









机器学习任务通过最小化 “目标函数” 求解,这种目标函数也称为损失函数,损失函数用于衡量模型预测期望输出的能力,损失越小,模型的预测能力越强。
损失函数大致可分为两类:分类损失和回归损失。
Regression loss
常见的回归损失:
Mean Square Error, Quadratic loss, L2 Loss
Mean Square Error (MSE) 是回归任务中最通用的损失函数,MSE是目标值与预测值之间差值平方和的均值:
ℓ
mse
(
f
)
=
1
m
[
Y
−
f
(
X
)
]
2
\ell_{\text{mse}}(f)=\frac{1}{m}[Y-f(X)]^2
ℓmse(f)=m1[Y−f(X)]2
MSE在均值处取极小值:
c
=
arg
min
c
∑
i
1
m
(
y
i
−
c
)
2
=
mean
(
y
)
c=\arg\min_c\sum_i\frac{1}{m}(y_i-c)^2=\text{mean}(y)
c=argcmini∑m1(yi−c)2=mean(y)
Mean Absolute Error, L1 Loss
Mean Absolute Error (MAE) 是目标值与预测值绝对差之和的均值,MAE不考虑误差方向,。
ℓ
abs
=
∣
y
−
f
(
x
)
∣
\ell_{\text{abs}}=|y-f(\boldsymbol x)|
ℓabs=∣y−f(x)∣
MAE在中位数处取极小值:
c
=
arg
min
c
∑
y
≥
c
(
y
−
c
)
+
∑
y
<
c
(
c
−
y
)
=
median
(
y
)
c=\arg\min_c\sum_{y\geq c}(y-c)+\sum_{y<c}(c-y)=\text{median}(y)
c=argcminy≥c∑(y−c)+y<c∑(c−y)=median(y)
考虑方向的损失叫做 Mean Bias Error (MBE),是所有目标值与预测值残差之和的均值,显然小于MAE。
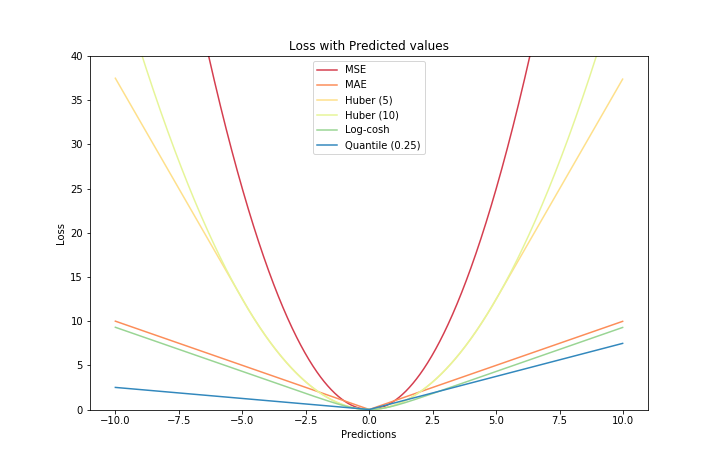
MSE and MAE
简而言之,使用MSE更容易拟合数据,但使用MAE模型对异常值的鲁棒性更强,让我们看看为什么?
