







在训练神经网络模型的时候需要使用到优化算法,最终我们都是通过求解代价函数的最优化问题来求解模型的参数。有的时候,训练一个神经网络模型可能需要几百上千台机器同时训练几个月,通过使用优化算法可以节省训练的时间加快模型的收敛。本篇文章主要介绍一下常用的优化算法
- 梯度下降算法
- 指数加权平均算法
- 动量梯度下降
- RMSprop算法
- Adam优化算法
常用的优化算法在面试的时候也会经常被问到。
一、梯度下降算法
在训练模型之前会先定义一个代价函数,然后通过不停的迭代训练数据利用梯度下降算法来减少每次迭代的误差,从而使得代价函数最小化。梯度下降算法主要包括三种,随机梯度下降、batch梯度下降、mini-batch梯度下降。最常用的是mini-batch梯度下降算法。
- 随机梯度下降
随机梯度下降算法是指在训练模型的时候,每次迭代只从训练数据中随机抽取一个数据来计算梯度更新模型的参数。随机梯度下降算法永远无法收敛,容易受到噪声的干扰,训练时间长,代价函数最终会围绕全局最小值或者局部极小值震荡。 - batch梯度下降
batch梯度下降算法是指在训练模型的时候,每次迭代时使用所有的训练数据来计算梯度更新模型的参数。batch梯度下降算法适用于小数据集的训练,对于大数据集(大于2000)不太适应,因为每次训练的时候都要使用所有的训练数据,会导致需要消耗大量的内存,增加电脑的计算量,计算时间长。batch梯度下降不容易受到噪声数据的干扰,在迭代的时候能够保证向全局最小值或局部极小值的方向进行收敛。
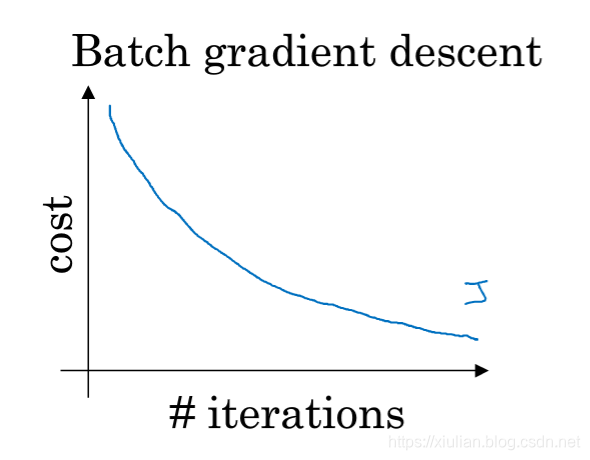
- mini-batch梯度下降
mini-batch梯度下降算法是指在训练模型的时候,每次迭代时会使用一个mini-batch数据来计算梯度更新模型的参数,这个mini-batch通常取64、128、256、512,通常采用2^n作为一个mini-batch,符合电脑的内存结构在一定程度上可以加快计算机的计算速度,从而减少训练的时间。mini-batch梯度下降算法是最常用的梯度下降算法,mini-batch对计算机的内存要求不高,收敛速度相对较快,在迭代的时候不能保证每次迭代都像全局最小值进行收敛,但是整体的趋势是向全局最小值进行收敛的。当mini-batch取1时,就变成了随机梯度下降算法,当mini-batch的大小为整个训练数据集的大小时就变成了batch梯度下降。
