执行 DAG。这与您在上一节中构建的图表相同,其中包含三个阶段。
请注意,根据您的 DAG 执行阶段,您的屏幕可能看起来会有所不同:
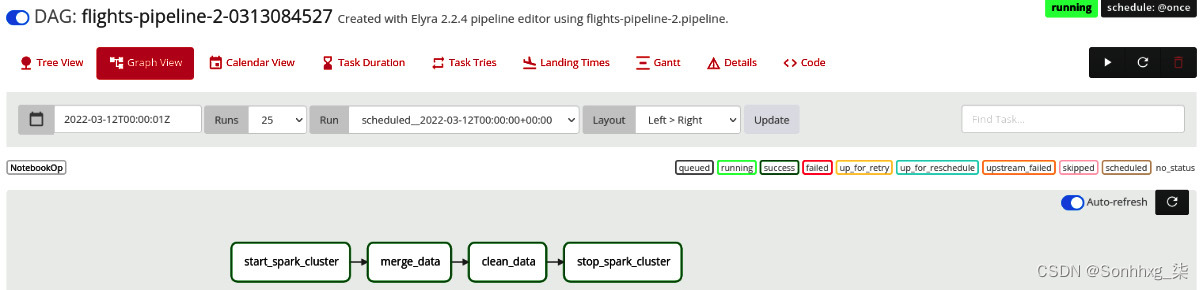
图 9.45 – DAG 执行状态
在本节中,您了解了数据工程师如何构建数据管道(merge_data笔记本),然后能够使用JupyterHub IDE 中的Airflow ( flights.pipeline ) 对其进行打包和部署。该平台提供了一个集成的解决方案来大规模构建、测试和运行您的数据管道。
IDE 提供了构建 Airflow DAG 的基础知识。如果您想更改 DAG 以使用 Airflow 引擎的高级功能怎么办?在下一节中,您将看到如何更改IDE 为高级用例生成的 DAG 代码。
通过编辑代码增强 DAG
你可能有注意到您构建的 DAG 只运行了一次。如果您想定期运行它怎么办?在本节中,您将通过将运行频率更改为每天运行来增强 DAG:
1.在 JupyterHub IDE 中打开flight.pipeline 。您将看到以下熟悉的屏幕:
图 9.46 – flight.pipeline 文件
2.单击顶部栏上的导出管道图标,您将看到一个导出管道的对话框。点击确定按钮:
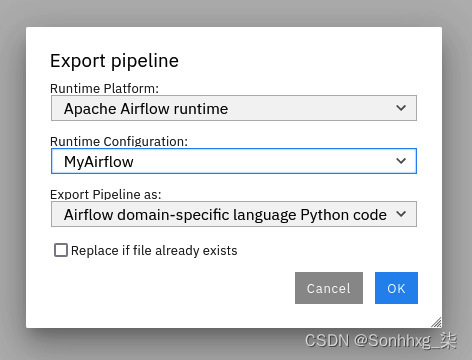
图 9.47 – 导出管道对话框
3.您将收到一条消息,表明管道导出成功,并且将创建一个新文件作为flight.py。打开通过从左侧面板中选择该文件。您应该会看到生成的 DAG 的完整代码:

图 9.48 – 导出后的 DAG 代码
4.您将在 Python 中看到您的 DAG 代码。从这里,您可以根据需要更改代码。为了这练习中,我们想改变 DAG 执行的频率。在代码中找到DAG对象;它将在第 11 行附近:
dag = DAG(
"flights-0310132300",
default_args=args,
schedule_interval="@once",
start_date=days_ago(1),
description="Created with Elyra 2.2.4 pipeline editor using flights.pipeline.",
is_paused_upon_creation=False,
)5.更改 DAG 对象的计划。将值从schedule_interval="@once"更改为schedule_interval="@daily"。
6.更改后的 DAG 代码如下所示:
dag = DAG(
"flights-0310132300",
default_args=args,
schedule_interval="@daily",
start_date=days_ago(1),
description="Created with Elyra 2.2.4 pipeline editor using flights.pipeline.",
is_paused_upon_creation=False,
)7.将文件保存在 IDE 中并将文件推送到 DAG 的 Git 存储库。这是您在配置 Airflow 时在第 7 章,模型部署和自动化中配置的 Git 存储库。
8.现在,加载Airflow GUI,您将能够看到包含@daily标记的Schedule列的新 DAG。这意味着该作业将每天运行:
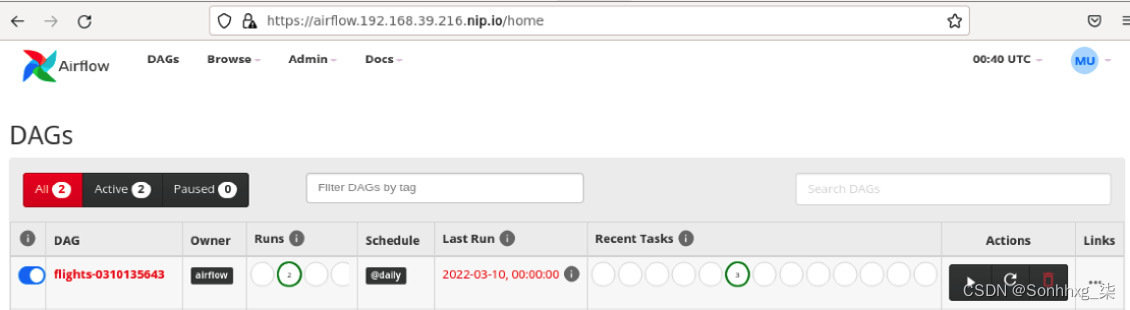
图 9.49 – 显示每日时间表的气流 DAG 列表
恭喜!你已成功构建数据管道并使用 DAG 自动执行管道。这种抽象的很大一部分是由平台管理的 Apache Spark 集群的生命周期。您的团队将拥有更高的速度,因为 IDE、自动化 (Airflow) 和数据处理引擎 (Apache Spark) 由平台管理。
概括
呸!这是另一个马拉松章节,您在其中构建了用于预测航班准点性能的数据处理管道。您已经了解了您构建的平台如何使您能够使用 Apache Spark 编写复杂的数据管道,而无需担心配置和维护 Spark 集群。事实上,您已经完成了所有练习,而无需 IT 小组的具体帮助。您已经使用平台中提供的技术自动执行数据管道,并从您的 IDE 中看到了 Airflow 管道的集成,您用于编写 Spark 数据管道的 IDE 相同。
请记住,本书的主要目的是帮助您提供一个平台,让数据和 ML 团队可以以自给自足和独立的方式工作,您刚刚实现了这一目标。您和您的团队拥有数据工程的整个生命周期并安排管道的执行。
在下一章中,您将看到如何将相同的原则应用于数据科学生命周期,以及团队如何使用该平台为该项目构建和自动化数据科学组件。















 704
704











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











