






随着人工智能、物联网、大数据等应用的快速发展,对数据处理与计算能力的需求持续增长。2015版AlphaGo使用了1202个CPU和176个GPU。此类需要高速处理海量数据及复杂计算的功能对高性能计算能力提出了更高要求。系统芯片(SoC,如CPU和GPU)内部存储还需大容量随机存取存储器以支持其数据链路的高性能计算。
通用计算机通常采用同步动态随机存取存储器(DRAM),在DDR5应用中可提供最高51Gb/s的带宽。例如,高级驾驶辅助系统需要超过500Gb/s的存储带宽以实现L5级全自动驾驶的精准预测。传统DRAM难以满足如此巨大的需求。因此,具有更低功耗、更高传输速率的堆叠互连高带宽内存(HBM)应运而生,成为主流高性能计算应用的选择。
在2.5D芯片-晶圆-基板(CoWoS)封装中,SoC与内存芯片通过Si interposer中的微凸块建立HBM通道链路,实现信号重新分配与传输。相较于印刷电路板(PCB),DRAM可更靠近SoC放置,但可用空间也更小。对于Si interposer中具有1024个I/O通道的典型HBM,信号线需采用细线宽且间距极小,以便在有限空间内完成布线。然而,随着传输速度提升,信号间串扰问题将愈发严重。此外,PCB中的实心或网格平面无法用于Si interposer,因此电源与地线均处于传输线模式且邻近信号线。当电源与信号线间距较近时,电源噪声的影响也会加剧。
第三代高带宽内存(HBM3)规范中,传输数据速率是第二代增强版(HBM2E)的两倍,达到6.4Gb/s,单堆栈最大带宽约为820Gb/s。若采用八堆栈HBM,总带宽可进一步提升至约6.5TB/s。