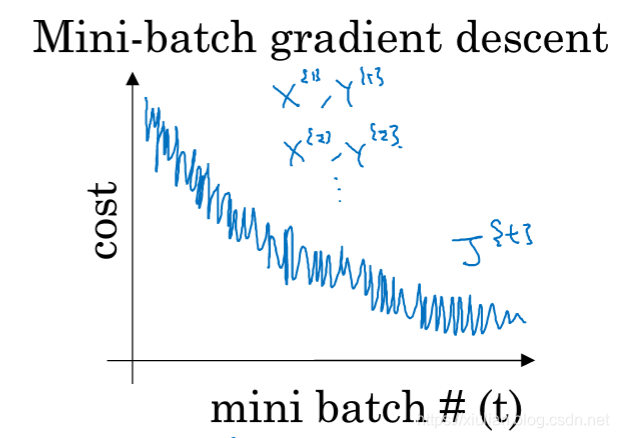
二、指数加权平均值
指数加权平均值,也被称为移动平均值,从名字可以看出来它其实也是一种求平均值的算法,在后面介绍动量、RMSProp和Adam的时候都需要用到它。
- 指数加权平均值计算方法
公式: v n = β ∗ v n − 1 + ( 1 − β ) ∗ θ n v_{n}=\beta*v_{n-1}+(1-\beta)*\theta_{n} vn=β∗vn−1+(1−β)∗θn,其中 β \beta β指的是系数通常取0.9, v n v_{n} vn表示的是当前的指数加权平均值, θ \theta θ表示的是当前的值,下面用一个例子来详细介绍一下指数加权平均值的计算:
我们有一组网站的访问量数据:

其中 θ \theta θ表示的是每天的访问量(万),下面我们来计算一下指数加权平均值,其中 β \beta β取0.9
v 0 v_{0} v0=0
v 1 v_{1} v1= β ∗ v 0 \beta*v_{0} β∗v0+ ( 1 − β ) ∗ θ 1 (1-\beta)*\theta_{1} (1−β)∗θ1=0.9 * 0+ 0.1 * 5=0.5
v 2 v_{2} v2= β ∗ v 1 \beta*v_{1} β∗v1+ ( 1 − β ) ∗ θ 2 (1-\beta)*\theta_{2} (1−β)∗θ2=0.9 * 0.5+ 0.1 * 6=1.05 -
β
\beta
β系数对于加权平均值的影响
指数加权平均值的计算公式: v n = β ∗ v n − 1 + ( 1 − β ) ∗ θ n v_{n}=\beta*v_{n-1}+(1-\beta)*\theta_{n} vn=β∗vn−1+(1−β)∗θn
从公式可以看出,当 β \beta β越大时结果与上一时刻的指数加权平均值 v n − 1 v_{n-1} vn−1的相关性越大,与当前时刻 θ n \theta_{n} θn相关性越小,导致的结果就是指数加权平均值无法更好的反映当前的变化趋势,可能会导致曲线右移,曲线更平滑。如果当 β \beta β越小时,指数加权平均值能够及时的反映出当前的变化趋势,但是曲线的变化幅度会比较大。如下图所示
