







为什么要正则化?
深度模型(参数多)擅长过度拟合训练数据,通过增加训练数据可有效防止过拟合,但一般无法得到大量有效的数据,一般通过对参数进行特殊处理防止过拟合。
我们没有magical formula衡量模型的大小是否合适,为找到合适的模型,有效的想法是先使用层数较少的模型,或使用较小值初始化参数,然后逐渐增加模型层数、调增参数的大小,通过模型在验证集上的表现,判断模型大小是否合适。
L2 Normalization
L2参数范数惩罚通常被称为权重衰减,正则化策略是在目标函数/损失函数中添加正则项:
Ω
(
θ
)
=
∣
∣
w
∣
∣
2
/
2
\Omega(\theta)=||w||^2/2
Ω(θ)=∣∣w∣∣2/2,使权重更接近原点,使用L2正则化的总目标函数为
J
~
(
w
;
X
,
y
)
=
α
2
w
⊤
w
+
J
(
w
;
X
,
y
)
\tilde J(w;X,y)=\frac{\alpha}{2}w^\top w+J(w;X,y)
J~(w;X,y)=2αw⊤w+J(w;X,y)
与之对应的梯度为
∇
w
J
~
(
w
;
X
,
y
)
=
α
w
+
∇
w
J
(
w
;
X
,
y
)
\nabla_w\tilde J(w;X,y)=\alpha w+\nabla_wJ(w;X,y)
∇wJ~(w;X,y)=αw+∇wJ(w;X,y)
使用单步梯度下降更新权重,执行以下更新:
w
→
w
−
ϵ
(
α
w
+
∇
w
J
(
w
;
X
,
y
)
)
=
(
1
−
ϵ
α
)
w
−
ϵ
∇
w
J
(
w
;
X
,
y
)
w \to w-\epsilon(\alpha w+\nabla_wJ(w;X,y))=(1-\epsilon\alpha)w-\epsilon\nabla_wJ(w;X,y)
w→w−ϵ(αw+∇wJ(w;X,y))=(1−ϵα)w−ϵ∇wJ(w;X,y)
在每次参数更新时,使用L2正则化比不使用多一步自身权重的缩放。 那么,最后整个训练过程到底发生了什么? 正则化后最优权重
w
~
\tilde w
w~和未正则化最优权重
w
∗
w^*
w∗的主要差异是什么?
由于目标函数在最优权重处一阶导为零,即正则化后的最优权重满足
α
w
~
+
∇
w
~
J
(
w
~
;
X
,
y
)
=
0
\alpha\tilde w+\nabla_{\tilde w}J(\tilde w;X,y)=0
αw~+∇w~J(w~;X,y)=0
对未正则化目标函数在其最优权重
w
∗
w^*
w∗处二次泰勒近似,得
J
(
w
;
X
,
y
)