串扰抑制
A.CoWoS平台上的HBM
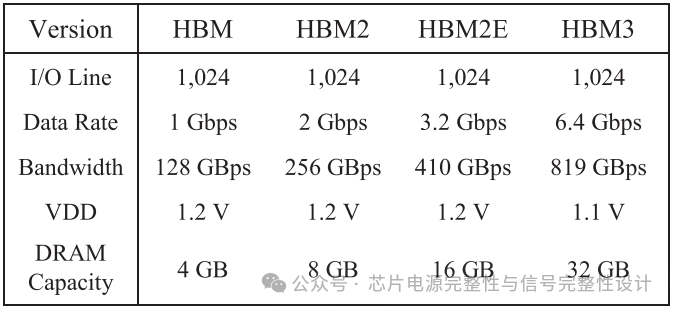
JEDEC于2013年发布第一代HBM规范,此后每三年更新一代。2021版HBM3的带宽较前代翻倍,主要通过提升数据速率实现。表I列出了各代HBM规格对比。单堆栈HBM带宽从第一代的128Gb/s提升至410Gb/s,而HBM3预计将达到约820Gb/s。在提升带宽的同时,工作电压从1.2V降至1.1V以降低功耗。
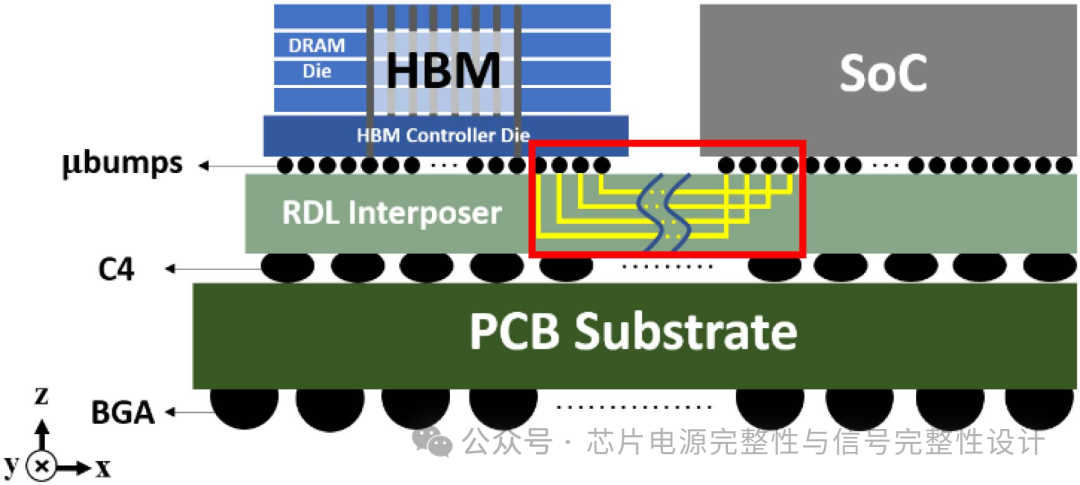
通过CoWoS工艺,下图展示了每个HBM堆栈由多层DRAM堆叠形成,并通过硅通孔(TSV)将信号收集到底层逻辑芯片。如图红色框所示,HBM通道链路在物理(PHY)层之间互连,单个HBM芯片尺寸为5.48mm×7.29mm,距SoC长度为5mm。逻辑芯片上的PHY区域包含堆叠HBM芯片中的所有DWORD与AWORD线,其中DWORD线通过Si interposer的1024个I/O通道传输。SoC芯片的PHY区域与每个HBM堆栈对应,两者通过微凸块在Si interposer特定PHY区域内实现信号重分布与传输。
B.Si interposer布线方案设计
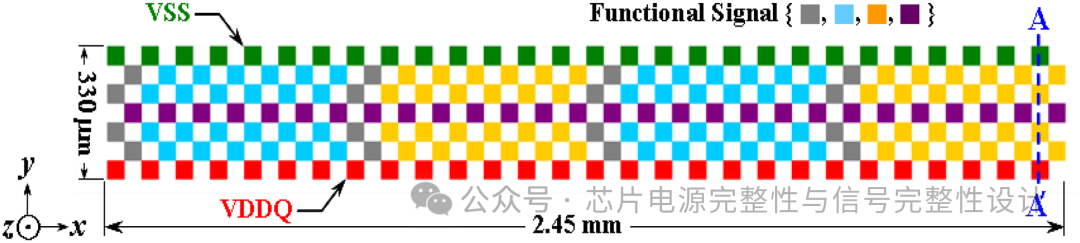
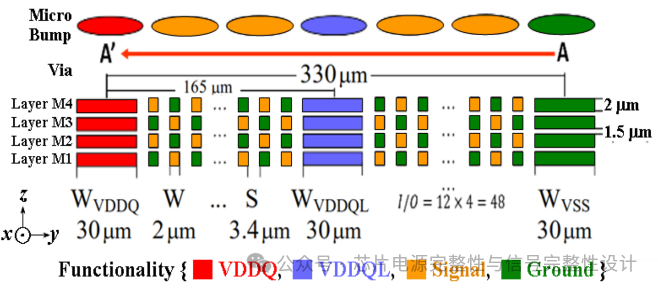