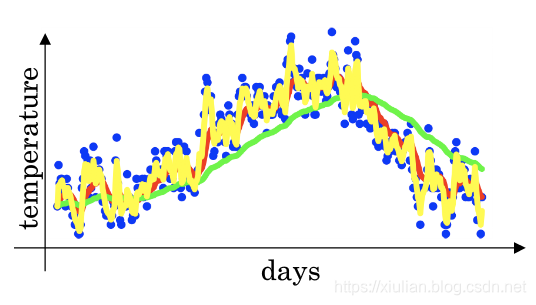
上图中,横轴表示的是天数,纵轴表示的是温度。通过上图可以发现,其中红色曲线的 β \beta β为0.9,黄色曲线的 β \beta β小于0.9,绿色曲线的 β \beta β大于0.9,当 β \beta β越来越大时,指数加权平均值曲线会慢慢的向右移动,反映温度的变化会延时,曲线会越来平滑。
指数加权平均算法相对于直接求平均值算法的优势在于,指数加权平均值只需要极小的空间就可以计算出近似平均值,而直接使用平均值算法需要保存以前所有的数据,相对而言指数加权平均值的计算出来平均值的精度没有那么高,它是牺牲了一定的精度来换取空间和速度的。由于它在空间上具有极大的优势,所以应用范围还是很广泛。 - 为什么叫指数加权平均值
v n = β ∗ v n − 1 + ( 1 − β ) ∗ θ n = β ∗ ( β ∗ v n − 2 + ( 1 − β ) ∗ θ n − 1 ) + ( 1 − β ) ∗ θ n = β 2 ∗ v n − 2 + β ∗ ( 1 − β ) ∗ θ n − 1 + ( 1 − β ) ∗ θ n = β n ∗ v 0 + β n − 1 ∗ ( 1 − β ) ∗ θ 1 + . . . + ( 1 − β ) ∗ θ n \begin{aligned} v_{n} &= \beta*v_{n-1}+(1-\beta)*\theta_{n} \\&= \beta*( \beta*v_{n-2}+(1-\beta)*\theta_{n-1})+(1-\beta)*\theta_{n} \\&= \beta^2*v_{n-2} + \beta*(1-\beta)*\theta_{n-1}+(1-\beta)*\theta_{n} \\&= \beta^n*v_{0}+\beta^{n-1}*(1-\beta)*\theta_{1}+...+(1-\beta)*\theta_{n} \end{aligned} vn=β∗vn−1+(1−β)∗θn=β∗(β∗vn−2+(1−β)∗θn−1)+(1−β)∗θn=β2∗vn−2+β∗(1−β)∗θn−1+(1−β)∗θn=βn∗v0+βn−1∗(1−β)∗θ1+...+(1−β)∗θn
通过上面的公式可以发现, θ \theta θ的权重系数呈现出一个指数的变化趋势。
