







论文题目:Mimic before Reconstruct: Enhancing Masked Autoencoders with Feature Mimicking
论文地址:https://arxiv.org/abs/2303.05475
代码地址:GitHub - Alpha-VL/ConvMAE: ConvMAE: Masked Convolution Meets Masked Autoencoders(好像并未更新为MR-MAE模型)
MR-MAE是在ConvMAE基础上提出的后续文章
ConvMAE相关信息如下:
论文题目:ConvMAE: Masked Convolution Meets Masked Autoencoders
论文地址:https://arxiv.org/abs/2205.03892
代码地址:GitHub - Alpha-VL/ConvMAE: ConvMAE: Masked Convolution Meets Masked Autoencoders
摘要
掩模自编码器(MAE)是一种流行的大规模视觉表征预训练方法。然而,MAE仅在解码器之后重建低级RGB信号,缺乏对编码器高级语义的监督,因此存在次优学习表征和较长的预训练时间。为了缓解这一问题,以前的方法只是用预训练图像(DINO)或图像语言(CLIP)对比学习的编码特征替换75%的掩码标记的像素重建目标。与这些研究不同的是,我们提出了先模仿后重建的掩膜自编码器,称为MR-MAE,它在预训练过程中不受干扰地共同学习高级和低级表征。对于高级语义,MR-MAE使用来自编码器的超过25%的可见标记的模拟损失来捕获在CLIP和DINO中编码的预训练模式。对于低级结构,我们继承MAE中的重建损失来预测解码器后75%掩码令牌的RGB像素值。由于MR-MAE在不同的分区分别应用高级和低级目标,它们之间的学习冲突可以自然地被克服,并有助于为各种下游任务提供更好的视觉表征。在ImageNet-1K上,预训练仅400 epoch的MR-MAE基础在微调后达到85.8%的top-1精度,比1600 epoch的MAE基础高出2.2%,比之前最先进的BEiT V2基础高出0.3%。代码和预训练模型将在https://github.com/Alpha-VL/ConvMAE上发布。
提炼
MR-MAE出发点:MAE仅在解码器之后重建低级RGB信号,缺乏对编码器高级语义的监督
已有方法:用预训练图像(DINO)或图像语言(CLIP)对比学习的编码特征替换75%的掩码标记的像素重建目标
MR-MAE方法:
-
结合DINO、CLIP和MAE,联合学习高级和低级表示;
-
使用Mimic避免冲突
-
使用encoder输出高级表示,decoder输出低级表示
创新点
-
MR-MAE同时利用高级表示和低级表示,并通过对这两个目标的学习来促进编码器的预训练