在PHY区域中,所有I/O线采用四层重分布线,在宽度为7.29mm的空间内完成布线。PHY区域包含16个通道,每列包含4个通道。下图展示了沿y轴的七列通道单元区域。七列微凸块包括VSS与VDDQ,而AWORD与DWORDI/O线通过VDDQL隔离。每个通道每列有6条有效I/O线,单元区域共96条信号线通过Si interposer沿y轴方向330μm宽度传输。
原始方案下图(a)采用分层交错布线以降低插入损耗,由于信号线间无隔离,串扰影响不可忽视。为减少串扰,对角错位布线方案下图(b),即通过错位排列地(G)与信号(Si)线,使地线包围所有信号线以有效隔离串扰
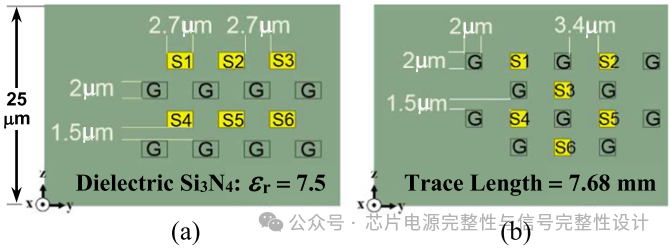
下图展示了七列微凸块下330μm空间内的布线示意,其中VDDQ、VDDQL与VSS宽线需保留30μm空间。在AA'截面135μm宽度内,需评估四层(M1、M2、M3、M4)上48条信号线与48条地线能否成功布线。在HBM2E规范的5.4μm间距条件下,初步评估线宽(W)与间距(S)分别为2.0μm与3.4μm。传输线重复排列以缓解串扰。
以上图中的Si单元为例,六条信号线(S1-S6)被相对介电常数εr=7.5、损耗角正切0.02的材料包围,通过提取其在1GHz下的电气参数。最坏情况下(S2与S3之间),电容耦合系数KC=0.0389(原方案为0.2433,降低84%),电感耦合系数KL=0.0514(原方案为0.2706,降低81%)。两种系数均实现至少五倍的降低。
C.串扰降低