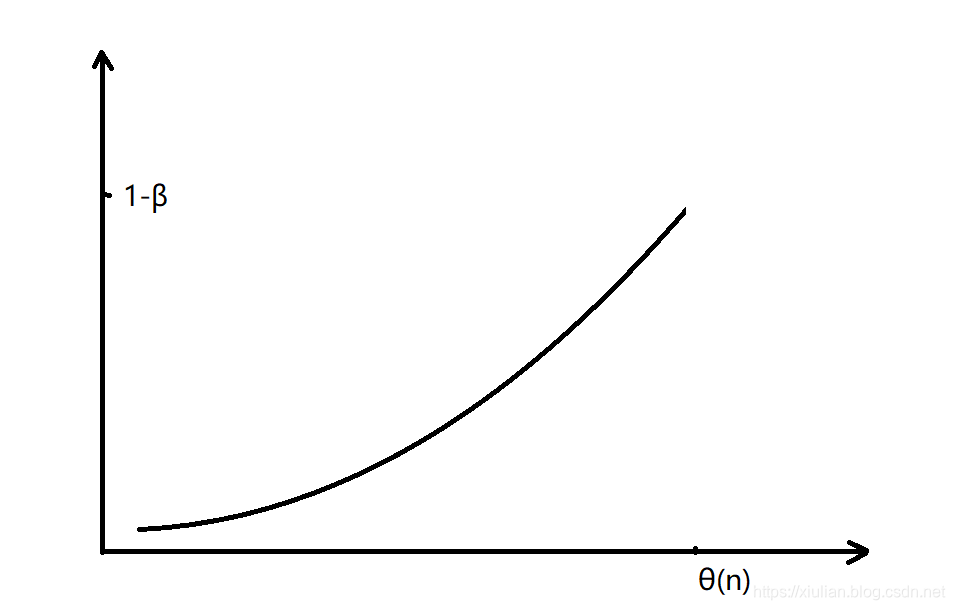
在计算 v n v_{n} vn的时候看起来好像用到了所有的 θ \theta θ平均了之前所有的天数,实际上只平均了一部分,当系数下降到峰值(1-β)的1/e(0.3678)时可以忽略不计,其中e(2.71828)表示的是自然常数,即当权重系数小于峰值的0.3678时,就可以认为它对于结果没有影响。 ( 1 − ϵ ) 1 / ϵ = 1 / e (1-\epsilon)^{1/\epsilon}=1/e (1−ϵ)1/ϵ=1/e,其中 ϵ = ( 1 − β ) \epsilon=(1-\beta) ϵ=(1−β),所以当 β \beta β等于0.9时, ϵ \epsilon ϵ等于0.1,所以0.9^10=1/e。所以十天以前的 θ \theta θ的影响可以忽略不计,就相当于平均了十天的温度。 - 偏差修正
在使用指数加权平均算法计算的时候存在一个问题就是,刚开始使用指数加权算法计算的时候初始值都是非常小的,偏差修正就是用于修正初始值的。如果你对于初始值不太关注,就可以不用使用偏差修正。
偏差修正公式: v n ′ = v n 1 − β n v_{n}^{'}=\frac{v_{n}}{1-\beta^{n}} vn′=1−βnvn
当n越来越大时, β n \beta^n βn趋于0, v n ′ = v n v_{n}^{'}=v_{n} vn′=vn,所以偏差修正的作用仅在n较小的时候有用,即初始化的时候。
三、动量梯度下降算法
动量梯度下降算法在梯度下降算法的基础上做了一些优化,梯度下降算法的收敛如下图所示

其中黑点表示的是起点,红点表示的是终点。通过梯度下降算法不停的迭代,慢慢的从黑点移动到红点的位置,通过上图可以发现黑点的移动轨迹在y方向上一直存在上下波动,而这个对于黑点移动到红点的位置没有任何的帮助,反而是在浪费时间,因为我们更希望减少这种不必要的计算,加速x轴方向上的移动步伐,如下图所示
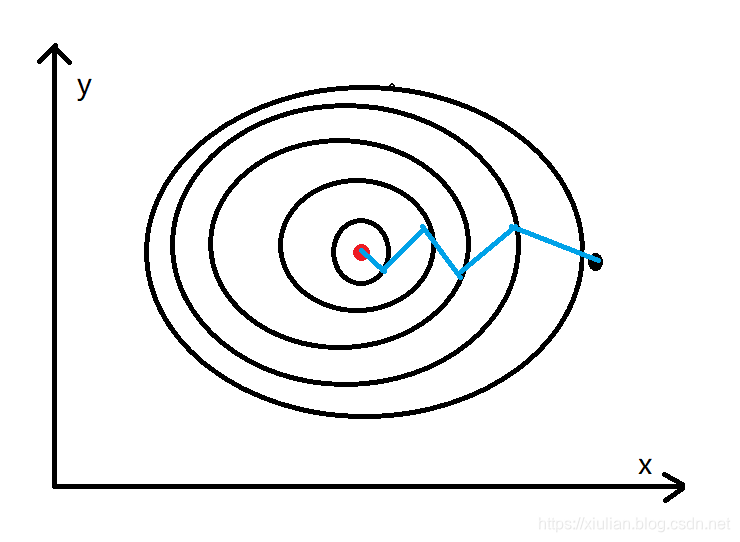
而上图正是动量梯度下降算法所追求的效果,那么它到底是如何实现的呢?
- 梯度下降算法
优化参数权重w w w和偏置b b b,梯度下降算法参数更新公式如下:
w = w − α ∗ d w w=w-\alpha*d{w} w=w−α∗dw
