







摘要
障碍物检测是安全高效自动驾驶的关键。为此,我们提出了NVRadarNet,一种深度神经网络(DNN),利用汽车雷达传感器检测动态障碍和自由空间。该网络利用来自多个雷达传感器的时间累积数据来检测动态障碍物,并在自上而下的鸟瞰视图(BEV)中计算它们的方向。该网络还回归可驾驶的自由空间,以检测未分类的障碍。我们的DNN是第一个利用稀疏雷达信号,仅从雷达数据实时执行障碍物和自由空间检测的同类产品。该网络已成功应用于真实自动驾驶场景下的自动驾驶车辆感知。该网络运行速度比在嵌入式GPU上的实时速度快,并显示出良好的跨地理区域泛化能力。
1.介绍
检测动态和固定障碍物(如汽车、卡车、行人、自行车、危险)的能力对自动驾驶汽车至关重要。这在具有大量遮挡和各种形状的复杂场景的半城市和城市环境中尤其重要。
以前的感知方法严重依赖于利用摄像机[1][2][3]或激光雷达[4][5][6][7]来检测障碍物。这些方法有一些缺点:在严重闭塞的情况下是不可靠的,传感器可能非常昂贵,在不利的天气条件下[8]或在夜间是不可靠的。传统的基于雷达的障碍物检测方法在检测具有良好反射特性的移动物体时效果良好,但在估计物体尺寸和方向时往往存在困难,在检测静止物体或雷达反射率差的物体时往往完全失败。
在本文中,我们提出了一个深度神经网络(DNN),它可以检测移动和静止的障碍物,计算它们的方向和大小,并从雷达数据中检测可驾驶的自由空间。我们在高速公路和城市场景中采用自上而下的鸟瞰(BEV),同时使用现成的汽车雷达。我们的方法仅依赖于雷达峰值检测[9][10],因为汽车雷达固件只提供这些数据。相比之下,其他方法[11][12]需要对原始雷达数据立方体横截面进行昂贵的快速傅里叶变换操作,这在大多数商用汽车传感器中是不可用的。
我们的深度学习方法能够准确地区分静止的障碍物(如汽车)和静止的背景噪声。当你在杂乱的城市环境中导航时,这一点很重要。此外,我们的方法允许我们回归这些障碍的维度和方向,这是经典方法不能提供的。我们的DNN甚至可以探测到像行人这样反射率差的障碍物。最后,我们的方法提供了一个占用概率图来标记未分类的障碍和回归可驾驶的自由空间。
我们已经在运行NVIDIA DRIVE AGX嵌入式GPU的车辆上测试了我们的NVRadarNet DNN。我们的DNN运行速度比实时快,端到端为1.5毫秒,并为计划者提供足够的时间安全反应。
我们的贡献如下:
•NVRadarNet:第一个多级别深度神经网络,可以端到端检测动态和静止的目标,而无需在自顶向下的鸟瞰视图(BEV)中进行后处理,只使用来自汽车雷达的峰值检测;
•一种新型半监督驾驶自由空间检测方法,仅使用雷达峰值检测;
•在嵌入式GPU上端到端运行速度比实时快1.5毫秒的DNN架构。
2.之前的工作
