







YOLOv7 目标检测算法深度解析
一、YOLOv7 核心原理与技术架构
YOLOv7 延续了YOLO系列单阶段目标检测范式,通过端到端网络直接预测目标边界框与类别。其核心创新点集中于网络架构优化、动态标签分配及模型缩放策略,实现了速度与精度的双重突破。
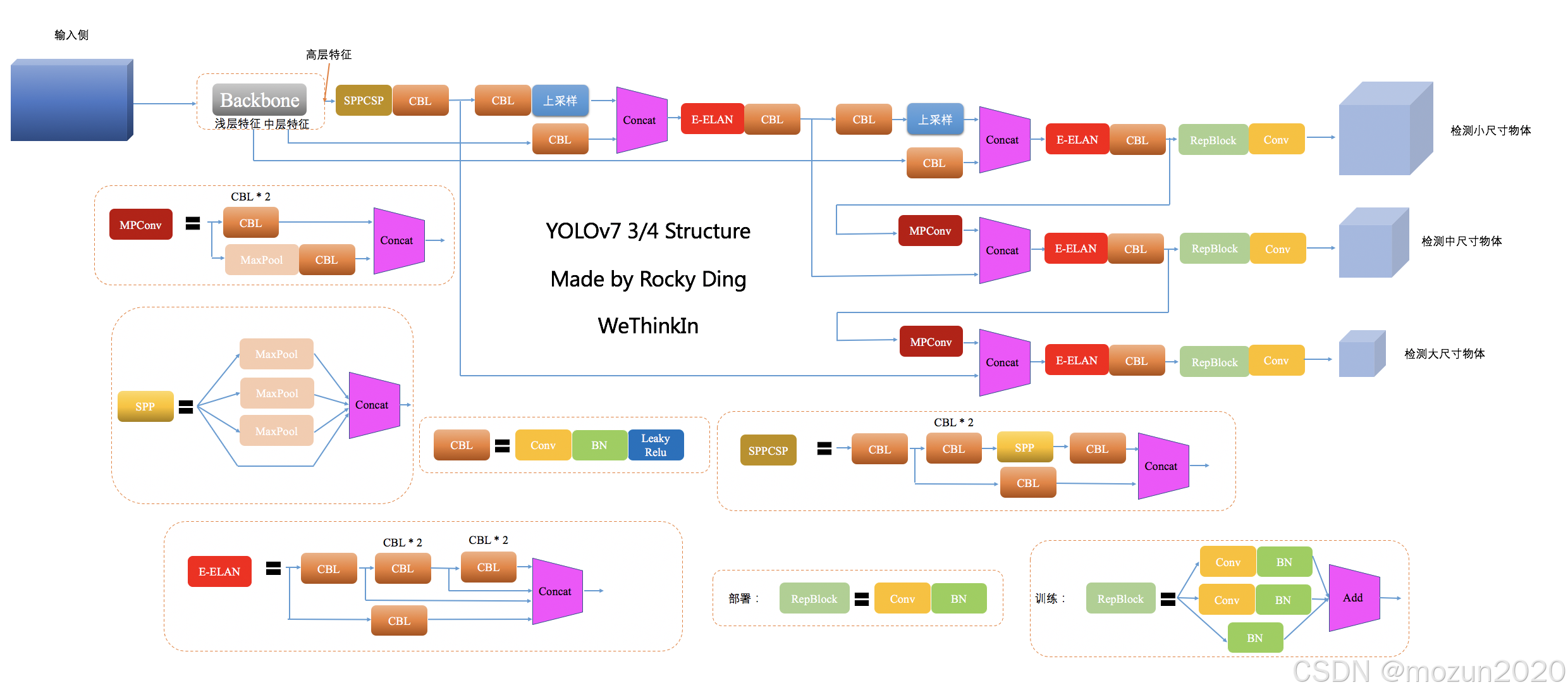
1.1 网络架构三段式设计
-
Backbone(主干特征提取)
- 输入处理:将输入图像缩放至640×640,通过CBS模块(Conv+BN+SiLU)进行初步特征提取。
- ELAN模块:采用多分支并行结构,融合不同尺度特征(如80×80×512、40×40×1024、20×20×1024),增强模型对多尺度目标的感知能力。
- SPPCSP结构:通过空间金字塔池化扩大感受野,适应不同大小目标。
-
Neck(特征增强)
- PANet路径聚合:结合上采样(如将40×40特征上采样至80×80)与下采样(如将20×20特征下采样至40×40),实现多尺度特征融合。
- RepConv重参数化:训练时采用多分支结构(如3×3卷积+1×1卷积),推理时合并为单一卷积,减少计算量。
-
Head(预测输出)
- 解耦头设计:分类与回归任务分离,通过1×1卷积生成预测结果。
- Anchor机制:每个尺度特征图预设3种宽高比Anchor,输出通道数为
3×(1+4+num_cls)(1为置信度,4为边界框坐标,num_cls为类别数)。
二、网络层参数统计与实现细节
2.1 卷积层(Conv Layer)
- 结构:由CBS模块(Conv+BN+SiLU)构成,如:
- 输入层:640×640×3 → 经过4层CBS后输出160×160×128。
- ELAN模块:8层CBS堆叠,保持输入输出尺寸一致(如80×80×512)。
- 参数计算:
- 卷积核参数:
K×K×C_in×C_out(如3×3×128×256)。 - BN层参数:
2×C_out(均值与方差)。
- 卷积核参数:
2.2 池化层(Pooling Layer)
- MaxPooling:用于下采样(如步长2的2×2池化),减少特征图尺寸。
- SPPCSP中的多尺度池化:并行使用5×5、9×9、13×13池化核,增强特征鲁棒性。
2.3 全连接层(FC Layer)
- 结构:仅在Head部分间接使用(通过1×1卷积实现分类与回归)。
- 参数:如分类分支输出
num_cls个节点,回归分支输出4个节点(边界框坐标)。
2.4 输出层(Output Layer)
- 预测内容:
- 边界框坐标(x, y, w, h)
- 置信度(Objectness Score)
- 类别概率(Class Probabilities)
- 输出尺寸:
- 三尺度特征图(80×80、40×40、20×20),每尺度对应3个Anchor。
- 总输出通道数:
3×(1+4+num_cls)×(80×80+40×40+20×20)。
三、YOLOv7 优劣势分析