-
重建损失遵循MAE,学习低级表示。原始的MAE随机抽取25%的可见标记,并由编码器处理它们。然后,将混合位置嵌入的编码标记送入轻量级解码器,用于预测75%掩码标记的像素值。
-
MR-MAE通过模拟损失学习高级表示,该模拟损失仅应用于编码器之后的可见token。模拟损失最小化了MAE编码器输出与由现成的预训练图像语言(CLIP)或图像-图像(DINO)生成的高级特征之间的L2距离。
-
模拟损失和重建损失应用于不同的令牌组(25%可见vs 75%掩码)和不同的网络层(编码器vs解码器的输出),MRMAE很好地解决了低级和高级学习目标之间的监督冲突。
相关工作
MAE
蒙面语言建模(MLM)通过大规模预训练彻底改变了自然语言理解。受此启发,MAE将 MLM 范式应用到视觉表示学习中。MAE只编码25%的可见图像标记,并重建其他75%掩码标记的RGB像素值。
与MLM相比,MAE存在以下缺点:
-
首先,与语言建模中的高级监督不同,MAE 的低级RGB信号过于原始和冗余,无法充分释放掩码自编码对下游视觉任务的理解能力。
-
其次,MAE 采用了重编码器和轻解码器的非对称架构,其中编码器经过预训练后保留,用于下游迁移学习。然而,MAE只对解码器的输出进行预训练监督,不足以引导编码器,并且减慢了预训练阶段的收敛速度。
对比学习
对比学习通过从信号源的增强视图中提取不变性,在学习有效的视觉表征方面取得了巨大的成功。DINO和CLIP是对比学习范式中的两种典型方法。
DINO通过图像-图像对比学习预训练的ViT产生了强烈的对象性。CLIP通过图像-文本对对比学习,展示了惊人的零样本学习能力。但是,DINO和CLIP在下游任务上的微调性能不如通过 MAE 方式学习的表征。
为了构建更有效的重构目标,现有的部分方法探索现成的预训练DINO、CLIP或在线动量特征作为高级监督。但是,考虑到不同目标同时重建造成的干扰,以往的方法都是简单地用高阶特征代替原有的RGB像素目标,只利用高阶特征来监督解码器的输出。
模型框架
整个训练过程可以分为预训练和下游任务,下游任务只使用预训练后的教师模型
预训练时的借口任务分别是重构任务和对比任务,目的是联合学习低级表示和高级表示,重构任务基于MAE模式进行

简单来说是在MAE的基础上,并行的添加了一个已经预训练好的模型(DINO或CLIP)对MAE的encoder输出进行约束。
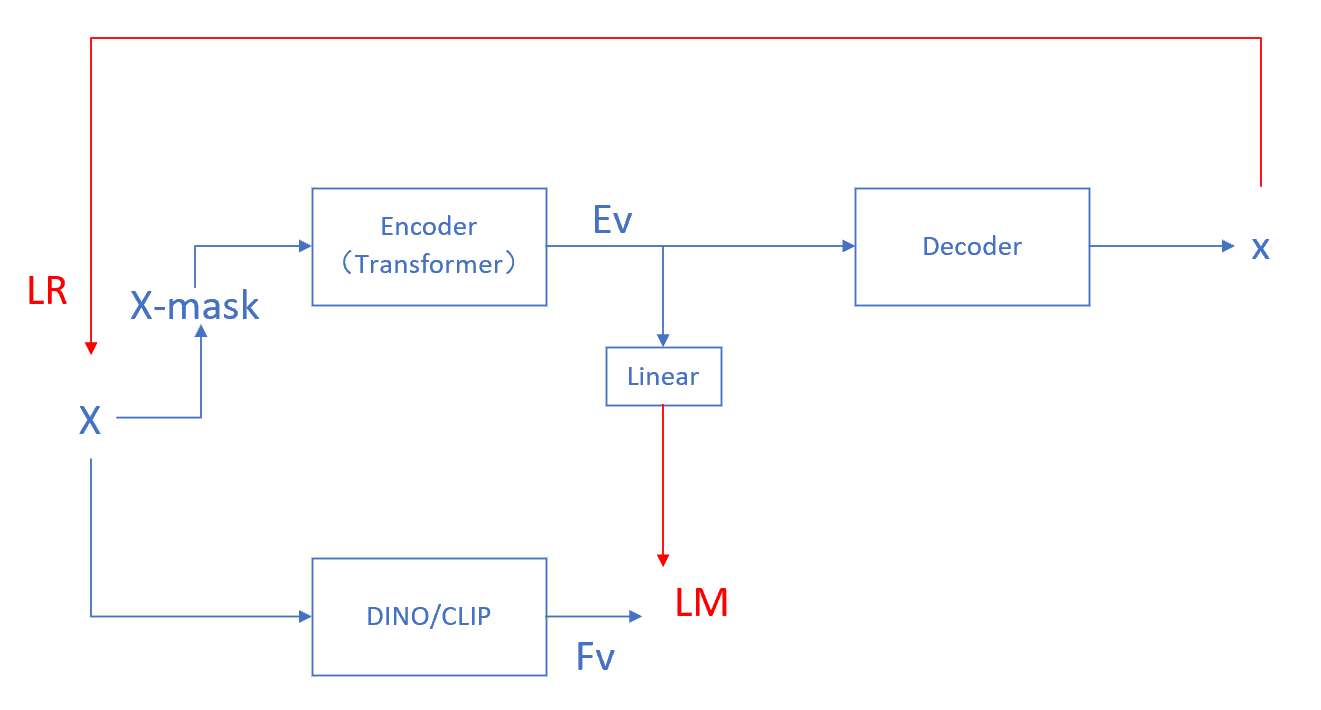
学习低级表示
MAE 采用非对称编码器-解码器设计,给定一个输入图像,MAE首先将其分成均匀的 patch,并随机屏蔽其中的75%。我们分别用 Im 和 Iv 表示被遮挡的和可见的 patch,然后,将25%的可见 patch 进行标记并送到encoder(transformer)中以产生c维中间表示Ev。MAE采用轻量级变压器解码器预测Dm,重建被屏蔽令牌的RGB值。在Dm和Im之间使用L2重构损耗LR:
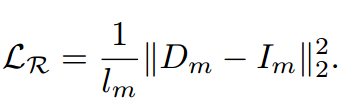
学习高级表示
MR-MAE使用预训练的现成特征编码器对中间表示进行正则化来增强MAE,即用预训练好的DINO或CLIP产生的高级特征来引导编码器的中间Ev,首先通过将输入图像送到基于transformer的视觉编码器中提取DINO或CLIP特征,表示为Fv,。通过一个线性投影层变换可见表示Ev来模拟Fv。Lm模拟损失定义为:
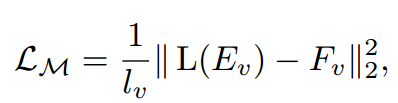
由于针对可见标记的特征模拟损失LM和针对掩蔽标记的重建损失LR旨在编码输入图像的不同方面,即高级语义和低级纹理,因此它们可以相互补充,以学习更具区别性的表示。
其他技巧
特征选择
MAE采用随机屏蔽策略进行可见令牌选择,这是低电平信号重建的自然选择,无需额外的引导。由于现成预训练模型中的cls token可以通过其注意图清楚地描绘重要区域,因此我们选择教师网络(即DINO/CLIP)注意图中最突出的token进行可见特征模仿。通过这种方式,MR-MAE可以更好地捕获教师网络中编码的信息性高级语义,而不是非显著的低级语义。
多层融合
MAE仅将编码器最后一层的输出令牌馈送到解码器以进行掩码像素重建。由于编码器的不同层可能描述图像的不同抽象层次,我们通过元素值相加来融合来自多个编码器中间层的可见标记,然后利用融合后的标记进行高层特征模拟和低层像素重建。这样,特征模拟的监督可以直接应用到编码器的多层,从而改善视觉表示。
mask的卷积
由于物体存在于不同的尺度,对多尺度视觉信息的探索在计算机视觉任务中取得了巨大的成功。在MCMAE之后,我们在Transformer块之前附加了额外的mask卷积,以有效地捕获高分辨率细节,并应用多尺度逐块掩膜来防止信息泄漏以进行像素重建。这种多尺度编码可以学习分层表示,并在下游任务上取得显著改进。
实验
参数设置
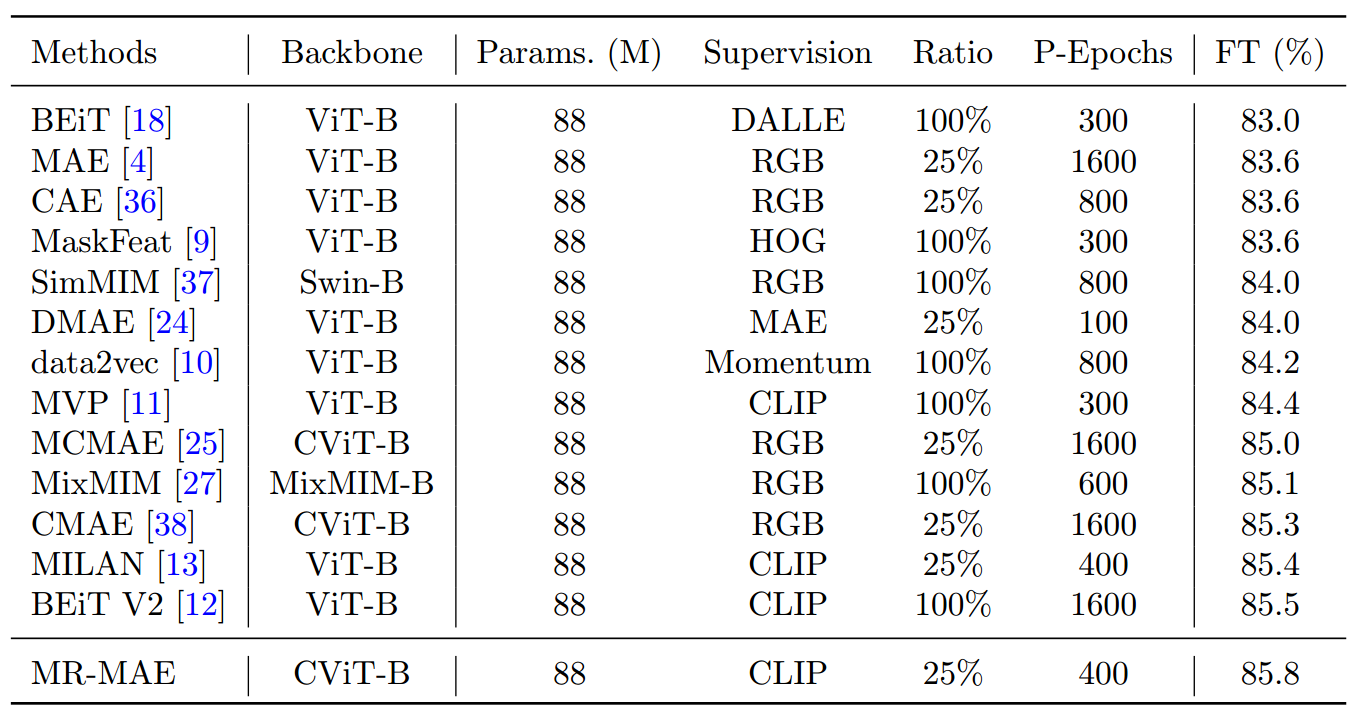
遵循ImageNet-1K的预训练和微调协议。MR-MAE预训练400个epoch,batch size为1024,权重衰减为0.05。采用AdamW优化器和余弦学习率调度器,最大学习率为1.5 × 10−4,预热 80 个epoch。使用25%的mask ratio和8个解码器块。对权重分别为0.5和0.5的重构损失和模拟损失进行了联合优化。选择经过CLIP预训练的ViT-B/16作为高级别教师。
在自监督预训练之后,微调100个epoch,预热5个epoch。采用与预训练相同的批大小、优化器和权重衰减。初始学习率、分层学习率衰减和下降路径率分别设置为3 ×10−4、0.6和0.2。
对比方法
BeiT , MAE , CAE用于预训练视觉变压器,采用低阶像素的重建和各向同性架构