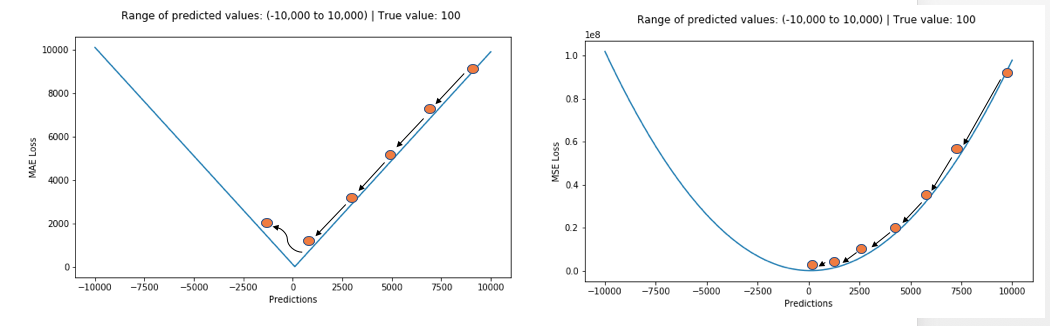
MSE损失在错分样本的损失随目标函数值以平方级变化,而MAE损失以线性级变化,对异常值敏感度低。另一个角度是,MSE最优解位于均值处,MAE最优解位于中位数处,显然中位数解比均值解对异常值的鲁棒性更强。
MSE和MAE的选择
如果异常值对业务很重要,应该使用MSE尽可能的拟合异常值,如果异常值只是噪声数据,则应该用MAE损失。
MSE和MAE均无法拟合的情况
考虑这种情景的数据:90%数据的目标值是150,10%数据的目标值位于0-30之间。MAE可能会把全部目标值预测为150(倾向于中位数),MSE可能预测较多的值位于0-30之间(倾向于异常值),这两种情况我们都不希望看到。
那如何解决这种问题呢?一种简单的方法是转换目标变量(???),另一种方法是使用其它损失函数,如Huber Loss。
Huber Loss, Smooth Mean Absolute Error
Huber损失对异常值没有MSE损失敏感,通过超参数
δ
\delta
δ控制多小的误差使用平方损失、多大的误差使用绝对损失,即真值附近
δ
\delta
δ区间使用MAE损失,否则使用MSE损失:
ℓ
hub
=
{
∣
y
−
f
(
x
)
∣
2
,
∣
y
−
f
(
x
)
∣
≤
δ
2
δ
∣
y
−
f
(
x
)
∣
−
δ
2
,
otherwise
\ell_{\text{hub}}= \begin{cases} |y-f(\boldsymbol x)|^2,&|y-f(\boldsymbol x)|\leq\delta\\[1ex] 2\delta|y-f(\boldsymbol x)|-\delta^2, &\text{otherwise} \end{cases}
ℓhub={∣y−f(x)∣2,2δ∣y−f(x)∣−δ2,∣y−f(x)∣≤δotherwise
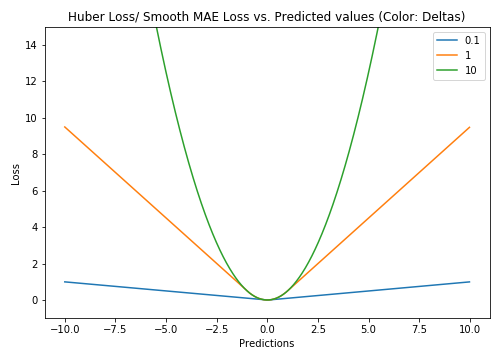
为什么使用Huber损失?
MAE损失在极值点附近梯度非常大,在极值点处非常不稳定,但对异常点不敏感;MSE对异常点敏感,但在接近极值点时梯度逐渐减小至0,可以得到精确极值。
Huber Loss对于包含异常点的数据集一般表现由于以上两者,异常值以MAE方式处理,极值点以MSE方式处理。
Log-Cosh Loss and Quantile Loss
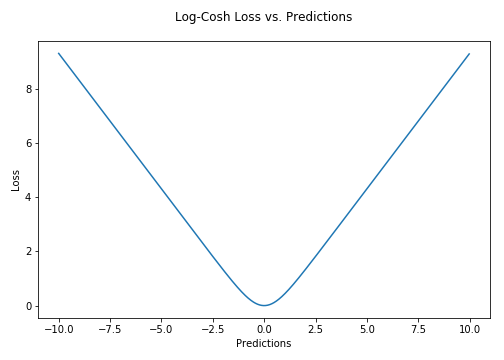 | 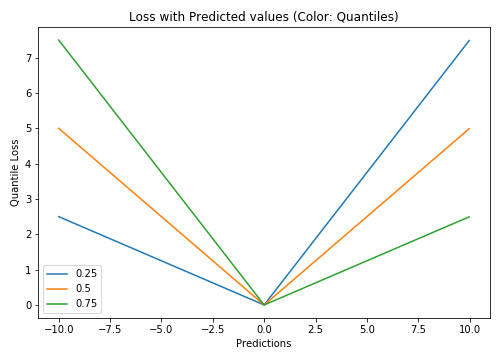 |
Classification loss
常见的分类损失:
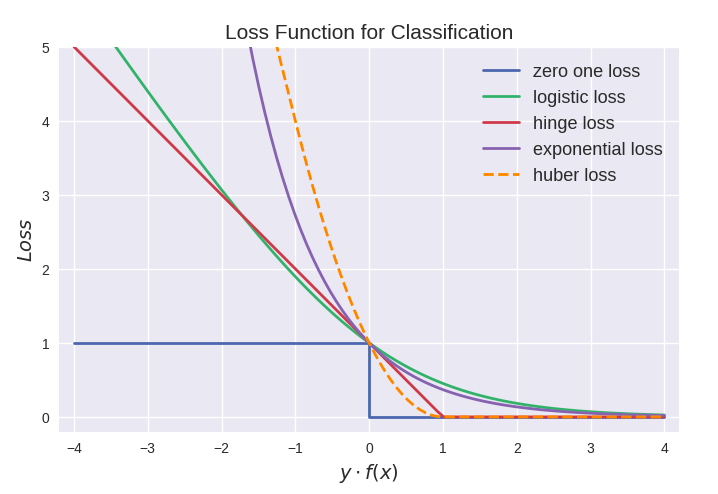
Binomial Deviance (Logistic)
令
p
(
x
)
p(x)
p(x)表示样本
x
\boldsymbol x
x的类1概率,logistic的对数似然损失为
L
(
y
′
,
p
)
=
−
[
y
′
ln
p
(
x