参考下图电路模型,输入电压1.1V,采用2^13伪随机二进制序列(PRBS)仿真。通过提取两种布线方案中六条信号线的S参数。

在分层交错布线(原始方案)与对角错位布线(改进方案)下评估信号完整性(仅SI)。分析两种场景:含串扰(激活所有信号线)与不含串扰(仅激活S3线)。数据速率3.2Gb/s、上升时间30ps时,四种电路设置的眼图如图所示。原始方案中,无串扰时S3线接收端眼高为0.68V(占1.1V的61.8%);含串扰时降至0.59V(53.6%)。改进方案中,无串扰时眼高为0.65V(59.1%),含串扰时为0.64V(58.2%)。
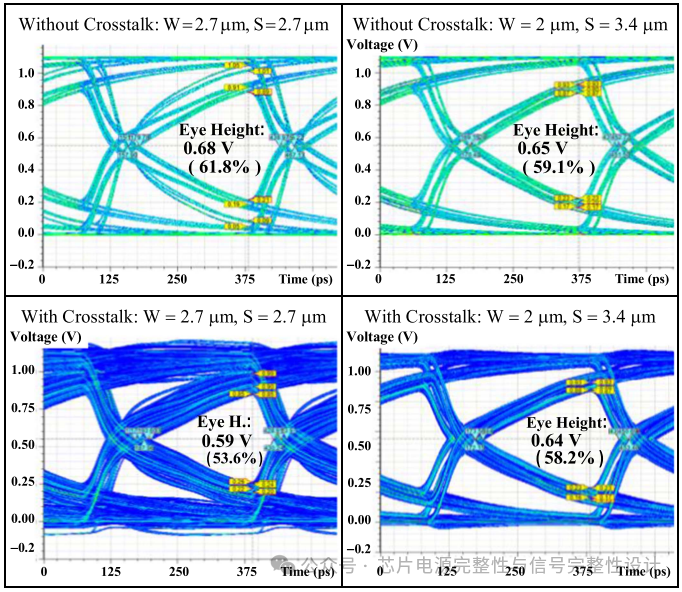
当数据速率升至6.4Gb/s(上升时间仍为30ps),原始方案眼高从0.59V骤降至0.11V(降幅81%),改进方案从0.64V降至0.16V(降幅75%)。尽管改进方案通过地屏蔽设计使眼高小幅提升,但仍无法满足速率翻倍后的需求。
失配系统中的阻抗优化设计
基于前文图中的I/O配置,负载端电容Cload=0.4pF,在1GHz下接近开路。整个电路网络呈现失配特性,导致传输线多次反射。接收端波形与源端和负载端反射系数Γs、Γo高度相关,可用于优化眼高。
A.失配传输线系统的PDA分析
对于时延(TD)的失配传输线系统,接收端脉冲响应通常由主脉冲及每隔2TD出现的反射脉冲组成。当TD大于单位间隔(UI)的一半(即0.5UI)时,反射脉冲不会重叠。下图展示了单脉冲响应的主光标、前导与后导干扰(ISI),其电压采样值标记为ISI+(正)与ISI-(负)。