b = b − α ∗ d b b=b-\alpha*d{b} b=b−α∗db
动量梯度下降算法参数更新公式如下:
v w = β ∗ v w + ( 1 − β ) ∗ d w v_{w}=\beta*v_w+(1-\beta)*dw vw=β∗vw+(1−β)∗dw
b b = β ∗ v b + ( 1 − β ) ∗ d b b_b=\beta*v_b+(1-\beta)*db bb=β∗vb+(1−β)∗db
w = w − α ∗ v w w=w-\alpha*v_w w=w−α∗vw
b = b − α ∗ v b b=b-\alpha*v_b b=b−α∗vb
上式中 α \alpha α表示学习率,通过上式可以发现,动量梯度下降算法在更新参数的时候并不是直接使用的梯度,它还利用到以前的梯度,具体到多少,与 β \beta β的大小有关, β \beta β越大使用到以前的梯度越多, β \beta β越小使用到以前的梯度越小。
因为在y轴方向上梯度是有正有负的,所以均值就近似为0,即在y轴方向上不会有太大的变化。而x轴方向上的梯度都是一致的,所以能够为x轴方向上提供动量加速更新。由于动量梯度下降算法,在更新参数的时候不仅使用到了当前的梯度还使用到了以前梯度的均值作为动量,当陷入到局部极小值(梯度接近于0),在更新的时候动量梯度下降算法还可以利用以前梯度的均值来跳出局部极小值,而梯度下降算法只会陷入到局部极小值。在使用动量梯度下降算法的时候 β \beta β通常可以取0.9。
四、RMSprop算法
RMSprop算法全称root mean square prop,RMSprop算法的思想和Moment算法的思想是一致的都是通过减少在y轴方向上的抖动,加大x轴方向上的移动步长。而在实现上略有不同,Moment主要是利用累积以前的梯度来实现加速,而RMSprop算法的思想是利用梯度下降算法在y轴方向上的梯度比较大,而在x轴方向上的梯度相对较小。在进行参数更新的时候,让y轴方向上的梯度除以一个大的数,这样y轴更新的幅度就小。而x轴方向上的梯度除以一个小的数,这样x轴更新的幅度就大。从而实现了,减小了y轴方向上的更新步长,增大了x轴方向上的更新步长,使得算法能够更快的收敛。更新公式如下:
S
d
w
=
β
∗
S
d
w
+
(
1
−
β
)
∗
d
w
2
S_{dw}=\beta *S_{dw} +(1-\beta)*dw^2