≈
J
(
w
∗
;
X
,
y
)
+
(
w
−
w
∗
)
⊤
g
+
1
2
(
w
−
w
∗
)
⊤
H
(
w
−
w
∗
)
J(w;X,y)\approx J(w^*;X,y)+(w-w^*)^\top g+\frac{1}{2}(w-w^*)^\top H(w-w^*)
J(w;X,y)≈J(w∗;X,y)+(w−w∗)⊤g+21(w−w∗)⊤H(w−w∗)
式中
g
g
g和
H
H
H分别表示未正则化目标函数
J
J
J在最优权重
w
∗
w^*
w∗处的Jacobian和Hessian矩阵,且
g
=
0
g=0
g=0,再对其求导得
∇
w
J
(
w
;
X
,
y
)
=
H
(
w
−
w
∗
)
\nabla_wJ(w;X,y)=H(w-w^*)
∇wJ(w;X,y)=H(w−w∗)
因此
α
w
~
+
H
(
w
~
−
w
∗
)
=
0
⟹
w
~
=
(
H
+
α
I
)
−
1
H
w
∗
\alpha\tilde w+H(\tilde w-w^*)=0 \implies \tilde w=(H+\alpha I)^{-1}Hw^*
αw~+H(w~−w∗)=0⟹w~=(H+αI)−1Hw∗
实对称矩阵可正交分解
H
=
Q
Λ
Q
⊤
H=Q\Lambda Q^\top
H=QΛQ⊤,因此
w
~
=
Q
(
Λ
+
α
I
)
−
1
Λ
Q
⊤
w
∗
\tilde w=Q(\Lambda +\alpha I)^{-1}\Lambda Q^\top w^*
w~=Q(Λ+αI)−1ΛQ⊤w∗
引理:实对称变换的意义
若矩阵 A A A为实对称矩阵,则可将其分解为 A = Q Λ Q ⊤ A=Q\Lambda Q^\top A=QΛQ⊤, Q Q Q的列向量 v v v是 A A A的特征向量, Λ \Lambda Λ对角线元素是特征值,由于 Q Q Q是正交矩阵,我们 可以将 A A A看做沿 v ( i ) v^{(i)} v(i)延展 λ i \lambda_i λi倍的空间,如下图所示:
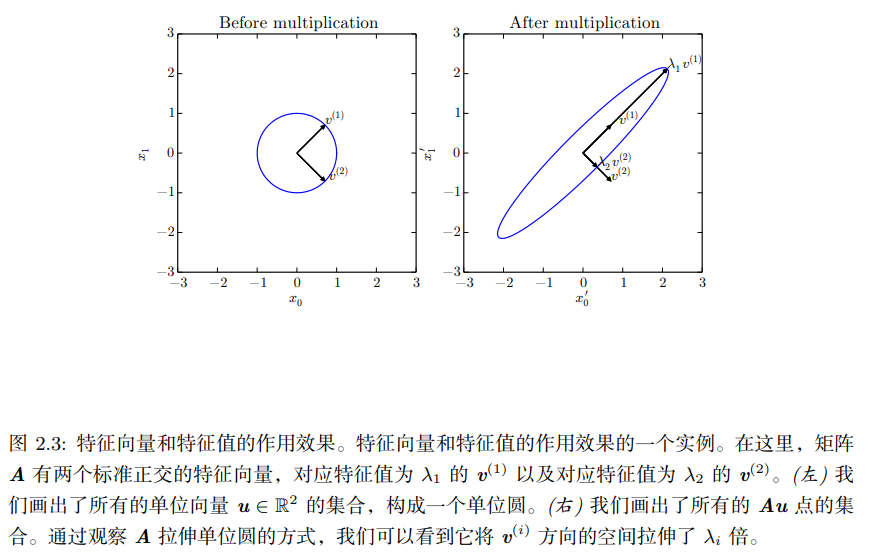
假设二维实对称矩阵
A
A
A的单位特征向量为
v
1
v_1
v1和
v
2
v_2
v2,对应特征值
λ
1
\lambda_1
λ1和
λ
2
\lambda_2
λ2,对任意
x
x
x进行变换
A
x
=
λ
1
v
1
v
1
⊤
x
+
λ
2
v
2
v
2
⊤
x
Ax=\lambda_1v_1v_1^\top x+\lambda_2v_2v_2^\top x
Ax=λ1v1v1⊤x+λ2v2v2⊤x