障碍物检测。快速高效的障碍物感知是自动驾驶汽车的核心组成部分。车载雷达传感器提供了一种经济高效的方式,以获取丰富的三维定位和速度信息,并广泛应用于大多数现代汽车。最近的几篇论文研究了密集雷达数据集的使用,以执行障碍物检测[11][12]。然而,这些方法需要较高的输入/输出带宽来获取如此丰富的数据。这使得它们不适合真正的自动驾驶汽车。因此,在汽车雷达应用中,大多数经典的方法都利用来自数据立方体的后处理峰值检测,以便执行分类和占用网格检测[13][14][15]。其他人意识到,雷达峰值检测可以被视为稀疏的3D点云,因此可以与3D激光雷达点一起用于传感器融合,方法类似于LiDAR DNNs[4][16][17][5][18]。有尝试通过融合雷达增强相机三维障碍物检测,比如[19]。
自由空间探测。[20]和[21]尝试了基于雷达的可行驶自由空间估计。
我们的DNN对动态和静态障碍物进行多类检测,并单独使用雷达峰值检测分割可驾驶自由空间。我们的DNN架构是轻量级的,在嵌入式GPU (NVIDIA DRIVE AGX)上端到端运行速度比实时快1.5毫秒。它已经被证明在现实驾驶中是强大的,并在10000多公里的高速公路和城市道路上进行了测试,作为我们自动堆栈的一部分。到目前为止,我们还不知道有哪种仅使用DNN的雷达峰值检测能够执行所有这些任务,并在自动驾驶汽车上高效运行。
3.方法
A:输入生成
输入到我们的网络的是一个自顶向下的BEV正投影,它是在我们的自我飞行器周围累积的雷达探测峰值,它被放置在这个顶部向下的鸟瞰图(BEV)的中心,正面朝右。
为了计算这个输入,我们首先累积车辆上所有雷达传感器(覆盖360度视野的8个雷达)的雷达峰值检测,然后将它们转换到我们的自我车辆钻机坐标系统。为了增加信号的密度,我们还将这些峰值检测时间累积在0.5秒以上。每个数据点都有一个相对时间戳来表示它的年龄,类似于[16]。接下来,我们对累积的检测进行自我运动补偿,直到最新的已知车辆位置。我们利用车辆的已知自我运动传播旧点,以估计它们在DNN推断(当前时间)时的位置。
接下来,我们使用所需的空间量化将每个累积的检测投射到一个自上而下的向下的BEV网格,为我们的DNN创建一个输入张量。我们将输入分辨率设置为800×800像素,每个方向±100米的范围,结果是每像素25厘米的分辨率。每个有效的BEV像素(带数据)在其深度通道中获得一组特征,通过对降落在该像素中的雷达探测的原始信号特征进行平均计算。我们对时间t的最终输入是一个张量It∈R(h×w×5),其中h = 800, w = 800为自上而下视图的高和宽。深度通道中的5个雷达特征是:多普勒、仰角、雷达截面(RCS)、方位角和相对探测时间戳的平均值。我们使用硬件规范提供的最大值和最小值将这些值归一化到[0,1]范围内,以便训练稳定性。得到的张量被用作网络的输入。
B:标签传递
我们使用基于lidar的人类注释边界框标签作为训练雷达DNN的地面真值。这些标签是为我们训练雷达DNN的同一场景的激光雷达数据创建的。考虑到雷达信号是多么稀疏,即使在顶部向下的BEV视图中,人类也几乎不可能单独使用雷达点来区分车辆。因此,我们依靠LiDAR来标记训练数据。我们捕获不同频率的激光雷达和雷达数据,并选择最接近的数据进行处理。然后我们创建一个自顶向下的激光雷达场景的BEV投影,供人类用边界框标签注释对象和用折线自由空间。对于每一个标记的LiDAR BEV帧,我们通过上述预处理方法计算最接近的雷达BEV累积图像,然后将标签转移到RADAR自上而下视图。我们进一步清理地面真相,删除任何包含少于4个雷达检测的车辆标签,经验证明这可以提高网络精度。最后,我们删除任何RCS低于−40 dBm的检测,因为我们根据经验确定它们引入的噪声比信号更多。如图1所示。