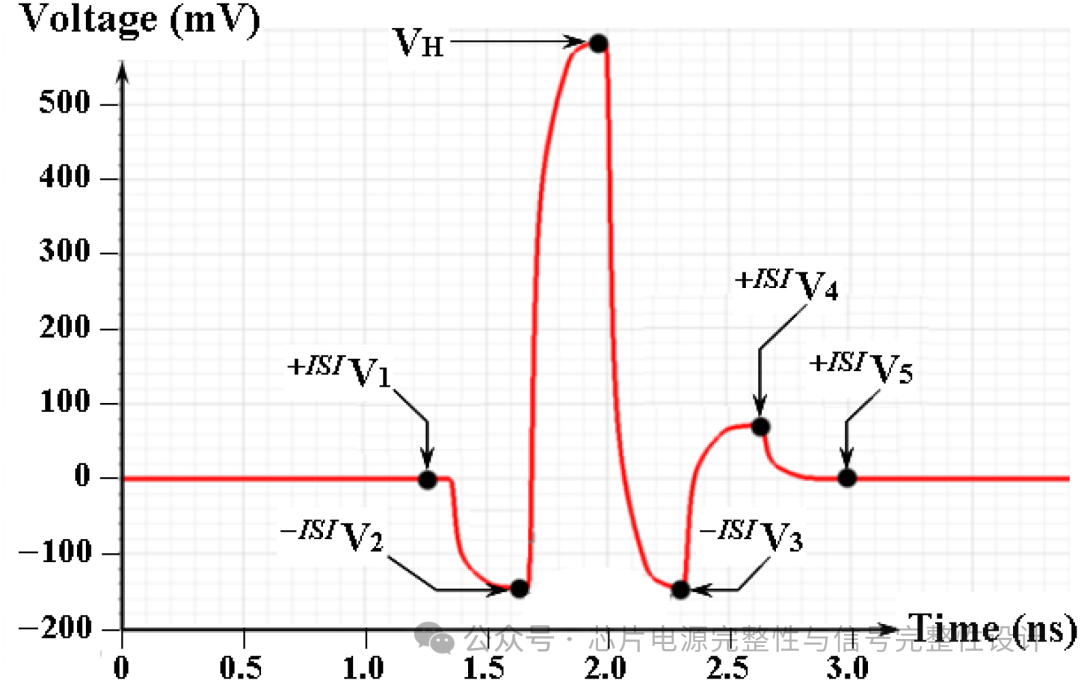
PDA预测最坏情况眼高为:

通过考虑后续反射脉冲的所有ISI,假设有损传输线衰减常数与频率无关,则最坏情况眼高可简化为:
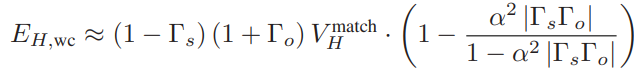
其中,α为信号沿传输线传播的衰减因子,通常通过相同匹配系统中长度ℓ与2ℓ的电压比近似。
为实现最大眼高,需满足Γo>0且Γs<0,而非阻抗匹配设计。由于衰减因子α²,源端反射较小。
B.眼高预测
设定源电压1.1V,UI=156.25ps,上升时间15ps,线长7.68mm。通过式计算信号线在不同Γs与Γo下的最坏情况眼高。下图(a)展示了Γs与Γo在-1至+1范围内的眼高等高线图。当传输线完全匹配(Γs=Γo=0)时,眼高略高于0.4V。在负载端开路的条件下,最大眼高出现在Γo=1且源阻抗Zs=35Ω处。进一步优化可得最佳传输线阻抗Z_0=40Ω,如图(b)所示。
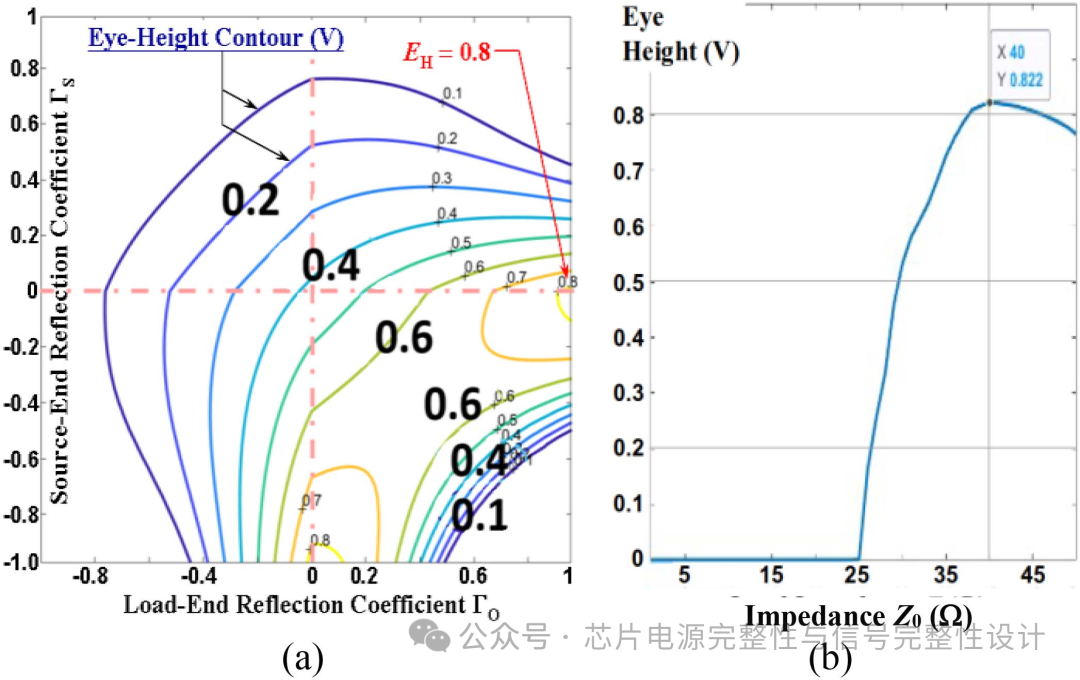
由于Si interposer厚度固定,需通过调整线宽w与间距s设计阻抗。下表显示线宽与间距对特性阻抗的敏感性。在间距固定时,增加线宽会减小线距。
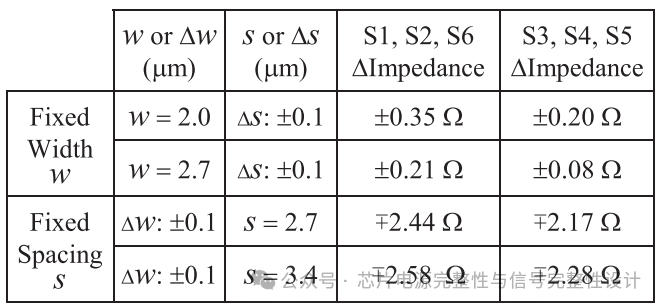
线宽±0.1μm变化会导致Z0约2Ω的波动,因此制造过程中需严格控制线宽精度。通过调整线距0.2μm,最终设计目标线宽与间距为2.2μm与3.2μm。
C.眼图仿真