其中 λ i v i v i ⊤ x \lambda_iv_iv_i^\top x λivivi⊤x的几何意义为, x x x在 v i v_i vi方向的投影伸缩 λ i \lambda_i λi倍得到的向量。
这里,我们可以看到权重衰减的效果是沿着由 H H H的特征向量所定义的轴缩放 w ∗ w^* w∗,具体地说,将 w ∗ w^* w∗在 H H H第 i i i个特征向量方向上的分量缩放 λ i / ( λ i + α ) \lambda_i/(\lambda_i+\alpha) λi/(λi+α)倍。因此,沿着 H H H特征值 λ i ≫ α \lambda_i\gg \alpha λi≫α的方向正则化的影响较小,特征值 λ i ≪ α \lambda_i\ll \alpha λi≪α的分量将会收缩至零,如下图:
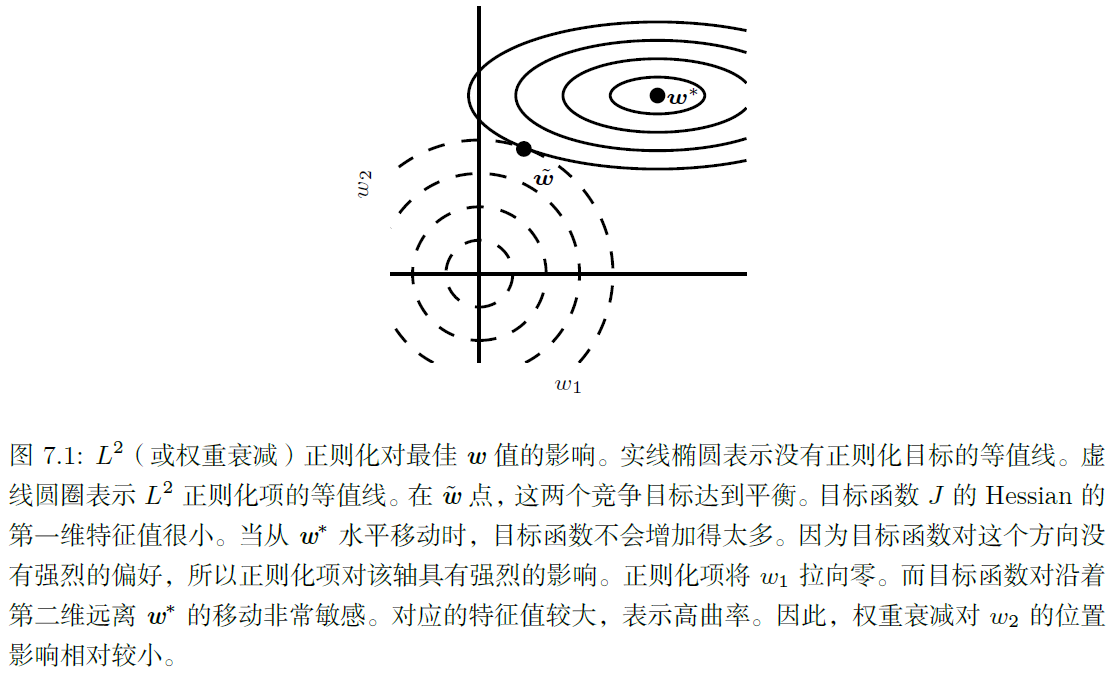
上图中,Hessian水平方向较扁,对应特征值较小,目标函数在这个方向移动函数值变化较小,因此极值点 w 1 w_1 w1较小 。
L1 Normalization
L1正则策略是在目标函数中添加参数的绝对值之和,添加L1正则项的目标/损失函数为
J
~
(
w
;
X
,
y
)
=
α
∣
∣
w
∣
∣
1
+
J
(
w
;
X
,
y
)
\tilde J(w;X,y)=\alpha||w||_1+J(w;X,y)
J~(w;X,y)=α∣∣w∣∣1+J(w;X,y)
对应梯度为
∇
w
J
~
(
w
;
X
,
y
)
=
α
sign
(
w
)
+
∇
w
J
(
w
;
X
,
y
)
\nabla_w\tilde J(w;X,y)=\alpha\text{sign}(w)+\nabla_wJ(w;X,y)
∇wJ~(w;X,y)=αsign(w)+∇wJ(w;X,y)
相比不使用正则化的目标函数,使用L1正则化在使用梯度下降更新时, w w w会加上或减去 α η \alpha\eta αη,使 w w w向 0 0 0靠拢。
从L2正则项章节中已知,未正则化目标函数的导数为
∇
w
J
(
w
;
X
,
y
)
=
H
(
w
−
w
∗
)
\nabla_wJ(w;X,y)=H(w-w^*)
∇wJ(w;X,y)=H(w−w∗)
使用L1正则项的损失函数没有清晰的代数表达式,我们假设其Hessian矩阵是对角矩阵,即输入特征间无相关性,则可将L1正则化目标函数二阶近似分解为关于参数求和的形式:
J
~
(
w
;
X
,
y
)
=
J
(
w
∗
;
X
,
y
)
+
∑
