







🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋
文章目录
在第 3 章中,我们介绍了如何从系统的角度处理数据。在本章中,我们将从数据科学的角度讨论如何处理数据。尽管训练数据在开发和改进 ML 模型中很重要,但 ML 课程在偏向于建模,许多从业者认为这是该过程的“有趣”部分。构建最先进的模型很有趣。花费数天时间处理大量格式错误的数据,这些数据甚至不适合您的机器内存,这令人沮丧。
数据是混乱的、复杂的、不可预测的并且可能是危险的。如果处理不当,它很容易使您的整个 ML 操作陷入困境。但这正是数据科学家和机器学习工程师应该学习如何很好地处理数据的原因,这可以节省我们的时间并让我们在以后头疼。
在本章中,我们将介绍获取或创建良好训练数据的技术。本章中的训练数据包含 ML 模型开发阶段使用的所有数据,包括用于训练、验证和测试的不同拆分(训练、验证、测试拆分)。本章从不同的采样技术开始,以选择用于训练的数据。然后,我们将解决创建训练数据的常见挑战,包括标签多重性问题、标签缺失问题、类别不平衡问题以及解决数据缺失问题的数据增强技术。
我们使用术语“训练数据”而不是“训练数据集”,因为“数据集”表示有限且平稳的集合。生产中的数据既不是有限的也不是静止的,我们将在“数据分布变化”一节中介绍这一现象。与构建 ML 系统的其他步骤一样,创建训练数据是一个迭代过程。随着您的模型在项目生命周期中不断发展,您的训练数据也可能会不断发展。
在我们继续前进之前,我只想重复一句已经说过很多次但仍然不够的警告。数据充满了潜在的偏差。这些偏见有许多可能的原因。在收集、取样或标记过程中会产生偏差。历史数据可能嵌入了人类偏见,而基于这些数据训练的 ML 模型可以使它们永久化。使用数据,但不要太相信它!
采样
采样是 ML 工作流程不可或缺的一部分,不幸的是,在典型的 ML 课程作业中经常被忽视。采样发生在 ML 项目生命周期的许多步骤中,例如采样从所有可能的真实世界数据中创建训练数据;从给定的数据集中采样以创建用于训练、验证和测试的拆分;或从您的 ML 系统中发生的所有可能事件中采样以进行监控。在本节中,我们将重点介绍用于创建训练数据的采样方法,但这些采样方法也可用于 ML 项目生命周期中的其他步骤。
在许多情况下,抽样是必要的。一种情况是,当您无法访问现实世界中的所有可能数据时,用于训练模型的数据是由一种或另一种采样方法创建的现实世界数据的子集。另一种情况是处理您有权访问的所有数据是不可行的——因为它需要太多时间或资源——因此您必须对这些数据进行抽样以创建一个可以处理的子集。在许多其他情况下,抽样很有帮助,因为它可以让您更快、更便宜地完成任务。例如,在考虑新模型时,您可能希望先对一小部分数据进行快速实验,以查看新模型是否有前景,然后再根据所有数据训练此新模型。1
了解不同的抽样方法以及它们在我们的工作流程中的使用方式,首先可以帮助我们避免潜在的抽样偏差,其次,帮助我们选择提高抽样数据效率的方法。
有两类抽样:非概率抽样和随机抽样。我们将从非概率抽样方法开始,然后是几种常见的随机抽样方法。
非概率抽样
非概率抽样是选择数据不基于任何概率标准。以下是非概率抽样的一些标准:
简单采样
数据样本的选择基于关于他们的可用性。这种采样方法很受欢迎,因为它很方便。
雪球采样
未来的样本是根据现有的样品。例如,要在不访问 Twitter 数据库的情况下抓取合法的 Twitter 账户,您可以从少量账户开始,然后抓取他们关注的所有账户,依此类推。
判断抽样
配额抽样
您根据配额选择样品某些数据切片,没有任何随机化。例如,在进行调查时,您可能需要每个年龄组的 100 条回复:30 岁以下、30 至 60 岁和 60 岁以上,而不管实际年龄分布如何。
由非概率标准选择的样本不能代表真实世界的数据,因此充满了选择偏差。2因为这些偏见,您可能会认为使用这一系列采样方法选择数据来训练 ML 模型是一个坏主意。你是对的。不幸的是,在许多情况下,ML 模型的数据选择仍然是由便利性驱动的。
这些情况的一个例子是语言建模。语言模型通常不是使用代表所有可能文本的数据进行训练,而是使用易于收集的数据进行训练——维基百科、Common Crawl、Reddit。
另一个例子是数据用于一般文本的情感分析。大部分数据是从具有自然标签(评级)的来源收集的,例如 IMDB 评论和亚马逊评论。然后将这些数据集用于其他情绪分析任务。IMDB 评论和亚马逊评论偏向于愿意在线发表评论的用户,并不一定代表无法访问互联网或不愿意在线发表评论的人。
第三个例子是用于训练自动驾驶汽车的数据。最初,为自动驾驶汽车收集的数据主要来自两个地区:亚利桑那州凤凰城(因为监管不严)和加利福尼亚湾区(因为许多制造自动驾驶汽车的公司都在这里)。这两个地区的天气普遍晴朗。2016 年,Waymo 将业务扩展到华盛顿州柯克兰,专门针对柯克兰的阴雨天气,3但晴天的自动驾驶汽车数据仍然比雨天或下雪的天气多得多。
非概率抽样是收集初始数据以启动项目的一种快速简便的方法。但是,对于可靠的模型,您可能希望使用基于概率的抽样,我们接下来会介绍。
简单随机抽样
在最简单的随机抽样形式中,您给总体中的所有样本以相等的概率被选中。4例如,您随机选择 10% 的人口,使该人口的所有成员都有 10% 的机会被选中。
这种方法的优点是易于实现。缺点是稀有类别的数据可能不会出现在您的选择中。考虑一个类仅出现在 0.01% 的数据总体中的情况。如果您随机选择 1% 的数据,则不太可能选择此稀有类别的样本。在此选择上训练的模型可能会认为这个稀有类不存在。
分层抽样
避免简单随机的缺点抽样,你可以先把你的人口分成你关心的组,然后分别从每个组中抽样。例如,要对具有 A 和 B 两个类的 1% 的数据进行采样,您可以对 A 类和 B 类的 1% 进行采样。这样,无论 A 类或 B 类多么罕见,您都可以确保它的样本将包含在选择中。每组称为一个层,这种方法称为分层抽样。
这种抽样方法的一个缺点是它并不总是可行的,例如当不可能将所有样本分成组时。当一个样本可能属于多个组时,这尤其具有挑战性,例如多标签任务。5例如,一个样本既可以是 A 类也可以是 B 类。
加权抽样
在加权抽样中,每个样本都是给定一个权重,它决定了它被选中的概率。例如,如果您有三个样本 A、B 和 C,并希望它们分别以 50%、30% 和 20% 的概率被选中,则可以赋予它们 0.5、0.3 和 0.2 的权重。
此方法允许您利用领域专业知识。例如,如果您知道某个数据子群(例如更新的数据)对您的模型更有价值,并希望它有更高的被选中机会,您可以赋予它更高的权重。
当您拥有的数据来自与真实数据不同的分布时,这也有帮助。例如,如果在你的数据中,红色样本占 25%,蓝色样本占 75%,但你知道在现实世界中,红色和蓝色发生的概率相等,你可以赋予红色样本权重 3 倍于蓝色样品。
在 Python 中,您可以使用以下方法进行加权采样random.choices:
