







前面 2 篇文章,我们通过查看 Transformers 包代码,学习了 Transformer 包模块 API 设计、模型初始化和加载流程:
- 第 1 篇:transformers 推理 Qwen2.5 等大模型技术细节详解(一)transformers 包和对象加载
- 第 2 篇:transformers 推理 Qwen2.5 等大模型技术细节详解(二)AutoModel 初始化和模型加载
本文是 Transformers 推理 LLM 大语言模型技术细节的第 3 篇,我们将基于 Qwen2.5 大模型,通过走读 Transformers 源代码的方式,来学习AutoTokenizer技术细节:
- 环境准备:配置虚拟环境,下载 Qwen2.5 模型文件
- AutoTokenizer分词器介绍、初始化和存储代码流程的技术细节
- Qwen2.5使用的分词算法介绍,和一些常用的 Token 操作用法
环境准备:配置虚拟环境和下载模型文件
【配置虚拟环境】 我们可以继续使用在上一篇中我们已经配置好的虚拟环境:
# Python虚拟环境名:Qwen2.5,版本号:3.10
conda create -n Qwen2.5 python=3.10 -y
# 激活虚拟环境
conda activate Qwen2.5
# 安装必要的Python依赖包
pip install torch
pip install "transformers>=4.43.1"
pip install "accelerate>=0.26.0"
【下载 Qwen2.5 模型文件】 我们也可以继续使用在上一篇中下载好的模型文件:
# Git大文件系统
git lfs install
# 下载模型文件
git clone https://www.modelscope.cn/qwen/Qwen2.5-1.5B-Instruct.git Qwen2.5-1.5B-Instruct
# 若下载过程中异常中断,可以通过`git lfs install`命令继续下载:
# 切换到Git目录
cd Qwen2.5-1.5B-Instruct
# 中断继续下载
git lfs install
git lfs pull
AutoTokenizer 初始化和存储流程
在大模型中,分词就是把模型的输入内容(如:文本序列)转换为Token(也称:词元)序列,Token 是最小的语义单元,且每个 Token 都有相对完整的语义。
如下代码示例,我们可以通过AutoTokenizer.from_pretrained方法初始化分词器:
import os
from transformers import AutoTokenizer
# 初始化分词器,从本地文件加载模型
model_dir = os.path.join('D:', os.path.sep, 'ModelSpace', 'Qwen2.5', 'Qwen2.5-1.5B-Instruct')
tokenizer = AutoTokenizer.from_pretrained(
model_dir,
local_files_only=True,
)
根据第 1 篇Transformers 包模块设计,我们可以找到AutoTokenizer类定义在./models/auto/tokenization_auto.py模块中,我们可以走读from_pretrained方法执行流程:
第 1 步:AutoTokenizer.from_pretrained解析tokenizer_config.json配置文件,获取tokenizer_class配置项,Qwen2.5 的配置文件中的值为Qwen2Tokenizer:
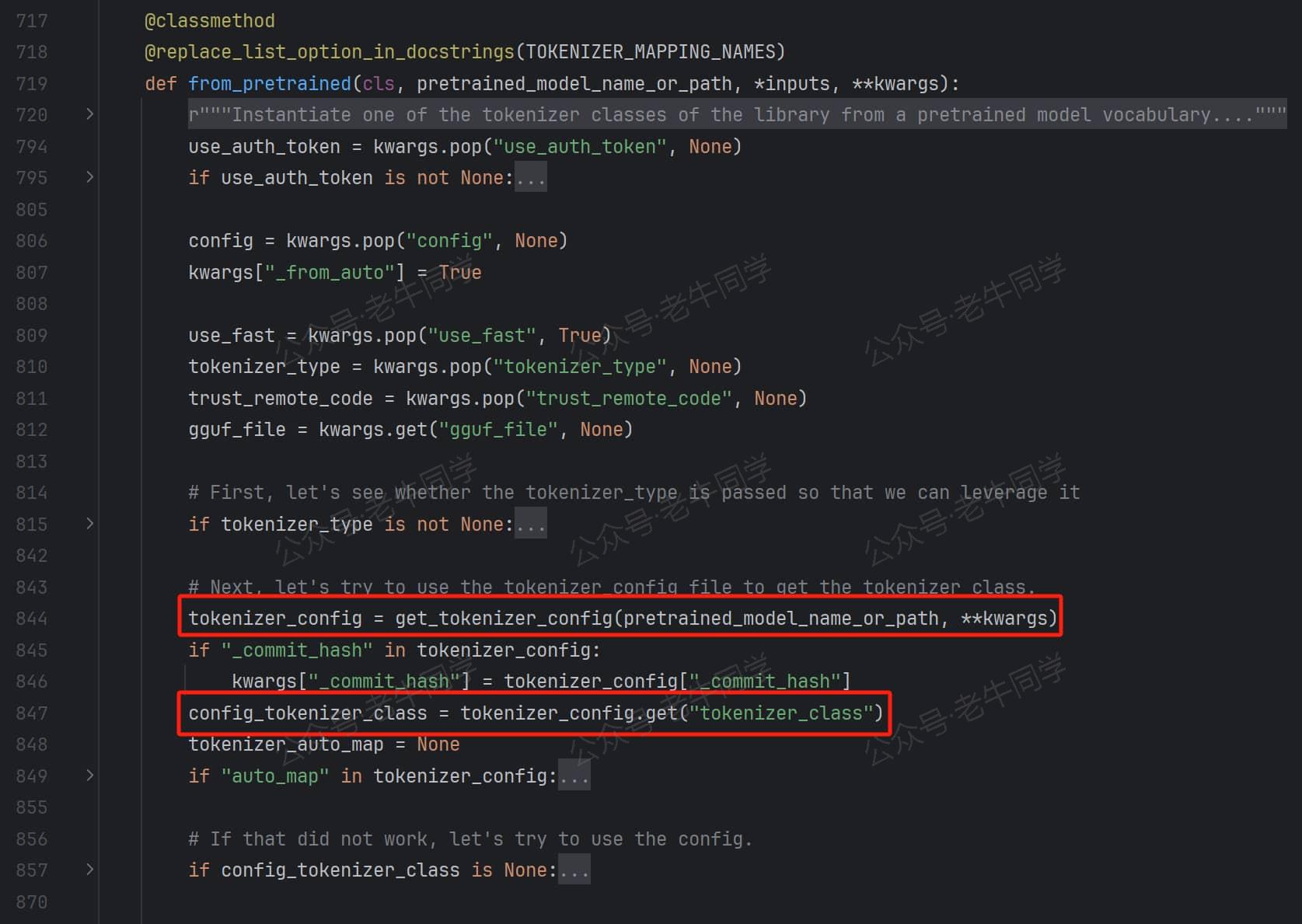
第 2 步:默认情况下,Transformers 优先使用带有Fast结尾的、性能更好的分词器实现。因此会先把Qwen2Tokenizer类型转为Qwen2TokenizerFast类,并调用tokenizer_class_from_name()方法加载Qwen2TokenizerFast类:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2719
2719

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