进一步评估原始分层交错布线、改进对角错位布线及优化线宽/间距方案。考虑三种信号源场景:1)3.2Gb/s,上升时间30ps;2)6.4Gb/s,上升时间30ps;3)6.4Gb/s,上升时间15ps。下表对比了含/不含串扰时的接收眼高结果。改进方案显著降低串扰,但在6.4Gb/s时眼高仍低于输入电压的20%。
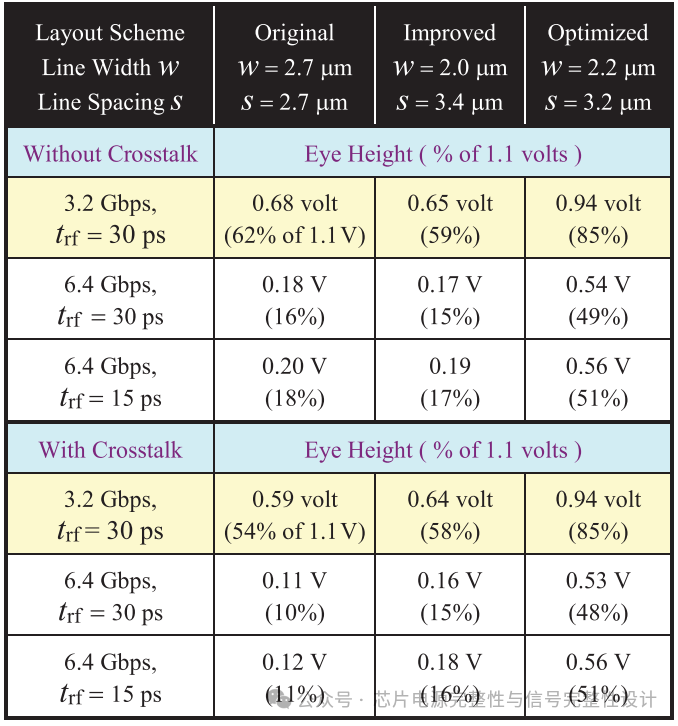
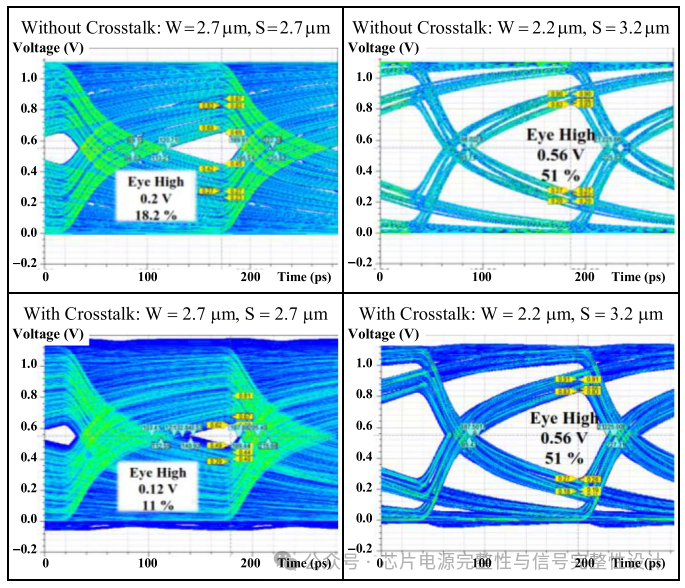
在3.2Gb/s、30ps上升时间下,优化方案的眼高可达1.1V的85%。当速率升至6.4Gb/s、15ps上升时间时,优化方案受串扰影响较小,眼高为原始方案的4.7倍(0.56/0.12V),占输入电压的51%。下图展示了两种方案在6.4Gb/s、15ps上升时间下的眼图对比。
电源完整性的交错布局
HBM与SoC信号通过微凸块从外部芯片供电。前文的拓扑结构显示主电源VDDQ(1.1V)通过左侧30μm宽线供电,距信号线仅3.0μm。若电源存在噪声,其通过串扰机制对信号线的影响不可忽视。
A.电源感知电感
下图展示了在对角错位布线方案中添加四层30μm宽电源线的3D结构。电源配送网络(PDN)中因I/O开关活动产生的电源噪声称为同步开关噪声(SSN)。通道链路与PDN间的耦合效应会加剧SSN。
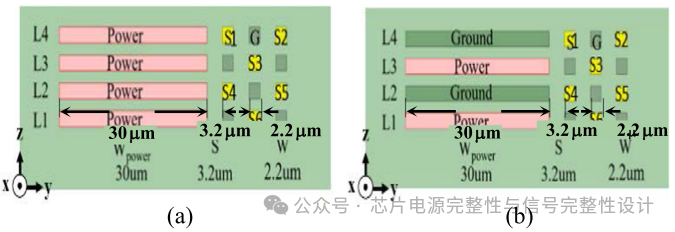
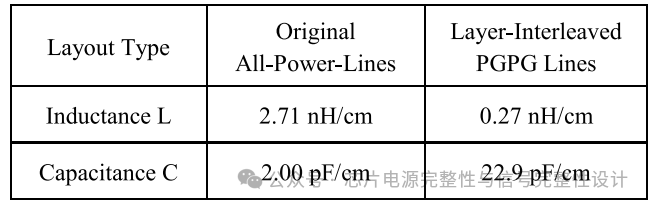