# Choose two items from the list such that 1, 2, 3, 4 each has
# 20% chance of being selected, while 100 and 1000 each have only 10% chance.
import random
random.choices(population=[1, 2, 3, 4, 100, 1000],
weights=[0.2, 0.2, 0.2, 0.2, 0.1, 0.1],
k=2)
# This is equivalent to the following
random.choices(population=[1, 1, 2, 2, 3, 3, 4, 4, 100, 1000],
k=2)ML 中与加权采样密切相关的一个常见概念是样本权重。加权采样用于选择用于训练模型的样本,而样本权重用于为训练样本分配“权重”或“重要性”。权重较高的样本对损失函数的影响更大。改变样本权重可以显着改变模型的决策边界,如图 4-1所示。
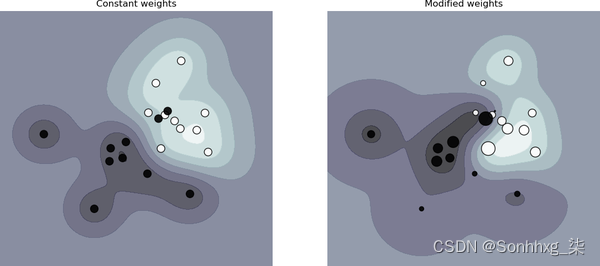
图 4-1。样本权重会影响决策边界。左边是当所有样本被赋予相同的权重时。右边是当样本被赋予不同的权重时。来源:scikit-learn 6
Reservoir 取样
水库取样是一个迷人的当您必须处理流数据时特别有用的算法,这通常是您在生产中所拥有的。
想象一下,您有一个传入的推文流,并且您想对一定数量的推文进行采样,k,以进行分析或训练模型。你不知道有多少条推文,但你知道你不能把它们都放在内存中,这意味着你事先不知道应该选择一条推文的概率。您要确保:
-
每条推文都有相同的被选中概率。
-
您可以随时停止算法,并以正确的概率对推文进行采样。
该问题的一种解决方案是储层采样。该算法涉及一个容器,它可以是一个数组,由三个步骤组成:
-
将前k个元素放入容器中。
-
对于每个传入的第n个元素,生成一个随机数i使得 1 ≤ i ≤ n。
-
如果 1 ≤ i ≤ k:将水库中的第i个元素替换为第n个元素。否则,什么都不做。
这意味着每个传入的第n个元素都有ķn在水库中的概率。你还可以证明水库中的每个元素都有ķn在那里的概率。这意味着所有样本都有相同的机会被选中。如果我们随时停止算法,则容器中的所有样本都以正确的概率进行了采样。图 4-2显示了一个说明性示例水库采样是如何工作的。
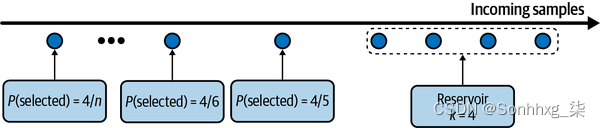
图 4-2。储层采样如何工作的可视化
重要性抽样
重要性抽样是最重要的抽样之一采样方法,不仅仅是在 ML 中。当我们只能访问另一个分布时,它允许我们从一个分布中采样。
想象一下,您必须从分布P ( x ) 中对x进行采样,但是P ( x ) 确实很昂贵、缓慢或无法从中采样。但是,您有一个更容易采样的分布Q ( x )。所以你从Q ( x ) 中采样x并通过P(x)/Q(x). Q ( x ) 称为提议分布或重要性分布。Q ( x ) 可以是任何分布,只要P ( x ) ≠ 0 时Q ( x ) > 0。下面的等式表明,在期望中,从P ( x ) 采样的x等于从Q ( x )采样的x加权P(x)/Q(x):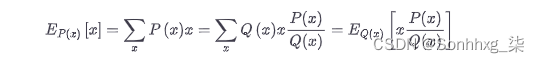
在 ML 中使用重要性采样的一个例子是基于策略的强化学习。当您想更新您的政策时,请考虑这种情况。您想估计新策略的价值函数,但计算采取行动的总回报可能会很昂贵,因为它需要考虑所有可能的结果,直到该行动之后的时间范围结束。但是,如果新政策与旧政策比较接近,您可以改为根据旧政策计算总奖励,并根据新政策重新加权。旧策略的奖励构成了提案分配。
标签
尽管有无监督机器学习的前景,但大多数机器学习模型今天在生产中是有监督的,这意味着他们需要标记数据来学习。ML 模型的性能仍然在很大程度上取决于它所训练的标记数据的质量和数量。
在与我的学生交谈时,特斯拉的人工智能总监 Andrej Karpathy 分享了一个轶事,即当他决定建立一个内部标签团队时,他的招聘人员问他需要这个团队多久。他回答说:“我们需要一个工程团队多久?” 数据标记已经从一项辅助任务变成了生产中许多 ML 团队的核心功能。
在本节中,我们将讨论获取数据标签的挑战。我们将首先讨论数据科学家在谈论标记时通常首先想到的标记方法:手工标记。然后,我们将讨论带有自然标签的任务,这些任务可以从系统中推断出标签而不需要人工注释,然后是在缺少自然标签和手标签时该怎么做。
手标签
任何曾经在生产环境中处理过数据的人都可能在内脏层面:为您的数据获取手标签很困难,原因有很多。首先,手工标记数据可能很昂贵,尤其是在需要主题专业知识的情况下。要对评论是否为垃圾邮件进行分类,您可以在众包平台上找到 20 个注释者,并在 15 分钟内训练他们为您的数据添加标签。但是,如果您想标记胸部 X 光片,则需要找到经过董事会认证的放射科医生,他们的时间有限且费用昂贵。
其次,手工标注对数据隐私构成威胁。手工标记意味着必须有人查看您的数据,如果您的数据有严格的隐私要求,这并不总是可行的。例如,您不能只将患者的医疗记录或公司的机密财务信息发送给第三方服务进行标记。在许多情况下,甚至可能不允许您的数据离开您的组织,并且您可能必须雇用或签约注释者来标记您的数据。
第三,手工贴标速度慢。例如,语音级别的语音话语的准确转录可能需要比话语持续时间长 400 倍的时间。7因此,如果你想为 1 小时的演讲添加注释,那么一个人将需要 400 小时或将近 3 个月的时间。在一项使用 ML 帮助通过 X 射线对肺癌进行分类的研究中,我的同事们不得不等待将近一年才能获得足够的标签。
缓慢的标记会导致缓慢的迭代速度,并使您的模型不太适应不断变化的环境和需求。如果任务更改或数据更改,您必须等待重新标记数据,然后再更新模型。想象一下当你有一个情绪分析模型来分析每条提到你的品牌的推文的情绪时的场景。它只有两个类别:NEGATIVE 和 POSITIVE。但是,部署后,您的公关团队意识到最大的损害来自愤怒的推文,他们希望更快地处理愤怒的消息。因此,您必须更新您的情绪分析模型,使其具有三个类别:NEGATIVE、POSITIVE 和 ANGRY。为此,您需要再次查看您的数据,以了解哪些现有训练示例应重新标记为 ANGRY。如果您没有足够的 ANGRY 示例,您将不得不收集更多数据。
标签多重性
通常,为了获得足够的标记数据,公司必须使用来自多个来源的数据并依赖于具有不同专业水平的多个注释者。这些不同的数据源和注释器也具有不同级别的准确度。这导致了标签模糊或标签多重性的问题:当数据实例有多个冲突标签时该怎么办。
考虑这个简单的实体识别任务。您向三个注释者提供以下示例,并要求他们注释他们可以找到的所有实体:
达斯·西迪厄斯(Darth Sidious),简称为皇帝,是西斯的黑暗领主,作为第一银河帝国的银河皇帝统治着银河系。
您会收到三种不同的解决方案,如表 4-1所示。三个注释器识别了不同的实体。你的模型应该在哪一个上训练?在由注释器 1 标记的数据上训练的模型与在由注释器 2 标记的数据上训练的模型的性能将大不相同。
| 注释器 | # 个实体 | 注解 |
|---|---|---|
| 1 | 3 | [Darth Sidious], known simply as the Emperor, was a [Dark Lord of the Sith] who reigned over the galaxy as [Galactic Emperor of the First Galactic Empire]. |
| 2 | 6 | [Darth Sidious], known simply as the [Emperor], was a [Dark Lord] of the [Sith] who reigned over the galaxy as [Galactic Emperor] of the [First Galactic Empire]. |
| 3 | 4 | [Darth Sidious], known simply as the [Emperor], was a [Dark Lord of the Sith] who reigned over the galaxy as [Galactic Emperor of the First Galactic Empire]. |
注释者之间的分歧非常普遍。所需的领域专业知识水平越高,注释分歧的可能性就越大。8如果一位人类专家认为标签应该是 A,而另一位专家认为标签应该是 B,我们如何解决这种冲突以获得一个单一的基本事实?如果人类专家无法就标签达成一致,那么人类水平的表现甚至意味着什么?