Sdw=β∗Sdw+(1−β)∗dw2
S
d
b
=
β
∗
S
d
b
+
(
1
−
β
)
∗
d
b
2
S_{db}=\beta * S_{db} + (1-\beta)*db^2
Sdb=β∗Sdb+(1−β)∗db2
w
=
w
−
α
∗
d
w
S
d
w
+
ϵ
w=w-\alpha * \frac{dw}{\sqrt{S_{dw}}+\epsilon}
w=w−α∗Sdw+ϵdw
b
=
b
−
α
∗
d
b
S
d
b
+
ϵ
b=b-\alpha * \frac{db}{\sqrt{S_{db}}+\epsilon}
b=b−α∗Sdb+ϵdb
为了避免在更新参数的时候,分母为0,所以需要在分母上加上一个极小的数
ϵ
\epsilon
ϵ,通常取
1
0
−
8
10^{-8}
10−8。
d
w
2
dw^2
dw2表示的是参数
w
w
w的梯度的平方也称为微分的平方。
五、Adam算法
Adam算法全称Adaptive Moment Estimation,主要是结合了Moment算法和RMSprop算法。公式如下:
v
d
w
=
0
,
v
d
b
=
0
,
S
d
w
=
0
,
S
d
b
=
0
v_{dw}=0,v_{db}=0,S_{dw}=0,S_{db}=0
vdw=0,vdb=0,Sdw=0,Sdb=0
v
d
w
=
β
1
∗
v
d
w
+
(
1
−
β
)
∗
d
w
v_{dw}=\beta_{1}*v_{dw}+(1-\beta)*dw
vdw=β1∗vdw+(1−β)∗dw
v
d
b
=
β
1
b
∗
v
d
b
+
(
1
−
β
)
∗
d
b
v_{db}=\beta_{1}b*v_{db}+(1-\beta)*db
vdb=β1b∗vdb+(1−β)∗db
S
d
w
=
β
∗
S
d
w
+
(
1
−
β
)
∗
d
w
2
S_{dw}=\beta *S_{dw} +(1-\beta)*dw^2
Sdw=β∗Sdw+(1−β)∗dw2
S
d
b
=
β
∗
S
d
b
+
(
1
−
β
)
∗
d
b
2
S_{db}=\beta * S_{db} + (1-\beta)*db^2
Sdb=β∗Sdb+(1−β)∗db2
参数的更新:
w
=
w
−
α
∗
v
d
w
S
d
w
+
ϵ