)
+
(
1
−
y
′
)
ln
(
1
−
p
(
x
)
)
]
,
p
(
x
)
=
1
1
+
exp
(
−
f
(
x
)
)
L(y', p)=-[y'\ln p(\boldsymbol x)+(1-y')\ln(1-p(\boldsymbol x))],\quad p(\boldsymbol x) =\frac{1}{1+\exp(-f(\boldsymbol x))}
L(y′,p)=−[y′lnp(x)+(1−y′)ln(1−p(x))],p(x)=1+exp(−f(x))1
则损失函数的负梯度为(sklearn-binomial deviance)
L
(
y
′
,
f
)
=
−
y
′
f
(
x
)
+
ln
(
1
+
exp
(
f
(
x
)
)
)
,
−
∇
f
L
=
y
′
−
1
1
+
exp
(
−
f
(
x
)
)
L(y', f)=-y'f(\boldsymbol x)+\ln(1+\exp(f(\boldsymbol x))),\quad -\nabla_fL=y'-\frac{1}{1+\exp(-f(\boldsymbol x))}
L(y′,f)=−y′f(x)+ln(1+exp(f(x))),−∇fL=y′−1+exp(−f(x))1
(GBDT二分类使用Deviance损失,参数初值)模型初始值满足
c
=
arg
min
c
∑
i
w
i
L
(
y
i
,
c
)
c=\arg\min_c\sum_iw_iL(y_i,c)
c=argminc∑iwiL(yi,c),得
∑
i
w
i
(
y
i
−
1
1
+
e
−
c
)
=
0
⟹
c
=
ln
∑
i
w
i
y
i
∑
i
w
i
(
1
−
y
i
)
\sum_iw_i(y_i-\frac{1}{1+e^{-c}})=0\implies c=\ln\frac{\sum_iw_iy_i}{\sum_iw_i(1-y_i)}
i∑wi(yi−1+e−c1)=0⟹c=ln∑iwi(1−yi)∑iwiyi
Multinomial Deviance (Softmax)
softmax的对数似然损失
L
(
y
,
f
1
,
⋯
,
f
K
)
=
−
∑
k
=
1
K
y
k
ln
p
k
(
x
)
,
p
k
(
x
)
=
exp
f
k
(
x
)
∑
i
exp
f
i
(
x
)
L(y,f_1,\cdots,f_K)=-\sum_{k=1}^Ky_k\ln p_k(\boldsymbol x),\quad p_k(\boldsymbol x)=\frac{\exp f_k(\boldsymbol x)}{\sum_i\exp f_i(\boldsymbol x)}
L(y,f1,⋯,fK)=−k=1∑Kyklnpk(x),pk(x)=∑iexpfi(x)expfk(x)
y k y_k yk表示样本 x \boldsymbol x x的真实类k概率. 可令上式一个冗余目标函数为0,如 f K ( x ) = 0 f_K(\boldsymbol x)=0 fK(x)=0.