为了尽量减少注释者之间的分歧,首先要有一个清晰的问题定义很重要。例如,在前面的实体识别任务中,如果我们澄清在多个可能实体的情况下,选择包含最长子串的实体,则可以消除一些分歧。这意味着银河第一帝国的银河皇帝,而不是银河皇帝和第一银河帝国。其次,您需要将该定义合并到注释者的培训,以确保所有注释者都理解规则。
数据沿袭
不加选择地使用来自多个来源的数据,由不同的注释器生成,而不检查它们的质量可能会导致您的模型神秘地失败。考虑一个案例,当您使用 100K 数据样本训练了一个中等好的模型。您的 ML 工程师相信更多数据会提高模型性能,因此您花费大量资金聘请注释者来标记另外一百万个数据样本。
但是,在对新数据进行训练后,模型性能实际上会下降。原因是新的一百万个样本被众包给了标注数据的标注者,标注的准确率远低于原始数据。如果您已经混合了数据并且无法区分新数据和旧数据,则可能特别难以解决此问题。
跟踪每个数据样本的来源及其标签是一种很好的做法,这种技术称为数据沿袭。数据沿袭可帮助您标记数据中的潜在偏差并调试模型。例如,如果您的模型在最近获取的数据样本上大部分都失败了,那么您可能想要研究如何获取新数据。不止一次,我们发现问题不在于我们的模型,而在于模型中错误标签的数量异常多。我们最近获得的数据。
自然标签
手工标签并不是唯一的来源标签。你可能很幸运能够处理带有自然真实标签的任务。具有自然标签的任务是模型的预测可以由系统自动评估或部分评估的任务。一个例子是在谷歌地图上估计某条路线的到达时间的模型。如果您选择那条路线,在您的行程结束时,Google 地图会知道行程实际花费了多长时间,从而可以评估预计到达时间的准确性。另一个例子是股票价格预测。如果您的模型在接下来的两分钟内预测股票价格,那么在两分钟后,您可以将预测价格与实际价格进行比较。
具有自然标签的任务的典型示例是推荐系统。推荐系统的目标是向用户推荐与他们相关的项目。用户是否点击推荐item 与否可以看作是对该建议的反馈。被点击的推荐可以被认为是好的(即标签是积极的),而在一段时间(比如 10 分钟)后没有被点击的推荐可以被认为是坏的(即标签是负面的)。
许多任务可以被定义为推荐任务。例如,您可以将预测广告点击率的任务构建为根据用户的活动历史和个人资料向用户推荐最相关的广告。从点击和评分等用户行为推断的自然标签也称为行为标签。
即使您的任务本身没有自然标签,也可能以允许您收集模型反馈的方式设置您的系统。例如,如果你正在构建一个像谷歌翻译这样的机器翻译系统,你可以选择让社区为糟糕的翻译提交替代翻译——这些替代翻译可以用来训练你的模型的下一次迭代(尽管你可能想先查看这些建议的翻译)。新闻源排名不是具有固有标签的任务,但通过为每个新闻源项目添加“赞”按钮和其他反应,Facebook 能够收集对其排名算法的反馈。
带有自然标签的任务相当业内常见。在对我网络中 86 家公司的调查中,我发现其中 63% 的公司处理带有自然标签的任务,如图 4-3所示。这并不意味着可以从 ML 解决方案中受益的任务中有 63% 具有自然标签。更有可能的是,公司发现首先开始具有自然标签的任务更容易、更便宜。
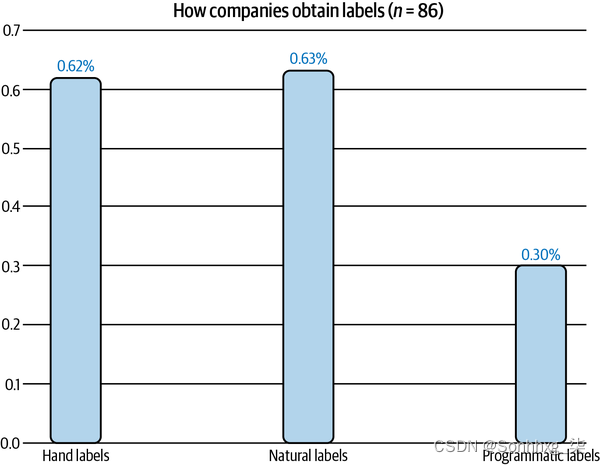
图 4-3。在我的网络中,63% 的公司从事带有自然标签的任务。百分比总和不等于 1,因为公司可以处理具有不同标签来源的任务。9
在前面的示例中,可以假定在一段时间后没有被点击的推荐是不好的。这被称为隐式标签,因为这个负标签是由于缺少正标签而假定的。它与显式标签不同,在显式标签中,用户通过给予低评价或否决来明确展示他们对推荐的反馈。
反馈回路长度
对于具有自然基本事实标签的任务,从提供预测到提供预测所需的时间提供的反馈是反馈回路长度。具有短反馈循环的任务是标签通常在几分钟内可用的任务。许多推荐系统具有较短的反馈循环。如果推荐的商品是亚马逊上的相关商品或推特上要关注的人,那么从推荐商品到被点击之间的时间很短,如果它被点击的话。
然而,并不是所有的推荐系统都有一分钟长的反馈循环。如果您使用较长的内容类型,例如博客文章或文章或 YouTube 视频,则反馈循环可能需要数小时。如果你建立一个系统来像 Stitch Fix 那样为用户推荐衣服,那么在用户收到商品并试穿之前,你不会得到反馈,这可能是几周后。
不同类型的用户反馈
如果要从用户中提取标签反馈,重要的是要注意有不同类型的用户反馈。它们可能发生在用户使用您的应用程序的不同阶段,并且因音量、信号强度和反馈循环长度而异。
例如,考虑一个类似于亚马逊的电子商务应用程序。用户在此应用程序上可以提供的反馈类型可能包括点击产品推荐、将产品添加到购物车、购买产品、评分、发表评论以及退回之前购买的产品。
与购买产品相比,点击产品的速度更快、频率更高(因此会产生更高的销量)。然而,与仅仅点击产品相比,购买产品是用户是否喜欢该产品的一个更强烈的信号。
在构建产品推荐系统时,许多公司专注于优化点击,这为他们提供了更多的反馈来评估他们的模型。然而,一些公司专注于采购,这给了他们更强的信号,这也与他们的业务指标(例如,产品销售收入)更相关。两种方法都有效。对于您应该针对您的用例优化哪种类型的反馈,没有明确的答案,这值得所有相关利益相关者之间进行认真讨论。
选择正确的窗口长度需要仔细考虑,因为它涉及速度和准确性的权衡。较短的窗口长度意味着您可以更快地捕获标签,这使您可以使用这些标签来检测模型的问题并尽快解决这些问题。但是,较短的窗口长度也意味着您可能会在点击推荐之前过早地将其标记为不好。
无论您将窗口长度设置多长,都可能会出现过早的负面标签。2021 年初,Twitter 广告团队的一项研究发现,尽管大多数广告点击发生在前五分钟内,但一些点击发生在广告展示后数小时。10这意味着这种类型的标签往往会低估实际点击率。如果您只记录 1,000 个 POSITIVE 标签,则实际点击次数可能会超过 1,000 次。
对于具有长反馈循环的任务,自然标签可能在数周甚至数月内都不会到达。欺诈检测是具有长反馈循环的任务的一个示例。在交易后的一段时间内,用户可以质疑该交易是否具有欺诈性。例如,当客户阅读他们的信用卡对帐单并看到他们不认识的交易时,他们可能会与银行提出异议,向银行提供反馈以将该交易标记为欺诈。典型的争议窗口是一到三个月。争议窗口过去后,如果用户没有争议,您可能会认为交易是合法的。
具有长反馈循环的标签有助于在季度或年度业务报告中报告模型的性能。但是,如果您想尽快检测模型的问题,它们并不是很有帮助。如果您的欺诈检测模型存在问题,并且您需要数月才能发现,那么当问题得到解决时,您的错误模型允许通过的所有欺诈交易可能已经造成了小企业破产。
处理缺少标签