电源噪声主要由PDN的高电感引起。通过在电源与地线间增加电容可抑制该效应。图(a)的原始全电源线(L1-L4)方案中,采用电源-地-电源-地(PGPG)层交错结构可将自感降低至原始方案的10%(0.27nH/cm VS 2.71nH/cm),如下表所示。此方案中,电源噪声被两侧地线包裹,有效隔离线间耦合。
B.PI电路配置
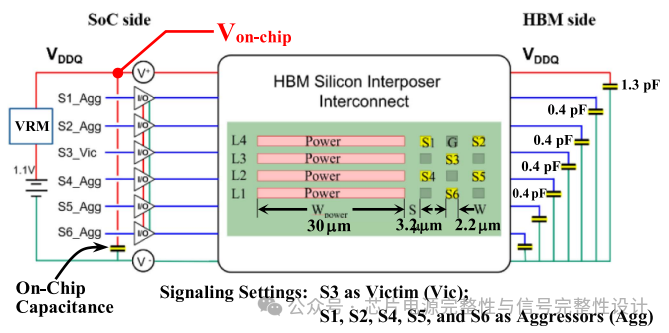
参考LPDDR4规范,建立PDN等效电路,包含理想电压源、四元件电压调节模块(VRM)与1.3pF片上电容。信号线接收端负载电容0.4pF。PGPG方案中,地线L2与L4在HBM端并联并接0.4pF电容。以中心信号线S3为受扰线,其余五条为干扰线,分析其眼图。
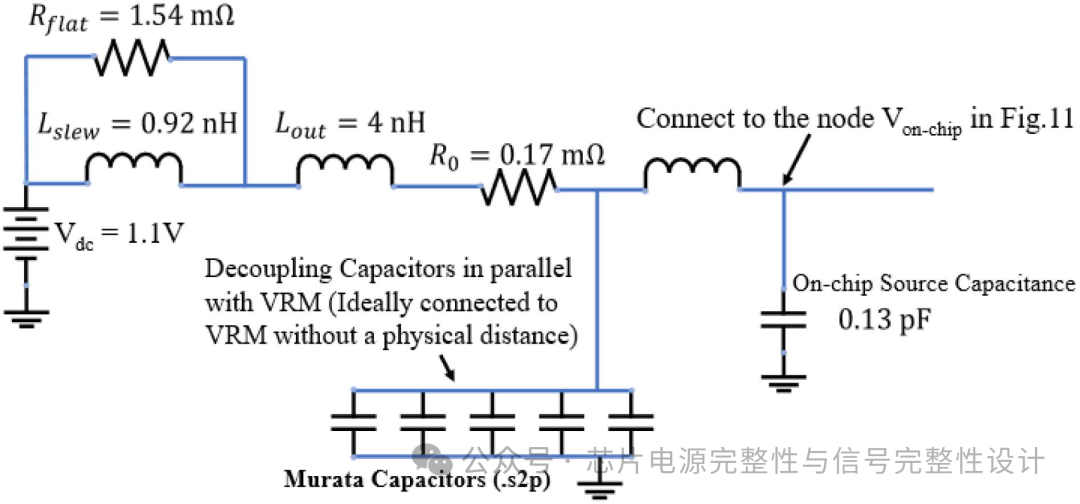
基于前文电源设计图(a)原始方案,在ADS中构建封装电源系统电路,包含1.1V理想电源、传输线系统(六条信号线与四层电源线L1-L4并联)、四元件模型(R0=0.17mΩ,Lout=4nH,Rflat=1.54mΩ,Lslew=0.92nH)及SoC端0.13pF片上电容。下图展示了VRM与去耦电容并联的等效电路模型。
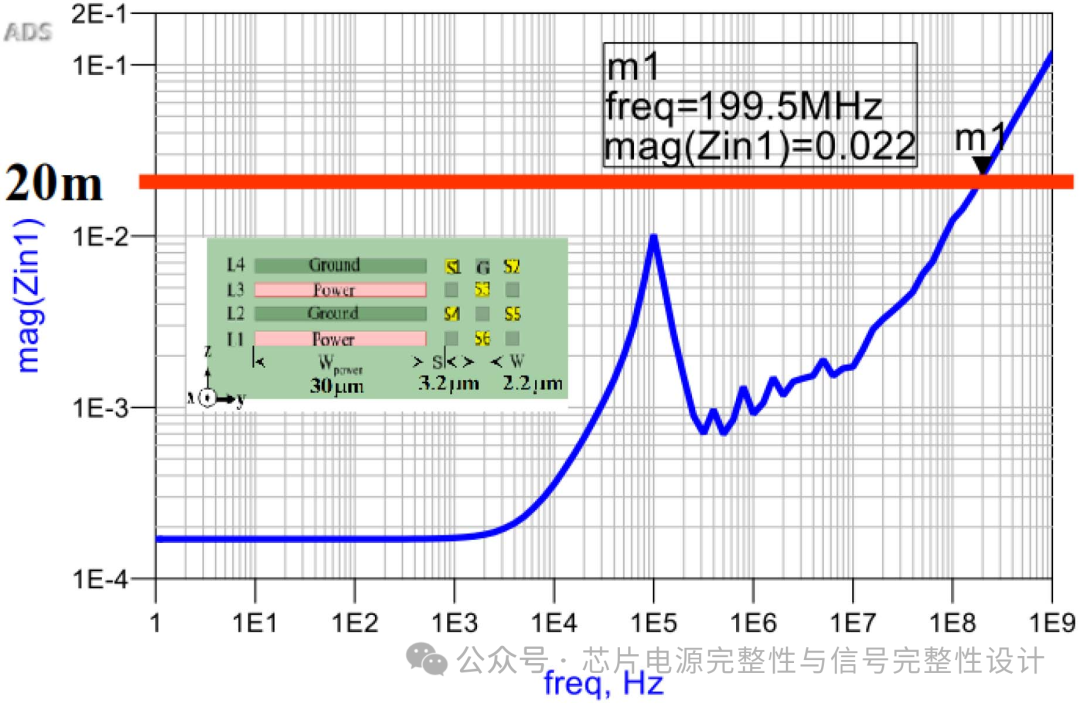
下图显示了特定去耦设计下的目标阻抗特性。目标阻抗在DC至199.5MHz范围内低于20mΩ,但仍需优化PDN时域噪声性能。
C.电源对眼图影响的仿真
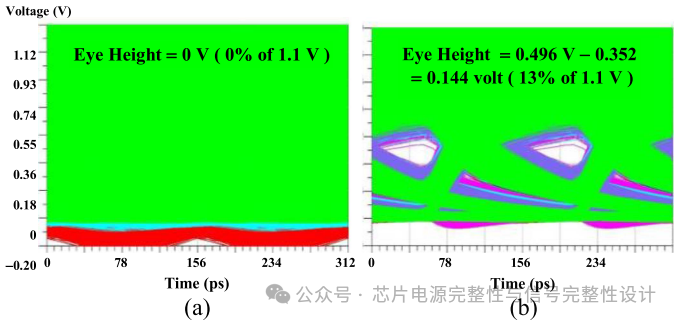