3.1 优势
- 速度与精度平衡:在COCO数据集上AP达56.8%,同时保持30+ FPS(V100 GPU)。
- 模型轻量化:YOLOv7-Tiny参数量仅6.2M,适合边缘设备部署。
- 动态标签分配:通过Lead Head生成软标签,提升小目标检测精度。
3.2 劣势
- 计算资源需求:大规模模型(如YOLOv7-X)需高性能GPU。
- 小目标检测局限:尽管支持多尺度,但极小目标(如<10×10像素)仍需优化。
四、关键创新点解析
4.1 E-ELAN模块
- 扩展-混洗-合并策略:通过分组卷积扩展通道数,再随机混洗特征图,增强特征多样性。
- 梯度路径优化:保持ELAN原有梯度传输路径,避免参数利用率下降。
4.2 重参数化技术
- 训练-推理解耦:训练时采用多分支结构(如RepConv),推理时合并为单一卷积,提升速度。
4.3 基于级联的模型缩放
- 复合缩放策略:同时调整计算块深度与过渡层宽度,保持模型最优结构。
4.4 动态标签分配
- 软标签生成:利用Lead Head预测结果生成粗细粒度标签,指导Auxiliary Head训练。
五、性能表现与对比
| 模型 | AP(COCO) | FPS(V100) | 参数量(M) |
|---|---|---|---|
| YOLOv7 | 56.8 | 30+ | 36.7 |
| YOLOv5 | 55.4 | 13.5 | 27.3 |
| YOLOX | 50.1 | 12.5 | 54.2 |
| YOLOv7-Tiny | 38.7 | 345 | 6.2 |
六、硬件部署方案
6.1 GPU部署
- 环境准备:
- 安装CUDA 11.3+、cuDNN 8.2+。
- 使用PyTorch框架(需与CUDA版本兼容)。
- 推理流程:
import torch model = torch.hub.load('WongKinYiu/yolov7', 'yolov7', pretrained=True) results = model(input_image)
6.2 边缘设备部署
- TensorRT优化:
- 将模型转换为ONNX格式,再通过TensorRT量化(如FP16)加速。
- 部署至Jetson AGX等设备,实现低延迟推理。
6.3 轻量化变体
- YOLOv7-Tiny:
- 参数量减少39%,计算量降低49%,适合移动端部署。
- 通过调整CBS模块数量与ELAN分支数实现轻量化。

七、总结与展望
YOLOv7通过E-ELAN、重参数化、动态标签分配等创新,实现了速度与精度的双重突破。其灵活的网络架构与部署方案,使其既适用于云端高性能计算,也可部署至边缘设备。未来,结合Transformer架构或自动模型压缩技术,YOLOv7有望进一步拓展应用场景。



















 9865
9865

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