因为收购困难重重足够的高质量标签,已经开发了许多技术来解决由此产生的问题。在本节中,我们将介绍其中的四种:弱监督、半监督、迁移学习和主动学习。这些方法的总结如表 4-2所示。
| 方法 | 如何 | 需要基本事实吗? |
|---|---|---|
| 监管薄弱 | 利用(通常是嘈杂的)启发式方法生成标签 | 否,但建议使用少量标签来指导启发式算法的开发 |
| 半监督 | 利用结构假设生成标签 | 是的,少量初始标签作为种子生成更多标签 |
| 迁移学习 | 利用在另一个任务上预训练的模型来完成新任务 | 零样本学习 不行 |
| 主动学习 | 标记对您的模型最有用的数据样本 | 是的 |
监管薄弱
如果手工贴标签有那么大的问题,如果我们完全不使用手标?一种流行的方法是弱监督。中的一个最流行的弱监督开源工具是斯坦福人工智能实验室开发的 Snorkel。11弱监督背后的洞察力在于,人们依赖启发式方法来标记数据,启发式方法可以通过主题专业知识开发出来。例如,医生可能会使用以下启发式方法来决定患者的病例是否应优先考虑为紧急情况:
如果护士的笔记中提到肺炎等严重疾病,应优先考虑患者的情况。
像 Snorkel 这样的图书馆已经建成围绕标签函数(LF) 的概念:一种编码启发式的函数。上述启发式可以用以下函数表示
def labeling_function(note):
if "pneumonia" in note:
return "EMERGENT"LFs 可以编码许多不同类型的启发式算法。这里是其中的一些:
关键字启发式
比如前面的例子
常用表达
例如,如果注释匹配或不匹配某个正则表达式
数据库查找
比如如果笔记中包含危险疾病列表中列出的疾病
其他模型的输出
例如,如果现有系统将其分类为EMERGENT
编写 LF 后,您可以将它们应用到要标记的样本上。
因为 LF 编码启发式,并且启发式是嘈杂的,所以 LF 生成的标签是嘈杂的。多个 LF 可能适用对于相同的数据示例,它们可能会给出相互冲突的标签。一个函数可能认为护士的笔记是EMERGENT,但另一个函数可能认为不是。一种启发式可能比另一种启发式更准确,您可能不知道,因为您没有基本事实标签来比较它们。对所有 LF 进行组合、去噪和重新加权以获得一组最有可能是正确的标签非常重要。图 4-4 概括地展示了 LF 是如何工作的。
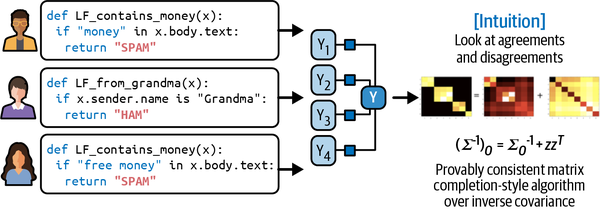
图 4-4。对标签功能如何组合的高级概述。资料来源:改编自 Ratner 等人的图像。12
理论上,你不需要任何手标签来进行弱监督。但是,要了解您的 LF 有多准确,建议使用少量的手标。这些手标签可以帮助您发现数据中的模式以编写更好的 LF。
当您的数据具有严格的隐私要求时,弱监督可能特别有用。您只需要查看一小部分已清除的数据即可写入 LF,无需任何人查看即可将其应用于其余数据。
使用 LF,可以对主题专业知识进行版本化、重用和共享。一个团队拥有的专业知识可以被另一个团队编码和使用。如果您的数据发生变化或您的需求发生变化,您只需将 LF 重新应用于数据样本。使用 LF 为数据生成标签的方法也称为程序化标签。表 4-3显示了程序化标记相对于手动标记的一些优势。
| 手工贴标 | 程序化标签 |
|---|---|
| 昂贵:尤其是在需要专业知识时 | 节省成本:可以在整个组织中对专业知识进行版本化、共享和重用 |
| 缺乏隐私:需要将数据发送给人工注释者 | 隐私:使用清除的数据子样本创建 LF,然后将 LF 应用于其他数据而不查看单个样本 |
| 慢:所需时间与所需标签数量成线性关系 | 快速:轻松从 1K 扩展到 1M 样本 |
| 非自适应:每次更改都需要重新标记数据 | 自适应:当发生变化时,只需重新应用 LF! |
这是一个案例研究,以展示弱监督在实践中的效果。在斯坦福医学的一项研究中,由一位放射科医生在编写 LF 八小时后获得的使用弱监督标签训练的13 个模型与使用通过近一年的手工标注获得的数据训练的模型具有相当的性能,如图 4-5所示。关于实验结果有两个有趣的事实。首先,即使没有更多的 LF,模型也会随着更多未标记的数据继续改进。其次,LF 被跨任务重用。研究人员能够在 CXR(胸部 X 射线)任务和 EXR(四肢 X 射线)任务之间重复使用 6 个 LF。14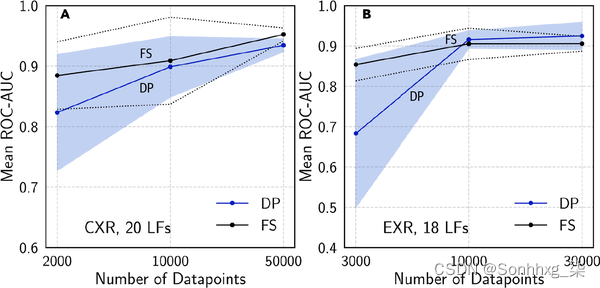
图 4-5。比较在 CXR 和 EXR 任务上使用完全监督标签 (FS) 训练的模型和使用程序标签 (DP) 训练的模型的性能。资料来源:邓蒙等人。15
我的学生经常问,如果启发式方法可以很好地标记数据,为什么我们需要 ML 模型?一个原因是 LF 可能无法覆盖所有数据样本,因此我们可以在以 LF 编程方式标记的数据上训练 ML 模型,并使用这个训练过的模型为任何 LF 未覆盖的样本生成预测。
弱监督是一种简单但强大的范式。然而,它并不完美。在某些情况下,通过弱监督获得的标签可能过于嘈杂而无用。但即使在这些情况下,当你想探索 ML 的有效性而又不想在手头上投入太多资金时,弱监督也是一个很好的入门方法预先标记。
半监督
如果弱监督利用启发式为了获得噪声标签,半监督利用结构假设基于一小组初始标签生成新标签。与弱监督不同,半监督需要一组初始标签。
半监督学习是一种早在 90 年代、16年代就使用过的技术,从那时起已经开发了许多半监督方法。对半监督学习的全面回顾超出了本书的范围。我们将介绍这些方法的一小部分,让读者了解它们是如何使用的。为了全面回顾,我推荐“半监督学习文献调查”(Xiaojin Zhu,2008)和“半监督学习调查”(Engelen 和 Hoos,2018)。
一个经典的半监督方法是自我训练。你首先在你的模型上训练一个模型现有的标记数据集,并使用此模型对未标记样本进行预测。假设具有高原始概率分数的预测是正确的,您将具有高概率预测的标签添加到您的训练集中,并在这个扩展的训练集上训练一个新模型。这种情况一直持续到您对模型性能感到满意为止。
另一种半监督方法假设具有相似特征的数据样本共享相同的标签。相似性可能很明显,例如在分类 Twitter 标签主题的任务中。您可以首先将标签“#AI”标记为计算机科学。假设出现在同一推文或个人资料中的主题标签可能是关于同一主题的,给定图 4-6中 MIT CSAIL 的个人资料,您还可以将主题标签“#ML”和“#BigData”标记为计算机科学。

图 4-6。因为#ML 和#BigData 与#AI 出现在同一个Twitter 个人资料中,我们可以假设它们属于同一个主题