SimMIM、MCMAE和MixMIM在MIM中引入了多尺度特征,与各向同性架构相比,提高了微调精度,仍然重建低水平信号
MaskFeat、data2vec、MVP和MILAN通过整合DINO、动量特征和CLIP,直接用高水平语义目标代替低水平信号的重建
MILAN提出了一种新的提升解码器和语义感知掩蔽,通过重构高级特征来增强特征学习
BeiT V2将原始的DALL-E标记器替换为通过自编码CLIP特征学习的高级语义标记器
CMAE通过对比损失和重建损失的联合优化来学习表征。与CMAE不同的是,MR-MAE使用了大规模图像-文本对比学习预训练的教师模型,该模型包含更丰富的语义知识
DMAE采用了与MR-MAE类似的方法,它模仿预训练的教师生成的特征,重建低级像素
对象检测
MRMAE能够有效提高检测率并缩短了训练轮次
消融实验
主要贡献点
比较文章提出了主要贡献点,包括两种损失以及三种技巧
可以看出Lm对结果产生了较大帮助,提升了1.7%得到准确率,另外三个技巧分别提升了0.2%,0.1%和0.5%

任务目标
由于低级目标和高级目标包含不同的视觉语义,它们的联合监督可能会相互冲突。如上表第4、5行所示,低水平和高水平目标直接联合重建使ImageNet-1K微调精度下降-1.7%。
另外,不同的高级目标也会影响模型性能。由于图像-图像对比学习(DINO)和图像-语言对比学习(CLIP)编码了不同的高级语义,用不同的高级语义来降低MR-MAE库的性能。
-
CLIP生成的特征可以超过DINO +1%。这意味着图像-语言对比学习比图像-图像对比学习提供了更强的高级语义。
-
用不同的高阶目标对MR-MAE进行预训练和微调,然后将两个模型集成。CLIP/DINO (Sep.)可以超过CLIP/DINO (Joint) +1.7%,验证了不同目标学习到的互补表示。

模型大小和训练次数
引入高级目标可以使MIM方法收敛得更快,MR-MAE在各种尺寸的模型上效果都优于MAE和MCMAE
可视化结果
可视化不同模型的最后一个自注意层的 CLS token 的注意图
-
MAE的目标是低级像素重建,因此其注意力偏向于纹理模式
-
DINO的注意力过分强调突出对象的部分信息
-
MR-MAE的注意力可以捕获完整的目标信息。

总结
-
MR-MAE保留了MAE的结构,在保证encoder学习低级表示的同时,加入了高级表示学习部分
-
MR-MAE模型使用了已经预训练好的DINO/CLIP模型作为学习高级表示的教师模型,迫使encoder学习高级表示
-
MR-MAE性能的提升也用到了一些其他技巧:可见token的选择,多层特征融合,mask卷积















 10万+
10万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