w=w-\alpha * \frac{v_{dw}}{\sqrt{S_{dw}}+\epsilon}
w=w−α∗Sdw+ϵvdw
b
=
b
−
α
∗
v
d
b
S
d
b
+
ϵ
b=b-\alpha * \frac{v_{db}}{\sqrt{S_{db}}+\epsilon}
b=b−α∗Sdb+ϵvdb
在使用指数加权平均值算法的时候,可能存在初始化的偏差比较大的情况,可以通过下面的方法进行偏差修正:
v
d
w
′
=
v
d
w
1
−
β
t
v_{dw}^{'}=\frac{v_{dw}}{1-\beta^{t}}
vdw′=1−βtvdw
S
d
w
′
=
S
d
w
1
−
β
t
S_{dw}^{'}=\frac{S_{dw}}{1-\beta^{t}}
Sdw′=1−βtSdw
上式中的t表示的是迭代的次数,通常情况下我们都不会太注意初始化值,因为函数收敛通常都需要迭代很多次。
β
1
\beta_{1}
β1指的是Moment的参数通常取0.9,
β
2
\beta_{2}
β2指的是RMSprop的参数,通常取0.999,
ϵ
\epsilon
ϵ主要是用来避免分母为0的情况取
1
0
−
8
10^{-8}
10−8。
六、总结
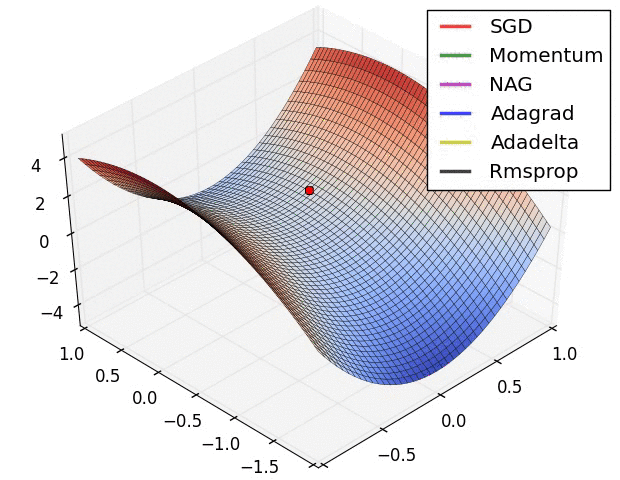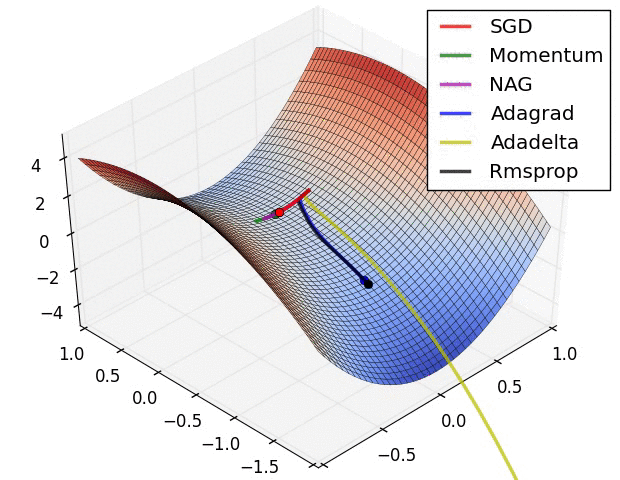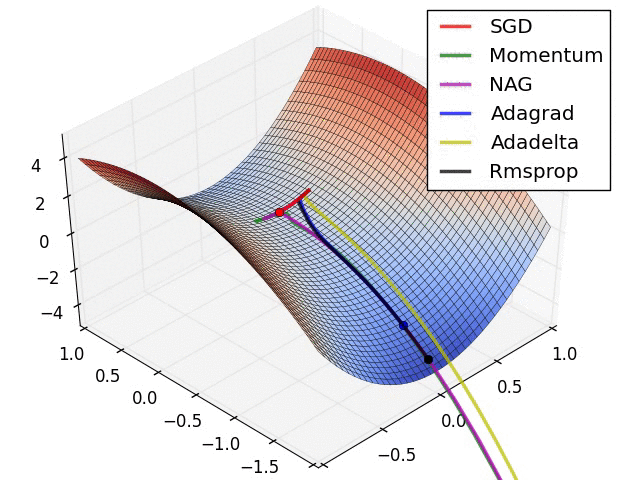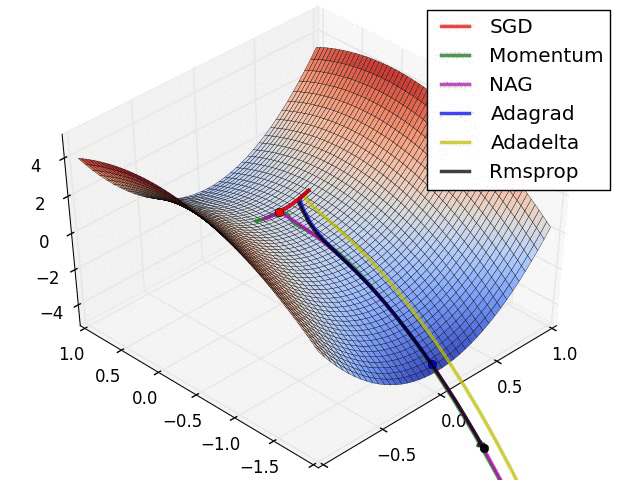
最后我们用两张图来比较一下算法的表现,这张图表示的是在同样的等高线的情况下各个算法的收敛情况
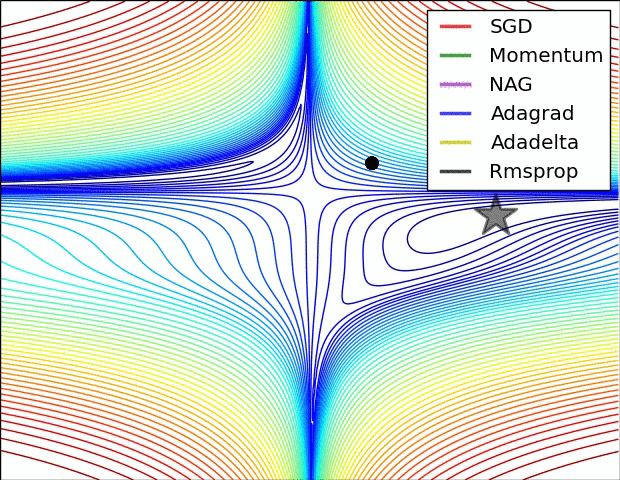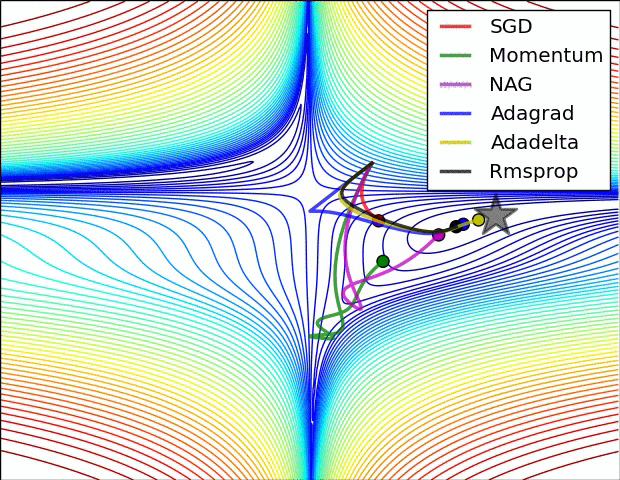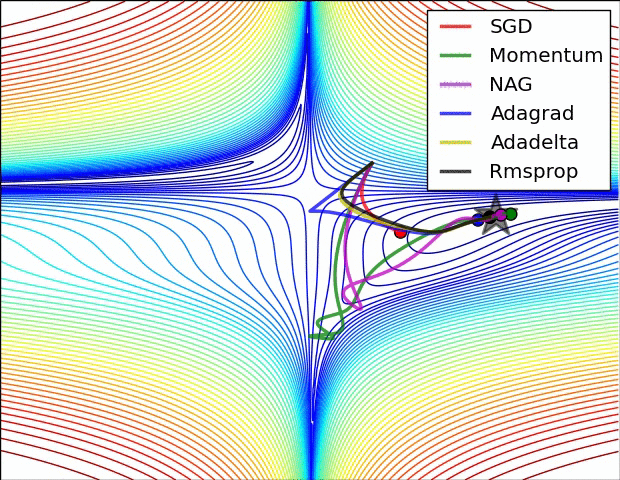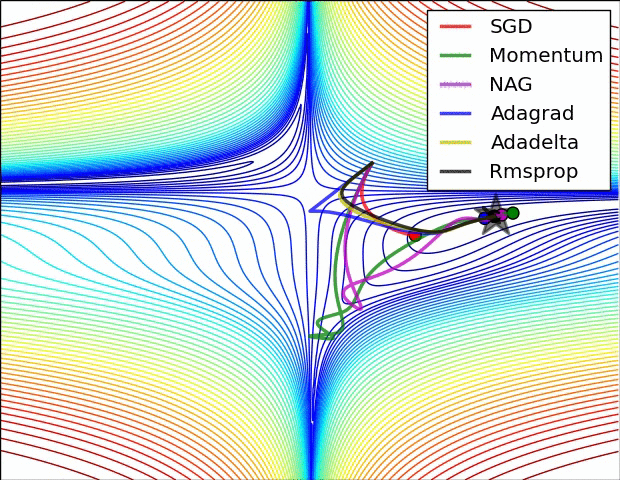
下面这张图表示的是不同算法在遇到鞍点时的表现


















 2360
2360

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