在大多数情况下,只有通过更复杂的方法才能发现相似性。例如,您可能需要使用聚类方法或k最近邻算法来发现属于同一聚类的样本。
近年来流行的一种半监督方法是基于扰动的方法。它基于假设对样本的小扰动不应改变其标签。因此,您对训练实例应用小扰动以获得新的训练实例。扰动可以直接应用于样本(例如,将白噪声添加到图像)或它们的表示(例如,将小的随机值添加到单词的嵌入)。扰动样本与未扰动样本具有相同的标签。我们将在“扰动”部分对此进行更多讨论。
在某些情况下,半监督方法已经达到了纯监督学习的性能,即使给定数据集中的大部分标签已被丢弃。17
当训练标签的数量有限时,半监督是最有用的。在使用有限数据进行半监督时要考虑的一件事是,应该使用多少有限数据来评估多个候选模型并选择最佳模型。如果您使用少量,那么在这个小评估集上表现最好的模型可能是最适合这个集的模型。另一方面,如果您使用大量数据进行评估,则基于此评估集选择最佳模型所获得的性能提升可能小于将评估集添加到有限训练集所获得的提升。许多公司通过使用相当大的评估集来选择最好的模型,然后继续在评估集上训练冠军模型。
迁移学习
迁移学习是指为任务开发的模型被重用的方法族。第二个任务的模型的起点。首先,基础模型针对基础任务进行训练。基础任务通常是具有廉价且丰富的训练数据的任务。语言建模是一个很好的候选者,因为它不需要标记数据。语言模型可以在任何文本体(书籍、维基百科文章、聊天历史)上进行训练,任务是:给定一系列标记,18 个预测下一个标记。当给出“我购买 NVIDIA 股票,因为我相信它的重要性”这一序列时,语言模型可能会输出“硬件”或“GPU”作为下一个标记。
然后可以将经过训练的模型用于您感兴趣的任务(下游任务),例如情绪分析、意图检测或问答。在某些情况下,例如就像在零样本学习场景中一样,您也许可以直接在下游任务上使用基础模型。在许多情况下,您可能需要微调 基础模型。微调意味着对基础模型进行微小的更改,例如继续根据来自给定下游任务的数据训练基础模型或基础模型的一部分。19
有时,您可能需要使用模板修改输入以提示基本模型生成所需的输出。20例如,要将语言模型用作问答任务的基本模型,您可能需要使用以下提示:
Q: When was the United States founded?
A: July 4, 1776.
Q: Who wrote the Declaration of Independence?
A: Thomas Jefferson.
Q: What year was Alexander Hamilton born?
A:
当您将此提示输入到诸如GPT-3之类的语言模型中时,它可能会输出 Alexander Hamilton 出生的年份。
迁移学习对于没有大量标记数据的任务特别有吸引力。即使对于具有大量标记数据的任务,与从头开始训练相比,使用预训练模型作为起点通常也可以显着提高性能。
近年来,出于正确的原因,迁移学习引起了极大的兴趣。它启用了许多以前由于缺乏训练样本而无法实现的应用程序。今天生产中的 ML 模型的一个重要部分是迁移学习的结果,包括利用在 ImageNet 上预训练的模型的对象检测模型和利用预训练的语言模型(如 BERT 或 GPT-3)的文本分类模型。21迁移学习还降低了进入机器学习的门槛,因为它有助于降低标记数据以构建机器学习应用程序所需的前期成本。
过去五年出现的一个趋势是(通常)预训练的基础模型越大,其在下游任务中的表现就越好。大型模型的训练成本很高。根据 GPT-3 的配置,估计训练这个模型的成本在几千万美元。许多人假设,未来只有少数公司能够负担得起训练大型预训练模型的费用。其他行业将直接使用这些预训练模型或微调他们满足他们的特定需求。
主动学习
主动学习是一种提高数据标签的效率。这里的希望是,如果 ML 模型可以选择从哪些数据样本中学习,它们可以用更少的训练标签实现更高的准确性。主动学习有时被称为查询学习——尽管这个术语越来越不受欢迎——因为模型(主动学习者)以未标记样本的形式发回查询,以由注释者(通常是人类)标记。
您不是随机标记数据样本,而是根据某些指标或启发式方法标记对您的模型最有帮助的样本。最直接的度量是不确定性测量——标记模型最不确定的示例,希望它们能帮助您的模型更好地学习决策边界。例如,在模型输出不同类别的原始概率的分类问题的情况下,它可能会选择预测类别概率最低的数据样本。图 4-7说明了这种方法在一个玩具示例上的效果如何。
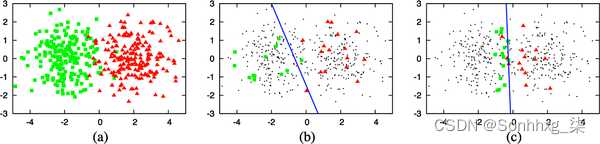
图 4-7。基于不确定性的主动学习如何工作。(a) 一个包含 400 个实例的玩具数据集,从两个高斯类中均匀采样。(b) 在 30 个随机标记的样本上训练的模型的准确率为 70%。(c) 对通过主动学习选择的 30 个样本进行训练的模型给出了 90% 的准确率。资料来源:伯尔定居22
另一种常见的启发式方法是基于多个候选模型之间的分歧。这种方法称为按委员会查询,是集成方法的一个示例。23您需要一个由多个候选模型组成的委员会,这些模型通常是使用不同超参数集训练的同一个模型,或者是在不同数据切片上训练的同一个模型。每个模型都可以对接下来要标记哪些样本进行投票,并且它可能会根据预测的不确定性进行投票。然后,您标记委员会最不同意的样本。
还有其他启发式方法,例如选择样本,如果对它们进行训练,将提供最高的梯度更新或最大程度地减少损失。要全面了解主动学习方法,请查看“主动学习文献调查”(Settles 2010)。
要标记的样本可以来自不同的数据机制。它们可以在您的模型在其最不确定的输入空间区域中生成样本的地方合成。24它们可能来自固定分布,您已经收集了大量未标记的数据,并且您的模型从该池中选择样本进行标记。它们可以来自现实世界的分布,您有数据流进入,就像在生产中一样,您的模型从这个数据流中选择样本进行标记。
当系统处理实时数据时,我对主动学习感到最兴奋。数据一直在变化,我们在第 1 章中简要介绍了这一现象,并将在第 8 章中进一步详细介绍。在这种数据体系中进行主动学习将使您的模型能够更有效地实时学习并更快地适应变化环境。
阶级失衡
类不平衡通常是指分类任务中的一个问题,其中存在显着差异每类训练数据的样本数。例如,在一个从 X 射线图像中检测肺癌任务的训练数据集中,99.99% 的 X 射线可能是正常肺,只有 0.01% 可能包含癌细胞。
类别不平衡也可能发生在标签连续的回归任务中。考虑任务估计医疗保健费用。25医疗保健账单高度倾斜——账单中位数很低,但第 95 个百分位的账单是天文数字。在预测医院账单时,准确预测第 95 个百分位的账单可能比中位数账单更重要。250 美元钞票的 100% 差异是可以接受的(实际 500 美元,预计 250 美元),但 1 万美元钞票的 100% 差异是不可接受的(实际 2 万美元,预计 1 万美元)。因此,我们可能必须训练模型以更好地预测第 95 个百分位数的账单,即使它会降低整体指标。