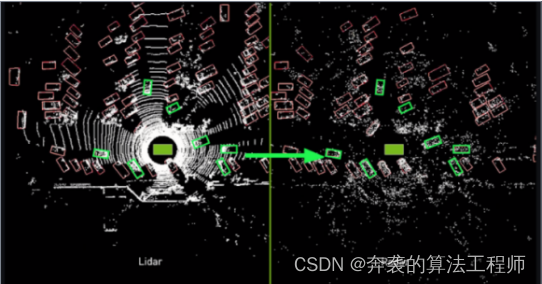
图1从LiDAR域向RADAR域传递汽车包围框标签
C:自由空间标签生成
自由空间目标是使用原始LiDAR点云生成的。首先,对点云进行预处理,通过对相邻激光雷达扫描线的表面坡度角估计,识别并去除属于可行驶表面本身的点;然后,我们覆盖手动获得的激光雷达空闲空间标签,以进一步清理这个估计。接下来,从自我飞行器的原点向各个角度追踪一组射线,使我们能够推断出哪些区域是:
•被观察和自由。
•观察和占据。
•没注意到。
•部分观察。
最后,我们将现有的3D障碍标签覆盖在自动生成的占用率上。我们明确地将障碍标记为观察到的和已占据的。见图2。

图2 自由空间目标的视觉表现:被观察和自由的为黑色,被观察和占用的为白色,未被观察的为浅灰色,部分被观察的为深灰色
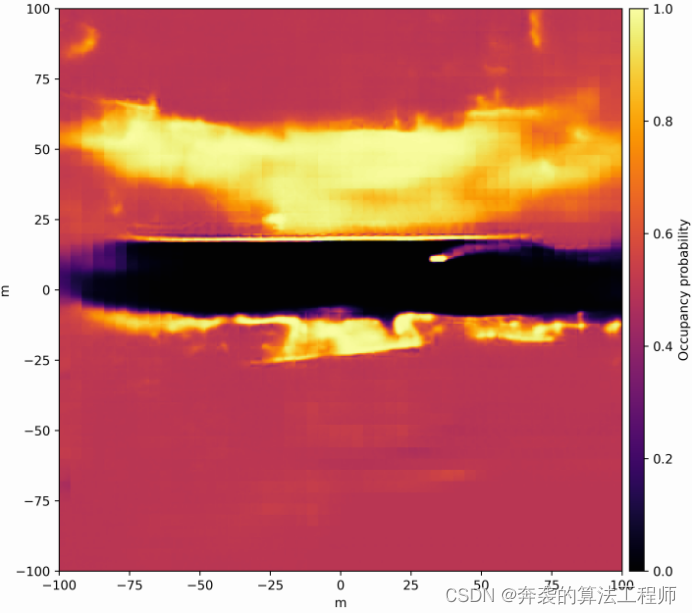
图3推断密集的居住概率图,显示概率从深色的低到红色到黄色的高(最高)梯度。
D:数据集
我们的模型在一个不同的内部数据集上进行训练,该数据集包含超过300k的训练帧和超过70k的验证帧,这些帧来自多个地理区域数百小时的驾驶采样。该数据集包括城市和公路数据的组合,并包含同步激光雷达、雷达和IMU读数。这些标签是人为标注的,包括车辆、骑自行车的人、行人和可驾驶的自由空间。
E:网络结构
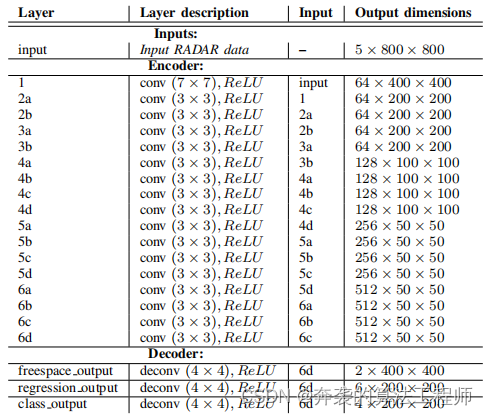
我们使用类似于特征金字塔网络[22]的DNN架构。我们的DNN包括编码器和解码器组件,以及几个用于预测不同的输出/放期权的头。高层结构见图4,具体见表1。
我们的编码器从一个具有64个滤波器、步幅2和7 × 7核的2D卷积层开始。接下来是4个块,每个块有4层,每个块增加两个过滤器的数量,同时将分辨率分成一半。块中的每一层都包含一个具有批处理归一化和ReLU激活的2D卷积。
该译码器由一个步长为4的二维转置卷积和每个头的4 × 4核组成。我们还试验了使用两个转置的二维卷积,中间有一个跳跃连接。得到的输出张量是输入的空间分辨率的1/4。
我们在网络中使用以下头部:
•类分割头预测多通道张量,每个类一个通道。每个值都包含一个置信度,该置信度指示给定像素属于与其通道对应的类。
•实例回归头使用每个预测像素的nr (nr = 6)通道的信息预测对象的定向边界框。nr元素向量包含:[δx, δy, w0, l0, sin θ, cos θ],其中(δx, δy)指向对应对象的质心,w0 × l0为对象的维数,θ为自顶向下BEV中的方位。
•反传感器模型头(ISM)计算每个网格单元[20]的占用概率图。

图4网络体系结构。我们的网络使用CNN作为带有跳跃式连接的编码器和解码器。该网络有三个头:分类头(产生检测概率),形状回归头(产生包围盒参数)和自由空间分割头。
表1 NVRadarNet的网络结构
F:损失函数