第k个目标函数的负梯度
g
k
=
−
∂
L
(
y
,
f
1
,
⋯
,
f
K
)
∂
f
k
=
y
k
−
exp
f
k
(
x
)
∑
i
exp
f
i
(
x
)
g_k=-\frac{\partial L(y,f_1,\cdots,f_K)}{\partial f_k}=y_k-\frac{\exp f_k(\boldsymbol x)}{\sum_i\exp f_i(\boldsymbol x)}
gk=−∂fk∂L(y,f1,⋯,fK)=yk−∑iexpfi(x)expfk(x)
Exponential Loss and Binomial Deviance Loss
给定样本 x \boldsymbol x x,类别 y ∈ { − 1 , + 1 } y\in\{-1,+1\} y∈{−1,+1},类别另一种表示 y ′ = ( y + 1 ) / 2 ∈ { 0 , 1 } y'=(y+1)/2\in\{0,1\} y′=(y+1)/2∈{0,1}.
二项偏差(Binomial Deviance)的类1概率为
p
(
x
)
=
P
(
y
=
1
∣
x
)
=
exp
(
f
(
x
)
)
exp
(
−
f
(
x
)
)
+
exp
(
f
(
x
)
)
=
1
1
+
exp
(
−
2
f
(
x
)
)
p(\boldsymbol x)=P(y=1|\boldsymbol x) =\frac{\exp(f(\boldsymbol x))}{\exp(-f(\boldsymbol x))+\exp(f(\boldsymbol x))} =\frac{1}{1+\exp(-2f(\boldsymbol x))}
p(x)=P(y=1∣x)=exp(−f(x))+exp(f(x))exp(f(x))=1+exp(−2f(x))1
二项偏差的对数似然损失(极大化似然概率等于极小化交叉熵)
−
[
y
′
ln
p
(
x
)
+
(
1
−
y
′
)
ln
(
1
−
p
(
x
)
)
]
=
−
ln
(
1
+
exp
(
−
2
y
f
(
x
)
)
)
-[y'\ln p(\boldsymbol x)+(1-y')\ln(1-p(\boldsymbol x))]=-\ln(1+\exp(-2yf(\boldsymbol x)))
−[y′lnp(x)+(1−y′)ln(1−p(x))]=−ln(1+exp(−2yf(x)))
基于经验风险最小化求解模型,则指数损失和二项偏差损失的解具有一致性,以下公式给出
f
(
x
)
=
arg
min
f
E
y
∣
x
[
exp
(
−
y
f
(
x
)
)
]
=
arg
min
f
P
(
y
=
1
∣
x
)
⋅
exp
(
−
f
(
x
)
)
+
P
(
y
=
−
1
∣
x
)
⋅
exp
(
f
(
x
)
)
=
1
2
ln
P
(
y
=
1
∣
x
)
P
(
y
=
−
1
∣
x
)
=
arg
min
f
E
y
∣
x
[
−
ln
(
1
+
exp
(
−
2
y
f
(
x
)
)
)
]
\begin{aligned} f(\boldsymbol x) &=\arg\min_f\Bbb E_{y|\boldsymbol x}[\exp(-yf(\boldsymbol x))]\\[2ex] &=\arg\min_fP(y=1|\boldsymbol x)\cdot\exp(-f(\boldsymbol x))+P(y=-1|\boldsymbol x)\cdot\exp(f(\boldsymbol x))\\[2ex] &=\frac{1}{2}\ln\frac{P(y=1|x)}{P(y=-1|x)}\\[2ex] &=\arg\min_f\Bbb E_{y|\boldsymbol x}[-\ln(1+\exp(-2yf(\boldsymbol x)))] \end{aligned}
f(x)=argfminEy∣x[exp(−yf(x))]=argfminP(y=1∣x)⋅exp(−f(x))+P(y=−1∣x)⋅exp(f(x))=21lnP(y=−1∣x)P(y=1∣x)=argfminEy∣x[−ln(1+exp(−2yf(x)))]
但两者在错分样本上损失程度不同,指数损失在错分样本的损失随目标函数取值以指数级变化(对异常值敏感如类标错误数据),而二项偏差损失以线性级变化.
Hinge Loss (SVM)
合页损失是SVM的损失函数,对于 y f ( x ) > 1 yf(x)>1 yf(x)>1的点,合页损失都是0,由此带来了稀疏解,使得SVM仅通过少量的支持向量就能确定最终分类超平面。
SVM的损失函数是合页损失 + L2正则化。
Reference
1. Regression Loss Functions All Machine Learners Should Know
2. 常见回归和分类损失函数比较

















 3652
3652

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