阶级失衡的挑战
ML,尤其是深度学习,效果很好在数据分布更加平衡的情况下,当类严重不平衡时通常不太好,如图 4-8 所示。由于以下三个原因,班级不平衡会使学习变得困难。
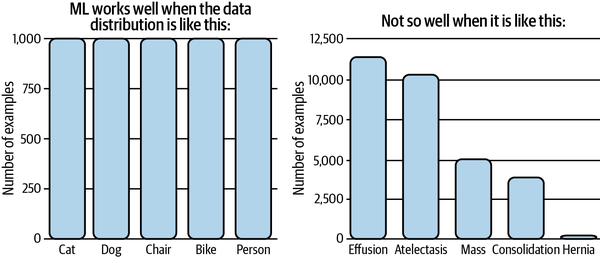
图 4-8。ML 在类平衡的情况下效果很好。资料来源:改编自 Andrew Ng 26的图片
第一个原因是类别不平衡通常意味着您的模型没有足够的信号来学习检测少数类别。在少数类中存在少量实例的情况下,问题就变成了一个小样本学习问题,您的模型在必须对其做出决定之前只能看到少数类几次。如果您的训练集中没有稀有类的实例,您的模型可能会假设这些稀有类不存在。
第二个原因是类不平衡通过利用简单的启发式而不是学习任何有关数据底层模式的有用信息,使您的模型更容易陷入非最优解决方案。考虑前面的肺癌检测示例。如果你的模型学会了总是输出多数类,它的准确率已经是 99.99%。27这种启发式算法很难被梯度下降算法击败,因为添加到这种启发式算法中的少量随机性可能会导致更差的准确性。
第三个原因是类别不平衡导致错误成本不对称——对稀有类别样本的错误预测成本可能远高于对多数类别样本的错误预测成本。
例如,对癌细胞的 X 射线错误分类比对正常肺 X 射线的错误分类危险得多。如果您的损失函数未配置为解决这种不对称性,您的模型将以相同的方式处理所有样本。因此,您可能会获得一个在多数类和少数类上表现同样好的模型,而您更喜欢在多数类上表现较差但在少数类上表现更好的模型。
当我在学校时,我收到的大多数数据集都有或多或少的平衡类。28开始工作并意识到阶级不平衡是常态,这让我感到震惊。在现实世界中,罕见事件通常比常规事件更有趣(或更危险),许多任务都集中在检测这些罕见事件上。
任务的经典示例类不平衡是欺诈检测。大多数信用卡交易都不是欺诈性的。截至 2018 年,持卡人每 100 美元消费 6.8 美分是欺诈性的。29另一个正在流失预言。您的大多数客户可能不打算取消他们的订阅。如果是这样,您的企业需要担心的不仅仅是客户流失预测算法。其他示例包括疾病筛查(幸运的是,大多数人没有绝症)和简历筛查(98% 的求职者在最初的简历筛查中被淘汰30)。
类不平衡任务的一个不太明显的例子是对象检测。目标检测算法目前的工作原理是在图像上生成大量边界框,然后预测哪些框最有可能在其中包含目标。大多数边界框不包含相关对象。
除了问题中固有的类别不平衡的情况之外,类别不平衡也可能是由采样过程中的偏差引起的。考虑一下您想要创建训练数据以检测电子邮件是否为垃圾邮件的情况。您决定使用公司电子邮件数据库中的所有匿名电子邮件。根据 Talos Intelligence 的数据,截至 2021 年 5 月,近 85% 的电子邮件都是垃圾邮件。31但大多数垃圾邮件在到达您公司的数据库之前就被过滤掉了,因此在您的数据集中,只有一小部分是垃圾邮件。
类别不平衡的另一个原因虽然不太常见,但由于标签错误。注释者可能有阅读说明错误或遵循错误说明(认为只有两个类,正和负,而实际上有三个),或者只是犯了错误。每当遇到类别不平衡的问题时,检查您的数据很重要了解它的原因。
处理类不平衡
由于它在现实世界的应用中很普遍,在过去的二十年里,类不平衡已经得到了彻底的研究。32类别不平衡会根据不平衡程度对任务产生不同的影响。有些任务比其他任务对类不平衡更敏感。Japkowicz 表明,对不平衡的敏感性随着问题的复杂性而增加,并且非复杂的线性可分问题不受所有级别的类不平衡的影响。33二分类问题中的类别不平衡比多类别分类问题中的类别不平衡要容易得多。丁等人。表明非常深的神经网络(在 2017 年具有“非常深”的意思超过 10 层)在不平衡数据上的表现要好于较浅的神经网络。34
已经提出了许多技术来减轻类不平衡的影响。然而,随着神经网络变得越来越大、越来越深,学习能力也越来越强,有些人可能会争辩说,如果数据在现实世界中是这样的,那么你不应该尝试“修复”类不平衡。一个好的模型应该学会模拟这种不平衡。然而,开发一个足够好的模型可能具有挑战性,所以我们仍然必须依赖特殊的训练技术。
在本节中,我们将介绍处理类不平衡的三种方法:为您的问题选择正确的指标;数据级方法,这意味着改变数据分布以减少不平衡;和算法级别的方法,这意味着改变你的学习方法,使其对类不平衡更加健壮。
这些技术可能是必要的,但还不够。对于全面的调查,我推荐“Survey on Deep Learning with Class Imbalance”(Johnson 和 Khoshgoftaar 2019)。
使用正确的评估指标
面对班级不平衡的任务时,最重要的是选择合适的评价指标。错误的指标会让您对模型的运行方式产生错误的想法,并且随后将无法帮助您开发或选择足够好的模型来完成您的任务。
总体准确率和错误率是报告 ML 模型性能最常用的指标。但是,对于具有类不平衡的任务,这些指标还不够,因为它们平等地对待所有类,这意味着您的模型在多数类上的性能将主导这些指标。当大多数班级不是您所关心的时,这尤其糟糕。
考虑一个具有两个标签的任务:CANCER(阳性类)和 NORMAL(阴性类),其中 90% 的标记数据是 NORMAL。考虑两个模型 A 和 B,其混淆矩阵如表4-4和4-5所示。
| A型 | 实际癌症 | 实际正常 |
|---|---|---|
| 预测癌症 | 10 | 10 |
| 预测正常 | 90 | 890 |
| B型 | 实际癌症 | 实际正常 |
|---|---|---|
| 预测癌症 | 90 | 90 |
| 预测正常 | 10 | 810 |
如果您和大多数人一样,您可能更喜欢模型 B 为您做出预测,因为它更有可能告诉您您是否真的患有癌症。但是,它们都具有相同的 0.9 精度。
帮助您了解模型在特定类方面的性能的指标将是更好的选择。如果您将准确度单独用于每个类,准确度仍然是一个很好的衡量标准。模型 A 在 CANCER 类上的准确率为 10%,模型 B 在 CANCER 类上的准确率为 90%。
F1、精度和召回率是衡量模型在二元分类问题中相对于正类的性能的指标,因为它们依赖于真正的正类——模型正确预测正类的结果。35
精度、召回率和 F1
对于需要刷新的读者,对于二元任务,精度、召回率和 F1 分数是使用真阳性、真阴性、假阳性和假阴性的计数来计算的。这些术语的定义见表 4-6。
| 预测阳性 | 预测负数 | |