我们的损失包括分类头的标准交叉熵损失,对少数类的权重强调较大,L1损失用于边界盒回归,以及反传感器模型损失用于自由空间检测[20]。
我们根据[23]中描述的方法,通过将每个任务的权重建模为同方差任务的依赖不确定性,使用贝叶斯学习权重将这些损失组合在一起。这种方法允许我们有效地联合训练这三个不同的任务,而不影响整个模型的准确性。
总的损失函数定义为:
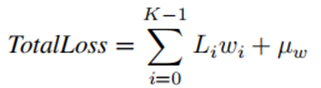 (1)
(1)
其中K为任务/人头数,Li为任务i的损失,![]() , δi为每个任务的学习对数方差参数,而uw为wi权重的平均值。
, δi为每个任务的学习对数方差参数,而uw为wi权重的平均值。
G:端到端障碍检测
为了避免昂贵的非最大抑制(NMS)或后处理(例如DBSCAN)的聚类,我们采用了端到端方法,通过对每个障碍的单个像素进行分类,灵感来自OneNet[24]。
首先,我们计算回归头的L1损失和分类头的像素级分类损失。接下来,对于每个目标障碍,我们在(ClassWeight * ClassLossPerPixel) + RegressionLossPerPixel之间选择总损失最小的前景像素。然后选择这个像素进行最终的损失计算,而忽略其余的前景像素。然后利用硬负挖掘有选择地利用来自背景像素的损失。最后,我们通过将交叉熵损失总量除以在上述过程中选择的正像素数量来进行批归一化。只计算所选正像素的回归损失。
在推断时,我们简单地在每个类的分类头中选择高于某个阈值的所有候选像素。障碍维度直接从每个对应阈值候选的回归头中选取。
通过使用这种技术,我们的网络可以直接输出最终的障碍,而不需要昂贵的后处理。
H:将ISM头输出转换为径向距离图
自动驾驶汽车的应用通常通过其边界轮廓来表示可驾驶的自由空间区域。在本节中,如果需要,我们将描述如何将边界等高线转换为径向距离图(RDM)。在自驾车的自顶向下BEV视图中,RDM为自驾车上的参考点![]() 与可驾驶自由空间边界之间的距离df指定了一组角方向φf。为了计算RDM,我们首先将密集占用概率图(DNN输出)重新采样到以参考点为中心的极坐标系中。通过采用最近邻插值模式,再采样过程可以用索引操作来表示。这将极性表示的每个像素(φf, df)的值指定为预测的密集占用概率图的单个像素的值。由于这个映射只依赖于占用地图的尺寸和参考点
与可驾驶自由空间边界之间的距离df指定了一组角方向φf。为了计算RDM,我们首先将密集占用概率图(DNN输出)重新采样到以参考点为中心的极坐标系中。通过采用最近邻插值模式,再采样过程可以用索引操作来表示。这将极性表示的每个像素(φf, df)的值指定为预测的密集占用概率图的单个像素的值。由于这个映射只依赖于占用地图的尺寸和参考点![]() 的位置,所有所需的索引都可以离线计算并存储在查找表中。图5为占用概率图。图3为极坐标下的重采样。重新采样后,每个角方向φf的距离df通过沿着每个角轴找到第一个像素来确定,其中占用概率达到某个阈值pocc。图6显示了该程序从图3所示的密集占用概率图推导出的可驾驶自由空间边界的RDM表示。
