







1月20日,一个改写AI历史的时刻悄然而至。中国AI公司DeepSeek发布DeepSeek R1模型。发布不到一周,就冲到了苹果App Store中国区免费榜第一名。
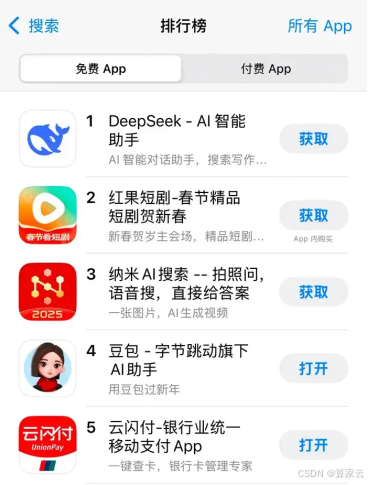
DeepSeek在2024年末带来了年终大礼,美股却迎来了历史性崩盘。
截至美东时间1月27日,英伟达股价暴跌近17%!一夜市值减少近6000亿美元,创下了单个公司史上最大市值损失纪录。
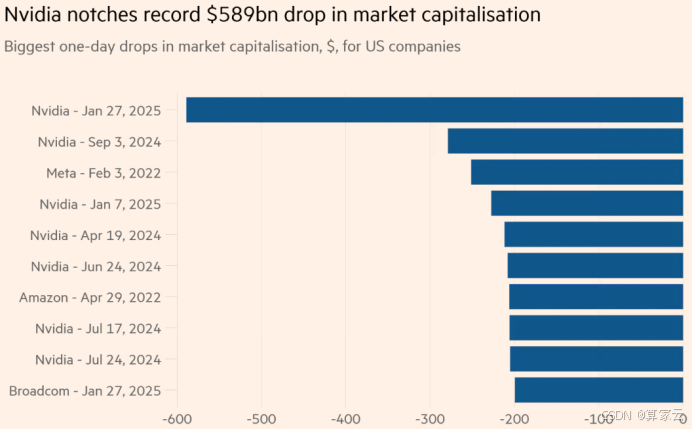
不仅如此,DeepSeek也引爆了国内外各大社交平台的热烈讨论。
英伟达资深研究员Jim Fan高度评价了DeepSeek在开源领域的贡献,还犀利地批评了Open AI“挤牙膏式”的技术发布策略——今天放个预告,明天发个代号,却始终对核心细节避而不谈。

UC Berkeley教授Alex Dimakis直言“DeepSeek在推理模型的泛化性与成本控制上已形成代际优势,美国企业必须加速迭代才能避免技术脱钩”。
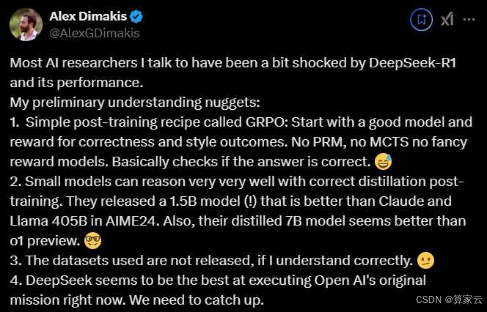
DeepSeek带来的火爆现象,让每一个中国人,都忍不住喊一声“DeepSeek牛逼!”
DeepSeek引领AI算力革命,攻破算力“护城河”
这不是普通的技术进展,而是一场颠覆性的AI算力革命。AI巨头们重金打造的算力护城河正在被 DeepSeek 带来的技术革命填平。
除开大家都在夸赞的性能和开源,DeepSeek的意义更在于开辟了一条全新道路:用最小的算力投入,实现最大的智能涌现,也就是真正实现了“降本增效”。
要知道,OpenAI等美国AI龙头企业对AI的投入,是其他国家难以企及的程度。光是AI的耗电量就几乎达到了美国发电量的3%。微软、谷歌、Meta、亚马逊等大厂分别拥有几十到上百万块H100,更别说上个月美国还宣布了历史上规模最大的科技投资计划——“星际之门”人工智能基础设施投资计划。

依赖强大的硬件优势,这些国际巨头在很长一段时间内制造了其他AI企业不可攻破的壁垒。此前,国内六大通用模型厂商(如文心一言、通义千问等)也依赖高算力投入追赶国际巨头,但技术代差始终存在。
而DeepSeek的出现则颠覆了传统逻辑。
为什么这么说呢?DeepSeek-R1通过算法结构的优化,仅用了10%的算力成本就训练出性能比肩GPT-4的6000亿参数模型!直接冲击传统“堆算力换性能”的路径。
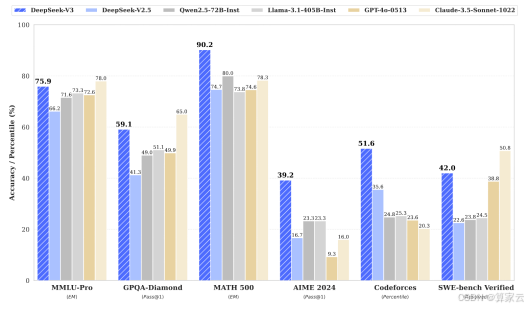
用更少的算力,却获得了堪比o1的性能。更牛的是,不仅性能相当,DeepSeek还是开源模型!这让各AI大牛也不得不感叹:这才是引领人类未来的AI之光!
算力需求改变,AI算力的“平民化”时代即将到来
DeepSeek的成功戳破了算力的护城河,打破了国外厂商对AI芯片市场的垄断,为国内AI产业发展注入了强心剂。这也可能会促使更多企业加入AI浪潮。
在算力需求结构方面,DeepSeek的成功可能会加快推理模型的发展,从而导致算力需求向推理侧改变。未来,市场对推理算力的需求可能会进一步增加。
另一方面,这也会使 AI 应用门槛进一步降低。随着大量中小企业和初创公司的加入,算力租赁可能会成为性价比更高且风险较低的最优选择。

因为这些企业自身不具备大规模建设算力设施的能力和资源,选择租赁算力,将大幅降低AI算力的使用门槛,使得更多企业和机构能够负担得起AI技术,从而推动AI技术在更广泛的应用场景中落地。
未来,随着AI技术的不断进步和应用场景的不断拓展,算力租赁将成为AI产业发展的重要基础设施。 DeepSeek-R1的成功只是一个开始,相信未来会有更多像DeepSeek这样的企业涌现出来,共同推动算力租赁行业的发展,构建更加智能的未来。


















 756
756

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