|---|---|---|
| 正面标签 | 真阳性(命中) | 假阴性(II型错误,遗漏) |
| 负面标签 | 误报(I 类错误,误报) | 真阴性(正确拒绝) |
精度 = 真阳性 /(真阳性 + 假阳性)
召回=真阳性/(真阳性+假阴性)
F1 = 2 × 精度 × 召回率 /(精度 + 召回率)
F1、精度和召回率是非对称度量,这意味着它们的值会根据哪个类被认为是正类而变化。在我们的例子中,如果我们将 CANCER 视为正类,模型 A 的 F1 为 0.17。但是,如果我们将 NORMAL 视为正类,模型 A 的 F1 为 0.95。CANCER为正类时模型A和模型B的准确率、准确率、召回率和F1分数如表4-7所示。
| 癌症 (1) | 正常 (0) | 准确性 | 精确 | 记起 | F1 | |
|---|---|---|---|---|---|---|
| A型 | 10/100 | 890/900 | 0.9 | 0.5 | 0.1 | 0.17 |
| B型 | 90/100 | 810/900 | 0.9 | 0.5 | 0.9 | 0.64 |
许多分类问题可以是建模为回归问题。您的模型可以输出一个概率,并根据该概率对样本进行分类。例如,如果值大于 0.5,则为正标签,如果小于或等于 0.5,则为负标签。这意味着您可以调整阈值以增加真阳性率(也称为召回率),同时降低误报率(也称为误报概率),反之亦然。我们可以绘制不同阈值的真阳性率与假阳性率。该图称为ROC 曲线(接收器工作特性)。当您的模型完美时,召回率为 1.0,曲线只是顶部的一条线。这条曲线向您展示了模型的性能如何随阈值而变化,并帮助您选择最适合您的阈值。越接近完美线,模型的性能就越好。
曲线下面积 (AUC) 测量 ROC 曲线下的面积。由于越接近完美线越好,所以这个区域越大越好,如图 4-9所示。
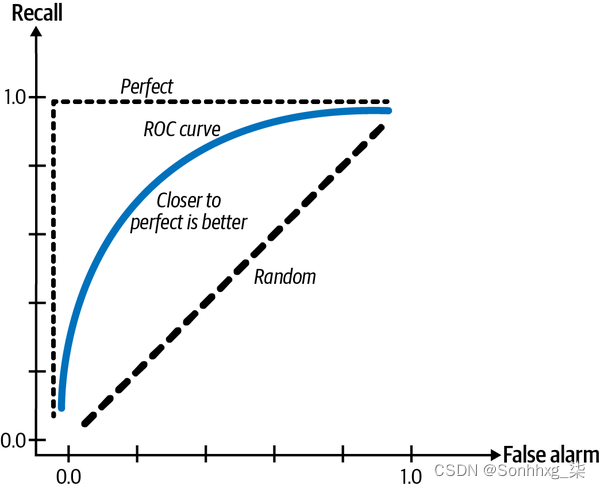
图 4-9。ROC曲线
与 F1 和召回率一样,ROC 曲线仅关注正类,并没有显示您的模型在负类上的表现如何。Davis 和 Goadrich 建议我们应该用他们所谓的 Precision-Recall 曲线来绘制精确度和召回率。他们认为这条曲线更详细地描述了算法在具有严重类别不平衡的任务上的表现。36
数据级方法:重采样
数据级方法修改训练数据的分布以减少不平衡程度,使其更容易供模型学习。一个常见的技术家族是重采样。重采样包括过采样,从少数类中添加更多实例,以及欠采样,删除多数类的实例。最简单的欠采样方法是从多数类中随机删除实例,而过采样的最简单方法是随机复制少数类,直到获得满意的比率。图 4-10显示了过采样和欠采样的可视化。
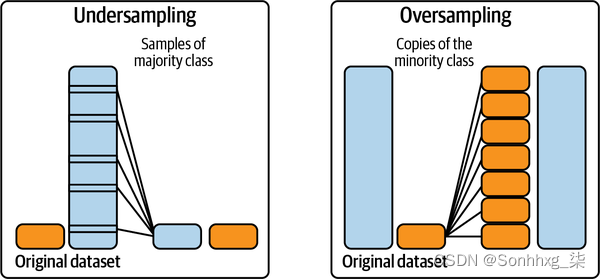
图 4-10。欠采样和过采样如何工作的插图。资料来源:改编自 Rafael Alencar 37的图片
一种流行的低维欠采样方法1976 年开发的数据是 Tomek 链接。38使用这种技术,您可以找到来自相反类别的非常接近的样本对,并删除每对中多数类别的样本。
虽然这使决策边界更加清晰,并且可以说有助于模型更好地学习边界,但它可能会降低模型的鲁棒性,因为模型无法从真实决策边界的细微之处学习。
一种流行的过采样低维数据的方法是 SMOTE(合成少数过采样技术)。39它通过合成少数类的新样本对少数类中现有数据点的凸组合进行采样。40
SMOTE 和 Tomek 链接都只在低维数据中被证明有效。许多复杂的重采样技术,如 Near-Miss 和单边选择41需要计算实例之间或实例与决策边界之间的距离,这对于高维数据或高维特征来说可能是昂贵的或不可行的空间,例如大型神经网络的情况。
当您对训练数据进行重新采样时,切勿根据重新采样的数据评估您的模型,因为这会导致您的模型过度拟合该重新采样的分布。
欠采样存在因删除数据而丢失重要数据的风险。过采样存在以下风险过度拟合训练数据,特别是如果添加的少数类副本是现有数据的副本。已经开发了许多复杂的采样技术来降低这些风险。
一种这样的技术是两阶段学习。42您首先在重新采样的数据上训练您的模型。这个重新采样的数据可以是通过随机对大类进行欠采样,直到每个类只有N个实例。然后,您可以根据原始数据微调您的模型。
另一种技术是动态采样:在训练过程中对表现不佳的类进行过采样,对表现好的类进行欠采样。由 Pouyanfar 等人43介绍,该方法旨在减少模型所具有的内容已经学到了更多它还没有学到的东西。
算法级方法
如果数据级方法减轻通过改变训练数据的分布来挑战类不平衡,算法级方法保持训练数据分布不变,但改变算法以使其对类不平衡更加鲁棒。
由于损失函数(或成本函数)指导学习过程,因此许多算法级方法都涉及对损失函数的调整。关键思想是,如果有两个实例x 1和x 2 ,并且由于对x 1做出错误预测而导致的损失高于x 2,则模型将优先对x 1做出正确预测而不是做出正确预测对x 2的预测。通过给我们关心的训练实例更高的权重,我们可以让模型更专注于学习这些实例。
让L(X;⊖)是实例x对具有参数集的模型造成的损失一世. 模型的损失通常定义为所有实例造成的平均损失。N表示训练样本的总数。

这个损失函数对所有实例造成的损失进行了同等评价,即使对某些实例的错误预测可能比对其他实例的错误预测代价更高。有很多方法可以修改这个成本函数。在本节中,我们将重点关注其中三个,从成本敏感型学习开始。
成本敏感型学习
早在 2001 年,基于这样的洞察力不同类别的错误分类会产生不同的成本,Elkan 提出了对成本敏感的学习,其中修改了个体损失函数以考虑这种不同的成本。44该方法首先使用成本矩阵来指定C ij:如果将i类分类为j类的成本。如果i = j,这是一个正确的分类,成本通常为 0。如果不是,这是一个错误分类。如果将正样本分类为负样本的成本是反之的两倍,那么您可以将C 10设为C 01的两倍。
例如,如果您有两个类,POSITIVE 和 NEGATIVE,则成本矩阵可能如表 4-8所示。
| 实际负面 | 实际积极 | |
|---|---|---|
| 预测负面 | C (0, 0) = C 00 | C (1, 0) = C 10 |
| 预测阳性 | C (0, 1) = C 01 | C (1, 1) = C 11 |
类i的实例x造成的损失将成为实例 x 的所有可能分类的加权平均值。

这个损失函数的问题是你必须手动定义成本矩阵,这对于不同规模的不同任务是不同的。
类平衡损失
一个在不平衡的数据集是它会偏向多数类并对少数类做出错误的预测。如果我们惩罚对少数类别做出错误预测的模型来纠正这种偏见怎么办?