的位置,所有所需的索引都可以离线计算并存储在查找表中。图5为占用概率图。图3为极坐标下的重采样。重新采样后,每个角方向φf的距离df通过沿着每个角轴找到第一个像素来确定,其中占用概率达到某个阈值pocc。图6显示了该程序从图3所示的密集占用概率图推导出的可驾驶自由空间边界的RDM表示。
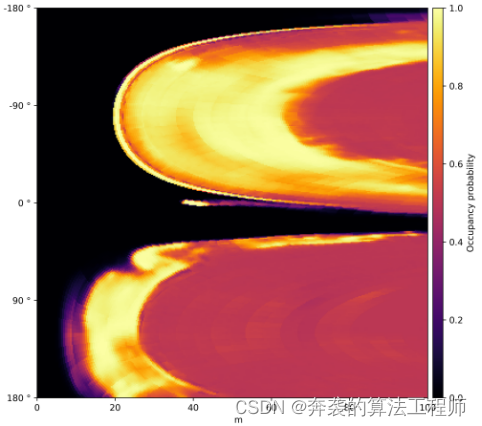
图5预测的密集占用地图重新采样到以参考点为中心的极坐标系![]() 。从红(低)到黄(高)表示概率。
。从红(低)到黄(高)表示概率。
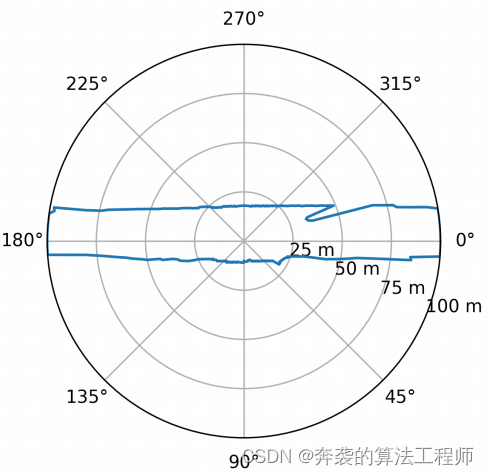
图6从预测的密集占用概率图中提取可驾驶自由空间边界的径向距离图表示。
4.实验
A.内部数据集实验
目前,专门用于基于雷达的障碍物和自由空间检测的数据集、基准和已发布的dnn都有限,这给评估带来了困难。参见表二,列出了可用的方法及其特性。最接近的工作[17][5][19][18]使用传感器融合,不公开只分享雷达结果。因此,据我们所知,我们正在为障碍物检测、分类和仅使用雷达峰值的自由空间回归设置基线。由于雷达信号的稀疏性,探测行人和骑自行车的人是一个很大的挑战。
我们在NVIDIA的RADAR数据集和nuScenes公共数据集上评估了我们的DNN。我们还尽可能地将我们的DNN与其他已发表的作品进行比较,并在此部分列出所有结果。
对于我们内部的NVIDIA雷达数据集,我们使用III-D节中提到的测试数据进行评估。需要注意的是,即使过滤掉包含太少雷达峰值检测的地面真相边界框(如第III-B节所述),我们最终仍然会得到嘈杂的地面真相标签。例如,在许多情况下,车辆被其他车辆遮挡,因此人类标签人员无法仅从激光雷达数据创建良好的地面真相。在这种情况下,RADAR仍然产生有效的回报,一些障碍被我们的DNN正确分类,但由于地面真相的缺点,在评估时被标记为假阳性。这降低了我们的精确度。此外,激光雷达传感器安装在车辆(车顶)上的位置高于雷达传感器(缓冲器),因此一些障碍可能被激光雷达看到,雷达能见度有限,导致雷达数据和标签有噪声。这会导致假阴性,降低我们的记忆力。
我们对目标检测任务的结果见表III、IV。空闲空间检测任务的度量(表V)分别针对空闲空间区域和空闲空间RDM计算。自由空间区域由占用概率po < 0.4定义。
B.NuScenes数据集表现
我们在公共nuScenes数据集[25]上进一步评估了我们的方法。该数据集包含来自1个激光雷达和5个雷达的传感器数据。然而,该数据集中的传感器来自较老的一代,因此很难进行直接比较。用于nuScenes数据收集的激光雷达传感器只包含32个光束,而在我们的内部数据集中则包含128个光束。这个数据集中额外的稀疏性降低了我们自动生成的空闲空间目标的质量。同样,与我们在内部数据集中使用的新一代大陆ARS430雷达传感器相比,nuScenes数据集中使用的大陆ARS 408-21雷达产生的探测量明显更少。尽管如此,我们展示了令人尊敬的结果,特别是在近距离。详情见表六、表七及表八。