数据速率6.4Gb/s、上升时间10ps时,信号线S1-S6采用PRBS输入。下图展示了原始全电源线与PGPG方案在Con-chip=1.3pF时的S3线眼图。原始方案中,即使采用优化线宽/间距,开关噪声仍使眼图闭合(图(a))。PGPG方案眼高为0.14V(图(b))。
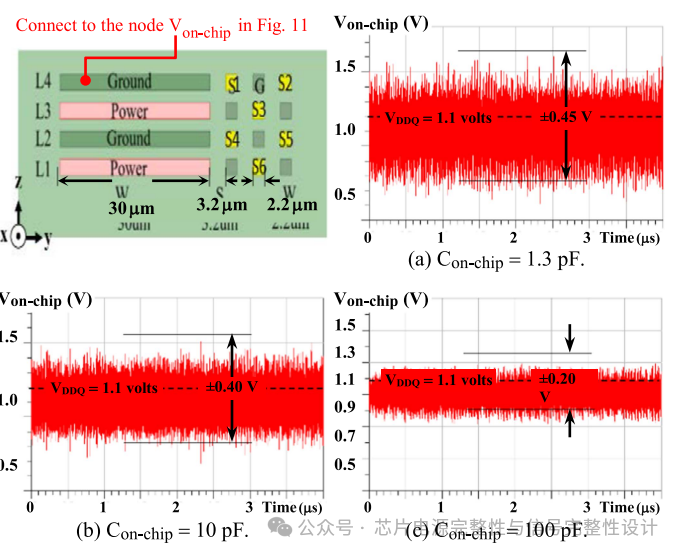
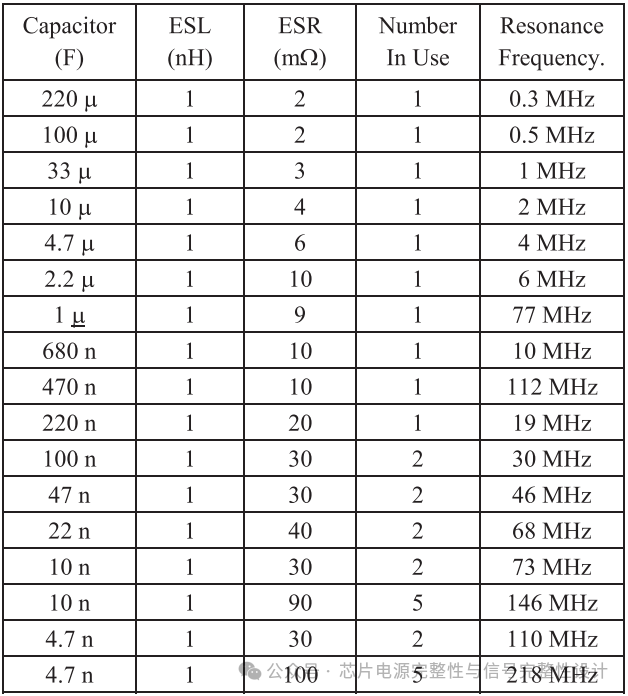
通过逐步增加Conchip至10pF与100pF,开关噪声分别降至±0.40V与±0.20V(下图)。
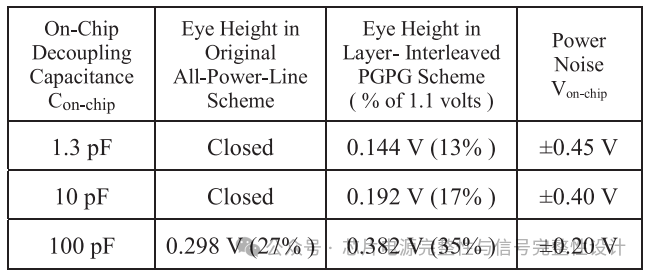
下表总结了不同Conchip下的最坏眼高。当Conchip=100pF时,PGPG方案眼高可达0.49V(占1.1V的45%),较SI-only情况仅降低12.5%。
D.含去耦电容的PI仿真
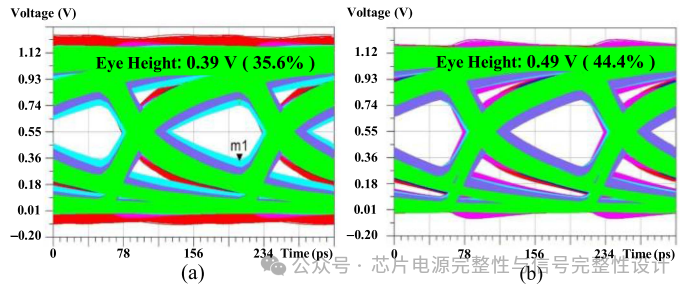
实际中,100pF的Conchip过大,需通过PCB去耦电容满足中频目标阻抗。下图展示了采用Murata去耦电容时的眼图。在6.4Gb/s、15ps上升时间下,原始方案眼高为0.38V(占35%),PGPG方案为0.52V(占47%),较SI-only情况保留93%。


















 1589
1589

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