i
[
1
2
H
i
,
i
(
w
i
−
w
i
∗
)
2
+
α
∣
w
i
∣
]
\tilde J(w;X,y)=J(w^*;X,y)+\sum_i\left[\frac{1}{2}H_{i,i}(w_i-w_i^*)^2+\alpha|w_i|\right]
J~(w;X,y)=J(w∗;X,y)+i∑[21Hi,i(wi−wi∗)2+α∣wi∣]
上式中一阶项在
w
∗
w^*
w∗处为0,已忽略,最小化这个近似代价函数,可得到解析解:
w
i
=
sign
(
w
i
∗
)
max
{
∣
w
i
∗
∣
−
α
H
i
,
i
,
0
}
w_i=\text{sign}(w_i^*)\max\left\{|w_i^*|-\frac{\alpha}{H_{i,i}},0\right\}
wi=sign(wi∗)max{∣wi∗∣−Hi,iα,0}
由此可见,L1正则化得到的权重更稀疏,最优权重存在一些参数为0。由L1正则化导出的稀疏性质已被广泛地用于特征选择机制,选择有意义的特征,化简机器学习问题。
Dropout
Dropout可以被认为是 集成大量深层网络的Bagging方法,提供了一种廉价的Bagging集成近似,能够训练和评估指数级数量的神经网络。
具体而言,Dropout训练的集成包括所有从基础网络除去非输出单元后形成的子网络,假如网络中除去输出节点外的包含n个节点,则子网络的可能数量为 ∑ i = 0 n C n i = 2 n \sum_{i=0}^nC_n^i=2^n ∑i=0nCni=2n,如图所示:
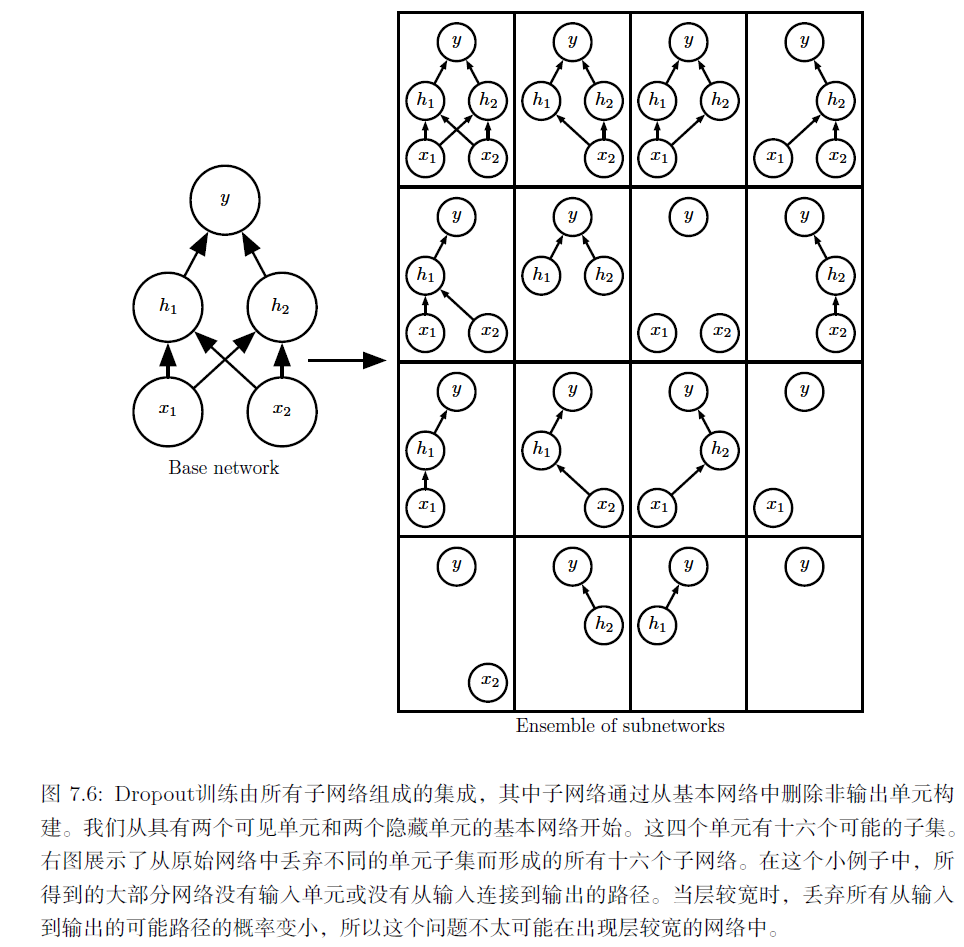
Bagging学习是定义k个不同模型(参数独立),并使用k个独立同分布的训练集分别训练这k个模型,最终集成k个不同模型,而Dropout学习思想类似于Bagging,即使用不同的mini-batch数据集训练不同的子网络,再集成这个子网络(参数共享)。使用Dropout学习,一般父网络单元数较多时,大多数子网络得不到训练,但是不同子网络间参数共享,会使得未训练的子网络也能具有较好的参数。
使用Bagging学习时,每个模型产生一个概率分布,集成预测是由这些分布的算术平均值给出:
1
k
∑
i
=
1
k
p
(
i
)
(
y
∣
x
)
\frac{1}{k}\sum_{i=1}^kp^{(i)}(y|x)
k1i=1∑kp(i)(y∣x)
使用Dropout学习时,通过掩码
u
u
u定义每个子模型的概率分布
p
(
y
∣
x
,
u
)
p(y|x,u)
p(y∣x,u),所有掩码的算术平均值为:
∑
u
p
(
u
)
p
(
y
∣
x
,
u
)
\sum_up(u)p(y|x,u)
u∑p(u)p(y∣x,u)
式中, p ( u ) p(u) p(u)是训练时采样 u u u的概率分布。
掩码算术平均涉及多达指数级的项求和,一般使用集成成员预测分布的几何平均分布取而代之:
p
e
n
s
e
m
b
l
e
(
y
∣
x
)
=
p
~
e
n
s
e
m
b
l
e
(
y
∣
x
)
∑
y
′
p
~
e
n
s
e
m
b
l
e
(
y
′
∣
x
)
,
p
~
e
n
s
e
m
b
l
e
(
y
∣
x
)
=
∏
u
p
(
y
∣
x
,
u
)
2
d
p_{ensemble}(y|x)=\frac{\tilde p_{ensemble}(y|x)}{\sum_y'\tilde p_{ensemble}(y'|x)},\quad \tilde p_{ensemble}(y|x)=\sqrt[2^d]{\prod_up(y|x,u)}
pensemble(y∣x)=∑y′p~ensemble(y′∣x)p~ensemble(y∣x),p~ensemble(y∣x)=2du∏p(y∣x,u)
式中, d d d是被丢弃的单元数。
一般通过评估模型的 p ( y ∣ x ) p(y|x) p(y∣x)来近似 p e n s e m b l e ( y ∣ x ) : p_{ensemble}(y|x): pensemble(y∣x):使用 权重比例推断原则 得到近似集成模型期望化单元输出,如在训练结束后将各单元的输出权重乘以其在训练时对应的droprate(缩小输出),或在训练时将各单元输出除以droprate(放大输出),两种达到的效果大致相同,权重比例推断虽未在深度非线性网络上进行理论论证,但经验上表现很好。
一种关于Dropout有效的解释是,由于其子网络参数共享机制,每个隐藏单元必须能够表现良好,必须准备好进行模型之间的交换,如有性繁殖涉及两个不同生物体基因的交换,进化的压力使得基因不仅良好,还要准备不同有机体之间的交换,使得新个体对环境变化稳健。
Dropout特点:
- 对于n个单元的dropour时间复杂度仅为O(n),需保存掩码状态,空间复杂度为O(n)。
- 不限制适用的模型或训练过程,前馈神经网络、概率模型、循环神经网络均适用。
- 大训练集下,能比正则化带来更小的泛化误差,但小数据集下效果较差。

















 509
509

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









