







论文链接
https://arxiv.org/abs/1905.00941
动机
目前的车道检测方法使用CNN预测车道线和车道标志,这种监督训练使得CNN非常依赖数据标签,但是这类车道的数据标签在一些城市很难得到。而且,由于道路环境中的标签类别比例不平衡,传统监督方法更易检测粗车道线。同时,行驶障碍物定位和可行驶区域检测也是非常重要的。但是这类检测在应用时需要降低计算开销。最后,车道定位无法给出行驶方向信息。
贡献
本文提出的算法使用单个CNN用于检测属于各个车道区域的像素。同时也增加一个开销很小的分类分支,用于预测道路场景类型,从而能够知道可行驶的车道。本文将该算法使用ROS框架实现,从而实现较低计算开销的多个CNN的数据融合
算法

上分支:采用encoder-decoder的结构进行语义分割,区分ego lane和其他车道,输出ego lane和其他车道区域的语义分割图
下分支:对道路场景进行分类,通过分类可知是否存在逆向车道,输出场景类别
网络结构:采用ERFNet网络结构

训练损失函数:语义分割和场景分类训练都使用了带权重的交叉熵损失函数:
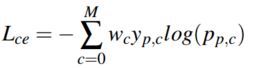
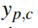 是标签值(0或1),
是标签值(0或1),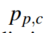 是预测为第c类的概率值,权重
是预测为第c类的概率值,权重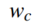 的定义为:
的定义为: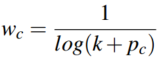 这里我的理解是
这里我的理解是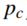 应该就是
应该就是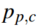
k是常量1.02。最后的综合loss为:
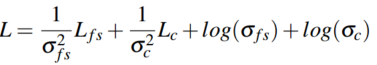
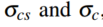 用于量化预测的不确定性,是可学习的参数。
用于量化预测的不确定性,是可学习的参数。
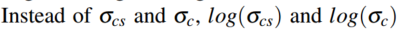 是为了使得训练更加稳定。
是为了使得训练更加稳定。
对语义分割图的后处理:先对语义分割图进行下采样,从而加速后续后处理的速度。再使用DBSCAN算法,对属于ego lane的像素和属于其他车道区域的像素进行聚类,得到不同车道的像素点聚类的凸包。这可以首先确定eog lane可行驶区域。对于车道之间重叠区域,本文直接将重叠区域从ego lane区域删去,尽可能减低侵犯其他车道区域的可能性。最后通过比较各个聚类中心点的x坐标和ego lane可行驶区域的聚类中心x坐标对ego lane两边的可行驶区域进行区分。
实验
数据集
使用BDD100K数据集,将里面的场景分成4个类:Highway scenarios, Residential scenarios, Others scenarios, City Street scenarios,用于预测道路场景
评价指标
车道语义分割:
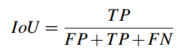 ,场景分类:Accuracy,预测速度:FPS,计算量:GMAC(一个 GMACS等于每秒10亿 (=10^9) 次的定点乘累加运算)
,场景分类:Accuracy,预测速度:FPS,计算量:GMAC(一个 GMACS等于每秒10亿 (=10^9) 次的定点乘累加运算)
结果

优缺点
优点:
- 能够进行同时进行车道可行驶区域检测和道路场景分类,并使用ROS框架实现
- 与其他方法相比,本文的算法能够使用较少的计算量实现较好的语义分割效果,并达到22fps以上的检测速度
- 在训练的损失函数设计上使用了带权重的损失函数以及用可学习的变量用于量化预测的不确定性,提升训练效果
缺点:
- 忽略了车道线信息,无法检测车道线的虚实类型,也就无法知道是否可以变道
- 检测逆向车道只能依赖于道路场景,对于检测逆向车道的效果不佳
- 道路场景分类类别过少
反思
- 是否可以将车道线检测也结合进来,实现车道线分类,用于判断是否可以变道?
- 能否加入更多道路场景类别以及天气分类功能?















 1890
1890











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