在其 vanilla 形式中,我们可以使每个类的权重与该类中的样本数成反比,以便稀有类具有更高的权重。在以下等式中,N表示训练样本的总数:

类i的实例x造成的损失如下,其中 Loss( x , j ) 是当x被分类为类j时的损失。它可以是交叉熵或任何其他损失函数。
这种损失的更复杂的版本可以考虑现有样本之间的重叠,例如基于有效样本数量的类平衡损失。45
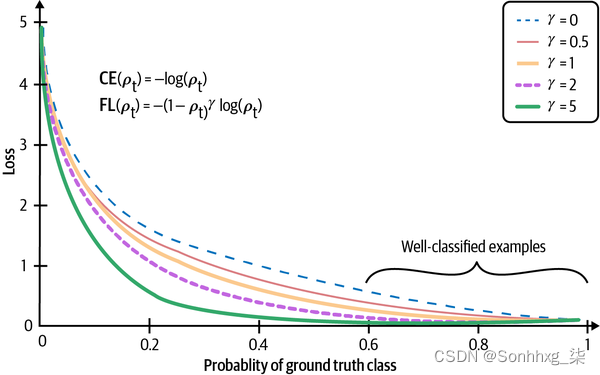
数据增强
数据增强是用于增加训练数据量的一系列技术。传统上,这些技术用于训练数据有限的任务,例如医学成像。然而,在过去的几年里,即使我们有大量数据,它们也被证明是有用的——增强数据可以使我们的模型对噪声甚至对抗性攻击更加鲁棒。
数据增强已成为许多计算机视觉任务中的标准步骤,并且正在进入自然语言处理(NLP)任务。这些技术在很大程度上取决于数据格式,因为图像处理不同于文本处理。在本节中,我们将介绍三种主要类型的数据增强:简单的标签保留转换;扰动,这是“添加噪音”的术语;和数据合成。在每种类型中,我们都会介绍计算机视觉和 NLP 的示例。
简单的标签保留转换
在计算机视觉中,最简单的数据增强技术是在保留其标签的同时随机修改图像。您可以通过裁剪、翻转、旋转、反转(水平或垂直)、擦除图像的一部分等来修改图像。这是有道理的,因为狗的旋转图像仍然是狗。PyTorch、TensorFlow 和 Keras 等常见的 ML 框架都支持图像增强。根据 Krizhevsky 等人的说法。在他们传奇的 AlexNet 论文中,“转换后的图像是在 CPU 上的 Python 代码中生成的,而 GPU 正在对前一批图像进行训练。因此,这些数据增强方案实际上在计算上是免费的。” 48
在 NLP 中,你可以随机用相似词替换一个词,假设这种替换不会改变句子的含义或情感,如表 4-9所示。可以通过同义词词典或通过在词嵌入空间中找到嵌入彼此接近的词来找到相似词。
| 原句 | 见到你真开心。 |
| 生成的句子 | 我很高兴见到你。 我很高兴见到你们。 我很高兴见到你。 |
这种类型的数据增强是一种将训练数据翻倍或翻倍的快速方法。
扰动
扰动也是一种标签保留操作,但因为有时它被用来欺骗模型做出错误的预测,所以我认为它应该有自己的部分。
一般来说,神经网络对噪声很敏感。在计算机视觉的情况下,这意味着向图像添加少量噪声会导致神经网络对其进行错误分类。苏等人。结果表明,Kaggle CIFAR-10 测试数据集中 67.97% 的自然图像和 16.04% 的 ImageNet 测试图像可以通过仅更改一个像素而被错误分类(见图 4-12)。49

图 4-12。改变一个像素会导致神经网络做出错误的预测。使用的三个模型是 AllConv、NiN 和 VGG。这些模型制作的原始标签高于更改一个像素后制作的标签。资料来源:苏等人。50
使用欺骗性数据来欺骗神经网络做出错误的预测被称为对抗性攻击。向样本添加噪声是创建对抗样本的常用技术。随着图像分辨率的增加,对抗性攻击的成功尤其被夸大。
将噪声样本添加到训练数据可以帮助模型识别其学习决策边界中的弱点并提高其性能。51噪声样本可以通过添加随机噪声或搜索策略来创建。Moosavi-Dezfooli 等人。提出了一种称为 DeepFool 的算法,该算法以高置信度找到导致错误分类所需的最小可能噪声注入。52这种类型的增强称为对抗性增强。53
对抗性增强在 NLP 中不太常见(带有随机添加像素的熊的图像仍然看起来像一只熊,但在随机句子中添加随机字符可能会使其变得乱码),但已使用扰动来使模型更加健壮。最值得注意的例子之一是 BERT,其中模型随机选择每个序列中所有标记的 15%,并选择用随机词替换 10% 的所选标记。例如,给定句子“My dog is hairy”,模型随机将“hairy”替换为“apple”,句子变为“My dog is apple”。因此,所有标记中的 1.5% 可能会导致无意义的含义。他们的消融研究表明,随机替换的一小部分给他们的模型带来了小的性能提升。54
在第 6 章中,我们将讨论如何使用扰动,而不仅仅是改进模型的性能,也可作为评价其性能的一种方式。
数据综合
由于收集数据既昂贵又缓慢,由于存在许多潜在的隐私问题,如果我们能够完全避开它并使用合成数据训练我们的模型,那将是一个梦想。尽管我们还远远不能合成所有的训练数据,但还是可以合成一些训练数据来提高模型的性能。
在 NLP 中,模板是引导模型的一种廉价方式。我使用的一个团队使用模板为他们的会话 AI(聊天机器人)引导训练数据。模板可能类似于:“在 [LOCATION] [NUMBER] 英里范围内给我找一家 [CUISINE] 餐厅”(见表 4-10)。通过列出所有可能的美食、合理的数字(您可能永远不想搜索 1,000 英里以外的餐馆)和每个城市的位置(家庭、办公室、地标、确切地址),您可以从模板生成数千个训练查询.
| 模板 | Find me a [CUISINE] restaurant within [NUMBER] miles of [LOCATION]. |
| 生成的查询 | Find me a Vietnamese restaurant within 2 miles of my office. Find me a Thai restaurant within 5 miles of my home. Find me a Mexican restaurant within 3 miles of Google headquarters. |
在计算机视觉中,合成新数据的一种直接方法是将现有示例与离散标签相结合以生成连续标签。考虑使用两个可能的标签对图像进行分类的任务:DOG(编码为 0)和 CAT(编码为 1)。从标签 DOG 的示例x 1和标签 CAT 的示例x 2,您可以生成x ' 例如:
x ' 的标签是x 1和x 2的标签的组合:r×0+(1-r)×1. 这种方法称为混合。作者表明,mixup 提高了模型的泛化能力,减少了它们对损坏标签的记忆,提高了它们对对抗样本的鲁棒性,并稳定了生成对抗网络的训练。55
使用神经网络合成训练数据是一种令人兴奋的方法,正在积极研究但尚未在生产中流行。桑福特等人。表明通过将使用 CycleGAN 生成的图像添加到其原始训练数据中,他们能够显着提高模型在计算机断层扫描 (CT) 分割任务上的性能。56
如果您有兴趣了解有关计算机视觉数据增强的更多信息,“A Survey on Image Data Augmentation for Deep Learning”(Shorten 和 Khoshgoftaar 2019)是全面审查。
概括
训练数据仍然是现代机器学习算法的基础。不管你的算法多么聪明,如果你的训练数据不好,你的算法就不能很好地执行。值得投入时间和精力来管理和创建训练数据,使您的算法能够学习一些有意义的东西。
在本章中,我们讨论了创建训练数据的多个步骤。我们首先介绍了不同的抽样方法,包括非概率抽样和随机抽样,它们可以帮助我们为我们的问题抽取正确的数据。
当今使用的大多数 ML 算法都是有监督的 ML 算法,因此获取标签是创建训练数据不可或缺的一部分。许多任务,例如交付时间估计或推荐系统,都有自然标签。自然标签通常是延迟的,从提供预测到提供反馈之间的时间是反馈循环长度。具有自然标签的任务在行业中相当普遍,这可能意味着公司更喜欢从具有自然标签的任务开始,而不是没有自然标签的任务。
对于没有自然标签的任务,公司倾向于依靠人工注释者来注释他们的数据。然而,手工标记有许多缺点。例如,手工标签可能既昂贵又缓慢。为了解决手标签的缺乏,我们讨论了包括弱监督、半监督、迁移学习和主动学习在内的替代方案。
ML 算法在数据分布更加平衡的情况下运行良好,而在类严重不平衡的情况下运行良好。不幸的是,阶级不平衡的问题是现实世界中的常态。在下一节中,我们讨论了为什么类不平衡使 ML 算法难以学习。我们还讨论了处理类别不平衡的不同技术,从选择正确的指标到重新采样数据,再到修改损失函数以鼓励模型关注某些样本。
我们在本章结束时讨论了数据增强技术,这些技术可用于提高模型在计算机视觉和 NLP 任务中的性能和泛化能力。
获得训练数据后,您将希望从中提取特征来训练您的 ML 模型,我们将在下一章中介绍。



















 258
258

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