我们进一步将我们的NVRadarNet DNN空闲空间检测精度与[21]中发表的方法进行了比较,该方法也在nuScenes数据集上给出了结果。然而,这种方法操作在一个网格上,覆盖自我车辆前面的区域直到86米,每边10米,不像我们的方法,不后退或分类障碍。对于这一比较,我们在相同的图像区域上进行评估,同时将预测的占用概率转换为以下三个类别:已占用、空闲和未观察。
•占用:pocc > 0.65
•免费:pocc < 0.35
•未观察到:0.35 <= pocc <= 0.65
结果载于表九。我们的DNN在已占用空间回归方面优于其他方法(粗体显示的最佳结果),在其他任务上也表现相似。
C.NVRadarNet深度神经网络推理
我们的NVRadarNet DNN可以在混合精度模式下使用INT8量化训练而不损失任何精度。我们使用NVIDIA TensorRT导出网络,并在自动驾驶汽车中使用的NVIDIA DRIVE AGX的嵌入式GPU上计时。我们的DNN能够实现所有三个头部的1.5毫秒端到端推断。我们处理所有的环绕雷达,执行障碍检测和自由空间分割比实时嵌入式GPU快得多。在文献中很难找到其他的RADAR深度神经网络推断时间进行直接比较。我们只发现[11]慢了一个数量级。
表2 相关雷达探测方法。我们的方法(粗体部分)只使用雷达数据,支持物体和自由空间检测,并提供公共结果。
表3我们的DNN在内部NVIDIA数据集上的障碍物检测精度,按类别和范围排序。
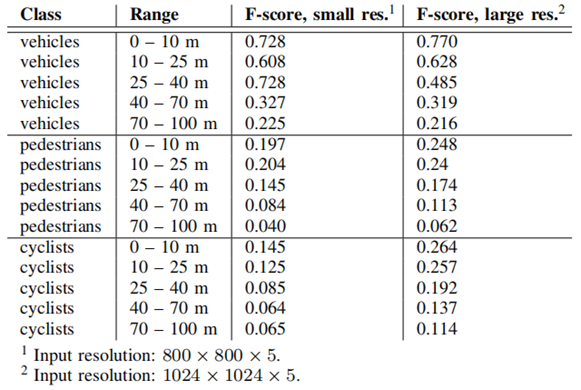
表4 我们的DNN在内部NVIDIA数据集上的障碍物检测精度,按类别排序。

表5 我们的DNN在内部NVIDIA数据集上的自由空间回归精度。

表6 我们的DNN在nuScenes数据集上的障碍物检测精度,按类别和范围排序。
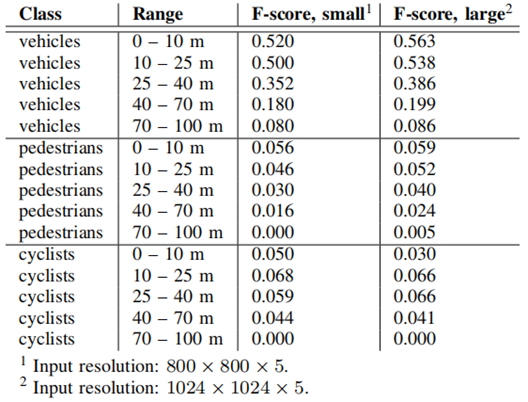
表7 我们的DNN在nuScenes数据集上的障碍物检测精度,按类别排序。

表8 我们的DNN在nuScenes数据集上的自由空间回归精度。

表9 nuScenes数据集上与occuancynet[21]的比较。粗体显示效果最好。

5.结论
在这项工作中,我们提出了NVRadarNet深度神经网络,一个实时的深度神经网络,用于从普通汽车雷达提供的原始雷达数据中检测障碍物和可驾驶自由空间。我们在内部NVIDIA数据集和公共nuScenes数据集上对DNN进行了基准测试,并提供了准确性结果。在NVIDIA DRIVE AGX的嵌入式GPU上,我们的DNN运行速度比实时更快,端到端推理时间为1.5毫秒。到目前为止,我们还没有发现任何其他雷达网络可以同时执行障碍物检测和自由空间回归,同时在汽车嵌入式计算机上运行得比实时更快。
致谢
我们要感谢Sriya Sarathy, Tilman Wekel和Stan Birchfield的技术贡献。我们还要感谢David Nister, Sangmin Oh和Minwoo Park对我们的支持。
















 1279
1279











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











